动手学深度学习(Pytorch版)代码实践 -卷积神经网络-28批量规范化
28批量规范化
"""可持续加速深层网络的收敛速度"""
import torch
from torch import nn
import liliPytorch as lp
import matplotlib.pyplot as pltdef batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):"""实现一个具有张量的批量规范化层。"""# 如果启用了梯度计算,torch.is_grad_enabled() 返回 True;否则返回 False。if not torch.is_grad_enabled():# torch.no_grad() 是一个上下文管理器,用于临时禁用梯度计算# torch.enable_grad() 是一个上下文管理器,用于在禁用梯度计算的上下文中重新启用梯度计算。X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)else:assert len(X.shape) in (2, 4)if len(X.shape) == 2:# 使用全连接层的情况,计算特征维上的均值和方差mean = X.mean(dim=0) # 计算张量 X 沿着第 0 维的平均值# 维度 0 代表样本数量,即沿着每个特征计算所有样本的平均值。var = ((X - mean) ** 2).mean(dim=0)else:# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。# 这里我们需要保持X的形状以便后面可以做广播运算mean = X.mean(dim=(0, 2, 3), keepdim=True)var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)# 训练模式下,用当前的均值和方差做标准化X_hat = (X - mean) / torch.sqrt(var + eps)# 更新移动平均的均值和方差moving_mean = momentum * moving_mean + (1.0 - momentum) * meanmoving_var = momentum * moving_var + (1.0 - momentum) * var# gamma 和 beta 的更新是通过反向传播和优化器自动完成的Y = gamma * X_hat + beta # 缩放和移位return Y, moving_mean.data, moving_var.dataclass BatchNorm(nn.Module):# num_features:完全连接层的输出数量或卷积层的输出通道数。# num_dims:2表示完全连接层,4表示卷积层def __init__(self, num_features, num_dims):super().__init__()if num_dims == 2:shape = (1, num_features)else:shape = (1, num_features, 1, 1)# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0self.gamma = nn.Parameter(torch.ones(shape))self.beta = nn.Parameter(torch.zeros(shape))# 非模型参数的变量初始化为0和1# 经过归一化处理后的数据均值接近于零。因此,将滑动均值初始化为0,是对数据初始均值的一种合理假设。self.moving_mean = torch.zeros(shape)# 方差表示数据的离散程度。将滑动方差初始化为1,意味着假设数据的初始方差为1,# 即数据分布接近标准正态分布。这样初始化可以避免初始阶段的数值不稳定。self.moving_var = torch.ones(shape)def forward(self, X):# 如果X不在内存上,将moving_mean和moving_var# 复制到X所在GPU上 if self.moving_mean.device != X.device:self.moving_mean = self.moving_mean.to(X.device)self.moving_var = self.moving_var.to(X.device)# 保存更新过的moving_mean和moving_varY, self.moving_mean, self.moving_var = batch_norm(X, self.gamma, self.beta, self.moving_mean,self.moving_var, eps=1e-5, momentum=0.9)return Y#使用批量规范化层的 LeNet
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), # 卷积层1:输入通道数1,输出通道数6,卷积核大小5x5,填充2BatchNorm(num_features=6, num_dims=4),nn.ReLU(), # 激活函数nn.AvgPool2d(kernel_size=2, stride=2), # 平均池化层1:池化窗口大小2x2,步幅2nn.Conv2d(6, 16, kernel_size=5), # 卷积层2:输入通道数6,输出通道数16,卷积核大小5x5BatchNorm(num_features=16, num_dims=4),nn.ReLU(), nn.AvgPool2d(kernel_size=2, stride=2), # 平均池化层2:池化窗口大小2x2,步幅2nn.Flatten(), # 展平层:将多维输入展平为1维nn.Linear(16 * 5 * 5, 120), # 全连接层1:输入节点数16*5*5,输出节点数120BatchNorm(num_features=120, num_dims=2),nn.ReLU(),nn.Linear(120, 84), # 全连接层2:输入节点数120,输出节点数84BatchNorm(num_features=84, num_dims=2),nn.ReLU(), nn.Linear(84, 10) # 全连接层3:输入节点数84,输出节点数10(对应10个分类)
)lr, num_epochs, batch_size = 1.0, 10, 256
train_iter, test_iter = lp.loda_data_fashion_mnist(batch_size)
# lp.train_ch6(net, train_iter, test_iter, num_epochs, lr, lp.try_gpu())
# plt.show()# loss 0.200, train acc 0.925, test acc 0.812
# 34957.3 examples/sec on cuda:0# loss 0.189, train acc 0.928, test acc 0.894
# 33471.2 examples/sec on cuda:0#简明实现
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6), nn.ReLU(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16), nn.ReLU(),nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),nn.Linear(256, 120), nn.BatchNorm1d(120), nn.ReLU(),nn.Linear(120, 84), nn.BatchNorm1d(84), nn.ReLU(),nn.Linear(84, 10)
)
lp.train_ch6(net, train_iter, test_iter, num_epochs, lr, lp.try_gpu())
plt.show()# nn.Sigmoid()
# loss 0.263, train acc 0.902, test acc 0.833
# 46935.0 examples/sec on cuda:0# nn.ReLU()
# loss 0.224, train acc 0.914, test acc 0.874
# 44479.2 examples/sec on cuda:0
"""
通常高级API变体运行速度快得多,因为它的代码已编译为C++或CUDA,而我们的自定义代码由Python实现。
"""

