能理解你的意图的自动化采集工具——AI和爬虫相结合
⭐️我叫忆_恒心,一名喜欢书写博客的研究生👨🎓。
如果觉得本文能帮到您,麻烦点个赞👍呗!
近期会不断在专栏里进行更新讲解博客~~~
有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三连支持一下呗。👍⭐️❤️
📂Qt5.9专栏定期更新Qt的一些项目Demo
📂项目与比赛专栏定期更新比赛的一些心得,面试项目常被问到的知识点。
欢迎评论 💬点赞👍🏻 收藏 ⭐️加关注+
✍🏻文末可以进行资料和源码获取欧😄
前言
当我们需要收集一些数据的时候,自动化数据采集工具总是可以帮到我们,但是传统的自动化数据采集工具,存在以下不足:
- 工具的通用程度低:需要我们手动分析每个网站的特点;
- 保存的数据格式也比较单一
- 操作麻烦
当AI的阅读理解能力遇到了自动化采集工具的时候,将会产生怎么样的魔法呢?
能够理解你的意图并自动执行复杂的网络数据抓取任务,ScrapeGraphAI 就是这样一个工具,它利用最新的人工智能技术,让数据提取变得前所未有地简单。
工具的优点

- 简单易用:只需输入 API 密钥,您就可以在几秒钟内抓取数千个网页!
- 开发便捷:你只需要实现几行代码,工作就完成了。
- 专注业务:有了这个库,您可以节省数小时的时间,因为您只需要设置项目,人工智能就会为您完成一切。
一、介绍
ScrapeGraphAI是一个网络爬虫 Python 库,使用大型语言模型和直接图逻辑为网站和本地文档(XML,HTML,JSON 等)创建爬取管道。
只需告诉库您想提取哪些信息,它将为您完成!

