AI学习指南机器学习篇-KNN的优缺点
AI学习指南机器学习篇-KNN的优缺点
在机器学习领域中,K最近邻(K-Nearest Neighbors,KNN)算法是一种十分常见的分类和回归方法之一。它的原理简单易懂,但在实际应用中也存在一些优缺点。本文将重点探讨KNN算法的优缺点,并结合具体示例来说明KNN算法在处理异常值敏感、计算复杂度高等方面的问题。
KNN算法简介
KNN算法是一种基于实例的学习方法,它利用已知类别标记的训练数据集,在分类时根据输入的待分类数据的特征,通过计算它与训练集中每个样本的距离,选取K个距离最近的样本作为邻居,然后通过投票法来决定待分类数据的类别。在回归问题中,KNN算法则是取K个最近邻居的平均值来进行预测。
KNN算法的优点
KNN算法具有以下优点:
1. 理论简单,易于理解和实现
KNN算法的原理非常简单直观,不需要进行模型训练,因此易于理解和实现。这使得KNN成为了众多机器学习算法中的入门级算法。
2. 适用于多分类问题
KNN算法在处理多分类问题时表现较为出色,因为它可以直接利用训练样本中的信息进行分类。
3. 适用于非线性数据
KNN算法对于非线性数据具有较强的分类能力,可以在较为复杂的数据集上取得较好的分类效果。
KNN算法的缺点
然而,KNN算法也存在一些较为明显的缺点:
1. 对异常值敏感
KNN算法是一种基于距离的方法,在距离计算时对异常值非常敏感。这意味着如果训练集中存在一些离群点(异常值),它们可能会对KNN算法的分类结果产生较大的影响。
为了更好地说明这一点,我们可以通过一个具体的示例来进行说明。假设我们有一个二维的数据集,其中大部分点聚集在一个区域内,但有一些极端的点则远离了其他点。如果我们使用KNN算法对这个数据集进行分类,那么这些离群点可能会影响KNN算法的分类结果,使得KNN算法倾向于将新样本分到与离群点相对应的类别中。
2. 计算复杂度高
另一个值得关注的问题是KNN算法的计算复杂度较高。因为在分类时需要计算待分类样本与训练集中每个样本的距离,所以当训练集规模较大时,计算量将会成指数增长。特别是在高维数据集上,由于维度灾难的影响,KNN算法的计算复杂度将会更加突出。
如何处理KNN算法的缺点
针对KNN算法的缺点,我们可以采取一些方法来加以应对。
1. 异常值处理
在处理数据集时,我们可以先对数据进行预处理,通过检测和处理异常值来减小它们对KNN算法的影响。一种常见的方法是利用离群点检测算法(如LOF、Isolation Forest等)来识别和处理异常值。
举一个具体的例子。如果我们使用KNN算法对一个包含离群点的数据集进行分类,那么离群点可能对KNN算法的分类结果产生负面影响。我们可以使用Isolation Forest算法来识别和移除这些离群点,从而提高KNN算法的分类准确度。
from sklearn.neighbors import LocalOutlierFactor
from sklearn.datasets import make_blobs
import numpy as np# 生成一个带有离群点的数据集
X, _ = make_blobs(n_samples=300, centers=1, cluster_std=1, random_state=0)
outliers = np.random.randint(0, 300, 20)
X[outliers] = np.random.random((20, 2)) * 20# 使用LOF算法识别离群点
lof = LocalOutlierFactor(n_neighbors=20, contamination=0.1)
y_pred = lof.fit_predict(X)
X_clean = X[y_pred > 0]# 使用KNN算法对处理后的数据集进行分类
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_scoreX_train, X_test, y_train, y_test = train_test_split(X_clean, y_pred[y_pred > 0], test_size=0.2, random_state=42)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
print("处理离群点后的KNN分类准确度:", accuracy_score(y_test, y_pred))
2. 降维处理
另一种缓解KNN算法计算复杂度的方法是对高维数据进行降维处理,以减小特征空间的维度。常见的降维方法包括主成分分析(PCA)和t-分布邻域嵌入(t-SNE)等。
举一个具体的例子。对于一个高维数据集,如果我们直接使用KNN算法进行分类,将面临维度灾难的问题,这会导致KNN算法的计算复杂度成指数增长。我们可以先使用PCA算法对数据进行降维处理,然后再利用KNN算法进行分类,以提高KNN算法的效率。
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris# 加载鸢尾花数据集
data = load_iris()
X, y = data.data, data.target# 使用PCA算法进行降维处理
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)# 使用KNN算法对处理后的数据集进行分类
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_scoreX_train, X_test, y_train, y_test = train_test_split(X_pca, y, test_size=0.2, random_state=42)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
print("使用PCA降维后的KNN分类准确度:", accuracy_score(y_test, y_pred))
以上是关于KNN算法的优缺点以及如何处理其缺点的一些讨论和示例,希望对理解和应用KNN算法有所帮助。在实际应用中,我们需要根据具体的问题和数据特点来选择适合的处理方法,以充分发挥KNN算法的优势,并缓解其缺点带来的影响。
相关文章:

AI学习指南机器学习篇-KNN的优缺点
AI学习指南机器学习篇-KNN的优缺点 在机器学习领域中,K最近邻(K-Nearest Neighbors,KNN)算法是一种十分常见的分类和回归方法之一。它的原理简单易懂,但在实际应用中也存在一些优缺点。本文将重点探讨KNN算法的优缺点…...

全网最全!25届最近5年上海理工大学自动化考研院校分析
上海理工大学 目录 一、学校学院专业简介 二、考试科目指定教材 三、近5年考研分数情况 四、近5年招生录取情况 五、最新一年分数段图表 六、历年真题PDF 七、初试大纲复试大纲 八、学费&奖学金&就业方向 一、学校学院专业简介 二、考试科目指定教材 1、考试…...

LANG、LC_MESSAGES和LC_ALL
在Linux系统中,环境变量LANG、LC_MESSAGES和LC_ALL用于控制系统和应用程序的语言和区域设置(locale)。它们的具体作用如下: LANG: LANG是最基本的环境变量,用于指定系统的默认语言和区域设置。它是一个全局…...
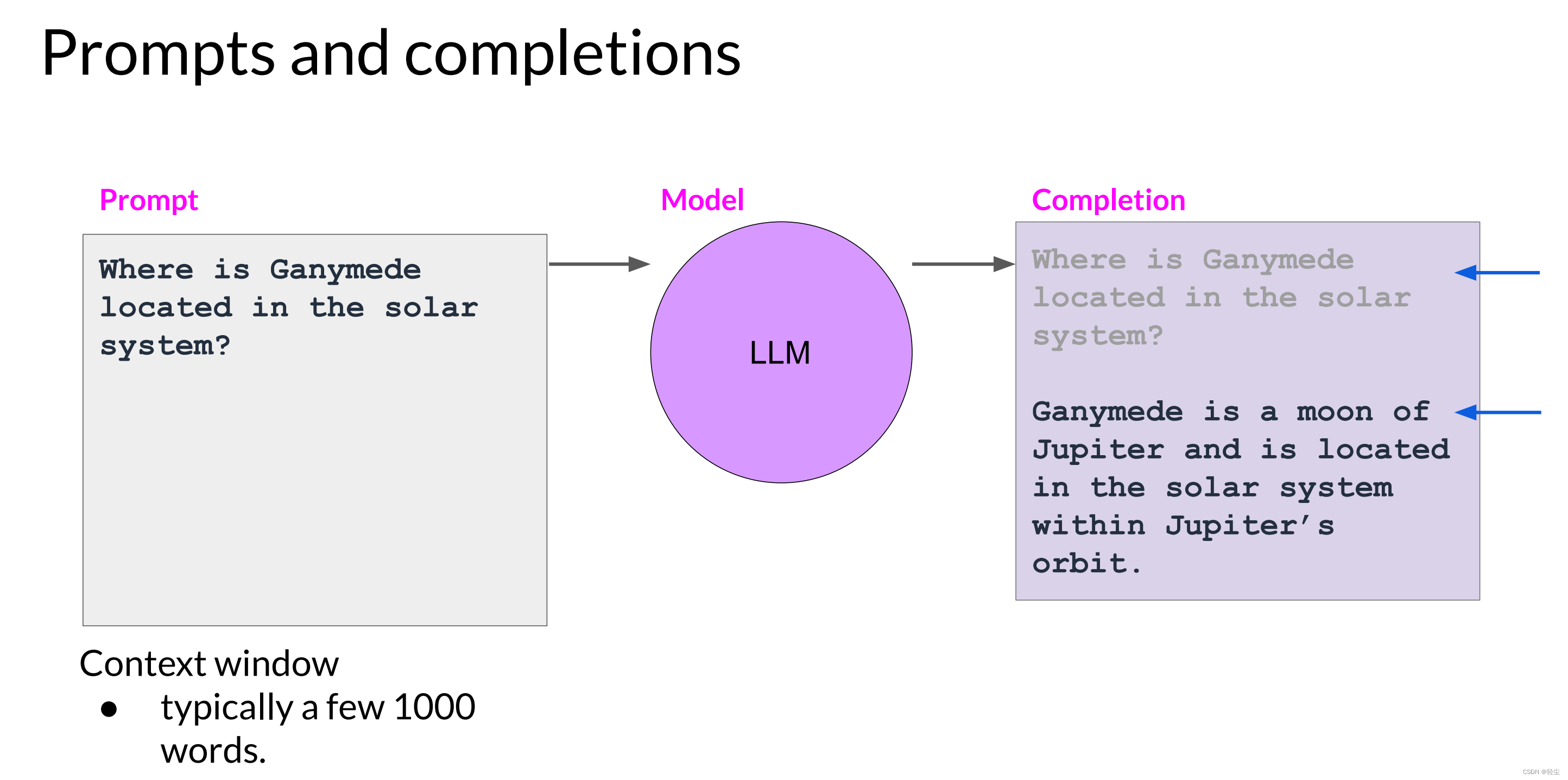
生成式AI和LLM的一些基本概念和名词解释
1. Machine Learning 机器学习是人工智能(AI)的一个分支,旨在通过算法和统计模型,使计算机系统能够从数据中学习并自动改进。机器学习算法使用数据来构建模型,该模型可用于预测或决策。机器学习应用于各种领域&#x…...

