Spring Data JPA
文章目录
- 一、Spring Data基础概念
- 二、JPA与JDBC的相同与不同之处
- 三、Hibernate & JPA快速搭建
- 1.添加依赖
- 2.实体类
- 3.hibernate的配置文件 ——hibernate.cfg.xml
- 四、测试——基于hibernate的持久化(单独使用)
- 五、测试——基于JPA的持久化(单独使用)
- 1.建立 /resources/META-INF/persistence.xml 配置文件
- 2.案例
- 六、JPA对象的四种状态
- 临时状态
- 持久状态
- 删除状态
- 游离状态
- 方法下对象的不同状态情况
- 1、persist(Object entity)
- 2、merge(Object entity)
- 3、refresh(Object entity)
- 4、remove(Object entity)
- 七、Spring Data JPA搭建 -- xml方式
- 1.添加依赖
- 2. spring.xml
- 3. CRUD测试 -- spring
- 八、Spring Data JPA搭建 -- JavaConfig 方式
- 1.JavaConfig
- 九、自定义操作
- 1.JPQL和SQL
- 2.规定方法名
- 3.Query By Example 动态查询
- 4.Specifications
- 5.Query DSL
一、Spring Data基础概念
Spring Data:统一和简化对不同类型持久性存储(关系数据库系统和NoSQL数据存储)的访问。
特性:模板制作、对象/数据存储映射、Repository支持
二、JPA与JDBC的相同与不同之处
相同:
1.都跟数据库操作有关,JPA是JDBC的升华。
2.JPA和JDBC都是一组规范接口
不同之处:
1.JDBC是由各个关系型数据库实现的,JPA是由ORM框架实现。
2.JDBC使用SQL语句和数据库通信,JPA用面向对象方式,通过ORM框架来生成SQL,进行操作。
3.JPA在JDBC之上,JPA也要依赖JDBC才能操作数据库。
三、Hibernate & JPA快速搭建
1.添加依赖
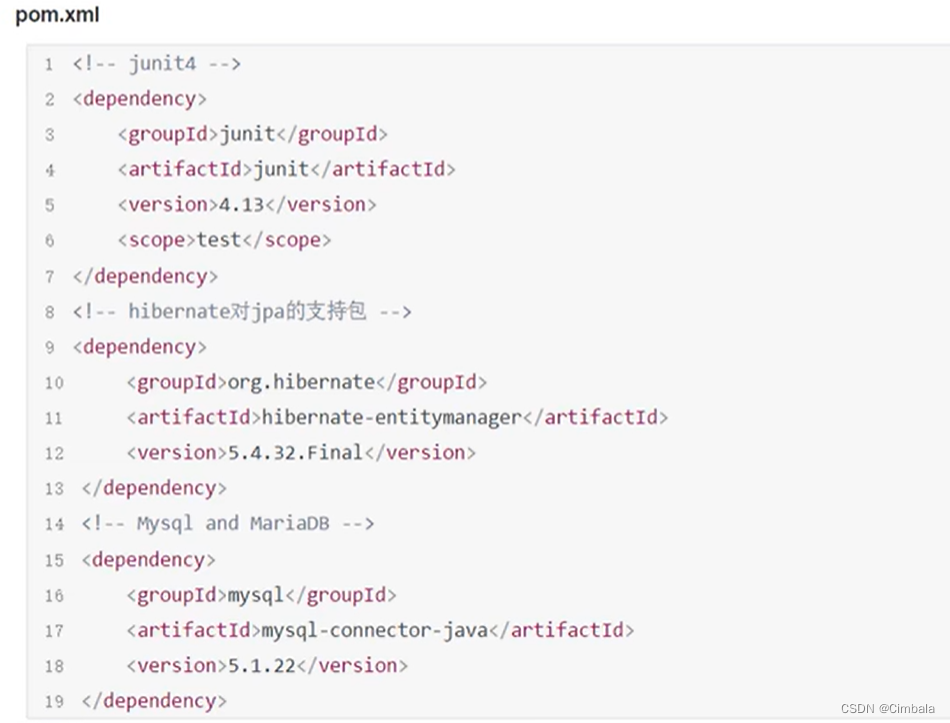
2.实体类
/*** 客户的实体类* 配置映射关系* 1.实体类和表的映射关系* @Entity:声明实体类* @Table:配置实体类和表的映射关系* name : 配置数据库表的名称* 2.实体类中属性和表中字段的映射关系*/
@Data
@Entity
@Table(name = "tb_customer")
public class Customer {/*** @Id:声明主键的配置* @GeneratedValue:配置主键的生成策略* strategy:* GenerationType.IDENTITY :自增,mysql* 底层数据库必须支持自动增长(底层数据库支持的自动增长方式,对id自增)* GenerationType.SEQUENCE : 序列,oracle* 底层数据库必须支持序列* GenerationType.TABLE : jpa提供的一种机制,通过一张数据库表的形式帮助我们完成主键自增* GenerationType.AUTO : 由程序自动的帮助我们选择主键生成策略* @Column:配置属性和字段的映射关系* name:数据库表中字段的名称*/@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(name = "customer_id")private Long Id; //客户的主键@Column(name = "customer_name")private String name;//客户名称@Column(name="customer_age")private int age;//客户年龄@Column(name="customer_sex")private boolean sex;//客户性别@Column(name="customer_phone")private String phone;//客户的联系方式@Column(name="customer_address")private String address;//客户地址
}
@Entity 作为hiberbate实体类
@Tabel(name=“表名”) 映射的表名
@Id 声明主键
@GenerateValue 主键的生成策略
@Column(name=“字段名”) 表单的列名
3.hibernate的配置文件 ——hibernate.cfg.xml
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC"-//Hibernate/Hibernate Configuration DTD//EN""http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration><session-factory><!--使用 Hibernate 自带的连接池配置--><property name="connection.driver_class">com.mysql.jdbc.Driver</property><property name="connection.url">jdbc:mysql://localhost:3306/bianchengbang_jdbc?characterEncoding=UTF-8</property><property name="hibernate.connection.username">root</property><property name="hibernate.connection.password">root</property><!--hibernate 方言--><property name="hibernate.dialect">org.hibernate.dialect.MySQL5Dialect</property><!--打印sql语句--><property name="hibernate.show_sql">true</property><!--格式化sql--><property name="hibernate.format_sql">true</property><!--表生成策略none :不会创建表create : 程序运行时创建数据库表(如果有表,先删除表再创建)update :程序运行时创建表(如果有表,不会创建表)create-drop : 每次加载hibernate时根据model类生成表,但是sessionFactory一关闭,表就自动删除。validate : 每次加载hibernate时,验证创建数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值--><property name="hbm2ddl.auto">update</property><!-- 加载映射文件 择一--><mapping resource="net/biancheng/www/mapping/User.hbm.xml"/><!-- 指定哪些pojo需要进行ORM映射 择一--><mapping class="com.test.pojo.Customer"/></session-factory>
</hibernate-configuration>
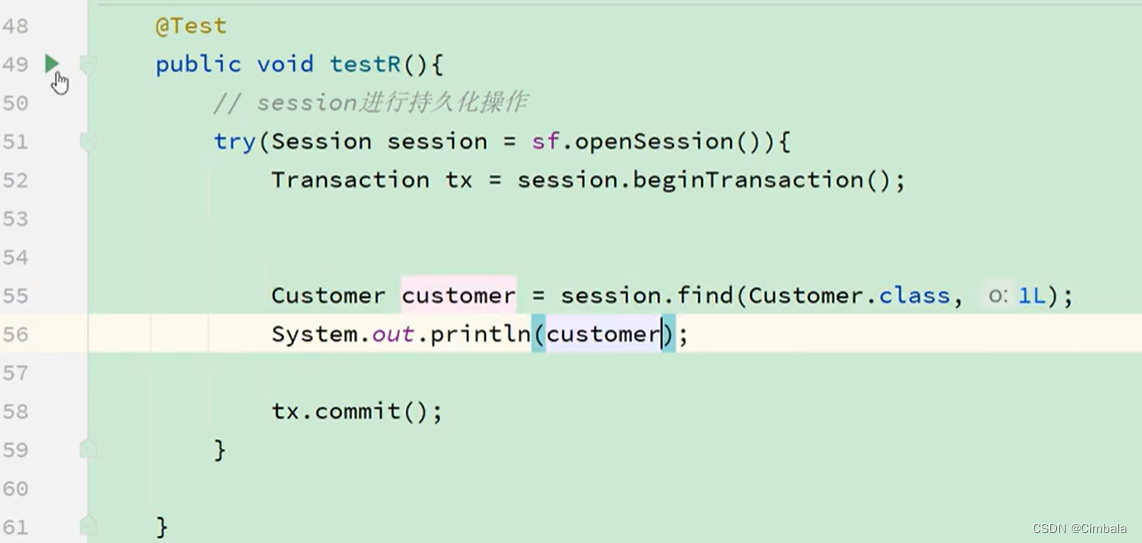
四、测试——基于hibernate的持久化(单独使用)
案例


