【论文笔记】LoRA LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
题目:LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
来源: ICLR 2022
模型名称: LoRA
论文链接: https://arxiv.org/abs/2106.09685
项目链接: https://github.com/microsoft/LoRA
文章目录
- 摘要
- 引言
- 问题定义
- 现有方法的问题
- 方法
- 将 LORA 应用于 Transformer
- 实验
- 思考
- 结论
- future work
摘要
随着模型越来越大,全量微调变得越来越不可行。作者提出了低秩适配器(LoRA),它冻结了预训练的模型权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层中,大大减少了下游任务的可训练参数的数量。在GPT-3 175B使用Adam上,与全量微调相比,LoRA减少了10,000倍参数量,减少了3倍GPU内存消耗。
🧐与Adapter相比,没有额外的推理延迟
引言
由于全量微调大模型比较不现实,因此除了每个任务的预训练模型之外,只需要存储和加载少量特定于任务的参数,大大提高了部署时的运行效率。
已有的方法引进了推理延迟,要么增加了模型的深度,要么减少了模型可以输入的序列长度,更重要的是,这些方法通常无法匹配微调基线,从而在效率和模型质量之间进行权衡。【adpter增加了深度,pormpt、prefix-tuning减少了模型可以接受的输入序列长度】
🧐We take inspiration from Li et al. (2018a); Aghajanyan et al. (2020) which show that the learned over-parametrized models in fact reside on a low intrinsic dimension. We hypothesize that the change in weights during model adaptation also has a low “intrinsic rank”, leading to our proposed Low-Rank Adaptation (LoRA) approach.
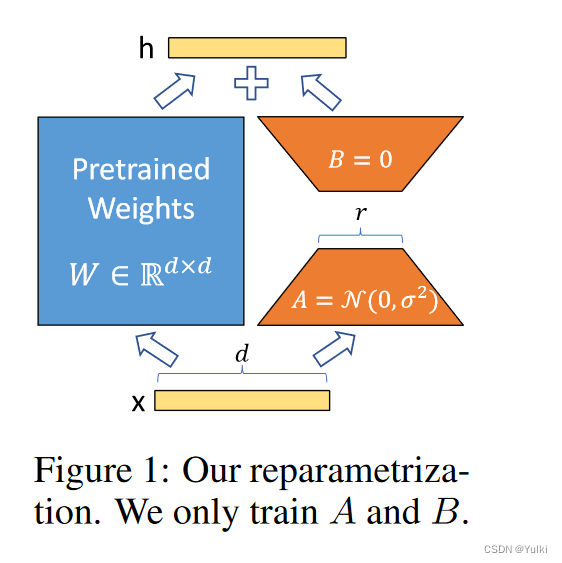
r = 1 or 2 d可以等于12,288
LoRA几个优势:
- 【基础模型不动,只修改A或者B】预训练模型可以共享并用于构建许多用于不同任务的小型 LoRA 模块。我们可以通过替换图1中的矩阵A和B来冻结共享模型并有效地切换任务,从而显着降低存储需求和任务切换开销。
- 【训练更高效】LoRA 使训练更加高效,并将硬件进入门槛降低了多达 3 倍,因为我们不需要计算梯度或维护大多数参数的优化器状态。相反,我们只优化注入的、小得多的低秩矩阵。
- 【推理更加高效】我们简单的线性设计使我们能够在部署时将可训练矩阵与冻结权重合并,通过构造,与完全微调的模型相比,不会引入推理延迟。
- 【可以与别的方法一起使用】LoRA 与许多现有方法正交,并且可以与其中许多方法相结合,例如前缀调整。
问题定义
下面是对语言建模问题的简要描述,特别是在给定特定任务提示的情况下条件概率的最大化。
预训练好的模型: P Φ ( y ∣ x ) P_Φ(y|x) PΦ(y∣x)
下游数据集: Z = { ( x i , y i ) } i = 1 , … , N \mathcal{Z}=\{(x_i,y_i)\}_{i=1,\ldots,N} Z={(xi,yi)}i=1,…,N
全量微调中优化目标: max Φ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ log ( P Φ ( y t ∣ x , y < t ) ) \max\limits_{\Phi}\sum_{(x,y)\in\mathcal{Z}}\sum_{t=1}^{|y|}\log\left(P_{\Phi}(y_t|x,y_{<t})\right) Φmax∑(x,y)∈Z∑t=1∣y∣log(PΦ(yt∣x,y<t))
LoRA优化目标: max Θ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ log ( p Φ 0 + Δ Φ ( Θ ) ( y t ∣ x , y < t ) ) \max\limits_{\Theta}\sum_{(x,y)\in\mathcal{Z}}\sum\limits_{t=1}^{|y|}\log\left(p_{\Phi_0+\Delta\Phi(\Theta)}(y_t|x,y_{<t})\right) Θmax∑(x,y)∈Zt=1∑∣y∣log(pΦ0+ΔΦ(Θ)(yt∣x,y<t))
当预训练模型为GPT-3 175B时,可训练参数个数| θ ∣ θ| θ∣可小至 ∣ Φ 0 ∣ |Φ_0| ∣Φ0∣ 的 0.01%。
现有方法的问题
增加adapter层,对现有的输入层的结构进行调整
**adapter层引入推理延迟。**虽然可以通过修剪层或利用多任务设置来减少总体延迟(,但没有直接的方法可以绕过适配器层中的额外计算。这似乎不是问题,因为适配器层被设计为具有很少的参数(有时<原始模型的 1%),并且具有小的瓶颈尺寸,这限制了它们可以添加的 FLOPs。然而,大型神经网络依赖硬件并行性来保持低延迟,并且适配器层必须按顺序处理。这对在线推理设置产生了影响,其中批量大小通常小至 1。
直接优化Prompt很难。 我们观察到prefix tuning很难优化,并且其性能在可训练参数中非单调变化,证实了原始论文中的类似观察结果。更重要的是,缩短了可以训练的长度。

