大数据学习-Hadoop
介绍
是 Apache 的顶级开源项目,一个分布式框架,主要功能:
- 分布式大数据存储——HDFS 组件
- 分布式大数据计算——MapReduce 组件
- 分布式资源调度——YARN 组件
学习起来相对简单,市场占有率高,为后续的其他大数据软件学习打下基础
HDFS
Hadoop Distributed File System,Hadoop 分布式文件系统,是一个用来存储数据的组件
为什么需要分布式来存储
单台服务器无法存储太大的数据,那就把文件分成多个部分,用多台服务器存储多个部分
多台服务器还可以实现性能横向扩展,比如带宽、磁盘 IO 、CPU 运算速度等
如何管理多个服务器
在大数据中大部分都是主从模式,这个 Hadoop 就是主从模式
基础架构
主角色:NameNode(是一个独立的进程,负责管理整个 HDFS 和 DataNode;领导)
从角色:DataNode (是一个独立的进程,主要负责存取数据;员工)
主角色辅助角色:SecondaryNameNode (是一个独立的进程,协助主角色合并元数据,这就是它唯一的作用;老板秘书)
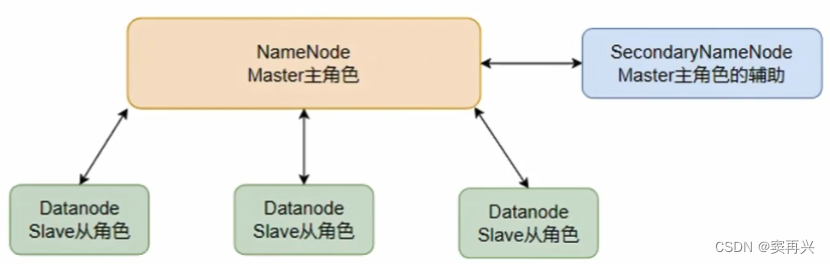
- NameNode 负责整个集群的管理,元数据的记录和权限的审核
- DataNode 负责集群中文件的存储
- SecondaryNameNode 负责合并元数据文件(edits & fsimage)
可以在 IDEA 中下载 Big Data Tools 插件,再进行一波配置就能连接上远程的 HDFS 了,可以用图形化界面进行文件的增删改查
VMware 集群部署配置
上传 & 解压
把 Hadoop 的压缩包上传到 /export/server 中,并解压
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server
cd /export/server
ln -s /export/server/hadoop-3.3.4 hadoop
修改配置文件


workers

hadoop-env.sh

core-site.xml

<configuration>
<property>
<name?>fs.defaultFS</name>
<value>hdfs:node1:8020</value>
</property>
<property>
<name?>io.file.buffer.size</name>
<value>131072</value>
</property>

hdfs-site.xml
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
创建数据保存的目录

把 node1 中的文件复制给另两个
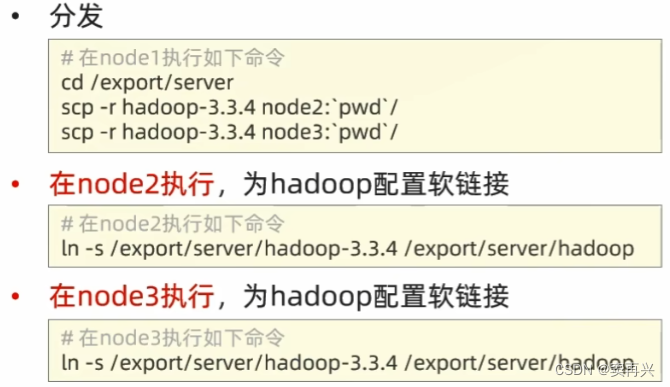
cd /export/server
scp -r hadoop-3.3.4 node2:/export/server
scp -r hadoop-3.3.4 node3:/export/server
软连接
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop
环境变量
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
为授权 hadoop 用户
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
格式化 HDFS
su hadoop
# 启动HDFS集群
start-dfs.sh
# 停止HDFS集群
成功标志

启动后,输入 jps,node1 有这些,node2/3 只有 DataNode
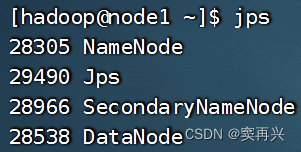
如果无法启动,说明配置文件或者权限有问题,去看日志+问AI基本都能解决
启动后,访问这个地址,可以看到 web 管理页面(Windows 的 hosts 文件有映射)
启动完毕后,关机,打快照,ssh 以后用 hadoop 用户登录
HDFS 操作
一键启动、停止
# 启动HDFS集群
start-dfs.sh
# 停止HDFS集群