scrapegraphai有三种主要的爬取管道可用于从网站(或本地文件)提取信息:
SmartScraperGraph: 单页爬虫,只需用户提示和输入源;SearchGraph: 多页爬虫,从搜索引擎的前 n 个搜索结果中提取信息;SpeechGraph: 单页爬虫,从网站提取信息并生成音频文件。SmartScraperMultiGraph: 多页爬虫,给定一个提示 可以通过 API 使用不同的 LLM,如 OpenAI,Groq,Azure 和 Gemini,或者使用 Ollama 的本地模型。
官方提供了非常详细的文档:官方文档
二、准备工作
2.1 安装ollama
点击前往网站 https://ollama.com/ ,下载ollama软件,目前该软件支持支持win、Mac、linux
2.2 下载LLM
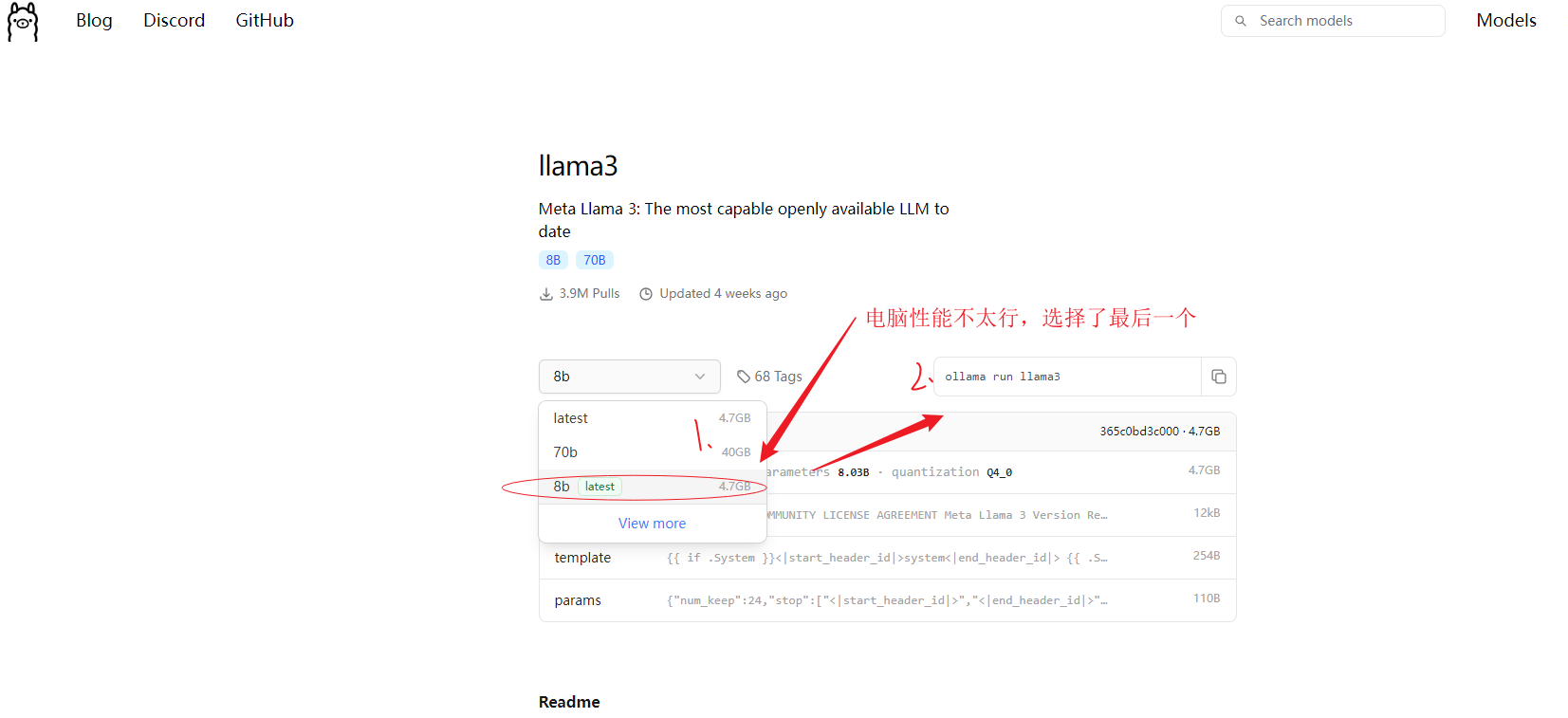
ollama软件目前支持多种大模型, 如阿里的(qwen、qwen2)、meta的(llama3),
以llama3为例,根据自己电脑显存性能, 选择适宜的版本。如果不知道选什么,那就试着安装,不合适不能用再删除即可。
打开电脑终端命令行cmd, 网络是连网状态,执行模型下载(安装)命令
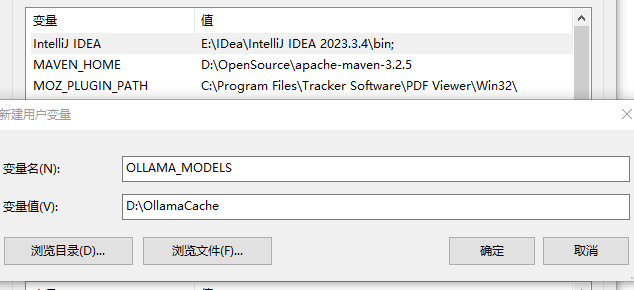
强烈建议,更改默认路径
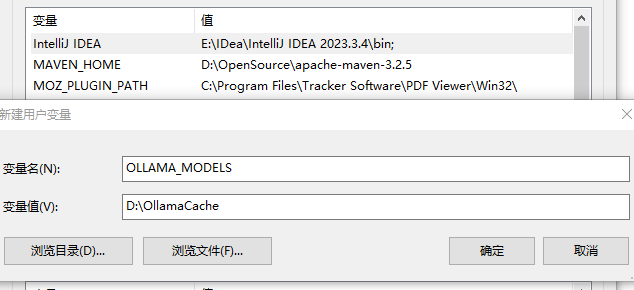
新建变量
OLLAMA_MODELS
值
D:\OllamaCache
添加了环境变量后,记得重启计算机,使其生效
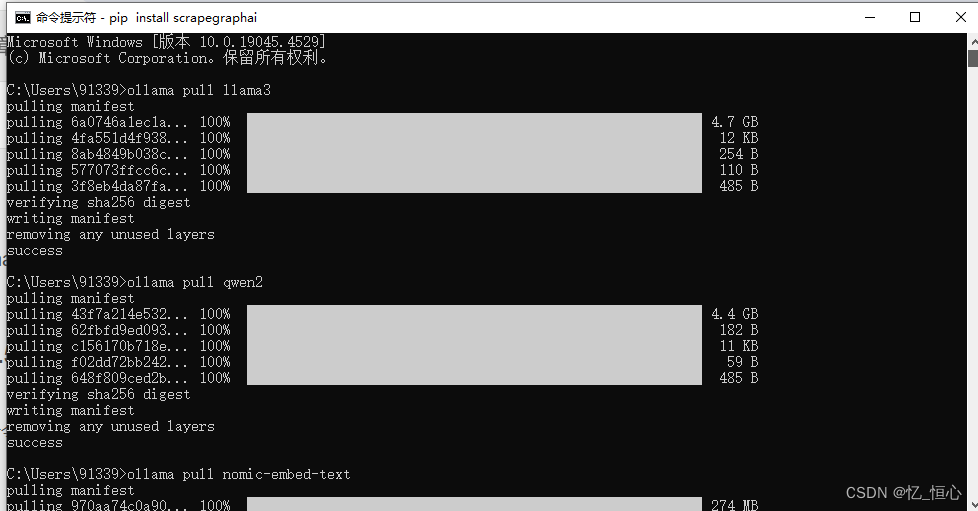
ollama pull llama3
ollama pull qwen2
ollama pull nomic-embed-text
等待 llama3、 nomic-embed-text 下载完成。
2.3 安装python包
在python中调用ollama服务,需要ollama包。
打开电脑命令行cmd(mac是terminal), 网络是连网状态,执行安装命令
pip3 install ollama
建议使用anaconda环境来管理这些包,因为默认的base环境可能会出现python版本不兼容的问题。
# 创建名为 ollama 的虚拟环境,并指定 Python 3.10
conda create --name ollama python=3.10
# 激活虚拟环境
conda activate ollama
2.4 启动ollama服务
在Python中调用本地ollama服务,需要先启动本地ollama服务, 打开电脑命令行cmd(mac是terminal), 执行
ollama serve
Run
