PyTorch(一)模型训练过程
PyTorch(一)模型训练过程
#c 总结 实践总结
该实践从「数据处理」开始到最后利用训练好的「模型」预测,感受到了整个模型的训练过程。其中也有部分知识点,例如定义神经网络,只是初步的模仿,有一个比较浅的认识,还需要继续学习原理。
整个流程:
「准备数据」,「创建数据加载器」,「选择训练设备」,「定义神经网络」,「定义损失函数和优化器」,「定义训练和测试函数」,「迭代训练」,「保存模型」,「加载模型」,「模型预测」。
相关知识点:
1.Dataset与DataLoader
2.迭代器
3.模型定义
4.损失函数与优化器
5.模型训练与测试
6.模型保存,加载与预测
1 数据处理
#d Dataset与DataLoader
在处理数据时,PyTorch有两个基本的原语来与数据交互:torch.utils.data.DataLoader 和 torch.utils.data.Dataset。Dataset 用于存储样本以及它们相应的标签,而 DataLoader 围绕 Dataset 封装了一个「迭代器」。
Dataset 类通常用来定义数据集,它包含了数据和标签。而 DataLoader 类则是用来批量加载数据集,支持自动加载、打乱数据、多线程加载等功能,使得数据的加载更加高效和灵活。
#e 导入库 Dataset与DataLoader
import torch
from torch import nn# 神经网络模块
from torch.utils.data import DataLoader# 数据加载器
from torchvision import datasets# 数据集
from torchvision.transforms import ToTensor# 图像转换为张量
#c 补充 特定领域库 Dataset与DataLoader
PyTorch 提供了特定领域的库,比如 TorchText、TorchVision 和 TorchAudio,它们都包含了Dataset。torchvision.datasets 模块包含了许多现实世界视觉数据集的 Dataset 对象,例如 CIFAR、COCO。每个 TorchVision 的Dataset都包括两个参数:transform 和 target_transform,它们分别用来修改样本和标签。
#d 迭代器(Iterable)
迭代器(Iterable)是一种允许程序员遍历一个容器(特别是列表等序列类型)的对象。在Python中,迭代器遵循迭代协议,即它们实现了__iter__()方法,该方法返回一个迭代器对象本身,这个对象还需要实现__next__()方法,该方法在每次迭代时返回容器中的下一个项目。通过提供一种统一、高效、按需处理数据的方式,极大地简化了数据遍历和处理的复杂性。
「迭代器」解决的问题:
- 统一的遍历接口:迭代器提供了一种统一的方法来遍历各种类型的数据容器(如列表、元组、字典等),而不需要知道容器的内部结构。
- 内存效率:迭代器允许按需遍历元素,而不是一次性将所有元素加载到内存中。这对于遍历大数据集特别有用,因为它可以显著减少程序的内存使用。
- 惰性计算:迭代器支持惰性计算,这意味着数据元素是在需要时才被计算和返回,而不是在迭代器创建时。这可以提高计算效率,特别是在处理复杂或无限的数据序列时。
没有「迭代器」的影响:
- 遍历复杂性增加:没有迭代器,程序员需要为不同类型的数据结构编写不同的遍历代码,这不仅增加了开发的复杂性,也降低了代码的可重用性。
- 内存效率降低:在处理大型数据集时,可能需要一次性将所有数据加载到内存中,这会导致显著的内存消耗,甚至可能导致内存不足的错误。
- 减少惰性计算的机会:没有迭代器机制,很难实现按需计算数据元素的逻辑,这可能导致不必要的计算开销,特别是在只需要数据集一小部分或者在数据集很大时。
#e 吃自助餐 迭代器
想象一下你在一家餐厅吃自助餐。自助餐提供了一个装满不同菜肴的长桌子,你拿着一个盘子,从一端开始,挨个检查每种菜肴,决定是否将其加入你的盘子。在这个过程中,你(顾客)就像一个迭代器,而长桌子上的菜肴就像是一个可迭代的容器。你一次检查一个菜肴,直到遍历完所有的菜肴,或者你的盘子满了为止。
#e 迭代访问列表 迭代器
假设我们有一个列表(List)numbers = [1, 2, 3, 4, 5],使用iter(numbers)创建了一个迭代器,它能够遍历列表numbers中的每个元素。使用next(iterator)可以获取容器中的下一个元素。当所有元素都被遍历完毕时,next()会抛出一个StopIteration异常,表示没有更多元素可以访问,这时我们结束循环。
numbers = [1, 2, 3, 4, 5] # 可迭代的容器
iterator = iter(numbers) # 创建迭代器while True:try:# 使用next()获取下一个元素number = next(iterator)print(number)except StopIteration:# 如果所有元素都遍历完毕,则结束循环break
#c 关联 相关概念
「迭代器」影响的「概念」:
-
可迭代对象(Iterable):任何实现了
