使用Java实现哈夫曼编码
前言
哈夫曼编码是一种经典的无损数据压缩算法,它通过赋予出现频率较高的字符较短的编码,出现频率较低的字符较长的编码,从而实现压缩效果。这篇博客将详细讲解如何使用Java实现哈夫曼编码,包括哈夫曼编码的原理、具体实现步骤以及完整的代码示例。
哈夫曼编码原理
哈夫曼编码的基本原理可以概括为以下几个步骤:
- 统计字符频率:遍历输入数据,统计每个字符出现的频率。
- 构建哈夫曼树:根据字符的频率构建一棵哈夫曼树。树的每个节点代表一个字符及其频率,树的叶子节点代表具体的字符。
- 生成哈夫曼编码:通过遍历哈夫曼树生成每个字符的哈夫曼编码。左子树表示’0’,右子树表示’1’。
- 编码数据:将原始数据根据哈夫曼编码表转换为二进制数据。
- 解码数据:根据哈夫曼树将二进制数据还原为原始字符。
实现步骤
1. 定义哈夫曼树的节点类
首先定义一个内部类Node,用于表示哈夫曼树的节点。每个节点包含字符、频率、左子节点和右子节点。实现Comparable<Node>接口用于在优先队列中排序。
private static class Node implements Comparable<Node> {private final char ch; // 字符private final int freq; // 频率private final Node left, right; // 左右子节点Node(char ch, int freq, Node left, Node right) {this.ch = ch;this.freq = freq;this.left = left;this.right = right;}// 判断是否为叶子节点private boolean isLeaf() {assert ((left == null) && (right == null)) || ((left != null) && (right != null));return (left == null) && (right == null);}// 根据频率比较节点,用于优先队列public int compareTo(Node that) {return this.freq - that.freq;}
}
2. 构建哈夫曼树
根据字符频率构建哈夫曼树。我们使用优先队列来实现该步骤。
private static Node buildTrie(int[] freq) {// 初始化优先队列,并将每个字符及其频率作为单节点树插入队列MinPQ<Node> pq = new MinPQ<Node>();for (char c = 0; c < R; c++)if (freq[c] > 0)pq.insert(new Node(c, freq[c], null, null));// 不断合并频率最小的两棵树,直到剩下一棵树while (pq.size() > 1) {Node left = pq.delMin();Node right = pq.delMin();Node parent = new Node('\0', left.freq + right.freq, left, right);pq.insert(parent);}return pq.delMin();
}
3. 生成哈夫曼编码表
通过遍历哈夫曼树生成每个字符的哈夫曼编码。
private static void buildCode(String[] st, Node x, String s) {if (!x.isLeaf()) {// 递归遍历左子树,路径加'0'buildCode(st, x.left, s + '0');// 递归遍历右子树,路径加'1'buildCode(st, x.right, s + '1');} else {// 叶子节点,记录字符的编码st[x.ch] = s;}
}
4. 压缩数据
读取输入数据,生成哈夫曼编码表,输出编码后的二进制数据。
public static void compress() {// 读取输入字符串并转换为字符数组String s = BinaryStdIn.readString();char[] input = s.toCharArray();// 计算每个字符的频率int[] freq = new int[R];for (int i = 0; i < input.length; i++)freq[input[i]]++;// 构建哈夫曼树Node root = buildTrie(freq);// 建立字符编码表String[] st = new String[R];buildCode(st, root, "");// 输出哈夫曼树以便解码使用writeTrie(root);// 输出原始未压缩的字节数BinaryStdOut.write(input.length);// 使用哈夫曼编码压缩输入for (int i = 0; i < input.length; i++) {String code = st[input[i]];for (int j = 0; j < code.length(); j++) {if (code.charAt(j) == '0') {BinaryStdOut.write(false);} else if (code.charAt(j) == '1') {BinaryStdOut.write(true);} else throw new IllegalStateException("Illegal state");}}// 关闭输出流BinaryStdOut.close();
}
5. 解码数据
读取哈夫曼树和编码后的二进制数据,解码还原原始数据。
public static void expand() {// 从输入流中读取哈夫曼树Node root = readTrie();// 读取原始字节数int length = BinaryStdIn.readInt();// 使用哈夫曼树解码输入的二进制数据并输出字符for (int i = 0; i < length; i++) {Node x = root;while (!x.isLeaf()) {boolean bit = BinaryStdIn.readBoolean();if (bit) x = x.right;else x = x.left;}BinaryStdOut.write(x.ch, 8);}BinaryStdOut.close();
}
完整代码
以下是完整的哈夫曼编码实现代码:
public class Huffman {// 定义扩展ASCII字符集的大小private static final int R = 256;// 防止实例化private Huffman() { }// 哈夫曼树的节点类,实现了Comparable接口以便于优先队列排序private static class Node implements Comparable<Node> {private final char ch; // 字符private final int freq; // 频率private final Node left, right; // 左右子节点Node(char ch, int freq, Node left, Node right) {this.ch = ch;this.freq = freq;this.left = left;this.right = right;}// 判断是否为叶子节点private boolean isLeaf() {assert ((left == null) && (right == null)) || ((left != null) && (right != null));return (left == null) && (right == null);}// 根据频率比较节点,用于优先队列public int compareTo(Node that) {return this.freq - that.freq;}}// 压缩方法public static void compress() {// 读取输入字符串并转换为字符数组String s = BinaryStdIn.readString();char[] input = s.toCharArray();// 计算每个字符的频率int[] freq = new int[R];for (int i = 0; i < input.length; i++)freq[input[i]]++;// 构建哈夫曼树Node root = buildTrie(freq);// 建立字符编码表String[] st = new String[R];buildCode(st, root, "");// 输出哈夫曼树以便解码使用writeTrie(root);// 输出原始未压缩的字节数BinaryStdOut.write(input.length);// 使用哈夫曼编码压缩输入for (int i = 0; i < input.length; i++) {String code = st[input[i]];for (int j = 0; j < code.length(); j++) {if (code.charAt(j) == '0') {BinaryStdOut.write(false);} else if (code.charAt(j) == '1') {BinaryStdOut.write(true);} else throw new IllegalStateException("Illegal state");}}// 关闭输出流BinaryStdOut.close();}// 构建哈夫曼树private static Node buildTrie(int[] freq) {// 初始化优先队列,并将每个字符及其频率作为单节点树插入队列MinPQ<Node> pq = new MinPQ<Node>();for (char c = 0; c < R; c++)if (freq[c] > 0)pq.insert(new Node(c, freq[c], null, null));// 不断合并频率最小的两棵树,直到剩下一棵树while (pq.size() > 1) {Node left = pq.delMin();Node right = pq.delMin();Node parent = new Node('\0', left.freq + right.freq, left, right);pq.insert(parent);}return pq.delMin();}// 输出哈夫曼树,用于解码private static void writeTrie(Node x) {if (x.isLeaf()) {BinaryStdOut.write(true);BinaryStdOut.write(x.ch, 8);return;}BinaryStdOut.write(false);writeTrie(x.left);writeTrie(x.right);}// 生成哈夫曼编码表private static void buildCode(String[] st, Node x, String s) {if (!x.isLeaf()) {// 递归遍历左子树,路径加'0'buildCode(st, x.left, s + '0');// 递归遍历右子树,路径加'1'buildCode(st, x.right, s + '1');} else {// 叶子节点,记录字符的编码st[x.ch] = s;}}// 解码方法public static void expand() {// 从输入流中读取哈夫曼树Node root = readTrie();// 读取原始字节数int length = BinaryStdIn.readInt();// 使用哈夫曼树解码输入的二进制数据并输出字符for (int i = 0; i < length; i++) {Node x = root;while (!x.isLeaf()) {boolean bit = BinaryStdIn.readBoolean();if (bit) x = x.right;else x = x.left;}BinaryStdOut.write(x.ch, 8);}BinaryStdOut.close();}// 从输入流中读取哈夫曼树private static Node readTrie() {boolean isLeaf = BinaryStdIn.readBoolean();if (isLeaf) {return new Node(BinaryStdIn.readChar(), -1, null, null);} else {return new Node('\0', -1, readTrie(), readTrie());}}// 主方法,根据参数决定执行压缩或解码public static void main(String[] args) {if (args[0].equals("-")) compress();else if (args[0].equals("+")) expand();else throw new IllegalArgumentException("Illegal command line argument");}
}
总结
哈夫曼编码是一种高效的无损数据压缩算法。本文通过详细的代码示例展示了如何使用Java实现哈夫曼编码的压缩和解压功能。从统计字符频率、构建哈夫曼树、生成哈夫曼编码表到最终的编码和解码,涵盖了哈夫曼编码的全部核心步骤。希望这篇博客能够帮助你更好地理解哈夫曼编码的实现原理和具体的编码实践。
相关文章:

使用Java实现哈夫曼编码
前言 哈夫曼编码是一种经典的无损数据压缩算法,它通过赋予出现频率较高的字符较短的编码,出现频率较低的字符较长的编码,从而实现压缩效果。这篇博客将详细讲解如何使用Java实现哈夫曼编码,包括哈夫曼编码的原理、具体实现步骤以…...
IDEA、PyCharm等基于IntelliJ平台的IDE汉化方式
PyCharm 或者 IDEA 等编辑器是比较常用的,默认是英文界面,有些同学用着不方便,想要汉化版本的,但官方没有这个设置项,不过可以通过插件的方式进行设置。 方式1:插件安装 1、打开设置 File->Settings&a…...
visual studio 创建c++项目
目录 环境准备:安装 visual studiovisual studio 创建c项目Tips:新建cpp文件注释与取消注释代码 其他初学者使用Visual Studio开发C和C时常遇到的3个坑 环境准备:安装 visual studio 官网:https://visualstudio.microsoft.com/zh…...

MGV电源维修KUKA机器人电源模块PH2003-4840
MGV电源维修 库卡电源模块维修 机器人电源模块维修 库卡控制器维修 KUKA电源维修 库卡机器人KUKA主机维修 KUKA驱动器模块维修 机械行业维修:西门子系统、法那克系统、沙迪克、FIDIA、天田、阿玛达、友嘉、大宇系统;数控冲床、剪板机、折弯机等品牌数控…...
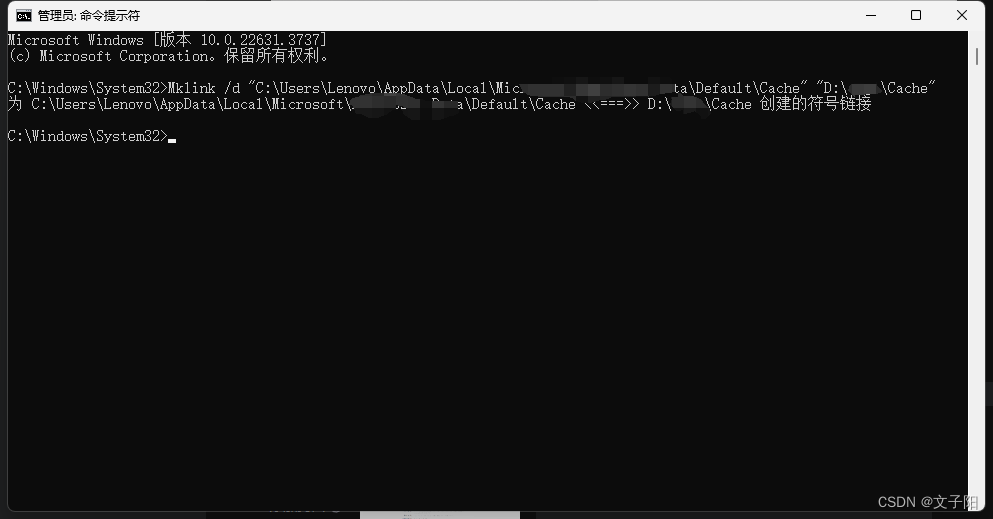
设置浏览器互不干扰
目录 一、查看浏览器文件路径 二、 其他盘新建文件夹Cache 三、以管理员运行CMD 四、执行命令 一、查看浏览器文件路径 chrome://version/ 二、 其他盘新建文件夹Cache D:\chrome\Cache 三、以管理员运行CMD 四、执行命令 Mklink /d "C:\Users\Lenovo\AppData\Loca…...

kafka操作命令详解
目录 1、集群运维命令 1.1、集群启停命令 1.3、集群迁移命令 1.4、权限管理命令 1.4.1、权限参数介绍 1.4.2、增加权限命令 1.4.3、移出权限命令 1.4.4、查看所有topic权限命令 1.4.5、查看某个topic权限命令 2、生产者命令 2.1、创建topic命令 2.2、删除topic命令 …...
graalvm jdk和openjdk
下载地址:https://github.com/graalvm/graalvm-ce-builds/releases 官网: https://www.graalvm.org...

docker基础使用教程
1.准备工作 例子:工程在docker_test 生成requirements.txt文件命令:(使用参考链接2) pip list --formatfreeze > requirements.txt 参考链接1: 安装pipreqs可能比较困难 python 项目自动生成环境配置文件require…...

