Spark 键值对RDD的操作
键值对RDD(Pair RDD)是指每个RDD元素都是(key,value)键值对类型,是一种常见的RDD类型,可以应用于很多的应用场景。
一、 键值对RDD的创建
键值对RDD的创建主要有两种方式:
(1)从文件中加载生成RDD;
(2)通过并行集合(数组)创建RDD。
1,从文件中加载生成RDD
首先使用textFile()方法从文件中加载数据,然后,使用map()函数转换得到相应的键值对RDD。
scala> val lines = sc.textFile("file:///usr/local/spark/mycode/pairrdd/word.txt")
lines: org.apache.spark.rdd.RDD[String] = file:///usr/local/spark/mycode/pairrdd/ word.txtMapPartitionsRDD[1] at textFile at <console>:27
scala> val pairRDD = lines.flatMap(line => line.split(" ")).map(word => (word,1)) pairRDD: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at <console>:29
scala> pairRDD.foreach(println)
(i,1)
(love,1)
(hadoop,1)
……
map(word => (word,1))函数的作用是,取出RDD中的每个元素,也就是每个单词,赋值给word,然后把word转换成(word,1)的键值对形式。
2,通过并行集合(数组)创建RDD
scala> val list = List("Hadoop","Spark","Hive","Spark")
list: List[String] = List(Hadoop, Spark, Hive, Spark) scala> val rdd = sc.parallelize(list) rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[11] at parallelize at <console>:29
scala> val pairRDD = rdd.map(word => (word,1)) pairRDD: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[12] at map at <console>:31
scala> pairRDD.foreach(println)
(Hadoop,1)
(Spark,1)
(Hive,1)
(Spark,1)
二、常用的键值对转换操作
常用的键值对转换操作包括reduceByKey(func)、groupByKey()、keys、values、sortByKey()、mapValues(func)、join和combineByKey等。
1,reduceByKey(func)
reduceByKey(func)的功能是,使用func函数合并具有相同键的值。
有一个键值对RDD包含4个元素,分别是(“Hadoop”,1)、(“Spark”,1)、(“Hive”,1)和(“Spark”,1)。可以使用reduceByKey()操作,得到每个单词的出现次数,代码及其执行结果如下:
scala> pairRDD.reduceByKey((a,b)=>a+b).foreach(println)
(Spark,2)
(Hive,1)
(Hadoop,1)
2,·groupByKey()
groupByKey()的功能是,对具有相同键的值进行分组。
有四个键值对(“spark”,1)、(“spark”,2)、(“hadoop”,3)和(“hadoop”,5),采用groupByKey()后得到的结果是:(“spark”,(1,2))和(“hadoop”,(3,5)),代码及其执行结果如下:
scala> pairRDD.groupByKey()
res15: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[15] at groupByKeyat <console>:34
reduceByKey和groupByKey的区别是:reduceByKey用于对每个key对应的多个value进行聚合操作,并且聚合操作可以通过函数func进行自定义;groupByKey也是对每个key进行操作,但是,对每个key只会生成一个value-list,groupByKey本身不能自定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。
3,keys()
键值对RDD每个元素都是(key,value)的形式,keys操作只会把键值对RDD中的key返回,形成一个新的RDD。
有一个键值对RDD,名称为pairRDD,包含4个元素,分别是(“Hadoop”,1)、(“Spark”,1)、(“Hive”,1)和(“Spark”,1),可以使用keys方法取出所有的key并打印出来,代码及其执行结果如下:
scala> pairRDD.keys
res17: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[17] at keys at <console>:34
scala> pairRDD.keys.foreach(println)
Hadoop
Spark
Hive
Spark
4,values()