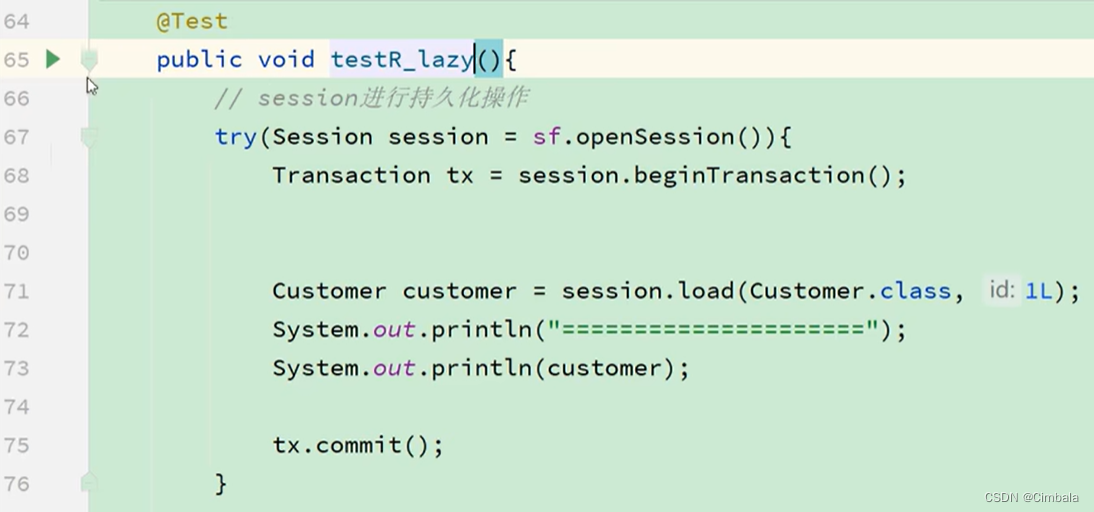
懒查询


五、测试——基于JPA的持久化(单独使用)
1.建立 /resources/META-INF/persistence.xml 配置文件
依赖不用改,多加一个配置文件。IDEA有persistence模板:setting=》file and code Template=》JPA==》Deployment descriptors=》persistenceXX.xml
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="http://java.sun.com/xml/ns/persistence" version="2.0"><!-- name:持久化单元名称,transaction-type:持久化单元事务类型(JTA:分布式事务管理,RESOURCE_LOCAL:本地事务管理) --><persistence-unit name="myJpa" transaction-type="RESOURCE_LOCAL"><!--jpa的实现方式,配置JPA服务提供商 --><provider>org.hibernate.jpa.HibernatePersistenceProvider</provider><!-- 可配可不配,如果配置了顺序不能错,必须在provider之后--><!--<class>com.test.pojo.Customer</class>--><!--可选配置:配置jpa实现方的配置信息--><properties><!-- 数据库信息配置:数据库驱动、数据库地址、数据库账户、数据库密码 --><property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver"/><property name="hibernate.connection.url" value="jdbc:mysql://127.0.0.1:3306/hibernate_jpa?characterEncoding=UTF-8"/><property name="hibernate.connection.username" value="root"/><property name="hibernate.connection.password" value="password"/><!-- 配置JPA服务提供商可选参数 --><property name="hibernate.show_sql" value="true" /><!-- 自动显示sql --><property name="hibernate.format_sql" value="true"/><!-- 格式化sql --><!-- 自动创建数据库表:none :不会创建表create : 程序运行时创建数据库表(如果有表,先删除表再创建)update :程序运行时创建表(如果有表,不会创建表)create-drop : 每次加载hibernate时根据model类生成表,但是sessionFactory一关闭,表就自动删除。validate : 每次加载hibernate时,验证创建数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值。--><property name="hibernate.hbm2ddl.auto" value="update" /></properties></persistence-unit>
</persistence>
2.案例
/**
* 测试jpa的保存 案例:保存一个客户到数据库中
* Jpa的操作步骤
* 1.加载配置文件创建工厂(实体管理器工厂)对象
* 2.通过实体管理器工厂获取实体管理器
* 3.获取事务对象,开启事务
* 4.完成增删改查操作
* 5.提交事务(回滚事务)
* 6.释放资源
*/
@Test
public void testSave() {//1.加载配置文件创建工厂(实体管理器工厂)对象EntityManagerFactory factory = Persistence.createEntityManagerFactory("myJpa");//2.通过实体管理器工厂获取实体管理器EntityManager em = factory.createEntityManager();//3.获取事务对象,开启事务EntityTransaction tx = em.getTransaction();tx.begin();//4.完成增删改查操作:保存一个客户到数据库中Customer customer = new Customer();customer.setName("Sam");customer.setAddress("Beijing");//保存操作em.persist(customer);//5.提交事务tx.commit();//6.释放资源em.close();factory.close();
}---------------------------------api
//立即查询
Customer customer = em.find(Custormer.class,1L);
//懒查询
Customer customer = em.getReference(Custormer.class,1L);
//更新 指定id会先查询数据是否有变化,有变化则更新,不指定id会插入一条数据
Customer customer = new Customer();
customer.setCustId(5L);
customer.setCustName("dfg");
em.merge(customer);
//更新 -- JPQL 不会进行查询 使用实体类名和属性名
String jpql = "Update Customer set name=:name where id=:id ";
em.createQuery(jpql).setParameter("name","李四").setParameter("id","5L").executeUpdate();
