从工具产品体验对比spark、hadoop、flink
作为一名大数据开发,从工具产品的角度,对比一下大数据工具最常使用的框架spark、hadoop和flink。工具无关好坏,但人的喜欢有偏好。
目录
- 评价标准
- 1 效率
- 2 用户体验分析
- 从用户的维度来看
- 从市场的维度来看
- 从产品的维度来看
- 3 用户体验的基本原则
- 成本和产出是否成正比
- 操作是否“人性化”
- 4. 功能性与用户体验评估
- 总而言之
- 大数据框架评估
- 用户视角
- 效率
- 示例代码
- Spark:计算Pi的近似值
- Flink:实时流处理示例
- 易用性
- 示例代码
- Hadoop:简单的WordCount程序
- 容错性
- 市场视角
- 适应性和现代特性
- 竞争优势
- 用户群体
- 产品视角
- 维护和支持
- 用户支持和文档
- 一致性和愿景
- 总结
评价标准
1 效率
- 明确目标:用户使用工具类产品是有明确的目标的。比如,美图产品需要帮助用户迅速进行美图。
- 简化操作:简化操作能够扩大用户数量,提升效率,提升用户满意度。操作困难重重的工具类产品注定会被替代。
- 容错性:使用工具有用错的可能,出错情况少、容错性高的工具让用户用起来更放心,更安心。
2 用户体验分析
- 用户群体(我是谁?)
- 解决场景下的痛点(我在哪里?)
- 解决痛点的形式(我在干什么?)
- 交互体验(UI感受)
- 行业优劣(竞品分析)
工具产品的共同道理,不管是什么形式的工具,其道理都是类似的:
从用户的维度来看
- 价值提供:工具是否能提供应该提供的价值,解决用户需求,完成用户的本质目标?
- 使用舒适度:用户在使用过程中是否感觉很舒服、容易?
- 目标促进:工具是否能吸引用户或促进用户完成目标?
- 易触达:工具是否易于触达?能否正常运行/使用?
从市场的维度来看
- 与时俱进:工具是否能与时俱进,比如设计风格、功能布局等?
- 功能对比:其他产品的功能是否更多更好?
- 用户量:工具的用户量是否最多?
从产品的维度来看
- 持续维护:工具是否会继续维护?
- 疑问解决:对工具有疑问时,是否有人及时解决?
- 定位不变:工具是否坚持自己的定位不变?
3 用户体验的基本原则
- 一看就用:好的用户体验,一看就能使用。
- 提高效率:提高用户效率,用完就走。
- 节省成本:节省成本,再次使用还会回来。
具体来说
成本和产出是否成正比
- 作为工具,若使用成本大于产出成本,那么宁可不使用工具。使用成本包括:上手成本、时间成本、工具成本,缺一不可,任何一环都需要考虑并进行衡量。
操作是否“人性化”
- 工具讲究易用性和效率,简单的使用界面和流程会使工具容易被接受(不包括军事或其他高级领域,只讨论2C)。
4. 功能性与用户体验评估
- 功能性:用户的需求是否满足,即客户要求的功能是否全部实现。
- 易用性:对新手用户来说,软件是否友好、方便,功能操作不需要用户花太多时间去学习或理解。
- 高效率性:软件的性能,在指定条件下实现功能所需的计算机资源的有效程度。效率反映了在完成功能要求时有没有浪费资源。资源包括内存、外存、通道能力及处理时间。
- 可靠性:在规定时间和条件下,软件维持其性能水平的程度。可靠性对某些软件是重要的质量要求,反映了软件在故障发生时能继续运行的程度。
- 可维护性:软件在研发时需求变更时进行相应修改的容易程度,以及上市后的运行维护的方便性。易于维护的软件系统也是易理解、易测试和易修改的,以便纠正或增加新功能,或允许在不同软件环境上操作。
- 可移植性:从一个环境转移到另一个环境的容易程度。
总而言之
“好不好用”圈定了讨论范围要围绕功能。从用户体验要素上来说,用户在进入产品之前有一个核心任务:
- 范围层:在产品内是否能使用户完成自己的任务?
- 结构层:用户完成任务的流程是否流畅?
- 框架层:用户是否能清晰地找到完成任务的入口?
- 表现层:任务完成各阶段的提示、反馈是否明确、有意义?
大数据框架评估
用户视角
效率
- Apache Hadoop:适用于处理大规模数据集,但设置和管理复杂,可能降低新用户的效率。
- Apache Spark:提供内存中处理,大大提升性能和速度,非常适合迭代算法和实时数据处理。
- Apache Flink:在实时流处理方面表现出色,提供高效的低延迟处理。
示例代码
Spark:计算Pi的近似值
from pyspark import SparkContext
import randomsc = SparkContext("local", "Pi Approximation")def inside(p):x, y = random.random(), random.random()return x*x + y*y < 1num_samples = 1000000
count = sc.parallelize(range(0, num_samples)).filter(inside).count()
pi = 4 * count / num_samples
print("Pi is roughly %f" % pi)
Flink:实时流处理示例