__iter__()方法的对象都是可迭代的,该方法需要返回一个迭代器对象。迭代器本身也是可迭代的,因为它实现了__iter__()方法,并返回自身。 -
生成器(Generator):生成器是一种特殊类型的迭代器,它使用函数加上
yield语句来实现,无需手动实现__iter__()和__next__()方法。生成器简化了迭代器的创建过程,直接受到了迭代器概念的启发。 -
循环(Loops):例如
for循环和while循环,在Python中,for循环内部实际上使用迭代器来遍历可迭代对象。 -
函数式编程工具:如
map()、filter()和reduce()等函数,它们接受一个函数和一个可迭代对象作为输入,内部通过迭代器遍历可迭代对象。
影响「迭代器」的概念:
-
面向对象编程(OOP):迭代器模式是面向对象设计模式的一部分,要求对象实现特定的接口(如Python中的
__iter__()和__next__()方法)。面向对象的概念提供了迭代器实现的框架。 -
惰性计算(Lazy Evaluation):惰性计算是指仅在真正需要计算结果时才进行计算。迭代器天然支持惰性计算,因为它们一次只处理集合中的一个元素。
-
函数式编程(Functional Programming):函数式编程强调使用函数来处理数据。迭代器与函数式编程紧密相关,因为迭代器提供了一种遍历和处理数据集合的方法,而不改变数据本身,这与函数式编程的不可变性原则相吻合。
#c 说明 数据集的选择
本次实践使用 FashionMNIST 数据集。该数据集是一个用于衣物识别的数据集,由Zalando(一家欧洲的在线时尚零售商)提供。它被设计为原始MNIST数据集的直接替代品,用于在机器学习和计算机视觉领域的基准测试中。FashionMNIST包含了10个类别的衣物图片,每个类别有7000张图片,整个数据集分为60000张训练图片和10000张测试图片。每张图片都是28x28像素的灰度图。这些类别包括:
- T-shirt/top(T恤/上衣)
- Trouser(裤子)
- Pullover(套衫)
- Dress(连衣裙)
- Coat(外套)
- Sandal(凉鞋)
- Shirt(衬衫)
- Sneaker(运动鞋)
- Bag(包)
- Ankle boot(短靴)
#e 下载数据集 数据集的选择
如果是自行搜集数据,比如利用爬虫获取自己想要的数据,获取的数据需要进行「数据处理」,例如「删除不符合数据」,「统一数据格式」,「去重」等方式。这里下载的数据已经是符合训练的数据格式,所以不需要进行对应的数据处理的环节。
# 下载训练数据集
train_data = datasets.FashionMNIST(root="data", # 数据存储的路径train=True, # 指定下载的是训练数据集download=True, # 如果数据不存在,则通过网络下载transform=ToTensor() # 将图片转换为Tensor
)# 下载测试数据集
test_data = datasets.FashionMNIST(root="data", # 数据存储的路径train=False, # 指定下载的是测试数据集download=True, # 如果数据不存在,则通过网络下载transform=ToTensor() # 将图片转换为Tensor
)
#d 数据加载
将 Dataset 作为参数传递给 DataLoader。DataLoader在dataset封装一个可迭代对象,并且支持自动批处理、采样、多进程数据加载等。
#e 加载代码 数据加载
在这里,定义了一个批量大小为64,即 dataloader 可迭代对象中的每个元素将返回一个包含64个特征和标签的批次。
batch_size = 64# 批大小# 创建数据加载器
train_dataloader = DataLoader(train_data, batch_size=batch_size)
#将dataset作为参数传入DataLoader,DataLoader会自动将数据分批,打乱数据,将数据加载到内存中
test_dataloader = DataLoader(test_data, batch_size=batch_size)for x,y in test_dataloader:print(f"Shape of x [N, C, H, W]: {x.shape}")#x.shape是一个4维张量,第一个维度是批大小,第二个维度是通道数,第三和第四维度是图像的高度和宽度print(f"Shape of y: {y.shape}, {y.dtype}")'''Shape of x [N, C, H, W]: torch.Size([64, 1, 28, 28])Shape of y: torch.Size([64]), torch.int64'''break
2 创建模型
#d 定义模型
在PyTorch中定义神经网络,需创建一个继承自nn.Module的类,并在__init__函数中定义神经网络的层,在forward函数中定义数据在神经网络中的传播路径。为了加速神经网络的训练,可以使用GPU或者MPS来训练模型。
#e 定义代码 定义模型
#使用cpu,gpu,mps的设备来训练模型
device =("cuda"if torch.cuda.is_available()else "mps"if torch.backends.mps.is_available()else "cpu"
