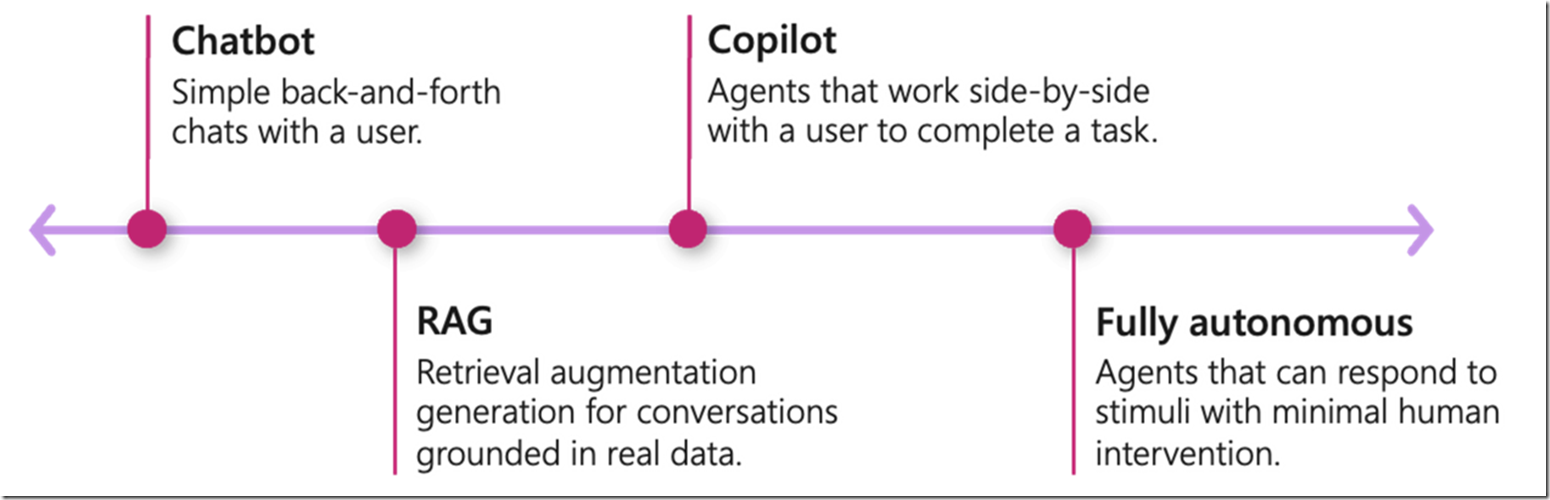
文本张量入门
张量,英文为Tensor,是机器学习的基本构建模块,是以数字方式表示数据的形式。
张量的基本类型:
创建一个标量(0维张量),也就是一个单独的数字
scalar = torch.tensor(7)
scalar.ndim # 返回张量的维度
0 # 因为标量是一个单一的数值,没有维度
创建一个向量(1维张量),包含两个元素
vector = torch.tensor([7, 7])
vector.ndim # 返回张量的维度
1 # 因为向量是一维的,只有一个轴,可以看作是一个行或者列向量
创建一个矩阵(2维张量),包含两行两列
MATRIX = torch.tensor([[7, 8],
[9, 10]])
MATRIX.ndim # 返回张量的维度
2 # 因为矩阵是二维的,有两个轴:行和列
创建一个三维张量,包含一个2x3的矩阵
TENSOR = torch.tensor([[[1, 2, 3],
[3, 6, 9],
[2, 4, 5]]])
TENSOR.ndim # 返回张量的维度
3 # 三维张量有三个轴,可以看作是一个立方体的形状
**注释解释**:
- **标量(scalar)**:只包含一个单独数值,没有维度。
- **向量(vector)**:包含多个数值,只有一个维度(行向量或列向量)。
- **矩阵(matrix)**:包含多行多列的数值,有两个维度:行和列。
- **多维张量(tensor)**:包含多个维度,可以有三维或更多维度,每个维度对应不同的轴。张量的创建:
torch.tensor() 根据指定数据创建张量
```python
import torch
import numpy as np# 1. 创建一个张量(标量)
data = torch.tensor(10)
print(data)
>>> tensor(10)# 2. 使用 numpy 数组创建张量
data = np.random.randn(2, 3) # 生成一个2x3的随机数组(数据类型为 float64)
data = torch.tensor(data) # 将numpy数组转换为PyTorch张量
print(data)
>>> tensor([[ 0.1345, 0.1149, 0.2435],[ 0.8026, -0.6744, -1.0918]], dtype=torch.float64)# 3. 使用列表创建张量(默认元素类型为 float32)
data = [[10., 20., 30.], [40., 50., 60.]]
data = torch.tensor(data) # 将列表转换为PyTorch张量
print(data)
>>> tensor([[10., 20., 30.],[40., 50., 60.]])
注释解释:
-
第一步:创建一个标量张量
tensor(10),其中torch.tensor(10)创建了一个值为10的张量。 -
第二步:使用 NumPy 生成一个2x3的随机数组
np.random.randn(2, 3),然后将其转换为 PyTorch 张量torch.tensor(data)。注意,由于 NumPy 的默认数据类型是 float64,所以转换后的张量也是dtype=torch.float64。 -
第三步:使用包含列表的数据创建张量
torch.tensor(data)。在这个例子中,列表中的数据都是浮点数,因此创建的张量的默认数据类型为float32。
总结:PyTorch 的 torch.tensor() 函数可以接受 Python 标量、Python 列表、NumPy 数组等作为输入,并将其转换为 PyTorch 的张量(Tensor)。在转换过程中,可以通过指定数据类型来控制张量的数据精度和类型。
torch.Tensor() 根据指定形状创建张量,也可以用来创建指定数据的张量
import torch# 1. 创建一个2行3列的张量,默认数据类型为 float32
data = torch.Tensor(2, 3)
print(data)
>>> tensor([[0.0000e+00, 3.6893e+19, 2.2018e+05],[4.6577e-10, 2.4158e-12, 1.1625e+33]])# 注意:torch.Tensor() 的使用有一些特点:# 2. 如果传递一个数值,则创建包含单个元素的张量
data = torch.Tensor([10])
print(data)
>>> tensor([10.])# 3. 如果传递一个列表,则根据列表中的元素创建张量
data = torch.Tensor([10, 20])
print(data)
>>> tensor([10., 20.])
