Day10—Spark SQL基础

Spark SQL介绍
Spark SQL是一个用于结构化数据处理的Spark组件。所谓结构化数据,是指具有Schema信息的数据,例如JSON、Parquet、Avro、CSV格式的数据。与基础的Spark RDD API不同,Spark SQL提供了对结构化数据的查询和计算接口。
Spark SQL的主要特点:
- 将SQL查询与Spark应用程序无缝组合
Spark SQL允许使用SQL或熟悉的API在Spark程序中查询结构化数据。与Hive不同的是,Hive是将SQL翻译成MapReduce作业,底层是基于MapReduce的;而Spark SQL底层使用的是Spark RDD。
- 可以连接到多种数据源
Spark SQL提供了访问各种数据源的通用方法,数据源包括Hive、Avro、Parquet、ORC、JSON、JDBC等。
- 在现有的数据仓库上运行SQL或HiveQL查询
Spark SQL支持HiveQL语法以及Hive SerDes和UDF (用户自定义函数) ,允许访问现有的Hive仓库。
DataFrame和DataSet
- DataFrame的结构
DataFrame是Spark SQL提供的一个编程抽象,与RDD类似,也是一个分布式的数据集合。但与RDD不同的是,DataFrame的数据都被组织到有名字的列中,就像关系型数据库中的表一样。
DataFrame在RDD的基础上添加了数据描述信息(Schema,即元信息) ,因此看起来更像是一张数据库表。例如,在一个RDD中有3行数据,将该RDD转成DataFrame后,其中的数据可能如图所示:

- DataSet的结构
Dataset是一个分布式数据集,是Spark 1.6中添加的一个新的API。相比于RDD, Dataset提供了强类型支持,在RDD的每行数据加了类型约束。
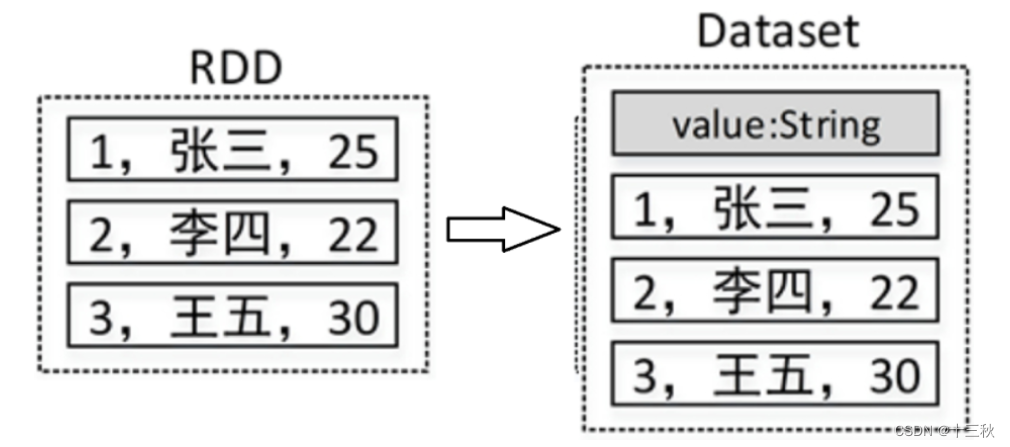
在Spark中,一个DataFrame代表的是一个元素类型为Row的Dataset,即DataFrame只是Dataset[Row]的一个类型别名。
Spark SQL的基本使用
Spark Shell启动时除了默认创建一个名为sc的SparkContext的实例外,还创建了一个名为spark的SparkSession实例,该spark变量可以在Spark Shell中直接使用。
SparkSession只是在SparkContext基础上的封装,应用程序的入口仍然是SparkContext。SparkSession允许用户通过它调用DataFrame和Dataset相关API来编写Spark程序,支持从不同的数据源加载数据,并把数据转换成DataFrame,然后使用SQL语句来操作DataFrame数据。
Spark SQL函数
内置函数
Spark SQL内置了大量的函数,位于API org.apache.spark.sql.functions
中。其中大部分函数与Hive中的相同。
使用内置函数有两种方式:一种是通过编程的方式使用;另一种是在SQL
语句中使用。
- 以编程的方式使用lower()函数将用户姓名转为小写/大写,代码如下:
df.select(lower(col("name")).as("greet")).show()
df.select(upper(col("name")).as("greet")).show()
上述代码中,df指的是DataFrame对象,使用select()方法传入需要查询的列,使用as()方法指定列的别名。代码col(“name”)指定要查询的列,也可以使用$"name"代替,代码如下:
df.select(lower($"name").as("greet")).show()
- 以SQL语句的方式使用lower()函数,代码如下:
df.createTempView("temp")
spark.sql("select upper(name) as greet from temp").show()
除了可以使用select()方法查询指定的列外,还可以直接使用filter()、groupBy()等方法对DataFrame数据进行过滤和分组,例如以下代码:
df.printSchema() # 打印Schema信息
df.select("name").show() # 查询name列
# 查询name列和age列,其中将age列的值增加1
df.select($"name",$"age"+1).show()
df.filter($"age">25).show() # 查询age>25的所有数据
# 根据age进行分组,并求每一组的数量
df.groupBy("age").count().show()
自定义函数
当Spark SQL提供的内置函数不能满足查询需求时,用户可以根据需求编写自定义函数(User Defined Functions, UDF),然后在Spark SQL中调用。
例如有这样一个需求:为了保护用户的隐私,当查询数据的时候,需要将用户手机号的中间4位数字用星号()代替,比如手机号180***2688。这时就可以编写一个自定义函数来实现这个需求,实现代码如下:
package spark.demo.sqlimport org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}/*** 用户自定义函数,隐藏手机号中间4位*/
object SparkSQLUDF {def main(args: Array[String]): Unit = {//创建或得到SparkSessionval spark = SparkSession.builder().appName("SparkSQLUDF").master("local[*]").getOrCreate()//第一步:创建测试数据(或直接从文件中读取)//模拟数据val arr=Array("18001292080","13578698076","13890890876")//将数组数据转为RDDval rdd: RDD[String] = spark.sparkContext.parallelize(arr)//将RDD[String]转为RDD[Row]val rowRDD: RDD[Row] = rdd.map(line=>Row(line))//定义数据的schemaval schema=StructType(List{StructField("phone",StringType,true)})//将RDD[Row]转为DataFrameval df = spark.createDataFrame(rowRDD, schema)//第二步:创建自定义函数(phoneHide)val phoneUDF=(phone:String)=>{var result = "手机号码错误!"if (phone != null && (phone.length==11)) {val sb = new StringBuffersb.append(phone.substring(0, 3))sb.append("****")sb.append(phone.substring(7))result = sb.toString}result}//注册函数(第一个参数为函数名称,第二个参数为自定义的函数)spark.udf.register("phoneHide",phoneUDF)//第三步:调用自定义函数df.createTempView("t_phone") //创建临时视图spark.sql("select phoneHide(phone) as phone from t_phone").show()// +-----------+// | phone|// +-----------+// |180****2080|// |135****8076|// |138****0876|// +-----------+}
}
窗口(开窗)函数
开窗函数是为了既显示聚合前的数据,又显示聚合后的数据,即在每一行的最后一列添加聚合函数的结果。开窗口函数有以下功能:
- 同时具有分组和排序的功能
- 不减少原表的行数
- 开窗函数语法:
聚合类型开窗函数
sum()/count()/avg()/max()/min() OVER([PARTITION BY XXX] [ORDER BY XXX [DESC]])
排序类型开窗函数
ROW_NUMBER() OVER([PARTITION BY XXX] [ORDER BY XXX [DESC]])
- 以row_number()开窗函数为例:
开窗函数row_number()是Spark SQL中常用的一个窗口函数,使用该函数可以在查询结果中对每个分组的数据,按照其排列的顺序添加一列行号(从1开始),根据行号可以方便地对每一组数据取前N行(分组取TopN)。row_number()函数的使用格式如下:
row_number() over (partition by 列名 order by 列名 desc) 行号列别名
上述格式说明如下:
partition by:按照某一列进行分组;
order by:分组后按照某一列进行组内排序;
desc:降序,默认升序。
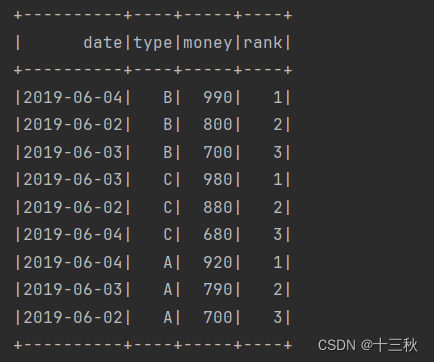
例如,统计每一个产品类别的销售额前3名,代码如下:
package spark.demo.sqlimport org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SparkSession}/*** 统计每一个产品类别的销售额前3名(相当于分组求TOPN)*/
object SparkSQLWindowFunctionDemo {def main(args: Array[String]): Unit = {//创建或得到SparkSessionval spark = SparkSession.builder().appName("SparkSQLWindowFunctionDemo").master("local[*]").getOrCreate()//第一步:创建测试数据(字段:日期、产品类别、销售额)val arr=Array("2019-06-01,A,500","2019-06-01,B,600","2019-06-01,C,550","2019-06-02,A,700","2019-06-02,B,800","2019-06-02,C,880","2019-06-03,A,790","2019-06-03,B,700","2019-06-03,C,980","2019-06-04,A,920","2019-06-04,B,990","2019-06-04,C,680")//转为RDD[Row]val rowRDD=spark.sparkContext.makeRDD(arr).map(line=>Row(line.split(",")(0),line.split(",")(1),line.split(",")(2).toInt))//构建DataFrame元数据val structType=StructType(Array(StructField("date",StringType,true),StructField("type",StringType,true),StructField("money",IntegerType,true)))//将RDD[Row]转为DataFrameval df=spark.createDataFrame(rowRDD,structType)//第二步:使用开窗函数取每一个类别的金额前3名df.createTempView("t_sales") //创建临时视图//执行SQL查询spark.sql("select date,type,money,rank from " +"(select date,type,money," +"row_number() over (partition by type order by money desc) rank "+"from t_sales) t " +"where t.rank<=3").show()}
}
结果展示
小结
本次学习了Spark SQL基础,学习Spark SQL基础是掌握大数据处理的关键一步。Spark SQL是Apache Spark的一个模块,它提供了对结构化和半结构化数据的高效处理能力。通过学习Spark SQL,你将能够使用SQL查询和DataFrame API来分析数据集。Spark SQL的核心优势在于其能够处理大规模数据集,同时保持高性能。它支持多种数据源,包括HDFS、S3、Parquet等,使得数据的读写变得简单。此外,Spark SQL还提供了丰富的数据类型和复杂的数据操作功能,如过滤、分组、排序和聚合。学习过程中,你将了解如何创建DataFrame,执行转换和操作,以及如何使用SQL语句进行查询。你还将学习到如何优化Spark SQL查询,包括使用分区、索引和缓存技术来提高性能。
掌握Spark SQL基础对于数据工程师和分析师来说非常重要,因为它不仅可以提高数据处理的效率,还可以帮助你更好地理解和分析大规模数据集。随着你的学习深入,你将能够更有效地利用Spark的强大功能来解决实际问题。
相关文章:
Day10—Spark SQL基础
Spark SQL介绍 Spark SQL是一个用于结构化数据处理的Spark组件。所谓结构化数据,是指具有Schema信息的数据,例如JSON、Parquet、Avro、CSV格式的数据。与基础的Spark RDD API不同,Spark SQL提供了对结构化数据的查询和计算接口。 Spark …...