计算机网络 交换机的安全配置
一、理论知识 1.交换机端口安全功能介绍 交换机端口安全功能是针对交换机端口进行安全属性的配置,以控制用户的安全接入。主要包括以下两种配置项: ①限制交换机端口的最大连接数:控制交换机端口连接的主机数量;防止用户进行恶…...
深入解析大语言模型系列:Transformer架构的原理与应用
引言 在自然语言处理(NLP)领域,大语言模型(Large Language Models, LLMs)近几年取得了突破性的进展,而 Transformer 作为这些模型的核心架构,功不可没。本文将详细介绍 Transformer 的原理、结…...

uni-app地图组件控制
uni.createMapContext(mapId,this) 创建并返回 map 上下文 mapContext 对象。在自定义组件下,第二个参数传入组件实例this,以操作组件内 <map> 组件。 注意:uni.createMapContext(mapId, this) app-nvue 平台 2.2.5 支持 uni.create…...

前端调用api发请求常用的请求头content- type的类型和常用场景
Content-Type 是一个非常重要的HTTP头,它定义了发送给服务器或客户端的数据的MIME类型。这对于服务器和客户端正确解析和处理数据至关重要。下面是一些常见的 Content-Type 值及其用途和区别。 常见的 Content-Type 值 text/plain • 用途: 纯文本,无格…...

数据仓库之SparkSQL
Apache Spark SQL是Spark中的一个组件,专门用于结构化数据处理。它提供了通过SQL和DataFrame API来执行结构化数据查询的功能。以下是对Spark SQL的详细介绍: 核心概念 DataFrame: 定义: DataFrame是一个分布式数据集合,类似于关系型数据库中…...

如何在 MySQL 中导入和导出数据库以及重置 root 密码
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 如何导入和导出数据库 导出 要导出数据库,打开终端,确保你没有登录到 MySQL 中,然后输入以下命令&…...

基于uni-app和图鸟UI的云课堂小程序开发实践
摘要: 随着移动互联网的快速发展,移动学习已成为教育领域的重要趋势。本文介绍了基于uni-app和图鸟UI框架开发的云课堂小程序,该小程序实现了移动教学、移动学习、移动阅读和移动社交的完美结合,为用户提供了一个便捷、高效的学习…...

解决python从TD数据库取50w以上大量数据慢的问题
1.问题背景描述 python项目中的时序数据都存放在TD数据库中,数据是秒级存入的,当查询一周数据时将超过50w数据量,这是一次性获取全量数据到python程序很慢,全流程10秒以上,希望进行优化加速 2.排查 首先,…...

游戏心理学Day21
玩家情绪与暴力攻击 情绪 情绪的分类 情绪是一种经常波动的东西,我们既体验过骄傲激动和开心,也体验过羞怯内疚和沮丧。我们的感受高度依赖于情境。研究者区分出至少三种途径来考察作为一种相对固定的人格特征的情绪,即为情感性࿰…...
接口测试基础 --- 什么是接口测试及其测试流程?
接口测试是软件测试中的一个重要部分,它主要用于验证和评估不同软件组件之间的通信和交互。接口测试的目标是确保不同的系统、模块或组件能够相互连接并正常工作。 接口测试流程可以分为以下几个步骤: 1.需求分析:首先,需要仔细…...

贪心+动归1
跳跃游戏 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则࿰…...
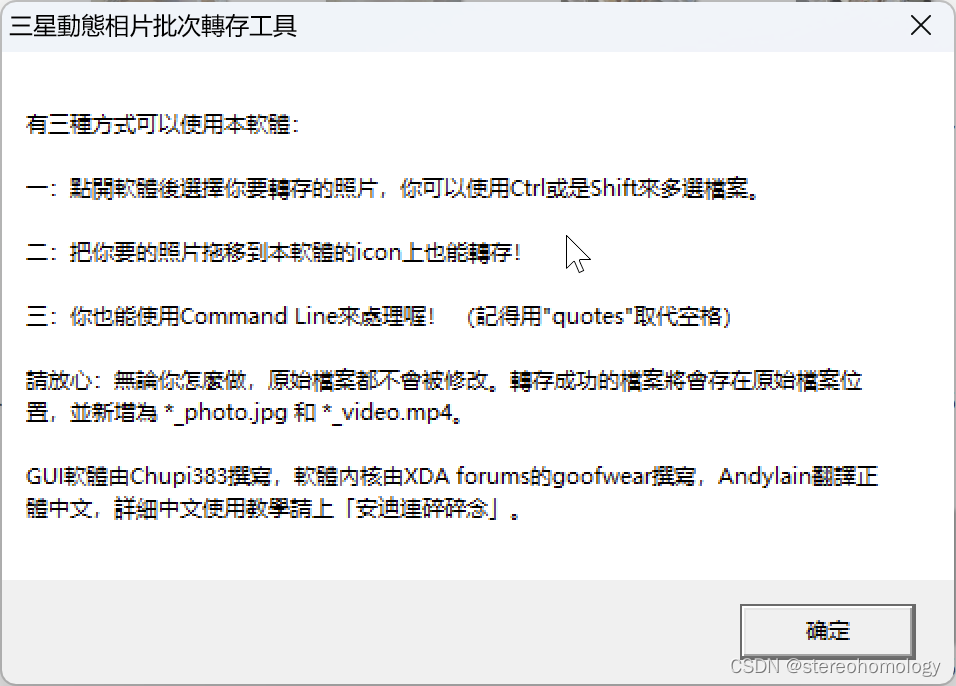
三星S20以上手机中的动态相片及其分解
三星S20以后的相机,相机拍出来的图片,用三星手机自带的“相册”打开之后,还会有“查看动态照片”的选项,点击之后就能查看拍照片时前后2秒左右的视频! 不知道这个功能是不是三星独有的。 这样得到的图片非常大。因为…...