注释解释:
-
第一步:使用
torch.Tensor(2, 3)创建一个2行3列的张量,默认数据类型为float32。这种方式会初始化张量的值,但具体数值取决于内存中的初始状态,所以结果是随机的。 -
第二步:如果在
torch.Tensor()中传递一个单独的数值(如torch.Tensor([10])),则会创建一个包含该数值的张量。在这个例子中,生成的张量是tensor([10.]),注意默认数据类型为float32。 -
第三步:如果传递一个列表(如
torch.Tensor([10, 20])),则根据列表中的元素创建张量。生成的张量是tensor([10., 20.]),其中列表中的每个元素都成为张量中的一个值。同样,默认数据类型为float32。
总结:torch.Tensor() 可以根据传递的参数不同来创建不同的张量。如果传递的是尺寸参数(如 torch.Tensor(2, 3)),则创建一个具有指定形状的张量,并且张量的值是未初始化的(随机值)。如果传递的是一个数值或者一个列表,将创建一个包含这些值的张量,并且默认数据类型为 float32。
torch.IntTensor()、torch.FloatTensor()、torch.DoubleTensor() 创建指定类型的张量
1. 创建2行3列, dtype 为 int32 的张量
data = torch.IntTensor(2, 3)
print(data)
tensor([[ 0, 1610612736, 1213662609],
[ 805308409, 156041223, 1]], dtype=torch.int32)
2. 注意: 如果传递的元素类型不正确, 则会进行类型转换
data = torch.IntTensor([2.5, 3.3])
print(data)
tensor([2, 3], dtype=torch.int32)
3. 其他的类型
data = torch.ShortTensor() # int16
data = torch.LongTensor() # int64
data = torch.FloatTensor() # float32
data = torch.DoubleTensor() # float64
● torch.arange 和 torch.linspace 创建线性张量
● torch.random.init_seed 和 torch.random.manual_seed 随机种子设置
● torch.randn 创建随机张量
●
import torch# 1. 使用 torch.arange(start, end, step) 在指定区间按照步长生成元素 [start, end)
data = torch.arange(0, 10, 2)
print(data)
>>> tensor([0, 2, 4, 6, 8])# 2. 使用 torch.linspace(start, end, steps) 在指定区间按照元素个数生成 [start, end]
data = torch.linspace(0, 11, 10)
print(data)
>>> tensor([ 0.0000, 1.2222, 2.4444, 3.6667, 4.8889, 6.1111, 7.3333, 8.5556,9.7778, 11.0000])
注释解释:
-
第一步:使用
torch.arange(0, 10, 2)函数,在区间[0, 10)中按照步长为 2 生成元素。生成的张量包含的元素为[0, 2, 4, 6, 8]。注意,结束位置 10 不包含在内,生成的数列从开始位置开始,每次增加步长,直到小于结束位置。 -
第二步:使用
torch.linspace(0, 11, 10)函数,在区间[0, 11]中按照指定的元素个数(10个元素)均匀生成数列。生成的张量为[0.0000, 1.2222, 2.4444, 3.6667, 4.8889, 6.1111, 7.3333, 8.5556, 9.7778, 11.0000]。这里的步长是根据起始值、结束值和元素个数自动计算得出的,确保生成的数列是均匀分布的。
总结:
torch.arange(start, end, step)函数用于在指定区间内按照指定步长生成元素。torch.linspace(start, end, steps)函数用于在指定区间内按照指定元素个数生成均匀分布的数列。
张量的元素类型转换:
● torch.random.initial_seed()查看随机种子
● torch.random.manual_seed() 设置随机数种子
● torch.randn() 创建随机张量
●
1. 创建随机张量
data = torch.randn(2, 3) # 创建2行3列张量
print(data)
tensor([[-0.5209, -0.2439, -1.1780],
[ 0.8133, 1.1442, 0.6790]])
2.查看随机数种子
print(‘随机数种子:’, torch.random.initial_seed())
随机数种子: 4508475192273306739
3.设置随机数种子
torch.random.manual_seed(100)
data = torch.randn(2, 3)
print(data)
print(‘随机数种子:’, torch.random.initial_seed())
tensor([[ 0.3607, -0.2859, -0.3938],
[ 0.2429, -1.3833, -2.3134]])
随机数种子: 100
张量的类型转换:
● torch.ones 和 torch.ones_like 创建全1张量
● torch.zeros 和 torch.zeros_like 创建全0张量
● torch.full 和 torch.full_like 创建全为指定值张量
import torch# 1. 使用 torch.zeros(shape) 创建指定形状全0张量
data = torch.zeros(2, 3)
print(data)
>>> tensor([[0., 0., 0.],[0., 0., 0.]])# 2. 使用 torch.zeros_like(tensor) 根据张量形状创建全0张量
data = torch.zeros_like(data)
print(data)
>>> tensor([[0., 0., 0.],[0., 0., 0.]])
注释解释:
-
第一步:使用
torch.zeros(2, 3)函数创建一个形状为 (2, 3) 的全0张量。生成的张量每个元素都是0,形状为二维的 2 行 3 列矩阵。 -
第二步:使用
torch.zeros_like(data)函数根据已有张量data的形状创建一个新的全0张量。这里data是之前创建的形状为 (2, 3) 的张量,因此torch.zeros_like(data)将生成一个与data相同形状的全0张量。
总结:
torch.zeros(shape)可以根据指定的形状创建全0张量。torch.zeros_like(tensor)可以根据给定的张量tensor的形状创建一个形状相同的全0张量。
import torch
1. 使用 torch.zeros(shape) 创建指定形状全0张量
data = torch.zeros(2, 3)
print(data)
tensor([[0., 0., 0.],
[0., 0., 0.]])
2. 使用 torch.zeros_like(tensor) 根据张量形状创建全0张量
data = torch.zeros_like(data)
print(data)
tensor([[0., 0., 0.],
[0., 0., 0.]])
注释解释:
● 第一步:使用 torch.zeros(2, 3) 函数创建一个形状为 (2, 3) 的全0张量。生成的张量每个元素都是0,形状为二维的 2 行 3 列矩阵。
● 第二步:使用 torch.zeros_like(data) 函数根据已有张量 data 的形状创建一个新的全0张量。这里 data 是之前创建的形状为 (2, 3) 的张量,因此 torch.zeros_like(data) 将生成一个与 data 相同形状的全0张量。
总结:
● torch.zeros(shape) 可以根据指定的形状创建全0张量。
● torch.zeros_like(tensor) 可以根据给定的张量 tensor 的形状创建一个形状相同的全0张量。
torch.zeros()、torch.zeros_like() 创建全0张量
1. 创建指定形状全1张量
data = torch.ones(2, 3)
print(data)
tensor([[1., 1., 1.],
[1., 1., 1.]])
2. 根据张量形状创建全1张量
data = torch.ones_like(data)
print(data)
tensor([[1., 1., 1.],
[1., 1., 1.]])
