智源联合多所高校推出首个多任务长视频评测基准MLVU
当前,研究社区亟需全面可靠的长视频理解评估基准,以解决现有视频理解评测基准在视频长度不足、类型和任务单一等方面的局限性。因此,智源联合北邮、北大和浙大等多所高校提出首个多任务长视频理解评测基准MLVU(A Comprehensive Benchmark for Multi-Task Long Video Understanding)。MLVU拥有充足且灵活可变的的视频长度、包含多种长视频来源、涵盖多个不同维度的长视频理解任务。通过对20个最新的流行多模态大模型(MLLM)评测发现,排名第一的GPT-4o的单选正确率不足65%,揭示了现有模型在长视频理解任务上仍然面临重大挑战。我们的实证研究还探讨了多个影响大模型长视频理解能力的关键因素,期待MLVU能够推动社区对长视频理解研究的发展。
论文标题:MLVU: A Comprehensive Benchmark for Multi-Task Long Video Understanding
论文链接:https://arxiv.org/abs/2406.04264
项目链接:https://github.com/FlagOpen/FlagEmbedding/tree/master/MLVU
背景介绍
使用MLLM进行长视频理解具有极大的研究和应用前景。然而,当前研究社区仍然缺乏全面和有效的长视频评测基准,它们主要存在以下问题:
1、视频时长不足:当前流行的 Video Benchmark[1,2,3] 主要针对短视频设计,大部分视频的长度都在1分钟以内。
2、视频种类和任务类型不足:现有评测基准往往专注在特定领域的视频(例如电影[4, 5],第一视角[6])和特定的视频评测任务(例如Captioning[2],Temporal Perception[7],Action Understanding[8])
3、缺乏合理的长视频理解任务设计:现有部分长视频理解评测任务往往只和局部帧有关[4];或者使用针对经典电影进行问答[9],MLLMs 可以直接凭借 text prompt 正确回答问题而不需对视频进行分析。
MLVU的构建过程
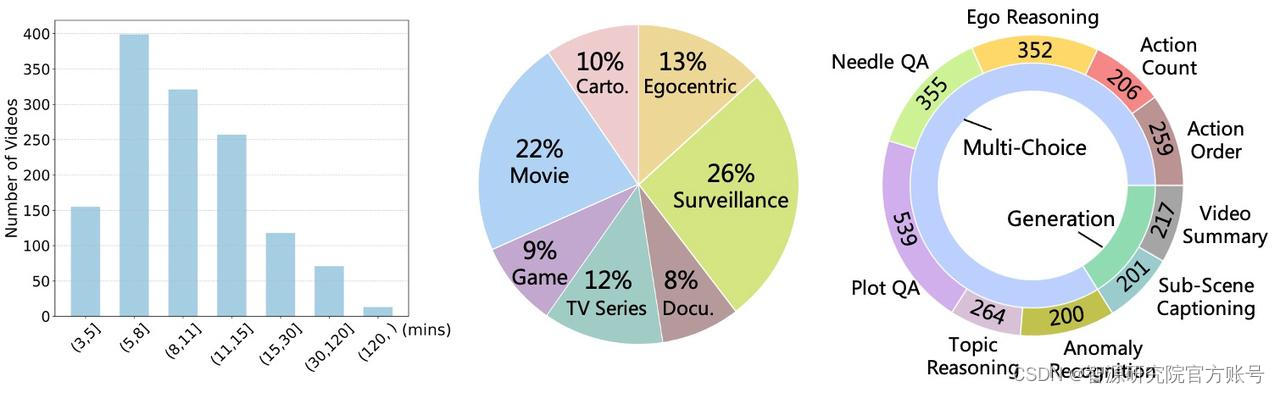
针对以上不足,我们提出了MLVU:首个全面的多任务长视频理解Benchmark。MLVU具有以下特点:
1、充足且灵活的视频时长
MLVU的视频时长覆盖了3分钟到超过2小时,平均视频时长12分钟,极大扩展了当前流行的Video Benchmark的时长范围。另外,MLVU的大部分任务标注过程中进行了片段-问题对应标注(例如,Video Summarization任务分段标注了视频的前3分钟,前6分钟...)。MLLMs可以灵活地在MLVU上选择测试不同时长情况下的长视频理解能力。
2、覆盖真实和虚拟环境的多种视频来源
MLVU收集了包括电影、电视剧、纪录片、卡通动画片、监控视频、第一视角视频和游戏视频等多个类型的长视频。覆盖了长视频理解的多个领域范围。
3、针对长视频理解设计的全面任务类别
我们针对长视频理解设计了9类不同的任务,并进一步将他们任务分为三类:全面理解,单细节理解、多细节理解。
·全面理解任务:要求MLLMs理解和利用视频的全局信息来解决问题;
·单细节理解任务:要求MLLMs根据问题定位长视频中的某一细节,并利用该细节来解决问题;
·多细节理解任务:要去MLLMs定位和理解长视频中的多个相关片段来完成和解决问题。
此外,我们还包括了单项选择题形式和开放生成式问题,全面考察MLLMs在不同场景下的长视频理解能力。
(文末提供了MLVU的9类任务示例图参考)
4、合理的问题设置与高质量答案标注
以情节问答(Plot Question Answering)任务为例。一部分Benchmark[9, 10]使用电影/电视的角色作为问题线索来对MLLMs进行提问,然而他们使用的视频多为经典电影/电视,MLLMs可以直接使用自有知识回答问题而不需要对输入视频进行理解。另一部分Benchmark[4]试图避免这个问题,但由于长视频的复杂性,仅仅利用代词和描述性语句来指代情节细节非常困难,他们的问题非常宽泛或者需要在问题中额外指定具体的时间片段而不是让MLLMs自己根据题目寻找对应细节。
MLVU通过精细的人工标注克服了这些问题,在所有的情节问答任务中,MLVU均使用“具有详细细节的代词”来指代情节中的人物、事件或背景,避免了问题泄露带来的潜在影响,MLLMs需要根据问题提供的线索识别和定位相关片段才能进一步解决问题。此外,MLVU的Plot QA问题具备丰富的多样性,增强了评测的合理性和可靠性。