单进程启停

文件系统操作命令
HDFS 的目录形式和 Linux 一样,命令名称和 Linux 几乎一样,在前面加上特定的关键字即可
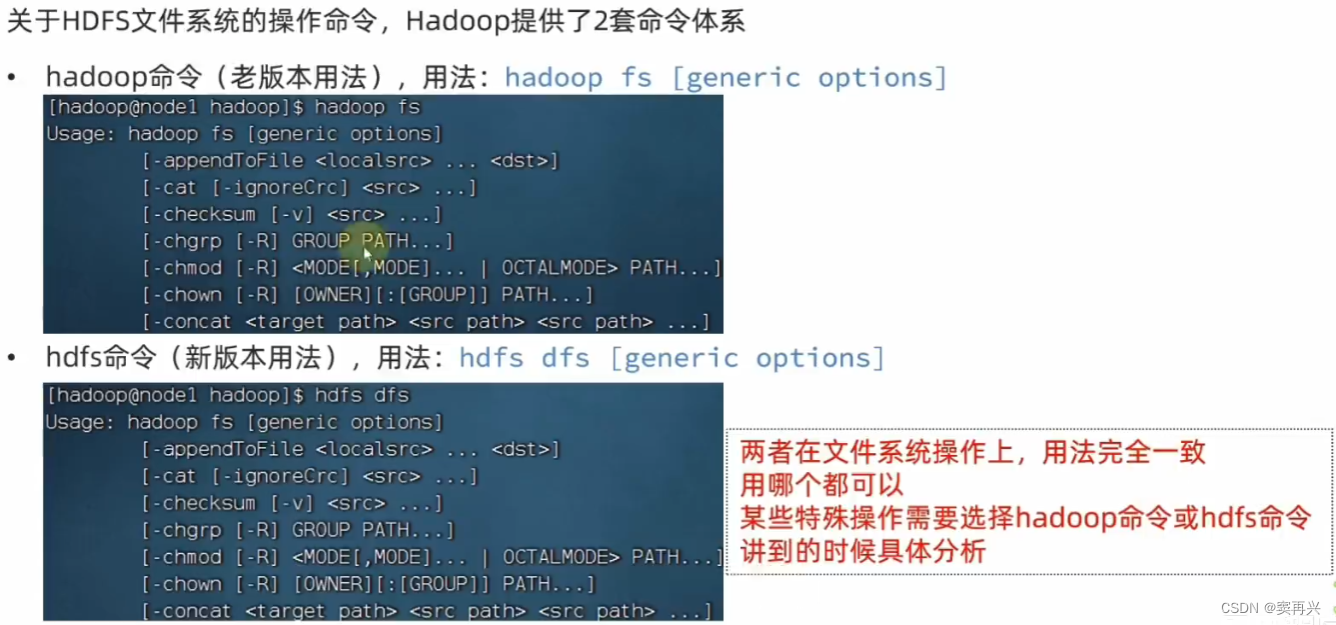
创建文件夹
hadoop 会自动识别创建的目录是 HDFS 还是 Linux 的目录的
查看目录中的内容

上传文件到 HDFS 指定目录

查看 HDFS 中文件内容

下载 HDFS 文件

复制 HDFS 文件

追加/删除 HDFS 文件内容

移动 HDFS 文件

删除 HDFS 文件

回收站功能

第一个的 1440,表示保留时长为一天(24 * 60 = 1440 min)
注意这个配置修改后会立即生效,在哪个机器进行配置,就在哪生效
web UI 操作 HDFS
切换到 root 用户,修改 core-site.xml 文件,然后重启集群
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
HDFS 权限

这个 supergroup 是启动 namenode 的用户(在本文中是 hadoop 用户)
谁启动谁就是超级用户,root 在 Linux 上超级用户,但是在 HDFS 中只是普通用户,无特权

HDFS 存储原理
block 块与备份
这是文件在 HDFS 中存储的统一单位,叫 block,一个 block 默认的大小是 256 MB(可以修改)
如果有个块出问题了怎么办?这样文件取出来后是损坏的(有点像 raid 0)
修改备份数

block 配置文件

临时设置备份数和 fsck 命令


元数据记录-NameNode
HDFS 中有很多的块和文件,hadoop 如何记录和整理文件和 block 之间的关系?通过 NameNode 写入的两个文件
edits 文件
是一个流水账文件,记录了 HDFS 中的每一次操作,还有本次操作影响的文件和对应的 block

