超参数调优-通用深度学习篇(上)
文章目录
- 深度学习超参数调优
- 网格搜索
- 示例一:网格搜索回归模型超参数
- 示例二:Keras网格搜索
- 随机搜索
- 贝叶斯搜索
- 超参数调优框架
- Optuna深度学习超参数优化框架
- nvidia nemo大模型超参数优化框架
参数调整理论: 黑盒优化:超参数优化算法最新进展总结
- 均为转载,联系侵删
深度学习超参数调优
- pytorch 网格搜索LSTM最优参数 python网格搜索优化参数
- Keras深度学习超参数优化官方手册
- Keras深度学习超参数优化手册-CSDN博客版
- 超参数搜索不够高效?这几大策略了解一下
- 使用贝叶斯优化进行深度神经网络超参数优化
网格搜索
示例一:网格搜索回归模型超参数
# grid search cnn for airline passengers
from math import sqrt
from numpy import array, mean
from pandas import DataFrame, concat, read_csv
from sklearn.metrics import mean_squared_error
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Conv1D, MaxPooling1D# split a univariate dataset into train/test sets
def train_test_split(data, n_test):return data[:-n_test], data[-n_test:]# transform list into supervised learning format
def series_to_supervised(data, n_in=1, n_out=1):df = DataFrame(data)cols = list()# input sequence (t-n, ... t-1)for i in range(n_in, 0, -1):cols.append(df.shift(i))# forecast sequence (t, t+1, ... t+n)for i in range(0, n_out):cols.append(df.shift(-i))# put it all togetheragg = concat(cols, axis=1)# drop rows with NaN valuesagg.dropna(inplace=True)return agg.values# root mean squared error or rmse
def measure_rmse(actual, predicted):return sqrt(mean_squared_error(actual, predicted))# difference dataset
def difference(data, order):return [data[i] - data[i - order] for i in range(order, len(data))]# fit a model
def model_fit(train, config):# unpack confign_input, n_filters, n_kernel, n_epochs, n_batch, n_diff = config# prepare dataif n_diff > 0:train = difference(train, n_diff)# transform series into supervised formatdata = series_to_supervised(train, n_in=n_input)# separate inputs and outputstrain_x, train_y = data[:, :-1], data[:, -1]# reshape input data into [samples, timesteps, features]n_features = 1train_x = train_x.reshape((train_x.shape[0], train_x.shape[1], n_features))# define modelmodel = Sequential()model.add(Conv1D(filters=n_filters, kernel_size=n_kernel, activation='relu', input_shape=(n_input, n_features)))model.add(MaxPooling1D(pool_size=2))model.add(Flatten())model.add(Dense(1))model.compile(loss='mse', optimizer='adam')# fitmodel.fit(train_x, train_y, epochs=n_epochs, batch_size=n_batch, verbose=0)return model# forecast with the fit model
def model_predict(model, history, config):# unpack confign_input, _, _, _, _, n_diff = config# prepare datacorrection = 0.0if n_diff > 0:correction = history[-n_diff]history = difference(history, n_diff)x_input = array(history[-n_input:]).reshape((1, n_input, 1))# forecastyhat = model.predict(x_input, verbose=0)return correction + yhat[0]# walk-forward validation for univariate data
def walk_forward_validation(data, n_test, cfg):predictions = list()# split datasettrain, test = train_test_split(data, n_test)# fit modelmodel = model_fit(train, cfg)# seed history with training datasethistory = [x for x in train]# step over each time-step in the test setfor i in range(len(test)):# fit model and make forecast for historyyhat = model_predict(model, history, cfg)# store forecast in list of predictionspredictions.append(yhat)# add actual observation to history for the next loophistory.append(test[i])# estimate prediction errorerror = measure_rmse(test, predictions)print(' > %.3f' % error)return error# score a model, return None on failure
