从 Hadoop 迁移,无需淘汰和替换

我们仍然惊讶于有如此多的客户来找我们,希望从HDFS迁移到现代对象存储,如MinIO。我们现在以为每个人都已经完成了过渡,但每周,我们都会与一个决定进行过渡的主要、高技术性组织交谈。
很多时候,在这些讨论中,他们希望在迁移后维护其基础设施的某些元素。HDFS 生态系统中的一些框架和软件得到了大量开发人员的支持,并且在现代数据堆栈中仍然占有一席之地。事实上,我们经常说 HDFS 生态系统带来了很多好处。根本问题在于存储和计算的紧密耦合,而不一定是大数据时代的工具和服务。
这篇博文将重点介绍如何在不淘汰和替换有价值的工具和服务的情况下进行迁移。现实情况是,如果你不对你的基础架构进行现代化改造,你就无法在组织所需的AI/ML方面取得进步,但你不必为了实现这一目标而抛弃一切。
使用 Spark 和 Hive 分解存储和计算
我们已经经历了一些完全撕裂和替换迁移的策略,在某些情况下,这是前进的道路。但是,让我们看一下实现 HDFS 实现现代化的另一种方法。
此架构涉及 Kubernetes 管理用于数据处理的 Apache Spark 和 Apache Hive 容器;Spark 与 MinIO 原生集成,而 Hive 使用 YARN。MinIO 处理有状态容器中的对象存储,在此架构中,它依赖于多租户配置进行数据隔离。