方法
动机:矩阵大部分都是满秩的,当适应特定任务时,预训练的语言模型具有较低的“内在维度”,尽管随机投影到较小的子空间,但仍然可以有效地学习。
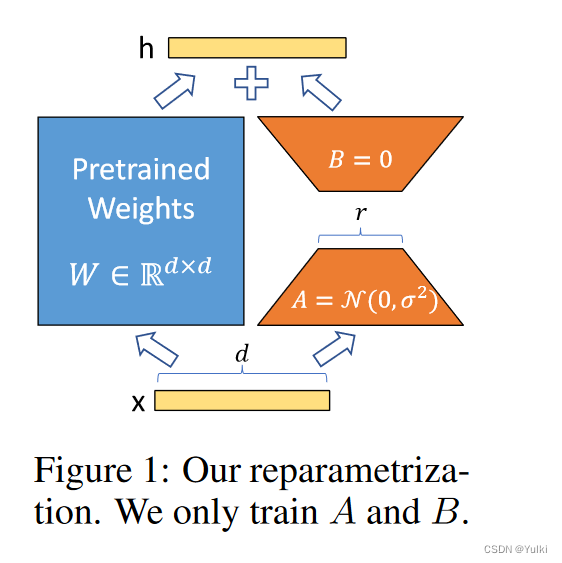
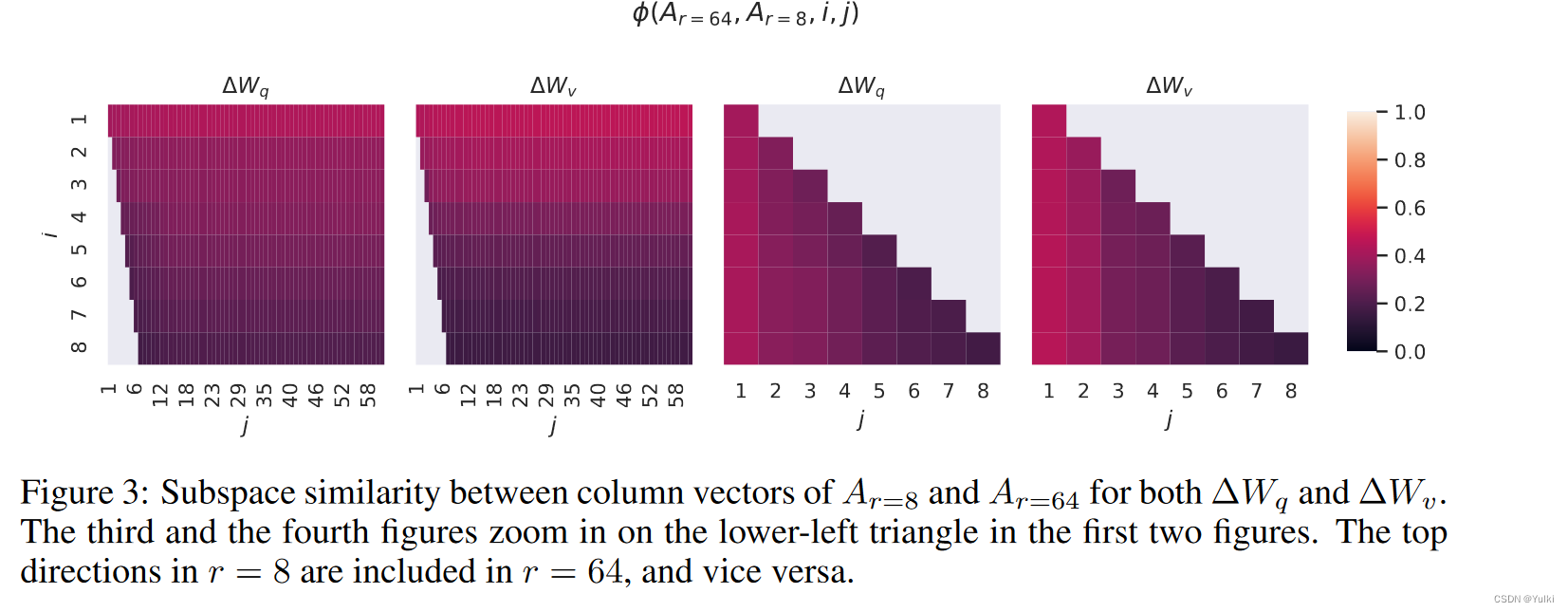
【重要的图不能只看一遍】
前向传播
h = W 0 x + Δ W x = W 0 x + B A x h=W_0x+\Delta Wx=W_0x+BAx h=W0x+ΔWx=W0x+BAx
B ∈ R d × r B\in\mathbb{R}^{d\times r} B∈Rd×r , A ∈ R r × k A\in\mathbb{R}^{r\times k} A∈Rr×k, r < < m i n ( d , k ) r<<min(d,k) r<<min(d,k),在进行微调的时候 W 0 W_0 W0冻结,仅训练 Δ W ΔW ΔW
全量微调的推广
我们通过将LoRA等级r设置为预训练权重矩阵的等级来粗略地恢复完全微调的表现力。
无额外推理延迟
对于不同的任务,只是需要不同的BA罢了。 W = W 0 + B A W = W_0 + BA W=W0+BA
将 LORA 应用于 Transformer