还有就是因为记录的是流水账,如果前面记录了新增文件,后面又删除了,所以查找文件时,需要从头到尾遍历所有的 edits 文件,这样效率就很低
解决方法:只要最后的结果,叫做 edits 文件的合并(那这种方法和 AOF 文件一样),这样的体积就会小很多
fsimage 文件
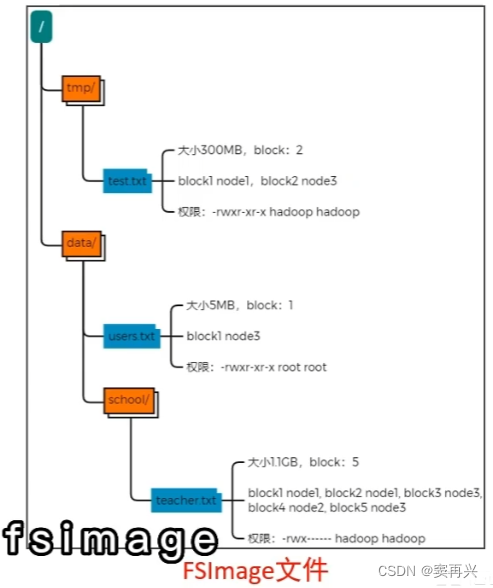
如果之前已经存在了 fsimage 文件,会将全部的 edits 文件和已经存在的 fsimage 文件进行合并,形成新的 fsimage 文件
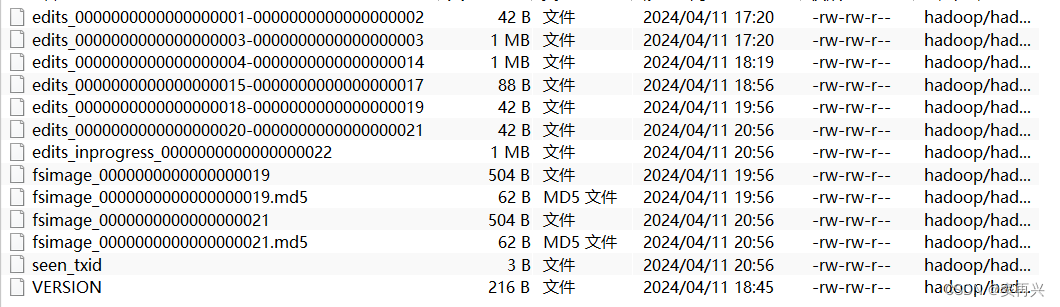
合并时间设置