def repeat_evaluate(data, config, n_test, n_repeats=10):# convert config to a keykey = str(config)# fit and evaluate the model n timesscores = [walk_forward_validation(data, n_test, config) for _ in range(n_repeats)]# summarize scoreresult = mean(scores)print('> Model[%s] %.3f' % (key, result))return (key, result)# grid search configs
def grid_search(data, cfg_list, n_test):# evaluate configsscores = [repeat_evaluate(data, cfg, n_test) for cfg in cfg_list]# sort configs by error, ascscores.sort(key=lambda tup: tup[1])return scores# create a list of configs to try
def model_configs():# define scope of configsn_input = [12]n_filters = [64]n_kernels = [3, 5]n_epochs = [100]n_batch = [1, 150]n_diff = [0, 12]# create configsconfigs = list()for a in n_input:for b in n_filters:for c in n_kernels:for d in n_epochs:for e in n_batch:for f in n_diff:cfg = [a, b, c, d, e, f]configs.append(cfg)print('Total configs: %d' % len(configs))return configs# define dataset
# 下载数据集:https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-passengers.csv
series = read_csv('airline-passengers.csv', header=0, index_col=0)
data = series.values
# data split
n_test = 12
# model configs
cfg_list = model_configs()
# grid search
scores = grid_search(data, cfg_list, n_test)
print('done')
# list top 10 configs
for cfg, error in scores[:3]:print(cfg, error)
示例二:Keras网格搜索
"""
调整batch size和epochs
"""# Use scikit-learn to grid search the batch size and epochs
import numpy as np
import tensorflow as tf
from sklearn.model_selection import GridSearchCV
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from scikeras.wrappers import KerasClassifier
# Function to create model, required for KerasClassifier
def create_model():# create modelmodel = Sequential()model.add(Dense(12, input_shape=(8,), activation='relu'))model.add(Dense(1, activation='sigmoid'))# Compile modelmodel.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])return model
# fix random seed for reproducibility
seed = 7
tf.random.set_seed(seed)
# load dataset
dataset = np.loadtxt("pima-indians-diabetes.csv", delimiter=",")
# split into input (X) and output (Y) variables
X = dataset[:,0:8]
Y = dataset[:,8]
# create model
model = KerasClassifier(model=create_model, verbose=0)
# define the grid search parameters
batch_size = [10, 20, 40, 60, 80, 100]
epochs = [10, 50, 100]
param_grid = dict(batch_size=batch_size, epochs=epochs)
grid = GridSearchCV(estimator=model, param_grid=param_grid, n_jobs=-1, cv=3)
grid_result = grid.fit(X, Y)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):print("%f (%f) with: %r" % (mean, stdev, param))
"""
更多参考:https://machinelearningmastery.com/grid-search-hyperparameters-deep-learning-models-python-keras/
"""
随机搜索
# Load the dataset
X, Y = load_dataset()# Create model for KerasClassifier
def create_model(hparams1=dvalue,hparams2=dvalue,...hparamsn=dvalue):# Model definition...model = KerasClassifier(build_fn=create_model) # Specify parameters and distributions to sample from
hparams1 = randint(1, 100)
hparams2 = ['elu', 'relu', ...]
...
hparamsn = uniform(0, 1)# Prepare the Dict for the Search
param_dist = dict(hparams1=hparams1, hparams2=hparams2, ...hparamsn=hparamsn)# Search in action!
n_iter_search = 16 # Number of parameter settings that are sampled.
random_search = RandomizedSearchCV(estimator=model, param_distributions=param_dist,n_iter=n_iter_search,n_jobs=, cv=, verbose=)
random_search.fit(X, Y)# Show the results
print("Best: %f using %s" % (random_search.best_score_, random_search.best_params_))
means = random_search.cv_results_['mean_test_score']