详细分析MLLMs在MLVU上的表现
我们在MLVU上对20个流行的MLLM进行了评测,包括开源模型和闭源模型。评测结果如下:
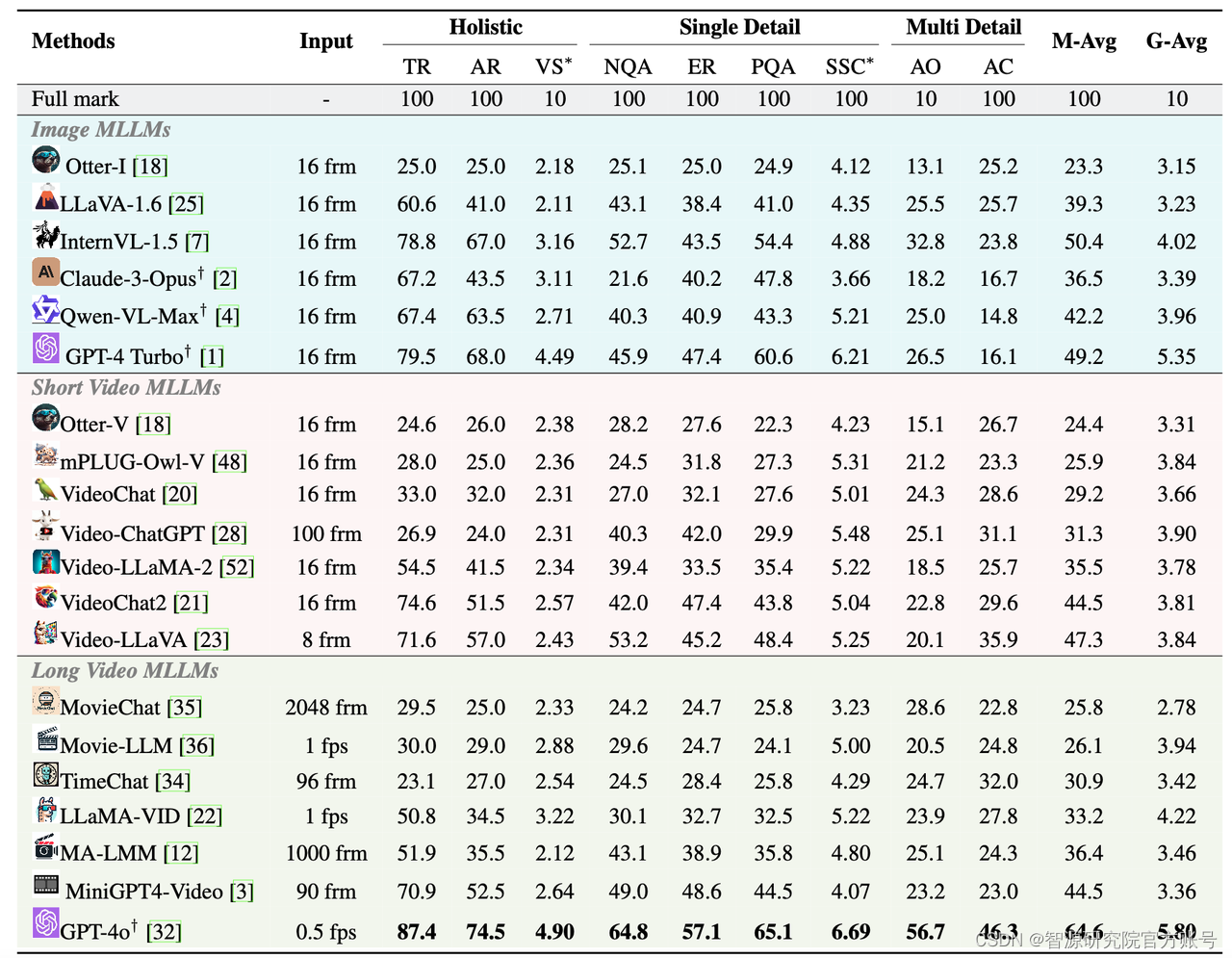
实验结果发现:
(1)长视频理解仍然是富有挑战的任务。尽管GPT-4o[11]在所有任务中均取得了第1名的成绩,然而,它的单选平均准确率只有64.6%。所有的模型都在需要细粒度理解能力的任务上(单细节、多细节理解任务)表现糟糕。此外,大部分模型的性能都会随着视频时长增加显著下降。
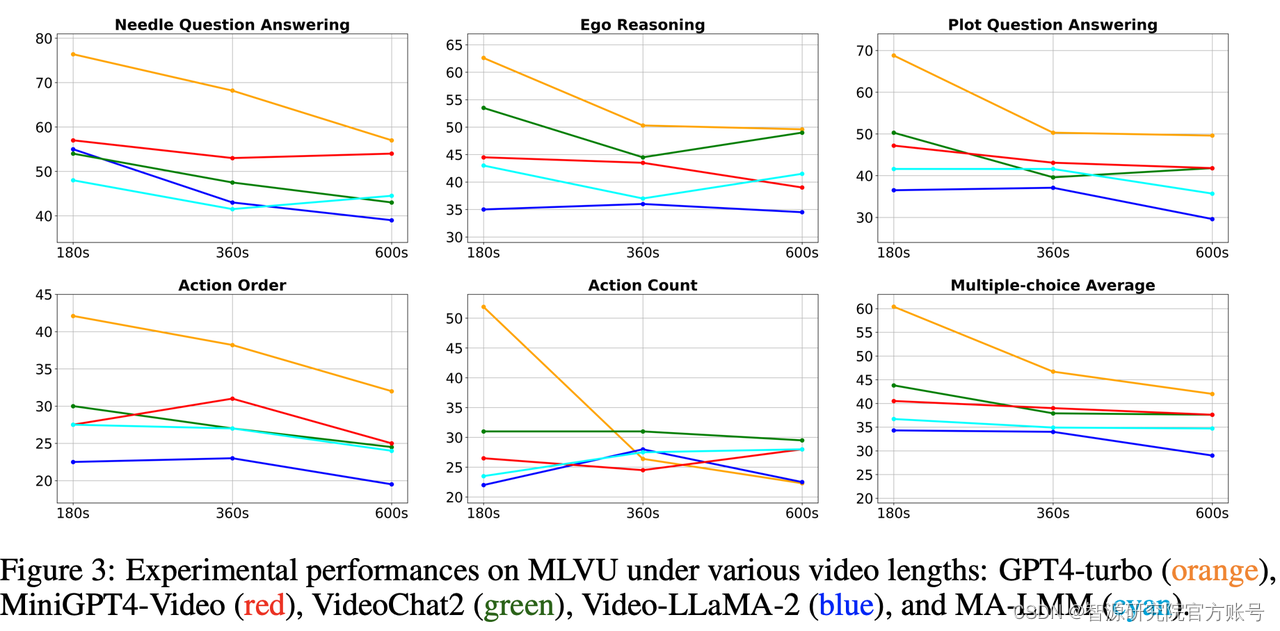
(2)开源模型和闭源模型之间存在较大的差距。开源模型中单项选择题性能最强的InternVL-1.5[12]单选平均准确度仅有50.4%;开放生成式题目最强的LLaMA-Vid得分仅有4.22,均远远落后于GPT-4o的64.6%和5.80。此外,现有长视频模型并没有在长视频理解任务上取得理想的成绩,说明当前的MLLMs在长视频理解任务上仍然存在较大的提升空间。