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class StreamingJob {public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> text = env.socketTextStream("localhost", 9999);DataStream<Tuple2<String, Integer>> wordCounts = text.flatMap(new Tokenizer()).keyBy(value -> value.f0).sum(1);wordCounts.print();env.execute("Streaming WordCount");}public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) {for (String word : value.split("\\s")) {out.collect(new Tuple2<>(word, 1));}}}
}
易用性
- Hadoop:学习曲线陡峭,需要管理其生态系统(HDFS, MapReduce, YARN),对初学者不太友好。
- Spark:提供丰富的API(Java, Scala, Python, R),集群管理更简便。
- Flink:同样提供丰富的API,设计上简化了流处理应用的开发。
用过hadoop再用spark的,应该再也不会用hadoop了
示例代码
Hadoop:简单的WordCount程序
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;
import java.util.StringTokenizer;public class WordCount {public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);}}}public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
容错性
- Hadoop:具有良好的容错性,通过HDFS的容错存储和任务失败重执行机制实现。
- Spark:通过数据血统(lineage)和弹性分布式数据集(RDD)提供容错性。
- Flink:通过状态快照和细粒度恢复机制提供高级容错,确保流处理的稳健性。
市场视角
适应性和现代特性
- Hadoop:虽然仍在发展,但由于其批处理根源,被认为不如Spark和Flink现代。
- Spark:经常更新新特性,保持领先的大数据处理选择地位。
- Flink:因其实时处理能力和复杂事件处理支持迅速获得关注。
竞争优势
- Hadoop:虽然是基础性技术,但面临Spark和Flink等新框架的激烈竞争。
- Spark:凭借广泛采用、活跃社区和批处理与流处理的多功能性保持竞争优势。
- Flink:在实时分析领域竞争力强,吸引了对高吞吐量、低延迟处理有需求的用户。
用户群体
- Hadoop:广泛使用,但在许多组织中逐渐被Spark补充或替代。
- Spark:用户群体大且不断增长,尤其是在需要快速数据处理和机器学习能力的行业中。
- Flink:用户群体增长迅速,特别是在实时数据分析至关重要的行业中。
产品视角
维护和支持
- Hadoop:由强大的社区支持,并通过Cloudera和Hortonworks(现为Cloudera的一部分)等供应商提供企业支持。
- Spark:由Databricks(Spark的创建者)和庞大的开源社区支持,确保持续改进和支持。
- Flink:由Apache社区和Ververica等商业实体支持,提供企业支持和开发。
用户支持和文档
- Hadoop:有广泛的文档、教程和社区支持论坛。
- Spark:优秀的文档、众多教程和活跃的社区提供广泛支持。
- Flink:文档质量良好,社区支持不断增长,资源越来越多。
一致性和愿景
- Hadoop:在提供稳健、可扩展的存储和处理框架方面表现一致,但创新速度较慢。
- Spark:通过新特性和集成不断创新,保持统一的分析愿景。
- Flink:专注于实时流处理,保持清晰愿景并迅速演变以满足现代数据处理需求。
总结
通过效率、易用性、容错性、适应性、竞争优势、用户群体、维护支持、一致性和愿景等多个维度评估大数据框架,可以全面了解其可用性。
- Apache Hadoop:最适合需要大规模批处理和强大管理能力的组织。
- Apache Spark:适用于需要高效数据处理和批处理与流处理多功能性的环境。
- Apache Flink:适合需要实时、低延迟处理和复杂事件处理能力的应用。
选择合适的框架取决于您的具体需求、现有基础设施和长期数据处理目标。每个框架都有其独特的优势,了解这些优势可以指导您为大数据项目做出明智的决策。
相关文章:
从工具产品体验对比spark、hadoop、flink
作为一名大数据开发,从工具产品的角度,对比一下大数据工具最常使用的框架spark、hadoop和flink。工具无关好坏,但人的喜欢有偏好。 目录 评价标准1 效率2 用户体验分析从用户的维度来看从市场的维度来看从产品的维度来看 3 用户体验的基本原则…...