stds = random_search.cv_results_['std_test_score']
params = random_search.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):print("%f (%f) with: %r" % (mean, stdev, param))
贝叶斯搜索
"""
准备数据
"""
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()# split into train, validation and test sets
train_x, val_x, train_y, val_y = train_test_split(train_images, train_labels, stratify=train_labels, random_state=48, test_size=0.05)
(test_x, test_y)=(test_images, test_labels)# normalize pixels to range 0-1
train_x = train_x / 255.0
val_x = val_x / 255.0
test_x = test_x / 255.0#one-hot encode target variable
train_y = to_categorical(train_y)
val_y = to_categorical(val_y)
test_y = to_categorical(test_y)# pip3 install keras-tuner
"""
调整获取最优参数(MLP版)
"""
model = Sequential()model.add(Dense(units = hp.Int('dense-bot', min_value=50, max_value=350, step=50), input_shape=(784,), activation='relu'))for i in range(hp.Int('num_dense_layers', 1, 2)):model.add(Dense(units=hp.Int('dense_' + str(i), min_value=50, max_value=100, step=25), activation='relu'))model.add(Dropout(hp.Choice('dropout_'+ str(i), values=[0.0, 0.1, 0.2])))model.add(Dense(10,activation="softmax"))hp_optimizer=hp.Choice('Optimizer', values=['Adam', 'SGD'])if hp_optimizer == 'Adam':hp_learning_rate = hp.Choice('learning_rate', values=[1e-1, 1e-2, 1e-3])
elif hp_optimizer == 'SGD':hp_learning_rate = hp.Choice('learning_rate', values=[1e-1, 1e-2, 1e-3])nesterov=Truemomentum=0.9
model.compile(optimizer = hp_optimizer, loss='categorical_crossentropy', metrics=['accuracy'])tuner_mlp = kt.tuners.BayesianOptimization(model,seed=random_seed,objective='val_loss',max_trials=30,directory='.',project_name='tuning-mlp')
tuner_mlp.search(train_x, train_y, epochs=50, batch_size=32, validation_data=(dev_x, dev_y), callbacks=callback)
best_mlp_hyperparameters = tuner_mlp.get_best_hyperparameters(1)[0]
print("Best Hyper-parameters")
# best_mlp_hyperparameters.values
"""
使用最优参数来训练模型
"""
model_mlp = Sequential()model_mlp.add(Dense(best_mlp_hyperparameters['dense-bot'], input_shape=(784,), activation='relu'))for i in range(best_mlp_hyperparameters['num_dense_layers']):model_mlp.add(Dense(units=best_mlp_hyperparameters['dense_' +str(i)], activation='relu'))model_mlp.add(Dropout(rate=best_mlp_hyperparameters['dropout_' +str(i)]))model_mlp.add(Dense(10,activation="softmax"))model_mlp.compile(optimizer=best_mlp_hyperparameters['Optimizer'], loss='categorical_crossentropy',metrics=['accuracy'])
history_mlp= model_mlp.fit(train_x, train_y, epochs=100, batch_size=32, validation_data=(dev_x, dev_y), callbacks=callback)
# model_mlp=tuner_mlp.hypermodel.build(best_mlp_hyperparameters)
# history_mlp=model_mlp.fit(train_x, train_y, epochs=100, batch_size=32, validation_data=(dev_x, dev_y), callbacks=callback)
"""
效果测试
"""
mlp_test_loss, mlp_test_acc = model_mlp.evaluate(test_x, test_y, verbose=2)
print('\nTest accuracy:', mlp_test_acc)
# Test accuracy: 0.8823"""
CNN版
"""
"""
基线模型
"""
model_cnn = Sequential()
model_cnn.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model_cnn.add(MaxPooling2D((2, 2)))
model_cnn.add(Flatten())
model_cnn.add(Dense(100, activation='relu'))
model_cnn.add(Dense(10, activation='softmax'))
model_cnn.compile(optimizer="adam", loss='categorical_crossentropy', metrics=['accuracy'])
"""
贝叶斯搜索超参数
"""
model = Sequential()model = Sequential()