相关文章:
动手学深度学习(Pytorch版)代码实践 -卷积神经网络-28批量规范化
28批量规范化 """可持续加速深层网络的收敛速度""" import torch from torch import nn import liliPytorch as lp import matplotlib.pyplot as pltdef batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):""&quo…...
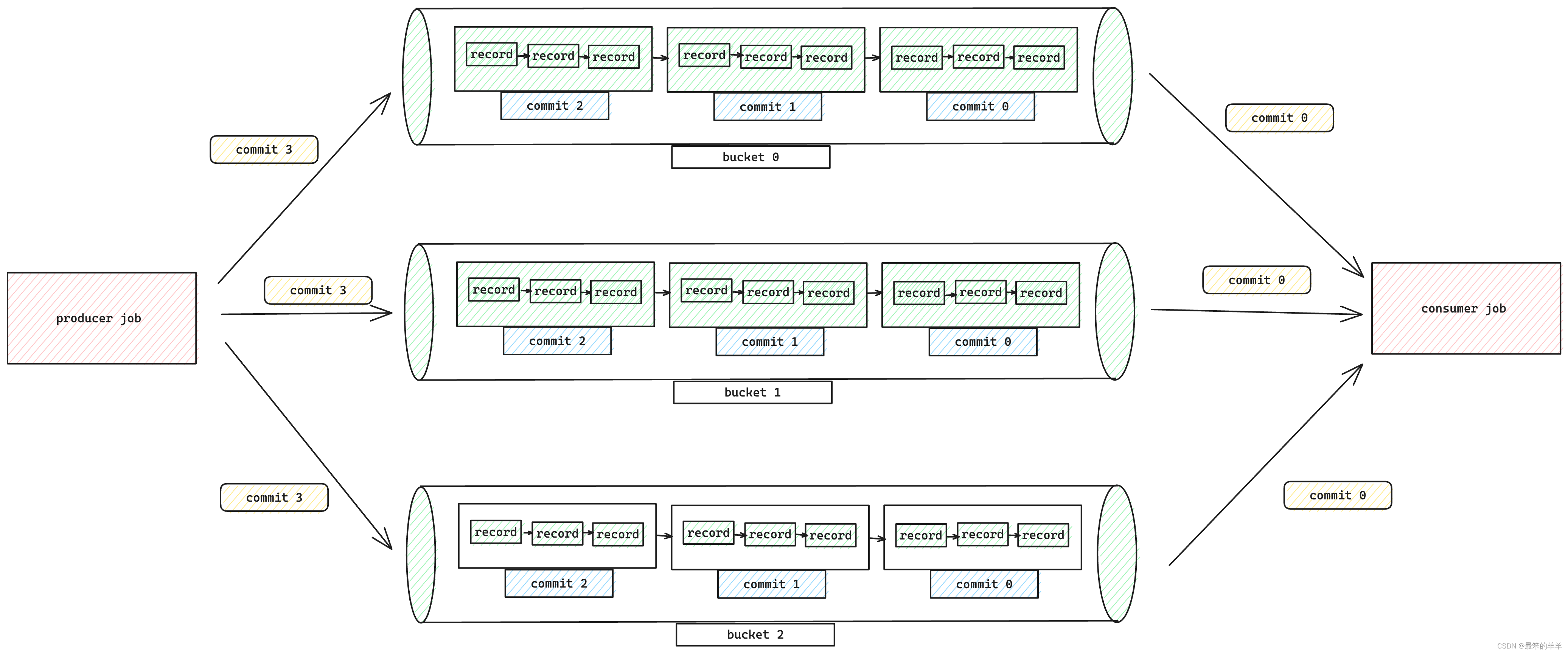
Apache Paimon系列之:Append Table和Append Queue
Apache Paimon系列之:Append Table和Append Queue 一、Append Table二、Data Distribution三、自动小文件合并四、Append Queue五、压缩六、Streaming Source七、Watermark Definition八、Bounded Stream 一、Append Table 如果表没有定义主键,则默认为…...