cmd(mac是terminal)看到如上的信息,说明本地ollama服务已开启。
2.5 安装scrapegraphai及playwright
电脑命令行cmd(mac是terminal), 网络是连网状态,执行安装命令
pip install scrapegraphai
之后继续命令行cmd(mac是terminal)执行
playwright install
等待安装完成后,进行实验
三、实验
注意端口冲突,尽量不要使用8080
3.1 案例1
以我的博客 ydlin.blog.csdn.net 为例,假设我想获取标题、日期、文章链接,
代码如下:
from scrapegraphai.graphs import SmartScraperGraphgraph_config = {"llm": {"model": "ollama/llama3","temperature": 0,"format": "json", # Ollama 需要显式指定格式"base_url": "http://localhost:11434", # 设置 Ollama URL},"embeddings": {"model": "ollama/nomic-embed-text","base_url": "http://localhost:11434", # 设置 Ollama URL},"verbose": True,
}smart_scraper_graph = SmartScraperGraph(prompt="返回该网站所有文章的标题、日期、文章链接",# 也接受已下载的 HTML 代码的字符串#source=requests.get("https://ydlin.blog.csdn.net/").text,source="https://ydlin.blog.csdn.net/",config=graph_config
)result = smart_scraper_graph.run()
print(result)
Run
--- Executing Fetch Node ---
--- Executing Parse Node ---
--- Executing RAG Node ---
--- (updated chunks metadata) ---
--- (tokens compressed and vector stored) ---
--- Executing GenerateAnswer Node ---
Processing chunks: 100%|█████████████████████████| 1/1 [00:00<00:00, 825.81it/s]...
3.2 案例2
采集豆瓣读书 https://book.douban.com/top250 中的 名字、作者名、评分、书籍链接 等信息。