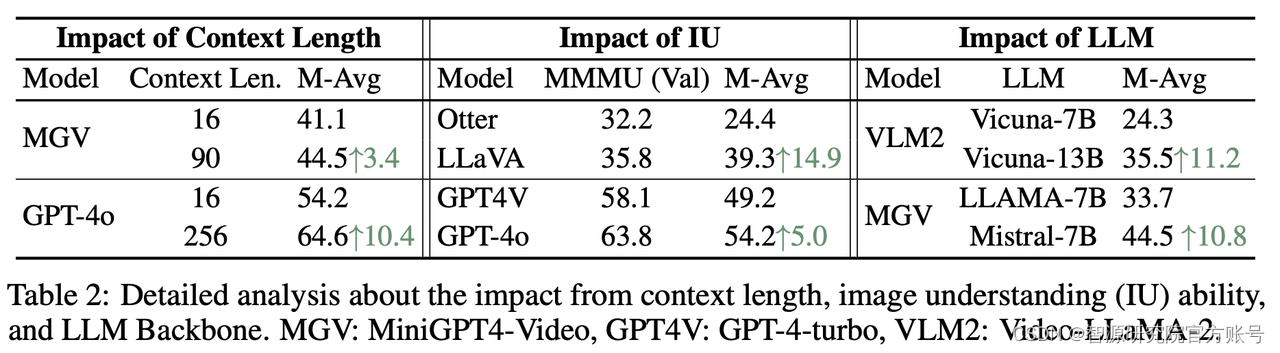
(3)上下文长度、图像理解能力、LLM Backbone 是MLLMs提升长视频理解能力的关键因素。实证研究发现,提升上下文窗口,提升MLLM的图像理解能力,以及使用更强大的LLM Backbone对长视频理解的性能具有显著的提升作用。这揭示了未来MLLMs在提升长视频理解能力的重要改进方向。
总结
我们提出MLVU,首个专为长视频理解任务设计的全面多任务评测基准。MLVU极大扩展了现有基准的视频长度、提供了丰富的视频类型,并针对长视频理解设计了多样化的评估任务,从而为MLLMs提供了一个可靠高质量的长视频理解评测平台。
通过评估当前流行的20个MLLMs,我们发现,长视频理解仍然是一个富有挑战和具有巨大提升空间的研究领域。通过实证研究,我们揭示了多个影响长视频理解能力的因素,为未来MLLMs的长视频理解能力构建提供了洞见。此外,我们将不断扩展和更新MLVU覆盖的视频类型和评估任务,期待MLVU能够促进社区对长视频理解研究的发展。
附录:MLVU的任务示例图

