数据仓库之SparkSQL
Apache Spark SQL是Spark中的一个组件,专门用于结构化数据处理。它提供了通过SQL和DataFrame API来执行结构化数据查询的功能。以下是对Spark SQL的详细介绍:
核心概念
-
DataFrame:
- 定义: DataFrame是一个分布式数据集合,类似于关系型数据库中的表。它是以命名列的形式组织数据的。
- 特性: DataFrame API是高层次的API,支持复杂查询、聚合和数据操作。
-
Dataset:
- 定义: Dataset是强类型的DataFrame,结合了RDD的强类型和DataFrame的优化查询计划特性。
- 特性: Dataset API提供编译时类型安全,支持Java和Scala。
-
SQLContext:
- 定义: SQLContext是Spark SQL的入口点,用于创建DataFrame和执行SQL查询。
- 特性: 通过SQLContext,用户可以从不同的数据源(如JSON、Parquet、Hive等)读取数据,并执行SQL查询。
-
SparkSession:
- 定义: SparkSession是SQLContext和HiveContext的统一入口点,是从Spark 2.0开始引入的。
- 特性: SparkSession不仅支持SQL查询,还支持DataFrame和Dataset API。
主要功能
-
SQL查询:
- Spark SQL允许用户使用标准的SQL语法查询结构化数据。可以使用
sql()方法执行SQL查询,并返回DataFrame。
val spark = SparkSession.builder.appName("SparkSQLExample").getOrCreate() val df = spark.sql("SELECT * FROM tableName") - Spark SQL允许用户使用标准的SQL语法查询结构化数据。可以使用
-
数据源支持:
- Spark SQL支持多种数据源,包括JSON、Parquet、ORC、Avro、CSV、JDBC、Hive等。
val df = spark.read.json("path/to/json/file") val df = spark.read.format("parquet").load("path/to/parquet/file") -
Schema推断和操作:
- Spark SQL能够自动推断结构化数据的schema,也允许用户自定义schema。
val df = spark.read.json("path/to/json/file") df.printSchema() -
UDAF和UDF:
- 用户定义聚合函数(UDAF)和用户定义函数(UDF)可以扩展Spark SQL的功能。
spark.udf.register("myUDF", (x: Int) => x * x) val df = spark.sql("SELECT myUDF(columnName) FROM tableName") -
与Hive的集成:
- Spark SQL可以与Apache Hive无缝集成,读取和写入Hive表,并使用Hive的元数据。
spark.sql("CREATE TABLE IF NOT EXISTS my_table (key INT, value STRING)") spark.sql("LOAD DATA LOCAL INPATH 'path/to/file' INTO TABLE my_table") -
Catalyst优化器:
- Catalyst是Spark SQL的查询优化器,提供了一系列优化规则,使查询执行更高效。
性能优化
-
Tungsten执行引擎:
- Tungsten是Spark SQL的底层执行引擎,提供了内存管理、缓存和代码生成等优化技术,以提高执行效率。
-
查询缓存:
- Spark SQL支持缓存表和DataFrame,以加快重复查询的执行速度。
val df = spark.sql("SELECT * FROM tableName") df.cache() df.count() -
广播变量:
- 对于小数据集,可以使用广播变量将数据分发到所有节点,从而减少数据传输开销。
val smallDf = spark.read.json("path/to/small/json/file") val broadcastVar = spark.sparkContext.broadcast(smallDf.collectAsList())
应用场景
- 批处理: 通过Spark SQL处理大规模结构化数据,执行复杂的批处理任务。
- 交互式查询: 使用Spark SQL进行实时交互式数据查询和分析。
- ETL: 使用Spark SQL进行数据抽取、转换和加载(ETL)操作。
- 数据仓库: Spark SQL可以用于搭建现代化的数据仓库,支持大数据量下的高效查询和分析。
示例代码
import org.apache.spark.sql.SparkSession// 创建SparkSession
val spark = SparkSession.builder.appName("SparkSQLExample").getOrCreate()// 读取JSON数据
val df = spark.read.json("path/to/json/file")// 创建临时视图
df.createOrReplaceTempView("people")// 执行SQL查询
val sqlDF = spark.sql("SELECT name, age FROM people WHERE age > 21")// 展示结果
sqlDF.show()// 停止SparkSession
spark.stop()
结论
Spark SQL通过提供简洁且强大的API,使结构化数据处理变得更加高效和方便。它支持多种数据源和查询优化技术,能够满足大规模数据分析的需求。通过与其他Spark组件的无缝集成,Spark SQL成为构建现代数据处理和分析平台的有力工具。
相关推荐:
大数据平台之Spark-CSDN博客
数据仓库之Hive-CSDN博客
相关文章:

数据仓库之SparkSQL
Apache Spark SQL是Spark中的一个组件,专门用于结构化数据处理。它提供了通过SQL和DataFrame API来执行结构化数据查询的功能。以下是对Spark SQL的详细介绍: 核心概念 DataFrame: 定义: DataFrame是一个分布式数据集合,类似于关系型数据库中…...

如何在 MySQL 中导入和导出数据库以及重置 root 密码
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 如何导入和导出数据库 导出 要导出数据库,打开终端,确保你没有登录到 MySQL 中,然后输入以下命令&…...

基于uni-app和图鸟UI的云课堂小程序开发实践
摘要: 随着移动互联网的快速发展,移动学习已成为教育领域的重要趋势。本文介绍了基于uni-app和图鸟UI框架开发的云课堂小程序,该小程序实现了移动教学、移动学习、移动阅读和移动社交的完美结合,为用户提供了一个便捷、高效的学习…...

解决python从TD数据库取50w以上大量数据慢的问题
1.问题背景描述 python项目中的时序数据都存放在TD数据库中,数据是秒级存入的,当查询一周数据时将超过50w数据量,这是一次性获取全量数据到python程序很慢,全流程10秒以上,希望进行优化加速 2.排查 首先,…...

游戏心理学Day21
玩家情绪与暴力攻击 情绪 情绪的分类 情绪是一种经常波动的东西,我们既体验过骄傲激动和开心,也体验过羞怯内疚和沮丧。我们的感受高度依赖于情境。研究者区分出至少三种途径来考察作为一种相对固定的人格特征的情绪,即为情感性࿰…...
接口测试基础 --- 什么是接口测试及其测试流程?
接口测试是软件测试中的一个重要部分,它主要用于验证和评估不同软件组件之间的通信和交互。接口测试的目标是确保不同的系统、模块或组件能够相互连接并正常工作。 接口测试流程可以分为以下几个步骤: 1.需求分析:首先,需要仔细…...

贪心+动归1
跳跃游戏 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则࿰…...
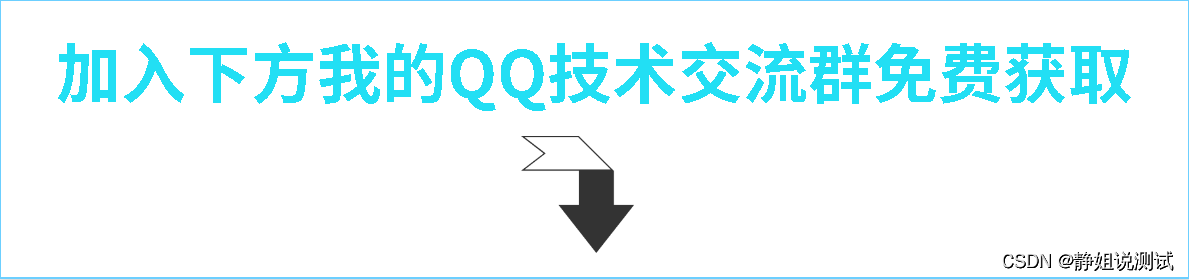
三星S20以上手机中的动态相片及其分解
三星S20以后的相机,相机拍出来的图片,用三星手机自带的“相册”打开之后,还会有“查看动态照片”的选项,点击之后就能查看拍照片时前后2秒左右的视频! 不知道这个功能是不是三星独有的。 这样得到的图片非常大。因为…...