from scrapegraphai.graphs import SmartScraperGraphgraph_config = {"llm": {"model": "ollama/llama3","temperature": 0,"format": "json", # Ollama 需要显式指定格式"base_url": "http://localhost:11434", # 设置 Ollama URL},"embeddings": {"model": "ollama/nomic-embed-text","base_url": "http://localhost:11434", # 设置 Ollama URL},"verbose": True,
}smart_scraper_graph2 = SmartScraperGraph(prompt="返回该页面所有书的名字、作者名、评分、书籍链接",source="https://book.douban.com/top250",config=graph_config
)result2 = smart_scraper_graph2.run()
print(result2)
Run
--- Executing Fetch Node ---
--- Executing Parse Node ---
--- Executing RAG Node ---
--- (updated chunks metadata) ---
--- (tokens compressed and vector stored) ---
--- Executing GenerateAnswer Node ---
Processing chunks: 100%|████████████████████████| 1/1 [00:00<00:00, 1474.79it/s]
{}
采集失败,返回空。
将大模型llama3改为qwen2
from scrapegraphai.graphs import SmartScraperGraphgraph_config2 = {"llm": {"model": "ollama/qwen2","temperature": 0,"format": "json", # Ollama 需要显式指定格式"base_url": "http://localhost:11434", # 设置 Ollama URL},"embeddings": {"model": "ollama/nomic-embed-text","base_url": "http://localhost:11434", # 设置 Ollama URL},"verbose": True,
}smart_scraper_graph3 = SmartScraperGraph(prompt="返回该页面所有书的名字、作者名、评分、书籍链接",source="https://book.douban.com/top250",config=graph_config2
)result3 = smart_scraper_graph3.run()
print(result3)
Run
--- Executing Fetch Node ---
--- Executing Parse Node ---
--- Executing RAG Node ---
--- (updated chunks metadata) ---
--- (tokens compressed and vector stored) ---
--- Executing GenerateAnswer Node ---
Processing chunks: 100%|████████████████████████| 1/1 [00:00<00:00, 1102.60it/s]
{'urls': ['https://book.douban.com/subject/10554308/', 'https://book.douban.com/subject/1084336/', 'https://book.douban.com/subject/1084336/', 'https://book.douban.com/subject/1046209/', 'https://book.douban.com/subject/1046209/', 'https://book.douban.com/subject/1255625/', 'https://book.douban.com/subject/1255625/', 'https://book.douban.com/subject/1060068/', 'https://book.douban.com/subject/1060068/', 'https://book.douban.com/subject/1449351/', 'https://book.douban.com/subject/1449351/', 'https://book.douban.com/subject/20424526/', 'https://book.douban.com/subject/20424526/', 'https://book.douban.com/subject/29799269/', 'https://book.douban.com/subject/1034062/', 'https://book.douban.com/subject/1229240/', 'https://book.douban.com/subject/1237549/', 'https://book.douban.com/subject/1078958/', 