model.add(Input(shape=(28, 28, 1)))for i in range(hp.Int('num_blocks', 1, 2)):hp_padding=hp.Choice('padding_'+ str(i), values=['valid', 'same'])hp_filters=hp.Choice('filters_'+ str(i), values=[32, 64])model.add(Conv2D(hp_filters, (3, 3), padding=hp_padding, activation='relu', kernel_initializer='he_uniform', input_shape=(28, 28, 1)))model.add(MaxPooling2D((2, 2)))model.add(Dropout(hp.Choice('dropout_'+ str(i), values=[0.0, 0.1, 0.2])))model.add(Flatten())hp_units = hp.Int('units', min_value=25, max_value=150, step=25)
model.add(Dense(hp_units, activation='relu', kernel_initializer='he_uniform'))model.add(Dense(10,activation="softmax"))hp_learning_rate = hp.Choice('learning_rate', values=[1e-2, 1e-3])
hp_optimizer=hp.Choice('Optimizer', values=['Adam', 'SGD'])if hp_optimizer == 'Adam':hp_learning_rate = hp.Choice('learning_rate', values=[1e-2, 1e-3])
elif hp_optimizer == 'SGD':hp_learning_rate = hp.Choice('learning_rate', values=[1e-2, 1e-3])nesterov=Truemomentum=0.9
model.compile( optimizer=hp_optimizer,loss='categorical_crossentropy', metrics=['accuracy'])tuner_cnn = kt.tuners.BayesianOptimization(model,objective='val_loss',max_trials=100,directory='.',project_name='tuning-cnn')
"""
采用最佳超参数训练模型
"""
model_cnn = Sequential()model_cnn.add(Input(shape=(28, 28, 1)))for i in range(best_cnn_hyperparameters['num_blocks']):hp_padding=best_cnn_hyperparameters['padding_'+ str(i)]hp_filters=best_cnn_hyperparameters['filters_'+ str(i)]model_cnn.add(Conv2D(hp_filters, (3, 3), padding=hp_padding, activation='relu', kernel_initializer='he_uniform', input_shape=(28, 28, 1)))model_cnn.add(MaxPooling2D((2, 2)))model_cnn.add(Dropout(best_cnn_hyperparameters['dropout_'+ str(i)]))model_cnn.add(Flatten())
model_cnn.add(Dense(best_cnn_hyperparameters['units'], activation='relu', kernel_initializer='he_uniform'))model_cnn.add(Dense(10,activation="softmax"))model_cnn.compile(optimizer=best_cnn_hyperparameters['Optimizer'], loss='categorical_crossentropy', metrics=['accuracy'])
print(model_cnn.summary())history_cnn= model_cnn.fit(train_x, train_y, epochs=50, batch_size=32, validation_data=(dev_x, dev_y), callbacks=callback)
cnn_test_loss, cnn_test_acc = model_cnn.evaluate(test_x, test_y, verbose=2)
print('\nTest accuracy:', cnn_test_acc)# Test accuracy: 0.92
超参数调优框架
- Optuna-深度学习-超参数优化
- nvidia nemo-大模型训练优化自动超参数搜索分析
- https://github.com/NVIDIA/NeMo-Framework-Launcher
Optuna深度学习超参数优化框架
import os
import optuna
import plotly
from optuna.trial import TrialState
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data
from torchvision import datasets
from torchvision import transforms
from optuna.visualization import plot_optimization_history
from optuna.visualization import plot_param_importances
from optuna.visualization import plot_slice
from optuna.visualization import plot_intermediate_values
from optuna.visualization import plot_parallel_coordinate# 下述代码指定了SGDClassifier分类器的参数:alpha、max_iter 的搜索空间、损失函数loss的搜索空间。
def objective(trial):iris = sklearn.datasets.load_iris()classes = list(set(iris.target))train_x, valid_x, train_y, valid_y = sklearn.model_selection.train_test_split(iris.data, iris.target, test_size=0.25, random_state=0)#指定参数搜索空间alpha = trial.suggest_loguniform('alpha', 1e-5, 1e-1)max_iter = trial.suggest_int('max_iter',64,192,step=64)loss = trial.suggest_categorical('loss',['hinge','log','perceptron'])clf = sklearn.linear_model.SGDClassifier(alpha=alpha,max_iter=max_iter)# 下述代码指定了学习率learning_rate、优化器optimizer、神经元个数n_uint 的搜索空间。