部分参考文献:
[1] Li K, Wang Y, He Y, et al. Mvbench: A comprehensive multi-modal video understanding benchmark[J]. arXiv preprint arXiv:2311.17005, 2023.
[2] Xu J, Mei T, Yao T, et al. Msr-vtt: A large video description dataset for bridging video and language[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 5288-5296.
[3] Li B, Wang R, Wang G, et al. Seed-bench: Benchmarking multimodal llms with generative comprehension[J]. arXiv preprint arXiv:2307.16125, 2023.
[4] Song E, Chai W, Wang G, et al. Moviechat: From dense token to sparse memory for long video understanding[J]. arXiv preprint arXiv:2307.16449, 2023.
[5] Wu C Y, Krahenbuhl P. Towards long-form video understanding[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 1884-1894.
[6] Mangalam K, Akshulakov R, Malik J. Egoschema: A diagnostic benchmark for very long-form video language understanding[J]. Advances in Neural Information Processing Systems, 2024, 36.
[7] Yu Z, Xu D, Yu J, et al. Activitynet-qa: A dataset for understanding complex web videos via question answering[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 9127-9134.
[8] Wang Z, Blume A, Li S, et al. Paxion: Patching action knowledge in video-language foundation models[J]. Advances in Neural Information Processing Systems, 2023, 36.
[9] Li Y, Wang C, Jia J. LLaMA-VID: An image is worth 2 tokens in large language models[J]. arXiv preprint arXiv:2311.17043, 2023.
[10] Lei J, Yu L, Bansal M, et al. Tvqa: Localized, compositional video question answering[J]. arXiv preprint arXiv:1809.01696, 2018.
[11] OpenAI. Gpt-4o. https://openai.com/index/hello-gpt-4o/, May 2024.
[12] Chen Z, Wang W, Tian H, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites[J]. arXiv preprint arXiv:2404.16821, 2024.
相关文章:
智源联合多所高校推出首个多任务长视频评测基准MLVU
当前,研究社区亟需全面可靠的长视频理解评估基准,以解决现有视频理解评测基准在视频长度不足、类型和任务单一等方面的局限性。因此,智源联合北邮、北大和浙大等多所高校提出首个多任务长视频理解评测基准MLVU(A Comprehensive Be…...