'https://book.douban.com/subject/1076932/', 'https://book.douban.com/subject/1075440/', 'https://book.douban.com/subject/1076932/', 'https://book.douban.com/subject/1078958/', 'https://book.douban.com/subject/1076932/', 'https://book.douban.com/subject/1078958/', 'https://book.douban.com/subject/1076932/', 'https://book.douban.com/subject/1078958/', 'https://book.douban.com/subject/1076932/'], 'images': ['https://img1.doubanio.com/view/subject/s/public/s1078958.jpg', 'https://img1.doubanio.com/view/subject/s/public/s1076932.jpg', 'https://img1.doubanio.com/view/subject/s/public/s1447349.jpg']}
采集到一些信息,但没有书名、作者等信息。
3.3 使用远程服务器
如果机子的性能比较差,直接利用ChatGPT的key。
仓库中的.md文件给出调用样例,输出的结果为音频文件。
然而实际上,往往在进行数据采集的时候,我们将采集的结果保存成文本格式就可了。
import os
from dotenv import load_dotenv
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_infoload_dotenv()def main():#openai_key = os.getenv("x")graph_config = {"llm": {"api_key": "OPENAI_API_KEY","model": "gpt-3.5-turbo",},}# ************************************************# Create the SmartScraperGraph instance and run it# ************************************************smart_scraper_graph = SmartScraperGraph(prompt="List me all the projects with their description.",# also accepts a string with the already downloaded HTML codesource="https://perinim.github.io/projects/",config=graph_config)result = smart_scraper_graph.run()print(result)if __name__ == "__main__":main()
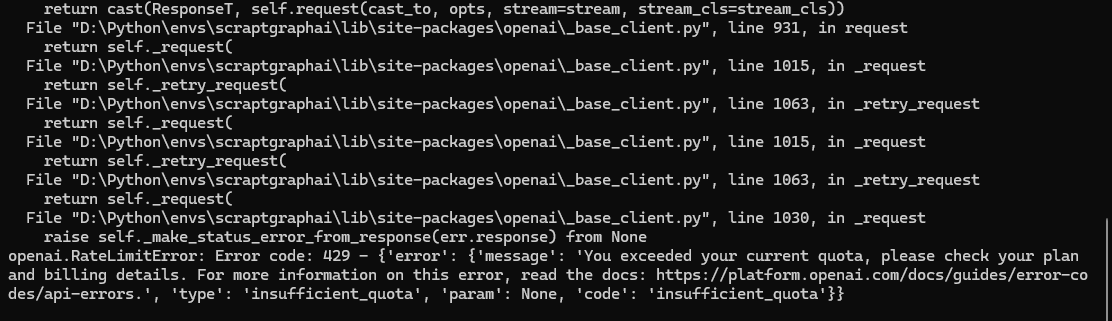
在环境都正常配上的时候,出现You exceeded your current quota 需要检查一下OPENAI_API_KEY是否有调用余额。
下面也附上仓库给出的示例,将爬取的结果保存成音频文件。
from scrapegraphai.graphs import SpeechGraphgraph_config = {"llm": {"api_key": "OPENAI_API_KEY","model": "gpt-3.5-turbo",},"tts_model": {"api_key": "OPENAI_API_KEY","model": "tts-1","voice": "alloy"},"output_path": "audio_summary.mp3",
}# ************************************************
# Create the SpeechGraph instance and run it
# ************************************************speech_graph = SpeechGraph(prompt="Make a detailed audio summary of the projects.",source="https://perinim.github.io/projects/",config=graph_config,
)result = speech_graph.run()
print(result)注意:
代码需要在 .py 中运行,在 .ipynb 中运行会报错。
四、讨论与总结
ScrapeGraphAI 能够理解你的意图并自动执行复杂的网络数据抓取任务。虽然,现在模型还存在着一些不够完善的地方(采集的速度比较慢,底层使用playwright访问速度较慢)
但是目前AI与自动化爬取相结合的一个大模型爬虫,真的可以称得上是一款可以理解用户意义的网络爬虫。
往期优秀文章推荐:
- 研究生入门工具——让你事半功倍的SCI、EI论文写作神器
- 磕磕绊绊的双非硕秋招之路小结
- 研一学习笔记-小白NLP入门学习笔记
- C++ LinuxWebServer 2万7千字的面经长文(上)
- C++Qt5.9学习笔记-事件1.5W字总结
资料、源码获取以及更多粉丝福利,可以关注下方进行获取欧

