深入探索 MongoDB GridFS:高效大文件存储与管理的全面指南
GridFS 是 MongoDB 的一个规范,用于存储和检索超过 BSON 文档大小限制(16MB)的文件。与传统的文件系统不同,GridFS 可以将一个大文件分割成多个小块,并存储在 MongoDB 的两个集合中:fs.files 和 fs.chunks。这种方式不仅解决了大文件存储问题,还能实现对文件内容的高效检索和管理。
基本语法和命令
安装 MongoDB 和 pymongo
首先,确保安装了 MongoDB 并且已经启动。然后使用以下命令安装 Python 的 pymongo 库:
pip install pymongo
GridFS 基本操作
- 导入必要的库
from pymongo import MongoClient
import gridfs
- 连接到 MongoDB 数据库
client = MongoClient('mongodb://localhost:27017/')
db = client['mydatabase']
- 创建 GridFS 实例
fs = gridfs.GridFS(db)
- 上传文件
with open('example.txt', 'rb') as file:fs.put(file, filename='example.txt')
- 下载文件
file_data = fs.get_last_version(filename='example.txt').read()
with open('downloaded_example.txt', 'wb') as file:file.write(file_data)
- 查找文件
file_info = fs.find_one({'filename': 'example.txt'})
if file_info:print("File found:", file_info.filename)
else:print("File not found")
- 删除文件
fs.delete(file_info._id)
示例代码
上传文件示例
from pymongo import MongoClient
import gridfs# 连接数据库
client = MongoClient('mongodb://localhost:27017/')
db = client['mydatabase']
fs = gridfs.GridFS(db)# 上传文件
with open('example.txt', 'rb') as file:fs.put(file, filename='example.txt')
下载文件示例
# 下载文件
file_data = fs.get_last_version(filename='example.txt').read()
with open('downloaded_example.txt', 'wb') as file:file.write(file_data)
查找和删除文件示例
# 查找文件
file_info = fs.find_one({'filename': 'example.txt'})
if file_info:print("File found:", file_info.filename)# 删除文件fs.delete(file_info._id)
else:print("File not found")
应用场景
GridFS 是 MongoDB 的一个用于存储和检索大文件的规范。它可以将一个大文件拆分成多个小块,存储在 MongoDB 集合中,并且提供了一套 API 用于文件的存储和读取。下
1. 大文件存储
说明:GridFS 适用于存储超过 BSON 限制(16 MB)的文件,比如视频、音频、图像等。它通过将大文件拆分成小块(默认每块 255 KB),并将这些块存储在 MongoDB 的 fs.chunks 集合中,同时在 fs.files 集合中存储文件的元数据。
示例代码:
from pymongo import MongoClient
from gridfs import GridFSclient = MongoClient('mongodb://localhost:27017/')
db = client['mydatabase']
fs = GridFS(db)# 存储大文件
with open('large_video.mp4', 'rb') as file:fs.put(file, filename='large_video.mp4')print("大文件存储完成")
2. 文件版本控制
说明:GridFS 允许存储同名文件的多个版本,每个文件版本都会有一个版本号(version),可以通过版本号来管理和访问不同的文件版本。
示例代码:
# 存储文件的不同版本
with open('document_v1.txt', 'rb') as file:fs.put(file, filename='document.txt', version=1)with open('document_v2.txt', 'rb') as file:fs.put(file, filename='document.txt', version=2)print("文件版本控制存储完成")# 读取特定版本的文件
file_v1 = fs.get_version('document.txt', version=1)
print(file_v1.read().decode('utf-8'))file_v2 = fs.get_version('document.txt', version=2)
print(file_v2.read().decode('utf-8'))
3. 分布式文件存储
说明:GridFS 与 MongoDB 的集群能力结合,适用于分布式系统中的文件存储需求。通过将文件存储在 MongoDB 集群中,GridFS 可以提供高可用性和水平扩展能力。
示例代码(假设已配置 MongoDB 集群):
# 连接到 MongoDB 集群
client = MongoClient('mongodb://cluster0-shard-00-00.mongodb.net:27017,cluster0-shard-00-01.mongodb.net:27017,cluster0-shard-00-02.mongodb.net:27017/?replicaSet=Cluster0-shard-0')
db = client['distributed_database']
fs = GridFS(db)# 存储文件到分布式数据库中
with open('distributed_file.txt', 'rb') as file:fs.put(file, filename='distributed_file.txt')print("分布式文件存储完成")
4. 跨平台文件共享
说明:通过将文件存储在 MongoDB 中,GridFS 实现了跨平台的文件共享和访问。任何支持 MongoDB 的平台都可以访问这些文件。