python项目(课设)——飞机大战小游戏项目源码(pygame)
主程序 import pygame from plane_sprites import * class PlaneGame: """ 游戏类 """ def __init__(self): print("游戏初始化") # 初始化字体模块 pygame.font.init() # 创建游戏…...

Chatgpt教我打游戏攻略
宝可梦朱 我在玩宝可梦朱的时候,我的同行队伍里有黏美儿,等级为65,遇到了下雨天但是没有进化,为什么呢? 黏美儿(Goomy)要进化为黏美龙(Goodra),需要满足以下…...
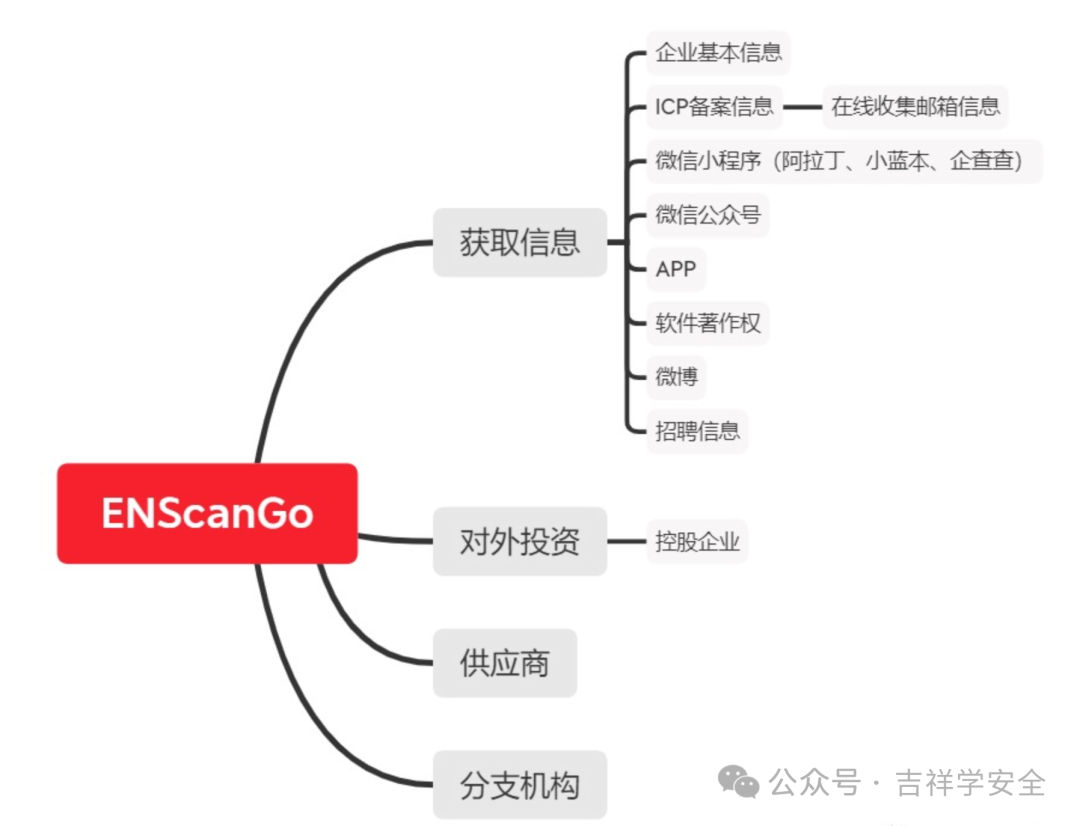
最全信息收集工具集
吉祥学安全知识星球🔗除了包含技术干货:Java代码审计、web安全、应急响应等,还包含了安全中常见的售前护网案例、售前方案、ppt等,同时也有面向学生的网络安全面试、护网面试等。 所有的攻防、渗透第一步肯定是信息收集了…...

redis类型解析汇总