谁来进行合并
在 HDFS 架构中,NameNode 有个辅助角色:SecondaryNameNode
它就是进行数据合并的,这也是它唯一的作用,不启动它的话,文件搜索的速度会越来越慢
它通过 HTTP 获取 edits 和 fsimage,合并完成后再提供给 NameNode
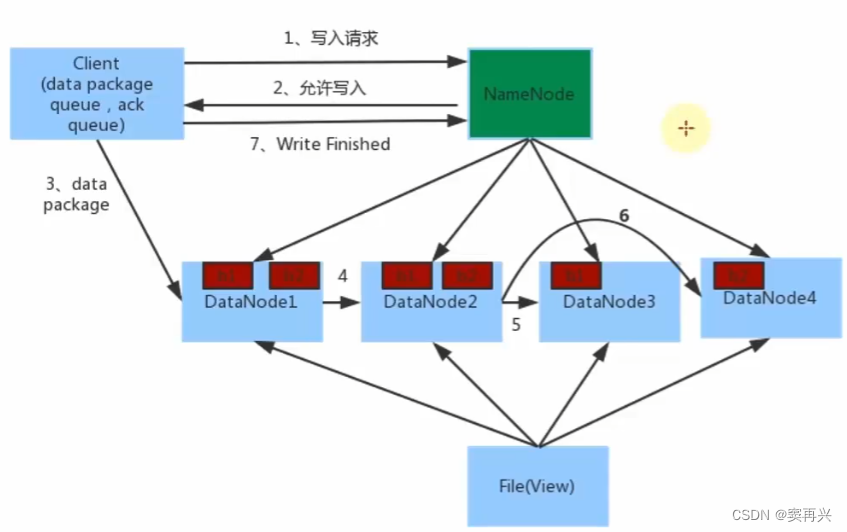
HDFS 写入数据流程
- 客户端向 NameNode 发送写入请求
- NameNode 检查客户端是否具有写入权限,HDFS 剩余空间是否充足;如果都 OK,那么会返回允许写入的消息,和要写入的地址(某个 DataNode 的 IP)
- 客户端向指定的 DataNode 发送数据包(写入数据)
- 被写入数据的 DataNode,会完成数据备份的操作,并将这些数据发送给其他的 DataNode
- 客户端通知 NameNode 写入完毕;NameNode 向 edits 和 fsimage 文件中写入数据
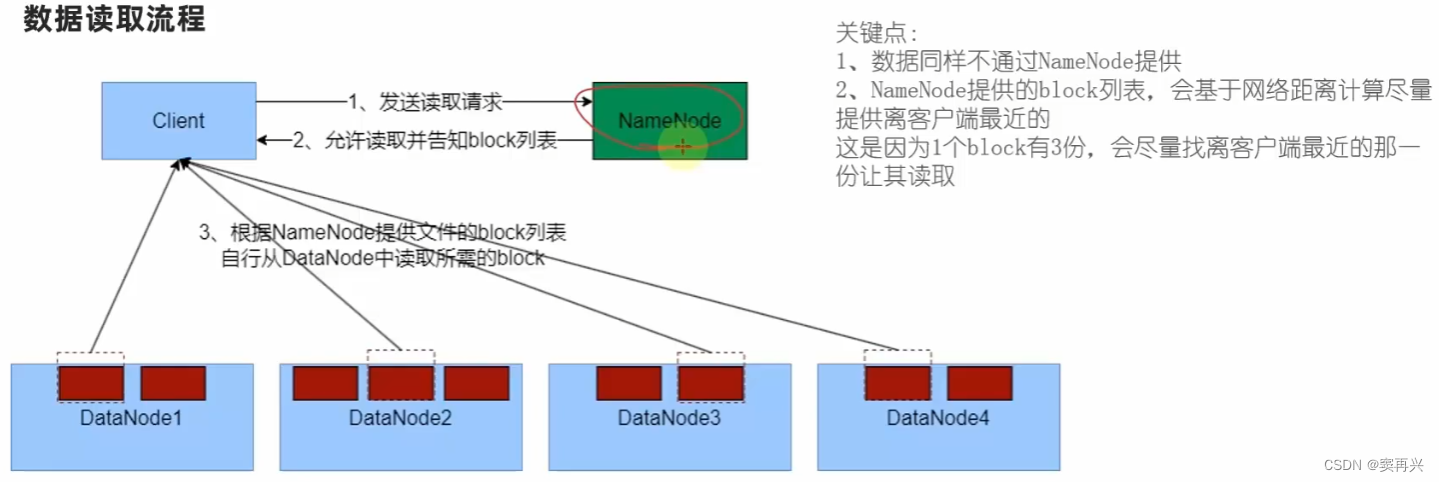
HDFS 读取文件流程
- 客户端发送读取请求给 NameNode
- NameNode 允许读取,并返回该文件的 block 列表
- 客户端根据列表,去 DataNode 中读取文件
MapReduce
分布式计算
多台计算机一起来计算,就是分布式计算;那这就会涉及多台计算机的管理问题
- 对于很大的数据,每台计算机得到一部分来进行计算
- 算完后,将各自的结果汇总到一台计算机中
- 最后由这台计算机计算出最终的结果
- 让一个节点作为总指挥,将任务分成若干个步骤
- 总指挥将任务下发给多个计算机,它们执行计算
不同点:在执行完某些步骤后,不同计算机之间会进行结论的交换后,才能继续进行计算
MapReduce 使用的是 分散-汇总模式,而更牛的框架(spark、flink 使用中心调度-步骤执行模式)
介绍
它是 Hadoop 的一个组件,用来进行分布式计算的一个框架;计算的模式:分散-汇总模式
- Map,提供“分散”功能,由多个服务器分布式地对数据进行处理
- Reduce,提供“汇总”功能,将分布式计算的结果进行汇总
但是现在基本都是使用 Hive 框架,它的底层是 MapReduce,所以这里只是简单介绍
简单分析执行原理
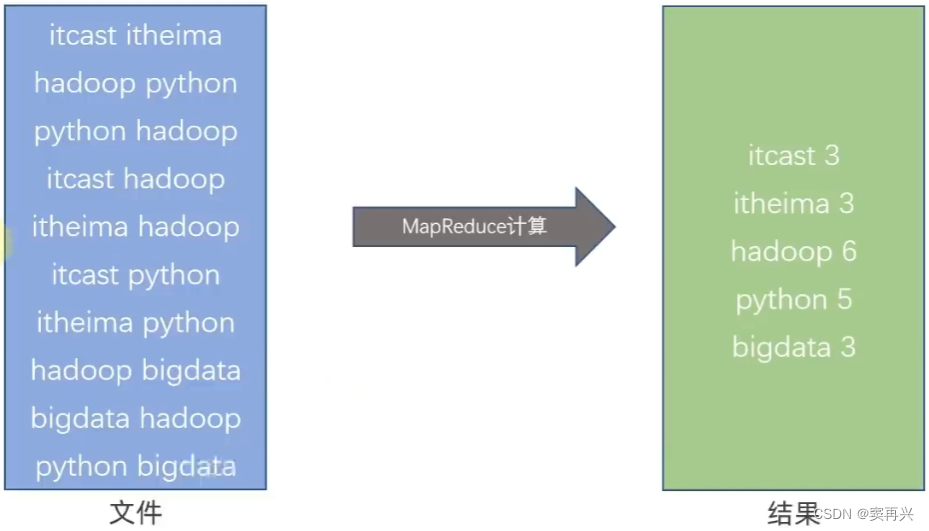
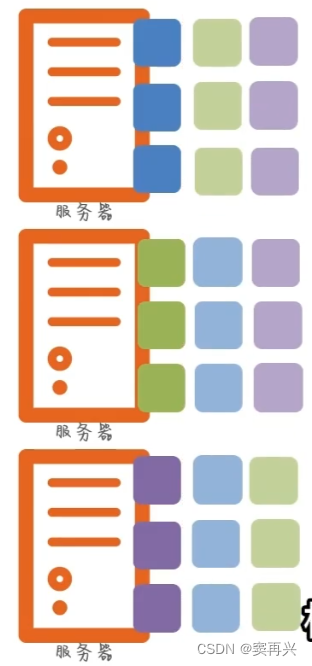
现在有三台服务器,两台执行 Map 的任务,一台执行 Reduce 的任务
会将文件分为多个部分,每台机器统计该部分的单词数量,最后将结果交给汇总的服务器
Yarn
对于多台服务器,需要有规划、统一地去调度各种硬件资源,提高资源利用率
MapReduce 是基于 Yarn 运行的,这样可以得到更好的资源利用率
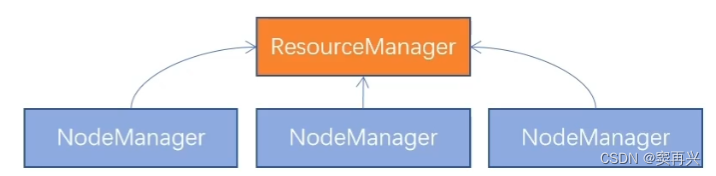
核心架构
- 主角色:ResourceManger,负责集群的资源调度,协调调度各个程序所需的资源(老板)
- 从角色:NodeManager,负责单台服务器的资源调度(各部门经理)
一个程序过来申请资源,就先去找 ResourceManager 要资源,老大再去通知小弟
容器
NodeManager 预先占用一部分资源,再将这部分资源提供给程序使用;程序使用的资源上限就是容器占用资源的大小,不能突破
程序需要 4GB 内存,那 NodeManager 就先占用 4GB 内存,然后将这些内存给程序使用
辅助架构
代理服务器-ProxyServer
在 Yarn 运行时,也会有一个 Web UI,如果在公网上就可能遭受攻击
历史服务器-JobHistoryServer
记录历史运行的程序信息、产生的日志、提供WEB UI站点供用户使用浏览器查看。
有它的原因是 Yarn 是用容器来分配资源的,如果要查看某个容器的日志,是比较麻烦的
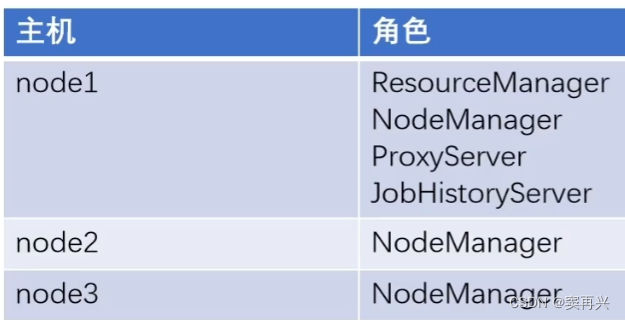
Yarn 集群部署
ProxyServer、JobHistoryServer 进程作为辅助节点
而 MapReduce 是运行在 Yarn 容器中的,所以无需独立启动进程,它也没有独立的进程,改改配置文件即可
MapReduce 配置文件
切换为 root 用户,来到 /export/server/hadoop-3.3.4/etc/hadoop 目录
# 设置 JDK 路径
export JAVA_HOME=/export/server/jdk
# 设置 JobHistoryServer 进程内存为 1G
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
# 设置日志级别为 INFO
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>MapReduce 的运行框架设置为 YARN</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
<description>历史服务器地址:node1:10020</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