【软件设计】详细设计说明书(word原件,项目直接套用)
软件详细设计说明书 1.系统总体设计 2.性能设计 3.系统功能模块详细设计 4.数据库设计 5.接口设计 6.系统出错处理设计 7.系统处理规定 软件全套资料:本文末个人名片直接获取或者进主页。...
优缺点,以及适用场景)
java本地缓存(map,Guava,echcache,caffeine)优缺点,以及适用场景
前言 在高并发系统环境下,jvm本地缓存扮演着至关重要的角色,合理的应用能够使系统响应迅速,提高用户体验感,而分布式缓存redis则存在着网络io,以及流量消耗问题,需要和本地缓存搭配使用,才能使…...

Monica
在 《long long ago》中,我论述了on是一个刚出生的孩子的脐带连接在其肚子g上的形象,脐带就是long的字母l和字母n,l表脐带很长,n表脐带曲转冗余和连接之性,on表一,是孩子刚诞生的意思,o是身体&a…...

国产数据库中读写分离实现机制
在数据库高可用架构下会存在1主多备的部署,备节点可以根据业务场景分发一部分流量以充分利用资源,并减轻主库的压力,因此在数据库的功能上需要读写分离来实现。 充分利用备节点的资源,提升业务的吞吐量;防止运维等非业…...

kubernetes部署dashboard
kubernetes部署dashboard 1. 简介 Dashboard 是基于网页的 Kubernetes 用户界面。 你可以使用 Dashboard 将容器应用部署到 Kubernetes 集群中,也可以对容器应用排错,还能管理集群资源。 你可以使用 Dashboard 获取运行在集群中的应用的概览信息&#…...

FPGA早鸟课程第二弹 | Vivado 设计静态时序分析和实际约束
在FPGA设计领域,时序约束和静态时序分析是提升系统性能和稳定性的关键。社区推出的「Vivado 设计静态时序分析和实际约束」课程,旨在帮助工程师们掌握先进的设计技术,优化设计流程,提高开发效率。 课程介绍 关于课程 权威认证&…...

STM32项目分享:家庭环境监测系统
目录 一、前言 二、项目简介 1.功能详解 2.主要器件 三、原理图设计 四、PCB硬件设计 1.PCB图 2.PCB板打样焊接图 五、程序设计 六、实验效果 七、资料内容 项目分享 一、前言 项目成品图片: 哔哩哔哩视频链接: https://www.bilibili.…...

华为HCIP Datacom H12-821 卷5
1.单选题 下列哪种工具不能被 route-policy 的 apply 子句直接引用? A、IP-Prefix B、tag C、community D、origin 正确答案: A 解析: 因route-policy工具中, apply 后面跟的是路由的相关属性。 但是ip-prefix是用来匹配路由的工具。 2.单选题...

Mongodb数据库基本操作
本文为在命令行模式下Mongodb数据库的基本操作整理。 目录 数据库操作 创建数据库 查看所有数据 查看当前数据库 删除数据库 断开连接 查看命令api 集合操作 查看当前数据库下集合 创建集合 删除当前数据库中的集合 文档操作 插入文档 insertOne()方法 insertMa…...