)
print(f"Using {device} device")
#Using cuda deviceclass NeuralNetwork(nn.Module):def __init__(self):#定义神经网络的层super().__init__()#调用父类的构造函数self.flatten = nn.Flatten()#将28*28的图像展平为784的向量self.linear_relu_stack = nn.Sequential(#定义一个包含三个线性层的神经网络nn.Linear(28*28,512),#输入层nn.ReLU(),#激活函数nn.Linear(512,512),#隐藏层nn.ReLU(),#激活函数nn.Linear(512,10),#输出层)def forward(self,x):#定义数据在神经网络中的传播路径x = self.flatten(x)#将图像展平logits = self.linear_relu_stack(x)#将展平后的图像传入神经网络return logits#返回输出
model = NeuralNetwork().to(device)#将模型加载到设备上
print(model)
'''
NeuralNetwork((flatten): Flatten(start_dim=1, end_dim=-1)(linear_relu_stack): Sequential((0): Linear(in_features=784, out_features=512, bias=True)(1): ReLU()(2): Linear(in_features=512, out_features=512, bias=True)(3): ReLU()(4): Linear(in_features=512, out_features=10, bias=True))
)
'''
3 优化模型参数
#d 定义训练参数
-
在训练模型之前,需要定义「损失函数(loss function)」[ 和「优化器(optimizer)」。概念解释(5 相关概念)
-
在单个训练循环中,模型会对分批提供它的「训练数据集」进行「预测」并通过「反向传播算法」预测误差以调整模型的参数。
-
检查模型在测试数据集上的性能,以确保它在学习.
-
训练过程在多个迭代(周期)中进行。在每个周期中,模型学习参数以做出更好的预测。在每个周期打印模型的准确率和损失,希望看到准确率随着每个周期的增加而提高,损失随着每个周期的减少。
#e 损失函数与优化器
loss_fn = nn.CrossEntropyLoss()#使用交叉熵损失函数
#使用随机梯度下降优化器,model.parameters()返回模型的参数,lr=1e-3是学习率
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
#e 训练函数
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset)#数据集的大小model.train()#将模型设置为训练模式for batch, (X, y) in enumerate(dataloader):#遍历数据集X, y = X.to(device), y.to(device)#将数据加载到设备上# 计算预测误差pred = model(X)#对输入的数据进行预测loss = loss_fn(pred, y)#计算损失,差异越小,模型预测的越准确# 反向传播loss.backward()#反向传播算法optimizer.step()#优化器更新模型参数optimizer.zero_grad()#梯度清零if batch % 100 == 0:#每100个批次打印一次loss, current = loss.item(), (batch+1) * len(X)#打印损失和当前的批次的数据量print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")'''{loss:>7f}:表示损失值以浮点数形式打印,总宽度为7位,右对齐。{current:>5d}:表示当前处理的总数据量以整数形式打印,总宽度为5位,右对齐。{size:>5d}:表示整个数据集的大小以整数形式打印,总宽度为5位,右对齐'''
#e 测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)#数据集的大小num_batches = len(dataloader)#批次的数量model.eval()#将模型设置为评估模式test_loss, correct = 0, 0#初始化损失和正确的数量with torch.no_grad():#关闭梯度计算for X, y in dataloader:X, y = X.to(device), y.to(device)#将数据加载到设备上pred = model(X)#对输入的数据进行预测test_loss += loss_fn(pred, y).item()#计算损失correct += (pred.argmax(1) == y).type(torch.float).sum().item()#计算正确的数量'''pred.argmax(1)找出每个预测中概率最高的类别的索引,== y判断这些索引是否与真实标签相等。结果是一个布尔Tensor,通过.type(torch.float)转换为浮点数Tensor,然后使用.sum().item()计算并累加正确预测的总数。'''test_loss /= num_batches#计算平均损失correct /= size#计算正确率print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")#e 迭代训练