Vue使用vue-esign实现在线签名 加入水印
Vue在线签名 一、目的二、样式三、代码1、依赖2、代码2.1 在线签名组件2.1.1 基础的2.1.2 携带时间水印的 2.2父组件 一、目的 又来了一个问题,直接让我在线签名(还不能存储base64),并且还得上传,我直接***违禁词。 好…...

与码无关:分数限制下,选好专业还是选好学校?
本文的目标读者:24届的高考生和家长。 写这篇非技术性文章,是因为我看到了24届考生和21年的我同样迷茫。 事先声明,本文带有强烈的个人思考色彩,可能会引起不适,如有不同观点,欢迎在评论区讨论。 一、前言…...

什么是负载均衡技术?
随着网络技术的快速发展,互联网行业也越来越广泛,人们的日常生活中也离不开网络技术,大量的用户进行浏览访问网站时,企业会使用负载均衡技术,降低当前网站的负载,以此来提高网站的访问速度。 今天小编就来给…...

存在重复元素Ⅱ python3
存在重复元素Ⅱ 问题描述解题思路代码实现复杂度 问题描述 给你一个整数数组 nums 和一个整数 k ,判断数组中是否存在两个 不同的索引 i 和 j ,满足 nums[i] nums[j] 且 abs(i - j) < k 。如果存在,返回 true ;否则ÿ…...