一文了解HarmonyOSNEXT发布重点内容
华为在2024年6月21日的开发者大会上正式发布了HarmonyOS NEXT版,这是华为在操作系统领域的一次重大飞跃,标志着华为在构建全场景智能生态方面的卓越成就。HarmonyOS NEXT版不仅带来了全新的系统架构和性能提升,还首次将AI能力融入系统&#x…...

矩阵中严格递增的单元格数
题目链接:leetcode:矩阵中严格递增的单元格数 描述 给你一个下标从 1 开始、大小为 m x n 的整数矩阵 mat,你可以选择任一单元格作为 起始单元格 。 从起始单元格出发,你可以移动到 同一行或同一列 中的任何其他单元格,但前提是目…...
)
超参数调优-通用深度学习篇(上)
文章目录 深度学习超参数调优网格搜索示例一:网格搜索回归模型超参数示例二:Keras网格搜索 随机搜索贝叶斯搜索 超参数调优框架Optuna深度学习超参数优化框架nvidia nemo大模型超参数优化框架 参数调整理论: 黑盒优化:超参数优化…...

小程序中data-xx是用方式
data-sts"3" 是微信小程序中的一种数据绑定语法,用于在 WXML(小程序模板)中将自定义的数据绑定到页面元素上。让我详细解释一下: data-xx 的作用: data-xx 允许你在页面元素上自定义属性,以便在事…...

【2024德国工作】外国人在德国找工作是什么体验?
挺难的,德语应该是所有中国人的难点。大部分中国人进德国公司要么是做中国业务相关,要么是做技术领域的工程师。先讲讲人在中国怎么找德国的工作,顺便延申下,德国工作的真实体验,最后聊聊在今年的德国工作签证申请条件…...

Unity中获取数据的方法
Input和GetComponent 一、Input 1、Input类: 用于处理用户输入(如键盘、鼠标、触摸等)的静态类 2、作用: 允许你检查用户的输入状态。如某个键是否被按下,鼠标的位置,触摸的坐标等 3、实例 (1) 键盘…...

Java的死锁问题
Java中的死锁问题是指两个或多个线程互相持有对方所需的资源,导致它们在等待对方释放资源时永久地阻塞的情况。 死锁产生条件 死锁发生通常需要满足以下四个必要条件: 互斥条件:至少有一个资源是只能被一个线程持有的,如果其他…...

Unity 公用函数整理【二】
1、在规定时间时间内将一个值变化到另一个值,使用Mathf.Lerp实现 private float timer;[Tooltip("当前温度")]private float curTemp;[Tooltip("开始温度")]private float startTemp 20;private float maxTemp 100;/// <summary>/// 升…...

千年古城的味蕾传奇-平凉锅盔
在甘肃平凉这片古老而神秘的土地上,有一种美食历经岁月的洗礼,依然散发着独特的魅力,那便是平凉锅盔。平凉锅盔,那可是甘肃平凉的一张美食名片。它外表金黄,厚实饱满,就像一轮散发着诱人香气的金黄月亮。甘…...
微信小程序视频如何下载
一、工具准备 1、抓包工具Fiddler Download Fiddler Web Debugging Tool for Free by Telerik 2、VLC media player Download official VLC media player for Windows - VideoLAN 3、微信PC端 微信 Windows 版 二、开始抓包 1、打开Fiddler工具,设置修改如下…...