redis类型解析汇总 介绍数据类型简介主要数据类型:衍生类型: 字符串(String)底层设计原理图例设计优势字符串使用方法设置字符串值获取字符串值获取和设置部分字符串获取字符串长度追加字符串设置新值并返回旧值递增/递减同时设置…...
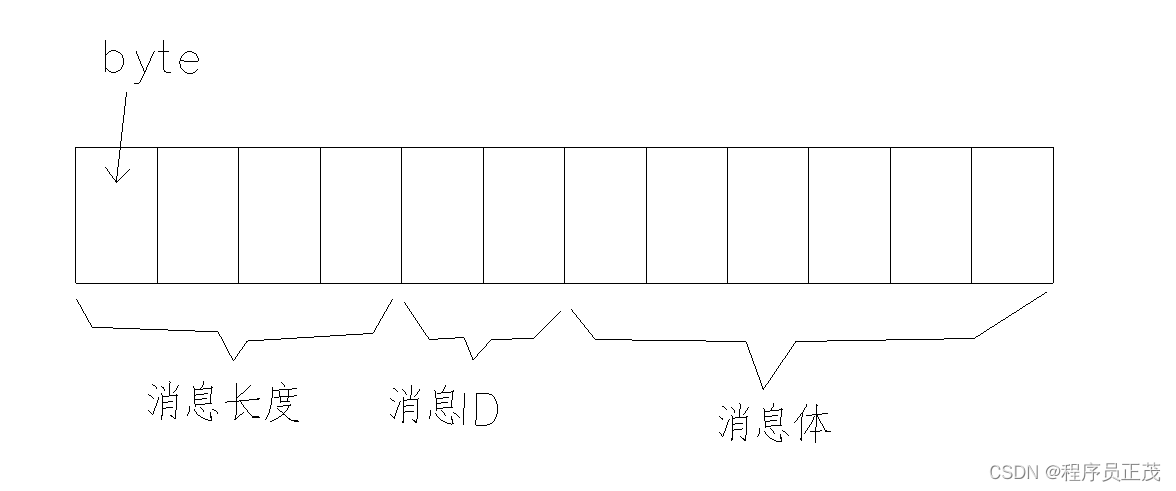
Unity3d自定义TCP消息替代UNet实现网络连接
以前使用UNet实现网络连接,Unity2018以后被弃用了。要将以前的老程序升到高版本,最开始打算使用Mirro,结果发现并不好用。那就只能自己写连接了。 1.TCP消息结构 (1). TCP消息是按流传输的,会发生粘包。那么在发射和接收消息时就需要对消息进行打包和解包。如果接收的消息…...

git fetch 和 git pull区别
git branch //查看本地所有分支 git branch -r //查看远程所有分支 git branch -a //查看本地和远程的所有分支 git branch <branchname> //新建分支 git branch -d <branchname> //删除本地分支 git branch -d -r <branchname> //删除远程分支&#x…...