3步轻松掌握:163MusicLyrics歌词下载完全指南
3步轻松掌握:163MusicLyrics歌词下载完全指南 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为找不到高质量的LRC歌词而烦恼吗?163MusicLyri…...

AutoCut终极指南:如何用文本编辑器快速剪辑100个视频
AutoCut终极指南:如何用文本编辑器快速剪辑100个视频 【免费下载链接】autocut 用文本编辑器剪视频 项目地址: https://gitcode.com/GitHub_Trending/au/autocut 还在为手动剪辑视频而烦恼吗?AutoCut项目让你告别复杂的视频编辑软件,通…...

3个高效方法:免费获取百度网盘高速下载直链的完整指南
3个高效方法:免费获取百度网盘高速下载直链的完整指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 当我们面对百度网盘缓慢的下载速度时,常常感到无…...

激光切割外壳设计全流程:从创客工具到产品级制造的实战指南
1. 项目概述:为什么选择激光切割来做外壳?如果你和我一样,捣鼓过不少电子项目,从简单的Arduino温湿度计到复杂的树莓派家庭服务器,那你一定为“给它们找个家”这件事头疼过。3D打印太慢,开模注塑成本又高得…...
)
【Midjourney数字艺术风格终极指南】:20年AI视觉专家亲授7大核心风格参数调优法则(含V6.1新增Realism Mode实测数据)
更多请点击: https://intelliparadigm.com 第一章:Midjourney数字艺术风格演进与V6.1核心变革 Midjourney自V1发布以来,其图像生成范式经历了从纹理模拟到语义理解、从风格模仿到跨模态协同的深层跃迁。V6.1标志着模型首次在原生架构中集成…...

Python Reddit数据采集与分析实战:从API调用到舆情监控
1. 项目概述与核心价值最近在开源社区里,一个名为openshrug/reddit-intel的项目引起了我的注意。乍一看,这像是一个针对 Reddit 平台的数据抓取或分析工具,但深入探究后,我发现它的定位远不止于此。它更像是一个为开发者、数据分析…...

成本优化策略:降低云资源支出
成本优化策略:降低云资源支出 一、成本优化策略概述 1.1 成本优化策略的定义 成本优化策略是指通过各种技术和管理手段,降低云资源支出的策略和方法。它包括资源优化、成本监控、预算管理和采购策略等方面。 1.2 成本优化策略的价值 成本降低:…...

MCP服务器自动发现与管理工具mcpfinder详解
1. 项目概述:一个用于发现与管理MCP服务器的工具如果你正在构建或使用基于模型上下文协议(Model Context Protocol, 简称MCP)的应用,那么你很可能遇到过这样的困扰:手头有几个不同功能的MCP服务器ÿ…...

基于WLED分段功能与激光切割的多层智能艺术灯板制作全攻略
1. 项目概述与核心价值如果你和我一样,对那种能随着音乐呼吸、或者能独立变换不同区域色彩的智能灯光装置着迷,那么你一定会喜欢这个项目。它远不止是把LED灯条粘在板子后面那么简单,而是将激光切割的精密工艺、分层的艺术设计,与…...

嵌入式事件驱动框架Curtroller:模块化设计提升开发效率
1. 项目概述与核心价值最近在嵌入式开发社区里,一个名为“Curtroller”的项目引起了我的注意。这个项目由开发者KenWuqianghao在GitHub上开源,名字本身就是一个巧妙的组合——“Curt”(可能是“Current”电流的缩写或“Control”控制的变体&a…...