开源技术:在线教育系统源码及教育培训APP开发指南
本篇文章,小编将探讨如何利用开源技术开发在线教育系统及教育培训APP,旨在为有志于此的开发者提供全面的指导和实践建议。 一、在线教育系统的基本构架 1.1架构设计 包括前端、后端和数据库三个主要部分。 1.2前端技术 在前端开发中,HTML…...

[C++][设计模式][观察者模式]详细讲解
目录 1.动机2.模式定义3.要点总结4.代码感受1.代码一1.FileSplitter.cpp2.MainForm.cpp 2.代码二1.FileSplitter.cpp2.MainForm.cpp 1.动机 在软件构建过程中,需要为某些对象建立一种“通知依赖关系” 一个对象(目标对象)的状态发生改变,所有的依赖对象…...

Adobe Acrobat 编辑器软件下载安装,Acrobat 轻松编辑和管理各种PDF文件
Adobe Acrobat,它凭借卓越的功能和丰富的工具,为用户提供了一个全面的解决方案,用于查看、创建、编辑和管理各种PDF文件。 作为一款专业的PDF阅读器,Adobe Acrobat能够轻松打开并展示各种格式的PDF文档,无论是文字、图…...

eVTOL飞机:技术挑战、应用机遇和运动的作用
最近,航空业的嗡嗡声围绕着电动空中出租车、空中拼车、无人驾驶航空货物运送等。这些概念都依赖于一类称为eVTOL的飞机,eVTOL是电动垂直起降的缩写。 与直升机类似,但没有噪音和排放,eVTOL可以在不需要简易机场的情况下飞行、悬停…...