epochs = 5#迭代次数
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train(train_dataloader, model, loss_fn, optimizer)#训练模型test(test_dataloader, model, loss_fn)#测试模型
print("Done!")#训练完成
'''
运行结果
Epoch 1
-------------------------------
loss: 2.304268 [ 64/60000]
loss: 2.284021 [ 6464/60000]
loss: 2.263621 [12864/60000]
loss: 2.259448 [19264/60000]
loss: 2.231920 [25664/60000]
loss: 2.221592 [32064/60000]
loss: 2.215944 [38464/60000]
loss: 2.191191 [44864/60000]
loss: 2.177027 [51264/60000]
loss: 2.141848 [57664/60000]
Test Error: Accuracy: 58.7%, Avg loss: 2.137664Epoch 2
-------------------------------
loss: 2.147467 [ 64/60000]
loss: 2.139907 [ 6464/60000]
loss: 2.077062 [12864/60000]
loss: 2.094236 [19264/60000]
loss: 2.030329 [25664/60000]
loss: 1.982215 [32064/60000]
loss: 1.997371 [38464/60000]
loss: 1.923110 [44864/60000]
loss: 1.913458 [51264/60000]
loss: 1.835431 [57664/60000]
Test Error: Accuracy: 61.3%, Avg loss: 1.839774
'''
4 模型的保存
#d 保存方式
保存模型的一种常见方法是序列化内部状态字典(包含模型参数)。
#e 实现代码 保存方式
torch.save(model.state_dict(), "./model.pth")
print("Saved PyTorch Model State to ./model.pth")
'''
Saved PyTorch Model State to ./model.pth
'''
5 模型加载与预测
#d 加载流程
加载模型的过程包括重新创建模型结构,并将状态字典加载到其中。
#e 加载代码 加载流程
model = NeuralNetwork().to(device)#创建模型,to(device)将模型加载到设备上
model.load_state_dict(torch.load("./model.pth"))#加载模型
#e 预测代码
#利用模型进行预测
classes = ["T-shirt/top","Trouser","Pullover","Dress","Coat","Sandal","Shirt","Sneaker","Bag","Ankle boot",
]
model.eval()#将模型设置为评估模式
x, y = test_data[0][0], test_data[0][1]#获取测试数据
with torch.no_grad():#关闭梯度计算pred = model(x.to(device))#对输入的数据进行预测predicted, actual = classes[pred[0].argmax(0)], classes[y]#获取预测的类别和真实的类别print(f'Predicted: "{predicted}", Actual: "{actual}"')'''Predicted: "Ankle boot", Actual: "Ankle boot"'''
#c 备注 完整python文件
AI_series_learn/PyTorch/1.快速开始/basic.py at main · togetherhkl/AI_series_learn (github.com)
相关文章:
模型训练过程)
PyTorch(一)模型训练过程
PyTorch(一)模型训练过程 #c 总结 实践总结 该实践从「数据处理」开始到最后利用训练好的「模型」预测,感受到了整个模型的训练过程。其中也有部分知识点,例如定义神经网络,只是初步的模仿,有一个比较浅的…...