这里只是考虑了将LoRA方法应用到Transformer中的注意力权重计算上,没有应用到其他层。
We leave the empirical investigation of adapting the MLP layers, LayerNorm layers, and biases to a future work.
对于GPT-3 175B来哦说,VRAM从1.2TB减少到350GB,r=4的时候,checkpoint的大小从350GB减小到35MB
LoRA 也有其局限性。例如,如果选择将 A 和 B 吸收到 W 中以消除额外的推理延迟,**那么在一次前向传递中将不同 A 和 B 的不同任务的输入批量输入并不简单。**尽管在延迟不重要的情况下,可以不合并权重并动态选择用于批量样本的 LoRA 模块。
实验
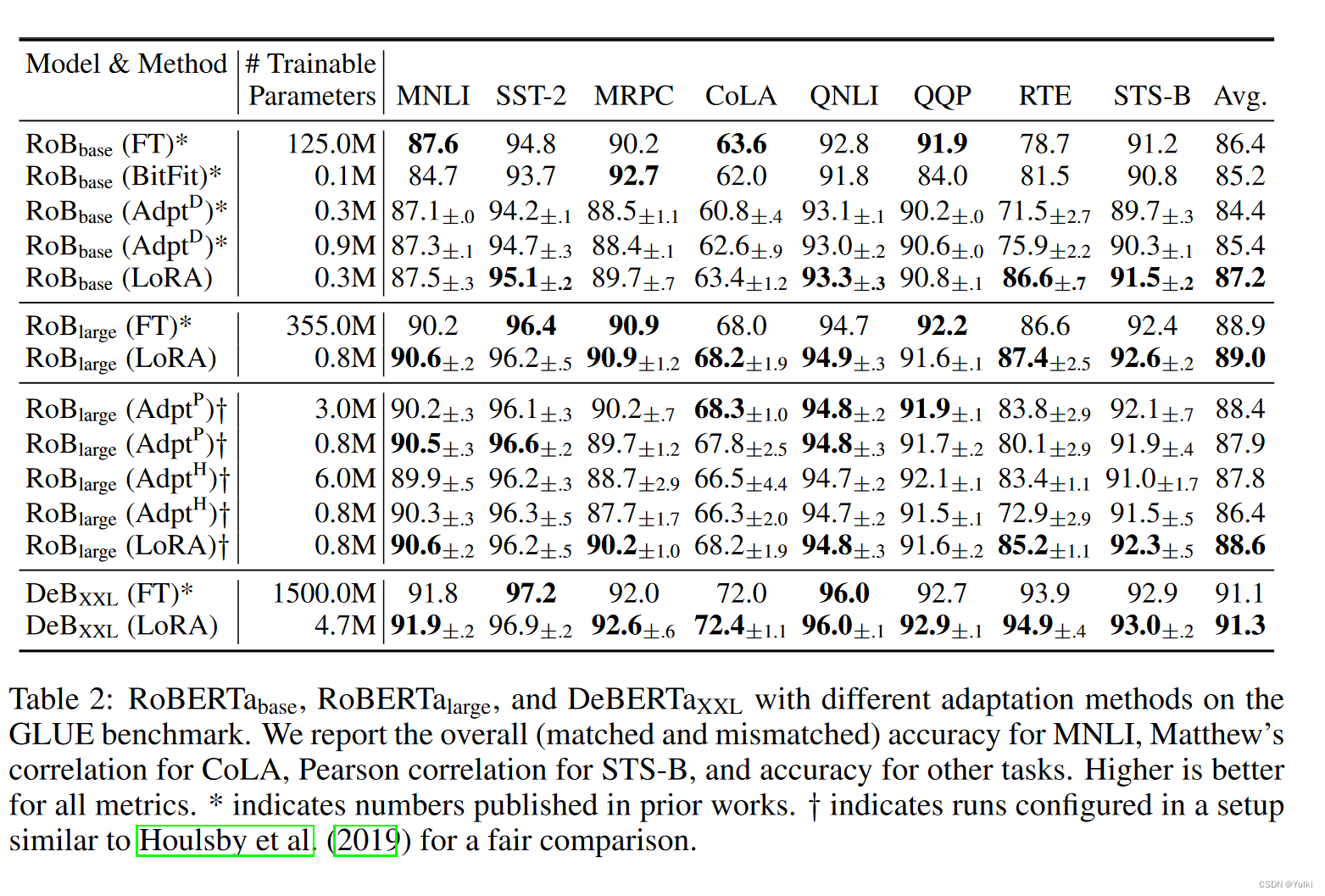
AdapterH:有两个完全连接的层,其中适配器层存在偏差,中间存在非线性。
AdapterL:仅在 MLP 模块和 LayerNorm 之后
LoRA:为了简化实验,只在Wq和Wv上面进行了应用, ∣ Θ ∣ = 2 × L L o R A × d m o d e l × r |Θ| = 2 × L_{LoRA} × d_model × r ∣Θ∣=2×LLoRA×dmodel×r