torch.full()、torch.full_like() 创建全为指定值张量
1. 创建指定形状指定值的张量
data = torch.full([2, 3], 10)
print(data)
tensor([[10, 10, 10],
[10, 10, 10]])
2. 根据张量形状创建指定值的张量
data = torch.full_like(data, 20)
print(data)
tensor([[20, 20, 20],
[20, 20, 20]])
张量元素类型转换
● data.type(torch.DoubleTensor)
● data.double()
data = torch.full([2, 3], 10)
print(data.dtype)
torch.int64
将 data 元素类型转换为 float64 类型
data = data.type(torch.DoubleTensor)
print(data.dtype)
torch.float64
转换为其他类型
data = data.type(torch.ShortTensor) # int16
data = data.type(torch.IntTensor) # int32
data = data.type(torch.LongTensor) # int64
data = data.type(torch.FloatTensor) # float32
data.double()
data = torch.full([2, 3], 10)
print(data.dtype)
torch.int64
将 data 元素类型转换为 float64 类型
data = data.double()
print(data.dtype)
torch.float64
转换为其他类型
data = data.short()
data = data.int()
data = data.long()
data = data.float()
上面转换总结:
创建张量的方式
● torch.tensor() 根据指定数据创建张量
● torch.Tensor() 根据形状创建张量, 其也可用来创建指定数据的张量
● torch.IntTensor()、torch.FloatTensor()、torch.DoubleTensor() 创建指定类型的张量
<2> 创建线性和随机张量
● torch.arrange() 和 torch.linspace() 创建线性张量
● torch.random.initial_seed() 和 torch.random.manual_seed() 随机种子设置
● torch.randn() 创建随机张量
<3> 创建01张量
● torch.ones() 和 torch.ones_like() 创建全1张量
● torch.zeros() 和 torch.zeros_like() 创建全0张量
● torch.full() 和 torch.full_like() 创建全为指定值张量
<4> 张量元素类型转换
● data.type(torch.DoubleTensor)
● data.double()
张量转换为NUMPY数组
● 使用 Tensor.numpy 函数可以将张量转换为 ndarray 数组,但是共享内存,可以使用 copy 函数避免共享。
1. 将张量转换为 numpy 数组
data_tensor = torch.tensor([2, 3, 4])
使用张量对象中的 numpy 函数进行转换
data_numpy = data_tensor.numpy()
print(type(data_tensor))
<class ‘torch.Tensor’>
print(type(data_numpy))
<class ‘numpy.ndarray’>
注意: data_tensor 和 data_numpy 共享内存
修改其中的一个,另外一个也会发生改变
data_tensor[0] = 100
data_numpy[0] = 100
print(data_tensor)
tensor([100, 3, 4])
print(data_numpy)
[100 3 4]
2. 对象拷贝避免共享内存
data_tensor = torch.tensor([2, 3, 4])
使用张量对象中的 numpy 函数进行转换,通过copy方法拷贝对象
data_numpy = data_tensor.numpy().copy()
print(type(data_tensor))
<class ‘torch.Tensor’>
print(type(data_numpy))
<class ‘numpy.ndarray’>
注意: data_tensor 和 data_numpy 此时不共享内存
修改其中的一个,另外一个不会发生改变
data_tensor[0] = 100
data_numpy[0] = 100
print(data_tensor)
tensor([2, 3, 4])
print(data_numpy)
[100 3 4]
NUMPY数组转换为张量
● 使用 from_numpy 可以将 ndarray 数组转换为 Tensor,默认共享内存,使用 copy 函数避免共享。
data_numpy = np.array([2, 3, 4])
将 numpy 数组转换为张量类型
1. from_numpy
2. torch.tensor(ndarray)
data_tensor = torch.from_numpy(data_numpy)
nunpy 和 tensor 共享内存
data_numpy[0] = 100
data_tensor[0] = 100
print(data_tensor)
tensor([100, 3, 4], dtype=torch.int32)
print(data_numpy)
[100 3 4]
● 使用 torch.tensor 可以将 ndarray 数组转换为 Tensor,默认不共享内存。
data_numpy = np.array([2, 3, 4])
data_tensor = torch.tensor(data_numpy)
nunpy 和 tensor 不共享内存
data_numpy[0] = 100
data_tensor[0] = 100
print(data_tensor)
tensor([100, 3, 4], dtype=torch.int32)
print(data_numpy)
[2 3 4]
标量张量和数字转换
● 对于只有一个元素的张量,使用item()函数将该值从张量中提取出来
当张量只包含一个元素时, 可以通过 item() 函数提取出该值
data = torch.tensor([30,])
print(data.item())
30
data = torch.tensor(30)
print(data.item())
30
总结
- 张量转换为 numpy 数组
● data_tensor.numpy()
● data_tensor.numpy().copy() - numpy 转换为张量
● torch.from_numpy(data_numpy)
● torch.tensor(data_numpy) - 标量张量和数字转换
● data.item()
张量的运算:
张量基本运算
● 加减乘除取负号:
● add、sub、mul、div、neg
● add_、sub_、mul_、div_、neg_(其中带下划线的版本会修改原数据)
data = torch.randint(0, 10, [2, 3])
print(data)
tensor([[3, 7, 4],
[0, 0, 6]])
1. 不修改原数据
new_data = data.add(10) # 等价 new_data = data + 10
print(new_data)
tensor([[13, 17, 14],
[10, 10, 16]])
2. 直接修改原数据 注意: 带下划线的函数为修改原数据本身
data.add_(10) # 等价 data += 10
print(data)
tensor([[13, 17, 14],
[10, 10, 16]])
3. 其他函数
print(data.sub(100))
tensor([[-87, -83, -86],
[-90, -90, -84]])
print(data.mul(100))
tensor([[1300, 1700, 1400],
[1000, 1000, 1600]])
print(data.div(100))
tensor([[0.1300, 0.1700, 0.1400],
[0.1000, 0.1000, 0.1600]])
print(data.neg())
tensor([[-13, -17, -14],
[-10, -10, -16]])
data1 = torch.tensor([[1, 2], [3, 4]])
data2 = torch.tensor([[5, 6], [7, 8]])
第一种方式
data = torch.mul(data1, data2)
print(data)
tensor([[ 5, 12],
[21, 32]])
第二种方式
data = data1 * data2
print(data)
tensor([[ 5, 12],
[21, 32]])
import torch# 定义两个张量
data1 = torch.tensor([[1, 2], [3, 4], [5, 6]])
data2 = torch.tensor([[5, 6], [7, 8]])# 方式一: 使用 @ 运算符进行点积运算
data3 = data1 @ data2
print("data3-->", data3)
>>> data3--> tensor([[19, 22],[43, 50],[67, 78]])# 方式二: 使用 torch.matmul() 函数进行点积运算
data4 = torch.matmul(data1, data2)
print("data4-->", data4)
>>> data4--> tensor([[19, 22],[43, 50],[67, 78]])
注释解释:
-
方式一:使用