架构概述:
-
计算节点:Kubernetes 高效管理计算节点上的无状态 Apache Spark 和 Apache Hive 容器,确保资源利用率和动态扩展。
-
存储层:MinIO纠删码和BitRot保护意味着您可能会丢失多达一半的驱动器数量,但仍然可以恢复,所有这些都不需要维护Hadoop所需的每个数据块的三个副本。
-
访问层:对 MinIO 对象存储的所有访问都通过 S3 API 统一,为与存储的数据交互提供无缝接口。
-
安全层:数据安全至关重要。MinIO 使用每个对象的密钥加密所有数据,确保对未经授权的访问提供强大的保护。
-
身份管理:MinIO Enterprise 与 WSO2、Keycloak、Okta、Ping Identity 等身份提供商完全集成,以允许应用程序或用户进行身份验证。
Hadoop的完全现代化替代品,使您的组织能够保留Hive,YARN和任何其他Hadoop生态系统数据产品,这些产品可以与对象存储集成,对象存储几乎是现代数据堆栈中的所有内容。
接入层中的互操作性
S3a是寻求从Hadoop过渡的应用程序的重要端点,它提供了与Hadoop生态系统中各种应用程序的兼容性。自 2006 年以来,兼容 S3 的对象存储后端已作为默认功能无缝集成到 Hadoop 生态系统中的众多数据平台中。这种集成可以追溯到将 S3 客户端实施整合到新兴技术中。
在所有与Hadoop相关的平台上,采用该 hadoop-aws 模块是 aws-java-sdk-bundle 标准做法,确保了对S3 API的强大支持。这种标准化方法有助于应用程序从 HDFS 和 S3 存储后端平稳过渡。只需指定适当的协议,开发人员就可以毫不费力地将应用程序从Hadoop切换到现代对象存储。S3 的协议方案用 s3a:// 表示,而 HDFS 的协议方案用 hdfs:// 表示。
迁移的好处
可以详细讨论从Hadoop迁移到现代对象存储的好处。如果你正在阅读这篇文章,你已经在很大程度上意识到,如果不从Hadoop等传统平台迁移,人工智能和其他现代数据产品的进步可能会被排除在外。原因归结为性能和规模。
毫无疑问,现代工作负载需要出色的性能来与正在处理的数据量和现在所需的任务复杂性竞争。当性能不仅仅是虚荣的基准测试,而是一个硬性要求时,Hadoop替代品的竞争者领域就会急剧下降。
推动迁移的另一个因素是云原生规模。当云的概念不再是物理位置,而更像是一种操作模型时,就可以做一些事情,比如在几分钟内从单个 .yaml 文件部署整个数据堆栈。如此迅速的实现会让任何Hadoop工程师从椅子上摔下来。
这一概念的一部分是摆脱供应商锁定带来的经济效益,它允许组织为特定工作负载选择一流的选项。更不用说,无需维护三个单独的数据副本来保护它,这已成为过去,具有主动-主动复制和纠删编码。投资于面向未来的技术通常也意味着更容易找到和招募有才华的专业人员来从事您的基础设施工作。人们希望从事推动业务发展的事情,而几乎没有比数据做得更好的了。这些因素共同促成了数据堆栈,该堆栈不仅更快、更便宜,而且更适合当今和未来的数据驱动需求。
开始
在深入了解我们架构的细节之前,您需要启动并运行一些组件。要从Hadoop迁移,显然必须首先安装它。如果要模拟此体验,可以通过在此处设置 Hadoop 的 Hortonworks 发行版来开始本教程。
否则,您可以从以下安装步骤开始:
1 . 设置 Ambari:接下来,安装 Ambari,它将通过自动为你配置 YARN 来简化服务的管理。Ambari提供了一个用户友好的仪表板,用于管理Hadoop生态系统中的服务,并保持一切顺利运行。
2 . 安装 Apache Spark:Spark 对于处理大规模数据至关重要。按照标准安装过程启动并运行 Spark。
3 . 安装 MinIO:根据您的环境,您可以在两种安装方法之间进行选择:Kubernetes 或 Helm Chart。
成功安装这些元素后,可以将 Spark 和 Hive 配置为使用 MinIO 而不是 HDFS。导航到 Ambari UI http://:8080/ 并使用默认凭据登录: username: admin, password: admin ,
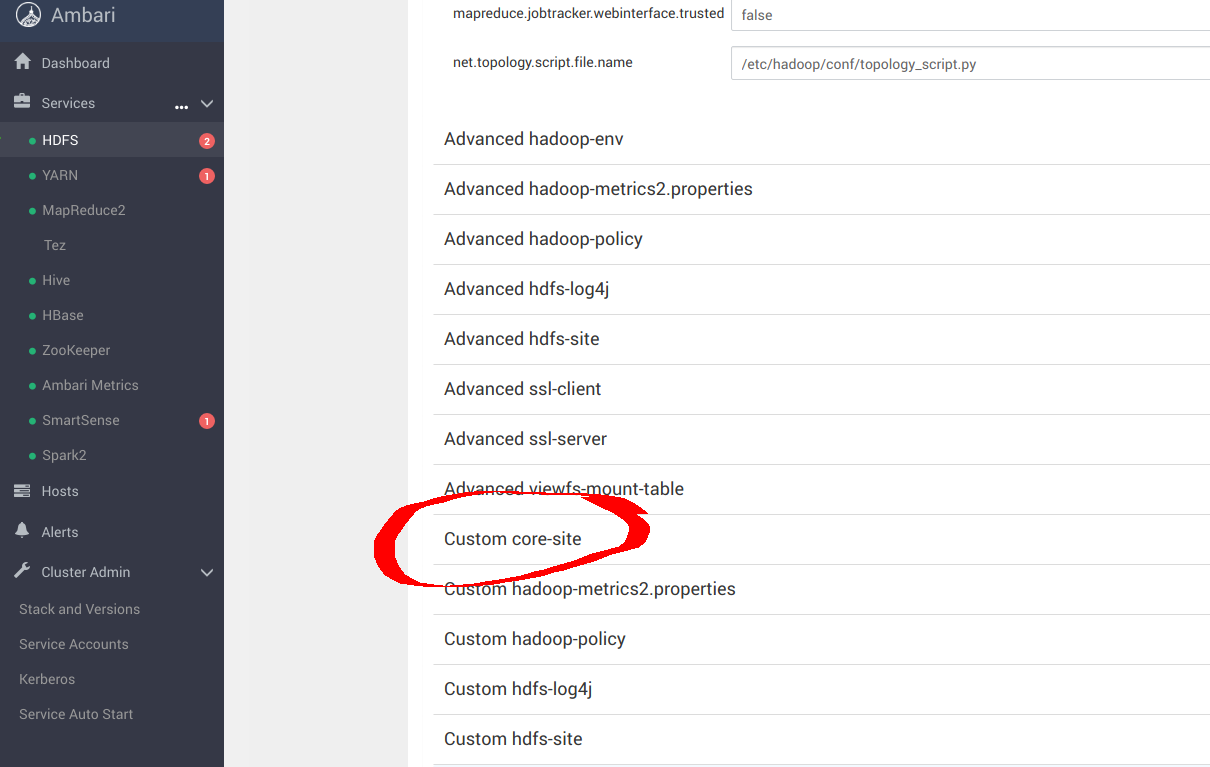
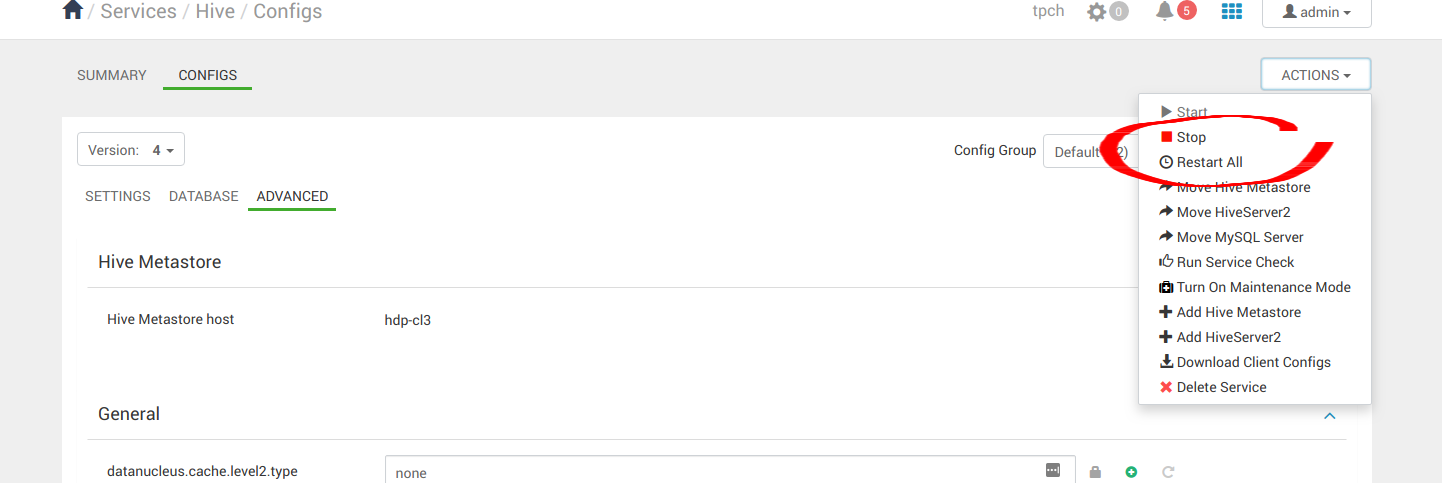
在 Ambari 中,导航到“services”,然后导航到 HDFS,然后导航到“配置”面板,如下面的屏幕截图所示。在本部分中,您将 Ambari 配置为将 S3a 与 MinIO 结合使用,而不是 HDFS。