values操作只会把键值对RDD中的value返回,形成一个新的RDD。
有一个键值对RDD,名称为pairRDD,包含4个元素,分别是(“Hadoop”,1)、(“Spark”,1)、(“Hive”,1)和(“Spark”,1),可以使用values方法取出所有的value并打印出来,代码及其执行结果如下:
scala> pairRDD.values
res0: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[2] at values at <console>:34
scala> pairRDD.values.foreach(println)
1
1
1
1
5,sortByKey()
sortByKey()的功能是返回一个根据key排序的RDD。
有一个键值对RDD,名称为pairRDD,包含4个元素,分别是(“Hadoop”,1)、(“Spark”,1)、(“Hive”,1)和(“Spark”,1),使用sortByKey()的效果如下:
scala> pairRDD.sortByKey()
res0: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[2] at sortByKey at <console>:34
scala> pairRDD.sortByKey().foreach(println)
(Hadoop,1)
(Hive,1)
(Spark,1)
(Spark,1)
6,sortBy()
sortByKey()的功能是返回一个根据key排序的RDD,而sortBy()则可以根据其他字段进行排序。
scala> val d1 = sc.parallelize(Array(("c",8),("b",25),("c",17),("a",42),("b",4),("d",9),("e",17),("c",2),("f",29),("g",21),("b",9)))
scala> d1.reduceByKey(_+_).sortByKey(false).collect res2: Array[(String, Int)] = Array((g,21),(f,29),(e,17),(d,9),(c,27),(b,38),(a,42))
sortByKey(false)括号中的参数false表示按照降序排序,如果没有提供参数false,则默认采用升序排序。从上面排序后的效果可以看出,所有键值对都按照key的降序进行了排序,因此输出Array((g,21),(f,29),(e,17),(d,9),(c,27),(b,38),(a,42))。
7,mapValues(func)
mapValues(func)对键值对RDD中的每个value都应用一个函数,但是,key不会发生变化。
有一个键值对RDD,名称为pairRDD,包含4个元素,分别是(“Hadoop”,1)、(“Spark”,1)、(“Hive”,1)和(“Spark”,1),下面使用mapValues()操作把所有RDD元素的value都增加1:
scala> pairRDD.mapValues(x => x+1)res2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[4] at mapValues at <console>:34 scala> pairRDD.mapValues(x => x+1).foreach(println) (Hadoop,2) (Spark,2) (Hive,2) (Spark,2)
8,join()
join表示内连接,对于给定的两个输入数据集(K,V1)和(K,V2),只有在两个数据集中都存在的key才会被输出,最终得到一个(K,(V1,V2))类型的数据集。
scala> val pairRDD1 = sc.| parallelize(Array(("spark",1),("spark",2),("hadoop",3),("hadoop",5)))
scala> val pairRDD2 = sc.parallelize(Array(("spark","fast")))
scala> pairRDD1.join(pairRDD2)
scala> pairRDD1.join(pairRDD2).foreach(println)
(spark,(1,fast))
(spark,(2,fast))
pairRDD1中的键值对(“spark”,1)和pairRDD2中的键值对(“spark”,“fast”),因为二者具有相同的key(即"spark"),所以会产生连接结果(“spark”,(1,“fast”))。
9,combineByKey()
combineByKey(createCombiner,mergeValue,mergeCombiners,partitioner,mapSideCombine)中的各个参数的含义如下:
(1)createCombiner:在第一次遇到key时创建组合器函数,将RDD数据集中的V类型值转换C类型值(V => C);
(2)mergeValue:合并值函数,再次遇到相同的Key时,将createCombiner的C类型值与这次传入的V类型值合并成一个C类型值(C,V)=>C;
(3)mergeCombiners:合并组合器函数,将C类型值两两合并成一个C类型值;
(4)partitioner:使用已有的或自定义的分区函数,默认是HashPartitioner;
(5)mapSideCombine:是否在map端进行Combine操作,默认为true。
文章来源:《Spark编程基础》 作者:林子雨
文章内容仅供学习交流,如有侵犯,联系删除哦!
相关文章:

Spark 键值对RDD的操作
键值对RDD(Pair RDD)是指每个RDD元素都是(key,value)键值对类型,是一种常见的RDD类型,可以应用于很多的应用场景。 一、 键值对RDD的创建 键值对RDD的创建主要有两种方式: &#x…...
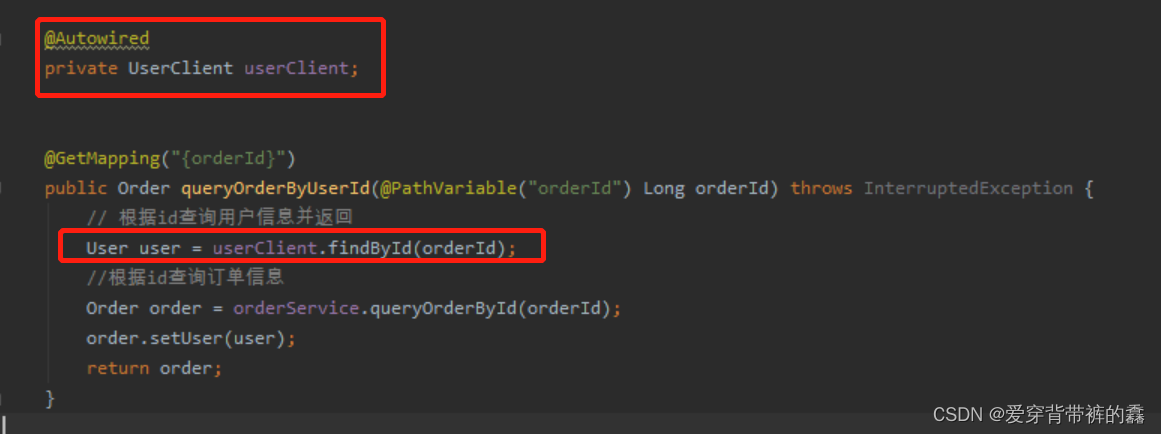
【SpringCloud】SpringCloud详解之Feign远程调用
目录前言SpringCloud Feign远程服务调用一.需求二.两个服务的yml配置和访问路径三.使用RestTemplate远程调用(order服务内编写)四.构建Feign(order服务内配置)五.自定义Feign配置(order服务内配置)六.Feign配置日志(oder服务内配置)七.Feign调优(order服务内配置)八.抽离Feign前…...
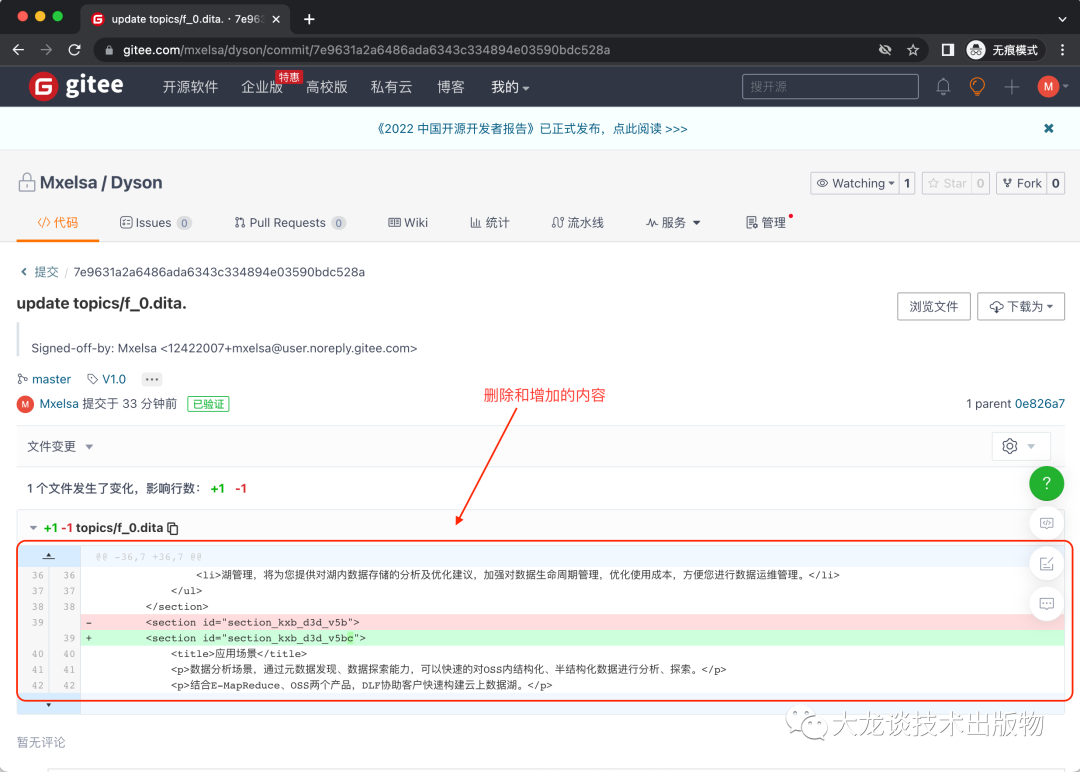
文档团队怎样使用GIT做版本管理
有不少小型文档团队想转结构化写作和发布,但是因为有限的IT技能和IT资源而受阻。本文为这样的小型文档团队而准备,描述怎样使用Git做内容的版本管理。 - 1 - 为什么需要版本管理 当一个团队进行协同创作内容时,有以下需要: 在对…...