【机器学习】基于Softmax松弛技术的离散数据采样
1.引言 1.1.离散数据采样的意义 离散数据采样在深度学习中起着至关重要的作用,它直接影响到模型的性能、泛化能力、训练效率、鲁棒性和解释性。 首先,采样方法能够有效地平衡数据集中不同类别的样本数量,使得模型在训练时能够更均衡地学习…...
.NET+Python量化【1】——环境部署和个人资金账户信息查询
前言:量化资料很少,.NET更少。那我就来开个先河吧~ 以下是使用QMT进行量化开发的环境部署和基础信息获取有关操作。 1、首先自己申请券商的QMT权限,此步骤省略。 2、登陆QMT,选择极简模式,或者独立交易模式之类的。会进…...

洛谷 P10584 [蓝桥杯 2024 国 A] 数学题(整除分块+杜教筛)
题目 思路来源 登录 - Luogu Spilopelia 题解 参考了两篇洛谷题解,第一篇能得出这个式子,第二篇有比较严格的复杂度分析 结合去年蓝桥杯洛谷P9238,基本就能得出这题的正确做法 代码 #include<bits/stdc.h> #include<iostream&g…...
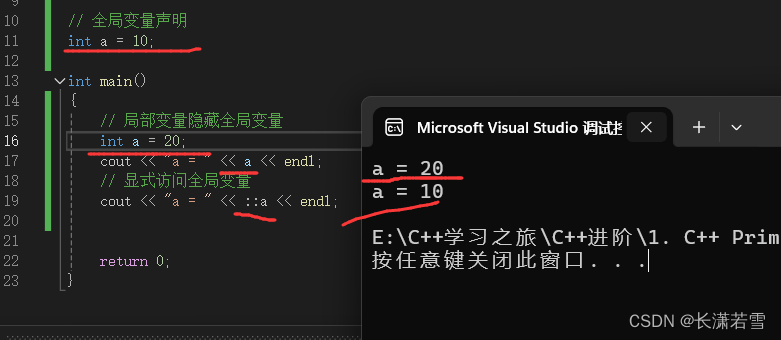
深入讲解C++基础知识(一)
目录 一、基本内置类型1. 类型的作用2. 分类3. 整型3.1 内存描述及查询3.2 布尔类型 —— bool3.3 字符类型 —— char3.4 其他整型 4. 有符号类型和无符号类型5. 浮点型6. 如何选择类型7. 类型转换7.1 自动类型转换7.2 强制类型转换7.3 类型转换总结 8. 类型溢出8.1 注意事项 …...

Python爬虫实战:批量下载网站图片
1.获取图片的url链接 首先,打开百度图片首页,注意下图url中的index 接着,把页面切换成传统翻页版(flip),因为这样有利于我们爬取图片! 对比了几个url发现,pn参数是请求到的数量。…...

使用 JavaScript 获取电池状态
在现代的移动设备和笔记本电脑上,了解电池状态是一项非常有用的功能。使用 JavaScript 可以轻松地获取电池的充电状态、电量百分比等信息。本文将介绍如何使用 JavaScript 访问这些信息,并将其显示在网页上。 1. HTML 结构 首先,我们需要一…...
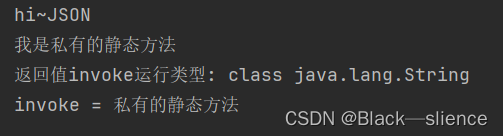
java—类反射机制
简述 反射机制允许程序在执行期间借助于Reflection API取得任何类的内部信息(如成员变量,构造器,成员方法等),并能操作对象的属性及方法。反射机制在设计模式和框架底层都能用到。 类一旦加载,在堆中会产生…...

浏览器-服务器架构 (BS架构) 详解
目录 前言1. BS架构概述1.1 BS架构的定义1.2 BS架构的基本原理 2. BS架构的优势2.1 客户端简化2.2 易于更新和维护2.3 跨平台性强2.4 扩展性高 3. BS架构的劣势3.1 网络依赖性强3.2 安全性问题3.3 用户体验局限 4. BS架构的典型应用场景4.1 企业内部应用4.2 电子商务平台4.3 在…...