向下滚动并导航到 Custom core-site 。您将在此处配置 S3a。
sudo pip install yq
alias kv-pairify='yq ".configuration[]" | jq ".[]" | jq -r ".name + \"=\" + .value"'从这里开始,您的配置将取决于您的基础结构。但是,下面可能代表了 core-site.xml 一种配置 S3a 的方法,其中 MinIO 在 12 个节点和 1.2TiB 内存上运行。
cat ${HADOOP_CONF_DIR}/core-site.xml | kv-pairify | grep "mapred"mapred.maxthreads.generate.mapoutput=2 # Num threads to write map outputs
mapred.maxthreads.partition.closer=0 # Asynchronous map flushers
mapreduce.fileoutputcommitter.algorithm.version=2 # Use the latest committer version
mapreduce.job.reduce.slowstart.completedmaps=0.99 # 99% map, then reduce
mapreduce.reduce.shuffle.input.buffer.percent=0.9 # Min % buffer in RAM
mapreduce.reduce.shuffle.merge.percent=0.9 # Minimum % merges in RAM
mapreduce.reduce.speculative=false # Disable speculation for reducing
mapreduce.task.io.sort.factor=999 # Threshold before writing to drive
mapreduce.task.sort.spill.percent=0.9 # Minimum % before spilling to drive通过查看有关此迁移模式的文档,以及 Hadoop 关于 S3 的文档,可以探索相当多的优化 此处 和 此处.
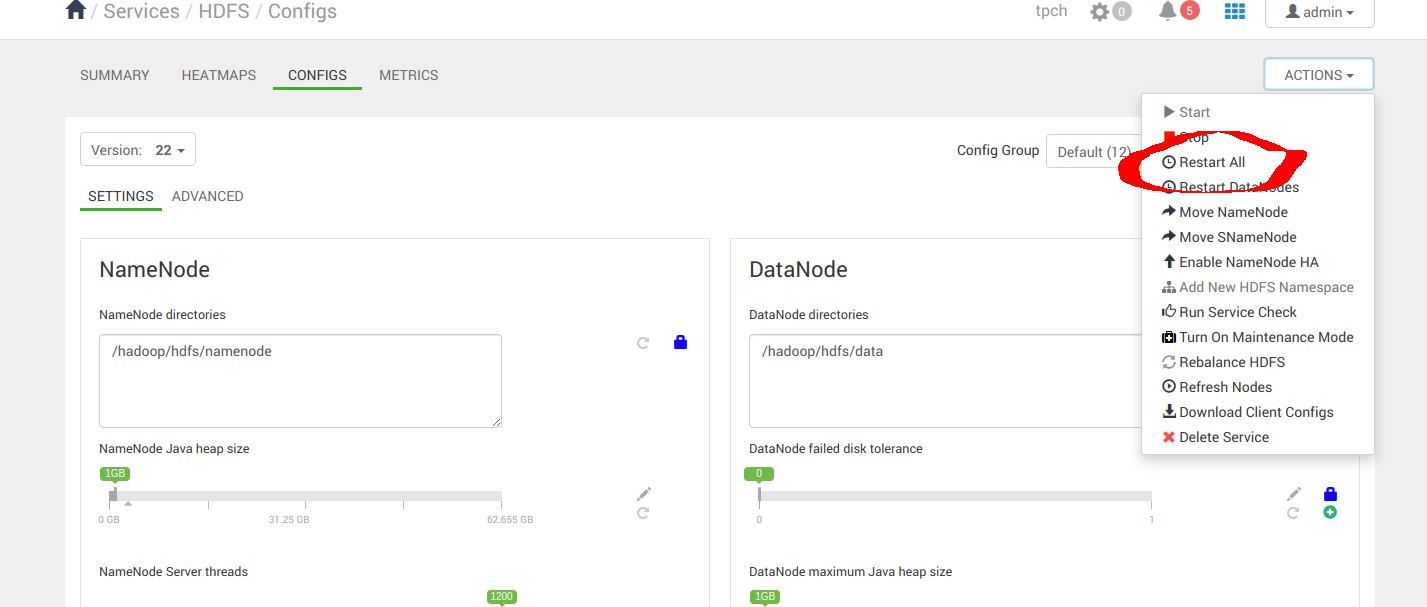
当您对配置感到满意时,请重新启动 All。
您还需要导航到 Spark2 配置面板。
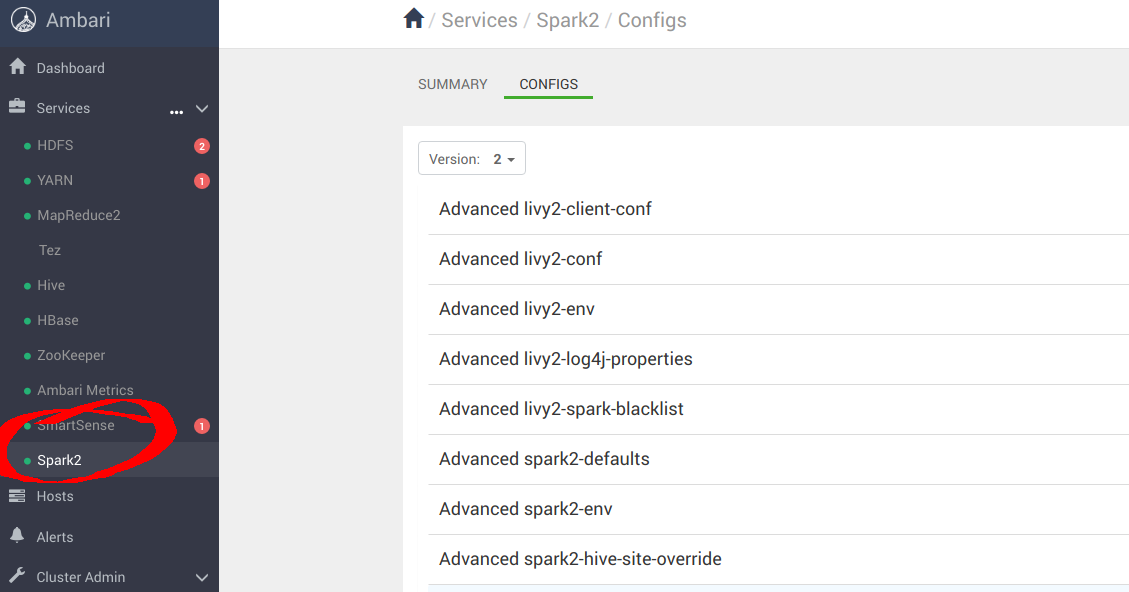
向下滚动到 Custom spark-defaults 并添加以下属性以使用 MinIO 进行配置:
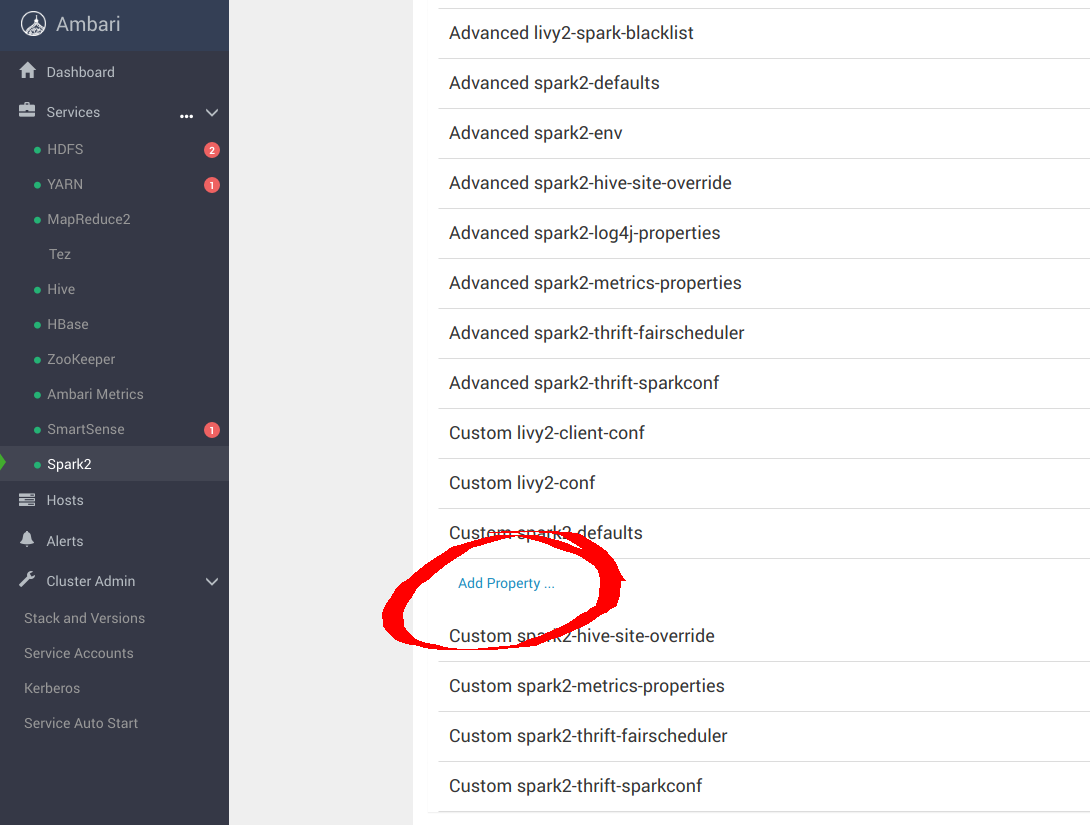
spark.hadoop.fs.s3a.access.key minio
spark.hadoop.fs.s3a.secret.key minio123
spark.hadoop.fs.s3a.path.style.access true
spark.hadoop.fs.s3a.block.size 512M
spark.hadoop.fs.s3a.buffer.dir ${hadoop.tmp.dir}/s3a
spark.hadoop.fs.s3a.committer.magic.enabled false
spark.hadoop.fs.s3a.committer.name directory
spark.hadoop.fs.s3a.committer.staging.abort.pending.uploads true
spark.hadoop.fs.s3a.committer.staging.conflict-mode append
spark.hadoop.fs.s3a.committer.staging.tmp.path /tmp/staging
spark.hadoop.fs.s3a.committer.staging.unique-filenames true
spark.hadoop.fs.s3a.committer.threads 2048 # number of threads writing to MinIO
spark.hadoop.fs.s3a.connection.establish.timeout 5000