相关文章:
能理解你的意图的自动化采集工具——AI和爬虫相结合
⭐️我叫忆_恒心,一名喜欢书写博客的研究生👨🎓。 如果觉得本文能帮到您,麻烦点个赞👍呗! 近期会不断在专栏里进行更新讲解博客~~~ 有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三连支…...

基于SpringBoot+大数据城市景观画像可视化设计和实现
💗博主介绍:✌全网粉丝10W,CSDN作者、博客专家、全栈领域优质创作者,博客之星、平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 🌟文末获取源码数据库🌟 感兴趣的可以先收藏起来,…...

Oracle表中的数据量达到30万条
当Oracle表中的数据量达到30万条,并且查询性能过慢时,增加索引是一个有效的优化方案。以下是一些建议来增加索引以提高查询性能: 分析查询需求: 首先,需要明确哪些查询是经常执行的,以及这些查询的WHERE子…...
【python】python学生成绩数据分析可视化(源码+数据+论文)【独一无二】
👉博__主👈:米码收割机 👉技__能👈:C/Python语言 👉公众号👈:测试开发自动化【获取源码商业合作】 👉荣__誉👈:阿里云博客专家博主、5…...

如何定期更新系统以保护网络安全
定期更新系统保护网络安全的方法 定期更新系统是确保网络安全的关键措施之一。以下是一些有效的方法: 及时获取更新信息:用户应通过邮件订阅、官方网站、厂商渠道等途径获取最新的更新通知。此外,互联网上的安全论坛和社区也是获取相关安全资…...
华为数通——OSPF
正掩码:/24 255.255.255.0 反掩码: 255.255.255.255 -255.-255.-255.0 0.0.0.255 例如掩码:255.255.252.0 反掩码:0.0.3.255 在反掩码里面,0 bit 表示精确匹配,1…...

RedHat9 | Web服务配置与管理(Apache)
一、实验环境 1、Apache服务介绍 Apache服务,也称为Apache HTTP Server,是一个功能强大且广泛使用的Web服务器软件。 起源和背景 Apache起源于NCSA httpd服务器,经过多次修改和发展,逐渐成为世界上最流行的Web服务器软件之一。…...

API-事件监听
学习目标: 掌握事件监听 学习内容: 事件监听拓展阅读-事件监听版本 事件监听: 什么是事件? 事件是在编程时系统内发生的动作或者发生的事情。 比如用户在网页上单击一个按钮。什么是事件监听? 就是让程序检测是否有事…...

如何为自己的项目生成changelog
背景 在github上看到人家的更新日志感觉很cool,怎么能给自己项目来一套呢 环境信息 tdstdsdeMacBook-Pro demo-doc % node -v v14.18.1 tdstdsdeMacBook-Pro demo-doc % npm -v 6.14.15硬件信息 型号名称:MacBook Pro版本: 12.6.9芯片&…...