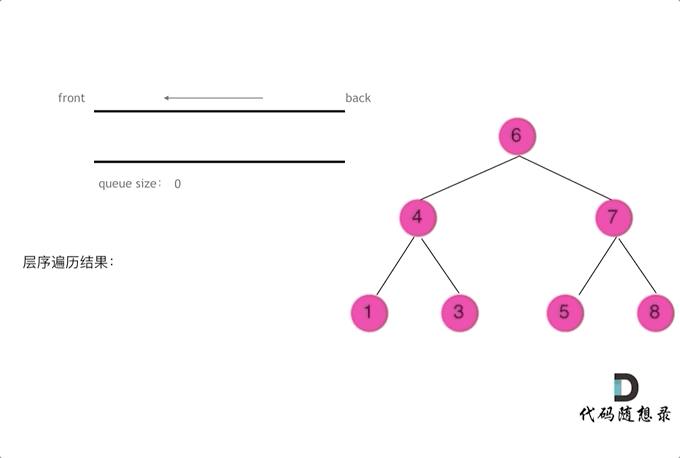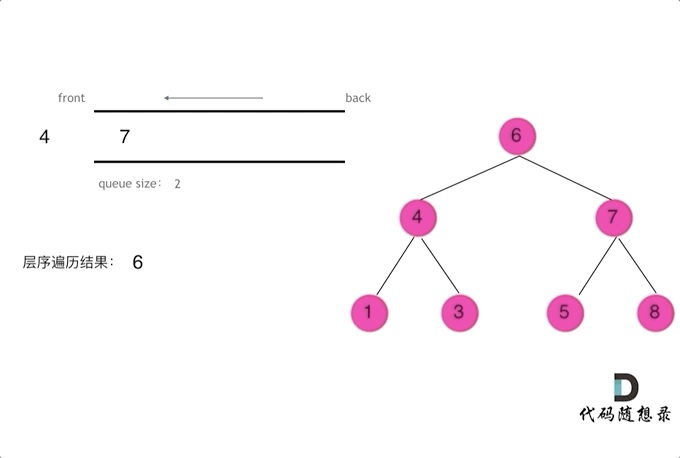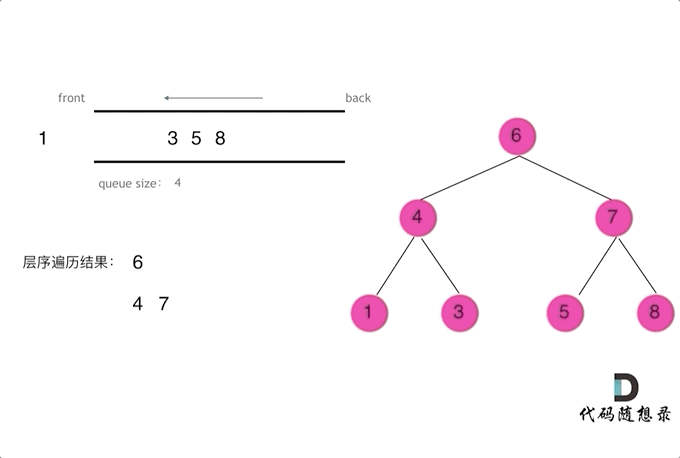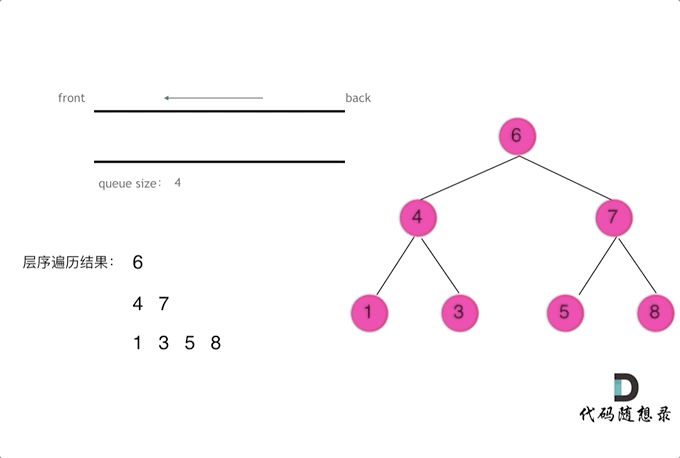
【CV炼丹师勇闯力扣训练营 Day13:§6二叉树1】
CV炼丹师勇闯力扣训练营 代码随想录算法训练营第13天 二叉树的递归遍历 二叉树的迭代遍历、统一迭代 二叉树的层序遍历 一、二叉树的递归遍历(深度优先搜索) 【递归步骤】 1.确定递归函数的参数和返回值:确定哪些参数是递归的过程中需要处理…...

代码随想录算法训练营第46天 [ 121. 买卖股票的最佳时机 122.买卖股票的最佳时机II 123.买卖股票的最佳时机III ]
代码随想录算法训练营第46天 [ 121. 买卖股票的最佳时机 122.买卖股票的最佳时机II 123.买卖股票的最佳时机III ] 一、121. 买卖股票的最佳时机 链接: 代码随想录. 思路:dp[i][0] 第i天持有股票的最大利润 dp[i][1] 第i天不持有股票的最大利润 做题状态:…...