冲击2024年CSDN博客之星TOP1:CSDN文章质量分查询在哪里?
文章目录 一,2023年博客之星规则1,不高的入围门槛2,[CSDN博文质量分测评地址](https://www.csdn.net/qc) 二,高分秘籍1,要有目录2,文章长度要足够,我的经验是汉字加代码至少1000字。3࿰…...

高性能并行计算华为云实验一:MPI矩阵运算
目录 一、实验目的 二、实验说明 三、实验过程 3.1 创建矩阵乘法源码 3.1.1 实验说明 3.1.2 实验步骤 3.2 创建卷积和池化操作源码 3.2.1 实验说明 3.2.2 实验步骤 3.3 创建Makefile文件并完成编译 3.4 建立主机配置文件与运行监测 四、实验结果与分析 4.1 矩阵乘法…...

库卡机器人减速机维修齿轮磨损故障
一、KUKA机器人减速器齿轮磨损故障的原因 1. 润滑不足:润滑油不足或质量不佳可能导致齿轮磨损。 2. 负载过重:超过库卡机械臂减速器额定负载可能导致齿轮磨损。 3. 操作不当:未按照说明书操作可能导致KUKA机器人减速器齿轮磨损。 4. 维护不足…...

【C/C++】我自己提出的数组探针的概念,快来围观吧
数组探针 在许多编程语言中如果涉及到数组那么就可以使用这个东西,便于遍历数组 中文名 数组探针 外文名 arrProbe 适用领域 大数据 所属学科 软件技术、编程 提出者 董翔 目录 1 概述2 工作原理3 应用场景 ▪ 数据处理和分析▪ 图像处理▪ 游戏开发▪…...
ArcGIS图斑分区(组)排序—从上到下从左到右
点击下方全系列课程学习 点击学习—>ArcGIS全系列实战视频教程——9个单一课程组合系列直播回放 ArcGIS图斑分区(组)从上到下从左到右排序 是之前的内容的升级 GIS技巧100例——12ArcGIS图斑空间排序 关于今天的内容 我们在19年已经和大家分…...

React useRef 组件内及组件传参使用
保存变量, 改变不引起渲染 import { useRef} from react; const dataRef useRef(null) ... dataRef.current setTimeout(()>console.log(...),1000)绑定dom const inputRef useRef(null) <input ref {inputRef} />绑定dom列表 - ref 回调 const ite…...

Intelij IDEA中Mapper.xml无法构建到资源目录的问题
问题场景: 在尝试把原本在eclipse上的Java Web项目转移至Intelij idea上时,在配置文件均与eclipse一致的情况下出现了如下报错: org.apache.ibatis.binding.BindingException: Invalid bound statement (not found): cn.umbrella.crm_core.…...

2024.6.23周报
目录 摘要 ABSTRACT 一、文献阅读 一、题目 二、摘要 三、网络架构 四、创新点 五、文章解读 1、Introduction 2、Method 3、实验 4、结论 二、代码实验 总结 摘要 本周阅读了一篇题目为NAS-PINN: NEURAL ARCHITECTURE SEARCH-GUIDED PHYSICS-INFORMED NEURAL N…...
)
鸿蒙实战开发:网络层的艺术——优雅封装与搭建指南(中)
前言 在鸿蒙开发的广袤天地中,网络层的搭建与封装无疑是构建高效、稳定应用的基石。继上篇的探索之后,本文将继续深入网络层的优化之旅,揭秘如何通过类型转换器、请求查询附加器以及丰富的常量参数,将网络层的构建艺术推向一个新…...

docker in docker 连私有仓库时报错 https
背景 jenkins 是使用 docker 方式部署的, 在 jenkins中又配置了 docker 的命令, 使用的宿主机的 docker 环境, 在jenkins 中执行 docker 相关命令的时候报错 jenkinse0e7b943b6e4:/$ docker login -u admin -p Harbor12345 172.16.100.15:80 WARNING! Using --password via t…...