def objective(trial):params = {'learning_rate': trial.suggest_loguniform('learning_rate', 1e-5, 1e-1),'optimizer': trial.suggest_categorical("optimizer", ["Adam", "RMSprop", "SGD"]),'n_unit': trial.suggest_int("n_unit", 4, 18)}model = build_model(params)accuracy = train_and_evaluate(params, model)return accuracy# 记录超参数训练过程
def objective(trial):iris = sklearn.datasets.load_iris()classes = list(set(iris.target))train_x, valid_x, train_y, valid_y = sklearn.model_selection.train_test_split(iris.data, iris.target, test_size=0.25, random_state=0)alpha = trial.suggest_loguniform('alpha', 1e-5, 1e-1)max_iter = trial.suggest_int('max_iter',64,192,step=64)loss = trial.suggest_categorical('loss',['hinge','log','perceptron'])clf = sklearn.linear_model.SGDClassifier(alpha=alpha,max_iter=max_iter)for step in range(100):clf.partial_fit(train_x, train_y, classes=classes)intermediate_value = 1.0 - clf.score(valid_x, valid_y)trial.report(intermediate_value, step)if trial.should_prune():raise optuna.TrialPruned()return 1.0 - clf.score(valid_x, valid_y)# 创建优化过程
def objective(trial):iris = sklearn.datasets.load_iris()classes = list(set(iris.target))train_x, valid_x, train_y, valid_y = sklearn.model_selection.train_test_split(iris.data, iris.target, test_size=0.25, random_state=0)alpha = trial.suggest_loguniform('alpha', 1e-5, 1e-1)max_iter = trial.suggest_int('max_iter',64,192,step=64)loss = trial.suggest_categorical('loss',['hinge','log','perceptron'])clf = sklearn.linear_model.SGDClassifier(alpha=alpha,max_iter=max_iter)for step in range(100):clf.partial_fit(train_x, train_y, classes=classes)intermediate_value = 1.0 - clf.score(valid_x, valid_y)trial.report(intermediate_value, step)if trial.should_prune():raise optuna.TrialPruned()return 1.0 - clf.score(valid_x, valid_y)study = optuna.create_study(storage='path',study_name='first',pruner=optuna.pruners.MedianPruner())
#study = optuna.study.load_study('first','path')
study.optimize(objective, n_trials=20)
print("Study statistics: ")
print(" Number of finished trials: ", len(study.trials))
print(" Number of pruned trials: ", len(pruned_trials))
print(" Number of complete trials: ", len(complete_trials))
print("Best trial:")
trial = study.best_trial
print(" Value: ", trial.value)
print(" Params: ")
for key, value in trial.params.items():print("{}:{}".format(key, value))# 可视化搜索结果
optuna.visualization.plot_contour(study)#若不行,请尝试:
vis_path = r'result-vis/'
graph_cout = optuna.visualization.plot_contour(study,params=['n_layers','lr'])
plotly.offline.plot(graph_cout,filename=vis_path+'graph_cout.html')plot_optimization_history(study)#若不行,请尝试:
vis_path = r'result-vis/'
history = plot_optimization_history(study)
plotly.offline.plot(history,filename=vis_path+'history.html')plot_intermediate_values(study)#若不行,请尝试:
vis_path = r'result-vis/'
intermed = plot_intermediate_values(study)
plotly.offline.plot(intermed,filename=vis_path+'intermed.html')plot_slice(study, params=['alpha','max_iter','loss'])#若不行,请尝试:
vis_path = r'result-vis/'
slices = plot_slice(study)
plotly.offline.plot(slices,filename=vis_path+'slices.html')plot_parallel_coordinate(study,params=['alpha','max_iter','loss'])#若不行,请尝试:
vis_path = r'result-vis/'
paraller = plot_parallel_coordinate(study)
plotly.offline.plot(paraller,filename=vis_path+'paraller.html')
nvidia nemo大模型超参数优化框架
- 用户手册:nvidia nemo用户手册
相关文章:
)
超参数调优-通用深度学习篇(上)
文章目录 深度学习超参数调优网格搜索示例一:网格搜索回归模型超参数示例二:Keras网格搜索 随机搜索贝叶斯搜索 超参数调优框架Optuna深度学习超参数优化框架nvidia nemo大模型超参数优化框架 参数调整理论: 黑盒优化:超参数优化…...