基于IDEA的Maven简单工程创建及结构分析
目录 一、用 mvn 命令创建项目 二、用 IDEA 的方式来创建 Maven 项目。 (1)首先在 IDEA 下的 Maven 配置要已经确保完成。 (2)第二步去 new 一个 project (创建一个新工程) (3)…...
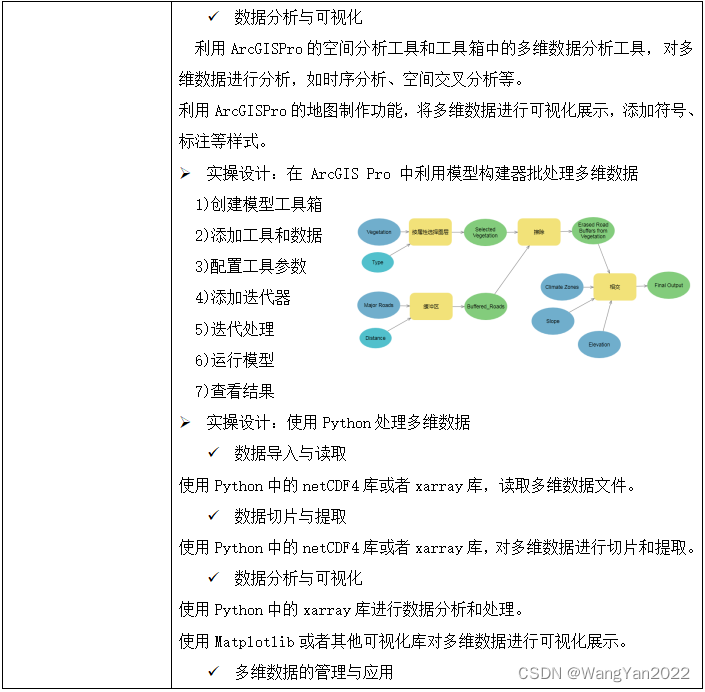
解锁空间数据奥秘:ArcGIS Pro与Python双剑合璧,处理表格数据、矢量数据、栅格数据、点云数据、GPS数据、多维数据以及遥感云平台数据等
ArcGISPro提供了用户友好的图形界面,适合初学者快速上手进行数据处理和分析。它拥有丰富的工具和功能,支持各种数据格式的处理和分析,适用于各种规模的数据处理任务。ArcGISPro在地理信息系统(GIS)领域拥有广泛的应用&…...

后端路线指导(4):后端春招秋招经验分享
后端春招&秋招经验分享 春招(暑期实习) /秋招是应届生非常重要的应聘时间,每一个想就业的同学一定要有所了解! 本篇内容,老白将与大家分享暑期实习和秋招如何应对招聘的个人经验,希望每个同学看完都能有所收获! 首先说明一下老白对于面试核心竞争力的…...

面完小红书算法岗,心态崩了。。。
暑期实习基本结束了,校招即将开启。 不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。提前准备才是完全之策。 最近,我们又陆续整理了很多大厂的面试题,…...
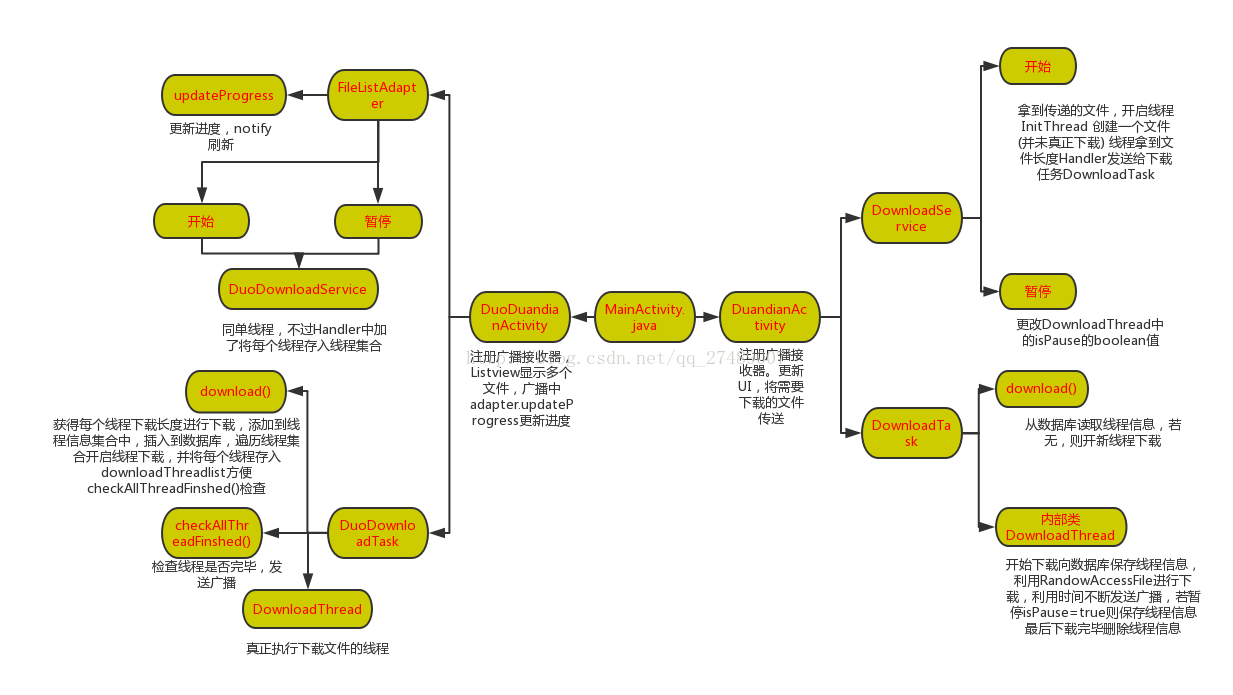
Android 断点续传进阶之多线程下载
今天继续下载的风骚走位内容—多线程多文件断点续传 Android 断点续传基础之单线程下载:http://blog.csdn.net/qq_27489007/article/details/53897653 效果图: 文件关系: 所需内容 多文件下载列表的显示 启动多个线程分段下载 使用通知栏…...