示例代码:
# 存储文件
with open('shared_file.txt', 'rb') as file:fs.put(file, filename='shared_file.txt')print("文件存储完成,可以跨平台共享")# 从其他平台读取文件
client_other_platform = MongoClient('mongodb://localhost:27017/')
db_other_platform = client_other_platform['mydatabase']
fs_other_platform = GridFS(db_other_platform)shared_file = fs_other_platform.get_last_version('shared_file.txt')
print(shared_file.read().decode('utf-8'))
通过以上示例代码,可以看到 GridFS 的多种应用场景,包括大文件存储、文件版本控制、分布式文件存储以及跨平台文件共享。GridFS 提供了灵活的文件存储解决方案,适用于各种需求。
注意事项
1. 性能考虑
说明:尽管 GridFS 适合存储大文件,但在高性能应用中,读写性能和网络带宽是关键因素。特别是在高并发访问场景下,频繁的文件读写操作可能导致性能瓶颈。此外,网络带宽的限制也会影响大文件的传输速度。
示例场景:
一个在线视频平台需要存储和流式传输大量高清视频文件。为了提高性能,可以使用如下策略:
- 使用 CDN 加速文件传输。
- 采用合适的文件块大小,以平衡传输性能和数据库查询效率。
- 优化数据库连接池,以支持高并发访问。
示例代码:
# 使用连接池优化数据库连接
from pymongo import MongoClient
from gridfs import GridFSclient = MongoClient('mongodb://localhost:27017/', maxPoolSize=50)
db = client['videoplatform']
fs = GridFS(db)# 存储大文件时设置合适的块大小
with open('high_quality_video.mp4', 'rb') as file:fs.put(file, filename='high_quality_video.mp4', chunkSize=1024*1024) # 1MB 块大小print("高性能大文件存储完成")
2. 索引优化
说明:对 fs.files 和 fs.chunks 集合进行索引优化,可以显著提高文件检索和读取速度。常见的索引包括对文件名、上传时间、文件 ID 等字段建立索引。
示例场景:
一个文档管理系统需要快速检索和访问存储在 GridFS 中的文档文件。可以通过建立索引来优化查询性能。
示例代码:
# 创建索引以优化查询性能
db['fs.files'].create_index([('filename', 1)])
db['fs.files'].create_index([('uploadDate', 1)])
db['fs.chunks'].create_index([('files_id', 1), ('n', 1)])print("索引优化完成")# 快速检索文件
file = fs.find_one({'filename': 'important_document.pdf'})
print(file.read().decode('utf-8'))
3. 文件碎片化
说明:在 GridFS 中,大文件被拆分成多个小块存储。在删除文件时,需要确保所有相关的块都被正确删除,以免造成数据碎片和存储浪费。
示例场景:
一个日志管理系统需要定期删除过期的日志文件,以释放存储空间。必须确保删除文件时,相关的所有块都被正确删除。
示例代码:
# 删除过期日志文件及其所有块
file_to_delete = fs.find_one({'filename': 'old_log_file.log'})
if file_to_delete:fs.delete(file_to_delete._id)print("过期日志文件删除完成")
else:print("未找到文件")
4. 文件安全
说明:存储敏感文件时,需要考虑文件的加密和访问控制。可以在文件上传前进行加密,并在检索时进行解密。此外,可以结合 MongoDB 的权限控制,限制对文件的访问。
示例场景:
一个医疗系统需要存储患者的医疗记录文件,这些文件需要加密存储,并且只有授权用户才能访问。
示例代码:
from cryptography.fernet import Fernet
import base64# 生成密钥
key = Fernet.generate_key()
cipher_suite = Fernet(key)# 加密文件内容
with open('patient_record.pdf', 'rb') as file:encrypted_data = cipher_suite.encrypt(file.read())fs.put(encrypted_data, filename='patient_record.pdf', metadata={'encryption_key': base64.b64encode(key).decode('utf-8')})print("文件加密并存储完成")# 解密文件内容
file = fs.find_one({'filename': 'patient_record.pdf'})
if file:key = base64.b64decode(file.metadata['encryption_key'])cipher_suite = Fernet(key)decrypted_data = cipher_suite.decrypt(file.read())with open('decrypted_patient_record.pdf', 'wb') as decrypted_file:decrypted_file.write(decrypted_data)print("文件解密完成")
通过这些示例代码,可以看到在不同应用场景中,如何处理性能考虑、索引优化、文件碎片化以及文件安全问题。这样可以更好地利用 GridFS 的功能,并确保系统的高效和安全运行。
总结
MongoDB 的 GridFS 提供了一种在数据库中存储大文件的有效方法,解决了 BSON 文档大小限制的问题。通过将大文件分割成小块存储,GridFS 实现了高效的文件管理和检索能力。虽然在性能和管理上有一定挑战,但通过合理的优化和使用,GridFS 可以成为大文件存储和管理的有效解决方案。
使用 GridFS 需要注意性能优化和文件管理,适用于大文件存储、文件版本控制和分布式文件存储等应用场景。理解和掌握 GridFS 的基本操作和注意事项,可以有效提升 MongoDB 在实际项目中的应用价值。
相关文章:

深入探索 MongoDB GridFS:高效大文件存储与管理的全面指南
GridFS 是 MongoDB 的一个规范,用于存储和检索超过 BSON 文档大小限制(16MB)的文件。与传统的文件系统不同,GridFS 可以将一个大文件分割成多个小块,并存储在 MongoDB 的两个集合中:fs.files 和 fs.chunks。…...
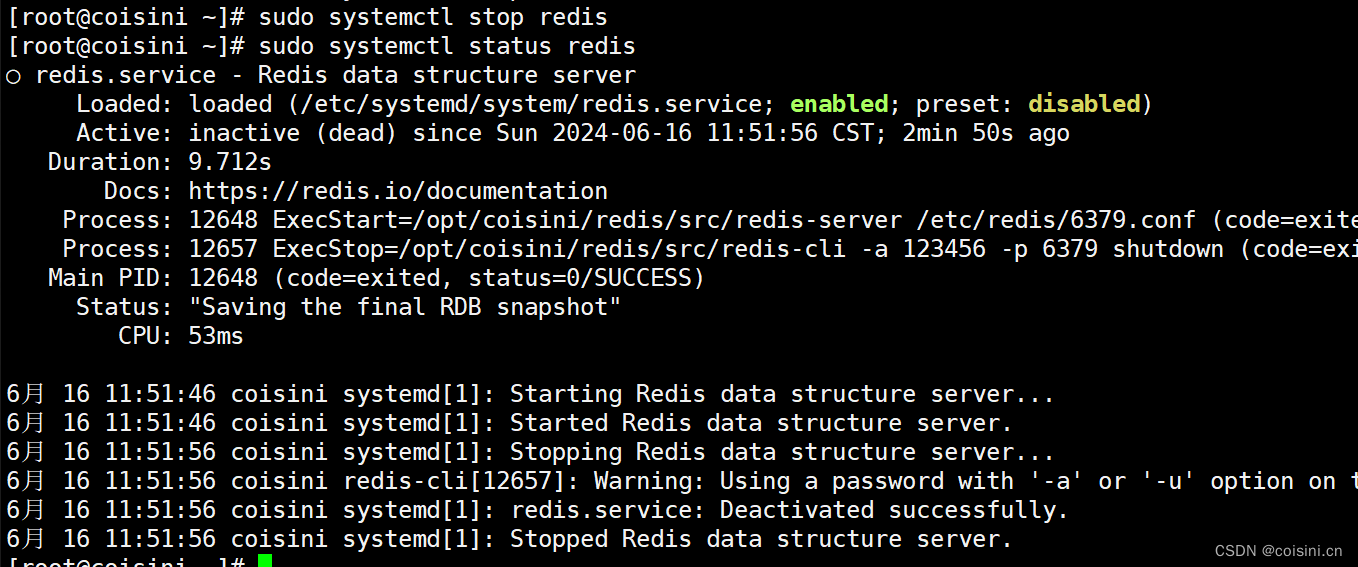
基于CentOS Stream 9平台 安装/卸载 Redis7.0.15
已更正systemctl管理Redis服务问题 1. 官方下载地址 https://redis.io/downloads/#redis-downloads 1.1 下载或上传到/opt/coisini目录下: mkdir /opt/coisini cd /opt/coisini wget https://download.redis.io/releases/redis-7.0.15.tar.gz2. 解压 tar -zxvf re…...