//更新 -- 使用SQL 使用表名和字段名
String sql = "Update tb_customer set name=:name where id=:id ";
em.createNativeQuery(sql).setParameter("name","李四11").setParameter("id","5L").executeUpdate();
//删除 先查再删除
//不能删除游离数据,只能删除持久化数据(从数据库里查出来的数据)
Customer customer = em.find(Custormer.class,5L);
em.remove(customer);
六、JPA对象的四种状态
临时状态
刚创建出来的对象,它此时还没与entityManager发生关系,没有被持久化,不处于entityManager中的对象。
持久状态
与entityManager发生关系,已经被持久化,是数据库实在的记录,比如执行了persist()、find()、merge()。
情况:
持久状态进行了修改会同步数据库;把数据库里的记录查询出来做修改并没有执行保存操作,也会把更新数据的操作同步到数据库。
删除状态
执行remove()方法,事物提交之前。
游离状态
游离状态是提交到数据库后,事务commit后实体的状态。比如该对象commit之后在数据库有对应的数据,但是它还没与entityManager发生关系。此时实体的属性可以做任何改变,也不会同步到数据库,因为事务已经提交了。 
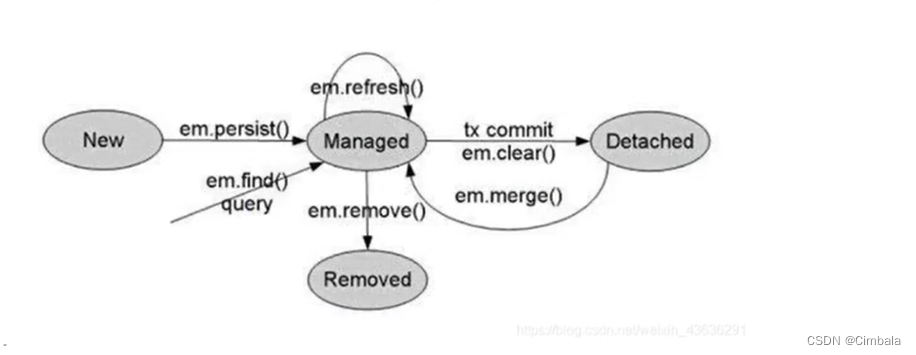
方法下对象的不同状态情况
1、persist(Object entity)
persist方法可以将实例转换为managed(托管)状态,在调用flush()方法或提交事物之后 ,实例将会被插入到数据库中。
对不同状态下的实例A,persist会产生以下操作:
1)如果A是一个new状态的实体,它将会转为managed状态;
2)如果A是一个managed状态的实体,它的状态不会发生任何改变,但是系统仍会在数据库执行 insert 操作;
3)如果A是一个removed(删除)状态的实体,它将会转换为受控状态;
4)如果A是一个detached(分离)状态的实体,该方法会抛出IllegalArgumentException异常,具体异常根据不同的JPA实现有关。
2、merge(Object entity)
merge方法的主要作用是将用户对一个detached状态实体的修改进行归档,归档后将产生一个新的managed状态对象。
对不同状态下的实例A,merge会产生以下操作:
1)如果A是一个detached状态的实体,该方法会将A的修改提交到数据库,并返回一个新的managed状态的实例A2;
2)如果A是一个new状态的实体,该方法会产生一个根据A产生的managed状态实体A2;
3)如果A是一个managed状态的实体,它的状态不会发生任何改变,但是系统仍会在数据库执行update操作。
4)如果A是一个removed状态的实体,该方法会抛出IllegalArgumentException异常。
3、refresh(Object entity)
refresh方法可以保证当前的实例与数据库中的实例内容一致。
对不同状态下的实例A,refresh会产生以下操作:
1)如果A是一个new状态的实体,A的状态不会发生任何改变,但系统仍会在数据库中执行delete语句;
2)如果A是一个managed状态的实体,它的属性将会和数据库中的数据同步;
3)如果A是一个removed状态的实体,该方法将会抛出异常:Entity not managed
4)如果A是一个detached状态的实体,该方法将会抛出异常;
4、remove(Object entity)
remove方法可以将实体转换为removed状态,并且在调用flush()方法或提交事物后删除数据库中的数据。
对不同状态下的实例A,remove会产生以下操作:
1)如果A是一个new状态的实体,A的状态不会发生任何改变,但系统仍会在数据库中执行delete语句;
2)如果A是一个managed状态的实体,它的状态会转换为removed;
3)如果A是一个removed状态的实体,不会发生任何操作;
4)如果A是一个detached状态的实体,该方法将会抛出异常;
七、Spring Data JPA搭建 – xml方式
1.添加依赖
父项目
添加spring data的统一版本管理,它可以统一子项目的Spring Data JDBC、Spring Data JPA 、Spring Data Redis等版本。
<dependencyManagement><dependencies><dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-bom</artifactId><version>2022.0.2</version><scope>import</scope><type>pom</type></dependency></dependencies>
</dependencyManagement>
子项目
spring 项目需要另外添加hibernate依赖,spring boot项目不需要。
<dependencies><dependency><groupId>org.springframework.data</groupId><artifactId>spring-data-jpa</artifactId></dependency>
<dependencies>
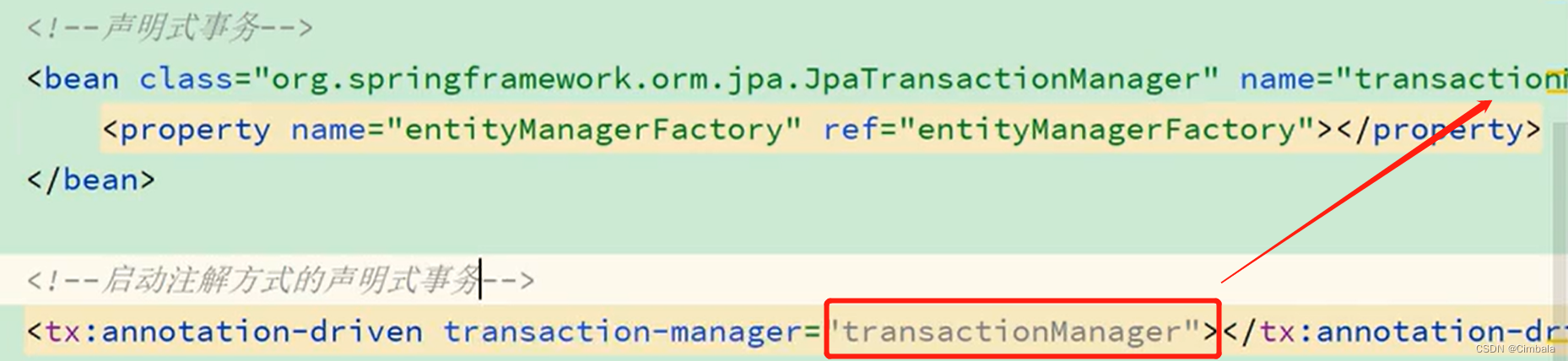
2. spring.xml
整合jpa


< jpa:repositories />对应@EnableJpaRepositories注解


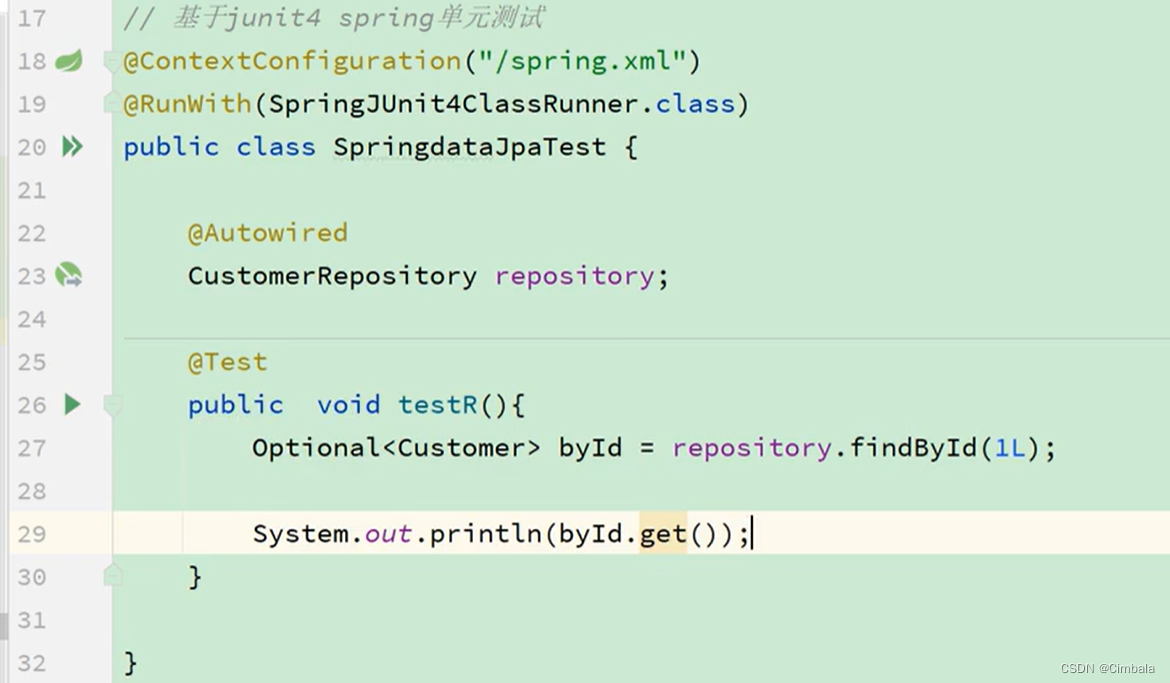
3. CRUD测试 – spring
定义接口继承CrudRepository接口
public interface CrudRepository<T, ID> extends Repository<T, ID> {}