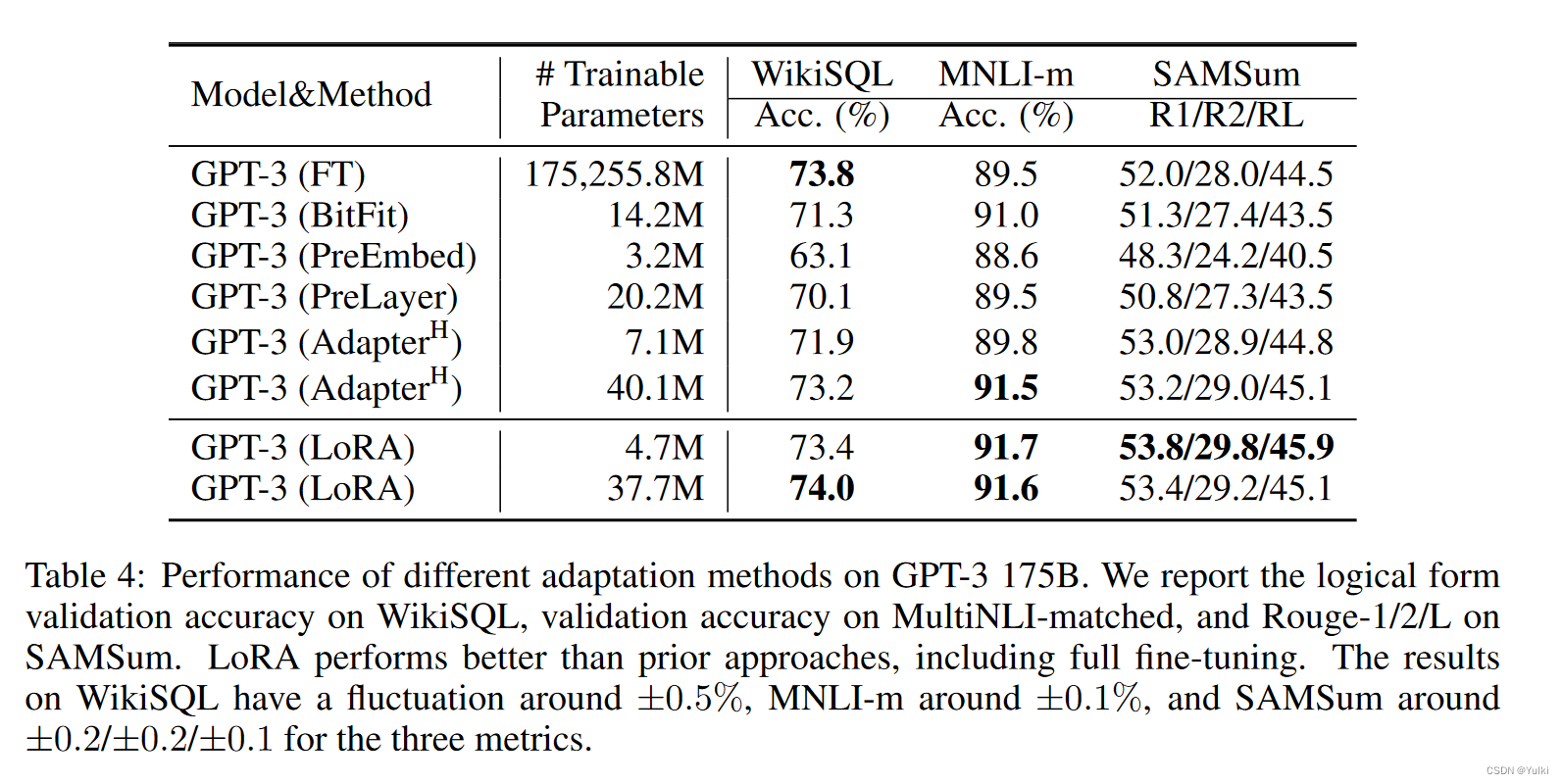

思考
请注意,低秩结构不仅降低了硬件进入门槛,使我们能够并行运行多个实验,而且还可以更好地解释更新权重与预训练权重的相关性
需要思考一下几个问题:
- 给定参数预算约束,我们应该调整预训练 Transformer 中的哪个权重矩阵子集来最大化下游性能?
- “最优”适应矩阵 ΔW 真的是非满秩的吗?如果是这样,在实践中使用多大的r比较好?
- ΔW 和 W 之间有什么关系? ΔW 与 W 高度相关吗? ΔW 与 W 相比有多大
作者认为对问题(2)和(3)的回答揭示了使用预训练语言模型进行下游任务的基本原则,这是 NLP 的一个关键主题。


后面的实验就没怎么关注,也没看懂


结论
一种有效的适应策略,既不会引入推理延迟,也不会减少输入序列长度,同时保持高模型质量。重要的是,当它部署为服务时,通过共享绝大多数模型参数,可以实现快速任务切换。虽然我们专注于 Transformer 语言模型,但所提出的原理通常适用于任何具有密集层的神经网络。
future work
- Similarly, combining LoRA with other tensor product-based methods could potentially improve its parameter efficiency, which we leave to future work.
- LoRA 可以与其他有效的适应方法相结合,有可能提供正交改进
- 微调或 LoRA 背后的机制尚不清楚——如何将预训练过程中学到的特征转化为在下游任务上表现出色?我们相信 LoRA 比完全微调更容易回答这个问题。
- 我们主要依靠启发式方法来选择应用 LoRA 的权重矩阵。有没有更有原则性的方法来做?
- Finally, the rank-deficiency of ∆W suggests that W could be rank-deficient as well, which can also be a source of inspiration for future works.
相关文章:
【论文笔记】LoRA LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
题目:LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS 来源: ICLR 2022 模型名称: LoRA 论文链接: https://arxiv.org/abs/2106.09685 项目链接: https://github.com/microsoft/LoRA 文章目录 摘要引言问题定义现有方法的问题方法将 LORA 应用于 Transformer 实…...

【Sa-Token|4】Sa-Token微服务项目应用
若微服务数量多,如果每个服务都改动,工作量大,则可以只在网关和用户中心进行改动,也是可以实现服务之间的跳转。 这种方式可以通过在网关服务中生成和验证 Sa-Token,并将其与现有的 Token关联存储在 Redis 中。用户中心…...
】)
鸿蒙开发系统基础能力:【@ohos.hilog (日志打印)】
日志打印 hilog日志系统,使应用/服务可以按照指定级别、标识和格式字符串输出日志内容,帮助开发者了解应用/服务的运行状态,更好地调试程序。 说明: 本模块首批接口从API version 7开始支持。后续版本的新增接口,采用…...