小程序中data-xx是用方式
data-sts"3" 是微信小程序中的一种数据绑定语法,用于在 WXML(小程序模板)中将自定义的数据绑定到页面元素上。让我详细解释一下: data-xx 的作用: data-xx 允许你在页面元素上自定义属性,以便在事…...

【2024德国工作】外国人在德国找工作是什么体验?
挺难的,德语应该是所有中国人的难点。大部分中国人进德国公司要么是做中国业务相关,要么是做技术领域的工程师。先讲讲人在中国怎么找德国的工作,顺便延申下,德国工作的真实体验,最后聊聊在今年的德国工作签证申请条件…...

Unity中获取数据的方法
Input和GetComponent 一、Input 1、Input类: 用于处理用户输入(如键盘、鼠标、触摸等)的静态类 2、作用: 允许你检查用户的输入状态。如某个键是否被按下,鼠标的位置,触摸的坐标等 3、实例 (1) 键盘…...

Java的死锁问题
Java中的死锁问题是指两个或多个线程互相持有对方所需的资源,导致它们在等待对方释放资源时永久地阻塞的情况。 死锁产生条件 死锁发生通常需要满足以下四个必要条件: 互斥条件:至少有一个资源是只能被一个线程持有的,如果其他…...

Unity 公用函数整理【二】
1、在规定时间时间内将一个值变化到另一个值,使用Mathf.Lerp实现 private float timer;[Tooltip("当前温度")]private float curTemp;[Tooltip("开始温度")]private float startTemp 20;private float maxTemp 100;/// <summary>/// 升…...

千年古城的味蕾传奇-平凉锅盔
在甘肃平凉这片古老而神秘的土地上,有一种美食历经岁月的洗礼,依然散发着独特的魅力,那便是平凉锅盔。平凉锅盔,那可是甘肃平凉的一张美食名片。它外表金黄,厚实饱满,就像一轮散发着诱人香气的金黄月亮。甘…...
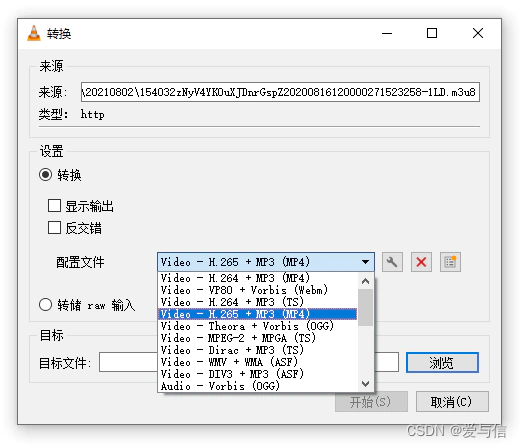
微信小程序视频如何下载
一、工具准备 1、抓包工具Fiddler Download Fiddler Web Debugging Tool for Free by Telerik 2、VLC media player Download official VLC media player for Windows - VideoLAN 3、微信PC端 微信 Windows 版 二、开始抓包 1、打开Fiddler工具,设置修改如下…...