【python】flask中如何向https服务器传输信息
【背景】 用flask做一个支持流媒体传输的网页,如何将信息post给流媒体服务器呢? 【方法】 简单例子,视图函数这么写: url = "https://yourip/mytext" headers = {Content-Type:application/octet-stream} @app.route(/,methods=["POST"...

计算机网络 —— 应用层(FTP)
计算机网络 —— 应用层(FTP) FTP核心特性:运作流程: FTP工作原理主动模式被动模式 我门今天来看应用层的FTP(文件传输协议) FTP FTP(File Transfer Protocol,文件传输协议&#x…...

zookeeper + kafka消息队列
zookeeper kafka 消息队列 一、消息队列简介 1、什么是消息队列 消息队列(Message Queue)是一种用于跨进程或分布式系统中传递消息的通信机制。消息队列在异步通信、系统解耦、负载均衡和容错方面具有重要作用。 (1)特性 异步…...

Python高级编程:深度学习基础
Python高级编程:深度学习基础 在前几篇文章中,我们探讨了Python的基础语法、面向对象编程、标准库、第三方库、并发编程、异步编程、网络编程与网络爬虫、数据库操作与ORM、数据分析与数据可视化以及机器学习基础。在这篇文章中,我们将深入探讨Python在深度学习领域的应用。…...
如何从magento1迁移到magento2
m2相较m1 变化可以说非常大,相当于从头到位都改写一遍,更现代化,更优雅。除了数据库表变化不是很大。 主要迁移的内容有: 1,主题 2,插件(自己开发的或者第三方插件) 3,数据库 主题 不能迁移到m…...
【Nginx】Nginx安装及简单使用
https://www.bilibili.com/video/BV1F5411J7vK https://www.kuangstudy.com/bbs/1353634800149213186 https://stonecoding.net/system/nginx/nginx.html https://blog.csdn.net/qq_40492693/article/details/124453090 Nginx 是一个高性能的 HTTP 和反向代理 Web 服务器。其特…...

【Linux系列】find命令使用与用法详解
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

Apple - DNS Service Discovery Programming Guide
本文翻译整理自:DNS Service Discovery Programming Guide(更新日期:2013-08-08 https://developer.apple.com/library/archive/documentation/Networking/Conceptual/dns_discovery_api/Introduction.html#//apple_ref/doc/uid/TP30000964 文…...

如何高效地为pip换源:详细操作指南
在Python开发中,pip是我们不可或缺的包管理工具。然而,默认的官方源下载速度较慢,尤其是在国内使用时可能会遇到网络问题。为了提高下载速度,我们可以通过更换国内的镜像源来解决这一问题。本文将详细介绍如何高效地为pip换源&…...
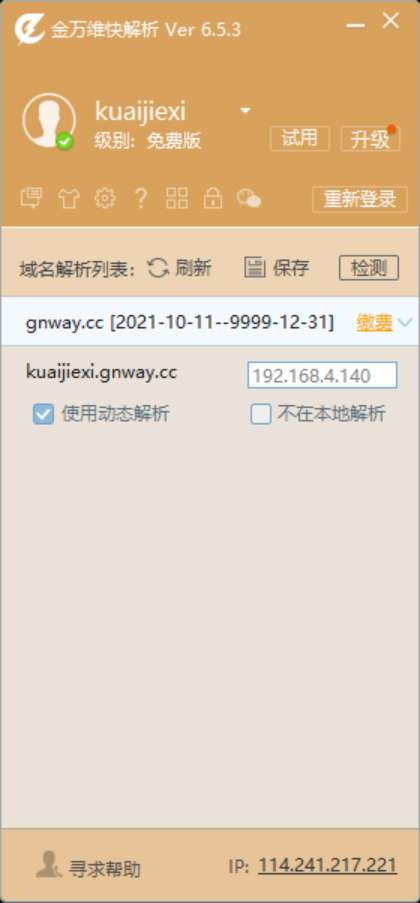
免费ddns工具,快解析DNS解析使用教程
DDNS(Dynamic Domain Name Server),中文叫动态域名解析,主要用于没有固定公网ip的网络环境下,使用一个固定的域名,解析动态变化的ip地址,达到远程访问的目的。 众所周知,目前公网ip资源非常紧缺…...