windows下cmd命令行模式中cd变换路径命令无效的解决办法
一,出现的情况 二,解决方法 当出现转换盘的时候打开 cmd 之后可能是无法生效的 ,因为在cmd 中转换盘首先需要用到换盘符 。 Solve1 : 先进行换盘 C: c: // 转换到 C盘 D: d: // 转化到 D盘 Solve2 : 直接进行强转 cd /dE:\ACM算法资源\XCP…...

收藏||电商数据采集流程||电商数据采集API接口
商务数据分析的流程 第一步:明确分析目的。首先要明确分析目的,并把分析目的分解成若干个不同的分析要点,然后梳理分析思路,最后搭建分析框架。 第二步:数据采集。主流电商API接口数据采集,一般可以通过数…...

修改源码,打patch包,线上环境不生效
1.首先看修改的源码文件是否正确 在node_modules中,找对应的包,然后查看包中package.json 的main和module。如果用require引入,则修改lib下面的组件,如果是import引入则修改es下面的文件 main 对应commonjs引入方式的程序入口文件…...

NUC980-OLED实现全中文字库的方法
1.背景 有一个产品,客户需要屏幕展示一些内容,要带一些中文,实现了OLED12864的驱动,但是它不带字库,现在要实现OLED全字库的显示 2.制作原始字库 下载软件pctolcd2002 设置 制作字库 打开原始文件 用软件自带的&…...

UEFI 启动原理及qemu 虚拟化中使用
UEFI 启动原理及qemu 虚拟化中使用 什么是BIOS?什么是 UEFI? 什么是BIOS? 计算机启动时会加载 BIOS,以初始化和测试硬件功能。它使用 POST 或 Power On Self Test 来确保硬件配置有效且工作正常,然后寻找存储引导设…...

35、正则表达式
一、正则表达式命令 正则表达式:匹配的是文本内容,linux的文本三剑客都是针对文本内容。 grep 过滤文本内容 sed 针对文本内容进行增删改查 awk 按行取列 文本三剑客----都是按照行进行匹配。 1.1、grep筛选: grep的作用就是…...

Ubuntu20.04中复现FoundationPose
Ubuntu20.04中复现FoundationPose 文章目录 Ubuntu20.04中复现FoundationPose1.安装cuda和cudnn2.下载相关资源3.环境配置4.运行model-based demo5.运行ycbv demoReference 🚀 非常重要的环境配置 🚀 ubuntu 20.04cuda 11.8.0cudnn v8.9.7python 3.9.19…...
】- QLabel文本框的使用)
【Qt快速入门(四)】- QLabel文本框的使用
目录 Qt快速入门(四)- QLabel文本框的使用QLabel文本框的使用QLabel的基本用法1. 创建和设置文本2. 动态设置文本 设置文本样式1.设置字体和颜色2.文本对齐方式3.富文本显示 显示图片QLabel的交互功能可点击标签 QLabel的高级特性1.缩放图片以适应标签大…...

用Python设置Excel工作表网格线的隐藏与显示
Excel表格界面的直观性很大程度上得益于表格中的网格线设计,这些线条帮助用户精确对齐数据,清晰划分单元格。网格线是Excel界面中默认显示的辅助线,用于辅助定位,与单元格边框不痛,不影响打印输出。然而,在…...

自回归模型胜过扩散模型:用于可扩展图像生成的 Llama
📜 文献卡 Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation作者: Peize Sun; Yi Jiang; Shoufa Chen; Shilong Zhang; Bingyue Peng; Ping Luo; Zehuan YuanDOI: 10.48550/arXiv.2406.06525摘要: We introduce LlamaGen, a new family …...

访问外网的安全保障——反向沙箱
反向沙箱作为一种网络安全技术,其核心理念在于通过构建一个隔离且受控的环境,来有效阻止潜在的网络威胁对真实系统的影响。在当今日益复杂的网络环境中,如何借助反向沙箱实现安全上网,已成为众多用户关注的焦点。 随着信息化的发…...