<description>历史服务器web端口为node1的19888</description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
<description>历史信息在HDFS的记录临时路径</description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
<description>历史信息在HDFS的记录路径</description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME 设置为 HADOOP_HOME</description>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME 设置为 HADOOP_HOME</description>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>MapReduce HOME 设置为 HADOOP_HOME</description>
</property>
YARN 配置文件
切换为 root 用户,来到 /export/server/hadoop-3.3.4/etc/hadoop 目录
# JDK 环境变量
export JAVA_HOME=/export/server/jdk
# HADOOP_HOME
export HADOOP_HOME=/export/server/hadoop
# 配置文件路径的环境变量
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
# export YARN_LOG_DIR=$HADOOP_HOME/logs/yarn
# 日志文件的环境变量
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
<configuration>
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
<description>历史服务器URL</description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>node1:8089</value>
<description>proxy server hostname and port</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>开启日志聚合,可以在浏览器中看到整理好的日志</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>程序日志HDFS的存储路径</description>
</property>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
<description>ResourceManager设置在node1节点</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>选择公平调度器</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
<description>NodeManager数据的本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
<description>NodeManager数据日志本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
<description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>为MapReduce程序开启shuffle服务</description>
</property>
把配置文件发送给其他服务器
cd /export/server/hadoop/etc/hadoop
scp * node2:/export/server/hadoop-3.3.4/etc/hadoop/
scp * node3:/export/server/hadoop-3.3.4/etc/hadoop/
一键启动停止
start-yarn.sh
启动历史服务器
mapred --daemon start historyserver
单独控制进程
$HADOOP_HOME/bin/yarn,此程序也可以用以单独控制所在机器的进程启停
yarn --daemon (start|stop) (resourcemanager|nodemanager|proxyserver)
查看结果 & 打快照
访问 http://node1:8088/,如果能看到页面,说明一切 OK
提交 MapReduce 的任务到 Yarn 中执行
相关文章:
大数据学习-Hadoop
介绍 是 Apache 的顶级开源项目,一个分布式框架,主要功能: 分布式大数据存储——HDFS 组件分布式大数据计算——MapReduce 组件分布式资源调度——YARN 组件 可以通过它来构建集群,完成大数据的存储和计算 学习起来相对简单&…...