SpringMVC系列十: 中文乱码处理与JSON处理
文章目录 中文乱码处理自定义中文乱码过滤器Spring提供的过滤器处理中文 处理json和HttpMessageConverter<T>处理JSON-ResponseBody处理JSON-RequestBody处理JSON-注意事项和细节HttpMessageConverter<T\>文件下载-ResponseEntity<T\>作业布置 上一讲, 我们学…...
使用MyBatisPlus进行字段的自动填充
使用MyBatisPlus进行字段的自动填充 需求场景 当我们往数据库里面插入一条数据,或者是更新一条数据时,一般都需要标记创建时间create_time和更新时间update_time的值,但是如果我们每张表的每个请求,在执行sql语句的时候我们都手…...

python爬虫之aiohttp多任务异步爬虫
python爬虫之aiohttp多任务异步爬虫 爬取的flash服务如下: from flask import Flask import timeapp Flask(__name__)app.route(/bobo) def index_bobo():time.sleep(2)return Hello boboapp.route(/jay) def index_jay():time.sleep(2)return Hello jayapp.rout…...

1964springboot VUE小程序在线学习管理系统开发mysql数据库uniapp开发java编程计算机网页源码maven项目
一、源码特点 springboot VUE uniapp 小程序 在线学习管理系统是一套完善的完整信息管理类型系统,结合springboot框架uniapp和VUE完成本系统,对理解vue java编程开发语言有帮助系统采用springboot框架(MVC模式开发),…...

【前端项目笔记】3 用户管理
用户管理相关功能实现 涉及表单、对话框、Ajax数据请求 基本页面 用户列表开发 在router.js中导入Users.vue 解决用户列表小问题 选中(激活)子菜单后刷新不显示高亮 给二级菜单绑定单击事件,点击链接时把对应的地址保存到sessionSto…...
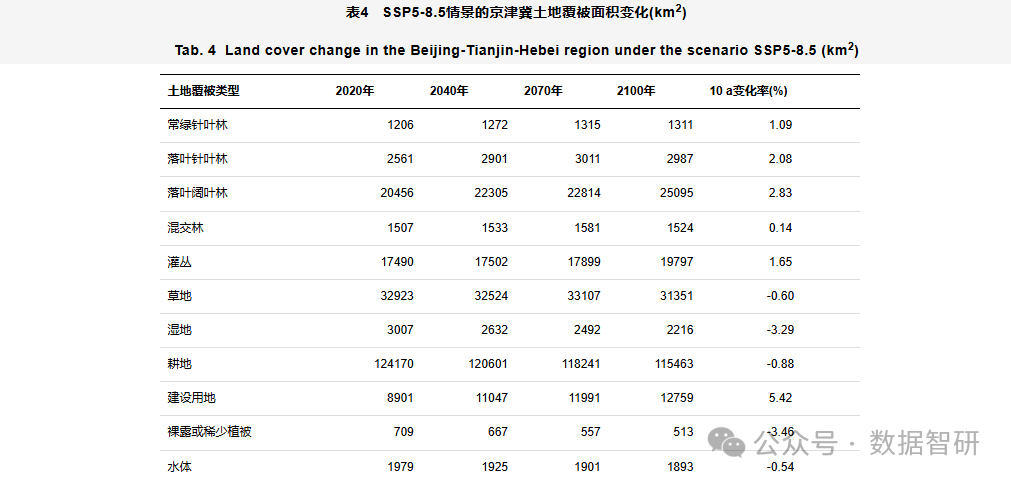
【文献及模型、制图分享】基于SSP-RCP不同情景的京津冀地区土地覆被变化模拟
公众号新功能 目前公众号新增以下等功能 1、处理GIS出图、Python制图、区位图、土地利用现状图、土地利用动态度和重心迁移图等等 2、核密度分析、网络od分析、地形分析、空间分析等等 3、地理加权回归、地理探测器、生态环境质量指数、地理加权回归模型影响因素分析、计算…...
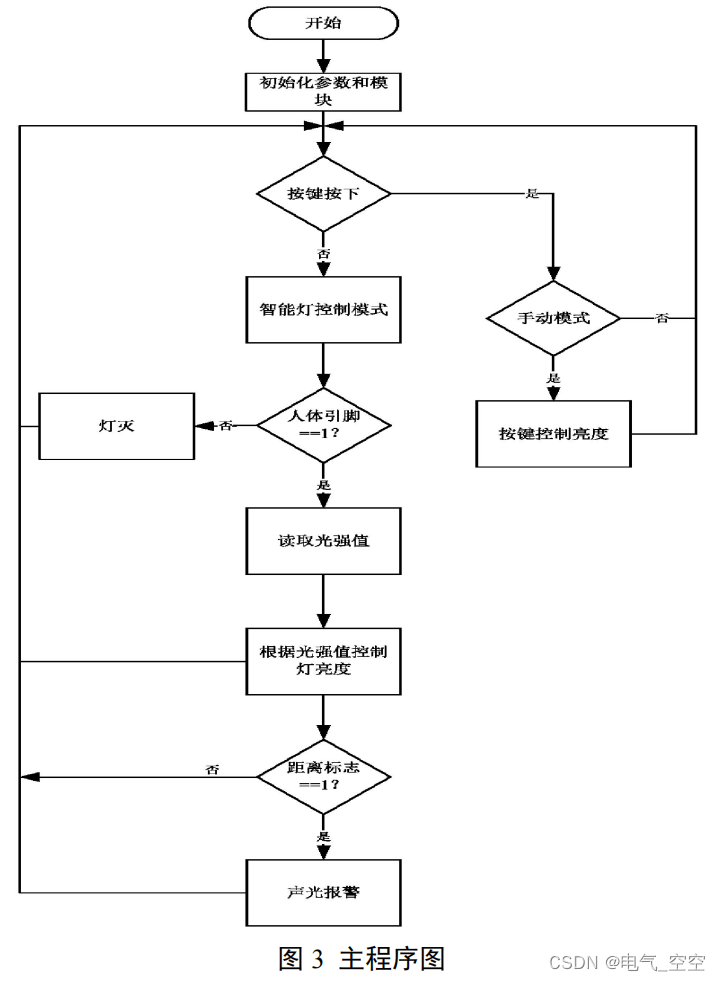
基于单片机的智能台灯控制系统
摘要: 文章设计一款单片机智能台灯控制系统,实现对台灯的手动和自动控制功能,以 STC89C52 单片机作为多功能智能台灯的主控制器,光电检测模块检测坐姿,红外传感器检测人体,光敏电阻检测光强,同…...