【java】Java中-> 是什么意思?
先看一个例子 EventQueue.invokeLater(() -> {JFrame frame new ImageViewerFrame();frame.setTitle("ImageViewer");frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);frame.setVisible(true);}); // 上面那一段可以看成如下: EventQueue.invokeLater(ne…...
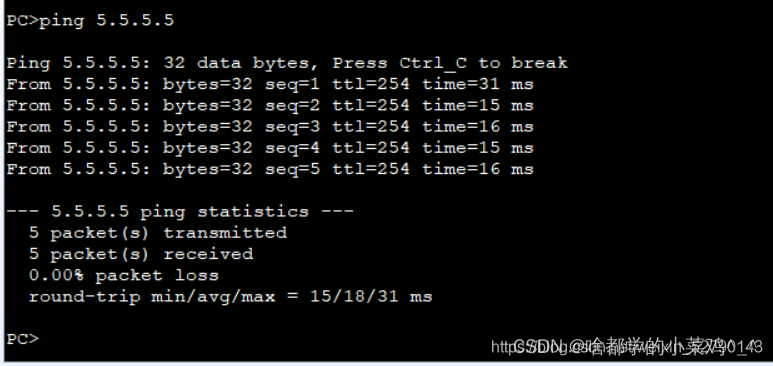
网络类型部分实验
1.实验思路: 首先用DHCP 给四台PC配置上地址,配置成功后 其次底层IP地址的下发完成的同时,进行检测是否可以ping通 接着进行R1和R5之间使用PPP的PAP认证,R5为主认证方 主认证方ISP 被认证方R1 其次进行R2和R5使用PPP的CHAP认证&am…...
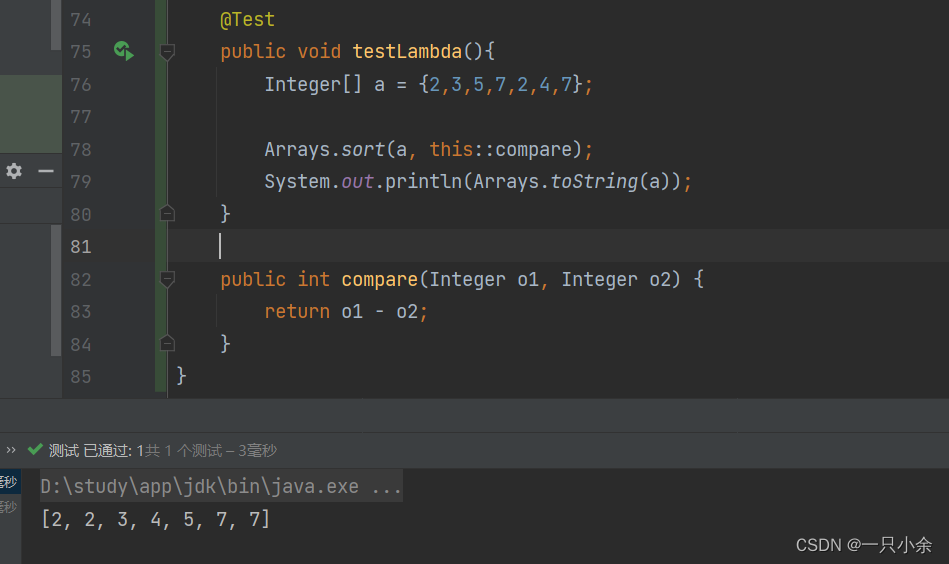
java教程--函数式接口--lambda表达式--方法引用
函数式接口 介绍 jdk8新特性,只有一个抽象方法的接口我们称之为函数接口。 FunctionalInterface JDK的函数式接口都加上了FunctionalInterface 注解进行标识。但是无论是否加上该注解只要接口中只有一个抽象方法,都是函数式接口。 如在Comparato…...
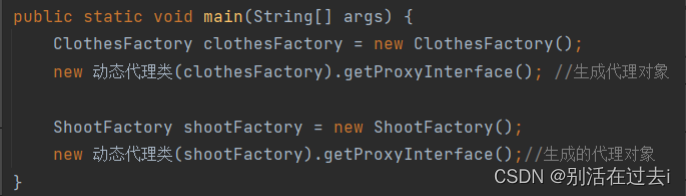
java——代理
什么是代理: 给目标对象一个代理对象,由代理对象控制着对目标对象的引用 为什么使用代理: ①:功能增强:通过代理业务对原有业务进行增强 ②:用户只能同行过代理对象间接访问目标对象,防止用…...