spark.hadoop.fs.s3a.connection.maximum 8192 # maximum number of concurrent conns
spark.hadoop.fs.s3a.connection.ssl.enabled false
spark.hadoop.fs.s3a.connection.timeout 200000
spark.hadoop.fs.s3a.endpoint http://minio:9000
spark.hadoop.fs.s3a.fast.upload.active.blocks 2048 # number of parallel uploads
spark.hadoop.fs.s3a.fast.upload.buffer disk # use disk as the buffer for uploads
spark.hadoop.fs.s3a.fast.upload true # turn on fast upload mode
spark.hadoop.fs.s3a.impl org.apache.hadoop.spark.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.s3a.max.total.tasks 2048 # maximum number of parallel tasks
spark.hadoop.fs.s3a.multipart.size 512M # size of each multipart chunk
spark.hadoop.fs.s3a.multipart.threshold 512M # size before using multipart uploads
spark.hadoop.fs.s3a.socket.recv.buffer 65536 # read socket buffer hint
spark.hadoop.fs.s3a.socket.send.buffer 65536 # write socket buffer hint
spark.hadoop.fs.s3a.threads.max 2048 # maximum number of threads for S3A应用配置更改后,全部重新启动。
导航到 Hive 面板以完成配置。
向下滚动到 Custom hive-site 并添加以下属性:
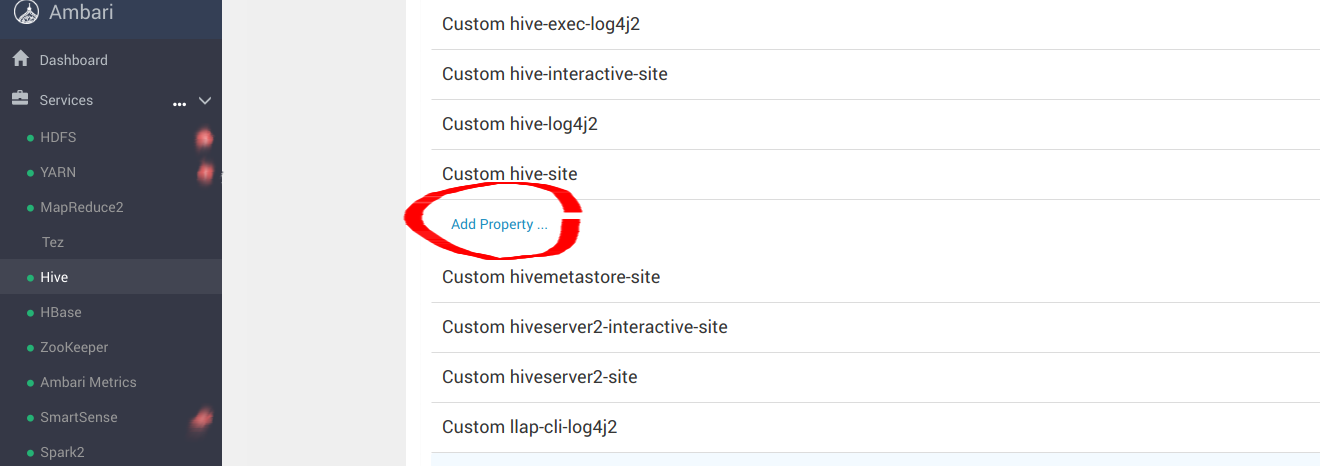
hive.blobstore.use.blobstore.as.scratchdir=true
hive.exec.input.listing.max.threads=50
hive.load.dynamic.partitions.thread=25
hive.metastore.fshandler.threads=50
hive.mv.files.threads=40
mapreduce.input.fileinputformat.list-status.num-threads=50您可以在此处找到更多微调配置信息。在进行配置更改后重新启动所有。
就是这样,您现在可以测试您的集成。
自行探索
这篇博文概述了一种从Hadoop迁移的现代方法,而无需彻底检修现有系统。通过利用 Kubernetes 管理 Apache Spark 和 Apache Hive,并集成 MinIO 进行有状态对象存储,组织可以实现支持动态扩展和高效资源利用的平衡架构。此设置不仅保留了数据处理环境的功能,而且增强了数据处理环境的功能,使其更加强大且面向未来。
借助 MinIO,您可以受益于在商用硬件上提供高性能的存储解决方案,通过纠缠编码(消除 Hadoop 数据复制的冗余)降低成本,并绕过供应商锁定和基于 Cassandra 的元数据存储等限制。这些优势对于希望在不丢弃现有数据系统核心元素的情况下利用高级 AI/ML 工作负载的组织至关重要。
相关文章:
从 Hadoop 迁移,无需淘汰和替换
我们仍然惊讶于有如此多的客户来找我们,希望从HDFS迁移到现代对象存储,如MinIO。我们现在以为每个人都已经完成了过渡,但每周,我们都会与一个决定进行过渡的主要、高技术性组织交谈。 很多时候,在这些讨论中ÿ…...
深度学习:从理论到应用的全面解析
引言 深度学习作为人工智能(AI)的核心技术之一,在过去的十年中取得了显著的进展,并在许多领域中展示了其强大的应用潜力。本文将从理论基础出发,探讨深度学习的最新进展及其在各领域的应用,旨在为读者提供全…...