激励-保健理论和公平理论
激励-保健理论 herzberg的激励-保健理论中,保健因素是context of a job,激励因素是content of a job。 context of a job是受组织控制的因素,比如工作条件,基本工资,公司政策等,个人无法支配。content of…...

深入探索 Spring Boot 自定义启动画面
目录 引言什么是 Spring Boot 启动画面Spring Boot 默认启动画面为什么要自定义启动画面如何自定义 Spring Boot 启动画面 修改配置文件使用 Banner 接口通过图片实现启动画面ASCII 艺术画的应用 进阶:基于环境变量的动态 Banner多模块项目中的启动画面Spring Boot…...
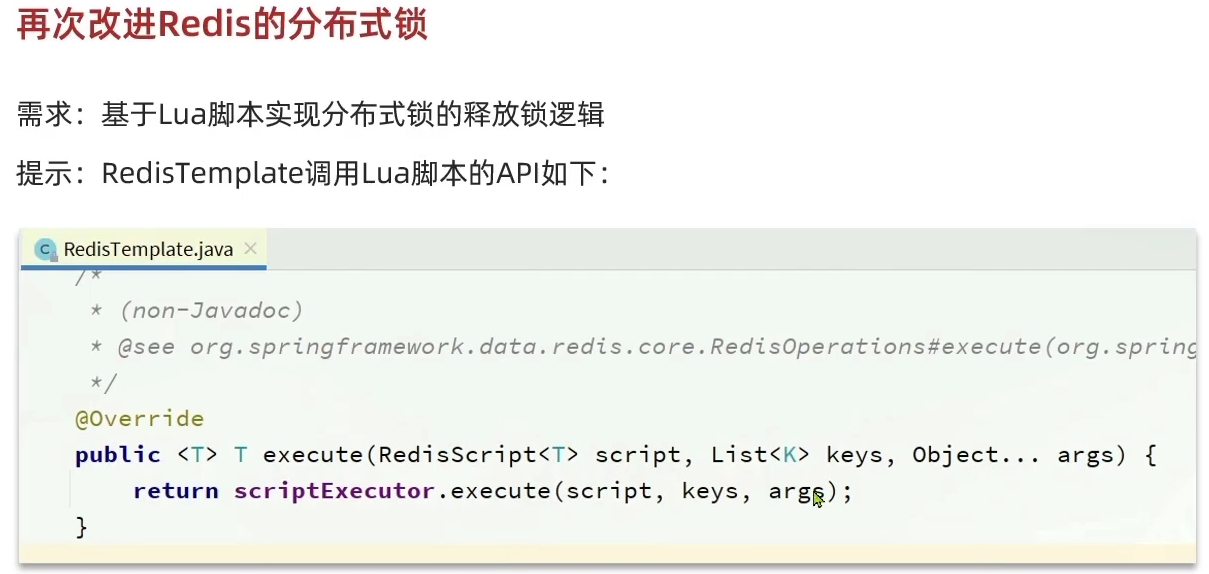
Redis实战—Redis分布式锁
本博客为个人学习笔记,学习网站与详细见:黑马程序员Redis入门到实战 P56 - P63 目录 分布式锁介绍 基于Redis的分布式锁 Redis锁代码实现 修改业务代码 分布式锁误删问题 分布式锁原子性问题 Lua脚本 编写脚本 代码优化 总结 分布式锁介绍…...

联想Y7000P 2023款拆机教程及升级内存教程
0.电脑参数介绍 联想Y7000P 2023电脑,笔者电脑CPU为i7-13700H,14核20线程;标配内存为三星的DDR5-5600MHz-8GB*2,由于电脑CPU限制,实际内存跑的频率为5200MHz; 2个内存插槽,2个固态硬盘插槽。每个内存插槽最…...