Python爬虫学习 | Scrapy框架详解
一.Scrapy框架简介 何为框架,就相当于一个封装了很多功能的结构体,它帮我们把主要的结构给搭建好了,我们只需往骨架里添加内容就行。scrapy框架是一个为了爬取网站数据,提取数据的框架,我们熟知爬虫总共有四大部分&am…...
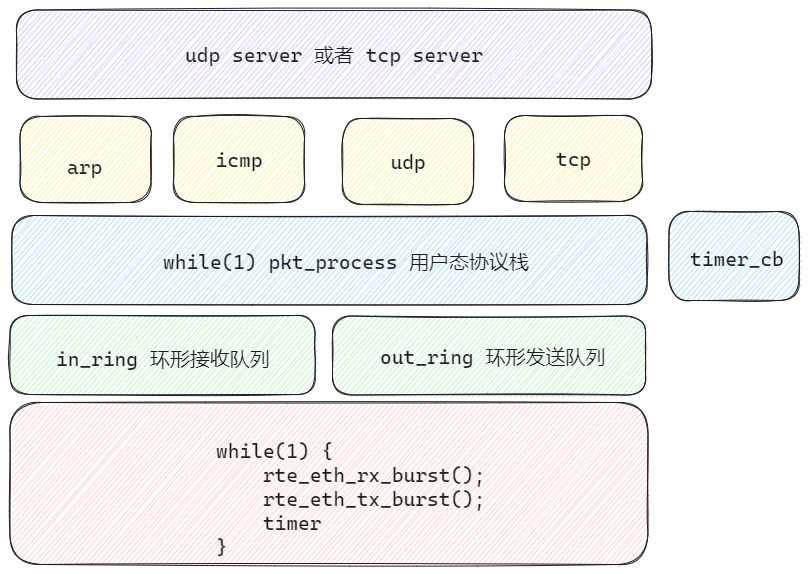
用户态协议栈05—架构优化
优化部分 添加了in和out两个环形缓冲区,收到数据包后添加到in队列;经过消费者线程处理之后,将需要发送的数据包添加到out队列。添加数据包解析线程(消费者线程),架构分层 #include <rte_eal.h> #inc…...

模拟退火算法
模拟退火算法(Simulated Annealing, SA)是一种用于全局优化问题的概率搜索算法,其灵感来自于金属退火过程。在金属退火中,材料被加热到高温,然后缓慢冷却,以减少其晶格中的缺陷并达到最小能量状态。模拟退火…...

Java匿名类
Java 匿名类是一种特殊的内部类,它没有名字,并且通常用来简化代码实现,尤其是在实现接口或者抽象类的实例时。匿名类可以在实例化时定义其行为,而不需要创建单独的类文件。 匿名类的特点 没有名字:匿名类是没有名字的…...