【绝对有用】C++ 字符串进行排序、vector增加内容 和 剔除值
在 C 中对字符串进行排序,可以使用标准库中的 std::sort 函数。std::sort 函数可以用于容器或范围内的元素排序,包括字符串中的字符。以下是一个简单的示例代码,展示了如何对字符串中的字符进行排序: #include <iostream> …...
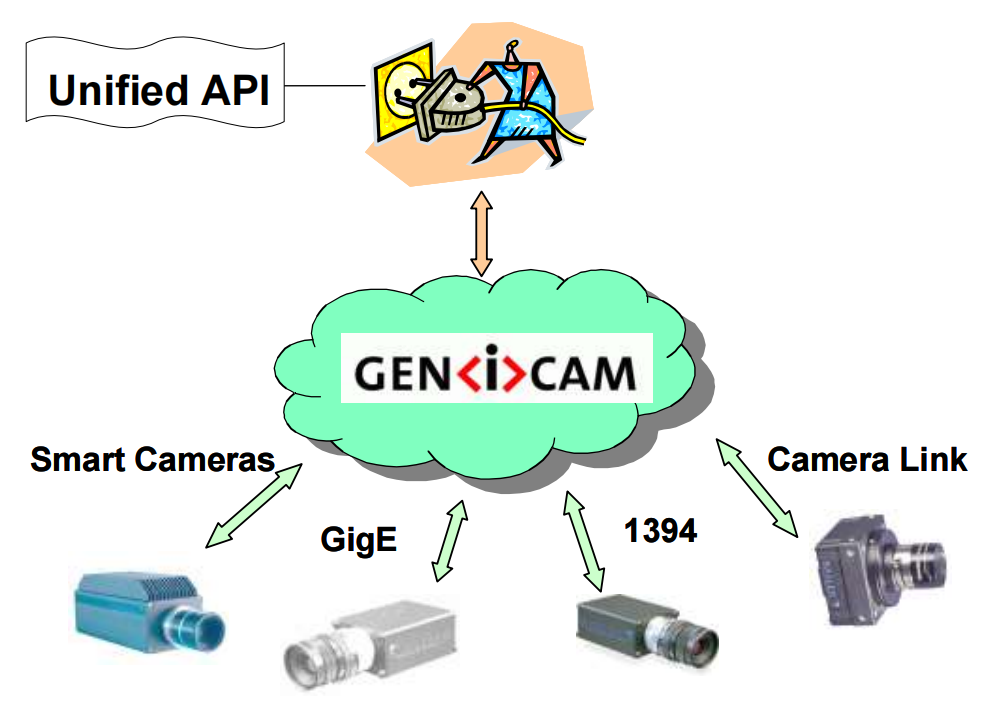
GenICam标准(一)
系列文章目录 GenICam标准(一) GenICam标准(二) GenICam标准(三) GenICam标准(四) GenICam标准(五) GenICam标准(六) 文章目录 系列文…...

【Redis】分布式锁基本理论与简单实现
目录 分布式锁解释作用特性实现方式MySQL、Redis、Zookeeper三种方式对比 原理 reids分布式锁原理目的容错redis简单分布式锁实现锁接口实现类下单场景的实现容错场景1解决思路优化代码 容错场景2Lua脚本Redis利用Lua脚本解决多条命令原子性问题 释放锁的业务流程Lua脚本来表示…...

Web开发技术大作业(HTML\CSS\PHP\MYSQL\JS)
从6月13日到6月15日,经过一系列的操作,终于把老师布置的大作业写完了,虽然有很多水分,很多东西都是为了应付(特别是最后做的那几个网页),真的是惨不忍睹,不过既然花时间写了…...