visualbox搭建linux环境双网卡配置
文章目录 1. 双网卡模式简介2. 网络模式配置2.1 virtualBox说明2.2 host-only网络模式配置2.3 NAT网络模式配置 3. 虚拟主机网络设置3.1 网卡一设置3.2 网卡二设置 4. 网卡配置5. ssh访问 本篇的目的是为了搭建本地的linux测试环境用。 1. 双网卡模式简介 双网卡网络模式简介 …...

一分钟了解Galaxybase银河图数据库先锋版升级功能!
Galaxybase 银河图数据库是一款创邻科技自主研发的商用图数据库,具有高性能、高可用、企业级安全等特性,支持大规模数据查询实时返回,快速挖掘关联关系,发现深层商业洞见,可广泛应用于金融、能源、电信、政企等行业中的…...

C++并发之协程实例(二)(计算斐波那契序列)
目录 1 协程2 实例-计算斐波那契序列2.1 斐波那契序列2.2 代码 3 运行 1 协程 协程(Coroutines)是一个可以挂起执行以便稍后恢复的函数。协程是无堆栈的:它们通过返回到调用方来暂停执行,并且恢复执行所需的数据与堆栈分开存储。这允许异步执行的顺序代码…...

云邮件推送服务如何配置?有哪些优势特点?
云邮件推送的性能怎么优化?如何选择邮件推送服务? 云邮件推送服务是一种基于云计算的邮件发送解决方案,能够帮助企业和个人高效地发送大规模邮件。AokSend将详细介绍如何配置云邮件推送服务,以便你能够充分利用其优势。 云邮件推…...
)
QT 数值型坐标轴有那些?(QValueAxis)
在Qt中,QValueAxis类用于表示数值型坐标轴,它本身没有直接的子类,但它是从QAbstractAxis这个抽象类继承而来的。QAbstractAxis是定义坐标轴属性和行为的基类,而QValueAxis则在此基础上提供了针对数值数据的具体实现。 Qt的图表模…...

《数字图像处理-OpenCV/Python》第16章:图像的特征描述
《数字图像处理-OpenCV/Python》第16章:图像的特征描述 本书京东 优惠购书链接 https://item.jd.com/14098452.html 本书CSDN 独家连载专栏 https://blog.csdn.net/youcans/category_12418787.html 第16章:图像的特征描述 特征通常是针对图像中的目标或…...

React的服务器端渲染(SSR)和客户端渲染(CSR)有什么区别?
React的服务器端渲染(SSR)和客户端渲染(CSR)是两种不同的页面渲染方式,它们各自有不同的特点和适用场景: 服务器端渲染(SSR) 页面渲染: 页面在服务器上生成,然后将完整的…...

安全生产第一位,靠谱的漏油监测系统有哪些?
漏油监测系统,一般是由漏油绳、漏油控制器、监控云平台组成,用于实时检测油库、油罐、加油站、输油管道、油类化工厂等场所是否发生漏油事故。在这些地方一旦发生漏油,就极可能引发爆炸,损害到人员及财产安全。而一套靠谱的漏油监…...

基于C#、Visual Studio 2017以及.NET Framework 4.5的Log4Net使用教程
在使用Log4Net记录日志时,以下是一个基于C#、Visual Studio 2017以及.NET Framework 4.5的详细步骤教程。这个教程适合初学者,会从添加Log4Net库、配置日志、编写日志记录代码等方面进行说明。 步骤1:安装Log4Net 通过NuGet安装 打开您的Vi…...

C# —— 构造函数
什么是构造函数 构造函数: 一般在函数为类的属性初始值的作用,构造函数的名称类名 在类里面定义构造函数 方法名和类名同名 不能带返回值类型 void/非void 不能有 // 创建一个构造函数 class People {public string Name { get; set; }public int Age { get; set;…...

HTML5的新属性
pattern:用于指定输入字段的正则表达式模式。在提交表单前,输入将验证是否符合指定的模式。 pattern 属性是 HTML5 中用于表单验证的一个属性,它用于指定一个正则表达式,以验证输入字段中的值是否符合特定的模式。该属性通常与 &l…...

[C语言] 常用排序算法
冒泡排序 思路: 从小到大,找到集合中最小的放在最左边,在剩下的集合中找到最小的放在最左边以此类推。如何找到最小的?(假定左边第一个数就是最小的,让它依次和它右边的比较,如果右边的比它还小…...