【linux学习】linux的一些奇怪知识,方便日常使用
我是程序员小青蛙,下面介绍关于linux的知识。前言一些基本知识,方便利用,比如热键[tab],[ctrl]-c,[ctrl]-d,粘滞位,权限等;xshell中的复制粘贴,Ctrlinsert,复制shiftinsert->粘贴一、重要的几…...

convoai-cli:命令行集成AI对话,提升开发效率的自动化利器
1. 项目概述:一个面向对话式AI的命令行利器如果你和我一样,经常需要和各类大语言模型(LLM)打交道,无论是调试一个提示词(Prompt),还是批量处理一堆文档,又或者只是想快速…...

PSoC时钟系统深度解析:从架构原理到配置避坑指南
1. 项目概述:为什么PSoC的时钟值得你花时间研究?如果你刚开始接触Cypress(现Infineon)的PSoC系列微控制器,可能会觉得它的开发环境PSoC Creator功能强大但有点复杂。在众多需要配置的模块里,时钟系统往往是…...
首次实践)
中华民族站起来了,《AI驱动上下五千年:从结绳记事到智能纪元》第三章:周礼分封——面向服务的架构(SOA)首次实践
第三章:周礼分封——面向服务的架构(SOA)首次实践 1.历史现场:周公的架构革命 时间:公元前1046年,周朝建立之初地点:镐京(今西安)明堂人物:周公旦、各诸侯国君…...

CircuitPython库管理实战:从安装优化到API深度应用
1. 项目概述与核心价值在嵌入式硬件开发的世界里,CircuitPython以其极低的入门门槛和“即写即得”的交互体验,成为了连接创意与现实的绝佳桥梁。无论是点亮第一颗LED,还是驱动复杂的传感器网络,其丰富的库生态系统都是项目成功的基…...

质子CT技术:原理、系统设计与临床应用
1. 质子CT技术概述:从原理到临床需求在放射治疗领域,质子治疗因其独特的布拉格峰(Bragg Peak)特性而备受关注。与传统X射线治疗相比,质子束在组织中沉积的能量分布具有明显的物理优势——在射程末端释放最大剂量后迅速衰减。这一特性使得肿瘤…...

保姆级教程:用STM32+ESP8266+微信小程序,5分钟搞定Onenet数据上传与设备控制
零基础实战:STM32ESP8266微信小程序极速对接Onenet全指南 在物联网技术快速普及的今天,许多嵌入式开发者都希望快速搭建一个完整的智能设备系统。本文将带你用最简单的方式,通过STM32微控制器、ESP8266 WiFi模块和微信小程序,实现…...

告别虚拟机卡顿:在VMware 17上为RHEL 9.2分配CPU和内存的黄金法则
告别虚拟机卡顿:在VMware 17上为RHEL 9.2分配CPU和内存的黄金法则 当你在VMware Workstation 17上运行RHEL 9.2时,是否经常遇到编译速度慢、桌面响应延迟甚至整个系统卡死的情况?这很可能是因为你没有根据宿主机的实际硬件情况科学分配虚拟资…...

NotebookLM电影文献处理失效真相:92%研究者忽略的3类语义断层及修复方案
更多请点击: https://kaifayun.com 第一章:NotebookLM电影研究辅助 NotebookLM 是 Google 推出的基于 AI 的研究协作者,专为深度阅读与知识整合设计。在电影研究场景中,它能高效解析剧本、影评、导演访谈、学术论文等多源文本&am…...

CircuitPython微控制器图形保存实战:从屏幕截图到BMP文件生成
1. 项目概述:为什么我们需要在微控制器上保存图形? 在嵌入式开发领域,尤其是当我们使用像Adafruit PyPortal、PyGamer这类带有彩色显示屏的开发板时,图形界面的调试和内容存档一直是个不大不小的痛点。想象一下,你花了…...