查询
插入

更新 先查再更新

删除 先查再删除,把new出来的实例的游离状态改为持久状态

八、Spring Data JPA搭建 – JavaConfig 方式
1.JavaConfig
//标记当前类为配置类
@Configuration
//启动jpa 相当于xml的<jpa:repository/>标签 basePackage:指定数据返回层.接口
@EnableJpaRepositories(basePackage="com.test.repositories")
//开启事务
@EnableTransactionManagement
class ApplicationConfig {@Beanpublic DataSource dataSource() {DruidDataSource dataSource = new DruidDataSource();dataSource.setUserName("root");dataSource.setPassWord("123456");dataSource.setDriverClassName("com.mysql.jdbc.Driver");dataSource.setUrl("jdbc:mysql://127.0.0.1:3306/hibernate_jpa?characterEncoding=UTF-8");return dataSource;//使用内嵌内存数据库/**EmbeddedDatabaseBuilder builder = new EmbeddedDatabaseBuilder();return builder.setType(EmbeddedDatabaseType.HSQL).build();**/}@Beanpublic LocalContainerEntityManagerFactoryBean entityManagerFactory() {HibernateJpaVendorAdapter vendorAdapter = new HibernateJpaVendorAdapter();vendorAdapter.setGenerateDdl(true);vendorAdapter.setShowSql(true);LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();factory.setJpaVendorAdapter(vendorAdapter);//指定实体类的包factory.setPackagesToScan("com.acme.domain");factory.setDataSource(dataSource());return factory;}@Beanpublic PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {JpaTransactionManager txManager = new JpaTransactionManager();txManager.setEntityManagerFactory(entityManagerFactory);return txManager;}
}
测试使用
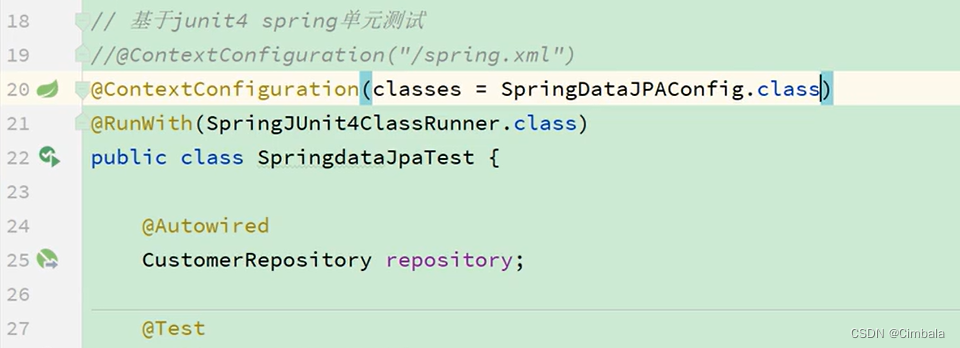
九、自定义操作
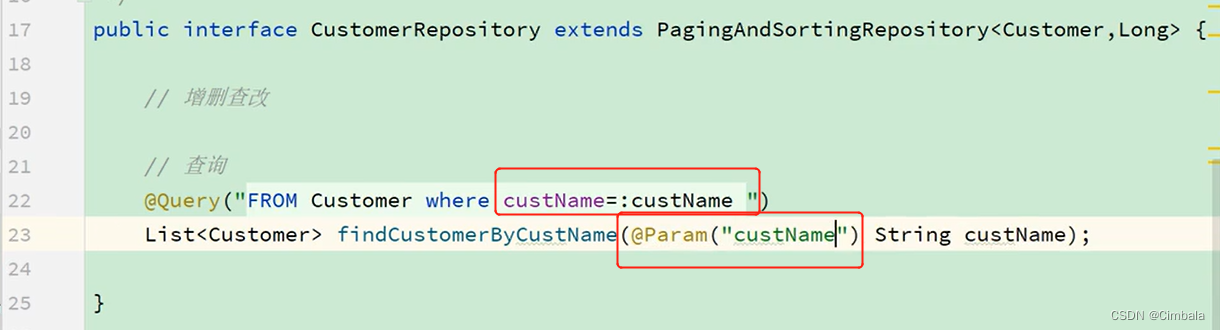
1.JPQL和SQL
JPQL定义,参数可以使用索引指定,或参数名结合@Param注解指定。
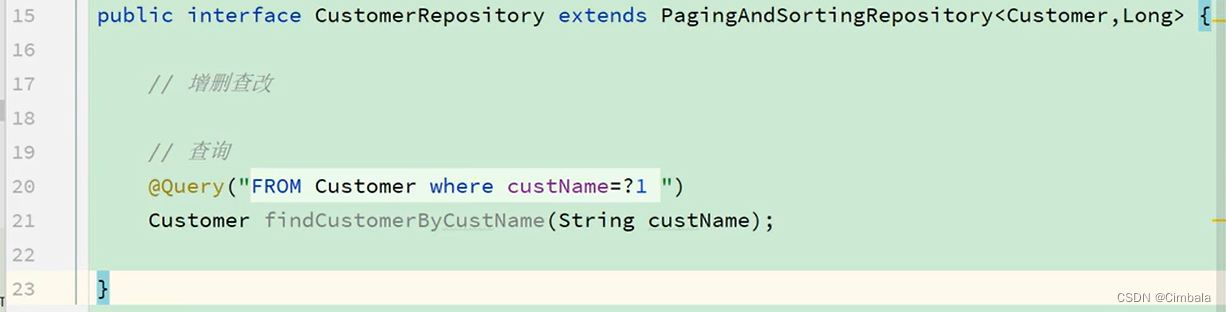
用 法

增删改需要开启事务,@Transactional通常放在业务逻辑层上声明。

JPQL是不支持新增的,用Hibernate实现伪插入,只能插入从别的地方查到的值。
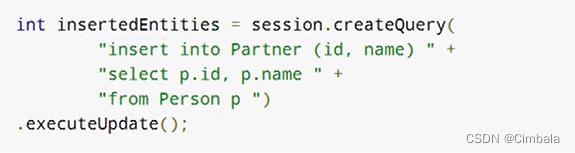



SQL

2.规定方法名
根据提供的主题关键字(前缀)决定方法作用,谓词关键字和修饰符决定查询条件。只支持查询和删除。官网使用说明,有详细使用方法的
例:
findBy(关键字)+ 属性名称(首字母大写)+ 查询条件(首字母大写)