【前端vue3】TypeScrip-interface(接口)和对象类型
对象类型 定义对象需要用到interface(接口),主要用来约束数据的类型满足格式 定义方式如下: interface Person {name: string;age: number; }如对象中与接口中的属性不一致会报错,必须保持一致 例如如下:…...
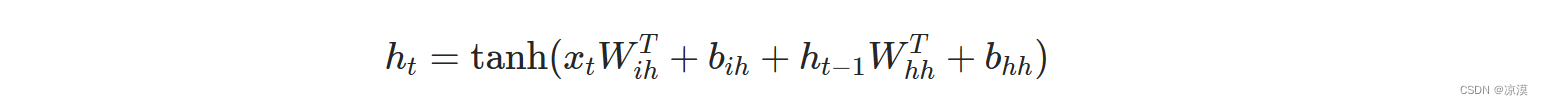
神经网络 torch.nn---nn.RNN()
torch.nn - PyTorch中文文档 (pytorch-cn.readthedocs.io) RNN — PyTorch 2.3 documentation torch.nn---nn.RNN() nn.RNN(input_sizeinput_x,hidden_sizehidden_num,num_layers1,nonlinearitytanh, #默认tanhbiasTrue, #默认是Truebatch_firstFalse,dropout0,bidirection…...
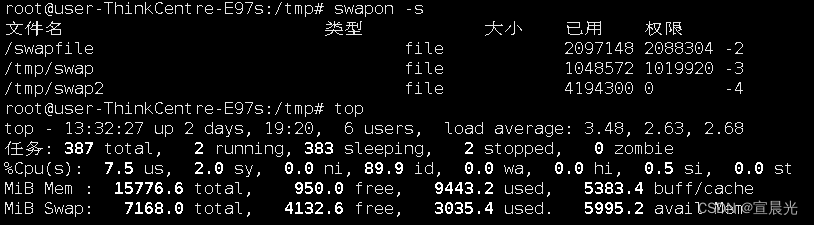
RocketMQ-记一次生产者发送消息存在超时异常
目录 1、背景说明 2、排查 2.1、防火墙 2.2、超时时间设置 2.3、服务器资源检查 2.3.1、内存、CPU等 2.3.2、磁盘空间 编辑 2.3.3、检查文件描述符 2.3.4、swap区 3、增加swap空间 3.1、创建目录 3.2、格式化 3.3、启动swap 3.4、查看效果 1、背景说明 在一次…...
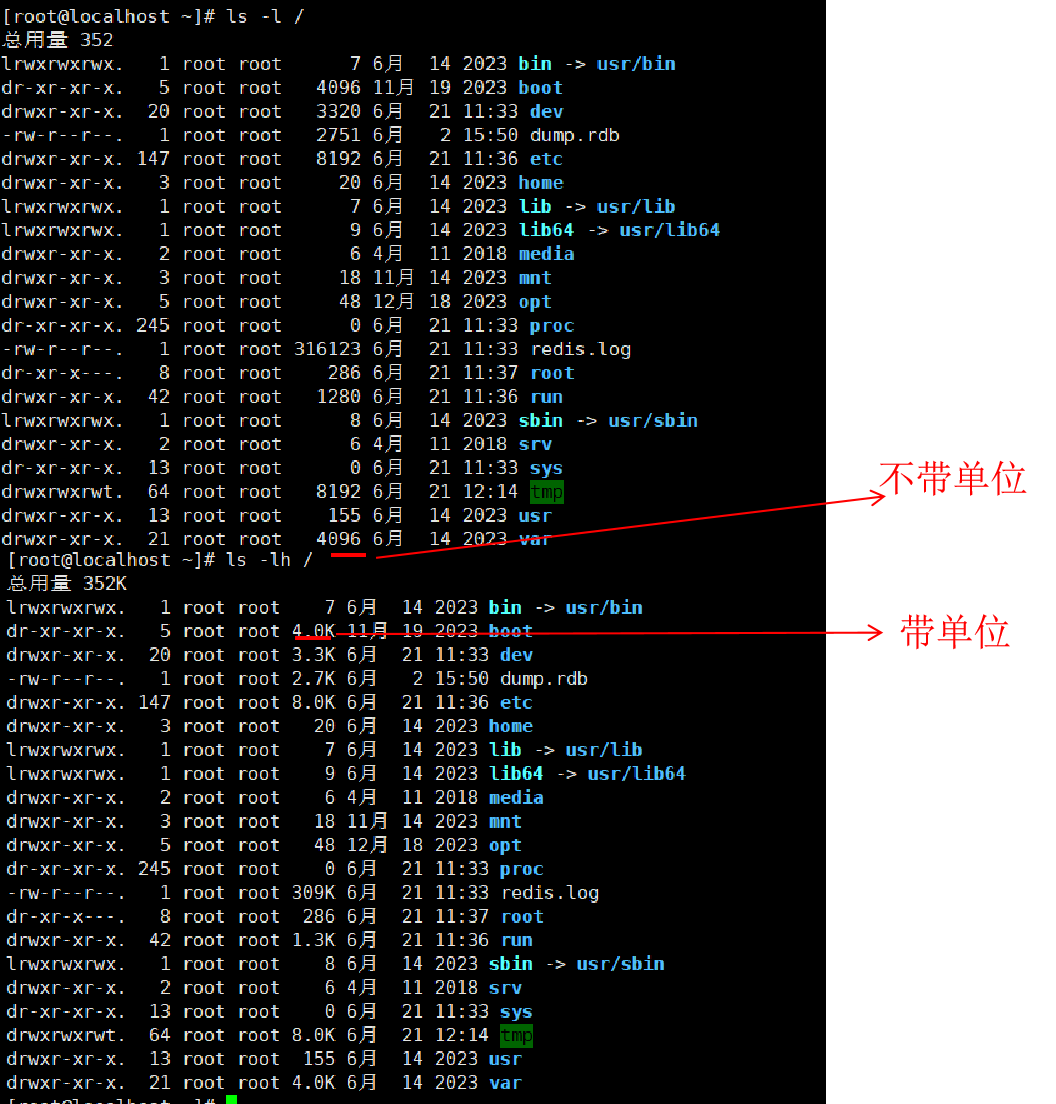
ls命令的参数选项
ls命令的参数的作用 可以指定要查看的文件夹(目录)的内容,如果不指定参数,就查看当前工作目录的内容。ls 命令的选项 常用语法:ls [-a -l -h] [linux路径] -a 选项表示 all ,即列出全部内容,包括…...
)
网络安全:Web 安全 面试题.(文件上传漏洞)
网络安全:Web 安全 面试题.(文件上传漏洞) 网络安全面试是指在招聘过程中,面试官会针对应聘者的网络安全相关知识和技能进行评估和考察。这种面试通常包括以下几个方面: (1)基础知识:包括网络基础知识、操…...