Linux系统:线程概念 线程控制
Linux系统:线程概念 & 线程控制 线程概念轻量级进程 LWP页表 线程控制POSIX 线程库 - ptherad线程创建pthread_createpthread_self 线程退出pthread_exitpthread_cancelpthread_joinpthread_detach 线程架构线程与地址空间线程与pthread动态库 线程的优缺点 线程…...
LearnOpenGL - Android OpenGL ES 3.0 绘制纹理
系列文章目录 LearnOpenGL 笔记 - 入门 01 OpenGLLearnOpenGL 笔记 - 入门 02 创建窗口LearnOpenGL 笔记 - 入门 03 你好,窗口LearnOpenGL 笔记 - 入门 04 你好,三角形OpenGL - 如何理解 VAO 与 VBO 之间的关系LearnOpenGL - Android OpenGL ES 3.0 绘制…...

山东济南最出名的起名大师颜廷利:二十一世纪哲学的领航者
山东济南最出名的起名大师颜廷利教授:二十一世纪哲学的领航者 在哲学的天空中,颜廷利教授犹如一颗璀璨的星辰,被无数求知者誉为21世纪最杰出的思想家之一。他的理论既深邃又广博,巧妙地将东方的儒家与道家哲学与西方的思辨传统交织…...

Nginx 负载均衡实现上游服务健康检查
Nginx 负载均衡实现上游服务健康检查 Author:Arsen Date:2024/06/20 目录 Nginx 负载均衡实现上游服务健康检查 前言一、Nginx 部署并新增模块二、健康检查配置2.1 准备 nodeJS 应用程序2.2 Nginx 配置负载均衡健康检查 小结 前言 如果你使用云负载均衡…...
小程序使用接口wx.getLocation配置
开通时需详细描述业务,否则可能审核不通过 可能需要绑定腾讯位置服务,新建应该,绑定到小程序 配置 权限声明:在使用wx.getLocation前,需要在app.json的permission字段中声明对用户位置信息的使用权限,并提…...
Protobuf安装配置--附带每一步截图
Protobuf Protobuf(Protocol Buffers)协议是一种由 Google 开发的二进制序列化格式和相关的技术,它用于高效地序列化和反序列化结构化数据,通常用于网络通信、数据存储等场景。 为什么要使用Protobuf Protobuf 在许多领域都得到…...