【02】区块链技术应用
区块链在金融、能源、医疗、贸易、支付结算、证券等众多领域有着广泛的应用,但是金融依旧是区块链最大且最为重要的应用领域。 1. 区块链技术在金融领域的应用 1.2 概况 自2019年以来,国家互联网信息办公室已发布八批境内区块链信息服务案例清单&#…...

一篇文章搞懂残差网络算法
残差网络(Residual Network,简称ResNet)是一种深度学习架构,它在2015年由微软研究院的Kaiming He等四位作者提出。ResNet的提出是为了解决深度神经网络训练中的梯度消失和梯度爆炸问题,以及随着网络层数增加而出现的性能退化问题。本文将详细介绍残差网络算法的定义、产生…...
网络安全:Web 安全 面试题.(SQL注入)
网络安全:Web 安全 面试题.(SQL注入) 网络安全面试是指在招聘过程中,面试官会针对应聘者的网络安全相关知识和技能进行评估和考察。这种面试通常包括以下几个方面: (1)基础知识:包括网络基础知识、操作系…...
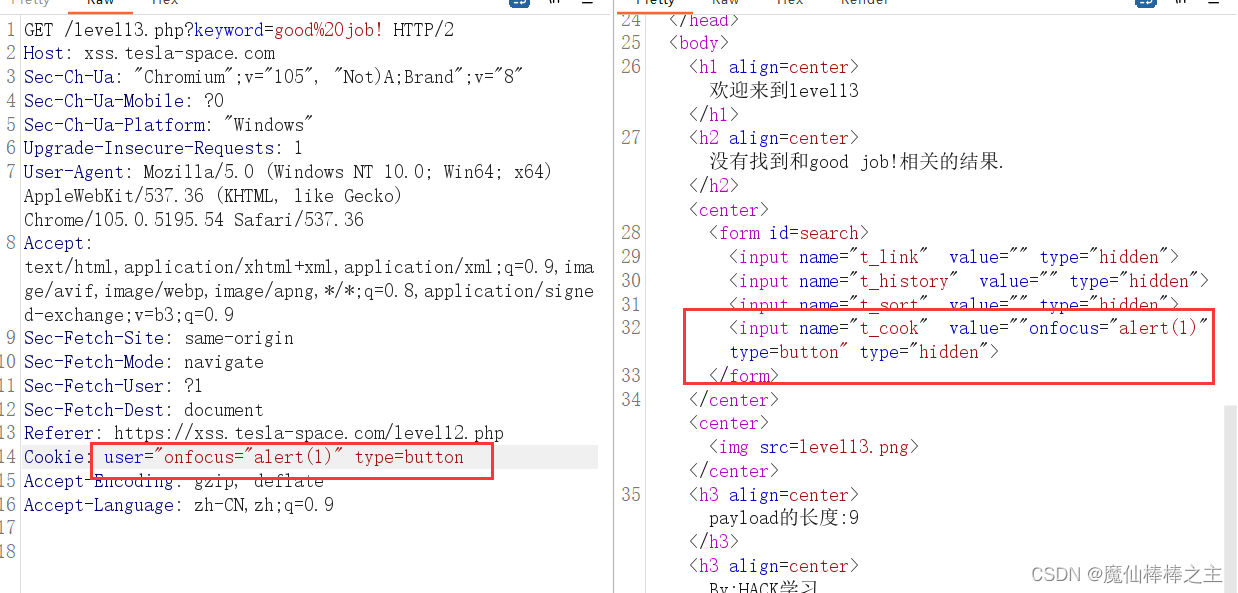
XSS学习(绕过)
学习平台:xss.tesla-space.com XSS学习(绕过) level1level2level3level4level5level6level7level8level9level10level11level12level13level14 level1 应该没有过滤 https://xss.tesla-space.com/level1.php?name<script>alert(1);&…...