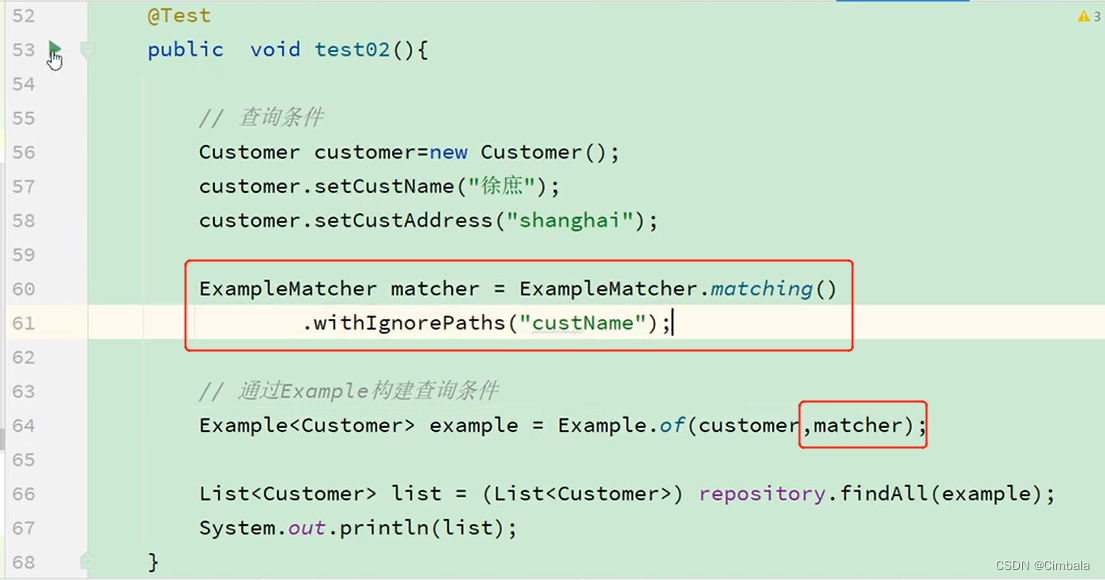
3.Query By Example 动态查询
只支持查询,只支持字符串(开头、包含、结尾、正则匹配),不支持嵌套或分组的属性约束。官网使用说明
实现:
//继承QueryByExampleExecutor接口
public interface CustomerRepository extends PagingAndSortingRepository<Customer, Long> ,QueryByExampleExecutor<Customer>{ … }
测试:
通过customer对象来进行筛选。

通过匹配器进行条件的限制。
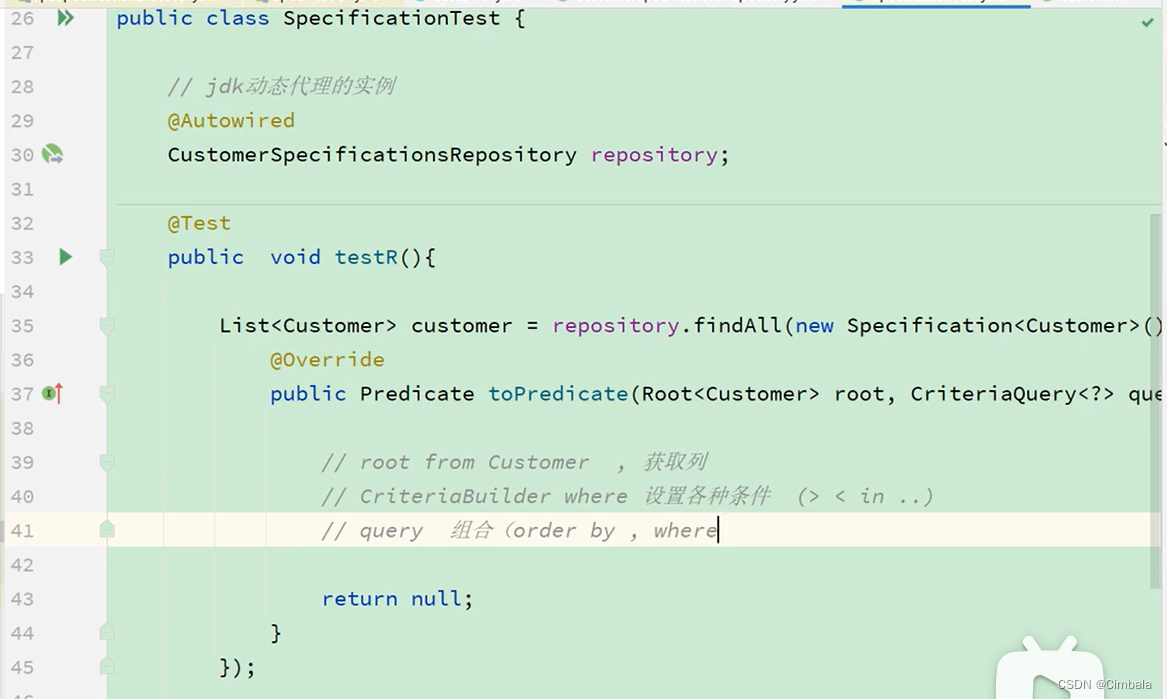
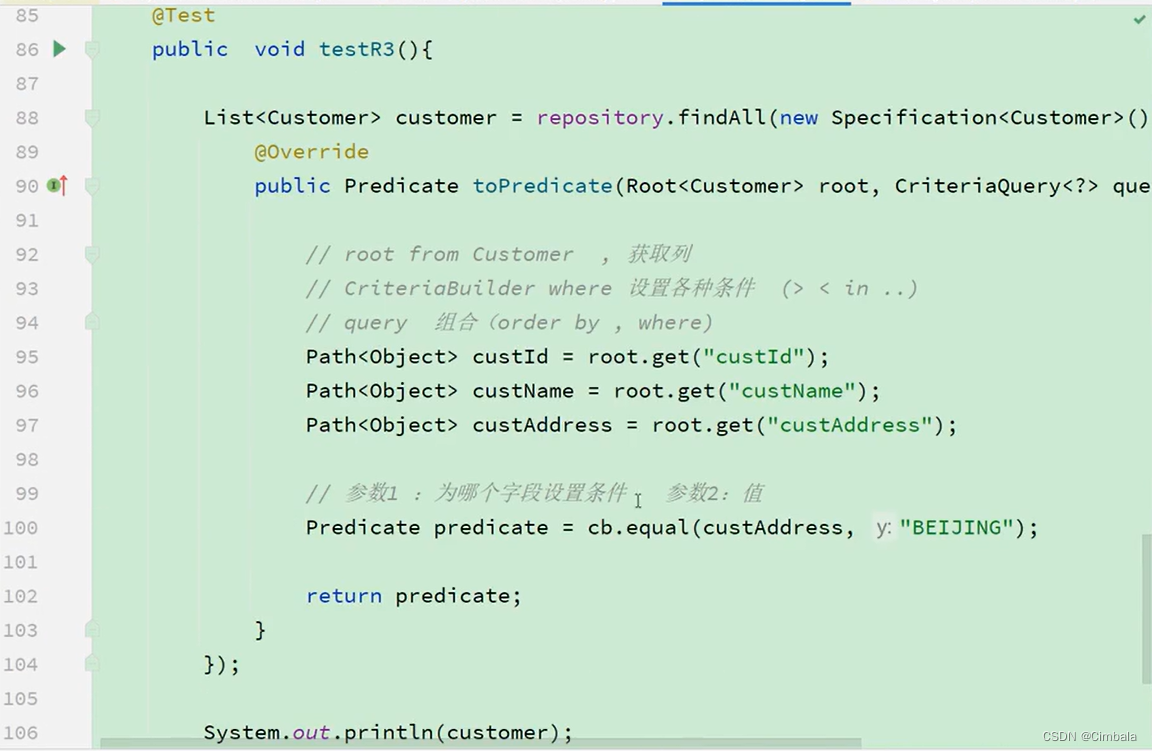
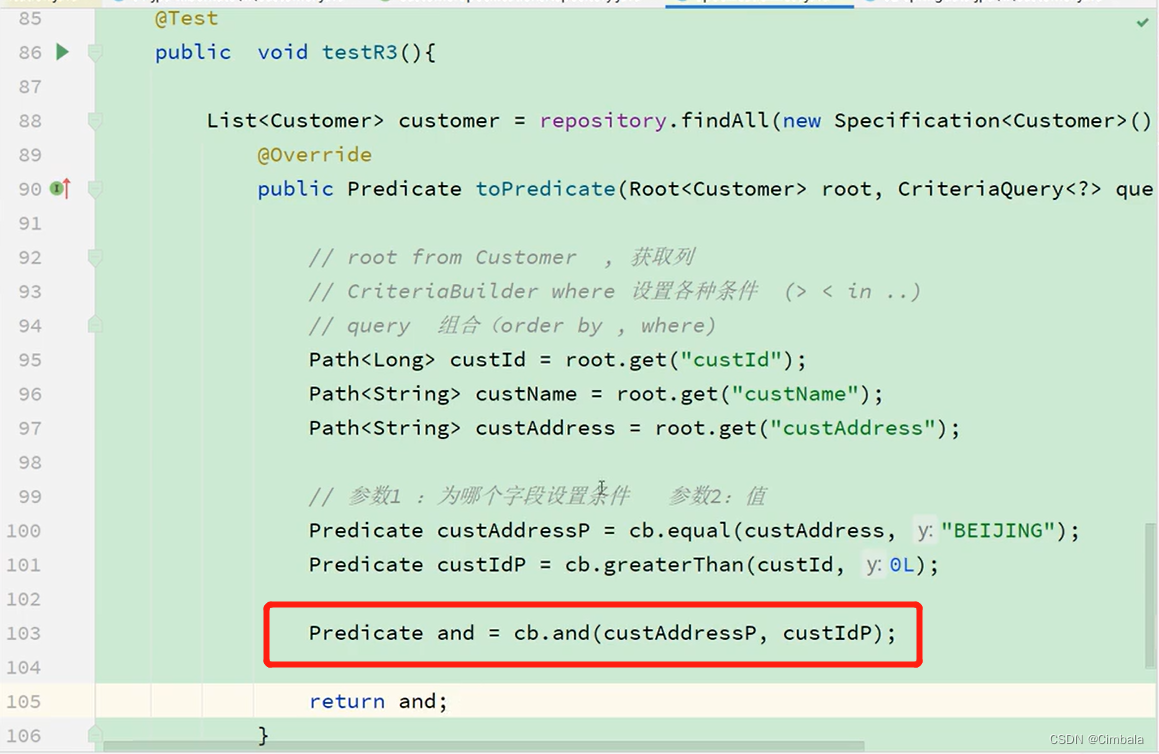
4.Specifications
对所有类型支持。
步骤:
1、通过root拿到需要设置条件的字段
2、通过CriteraBuilder设置不同类型条件
3、组合条件
实现:
//继承JpaSpecificationExecutor接口
public interface CustomerRepository extends CrudRepository<Customer, Long>, JpaSpecificationExecutor<Customer> {…
}
测试:
5.Query DSL
通用查询框架,借助QueryDSL可以在任何支持的ORM框架或SQL平台上以通用API方式构建查询。官网使用说明
实现:
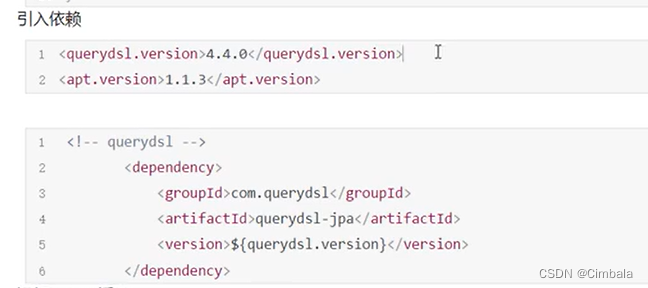
//继承QuerydslPredicateExecutor
interface UserRepository extends CrudRepository<User, Long>, QuerydslPredicateExecutor<User> {
}//官方例子,能直接实体类user.firstname是添加了插件
Predicate predicate = user.firstname.equalsIgnoreCase("dave").and(user.lastname.startsWithIgnoreCase("mathews"));userRepository.findAll(predicate);
使用:


相关文章:
Spring Data JPA
文章目录一、Spring Data基础概念二、JPA与JDBC的相同与不同之处三、Hibernate & JPA快速搭建1.添加依赖2.实体类3.hibernate的配置文件 ——hibernate.cfg.xml四、测试——基于hibernate的持久化(单独使用)五、测试——基于JPA的持久化(…...

java List报错Method threw ‘java.lang.UnsupportedOperationException‘ exception. 解决
问题描述:List使用Arrays.asList()初始化后,再add对象时报错:Method threw java.lang.UnsupportedOperationException exception.错误示例如下: List<ExportListVO.ExportSheet> sheetVOList Arrays.asList(new ExportList…...
数据结构-用栈实现队列
前言: 请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty): 实现 MyQueue 类: void push(int x) 将元素 x 推到队列的末尾 int pop() 从队列的开头移除并返回元素 int…...

第十四章 从 Windows 客户端控制 IRIS
文章目录第十四章 从 Windows 客户端控制 IRISIRISctlGetDirsSyntaxReturn ValuesIRISctlConfigStatusSyntaxReturn ValuesIRISctlControlSyntaxReturn Values第十四章 从 Windows 客户端控制 IRIS IRIS 为 Windows 客户端程序提供了一种机制来控制 IRIS 配置并启动 IRIS 进程…...
数据结构---双链表
专栏:数据结构 个人主页:HaiFan. 专栏简介:从零开始,数据结构!! 双链表前言双链表各接口的实现为要插入的值开辟一块空间BuyLN初始化LNInit和销毁LNDestory打印链表中的值LNPrint尾插LNPushBack和尾删LNPop…...

Windows 环境安装Scala详情
为了进一步学习Spark,必须先学习Scala 编程语言。首先开始Scala 环境搭建。温馨提示:本文是基于Windows 11 安装Scala 2.13.1 版本第一步:确保本机已经正确安装JDK1.8 环境第二步:Scala 官网下载我们所属scala版本文件。Scala 官网…...
C++ Qt自建网页浏览器
C Qt自建网页浏览器如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助!前言这篇博客针对<<C Qt自建网页浏览器>>编写代码,代码整洁,规则,易读。 学习与应用推荐首选。文…...
Flink从入门到精通系列(四)
5、DataStream API(基础篇) Flink 有非常灵活的分层 API 设计,其中的核心层就是 DataStream/DataSet API。由于新版本已经实现了流批一体,DataSet API 将被弃用,官方推荐统一使用 DataStream API 处理流数据和批数据。…...
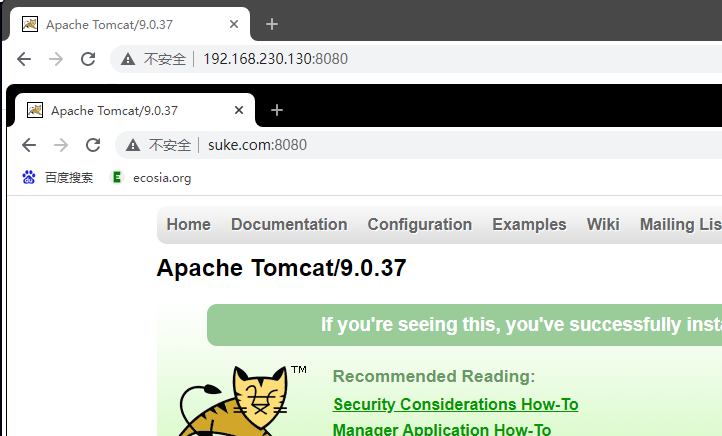
Nginx 配置实例-反向代理案例一
实现效果:使用nginx反向代理,访问 www.suke.com 直接跳转到本机地址127.0.0.1:8080 一、准备工作 Centos7 安装 Nginxhttps://liush.blog.csdn.net/article/details/125027693 1. 启动一个 tomcat Centos7安装JDK1.8https://liush.blog.csdn.net/arti…...