MySQL之表碎片化
文章目录 1. 前言2. InnoDB表碎片3. 清除表碎片3.1 查找碎片化严重的表3.2 清除碎片 4. 小结5. 参考 1. 前言 周一在对线上表进行数据清除时,发现一个问题,我要清除的单表大概有2500w条数据,清除数据大概在1300w条左右,清除之前通…...
碳+绿证如何能源匹配?考虑碳交易和绿证交易制度的电力批发市场能源优化程序代码!
前言 近年来,面对日益受到全社会关注的气候变化问题,国外尤其是欧美等发达国家和地区针对电力行业制定了一系列碳减排组合机制。其中,碳排放权交易(以下简称“碳交易”)和绿色电力证书交易(以下简称“绿证…...
【原创】springboot+mysql海鲜商城设计与实现
个人主页:程序猿小小杨 个人简介:从事开发多年,Java、Php、Python、前端开发均有涉猎 博客内容:Java项目实战、项目演示、技术分享 文末有作者名片,希望和大家一起共同进步,你只管努力,剩下的交…...
envi5.6+SARscape560安装(CSDN_20240623)
envi和SARscape的版本必须匹配,否则有些功能不能使用。 Envi5.6安装 1. 点击安装程序. 2. 进入安装界面,点击“Next”. 3. 选择“I accept the agreement”,点击“Next”。 4. 选择安装路径,建议直接安装在默认路径下࿰…...
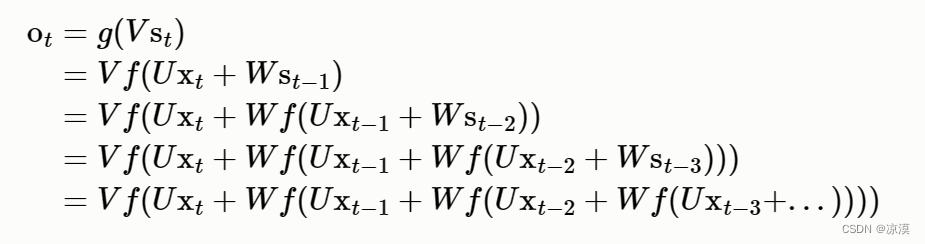
基本循环神经网络(RNN)
RNN背景:RNN与FNN 在前馈神经网络中,信息的传递是单向的,这种限制虽然使得网络变得更容易学习,但在一定程度上也减弱了神经网络模型的能力。 在生物神经网络中,神经元之间的连接关系要复杂的多。前馈神经网络可以看着…...
win32API(CONSOLE 相关接口详解)
前言: Windows这个多作业系统除了协调应⽤程序的执⾏、分配内存、管理资源之外,它同时也是⼀个很⼤的服务中⼼,调⽤这个服务中⼼的各种服务(每⼀种服务就是⼀个函数),可以帮应⽤程式达到开启视窗、描绘图形…...
python爬虫学习笔记一(基本概念urllib基础)
学习资料:尚硅谷_爬虫 学习环境: pycharm 一.爬虫基本概念 爬虫定义 > 解释1:通过程序,根据URL进行爬取网页,获取有用信息 > 解释2:使用程序模拟浏览器,向服务器发送请求,获取相应信息…...

MyBatis映射器:一对多关联查询
大家好,我是王有志,一个分享硬核 Java 技术的金融摸鱼侠,欢迎大家加入 Java 人自己的交流群“共同富裕的 Java 人”。 在学习完上一篇文章《MyBatis映射器:一对一关联查询》后,相信你已经掌握了如何在 MyBatis 映射器…...

100多个ChatGPT指令提示词分享
当前,ChatGPT几乎已经占领了整个互联网。全球范围内成千上万的用户正使用这款人工智能驱动的聊天机器人来满足各种需求。然而,并不是每个人都知道如何充分有效地利用ChatGPT的潜力。其实有许多令人惊叹的ChatGPT指令提示词,可以提升您与ChatG…...

vue2和vue3数据代理的区别
前言: vue2 的双向数据绑定是利⽤ES5的⼀个 API ,Object.defineProperty( )对数据进行劫持结合发布订阅模式的方式来实现的。 vue3 中使⽤了 ES6的Proxy代理对象,通过 reactive() 函数给每⼀个对象都包⼀层Proxy,通过 Proxy监听属…...
已解决ApplicationException异常的正确解决方法,亲测有效!!!
已解决ApplicationException异常的正确解决方法,亲测有效!!! 目录 问题分析 出现问题的场景 报错原因 解决思路 解决方法 分析错误日志 检查业务逻辑 验证输入数据 确认服务器端资源的可用性 增加对特殊业务情况的处理…...