力扣1019.链表中的下一个更大节点
力扣1019.链表中的下一个更大节点 从左到右 每个数确定下一个更大节点后 弹出栈中存下标 即res.size() class Solution {public:vector<int> nextLargerNodes(ListNode* head) {vector<int> res;stack<int> st;for(auto ihead;i;ii->next){while(!st.e…...

查询mysql库表的几个语句
1、查询某个数据库的所有表 SELECTtable_name FROMinformation_schema.TABLES WHEREtable_schema database_namedatabase_name替换成你需要查询的数据库名称 2、查询某张表的所有字段名称 SELECTCOLUMN_NAME,column_comment FROMinformation_schema.COLUMNS WHEREtable…...

【CT】LeetCode手撕—103. 二叉树的锯齿形层序遍历
目录 题目1- 思路2- 实现⭐103. 二叉树的锯齿形层序遍历——题解思路 2- ACM实现 题目 原题连接:103. 二叉树的锯齿形层序遍历 1- 思路 二叉树的层序遍历,遇到奇数时,利用 Collections.reverse() 翻转即可 2- 实现 ⭐103. 二叉树的锯齿形层…...

1958springboot VUE宿舍管理系统开发mysql数据库web结构java编程计算机网页源码maven项目
一、源码特点 springboot VUE宿舍管理系统是一套完善的完整信息管理类型系统,结合springboot框架和VUE完成本系统,对理解JSP java编程开发语言有帮助系统采用springboot框架(MVC模式开发) ,系统具有完整的源代码和数…...

LVS DR模式
Linux Virtual Server(LVS)是一个由Linux内核支持的负载均衡解决方案,旨在通过集群技术来提高服务器的可扩展性、可靠性和高可用性。LVS通过将客户端的请求分发到多个服务器上,从而实现负载均衡和容错。 目录 LVS的工作模式 DR模…...

myslql事务示例
在 MySQL 中,事务(Transaction)是一组要么全部执行,要么全部不执行的SQL语句。这可以确保数据的一致性和完整性。事务管理的核心包括四个属性,即原子性(Atomicity)、一致性(Consiste…...

解决Flutter应用程序的兼容性问题
哈喽呀,大家好呀,淼淼又来和大家见面啦,Flutter作为一个跨平台的移动应用开发框架,极大地简化了开发者同时在Android和iOS平台上构建应用的难度。然而,由于不同设备、操作系统版本以及Flutter框架本身的变化࿰…...

整合微信支付一篇就够了
需要的工具 微信开发小程序工具 需要的材料 关键步骤 postman获取微信access_token https://api.weixin.qq.com/cgi-bin/token?appid=wxfssafa629021&grant_type=client_credential&secret=701d213dsfsdfsfdss4fb274生成h5跳转小程序的链接 https://api.weixin.…...

视创云展为企业虚拟展厅搭建,提供哪些功能?
在当下数字化浪潮中,如何为用户创造更富生动性和真实感的展示体验,已成为企业营销策略的核心。借助视创云展的线上虚拟3D企业展厅搭建服务,利用3D空间漫游和VR技术的融合,可以为用户呈现出一个既真实又充满想象力的全景图或三维模…...

c++ 常用的锁及用法介绍和示例
2024/6/21 14:20:10 在 C++ 中,常用的锁主要包括以下几种:std::mutex、std::recursive_mutex、std::timed_mutex 和 std::shared_mutex。这些锁可以帮助我们在多线程编程中保护共享数据,避免竞争条件。以下是每种锁的介绍及其用法示例: std::mutex std::mutex 是最基本的互…...

PostgreSQL源码分析——口令认证
认证机制 对于数据库系统来说,其作为服务端,接受来自客户端的请求。对此,必须有对客户端的认证机制,只有通过身份认证的客户端才可以访问数据库资源,防止非法用户连接数据库。PostgreSQL支持认证方法有很多࿱…...
)
Stability-AI(图片生成视频)
1.项目地址 GitHub - Stability-AI/generative-models: Generative Models by Stability AI 2.模型地址 魔搭社区 3.克隆项目后,按照教程安装 conda create --name Stability python3.10 conda activate Stability pip3 install -r requirements/pt2.txt py…...