PrestaShop的一些使用介绍
目录 PrestaShop 是一个功能丰富的开源电子商务解决方案。 1. 以下是其基本概念和架构的一些要点: 2. PrestaShop 的模块开发是扩展其功能的重要方式。以下是对 PrestaShop 模块开发的详细介绍: 开发环境准备: 3. PrestaShop 的模块开发允…...

零基础女生如何入门人工智能,从哪里下手?学习时间大概要多久?
作为一个理工科早期毕业生,出于近乎本能的敏感,格外关注全网热议的ChatGPT。 本来国内就业环境就不好,各行各业内卷越来越严重,加上人工智能的异军突起,各行各业势必将迎来科技进步跨时代的巨大冲击,在此情…...

简答分享python学习进修网站
一、网战推荐 CodeCombat 是一款网页编程游戏。这款编程游戏借鉴了游戏很多设计元素,游戏剧情十分丰富。Codecombat能够学习Python多种语言,这些语言能够运用到游戏设计、网页应用、app的开发上。 Checkio 是一个基于浏览器的游戏,你需要使…...
)
linux高级编程(I/O)
fputc int fputc(int c, FILE *stream); 功能: 向流中写入一个字符 参数: c:要写入的字符 stream:文件流指针 返回值: 成功返回写入的字符ASCII码值 失败返回EOF fgetc int fgetc(FILE *stream); 功能: 从流中读取一个字符 参数: stream:文件流…...

Java面试——认证与授权
X、常见面试题汇总 1、Shiro与SpringSecutity对比 1)Shiro的特点: Shiro 是 Apache 下的项目,相对简单、轻巧,更容易上手使用。 Shiro 权限功能基本都能满足,单点登录都可以实现。且不用与任何的框架或者容器绑定, 可…...
【经典算法OJ题讲解】
1.移除元素 经典算法OJ题1: 移除元素 . - 力扣(LeetCode). - 备战技术面试?力扣提供海量技术面试资源,帮助你高效提升编程技能,轻松拿下世界 IT 名企 Dream Offer。https://leetcode.cn/problems/remove-element/desc…...

大数据面试题之Zookeeper面试题
目录 1、介绍下Zookeeper是什么? 2、Zookeeper有什么作用?优缺点?有什么应用场景? 3、Zookeeper的选举策略,leader和follower的区别? 4、介绍下Zookeeper选举算法 5、Zookeeper的节点类型有哪些?分别作用是什么? 6、Zookeeper的节点数怎么设置比较好? …...
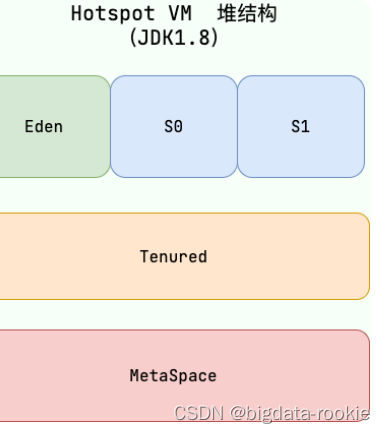
JVM 内存区域
一、运行时数据区域 Java 虚拟机在执行 Java 程序的过程中,会把它管理的内存划分成若干个不同的数据区域。 JDK 1.8 和之前的版本略有不同,这里介绍 JDK 1.7 和 JDK 1.8 两个版本。 JDK 1.7: 线程私有: 程序计数器虚拟机栈本地…...