为什么北欧的顶级程序员数量远超中国?
说起北欧,很多人会想到寒冷的冬天,漫长的极夜,童话王国和圣诞老人,但是如果我罗列下诞生于北欧的计算机技术,恐怕你会惊掉下巴。Linux:世界上最流行的开源操作系统,最早的内核由Linus Torvalds开…...
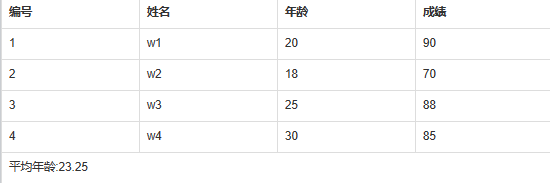
vuex getters的作用和使用(求平均年龄),以及辅助函数mapGetters
getters作用:派生状态数据mapGetters作用:映射getters中的数据使用:方法名自定义,系统自动注入参数:state,每一个方法中必须有return,其return的结果被该方法名所接收。在state中声明数据listst…...
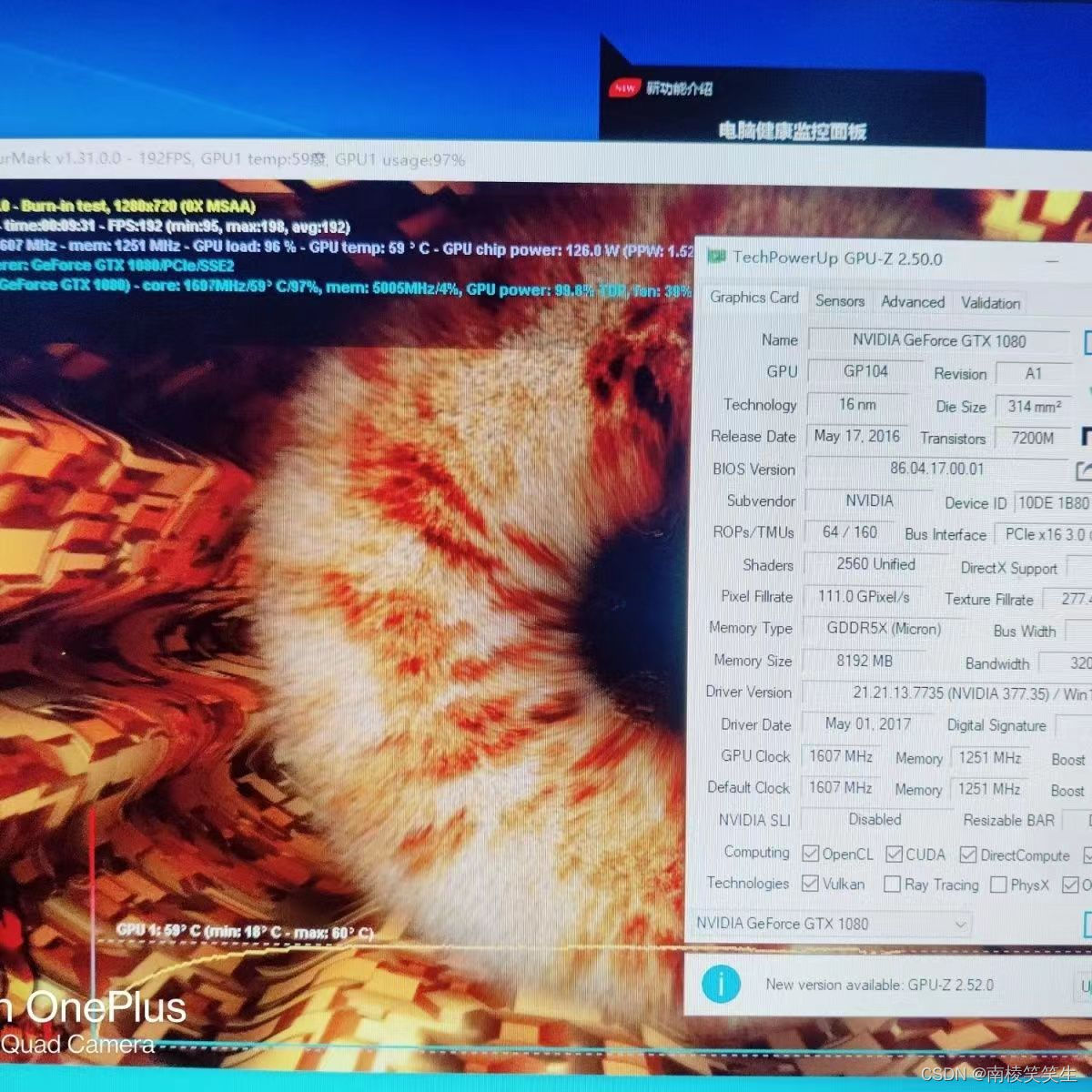
20230311给Ubuntu18.04下的GTX1080M安装驱动
20230311给Ubuntu18.04下的GTX1080M安装驱动 2023/3/11 12:50 2. 安装GTX1080驱动 安装 Nvidia 驱动 367.27 sudo add-apt-repository ppa:graphics-drivers/ppa 第一次运行出现如下的警告: Fresh drivers from upstream, currently shipping Nvidia. ## Curren…...

2023腾讯面试真题:
【腾讯】面试真题: 1、Kafka 是什么?主要应用场景有哪些? Kafka 是一个分布式流式处理平台。这到底是什么意思呢? 流平台具有三个关键功能: 消息队列:发布和订阅消息流,这个功能类似于消息…...
)
23种设计模式-建造者模式(Android应用场景介绍)
什么是建造者模式 建造者模式是一种创建型设计模式,它允许您使用相同的创建过程来生成不同类型和表示的对象。在本文中,我们将深入探讨建造者模式的Java实现,并通过一个例子来解释其工作原理。我们还将探讨如何在Android应用程序中使用建造者…...

English Learning - L2 语音作业打卡 双元音 [ʊə] [eə] Day17 2023.3.9 周四
English Learning - L2 语音作业打卡 双元音 [ʊə] [eə] Day17 2023.3.9 周四💌发音小贴士:💌当日目标音发音规则/技巧:🍭 Part 1【热身练习】🍭 Part2【练习内容】🍭【练习感受】🍓元音 [ʊə…...

【动态规划】多重背包问题,分组背包问题
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 我会一直往里填充内容哒! &…...

JAVA面向对象特征之——封装
4.封装 private关键字 是一个权限修饰符 可以修饰成员(成员变量和成员方法) 作用是保护成员不被别的类使用,被private修饰的成员只在本类中才能访问 针对private修饰的成员变量,如果需要被其他类使用,提供相应的操作 提供 “get变量名()…...