Linux机器通过Docker-Compose安装Jenkins发送Allure报告
目录 一、安装Docker 二、安装Docker Compose 三、准备测试用例 四、配置docker-compose.yml 五、启动Jenkins 六、配置Jenkins和Allure插件 七、创建含pytest的Jenkins任务 八、项目结果通知 1.通过企业微信通知 2.通过邮件通知 九、配置域名DNS解析 最近小编接到一…...

AI伦理决策:从技术中立到可执行框架的工程实践
1. 项目概述:当代码开始“思考”对错最近和几个做AI产品落地的朋友聊天,话题总绕不开一个越来越现实的困境:我们开发的智能体,在帮用户做决策时,到底该不该、以及能不能有自己的“道德判断”?比如ÿ…...

第四章 数字孪生制作完整流程
4.1 项目需求分析、场景规划、页面布局设计数字孪生项目开发前期必须进行需求分析,明确项目用途、使用人群、展示内容以及功能模块,避免盲目开发造成资源浪费。需求分析是整个项目开发的逻辑起点,决定项目最终呈现效果。4.1.1 需求分析开发者…...

MMD创作者必看:除了跳舞,你还能用MikuMikuDance玩出哪些花样?
MMD创作者进阶指南:解锁MikuMikuDance的隐藏玩法 当你已经能熟练制作MMD舞蹈视频时,是否想过这款免费3D动画软件还能玩出更多花样?MikuMikuDance远不止是一个"虚拟歌姬跳舞模拟器",它其实是一个被严重低估的轻量级3D动画…...

ARMv8内存管理:TCR_EL1寄存器详解与实战配置
1. ARMv8内存管理基础与TCR_EL1概述在ARMv8架构中,内存管理单元(MMU)通过多级页表机制实现虚拟地址到物理地址的转换。TCR_EL1(Translation Control Register for EL1)作为关键控制系统寄存器,定义了EL1异常级别下的地址转换行为规范。这个64位寄存器包含…...

QMCDecode终极指南:如何快速解锁QQ音乐加密文件实现跨设备播放
QMCDecode终极指南:如何快速解锁QQ音乐加密文件实现跨设备播放 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录ÿ…...

5分钟上手Efficient-KAN:高效Kolmogorov-Arnold网络实战指南
5分钟上手Efficient-KAN:高效Kolmogorov-Arnold网络实战指南 【免费下载链接】efficient-kan An efficient pure-PyTorch implementation of Kolmogorov-Arnold Network (KAN). 项目地址: https://gitcode.com/GitHub_Trending/ef/efficient-kan 还在为传统神…...

C#循环入门指南:从0到1掌握循环逻辑
一、for循环:已知循环次数,首选它for循环是最常用、最规范的循环,适合已知循环次数的场景(比如打印10遍文字、计算1到100的和)。它的结构很固定,就像一个“固定流程的重复机器”,一步都不会乱。…...

从‘主仆’到‘边沿’:一个硬件工程师眼中的触发器进化史,以及为什么主从结构今天依然值得学
从机械钟摆到量子比特:触发器技术演进中的工程智慧 在数字电路的世界里,触发器如同精密的时间齿轮,默默协调着信息流动的节奏。当我们回溯这段技术发展史,会发现每一次触发器结构的革新都不是偶然的灵感闪现,而是工程…...

深入Acid引擎架构:模块化设计与现代C++17的最佳实践指南
深入Acid引擎架构:模块化设计与现代C17的最佳实践指南 【免费下载链接】Acid A high speed C17 Vulkan game engine 项目地址: https://gitcode.com/gh_mirrors/ac/Acid Acid引擎是一个基于Vulkan API的高性能C17游戏引擎,采用先进的模块化架构设…...

从苹果三星2016年困境看消费电子行业创新与供应链管理
1. 行业巨头的十字路口:苹果与三星的2016年镜像2016年,对于全球消费电子行业而言,是一个充满微妙转折的年份。站在聚光灯下的两大巨头——苹果与三星,仿佛站在了同一面镜子的两侧,映照出截然不同的困境,却又…...