【全开源】沃德会务会议管理系统(FastAdmin+ThinkPHP+Uniapp)
沃德会务会议管理系统一款基于FastAdminThinkPHPUniapp开发的会议管理系统,对会议流程、开支、数量、标准、供应商提供一种标准化的管理方法。以达到量化成本节约,风险缓解和服务质量提升的目的。适用于大型论坛、峰会、学术会议、政府大会、合作伙伴大会…...
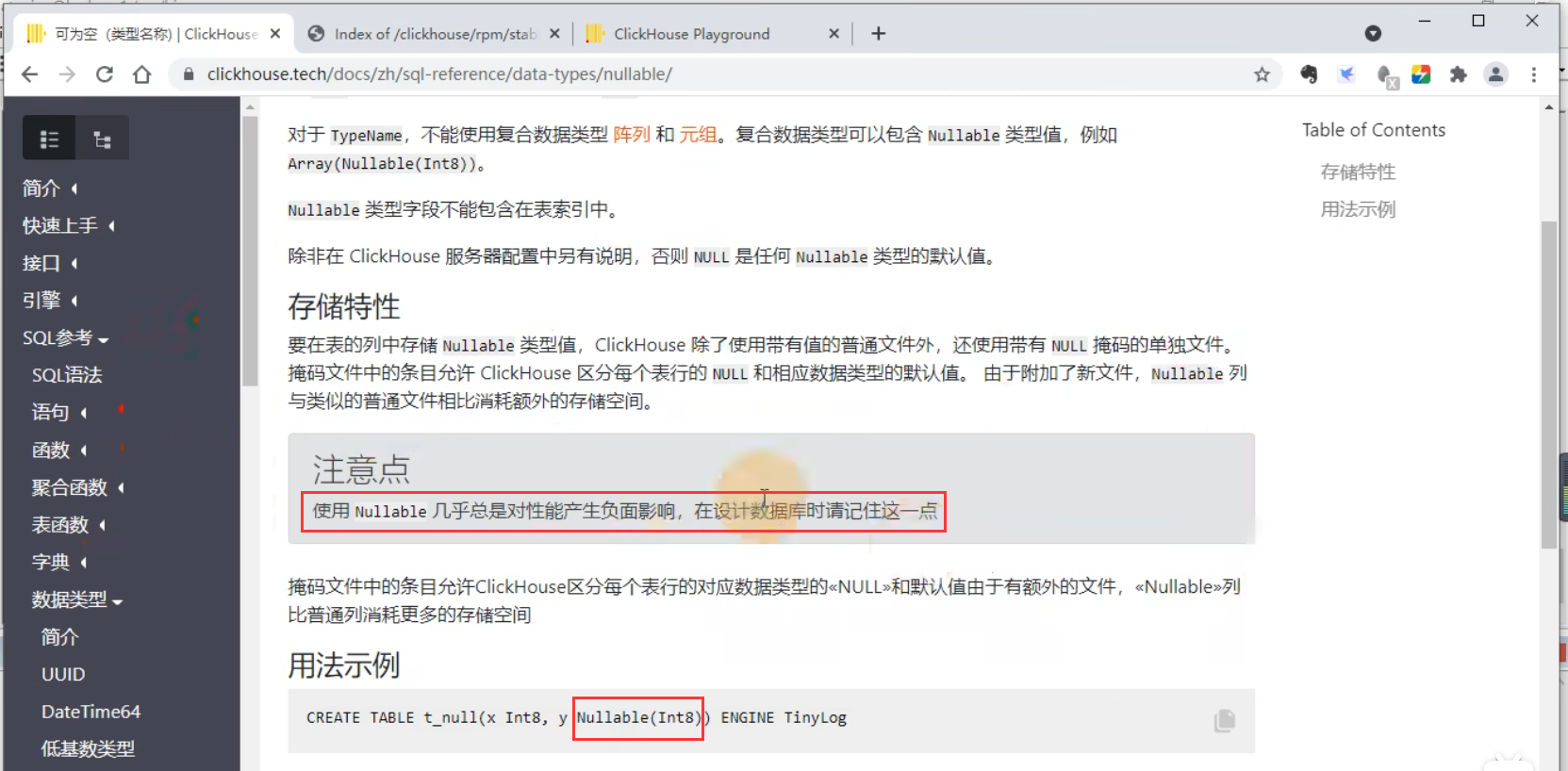
尚硅谷大数据技术ClickHouse教程-笔记01【ClickHouse单机安装、数据类型】
视频地址:一套上手ClickHouse-OLAP分析引擎,囊括Prometheus与Grafana_哔哩哔哩_bilibili 01_尚硅谷大数据技术之ClickHouse入门V1.0 尚硅谷大数据技术ClickHouse教程-笔记01【ClickHouse单机安装、数据类型】尚硅谷大数据技术ClickHouse教程-笔记02【表引…...

生产管理系统看板,在自动化设备领域的创新应用
在自动化设备领域,生产管理系统看板的创新应用是一项引人注目的技术进步。以广州某自动化设备有限公司为例,他们是一家涂装工程设备制造企业,将讯鹏生产管理系统电子看板成功应用于全自动立式静电喷粉线、卧式静电喷粉线、氟碳喷涂生产线等领…...
分享一个图片转换工具XnConvert
目录 stablediffusion3 生成图片效果图图片转换工具XnConvertpixzip stablediffusion3 生成图片效果图 今天在使用stablediffusion3时,尝试生成了几张Java的图片,发现确实很好看,文生图的效果超出我的预期,忍不住想要给自己的csd…...