SVN 安装教程
SVN 安装教程 SVN(Subversion)是一个开源的版本控制系统,广泛用于软件开发和文档管理。本文将详细介绍如何在不同的操作系统上安装SVN,包括Windows、macOS和Linux。 Windows系统上的SVN安装 1. 下载SVN 访问SVN官方网站或Visu…...

HTML静态网页成品作业(HTML+CSS)—— 家乡山西介绍网页(3个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,未使用Javacsript代码,共有6个页面。 二、作品演示 三、代…...

CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战
CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战 车牌识别系统中,数据预处理的质量直接影响模型性能。CCPD作为目前最全面的中文车牌数据集,其四点标注特性为透视变换提供了基础,但也暗藏诸多陷阱。本文将手把手带您穿…...

Kubernetes部署Valheim游戏服务器:云原生架构实践指南
1. 项目概述:当维京英灵殿遇上Kubernetes如果你和我一样,既沉迷于《英灵神殿》(Valheim)里那种与三五好友一起伐木、采矿、建造长屋,然后被巨魔追得满地图跑的原始乐趣,又恰好是一名整天和容器、编排系统打…...

高考解析几何“秒杀”技巧:用极点极线快速搞定椭圆定点定值难题
高考解析几何“秒杀”技巧:用极点极线快速搞定椭圆定点定值难题 解析几何作为高考数学的压轴题型,常常让考生望而生畏。面对复杂的计算和抽象的条件,如何在有限时间内快速找到突破口?极点极线理论作为高等几何中的重要工具&#x…...

SyntaxUI:基于原子设计与Web组件的现代UI库开发实践
1. 项目概述:一个为开发者而生的现代UI组件库 如果你是一名前端开发者,或者正在构建一个需要用户界面的应用,那么你肯定经历过这样的场景:为了一个按钮的样式、一个表格的交互,或者一个模态框的动画,反复在…...

LVGL在无显存TFT屏上的驱动适配:双缓冲与DMA优化实践
1. 项目概述:当TFT屏幕遇上LVGL最近在做一个嵌入式GUI项目,核心任务是把LVGL这个轻量级图形库,适配到一块分辨率不算高但接口比较“个性”的TFT屏幕上。这活儿听起来像是把标准插头插到非标插座上,得自己动手改改线序。LVGL这几年…...

Copaw_dev:AI编程助手增强框架,提升代码生成与自动化开发效率
1. 项目概述:Copaw_dev 是什么,以及它为何值得关注如果你是一名开发者,尤其是对自动化、代码生成或者AI辅助编程感兴趣,那么“Copaw_dev”这个项目标题很可能已经引起了你的注意。乍一看,这个由“G-Divine”维护的项目…...

Apache Burr:用状态机模式构建Python流式应用
1. 项目概述:一个用于构建流式应用的Python框架最近在折腾一些实时数据处理和模型推理的项目,从简单的日志分析到复杂的在线推荐,总感觉现有的工具链要么太重,要么太散。想要一个既能处理流式数据,又能轻松集成机器学习…...

mg3640s,ts8080,ts8100,g5080,g3800,g4800,ix6780,ts8180报错5B00,P07,E08,5b02,1704,1700,5b04佳能V6.200,亲测有用
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...

Arm Cortex-A35 Cycle Model技术解析与SoC集成实战
1. Arm Cortex-A35 Cycle Model技术解析在SoC设计领域,虚拟平台验证已成为不可或缺的关键环节。作为Armv8-A架构中的能效比优化核心,Cortex-A35处理器通过Cycle Model提供了RTL级精度的硬件行为模拟能力。我在多个车载SoC项目中验证发现,其Cy…...

从零解析开源API网关fiGate:架构设计与生产实践
1. 项目概述:从零解析一个开源API网关最近在梳理团队内部微服务治理方案时,我又重新审视了市面上各类API网关的实现。除了大家耳熟能详的Kong、APISIX、Tyk这些“明星产品”,其实在GitHub的海洋里,还藏着不少设计精巧、思路独特的…...