SVN 安装教程
SVN 安装教程 SVN(Subversion)是一个开源的版本控制系统,广泛用于软件开发和文档管理。本文将详细介绍如何在不同的操作系统上安装SVN,包括Windows、macOS和Linux。 Windows系统上的SVN安装 1. 下载SVN 访问SVN官方网站或Visu…...

HTML静态网页成品作业(HTML+CSS)—— 家乡山西介绍网页(3个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,未使用Javacsript代码,共有6个页面。 二、作品演示 三、代…...
:定理6的补充证明及三道循环置换例题)
【抽代复习笔记】20-群(十四):定理6的补充证明及三道循环置换例题
例1:找出S3中所有不能和(123)交换的元。 解:因为 (123)(1) (1)(123) (123),(123)(132) (132)(123) (1),所以(1)、(132)和(123)均可以交换; 而(12)(123) (23),(123)(12) (13),故 (12)(12…...
【单片机毕业设计选题24018】-基于STM32和阿里云的农业大棚系统
系统功能: 系统分为手动和自动模式,上电默认为自动模式,自动模式下系统根据采集到的传感器值 自动控制,温度过低后自动开启加热,湿度过高后自动开启通风,光照过低后自动开启补 光,水位过低后自动开启水泵…...

【计算机毕业设计】206校园顺路代送微信小程序
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...

9、PHP 实现调整数组顺序使奇数位于偶数前面
题目: 调整数组顺序使奇数位于偶数前面 描述: 输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分, 所有的偶数位于位于数组的后半部分,并保证奇数和奇数ÿ…...
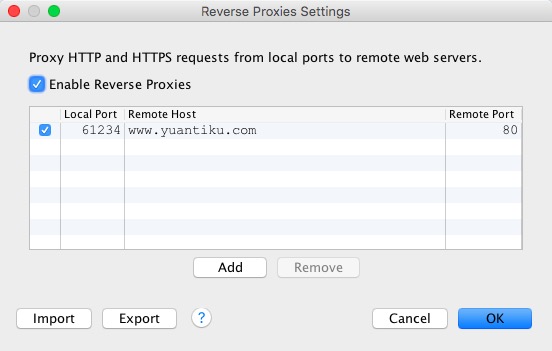
iOS开发工具-网络封包分析工具Charles
一、Charles简介 Charles 是在 Mac 下常用的网络封包截取工具,在做 移动开发时,我们为了调试与服务器端的网络通讯协议,常常需要截取网络封包来分析。 Charles 通过将自己设置成系统的网络访问代理服务器,使得所有的网络访问请求…...

7、PHP 实现矩形覆盖
题目: 矩形覆盖 描述: 我们可以用21的小矩形横着或者竖着去覆盖更大的矩形。 请问用n个21的小矩形无重叠地覆盖一个2*n的大矩形,总共有多少种方法? <?php function rectCover($number) {$prePreNum 1;$preNum 2;$temp 0;i…...
鸿蒙开发通信与连接:【@ohos.wifiext (WLAN)】
WLAN 说明: 本模块首批接口从API version 8开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。 该文档中的接口只供非通用类型产品使用,如路由器等,对于常规类型产品,不应该使用这些接口。 导入模块 …...

Ps:脚本事件管理器
Ps菜单:文件/脚本/脚本事件管理器 Scripts/Script Events Manager 脚本事件管理器 Script Events Manager允许用户将特定的事件(如打开、存储或导出文件)与 JavaScript 脚本或 Photoshop 动作关联起来,以便在这些事件发生时自动触…...

redis哨兵模式下业务代码连接实现
目录 一:背景 二:实现过程 三:总结 一:背景 在哨兵模式下,真实的redis服务地址由一个固定ip转变为可以变化的ip,这样我们业务代码在连接redis的时候,就需要判断哪个主redis服务地址,哪个是从…...
Java中将文件转换为Base64编码的字节码
在Java中,将文件转换为Base64编码的字节码通常涉及以下步骤: 读取文件内容到字节数组。使用java.util.Base64类对字节数组进行编码。 下面是一个简单的Java示例代码,演示如何实现这个过程: import java.io.File; import java.io…...