kubernetes中service探讨
文章目录序言kube-proxy代理模型userspace代理模型iptables代理模型ipvs代理模型修改代理模型Service资源类型ClusterIPNodePortLoadBalancerExternalName应用Service资源应用ClusterIP Service资源应用NodePort Service资源应用LoadBalancer Service资源外部IP序言 在Kuberne…...

Python3实现“美颜”功能
导语利用Python实现美颜。。。这是之前在GitHub上下载的一个项目。。。似乎有些日子了。。。所以暂时找不到原项目的链接了。。。今天抽空看了下它源代码的主要思想,似乎挺简单的。。。于是决定用Python3自己复现一下。。。T_T感觉还是挺有趣的。。。Just have a tr…...
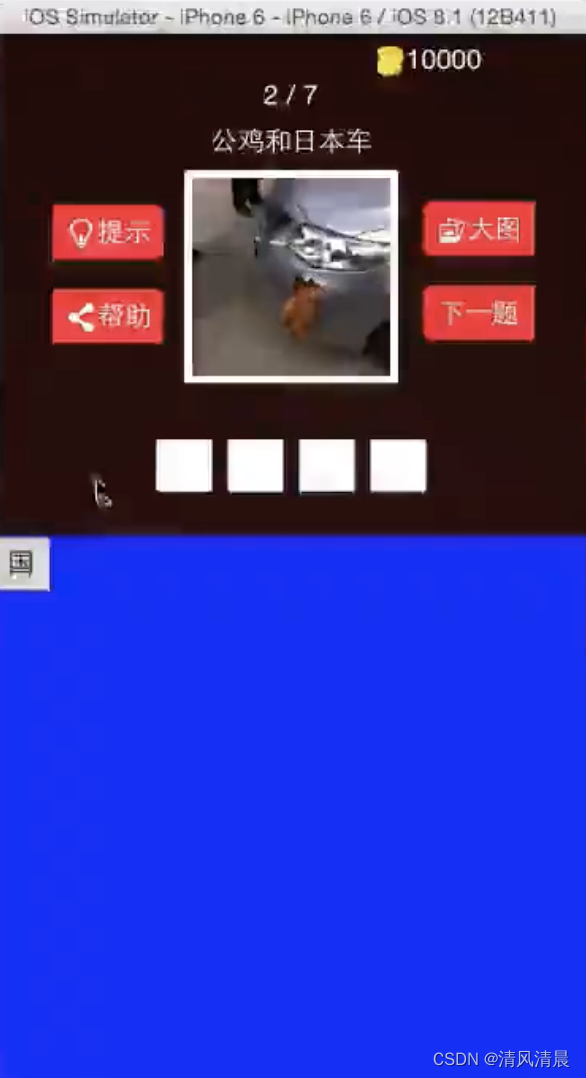
【创建“待选项”按钮02计算坐标 Objective-C语言】
一、之前,我们已经把“待选项”按钮,创建好了,但是唯一的问题是,坐标都是一样的,所以都显示在一起了 1.下面,我们来设置一下,这些“待选项”按钮的坐标, 现在,“待选项”按钮的坐标,是不是都在同一个位置啊, 回忆一下,这个待选项按钮,是怎么生成的, 首先,是在…...