@运算符进行张量的点积运算。在 PyTorch 中,@运算符与torch.matmul()函数等效,用于执行张量的矩阵乘法操作。 -
方式二:使用
torch.matmul(data1, data2)函数进行点积运算,同样可以得到与@运算符相同的结果。
总结:
- 在 PyTorch 中,可以使用
@运算符或torch.matmul()函数进行张量的矩阵乘法(点积)运算。 - 这两种方式都适用于执行矩阵乘法,计算结果相同。
点乘(Element-wise Multiplication):
● 点乘是指两个矩阵或向量中对应位置元素相乘的操作,
点积结果是两个向量对应元素相乘后的和
总结
<1> 张量基本运算函数
● add、sub、mul、div、neg等函数
● add_、sub_、mul_、div_、neg_等函数
<2> 张量的点乘运算
● mul 和运算符 *
<3> 点积运算
● 运算符@用于进行两个矩阵的点乘运算
● torch.matmul 对进行点乘运算的两矩阵形状没有限定,对数输入的 shape 不同的张量, 对应的最后几个维度必须符合矩阵运算规则
张量的函数计算:
import torch
data = torch.randint(0, 10, [2, 3], dtype=torch.float64)
print(data)
tensor([[4., 0., 7.],
[6., 3., 5.]], dtype=torch.float64)
1. 计算均值
注意: tensor 必须为 Float 或者 Double 类型
print(data.mean())
tensor(4.1667, dtype=torch.float64)
print(data.mean(dim=0)) # 按列计算均值
tensor([5.0000, 1.5000, 6.0000], dtype=torch.float64)
print(data.mean(dim=1)) # 按行计算均值
tensor([3.6667, 4.6667], dtype=torch.float64)
2. 计算总和
print(data.sum())
tensor(25., dtype=torch.float64)
print(data.sum(dim=0))
tensor([10., 3., 12.], dtype=torch.float64)
print(data.sum(dim=1))
tensor([11., 14.], dtype=torch.float64)
3. 计算平方
print(torch.pow(data,2))
tensor([[16., 0., 49.],
[36., 9., 25.]], dtype=torch.float64)
4. 计算平方根
print(data.sqrt())
tensor([[2.0000, 0.0000, 2.6458],
[2.4495, 1.7321, 2.2361]], dtype=torch.float64)
5. 指数计算, e^n 次方
print(data.exp())
tensor([[5.4598e+01, 1.0000e+00, 1.0966e+03],
[4.0343e+02, 2.0086e+01, 1.4841e+02]], dtype=torch.float64)
6. 对数计算
print(data.log()) # 以 e 为底
tensor([[1.3863, -inf, 1.9459],
[1.7918, 1.0986, 1.6094]], dtype=torch.float64)
print(data.log2())
tensor([[2.0000, -inf, 2.8074],
[2.5850, 1.5850, 2.3219]], dtype=torch.float64)
print(data.log10())
tensor([[0.6021, -inf, 0.8451],
[0.7782, 0.4771, 0.6990]], dtype=torch.float64)
张量的索引操作:
. 张量的索引操作
● 在操作张量时,经常要去获取某些元素进行处理或者修改操作,在这里需要了解torch中的索引操作。
import torch
随机生成数据
data = torch.randint(0, 10, [4, 5])
print(data)
tensor([[0, 7, 6, 5, 9],
[6, 8, 3, 1, 0],
[6, 3, 8, 7, 3],
[4, 9, 5, 3, 1]])
print(data[0])
tensor([0, 7, 6, 5, 9])
print(data[:, 0])
tensor([0, 6, 6, 4])
import torch# 创建一个示例张量
data = torch.tensor([[1, 7, 3],[4, 8, 2]])# 返回 (0, 1)、(1, 2) 两个位置的元素
print(data[[0, 1], [1, 2]])
>>> tensor([7, 2])# 返回 0、1 行的 1、2 列共4个元素
print(data[[[0], [1]], [1, 2]])
>>> tensor([[7, 2],[8, 2]])
注释解释:
-
第一个示例:
data[[0, 1], [1, 2]]使用两个索引列表来获取张量中指定位置的元素。具体来说,它返回的是索引为(0, 1)和(1, 2)的两个元素。在这里,data[0, 1]返回的是第一行第二列的元素7,data[1, 2]返回的是第二行第三列的元素2。 -
第二个示例:
data[[[0], [1]], [1, 2]]使用两个索引列表来获取多行多列的元素。其中,[[0], [1]]表示选择第 0 行和第 1 行,[1, 2]表示选择第 1 列和第 2 列。这个操作返回的是一个形状为 (2, 2) 的张量,其中包含了选择的行和列的元素:- 第一个
[0]行选择了第 0 行的第 1 列和第 2 列,即[7, 3]。 - 第二个
[1]行选择了第 1 行的第 1 列和第 2 列,即[8, 2]。
- 第一个
总结:
- 在 PyTorch 中,可以使用索引列表来同时选择张量中的多个元素或者多行多列的元素。
- 索引列表的长度和形状需要匹配张量的维度要求。
范围索引的使用
import torch# 创建一个示例张量
data = torch.tensor([[0, 7, 4, 1],[6, 8, 2, 5],[6, 3, 9, 4]])# 前3行的前2列数据
print(data[:3, :2])
>>> tensor([[0, 7],[6, 8],[6, 3]])# 第2行到最后的前2列数据
print(data[2:, :2])
>>> tensor([[6, 3],[4, 9]])
注释解释:
-
第一个示例:
data[:3, :2]选择了张量data的前三行和前两列的数据。具体操作为::3表示选择索引从 0 到 2 的行(前三行)。:2表示选择索引从 0 到 1 的列(前两列)。- 因此,返回的张量包含了
data的前三行和前两列的数据,即:tensor([[0, 7],[6, 8],[6, 3]])
-
第二个示例:
data[2:, :2]选择了张量data的从第二行开始到最后一行,并且选择了前两列的数据。具体操作为:2:表示选择从索引 2 开始到最后一行的数据。:2表示选择索引从 0 到 1 的列(前两列)。- 因此,返回的张量包含了
data的第二行到最后一行的数据,并且只选择了前两列,即:tensor([[6, 3],[4, 9]])
总结:
- 在 PyTorch 中,可以使用切片操作来选择张量中的部分数据。
- 切片操作的形式为
start:end:step,其中start表示起始索引(默认为 0),end表示结束索引(不包含在内,默认为末尾),step表示步长(默认为 1)。
布尔索引的使用:
import torch# 创建一个示例张量
data = torch.tensor([[0, 7, 6, 5, 9],[6, 3, 8, 7, 3],[6, 8, 2, 1, 5],[4, 9, 1, 2, 4]])# 第三列大于5的行数据
print(data[data[:, 2] > 5])
>>> tensor([[0, 7, 6, 5, 9],[6, 3, 8, 7, 3]])# 第二行大于5的列数据
print(data[:, data[1] > 5])
>>> tensor([[0, 7],[6, 8],[6, 3],[4, 9]])
注释解释:
-
第一个示例:
data[data[:, 2] > 5]选择了张量data中第三列元素大于 5 的行数据。具体操作为:data[:, 2]表示选择data的第三列(索引为 2)。data[:, 2] > 5返回一个布尔张量,指示哪些行的第三列元素大于 5。data[data[:, 2] > 5]使用布尔索引选择满足条件的行,即第三列元素大于 5 的行数据。返回的张量为:tensor([[0, 7, 6, 5, 9],[6, 3, 8, 7, 3]])
-
第二个示例:
data[:, data[1] > 5]选择了张量data中第二行元素大于 5 的列数据。具体操作为:data[1] > 5返回一个布尔张量,指示哪些列的第二行元素大于 5。data[:, data[1] > 5]使用布尔索引选择满足条件的列,即第二行元素大于 5 的列数据。返回的张量为:tensor([[0, 7],[6, 8],[6, 3],[4, 9]])
总结:
- 在 PyTorch 中,可以使用布尔索引来根据条件选择张量中的元素或者行列。
- 布尔索引的结果张量形状与原张量形状相同,但仅包含满足条件的部分数据。
多维索引的使用:
import torch# 创建一个形状为 [3, 4, 5] 的随机整数张量
data = torch.randint(0, 10, [3, 4, 5])
print(data)
>>> tensor([[[2, 4, 1, 2, 3],[5, 5, 1, 5, 0],[1, 4, 5, 3, 8],[7, 1, 1, 9, 9]],[[9, 7, 5, 3, 1],[8, 8, 6, 0, 1],[6, 9, 0, 2, 1],[9, 7, 0, 4, 0]],[[0, 7, 3, 5, 6],[2, 4, 6, 4, 3],[2, 0, 3, 7, 9],[9, 6, 4, 4, 4]]])# 获取0轴上的第一个数据(第一个子张量)