FPGA/CPLD数字系统设计实战:从器件选型到调试验证的工程指南
1. 从一则行业趣闻聊起:FPGA厂商的“江湖地位”与我们的设计选择前几天翻看一些老旧的行业资料,偶然间又看到了这篇2012年来自EE Times的“陈年旧文”。文章作者Clive Maxfield用他标志性的幽默笔调,聊了一个看似无厘头的话题:将科…...

ARM Firmware Suite与Integrator开发板嵌入式开发指南
1. ARM Firmware Suite与Integrator开发板概述ARM Firmware Suite(AFS)是ARM架构下专为嵌入式系统开发设计的固件套件,在Integrator系列开发板上发挥着核心作用。这套工具链最初由ARM Limited在1999-2002年间开发,至今仍在许多传统…...

模块化前端框架设计:从原子状态到组合式架构的工程实践
1. 项目概述:一个轻量级、模块化的现代Web应用框架最近在梳理手头的几个前端项目,发现随着功能迭代,代码越来越臃肿,不同项目间的基础工具函数、状态管理逻辑、路由配置总是要重新写一遍,或者复制粘贴,维护…...

自感痕迹论的思想史意义:一场发生学范式的四维跃迁
自感痕迹论的思想史意义:一场发生学范式的四维跃迁摘要在当代思想版图中,人文精神与科学技术正处于前所未有的割裂状态。一方面,现象学、后结构主义在解构了宏大叙事后,陷入相对主义与操作空转的泥淖;另一方面…...

大部分 App 没准备好被 Agent 操作——这是设计缺陷,不是功能缺失
大部分 App 没准备好被 Agent 操作——这是设计缺陷,不是功能缺失 2025 年被很多人称为「AI Agent 元年」。 Claude Code、Cursor、Windsurf……一批 agentic 工具密集涌现,Agent 不再只是聊天框里的助手,它开始真正「做事」:自己…...
)
【AI原生架构黄金法则】:SITS 2026现场实录的7条反直觉设计铁律(仅限首批参会专家内部流出)
AI原生应用架构设计:SITS 2026技术专家实战经验分享 更多请点击: https://intelliparadigm.com 第一章:SITS 2026现场共识与AI原生架构范式跃迁 在SITS 2026全球智能系统技术峰会上,来自37个国家的架构师、AI平台工程师与标准化组…...
 - Android 反编译器和调试器)
JEB Pro 5.40 (macOS, Linux, Windows) - Android 反编译器和调试器
JEB Pro 5.40 (macOS, Linux, Windows) - 逆向工程平台 Reverse Engineering for Professionals. 请访问原文链接:https://sysin.org/blog/jeb/ 查看最新版。原创作品,转载请保留出处。 作者主页:sysin.org JEB Decompiler JEB 是逆向工程…...

HsMod终极指南:55项功能全面优化炉石传说游戏体验的完整方案
HsMod终极指南:55项功能全面优化炉石传说游戏体验的完整方案 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx框架开发的炉石传说模改插件,为…...

C++项目集成Tesseract 5.x踩坑实录:从编译选项到内存管理的完整避坑指南
C项目集成Tesseract 5.x踩坑实录:从编译选项到内存管理的完整避坑指南 在计算机视觉和文档处理领域,Tesseract OCR引擎以其开源免费、多语言支持和较高的识别准确率,成为众多C项目的首选集成方案。然而,从源码编译到生产环境部署&…...
)
从USB3.2到PCIe 5.0:我的高速串行链路阻抗匹配踩坑实录(附Sigrity仿真文件)
从USB3.2到PCIe 5.0:我的高速串行链路阻抗匹配踩坑实录 去年负责一款数据中心加速卡的设计时,我遇到了职业生涯中最棘手的高速信号完整性问题。这块板卡需要同时支持PCIe 5.0 x16和四个USB3.2 Gen2x2接口,当第一批工程样机回来进行信号测试时…...