智源联合多所高校推出首个多任务长视频评测基准MLVU
当前,研究社区亟需全面可靠的长视频理解评估基准,以解决现有视频理解评测基准在视频长度不足、类型和任务单一等方面的局限性。因此,智源联合北邮、北大和浙大等多所高校提出首个多任务长视频理解评测基准MLVU(A Comprehensive Be…...

Linux系统:线程概念 线程控制
Linux系统:线程概念 & 线程控制 线程概念轻量级进程 LWP页表 线程控制POSIX 线程库 - ptherad线程创建pthread_createpthread_self 线程退出pthread_exitpthread_cancelpthread_joinpthread_detach 线程架构线程与地址空间线程与pthread动态库 线程的优缺点 线程…...

从 LLM 到 Agent Skill —— 一文打通 AI 核心概念底层逻辑
从 LLM 到 Agent Skill —— 一文打通 AI 核心概念底层逻辑你是否经常听到 LLM、Token、Prompt、RAG、Agent 这些词,却总觉得一知半解? 别担心,这篇文章用最通俗的方式,把这10个AI核心概念一次性讲清楚。1. LLM —— 大 Language …...

如何构建你的个人AI记忆库:三步完成微信聊天数据永久留存
如何构建你的个人AI记忆库:三步完成微信聊天数据永久留存 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/We…...

房地产行业 Zoom 钓鱼攻击机理与防御体系研究
摘要 2026 年 5 月,美国加利福尼亚房地产协会(C.A.R.)发布预警,针对房产中介的新型 Zoom 钓鱼诈骗呈高发态势。攻击者依托房产门户网站房源信息,伪装成意向购房者发起虚假咨询,以沟通房源细节为由诱导中介点…...

CANN/asc-devkit make_int2向量构造函数
make_int2 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/…...

2026廊坊硅酸铝柔性包裹,防火专业厂家这样选
最近在跑几个建筑机电工程,跟不少项目经理、施工队负责人聊了聊,发现大家不约而同遇到了同一个坎儿——管道防火验收。尤其是湿式报警阀间、排烟管道这些“硬骨头”,防火包裹的材质、阻燃等级、贴合度,直接决定了消防验收能不能一…...

【数据结构】与排序算法鏖战5天,我终于搞懂了排序的思路和实现--排序算法大全的保姆级攻略
目录 一,排序的概念及分类 二,排序算法的实现 1,插入排序(intsert sort) _1,核心思路: _2,代码实现: _3,总结: 2,希尔排序(Shell sort) _…...

大语言模型评测框架解析:从公平对比到工程选型实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“ai-llm-comparison”。光看名字,你大概能猜到它是做什么的——对比不同的大语言模型。但如果你以为这只是个简单的跑分列表,那就太小看它了。作为一个在AI应用开发领域摸爬滚…...

别再只会用Bridge了!从KVM网络配置到Open vSwitch实战,聊聊虚拟交换机的那些‘坑’
从传统桥接到Open vSwitch:虚拟网络进阶实战指南 在虚拟化技术普及的今天,网络配置往往成为制约整体性能的关键瓶颈。许多运维工程师在初期使用KVM默认的桥接或NAT网络时,能够满足基本需求,但随着业务规模扩大,传统方案…...

初创团队如何利用taotoken实现api密钥的统一管理与访问控制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用 Taotoken 实现 API 密钥的统一管理与访问控制 对于初创技术团队而言,在多人协作开发中引入大模型能力…...

Diablo Edit2完全手册:开源角色编辑器的深度解析
Diablo Edit2完全手册:开源角色编辑器的深度解析 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾在暗黑破坏神2中花费数小时刷装备,只为获得一件特定属性的装备&am…...