print(data[0, :, :])
>>> tensor([[2, 4, 1, 2, 3],[5, 5, 1, 5, 0],[1, 4, 5, 3, 8],[7, 1, 1, 9, 9]])# 获取1轴上的第一个数据(每个子张量的第一个行)
print(data[:, 0, :])
>>> tensor([[2, 4, 1, 2, 3],[9, 7, 5, 3, 1],[0, 7, 3, 5, 6]])# 获取2轴上的第一个数据(每个子张量的第一个列)
print(data[:, :, 0])
>>> tensor([[2, 5, 1, 7],[9, 8, 6, 9],[0, 2, 2, 9]])
注释解释:
data是一个形状为 [3, 4, 5] 的三维张量,包含了随机生成的整数数据。- 获取0轴上的第一个数据:
data[0, :, :]选择了在第0个轴(最外层维度)上的第一个子张量。这相当于选择了data中索引为 0 的子张量,其形状为 [4, 5]。 - 获取1轴上的第一个数据:
data[:, 0, :]选择了在第1个轴上每个子张量的第一个行。这相当于选择了data中每个子张量的索引为 0 的行,形状为 [3, 5]。 - 获取2轴上的第一个数据:
data[:, :, 0]选择了在第2个轴上每个子张量的第一个列。这相当于选择了data中每个子张量的索引为 0 的列,形状为 [3, 4]。
这些操作展示了如何通过索引在多维张量中选择特定的子集或者元素。
张量的形状操作:
这里是对每个函数的解释和带有注释的示例代码:
1. torch.reshape(input, shape)
- 功能:重塑张量
input为指定的shape,如果形状兼容的话。 - 示例代码:
import torch# 创建一个形状为 (3, 4) 的张量 data = torch.tensor([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])# 使用 reshape 将其重塑为 (4, 3) 的形状 reshaped_data = torch.reshape(data, (4, 3)) print(reshaped_data)
2. tensor.view(shape)
- 功能:返回一个不同形状的张量视图,但与原始张量共享相同的数据。
- 示例代码:
import torch# 创建一个形状为 (3, 4) 的张量 data = torch.tensor([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])# 使用 view 返回一个形状为 (4, 3) 的张量视图 viewed_data = data.view(4, 3) print(viewed_data)
3. tensor.contiguous()
- 功能:确保张量在内存中是整块的,有时在操作非连续的张量时需要调用此方法。
- 示例代码(需要在具体场景中使用,这里不展示具体示例)。
4. torch.stack(tensors, dim=0)
- 功能:沿着新的维度
dim连接多个张量序列,所有张量必须具有相同的大小。 - 示例代码:
import torch# 创建两个形状为 (3,) 的张量 tensor1 = torch.tensor([1, 2, 3]) tensor2 = torch.tensor([4, 5, 6])# 使用 stack 沿着新的维度 0 连接这两个张量 stacked_tensor = torch.stack([tensor1, tensor2], dim=0) print(stacked_tensor)
5. torch.squeeze(input)
- 功能:挤压张量
input中所有尺寸值为 1 的维度。 - 示例代码:
import torch# 创建一个形状为 (1, 3, 1, 2) 的张量 data = torch.tensor([[[[1, 2]], [[3, 4]], [[5, 6]]]])# 使用 squeeze 挤压张量中的尺寸值为 1 的维度 squeezed_data = torch.squeeze(data) print(squeezed_data.shape) # 输出为 (3, 2)
6. torch.unsqueeze(input, dim)
- 功能:在张量
input的dim维度处添加维度值为 1 的新维度。 - 示例代码:
import torch# 创建一个形状为 (3, 2) 的张量 data = torch.tensor([[1, 2], [3, 4], [5, 6]])# 在第 1 维度处添加一个维度 unsqueezed_data = torch.unsqueeze(data, dim=1) print(unsqueezed_data.shape) # 输出为 (3, 1, 2)
7. torch.transpose(input, dim0, dim1)
- 功能:交换张量
input的指定维度dim0和dim1。 - 示例代码:
import torch# 创建一个形状为 (3, 4) 的张量 data = torch.tensor([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])# 对张量进行转置,交换第 0 和第 1 维度 transposed_data = torch.transpose(data, 0, 1) print(transposed_data.shape) # 输出为 (4, 3)
8. torch.permute(input, dims)
- 功能:返回原始张量
input的视图,其尺寸被按照dims指定的顺序重新排列。 - 示例代码:
import torch# 创建一个形状为 (3, 4, 5) 的张量 data = torch.randn(3, 4, 5)# 使用 permute 对张量的维度进行重新排列 permuted_data = torch.permute(data, (2, 0, 1)) print(permuted_data.shape) # 输出为 (5, 3, 4)
这些函数提供了对张量进行重塑、维度操作和形状变换的多种功能,适用于各种深度学习任务中对数据结构的处理和准备。
堆叠解释:
在深度学习中,"堆叠(stack)"通常指的是沿着新的维度将多个张量连接起来,形成一个新的张量。这个新的维度被称为"堆叠维度(stack dimension)“或者"堆叠轴(stack axis)”。堆叠的意义在于可以将多个具有相同形状的张量按照特定方向进行组合,从而方便进行批处理、并行计算或者数据整合。
示例代码解释:
import torch# 创建一个形状为 (7,) 的张量
x = torch.tensor([5., 2., 3., 4., 5., 6., 7.])# 使用 torch.stack 将 x 堆叠四次,沿着新的维度(维度0)堆叠
x_stacked = torch.stack([x, x, x, x], dim=0)print(x_stacked)
解释:
- x 是一个形状为 (7,) 的张量,包含了7个元素。
- torch.stack([x, x, x, x], dim=0) 表示将张量 x 在维度0上进行堆叠,即在行的方向上重复堆叠4次。
- 结果 x_stacked 是一个形状为 (4, 7) 的张量,其中4表示堆叠的次数,7表示原始张量 x 的维度。
意义:
- 批处理(Batching):在深度学习中,通常需要对多个样本进行并行处理。堆叠可以将多个样本的输入数据组合成一个张量,从而一次性输入神经网络进行处理,提高计算效率。
- 并行计算(Parallel Computation):某些情况下,可以同时处理多个堆叠的张量,例如在GPU上并行计算。
- 数据整合(Data Integration):当需要将多个来源的数据按照一定规则整合成一个张量时,堆叠是一种常见的操作方式。
总之,堆叠是在深度学习中常用的数据处理手段,能够帮助提高计算效率和数据管理的便捷性。
总结
<1> reshape 函数可以在保证张量数据不变的前提下改变数据的维度
<2> squeeze 和 unsqueeze 函数可以用来增加或者减少维度
<3> transpose 函数可以实现交换张量形状的指定维度, permute 可以一次交换更多的维度
<4> view 函数也可以用于修改张量的形状, 但是它要求被转换的张量内存必须连续,所以一般配合 contiguous 函数使用
张量的拼接操作:
张量的拼接是现有维度,形状相同,然后拼接在一起
这段代码展示了如何使用PyTorch的torch.cat()函数沿不同维度拼接张量,并且输出了每次拼接后的张量形状。
-
按0维度拼接 (
dim=0):- 在0维度上拼接意味着沿着第一个轴(通常是批次轴)堆叠张量。
data1和data2都是形状为[1, 2, 3]的张量。- 在0维度上拼接后,新的张量
new_data的形状为[2, 2, 3],表示在批次维度上堆叠了两个张量。
-
按1维度拼接 (
dim=1):- 在1维度上拼接意味着沿着第二个轴堆叠张量。
data1和data2在1维度上拼接后,形状为[1, 4, 3],表示在每个批次中堆叠了四个张量。
-
按2维度拼接 (
dim=2):- 在2维度上拼接意味着沿着第三个轴堆叠张量。
data1和data2在2维度上拼接后,形状为[1, 2, 6],表示在每个批次的每行中堆叠了六个元素。
总结:
torch.cat()函数允许按指定的维度将多个张量连接起来。- 拼接后的张量形状取决于拼接的维度和张量的形状。
张量的堆叠是
堆叠用法:
import torch
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
stacked = torch.stack([x, x], dim=0) dim0 =行 dim1=列 列堆叠就是列复制 行堆叠就是增加批次
列堆叠将多个张量的相同列堆叠在一起。
行堆叠增加样本批次
相关文章:

文本张量入门
张量,英文为Tensor,是机器学习的基本构建模块,是以数字方式表示数据的形式。 张量的基本类型: 创建一个标量(0维张量),也就是一个单独的数字 scalar torch.tensor(7) scalar.ndim # 返回张量的维度 0 # …...