Phi-4-mini-reasoning镜像免配置:预置Prometheus监控指标暴露配置
Phi-4-mini-reasoning镜像免配置:预置Prometheus监控指标暴露配置 1. 模型简介与部署概述 Phi-4-mini-reasoning是一个基于合成数据构建的轻量级开源模型,专注于高质量、密集推理的数据处理能力。作为Phi-4模型家族的一员,它特别针对数学推…...

openclaude:模型接入 Code 工具链
作为一名长期关注人工智能工程化落地的开发者,我深知本地大模型在隐私保护和成本控制上的优势,但往往苦于缺乏像 Claude Code 那样强大的工具调用能力。很多时候,我们拥有强大的模型(如 DeepSeek、Ollama 本地部署)&am…...

Phi-3-mini-4k-instruct-gguf保姆级教程:从CSDN GPU平台访问到结果导出全流程
Phi-3-mini-4k-instruct-gguf保姆级教程:从CSDN GPU平台访问到结果导出全流程 1. 认识Phi-3-mini-4k-instruct-gguf Phi-3-mini-4k-instruct-gguf是微软Phi-3系列中的轻量级文本生成模型GGUF版本。这个模型特别适合处理问答、文本改写、摘要整理以及简短创作等任务…...

昆明波纹管供应商哪个好
在市政排水、农田灌溉、通信保护等工程领域,HDPE双壁波纹管因其优异的环刚度、耐腐蚀性和施工便捷性,已成为不可或缺的关键建材。然而,面对市场上琳琅满目的供应商,尤其是在地质气候条件独特的西南地区,如何选择一个真…...

OpenClaw自动化测试:Kimi-VL-A3B-Thinking多模态交互验证框架
OpenClaw自动化测试:Kimi-VL-A3B-Thinking多模态交互验证框架 1. 为什么需要AI驱动的自动化测试 去年接手一个客户端项目时,我遇到了一个典型痛点——每次发版前的手动回归测试需要3个人天。更麻烦的是,UI微调导致的视觉差异很难通过传统断…...

OpenClaw多终端同步:手机遥控Phi-3-mini-128k-instruct执行电脑任务
OpenClaw多终端同步:手机遥控Phi-3-mini-128k-instruct执行电脑任务 1. 为什么需要手机遥控电脑? 上周五晚上十点半,我正躺在沙发上刷手机,突然想起有个重要文档忘在办公室电脑里了。如果按传统方式,我需要ÿ…...

一码一物的生成软件,为什么总能先把窜货和返利黑洞堵住?
一码一物的生成软件,为什么总能先把窜货和返利黑洞堵住?很多老板嘴上说生意难做,真把账摊开看,难的不是卖不出去,而是货卖到哪儿不知道、钱花给谁不清楚、促销有没有真拉动更说不明白。一码一物的生成软件,…...
模块?)
OpenClaw 的模型架构中,是否使用了非自回归生成(NAR)模块?
关于OpenClaw模型架构中是否使用了非自回归生成模块,这其实是一个挺有意思的问题。在讨论具体细节之前,或许可以先聊聊非自回归生成本身在技术演进中的位置。 非自回归生成,也就是NAR,和常见的自回归生成方式不太一样。自回归生成…...

OpenClaw+Qwen3-14b_int4_awq:跨平台文件同步助手
OpenClawQwen3-14b_int4_awq:跨平台文件同步助手 1. 为什么需要智能文件同步 上周我差点犯了个职场大错——把包含客户联系方式的Excel表格同步到了公共网盘。这件事让我意识到:传统的文件同步工具就像个"搬运工",它分不清哪些文…...

嵌入式LED闪烁控制库Blinker工程实践指南
1. Blinker:嵌入式LED闪烁控制库的工程化实现解析Blinker并非一个广为人知的通用开源库,其项目摘要“Simple library for LED blinking”与关键词“blinking, led”表明这是一个高度聚焦、轻量级的底层驱动组件。在嵌入式系统开发中,“LED闪烁…...