【数据结构】二叉树相关OJ题
文章目录一、单值二叉树二、检查两颗树是否相同三、判断一棵树是否为另一颗树的子树四、对称二叉树五、二叉树的前序遍历六、二叉树中序遍历七、二叉树的后序遍历八、二叉树的构建及遍历一、单值二叉树 单值二叉树 题目描述 如果二叉树每个节点都具有相同的值,那…...
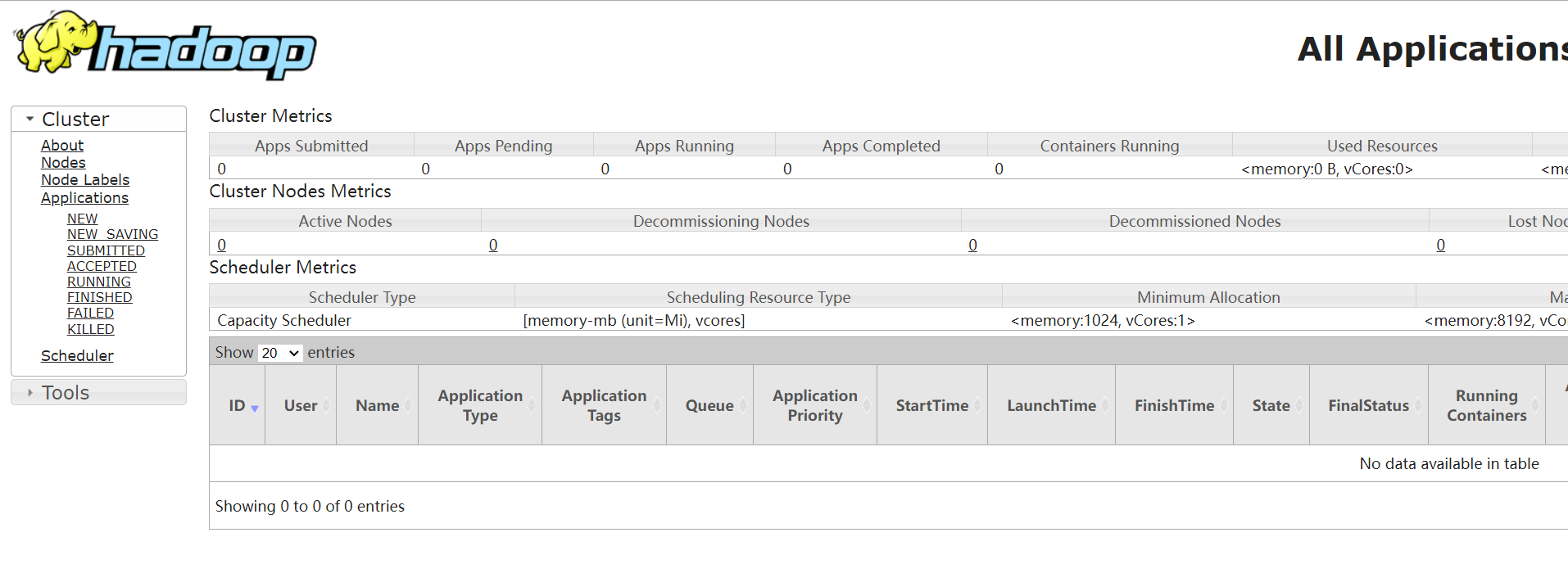
Windows安装Hadoop
当初搭建Hadoop、Hive、HBase、Flink等这些没有截图写文,今为分享特重装。下载Hadoop下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/以管理员身份运行cmd切换到所在目录执行start winrar x -y hadoop-3.3.4.tar.gz,解压。配置…...
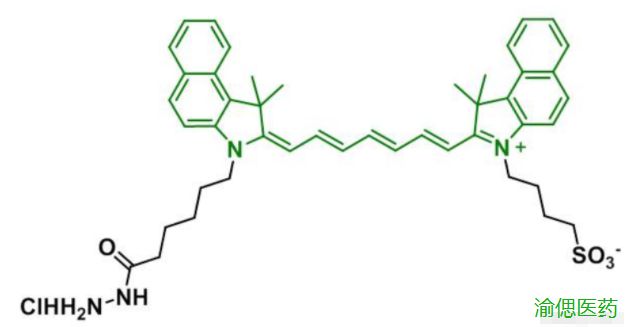
ICG-Hydrazide,吲哚菁绿-酰肼,ICG-HZ结构式,溶于二氯甲烷等部分有机溶剂,
ICG-Hydrazide,吲哚菁绿-酰肼 中文名称:吲哚菁绿-酰肼 英文名称:ICG-Hydrazide 英文别名:ICG-HZ 性状:粉末或固体 溶剂:溶于二氯甲烷等部分有机溶剂 稳定性:-20℃密封保存、置阴凉干燥处、防潮 分子…...
)
第六届机械制造与智能控制国际学术会议(ICMMIC 2026)
第六届机械制造与智能控制国际学术会议(ICMMIC 2026)将于2026年6月12-14日在中国浙江湖州隆重举行。本次会议旨在汇聚全球“机械制造、智能控制”领域的学者、专家、研发者和技术人员,共同探讨学术前沿,分享科研成果,促…...
:风险计算、工具应用)
信息安全工程师-网络安全风险评估(下篇):风险计算、工具应用
一、引言风险评估是软考信息安全工程师考试中风险管理模块的核心考点,分值占比约 8%-12%,涵盖客观题、案例分析题两类题型。从技术定位来看,风险评估是连接安全需求与安全建设的核心枢纽,其输出结果直接作为安全策略制定、安全措施…...

ComfyUI-Impact-Pack终极指南:快速掌握AI图像增强的完整教程
ComfyUI-Impact-Pack终极指南:快速掌握AI图像增强的完整教程 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址: ht…...

基于确定性脚本与LLM决策的AI多智能体自动化监控系统设计与实践
1. 项目概述:一个为AI多智能体协作而生的“自动化监工”如果你正在用OpenClaw这类框架玩多AI智能体协作,大概率会遇到一个头疼的问题:怎么知道这群“数字员工”到底在不在干活?谁在摸鱼?任务到底完成了没有?…...

开源自托管看板工具:基于Preact+Hono+SQLite的零云依赖方案
1. 项目概述:一个为自托管与AI协作而生的看板应用如果你正在寻找一个可以完全掌控在自己手里、没有订阅费用、又能无缝集成到你自己产品中的看板工具,那么clawnify/open-kanban这个项目值得你花时间深入研究。它不是一个玩具,而是一个生产就绪…...

从SPI模式0到Quad I/O:手把手带你玩转W25Q128JV的性能压榨与接口升级
从SPI模式0到Quad I/O:W25Q128JV性能优化实战指南 在嵌入式系统设计中,存储器的性能往往成为整个系统响应速度的瓶颈。W25Q128JV这颗128Mbit容量的串行Flash芯片,凭借其灵活的接口配置和出色的性价比,已成为众多物联网设备、消费电…...

3大核心功能,让你的惠普OMEN游戏本性能彻底解放
3大核心功能,让你的惠普OMEN游戏本性能彻底解放 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为惠普OMEN游戏本官方软件过于臃肿而烦恼吗…...

构建个人技能库:从代码片段到可复用技能单元的设计与实践
1. 项目概述:当代码遇上魔法,技能库的构建哲学在软件开发的日常里,我们常常会羡慕那些“魔法师”般的同事:他们似乎总能信手拈来一段代码,优雅地解决一个棘手问题;或者拥有一个私人的“百宝箱”,…...

【实战篇】Nginx反向代理负载均衡:从轮询到权重的策略演进
1. 反向代理与负载均衡基础认知 第一次接触Nginx的反向代理功能时,我盯着配置文件里的proxy_pass参数看了半天。这行看似简单的配置,背后其实隐藏着现代分布式系统的核心设计思想。想象一下这样的场景:当你在电商网站点击"立即购买"…...

一站式解决Windows程序运行问题的Visual C++运行库修复指南
一站式解决Windows程序运行问题的Visual C运行库修复指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过打开软件时突然弹窗提示"缺少msv…...