js文字如何轮播?
<div class"td-style"> <span class"td-text">内容1内容1内容1内容1内容1内容1</span> </div> css: <style> .td-style { width: 160px; height: 72px; overflow: hidden; white-…...

Linux 五种IO模型
注:还有一种信号驱动IO,使用较少暂不讨论; 一,区分阻塞、非阻塞和同步、异步 看了很多文章对这两组概念解释和对比,说的太复杂了,其实没必要,两句话就能说清楚。 首先,对于读数据rec…...
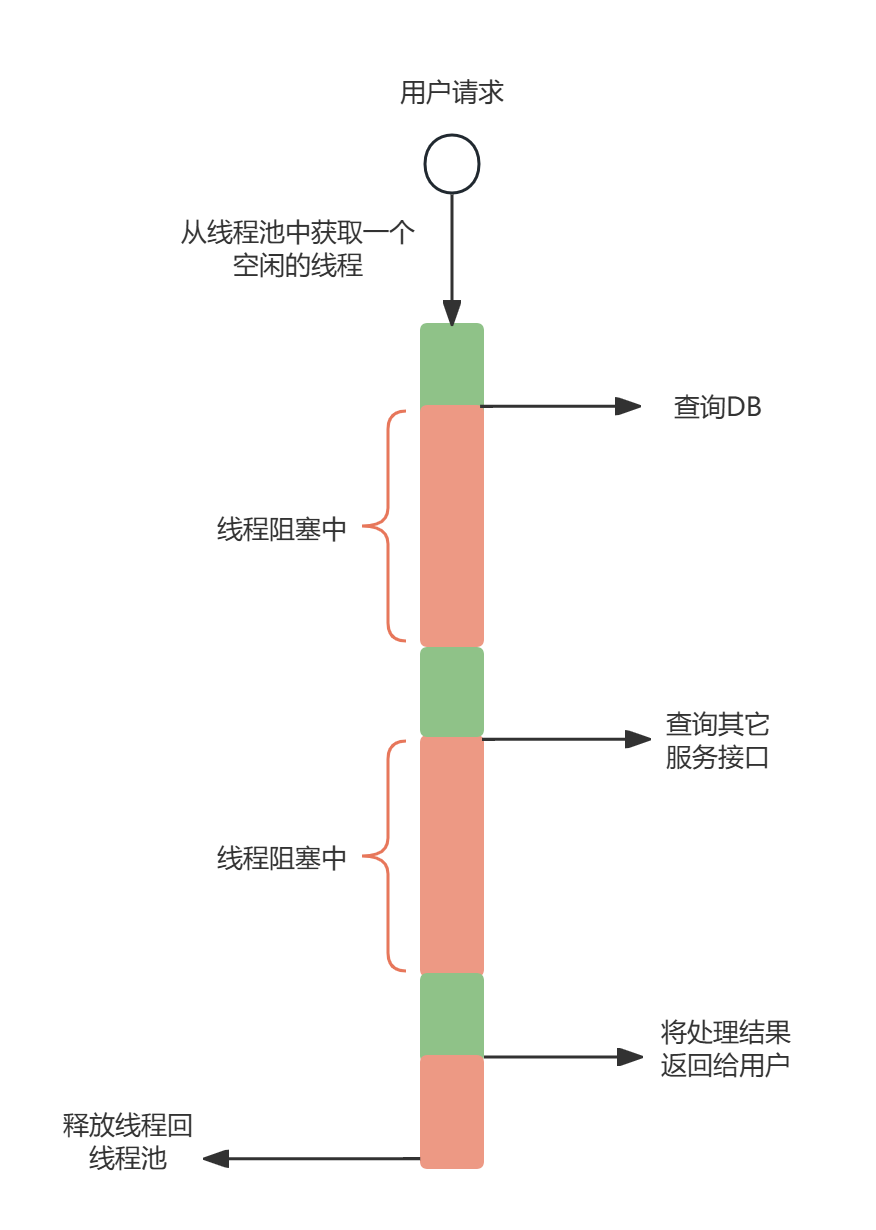
深度解析响应式异步编程模型
上一篇文章中我们聊了一下线程池,基于线程池的多线程编程是我们在高并发场景下提升系统处理效率的有效手段,但却不是唯一的。今天我们来看一下另一种异步开发的常用手段-响应式编程模型 传统多线程模型的缺陷 多线程模型是目前应用最为广泛的并发编程手段,但凡遇到什么性能…...

一个软件是如何开发出来的呢?
一、前言 如今,AI大爆发的时代,作为一名IT从业者,你是否也想尝试开发一套自己的系统,实现那些看似有可能实现的天马行空的想法,变成一个优秀甚至伟大的产品,甚至带来某个行业的革新,那作为一名…...

宝塔板面有哪些优势
哈喽呀,大家好呀,淼淼又来和大家见面啦,在当今数字化时代,随着云计算和互联网技术的飞速发展,服务器管理成为了许多企业和个人开发者不可或缺的一部分。然而,传统服务器管理方式的复杂性和技术门槛往往令初…...