开发常用依赖
目录 代理对象 Swagger Web 单元测试 MybatisPlus Lombok Mysql SpringBoot Jdk SpringCloud 数据库驱动包 hutool工具 配置仓库 通用库 maven插件 nacos注册中心 OpenFeign Spring AMQP JSON转换器 Redis 邮箱验证 Redisson分布式锁 客户端 代理对象 &l…...
【区分vue2和vue3下的element UI Empty 空状态组件,分别详细介绍属性,事件,方法如何使用,并举例】
在 Element UI(为 Vue 2 设计)和 Element Plus(为 Vue 3 设计)中,Empty(空状态)组件通常用于在数据为空或没有内容时向用户展示一种占位提示。然而,需要注意的是,Element…...
【AI作曲】毁掉音乐?早该来了!一个网易音乐人对于 AI 大模型音乐创作的思辨
引言:AI在创造还是毁掉音乐? 正如当初 midjourney 和 StableDiffusion 在绘画圈掀起的风波一样,suno 和 各大音乐大模型的来临,其实早该来了。 AI 在毁掉绘画?或者毁掉音乐? 没错,但也错了。…...
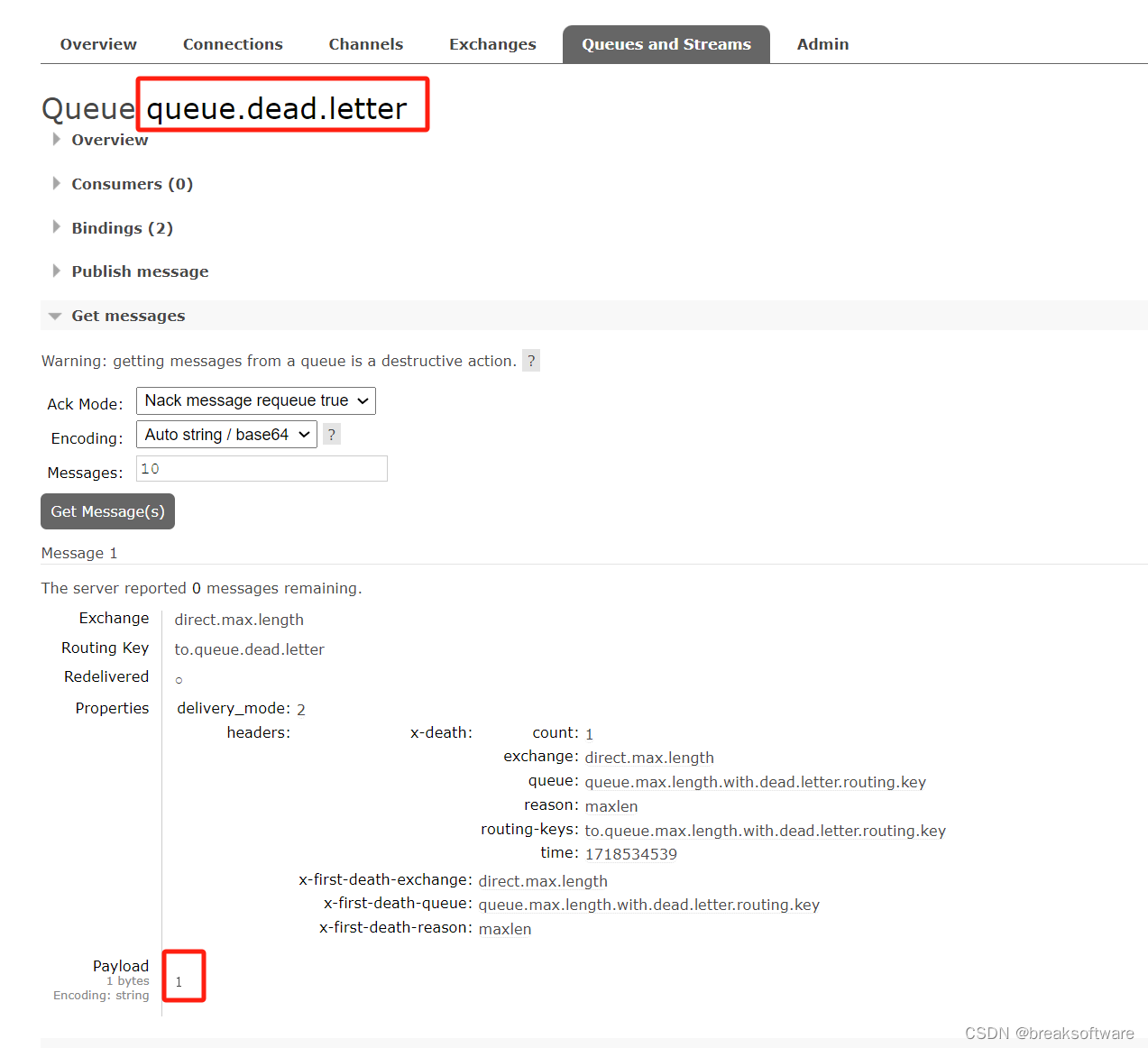
RabbitMQ实践——最大长度队列
大纲 抛弃消息创建最大长度队列绑定实验 转存死信创建死信队列创建可重写Routing key的最大长度队列创建绑定关系实验 在一些业务场景中,我们只需要保存最近的若干条消息,这个时候我们就可以使用“最大长度队列”来满足这个需求。该队列在收到消息后&…...
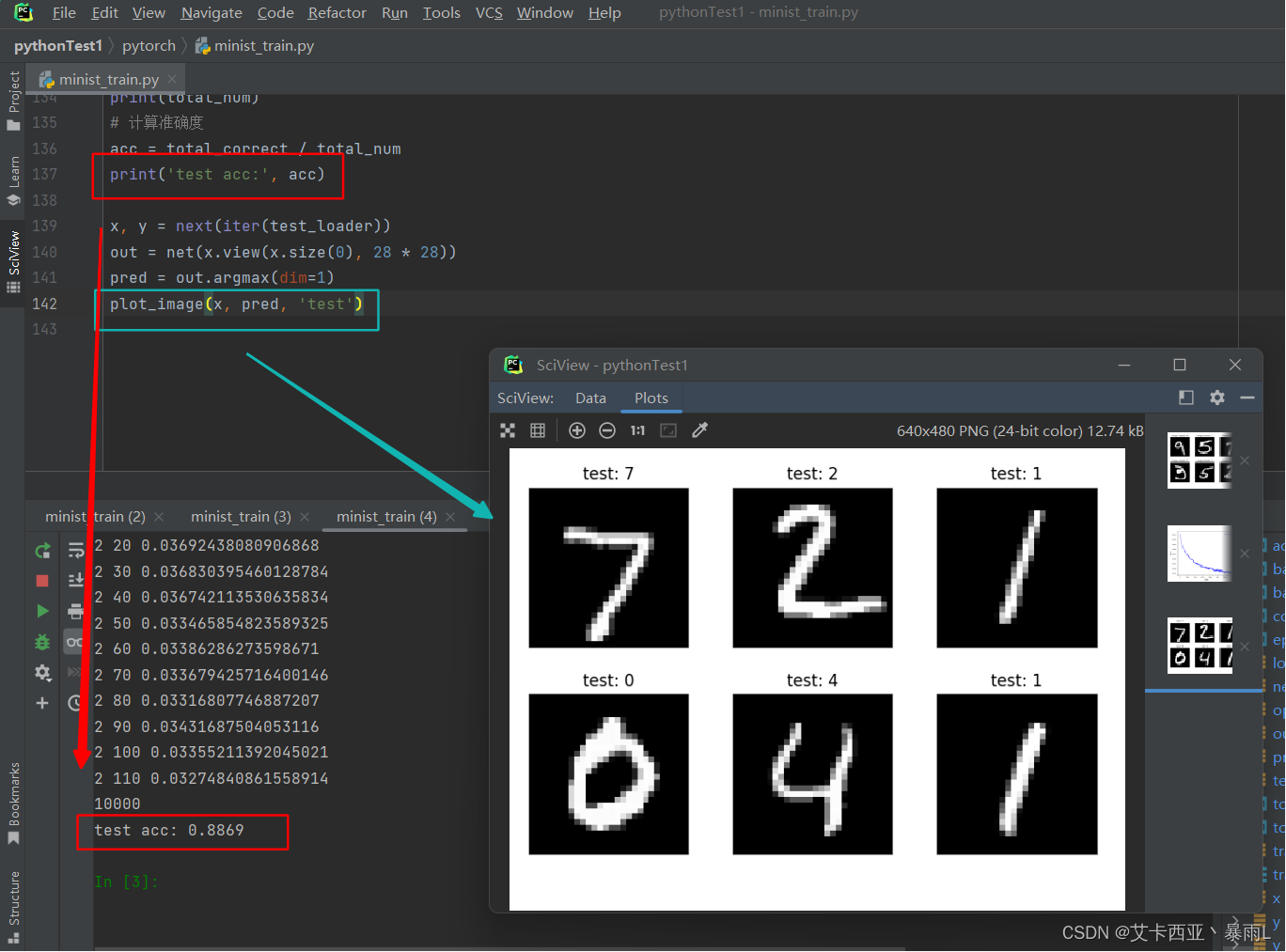
【pytorch02】手写数字问题引入
1.数据集 现实生活中遇到的问题 车牌识别身份证号码识别快递单的识别 都会涉及到数字识别 MNIST(收集了很多人手写的0到9数字的图片) 每个数字拥有7000个图像train/test splitting:60k vs 10k 图片大小28 28 数据集划分成训练集和测试集合的意义…...