微型操作系统内核源码详解系列五(四):cm3下svc启动任务
系列一:微型操作系统内核源码详解系列一:rtos内核源码概论篇(以freertos为例)-CSDN博客 系列二:微型操作系统内核源码详解系列二:数据结构和对象篇(以freertos为例)-CSDN博客 系列…...
)
筛质数(暴力法、埃氏筛、欧拉筛)
筛质数(暴力法、埃氏筛、欧拉筛) 暴力法 思路分析: 直接双for循环来求解质数 如果不设置标记只是简单地执行了break会导致内部循环(由j控制)而不是立即打印i或者跳过它。如果打印语句写到内部循环中,也会导致每个 非素数也被打…...

神经网络分子动力学与长程静电模拟优化策略
1. 神经网络分子动力学与长程静电模拟的技术背景分子动力学模拟作为计算化学和材料科学的核心工具,其本质是通过数值求解牛顿运动方程来预测原子和分子的运动轨迹。传统的第一性原理分子动力学(AIMD)虽然精度高,但由于计算复杂度随…...

NotebookLM思维导图生成已进入「语义拓扑时代」:2024Q2最新Benchmark显示其节点关联准确率超越MindNode Pro 41.6%
更多请点击: https://intelliparadigm.com 第一章:NotebookLM思维导图生成已进入「语义拓扑时代」 传统基于关键词共现或规则模板的思维导图生成方式,正被 NotebookLM 的语义理解能力彻底重构。其底层 LLM 模型不再仅识别显式术语关系&#…...

Circuit Playground Express 硬件解析与四步编程实战:从创客入门到项目开发
1. 项目概述:为什么选择 Circuit Playground Express 作为创客起点 如果你对硬件编程、物联网或者智能设备感兴趣,但又被 Arduino Uno 上密密麻麻的杜邦线和面包板劝退,或者觉得树莓派 Zero 的 Linux 系统门槛太高,那么 Adafruit…...

AI智能体开发实战:agent-skills工具库核心技能解析与应用
1. 项目概述与核心价值最近在折腾AI智能体开发,发现一个挺有意思的现象:很多开发者,包括我自己在内,一开始都热衷于去研究那些大型的、功能全面的智能体框架,试图打造一个“全能”的AI助手。但实际落地时,往…...

ESXi 8.0U3i 新版本深度解析|官方原版核心优势 + 部署指南,稳定运维首选
随着企业虚拟化、私有云部署需求的不断升级,一款稳定、安全、可追溯的底层虚拟化系统,成为数据中心、机房运维与合规生产的核心诉求。VMware ESXi 8.0U3i(版本 8.0U3i-25205845)作为 8.0 系列 2026 年最新推出的稳定版本ÿ…...

利用coze使用无代码平台搭建图片识别机器人
利用coze使用无代码平台搭建图片识别机器人 无代码平台允许用户通过可视化界面快速创建聊天机器人,无需编程基础。例如,扣子(Coze) 是一个由字节跳动开发的智能体应用开发平台,支持集成多种大语言模型(如 …...
LLM实战指南:从Transformer原理到微调部署的完整学习路径
1. 项目概述:一个面向实践者的LLM学习路线图最近在GitHub上看到一个叫mlabonne/llm-course的项目,热度非常高。点进去一看,这其实不是一个传统意义上的“课程”,而更像一份由社区驱动的、持续更新的“大型语言模型实战指南”。它的…...

数控编程软件|PowerMill 2026全流程下载安装教程
相信大家不会感到陌生,PowerMill是一款功能强大且专业的计算机辅助制造(CAM)软件工具,专注于复杂零件的数控(CNC)加工编程,尤其适用于模具、航空航天、汽车制造等高精度、高复杂度…...

Day 2|项目目录与多布局、路由与权限守卫:从结构到落地代码
1. 目标与产出 明确中后台项目目录分层与职责边界。落地多布局(主布局/业务布局),沉淀可复用容器组件。设计路由与权限模型(角色/权限点),实现路由守卫与菜单联动。产出可复用的 Pinia 权限状态、权限指令、…...

如何快速制作专业演示文稿?终极免费开源在线PPT工具PPTist完整指南
如何快速制作专业演示文稿?终极免费开源在线PPT工具PPTist完整指南 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint,…...