【Vite】控制打包结构
配置 vite.config.json 文件: import { defineConfig } from "vite";export default defineConfig({// ...build: {rollupOptions: {output: {entryFileNames: "js/[name]-[hash].js",chunkFileNames: "js/[name]-[hash].js",assetF…...
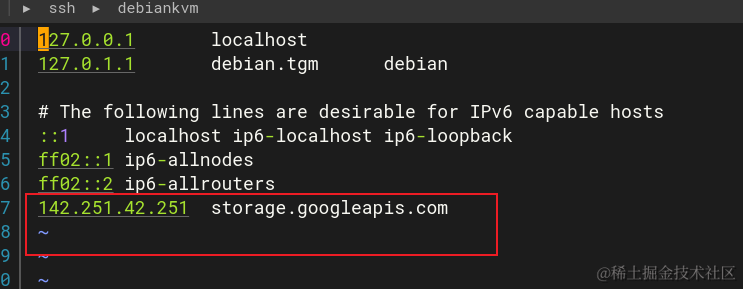
Debian Linux安装minikubekubectl
minikube&kubectl minkube用于在本地开发环境中快速搭建一个单节点的Kubernetes集群,还有k3s,k3d,kind都是轻量级的k8skubectl是使用K8s API 与K8s集群的控制面进行通信的命令行工具 这里使用Debian Linux演示,其他系统安装见官网,首先…...
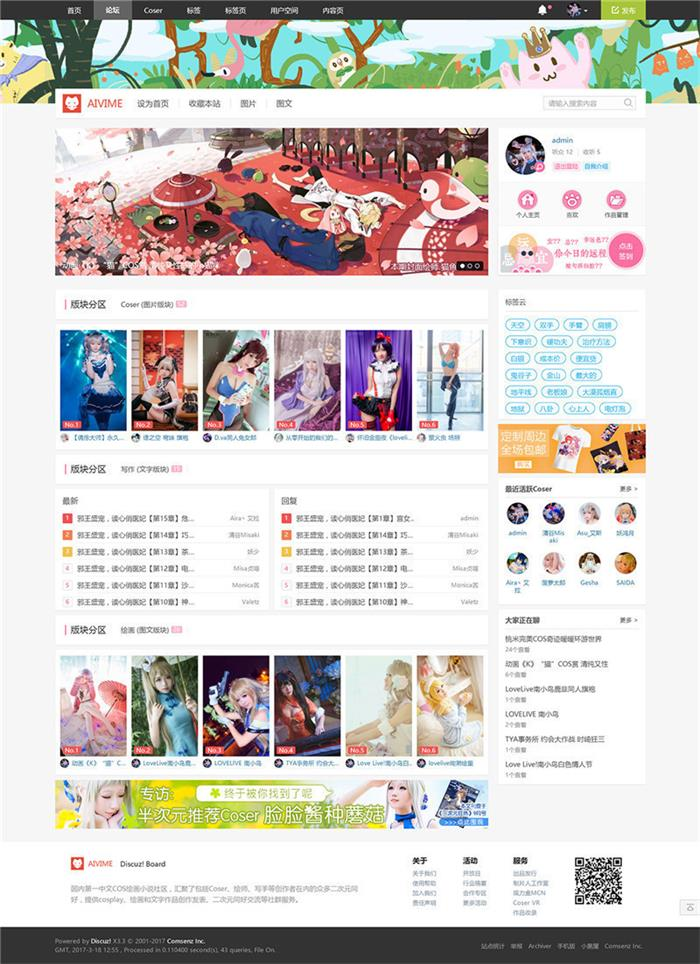
Discuz动漫二次元风格网站模板
1、本模板为门户论坛个人空间形式,其中个人空间模板需要单独购买,点击购买,美化N多默认模板页面 2、全新设计的标签页,标签页帖子图文调用 3、论坛首页,分区下版块帖子论坛首页自动调用,自带分区图片模式与…...

RIP、OSPF、IS-IS学习
文章目录 前言RIP路由信息协议OSPF开放最短路径优先IS-IS 中间系统到中间系统总结 前言 路由协议的种类繁多,每种协议都有其独特的特性、工作原理和适用场景。本文将重点介绍:RIP(路由信息协议)、OSPF(开放最短路径优…...