【查看显卡信息】——Ubuntu和windows
1、VMware虚拟机 VMware虚拟机上不能使用CUDA/CUDNN,也安装不了显卡驱动 查看显卡信息: lspci | grep -i vga 不会显示显卡信息,只会输出VMware SVGA II Adapter,表示这是一个虚拟机,无法安装和使用显卡驱动 使用上…...

在 RK3568 上构建 Android 11 模块:深入解析 m、mm、mmm 编译命令
目录 Android 编译系统概述编译命令简介 环境准备使用 m、mm、mmm 编译模块编译整个源码树编译单个模块编译指定目录下的模块 高级应用并行编译清理编译结果编译特定配置 在 Android 开发中,特别是在 RK3568 这样的高性能平台上,有效地编译和管理模块是确…...

实战|YOLOv10 自定义目标检测
引言 YOLOv10[1] 概述和使用自定义数据训练模型 概述 由清华大学的研究团队基于 Ultralytics Python 包研发的 YOLOv10,通过优化模型结构并去除非极大值抑制(NMS)环节,提出了一种创新的实时目标检测技术。这些改进不仅实现了行业领…...

TTS前端原理学习 chatgpt生成答案
第一篇文章学习 小绿鲸阅读器 通篇使用chatgpt生成答案 文章: https://arxiv.org/pdf/2012.15404 1. 文章概述 本文提出了一种基于Distilled BERT模型的统一普通话文本到语音前端模块。该模型通过预训练的中文BERT作为文本编码器,并采用多任务学习技术…...

AI“音乐创作”横行给音乐家带来哪些隐忧
近日,200多名国际乐坛知名音乐人联署公开信,呼吁AI开发者、科技公司、平台和数字音乐服务商停止使用人工智能(AI)来侵犯并贬低人类艺术家的权利,具体诉求包括,停止使用AI侵犯及贬低人类艺术家的权利,要求…...

SolidityFoundry 安全审计测试 Delegatecall漏洞2
名称: Delegatecall漏洞2 https://github.com/XuHugo/solidityproject/tree/master/vulnerable-defi 描述: 我们已经了解了delegatecall 一个基础的漏洞——所有者操纵漏洞,这里就不再重复之前的基础知识了,不了解或者遗忘的可…...

【字符串 状态机动态规划】1320. 二指输入的的最小距离
本文涉及知识点 动态规划汇总 字符串 状态机动态规划 LeetCode1320. 二指输入的的最小距离 二指输入法定制键盘在 X-Y 平面上的布局如上图所示,其中每个大写英文字母都位于某个坐标处。 例如字母 A 位于坐标 (0,0),字母 B 位于坐标 (0,1)࿰…...
【AI测试版】)
2024.06.23【读书笔记】丨生物信息学与功能基因组学(第十七章 人类基因组 第三部分)【AI测试版】
第三部分:人类基因组的深入分析与比较基因组学 摘要: 本部分基于2001年国际人类基因组测序联盟(IHGSC)发布的人类基因组测序及分析草图,从生物信息学角度深入讨论了人类基因组的结构特征和分析方法。同时,提及了塞莱拉公司(Celera Genomics)版本的人类基因组草图及其…...
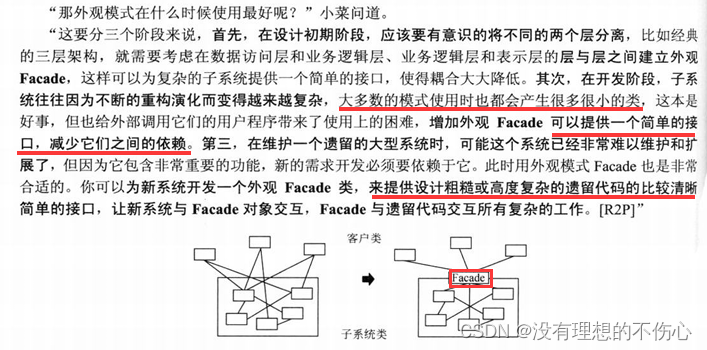
外观模式(大话设计模式)C/C++版本
外观模式 C #include <iostream> using namespace std;class stock1 { public:void Sell(){cout << "股票1卖出" << endl;}void Buy(){cout << "股票1买入" << endl;} };class stock2 { public:void Sell(){cout << …...
项目推荐:深入理解与掌握正交频分复用技术)
OFDM仿真(Matlab)项目推荐:深入理解与掌握正交频分复用技术
OFDM仿真(Matlab)项目推荐:深入理解与掌握正交频分复用技术 【下载地址】OFDM仿真matlab完整可运行 本资源提供了一个完整的OFDM(正交频分复用)仿真代码,基于Matlab平台开发。该仿真代码包含了OFDM系统中的多个关键模块࿰…...