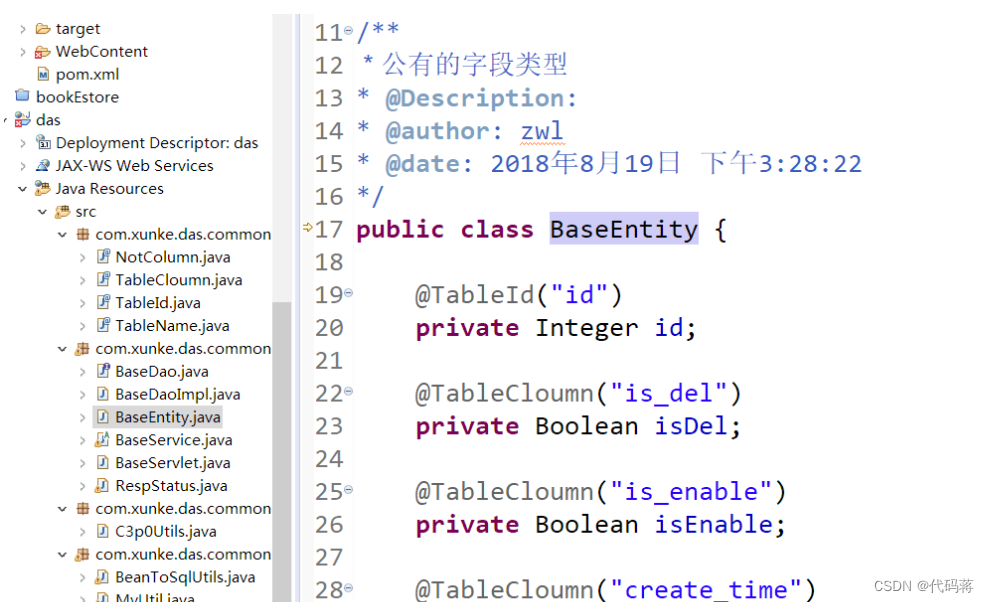
Mybatis中BaseEntity作用
新建各种对象的时候,一般来说,有几个属性是所有对象共有的,比如说id,is_del,is_enable这些,然后设置一个基础对象,以后新建所有对象的时候都继承它,就省的每次都要写这些共有的属性了...
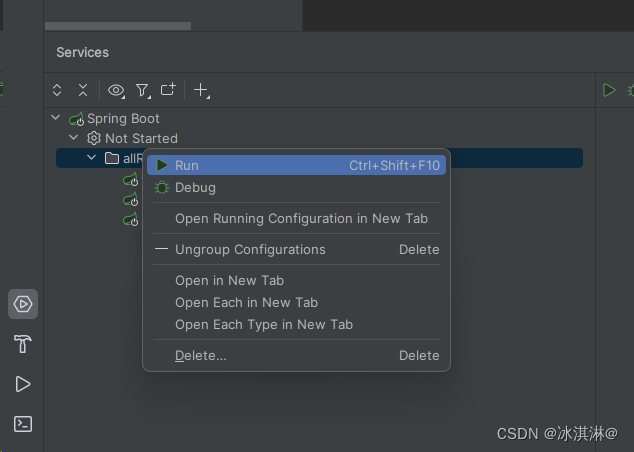
IDEA2023中使用run Dashboard面板?实现批量运行微服务
1、直接点击Add service--->Run Configuration Type---->Spring Boot 2、这样就出现了run Dashboard面板,可同时运行多个工程模块,shift选中所有启动类组命名(Group Configurations) 3、启动所有的项目...

分数受限,鱼和熊掌如何兼得?专业or学校,这样选最明智!
文章目录 引言一、专业解析二、名校效应分析三、好专业和好学校的权衡结论个人建议 引言 24年高考帷幕落下,一场新的思考与选择悄然来临。对于每一位高考考生,学校和专业都是开启大学新生活的两个前置必选项。但有时候“鱼与熊掌不可兼得”,…...

CentOS 8.5 - 配置ssh的免密登录
文章目录 生成ssh密钥公钥内容放入服务器 生成ssh密钥 在本地主机安装 ssh工具,并生成公钥、私钥。 # 命令行输入 ssh-keygen -r rsa# 会在当前用户的家目录下生成一个.ssh目录公钥内容放入服务器 将上一步生成的id_rsa.pub公钥的内容复制到远程服务器 # 编辑文…...
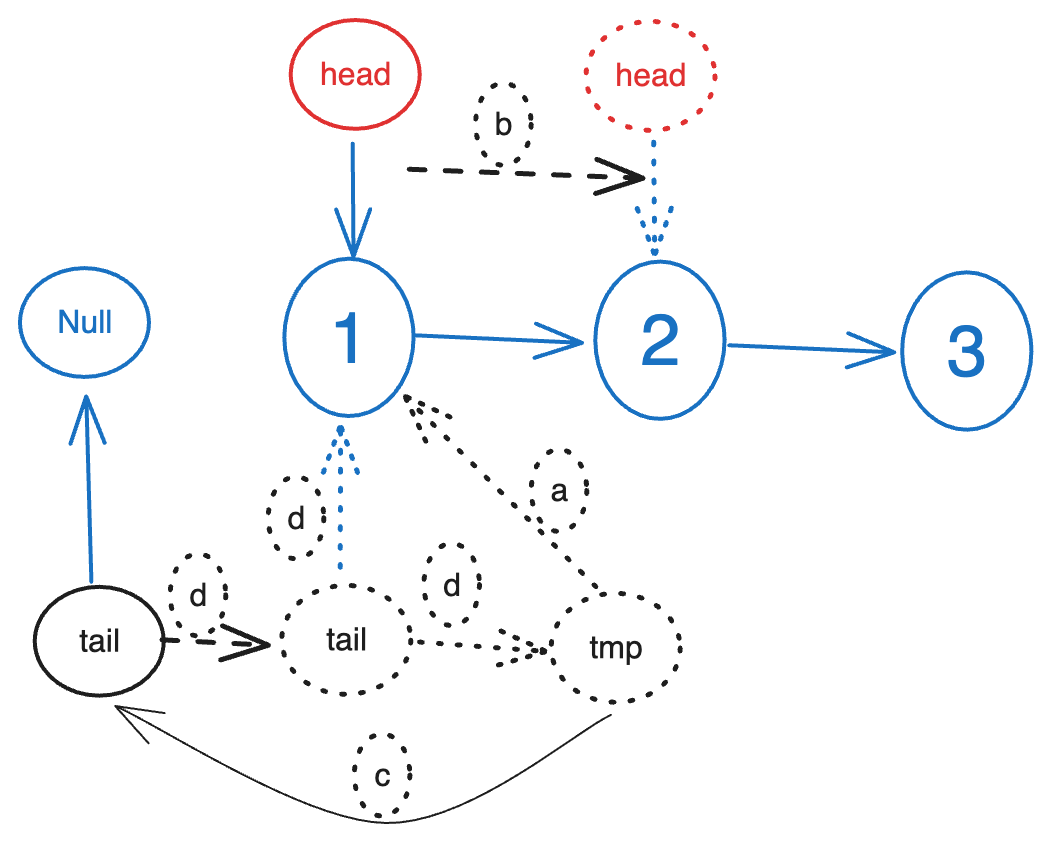
反转链表(java精简版)
反转一个单向链表。 public class ReversingLinkedList {static class Node {int val;Node next;public Node(int val) {this.val val;}public boolean hasNext() {return next ! null;}}public static void main(String[] args) {//构造Node head null;Node shift null;for…...