移植案例与原理 - build lite源码分析 之 hb命令__main__.py
hb命令可以通过python pip包管理器进行安装,应该是OpenHarmony Build的缩写,在python包名称是ohos-build。hb作为编译构建子系统提供的命令行,用于编译构建产品、芯片厂商组件或者单个组件。本文,我们来学习hb的源码。 1、hb的安…...

如何快速掌握G-Helper:华硕笔记本轻量级控制工具完全指南
如何快速掌握G-Helper:华硕笔记本轻量级控制工具完全指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook,…...

矩阵Zig-Zag遍历:对角线路径的优雅实现
矩阵Zig-Zag遍历:对角线路径的优雅实现 最近刷题遇到一个很有意思的矩阵遍历问题:如何以Zig-Zag(之字形)的方式打印一个二维矩阵? 什么是Zig-Zag遍历? 简单来说,就是从矩阵的左上角开始&#…...
)
救砖实录:河南联通B860AV2.1U变砖后,我是如何通过线刷救活的(S905LB+NAND闪存方案)
从绝望到重生:B860AV2.1U机顶盒线刷救砖全流程拆解 那天晚上十一点半,当我第七次按下机顶盒电源键却依然只看到指示灯诡异闪烁时,后背的冷汗已经浸透了T恤——这个价值四百多的联通定制设备,在我尝试刷入第三方固件后彻底变成了一…...

UI-TARS桌面版:用自然语言控制计算机的智能GUI助手
UI-TARS桌面版:用自然语言控制计算机的智能GUI助手 【免费下载链接】UI-TARS-desktop The Open-Source Multimodal AI Agent Stack: Connecting Cutting-Edge AI Models and Agent Infra 项目地址: https://gitcode.com/GitHub_Trending/ui/UI-TARS-desktop …...

Akebi-GC游戏辅助工具:5个核心模块深度解析与实战应用指南
Akebi-GC游戏辅助工具:5个核心模块深度解析与实战应用指南 【免费下载链接】Akebi-GC (Fork) The great software for some game that exploiting anime girls (and boys). 项目地址: https://gitcode.com/gh_mirrors/ak/Akebi-GC Akebi-GC是一款专为特定游戏…...
)
不止于统计:用ArcGIS Model Builder自动化你的土地利用转移矩阵(附模型下载与修改教程)
从手动到智能:ArcGIS Model Builder在土地利用分析中的高阶自动化实践 当规划师面对十年间的土地利用变化数据时,传统的手工操作流程往往成为效率瓶颈。每增加一个研究时段,就需要重复执行数据融合、空间相交、表格导出和矩阵制作等标准化操作…...
)
类与对象(三)
再谈构造函数构造函数体赋值在创建对象时,编译器会通过调用构造函数,给对象中的各个成员变量一个合适的初始值:调用该构造函数后,对象中的每个成员变量都有了一个初始值,但是构造函数中的语句只能将其称作为赋初值&…...
SVPWM算法MATLAB仿真进阶:从模型搭建到代码生成)
stm32 FOC从学习开发(七)SVPWM算法MATLAB仿真进阶:从模型搭建到代码生成
1. SVPWM算法仿真与代码生成全流程 搞电机控制的朋友都知道,SVPWM(空间矢量脉宽调制)是FOC(磁场定向控制)的核心算法之一。前几期我们聊过Clark变换、Park变换,也讲过SVPWM的基本原理,今天咱们就…...

YouMightNotNeedJS与响应式设计:打造完美适配所有设备的UI组件
YouMightNotNeedJS与响应式设计:打造完美适配所有设备的UI组件 【免费下载链接】YouMightNotNeedJS 项目地址: https://gitcode.com/gh_mirrors/yo/YouMightNotNeedJS 在现代网页开发中,实现跨设备兼容的响应式界面是提升用户体验的关键。YouMig…...
)
Unity SLG大地图实战:用TileManager和AOI搞定网格管理与视野同步(附Demo代码)
Unity SLG大地图开发实战:网格管理与AOI视野同步的工程化解决方案 在SLG游戏开发中,大地图系统是核心体验的基石。面对动辄数万网格的动态管理需求,以及需要与后端高效协作的视野同步问题,传统开发方式往往陷入性能瓶颈和逻辑混乱…...