深信服2024笔试
一 :服务器 小明是一名公司的IT运维工程师,负责管理公司的IT系统。公司总共有两个配置相同的服务器A和B,各运行了若干个服务。现在小明发现两台服务器上运行的服务占用的内存总和不相等(假设每个服务占用内存是-个恒定正整数),打…...

IOS Swift 从入门到精通:闭包 第一部分
文章目录 创建基本闭包在闭包中接受参数从闭包返回值闭包作为参数尾随闭包语法 创建基本闭包 Swift 允许我们像使用字符串和整数等其他类型一样使用函数。这意味着您可以创建一个函数并将其分配给一个变量,使用该变量调用该函数,甚至可以将该函数作为参…...

解两道四年级奥数题(等差数列)玩玩
1、1~200这200个连续自然数的全部数字之和是________。 2、2,4,6,……,2008这些偶数的所有各位数字之和是________。 这两道题算易错吧,这里求数字之和,比如124这个数的全部数字之和是1247。 …...

深入理解Python中的并发与异步的结合使用
在上一篇文章中,我们讨论了异步编程中的性能优化技巧,并简单介绍了trio和curio库。今天,我们将深入探讨如何将并发编程与异步编程结合使用,并详细讲解如何利用trio和curio库优化异步编程中的性能。 文章目录 并发与异步编程的区…...