QPair使用详解
QPair使用详解 一、创建和初始化 QPair1.1 QPair默认构造1.2 使用值初始化1.3 QPair拷贝构造 二、访问 QPair 的值2.1 修改 QPair 的值2.2 比较 QPair2.3 使用 qMakePair 辅助函数2.4 使用 QPair 的场景 三、QPair自定结构体3.1 定义自定义结构体3.2 在 QPair 中使用自定义结构…...
C# 语言在AGI 赛道上能做什么
自从2022年11月OpenAI正式对外发布ChatGPT依赖,AGI 这条赛道上就挤满了重量级的选手,各大头部公司纷纷下场布局。原本就在机器学习、深度学习领域占据No.1的Python语言更是继续稳固了自己AI一哥的位置。凭借着Microsoft 和 OpenAI 长期以来一直是紧密相连…...

微信小程序-API 本地存储
一.本地存储-同步API 存储 : wx.setStorageSync 获取:wx.getStorageSync 删除:wx.removeStorageSync 清空:wx.clearStorageSync 代码: save(){//存储wx.setStorageSync(id, 1) wx.setStorageSync(obj, {name:"te…...

TensorFlow音频分类修复
原先传wav格式,后来发现前端生成的wav格式不完整 后端改mp3 其实是mp3和wav都可以接收 前端MP3和wav格式不正确,导致可以接收,但都无法计算时长 该文作废,可能导致音频分类不准确 修复TensorFlow放到生产后报错问题-CSDN博客 依赖 <dependency><groupId>or…...

C#学习系列之ListView垂直滚动
C#学习系列之ListView垂直滚动 前言垂直滚动总结 前言 当ListView中不断增加新内容,经常是纵向滚动。 垂直滚动 这个是关键:<VirtualizingStackPanel/> <ListView.ItemsPanel><ItemsPanelTemplate><VirtualizingStackPanel/>&…...

MySQL 常用函数总结
MySQL 提供了丰富的内置函数,用于在查询中进行各种计算、字符串处理、日期和时间操作等。这些函数可以帮助我们更有效地从数据库中检索和处理数据。下面将总结一些 MySQL 中常用的函数及其用法。 1. 数值函数 1.1 ROUND() ROUND() 函数用于对数值进行四舍五入操作…...
SpingBoot快速入门下
响应HttpServietResponse 介绍 将ResponseBody 加到Controller方法/类上 作用:将方法返回值直接响应,如果返回值是 实体对象/集合,将会自动转JSON格式响应 RestController Controller ResponseBody; 一般响应 统一响应 在实际开发中一般…...

什么是symbol?
在ES6(ECMAScript 2015)中,Symbol是一种新的基本数据类型,它的主要特点是独一无二且不可变。以下是关于ES6中Symbol的详细解释: 定义与特性: Symbol是ES6引入的一种基本数据类型,用于表示独一无…...

Tailwind CSS 响应式设计实战指南
title: Tailwind CSS 响应式设计实战指南 date: 2024/6/13 updated: 2024/6/13 author: cmdragon excerpt: 这篇文章介绍了如何运用Tailwind CSS框架创建响应式网页设计,涵盖博客、电商网站及企业官网的布局实例,包括头部导航、内容区域、侧边栏、页脚…...

gcoord与proj4js对比分析:选择最适合你的地理坐标库
gcoord与proj4js对比分析:选择最适合你的地理坐标库 【免费下载链接】gcoord 地理坐标系转换工具 项目地址: https://gitcode.com/gh_mirrors/gc/gcoord 在Web地图开发中,地理坐标系转换是一个常见需求。gcoord和proj4js都是优秀的JavaScript坐标…...
)
Python 3.15 JIT不是“可选优化”——而是CPython官方首次强制嵌入的LLVM后端(2024 Q3起新项目默认启用)
第一章:Python 3.15 JIT 的历史定位与架构革命Python 3.15 标志着 CPython 运行时的一次范式跃迁——它首次将生产就绪的、默认启用的即时编译(JIT)引擎深度集成至解释器核心,而非作为外部补丁或实验性分支存在。这一设计终结了自…...

MultiHighlight插件完全指南:5步提升代码阅读效率300%
MultiHighlight插件完全指南:5步提升代码阅读效率300% 【免费下载链接】MultiHighlight Jetbrains IDE plugin: highlight identifiers with custom colors 🎨💡 项目地址: https://gitcode.com/gh_mirrors/mu/MultiHighlight 在当今快…...

模型微调集成:OpenClaw调用Qwen3-32B的LoRA适配器实战
模型微调集成:OpenClaw调用Qwen3-32B的LoRA适配器实战 1. 为什么需要本地微调模型接入? 去年我在处理一批医疗文献自动化摘要任务时,发现通用大模型对专业术语的理解总差那么一口气。当模型把"冠状动脉搭桥术"解释成"心脏旁…...

电力电子顶刊投稿避坑指南:TIE与TPEL审稿流程、周期及常见误区全解析
电力电子顶刊投稿策略全解析:从TIE到TPEL的实战避坑指南 在电力电子与电机驱动领域,IEEE Transactions on Industrial Electronics (TIE)和IEEE Transactions on Power Electronics (TPEL)无疑是研究者梦寐以求的发表平台。这两本期刊不仅代表着行业内的…...

Ryujinx:高性能Nintendo Switch模拟器技术指南
Ryujinx:高性能Nintendo Switch模拟器技术指南 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx Ryujinx是一款采用C#开发的开源Nintendo Switch模拟器,它通过精确…...
+CAD+solidworks】)
棉花打包机的设计【说明书(论文)+CAD+solidworks】
棉花打包机作为农业机械化领域的关键设备,其核心作用在于将散状棉花高效压缩成标准化包型,以满足运输、仓储及后续加工的工艺需求。传统打包方式依赖人工或简单机械,存在效率低、包型不均、劳动强度大等问题,而现代棉花打包机通过…...

PdfiumAndroid完全指南:从集成到高级应用
PdfiumAndroid完全指南:从集成到高级应用 【免费下载链接】PdfiumAndroid 项目地址: https://gitcode.com/gh_mirrors/pd/PdfiumAndroid PdfiumAndroid是一款专为Android开发打造的PDF渲染库,基于Pdfium原生库提供API级别14及以上设备的PDF文件处…...
)
SpringBoot整合MQTT实战:手把手教你实现设备动态连接与主题订阅管理(附完整源码)
SpringBoot整合MQTT实战:动态连接与主题订阅管理的工程化实现 在物联网项目开发中,设备连接管理和消息路由的灵活性往往是系统设计的难点。想象这样一个场景:你的智慧农业系统需要随时接入新部署的土壤传感器,气象站设备可能因网…...

Phi-4-Reasoning-Vision行业落地:教育领域图像题解与隐藏线索识别案例
Phi-4-Reasoning-Vision行业落地:教育领域图像题解与隐藏线索识别案例 1. 项目背景与价值 在教育领域,图像题解和隐藏线索识别一直是教学和考试中的难点。传统方法依赖人工标注和分析,效率低下且容易遗漏关键信息。Phi-4-Reasoning-Vision多…...