自组织( Self-organization),自组织临界性(Self-organized criticality)
文章目录1. 自组织概述原则历史按领域物理化学生物学2. 自组织临界性概述3. 自组织临界性的特征4. 自组织临界模型5. 自然界中的自组织临界6. 自组织临界性和优化7. 自组织临界性的控制7.1 方案7.2 应用1. 自组织 wiki: Self-organization 图 200 C 水热处理过程中微米级 Nb3O…...
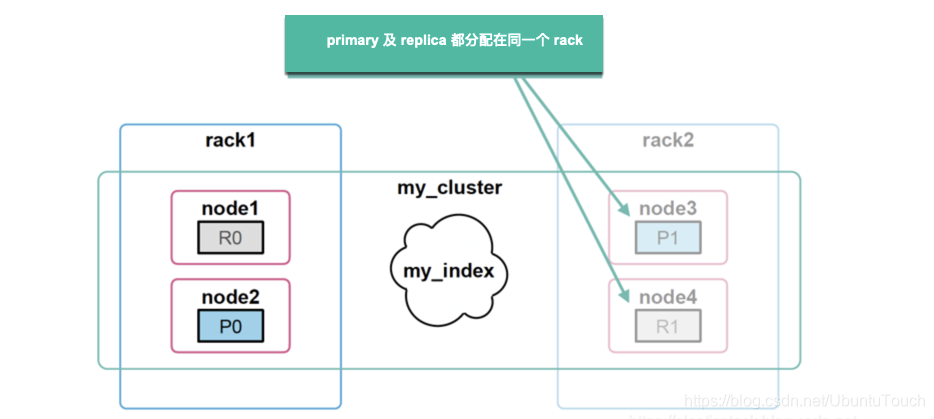
Elasticsearch:集群管理
在今天的文章中,我们应该学习如何管理我们的集群。 备份和分片分配是我们应该能够执行的基本任务。 分片分配过滤 Elasticsearch 将索引配到一个或多个分片中,我们可以将这些分片保存在特定的集群节点中。 例如,假设你有多个数据集群节点&am…...
| 机考必刷)
华为OD机试题 - 非严格递增连续数字序列(JavaScript)| 机考必刷
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:非严格递增连续数字序列题目输入输出示例一输入输出说明Code解题…...

lc23. 合并K个升序链表
题目描述给你一个链表数组,每个链表都已经按升序排列。请你将所有链表合并到一个升序链表中,返回合并后的链表。示例 1:输入:lists [[1,4,5],[1,3,4],[2,6]]输出:[1,1,2,3,4,4,5,6]解释:链表数组如下&…...
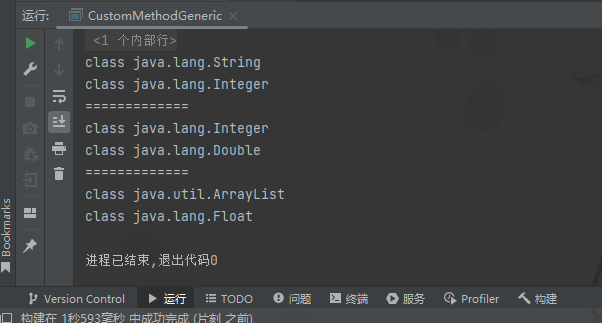
Java笔记029-泛型
泛型泛型的理解和好处看一个需求请编写程序,在ArrayList中,添加3个Dog对象Dog对象含有name和age,并输出name和age(要求使用getXxx)先用传统的方法来解决->引出泛型package com15.generic;import java.util.ArrayList;/*** author 甲柒* ve…...

港科夜闻|香港科大与中国联通成立联合实验室,推动智慧社会研究发展
关注并星标每周阅读港科夜闻建立新视野 开启新思维1、香港科大与中国联通成立联合实验室,推动智慧社会研究发展。香港科大与中国联通于3月9日签署两份协议以加强战略合作,并成立「香港科技大学 - 中国联通智慧社会联合实验室」,就香港科大建构…...
制作一个简单的信用卡验证表
下载:https://download.csdn.net/download/mo3408/87559584 效果图: 您可以从文章顶部附近的下载按钮获取该项目的完整代码。这些文件的概述如下所示: 我们需要将两个 .css 文件和两个 .js 文件包含在我们的 HTML 中。所有其他资源,例如 Bootstrap 框架、jQuery 和 Web 字…...

牛客小白月赛68
牛客小白月赛68A Tokitsukaze and New OperationB Tokitsukaze and Order Food DeliveryC Tokitsukaze and Average of SubstringD Tokitsukaze and Development TaskE Tokitsukaze and Colorful ChessboardF Tokitsukaze and New RenKinKama题目链接A Tokitsukaze and New Ope…...

【id:21】【20分】A. DS单链表--类实现
题目描述用C语言和类实现单链表,含头结点属性包括:data数据域、next指针域操作包括:插入、删除、查找注意:单链表不是数组,所以位置从1开始对应首结点,头结点不放数据类定义参考输入n第1行先输入n表示有n个…...