如何将 ChatGPT 集成到你的应用中
在当今快速发展的技术环境中,将人工智能聊天解决方案集成到你的应用程序中可以显著提升用户体验和参与度。OpenAI 的 ChatGPT 以其对话能力和高级语言理解而闻名,对于希望在其应用程序中实现智能聊天功能的开发人员来说是一个绝佳的选择。那我们今天就来…...

在 Swift 中,UILabel添加点击事件的方法
在 Swift 中,可以使用 UITapGestureRecognizer 给 UILabel 添加点击事件。以下是一个详细的步骤和示例代码: 1. 创建 UILabel 并添加到视图 在 Storyboard 或代码中创建一个 UILabel 并将其添加到视图中。 2. 启用 UILabel 的用户交互 默认情况下&am…...
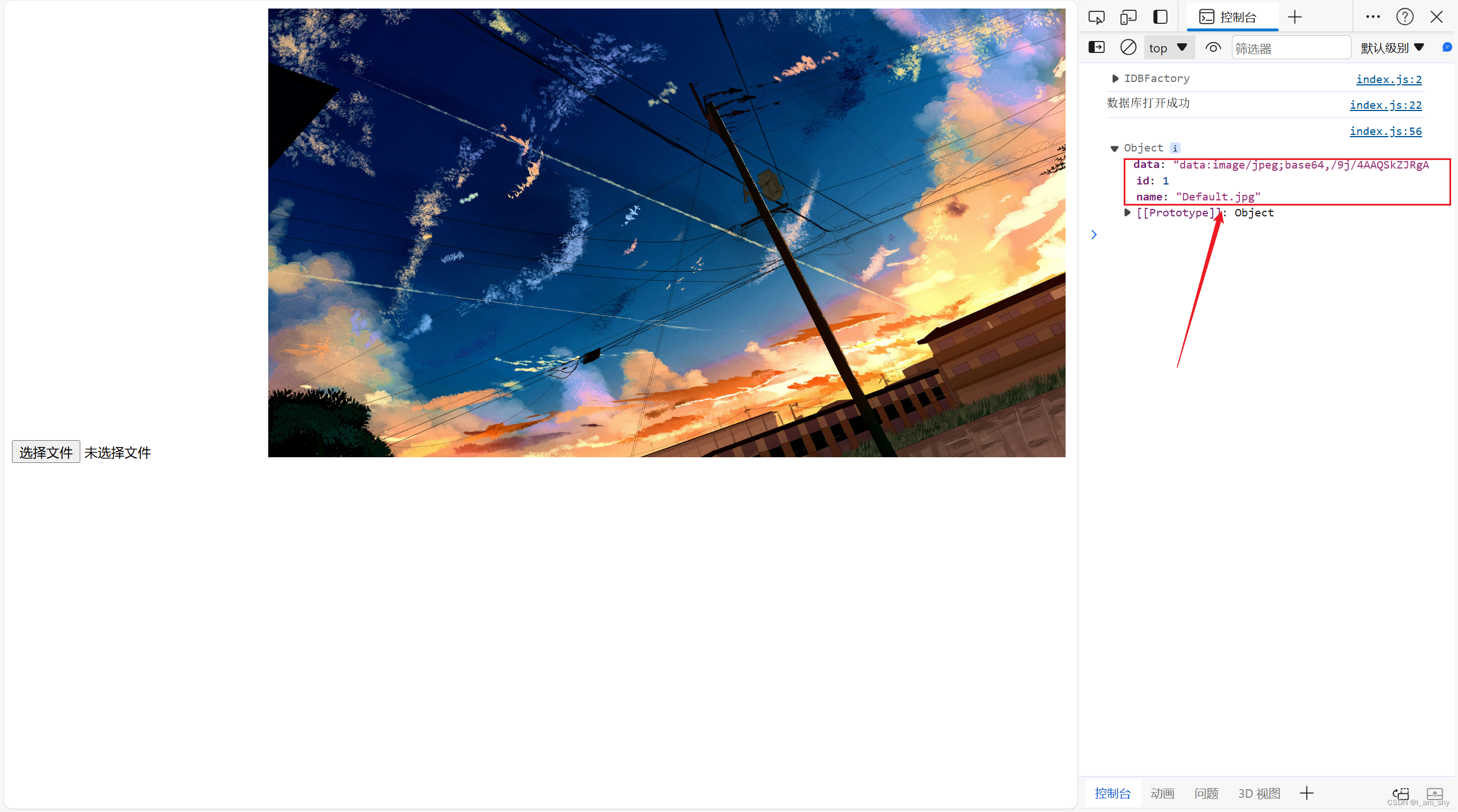
indexedDB---掌握浏览器内建数据库的基本用法
1.认识indexedDB IndexedDB 是一个浏览器内建的数据库,它可以存放对象格式的数据,类似本地存储localstore,但是相比localStore 10MB的存储量,indexedDB可存储的数据量远超过这个数值,具体是多少呢? 默认情…...
【css】如何修改input选中历史选项后,自动填充的蓝色背景色
自动填充前: 自动填充后: 解决办法 方法一:设置背景透明(通过拉长过渡时间,和延迟过渡开始时间,掩盖input自动填充背景颜色) PS:注意,这个过渡效果会在你的delay tim…...