G7易流赋能化工物流,实现安全、环保与效率的共赢
近日,中国物流与采购联合会在古都西安举办了备受瞩目的第七届化工物流安全环保发展论坛。以"坚守安全底线,追求绿色发展,智能规划化工物流未来"为主题,该论坛吸引了众多政府部门、行业专家和企业代表的参与。G7易流作为…...
)
y=sin(2x)
函数 \( y \sin(2x) \) 是一个正弦函数,其中 \( x \) 是自变量,\( y \) 是因变量。这个函数描述了一个周期性波动的波形,其特点是: 1. **振幅**:正弦函数的振幅是 1,这意味着波形在 \( y \) 轴上的最大值…...

快捷方式(lnk)--加载HTA-CS上线
免责声明:本文仅做技术交流与学习... 目录 CS: HTA文档 文件托管 借助mshta.exe突破 本地生成lnk快捷方式: 非系统图标路径不同问题: 关于lnk的上线问题: CS: HTA文档 配置监听器 有效载荷---->HTA文档--->选择监听器--->选择powershell模式----> 默认生成一…...

探索SillyTavern:为AI角色注入灵魂的PNG元数据魔法
探索SillyTavern:为AI角色注入灵魂的PNG元数据魔法 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 想象一下,当你分享一张角色图片时,你实际上是在分享一…...

apk 包管理器完全指南:Alpine Linux 的轻量级利器
一、apk 体系架构全景 apk(Alpine Package Keeper)是 Alpine Linux 的核心包管理工具,与 Debian 的 APT 相比,它遵循极简主义设计哲学:代码量少、依赖解析简单、资源占用极低。这使得 Alpine 成为 Docker 容器的默认基…...

基于Adafruit TRRS Trinkey构建低成本无障碍鼠标键盘模拟器与开关控制器
1. 项目概述:为无障碍交互打开一扇新窗在数字时代,鼠标和键盘是我们与计算机交互最直接的桥梁。然而,对于许多因运动神经元疾病、脊髓损伤、脑瘫或其他肢体障碍而无法使用传统输入设备的朋友来说,这座桥梁却显得遥不可及。作为一名…...

Manus开源框架:高效探索与开发灵巧手抓取技能
1. 项目概述与核心价值最近在机器人抓取领域,一个名为“Manus Open Claw Skill Hunter and Developer”的项目引起了我的注意。这个项目由Simplio Labs开源,它不是一个具体的硬件爪子,也不是一个单一的算法,而是一个专门用于发现、…...

基于n8n与Puppeteer的LinkedIn求职自动化:从原理到部署实践
1. 项目概述:一个为求职者打造的自动化“侦察兵”如果你正在找工作,或者曾经找过工作,那你一定对“海投”这个词不陌生。每天花几个小时,在各大招聘网站上重复填写个人信息、上传简历、回答同样的问题,最后却往往石沉大…...

告别臃肿软件!OmenSuperHub:惠普暗影精灵的纯净硬件控制神器
告别臃肿软件!OmenSuperHub:惠普暗影精灵的纯净硬件控制神器 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 厌倦了官方Omen Gamin…...

网络安全5大高薪赛道,哪条是你的职业快车道?
1. 政企安全:国家队的黄金赛道 政企安全领域就像网络安全行业的"公务员体系",稳定性和薪资待遇都处于行业头部水平。我接触过不少从互联网公司转行做政企安全的工程师,他们普遍反馈"虽然加班也不少,但项目预算充足…...

云原生环境中的混沌工程实践指南
云原生环境中的混沌工程实践指南 引言 混沌工程是一种主动验证系统可靠性的方法,通过在生产环境中注入故障来发现潜在的系统弱点。本文将深入探讨如何在云原生环境中实施混沌工程。 一、混沌工程概述 1.1 核心概念 ┌───────────────────────…...

利用Taotoken用量看板精细化管理团队大模型API消费
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken用量看板精细化管理团队大模型API消费 对于团队管理者而言,在引入大模型能力后,一个普遍存在的…...

嵌入式硬件设计中的“隐形保镖”:电压跟随电路如何让你的系统更稳定?
嵌入式硬件设计中的“隐形保镖”:电压跟随电路如何让你的系统更稳定? 在复杂的嵌入式系统中,信号链的完整性往往决定了整个产品的可靠性。想象一下,当你精心设计的传感器数据经过长距离传输后,最终到达MCU时却出现了严…...