【实习_面试全程辅导分享】简历篇
🎋🎋哈喽,大家好,我是辰柒。快有一个月没有更新博文啦,那么这一个月不是在偷懒,而是在全心准备找实习的过程中。那么最终也是拿到了心仪的大厂offer——海康威视!!经过这次找实习的经历,我想就在校大学生找实习这件事情开设一个专栏,帮助大家在找实习的过程中减少焦…...
)
Jupyter Notebook文件损坏?3种方法快速恢复.ipynb中的代码(附Python脚本)
Jupyter Notebook文件损坏?3种方法快速恢复.ipynb中的代码(附Python脚本) 当你在深夜赶数据分析报告时突然断电,重启后发现Jupyter Notebook文件无法打开——这种绝望感每个数据工作者都懂。.ipynb文件损坏并非世界末日࿰…...

毕业设计实战:基于SpringBoot的网购平台管理系统设计与实现全攻略
毕业设计实战:基于SpringBoot的网购平台管理系统设计与实现全攻略 在开发“基于SpringBoot的网购平台管理系统”毕业设计时,曾因“订单状态与库存管理脱节”踩过关键坑——初期未设计清晰的订单状态机和库存联动机制,导致用户下单后库存未及时…...

手机越用越卡?Universal Android Debloater让Android设备重获新生
手机越用越卡?Universal Android Debloater让Android设备重获新生 【免费下载链接】universal-android-debloater Cross-platform GUI written in Rust using ADB to debloat non-rooted android devices. Improve your privacy, the security and battery life of …...

掌握Agentic RAG:动态智能代理,提升大模型学习与实战效率,CSDN小白程序员必收藏!
掌握Agentic RAG:动态智能代理,提升大模型学习与实战效率,CSDN小白程序员必收藏! Agentic RAG技术通过引入自主AI代理,解决了传统RAG系统依赖静态数据的局限性,实现实时检索最新数据,灵活调整策…...

Python类与对象实战:从简历模板到动态方法绑定的完整指南
Python类与对象实战:从简历模板到动态方法绑定的完整指南 面向对象编程(OOP)是现代编程语言的核心范式之一,而Python作为一门多范式语言,其面向对象特性尤为强大且易于使用。本文将通过构建一个简历模板系统的完整案例…...

Python:图解 NumPy
NumPy 是 Python 中最受欢迎的第三方库之一。本文将通过图示和更具实践性的方式介绍其使用方法,使你能够通过直观理解来加深记忆。一、导入 NumPyimport numpy as np二、NumPy 数组的创建NumPy 支持从列表、元组、字符串、缓冲区、迭代器等多种数据来源创建数组。1、…...

从零到一:在KEIL5中高效搭建华大HC32F460单片机开发环境
1. 开发环境搭建前的准备工作 第一次接触华大HC32F460单片机时,我完全被各种文件搞得晕头转向。后来才发现,只要理清楚文件结构,搭建开发环境其实并不复杂。这里分享下我的实战经验,帮你避开那些新手常踩的坑。 首先需要明确的是…...

第20篇:扩展卡尔曼滤波器实战精讲
本篇前置知识:掌握基础线性代数、了解状态空间方程、会基础Python编程、熟悉标准卡尔曼滤波原理、接触过工控闭环数据采集。 零基础小白也能跟着吃透,全程避开晦涩纯数学推导,所有知识点绑定机器人、自动驾驶、工控实测场景,代码直…...
)
Seurat实战:如何用FindMarkers函数精准鉴定单细胞亚群(附避坑指南)
Seurat实战:用FindMarkers函数精准鉴定单细胞亚群的7个关键策略 单细胞RNA测序技术正在彻底改变我们对复杂组织的理解能力。在肌肉组织、肿瘤微环境或大脑皮层等高度异质性的样本中,准确识别和注释细胞亚群是每个研究者面临的重大挑战。Seurat工具包中的…...

sysstat多语言支持:国际化部署的完整指南
sysstat多语言支持:国际化部署的完整指南 【免费下载链接】sysstat Performance monitoring tools for Linux 项目地址: https://gitcode.com/gh_mirrors/sy/sysstat sysstat是一款功能强大的Linux性能监控工具,支持多语言界面,能够帮…...