ESP32-S2物联网实战:IPv6配置与Adafruit IO双向通信
1. 项目概述与核心价值如果你手头有一块ESP32-S2开发板,并且已经厌倦了仅仅让它连上Wi-Fi、点个灯,想让它真正“活”起来,成为一个能融入现代互联网、能与云端自由对话的智能节点,那么这篇文章就是为你准备的。我们将深入两个在物…...

别再手动算位宽了!Vivado FIR IP核的位宽计算逻辑与配置避坑指南
Vivado FIR IP核位宽计算实战:从黑盒解析到精准配置 在FPGA数字信号处理领域,FIR滤波器作为基础构建模块,其性能表现直接影响整个系统的信号处理质量。而位宽配置这个看似简单的参数,往往成为项目后期调试阶段的"隐形杀手&qu…...

恶劣环境下LED发光服饰的可靠系统构建:从设计到工艺的工程实践
1. 项目概述与核心挑战如果你曾经尝试过制作一件会发光的服装,无论是为了音乐节、万圣节还是水下表演,你大概都体会过那种“亮一次,修三次”的挫败感。LED灯带在工作室的桌面上测试时完美无瑕,一旦穿到身上,开始活动、…...

如何3步获取百度网盘真实下载地址实现满速下载
如何3步获取百度网盘真实下载地址实现满速下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾被百度网盘的非会员下载速度困扰?当下载重要的工作文件、学…...

番茄小说下载器:打造属于你的个人数字图书馆终极指南
番茄小说下载器:打造属于你的个人数字图书馆终极指南 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾经遇到过这样的场景?深夜追更小说时网络突然断线&…...

PowerInfer:基于热点神经元预测的LLM高性能推理引擎部署指南
1. 项目概述:当推理速度成为AI落地的瓶颈最近在折腾本地大模型推理的朋友,估计都绕不开一个核心痛点:速度。模型效果再好,生成一句话要等上十几秒,那种“卡顿感”足以劝退绝大多数想把它集成到实际应用里的开发者。我自…...
)
保姆级教程:INCA 7.2.3 从新建工程到观测标定的完整流程(附A2L文件处理技巧)
INCA 7.2.3 全流程实战指南:从工程搭建到参数标定的深度解析 在汽车电子开发领域,标定工具链的掌握程度直接影响开发效率。作为行业标准的INCA软件,其7.2.3版本在工程管理、实时观测和参数标定方面提供了更完善的解决方案。本文将采用"操…...

构建轻量级应用沙盒:Microverse原理与实践指南
1. 项目概述:一个轻量级、可移植的“微宇宙”开发沙盒最近在折腾一些边缘计算和嵌入式AI应用的原型验证,经常遇到一个头疼的问题:开发环境和部署环境不一致。在本地笔记本上跑得好好的Python脚本,放到树莓派或者Jetson Nano上&…...

Simulink模型到汽车控制器:基于模型开发的完整路径
Simulink模型到汽车控制器:基于模型开发的完整路径 一辆智能电动汽车的"灵魂",通常写在300万行以上的嵌入式代码里。但如果每一行代码都要工程师手写,开发周期会从18个月变成……永远完成不了。 一个真实的问题 2023年,…...

氛围驱动开发:数据化提升开发者效率与团队协作的实践指南
1. 项目概述:当开发节奏遇上“氛围感”最近在GitHub上看到一个挺有意思的项目,叫“vibe-driven-dev”。光看名字,你可能会有点摸不着头脑——“氛围驱动开发”?这听起来不像是一个传统的技术框架或工具库。没错,它确实…...