红队内网攻防渗透:内网渗透之内网对抗:网络通讯篇防火墙组策略入站和出站规则单层双层C2正反向上线解决方案
红队内网攻防渗透 1. 内网网络通讯1.1 防火墙策略-入站规则&出站规则&自定义1.1.1 防火墙默认入站&出站策略1.1.2 防火墙自定义入站&出站策略1.1.3 内网域防火墙同步策略1.2 防火墙限制1.2.1 防火墙限制端口1.2.2 防火墙限制协议1.2.2.1 防火墙协议入站限制1.2…...

linux 查看进程启动方式
目录 如果是systemd管理的服务怎么快速找到对应的服务器呢 什么是CGroup 查找进程对应的systemd服务 方法一:查看 /proc//cgroup 文件 方法二:使用 ps 命令结合 --cgroup 选项 方法三:systemd-cgls 关于 system.slice 与 user.slice …...
基于Java实训中心管理系统设计和实现(源码+LW+调试文档+讲解等)
💗博主介绍:✌全网粉丝10W,CSDN作者、博客专家、全栈领域优质创作者,博客之星、平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 🌟文末获取源码数据库🌟 感兴趣的可以先收藏起来,…...

第2章 Android应用的界面编程
🌈个人主页:小新_- 🎈个人座右铭:“成功者不是从不失败的人,而是从不放弃的人!”🎈 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝 🏆所属专栏࿱…...

springboot学习-图灵课堂-最详细学习
springboot-repeat springBoot学习代码说明为什么java -jar springJar包后项目就可以启动 配置文件介绍 springBoot学习 依赖引入 <properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.target>8</mav…...

Total CAD Converter与Total Excel Converter软件分享
1.软件介绍 Total CAD Converter Total CAD Converter 是一款功能强大的工具,能够将 CAD 文件转换为多种格式,如 PDF、TIFF、JPEG、BMP、WMF、PNG、DXF、BMP、CGM、HPGL、SVG、PS 和 SWF 等。其支持的源格式丰富多样,包括 dxf、dwg、dwf、d…...

HTML代码加密工具源码_在线网页加密解密_防复制源码
概述 在前端开发与网页设计中,保护原创代码不被轻易复制或篡改是许多开发者的核心诉求。无论是为了隐藏核心逻辑,还是防止样式被恶意盗用,一款高效、安全的加密工具都显得尤为重要。为此,幽络源源码网特别整理并分享这款HTML代码…...

直播字幕难题终结者:OBS实时字幕插件完全攻略
直播字幕难题终结者:OBS实时字幕插件完全攻略 【免费下载链接】OBS-captions-plugin Closed Captioning OBS plugin using Google Speech Recognition 项目地址: https://gitcode.com/gh_mirrors/ob/OBS-captions-plugin 你是否曾为直播观众听不清你的声音而…...

RISC-V开发板VisionFive 2 UEFI固件移植与启动实战指南
1. 项目概述:当RISC-V单板机拥抱UEFI 对于玩惯了x86平台或者树莓派的开发者来说,给一块单板计算机(SBC)刷写固件、配置启动项,可能已经轻车熟路。但当你把目光投向RISC-V架构,特别是像赛昉科技的VisionFiv…...

GSE魔兽世界宏编译器完全指南:告别255字符限制,实现智能一键输出
GSE魔兽世界宏编译器完全指南:告别255字符限制,实现智能一键输出 【免费下载链接】GSE-Advanced-Macro-Compiler GSE is an alternative advanced macro editor and engine for World of Warcraft. 项目地址: https://gitcode.com/gh_mirrors/gs/GSE-…...

FOC如何控制速度力矩大小,以及无感FOC检测电角度的方法
FOC 控制电机,本质就一句话: 通过控制三相电流,让定子磁场始终在“最合适的角度”拉着/推着转子转。 更工程一点说: 速度靠速度环调节,扭矩靠 q 轴电流 Iq 调节,电角度靠编码器/霍尔/无感估算得到。 1. …...

Yokogawa ADV551数字输出模块
Yokogawa ADV551 数字输出模块是横河 CENTUM VP/CS 3000 系统的核心输出组件,具备以下 15 条特点:提供 32 路独立数字量输出通道。额定电压 24V DC,每通道负载能力充足。输出类型为电流吸收型(Current Sink)。支持状态…...
)
ssm中国篮球人才管理系统(10050)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

关于光缆,这些事儿通信人一定要知道
随着5G网络的全面铺开和持续深耕,通信工程师的工作边界正在不断拓展。过去,后台网优工程师可能更多地专注于参数调整、信令分析和性能优化;而如今,越来越多的项目要求前后台协同作业,网优人员也需要熟悉现场施工规范&a…...

低查重AI教材生成利器,AI写教材工具让你1周完成40万字书稿!
在撰写教材的过程中,总是难以避免“慢节奏”的所有坑。当框架和资料都已准备妥当时,却常常因为撰写内容而停滞不前——一句话反复斟酌半小时,仍觉得不够准确;章节间的衔接更是让人绞尽脑汁,找不到合适的表达方式&#…...

从SystemTap到ftrace:为什么Linux内核‘原装’的追踪工具更适合日常调试?
从SystemTap到ftrace:为什么Linux内核原生追踪工具更适合日常调试? 在Linux内核开发与性能优化领域,追踪工具的选择往往决定了问题排查的效率与系统稳定性。当面对SystemTap、eBPF/BCC和ftrace等工具时,资深开发者常陷入选择困境—…...