全网最强剖析Spring AOP底层原理
相信各位读者对于Spring AOP的理解都是一知半解,只懂使用,却不懂原理。网上关于Spring AOP的讲解层出不穷,但是易于理解,让人真正掌握原理的文章屈指可数。笔者针对这一痛点需求,决定写一篇关于Spring AOP原理的优质博…...

Vscode中的行尾序列CRLF/LF不兼容问题
最近开发的的时候,打开项目文件经常会出现爆红错误提示信息,显示如下图: 这东西太烦人了,毕竟谁都不希望在遍地都是爆红的代码里写东西,就像能解决这个问题,根据提示可以知道这是vscode中使用的prettier插件…...

GraphGym高级特性:动态图学习与多任务图神经网络
GraphGym高级特性:动态图学习与多任务图神经网络 【免费下载链接】GraphGym Platform for designing and evaluating Graph Neural Networks (GNN) 项目地址: https://gitcode.com/gh_mirrors/gr/GraphGym GraphGym是一个强大的图神经网络(GNN&am…...

阿里健康年营收342亿:净利19亿 CFO屠燕武辞职
雷递网 雷建平 5月14日阿里健康(股份代号:00241)今日发布截至2026年3月31日的财报。财报显示,截至2026年3月31日的年度,阿里健康营收为342.55亿元,较上年同期的306亿元增长12%。截至2026年3月31日的年度&am…...

我的世界《农场物语》整合包下载2026最新版下载分享
一、整合包基础信息我的世界农场物语 1.4.1 整合包,是依托《我的世界》1.20.1 版本打造的精品模组整合包,采用 Forge 框架运行,内置 310 个精心筛选与适配的模组,以星露谷物语为核心创作灵感,深度融合农场经营与方块生…...

汽车电子功能安全:锁步核与ECC技术解析
1. 功能安全与汽车电子:为什么它如此重要?在现代汽车电子系统中,功能安全已经从"锦上添花"变成了"不可或缺"。想象一下,当你的车辆以120km/h在高速公路上行驶时,电子稳定控制系统(ESC)突然因为一个…...

基于MCP协议的AI智能体安全扫描器:架构、部署与实战指南
1. 项目概述:一个为AI智能体设计的“安全门卫”最近在折腾AI智能体(Agent)的落地应用,发现一个挺普遍但容易被忽视的问题:当你的智能体开始联网、调用工具、处理外部数据时,它接收到的信息就像从四面八方涌…...

ChatGPT对话转Anki卡片:自动化工具实现与高效学习流搭建
1. 项目概述:从ChatGPT对话到Anki卡片的自动化桥梁最近在整理学习笔记时,我发现了一个效率痛点:和ChatGPT的对话里充满了高质量的知识点,但要把它们变成可以复习的Anki卡片,过程却异常繁琐。复制、粘贴、手动制卡&…...

Softether实战:用它把家里旧电脑变成公司远程访问网关,支持Win/Mac/iOS/Android全平台
利用SoftEther实现跨平台远程办公网关搭建指南 引言 在数字化办公日益普及的今天,远程访问企业内部资源已成为许多企业的刚需。传统商业解决方案往往价格昂贵且配置复杂,而基于SoftEther的开源方案则提供了一种高性价比的替代选择。本文将详细介绍如何利…...

yargs配置加密:敏感信息处理与解密中间件终极指南
yargs配置加密:敏感信息处理与解密中间件终极指南 【免费下载链接】yargs yargs the modern, pirate-themed successor to optimist. 项目地址: https://gitcode.com/gh_mirrors/ya/yargs yargs作为现代命令行参数解析工具,在处理配置文件时经常…...

Memo性能优化秘籍:提升Flutter应用响应速度的10个技巧
Memo性能优化秘籍:提升Flutter应用响应速度的10个技巧 【免费下载链接】memo Memo is an open-source, programming-oriented spaced repetition software (SRS) written in Flutter. 项目地址: https://gitcode.com/gh_mirrors/me/memo Memo是一款基于Flutt…...
)
NotebookLM多语言支持到底行不行?基于2000+跨语言笔记片段的BLEU-4与BERTScore双维度评测(含原始数据集下载链接)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM多语言支持到底行不行?基于2000跨语言笔记片段的BLEU-4与BERTScore双维度评测(含原始数据集下载链接) NotebookLM 官方宣称支持“30语言”,但其…...