多臂老虎机问题——一个面向初学者的指南
原文:towardsdatascience.com/the-multi-armed-bandit-problem-a-beginner-friendly-guide-2293ce7d8da8 多臂老虎机 (MAB) 是决策中的一个经典问题,其中代理必须在多个选项(称为“臂”)之间进行选择,并在一系列试验中…...

CVPR2021明星算法LoFTR实战:在Ubuntu 20.04上从零搭建Python 3.7+Pytorch 1.6.0环境,跑通第一个图像匹配Demo
CVPR2021明星算法LoFTR实战:在Ubuntu 20.04上从零搭建Python 3.7Pytorch 1.6.0环境,跑通第一个图像匹配Demo 计算机视觉领域每年都会涌现出大量创新算法,而CVPR2021上发表的LoFTR(Detector-Free Local Feature Matching with Tran…...

如何用Fetch实现高效Android文件下载:10个实用技巧
如何用Fetch实现高效Android文件下载:10个实用技巧 【免费下载链接】Fetch The best file downloader library for Android 项目地址: https://gitcode.com/gh_mirrors/fetch/Fetch Fetch是Android平台上最强大的文件下载管理器库之一,专为开发者…...
:图灵的答案)
从沙子到车辙(1.3):图灵的答案
1.3 图灵的答案 那个跑步穿过剑桥的人 1935 年,剑桥大学国王学院。一个 23 岁的研究生躺在草地上,望着天空,想着一件事: 什么是"计算"? 他叫艾伦图灵(Alan Turing)。 这个年轻人…...

如何快速构建高质量双语学习材料:Lingtrain Aligner文本对齐工具完全指南
如何快速构建高质量双语学习材料:Lingtrain Aligner文本对齐工具完全指南 【免费下载链接】lingtrain-aligner Lingtrain Aligner — ML powered library for the accurate texts alignment. 项目地址: https://gitcode.com/gh_mirrors/li/lingtrain-aligner …...

强烈的“似曾相识“感:由于人类左右大脑处理信息的速度并非完全同步,在某些特殊瞬间,这个流程会被打乱
海马效应(既视现象) 目录 海马效应(既视现象) 核心科学原理 高发场景与人群 典型例子 海马效应,科学上称为既视现象(Dj vu),是指人在从未真实经历过的当下场景中,突然产生强烈的"似曾相识"感,误以为眼前的一切曾经发生过的认知错觉。它并非玄学中的"…...

央视刷屏燃了!82 岁“中国刻蚀机之父”放狠话:我们已有能力来做最先进的设备
5 月 16 日央视《对话》播出后,82 岁的“中国刻蚀机之父”尹志尧一夜刷屏,相关话题冲上热搜,背后是他的硬核宣言:我们现在已经有能力来做最先进的设备。①尹志尧早年赴美深造,在半导体设备领域深耕数十年。他曾先后在英…...

【大模型知识增强】KnowLM实战:从文本到知识图谱的自动化构建与精准管理
1. 为什么需要KnowLM这样的知识增强大模型? 最近在处理公司积累的几万份技术文档时,我深刻体会到了传统信息抽取方法的局限性。用通用大模型直接处理专业领域文本,经常会出现实体识别错误、关系张冠李戴的情况。比如把"Transformer架构&…...

告别AI效果波动!掌握“输入供给系统“让模型稳定输出,成本可控
文章指出传统AI系统开发路径固定但效果不稳定,核心问题是模型输入供给无序。文章提出Context Engineering(上下文工程)是构建可控输入供给系统的关键,强调其本质是工程链路而非功能模块。文章系统阐述了输入供给系统的四类问题&am…...