大数据面试题之Zookeeper面试题
目录
1、介绍下Zookeeper是什么?
2、Zookeeper有什么作用?优缺点?有什么应用场景?
3、Zookeeper的选举策略,leader和follower的区别?
4、介绍下Zookeeper选举算法
5、Zookeeper的节点类型有哪些?分别作用是什么?
6、Zookeeper的节点数怎么设置比较好?
7、Zookeeper架构
8、Zookeeper的功能有哪些
9、Zookeeper的数据结构(树)?基于它实现的分布式锁?基于它实现的Master选举?基于它的集群管理? Zookeeper的注册(watch)机制使用场景?
10、介绍下Zookeeper消息的发布订阅功能
11、Zookeeper的分布式锁实现方式?
12、Zookeeper怎么保证一致性的
13、Zookeeper的zab协议(原子广播协议)?
14、ZAB是以什么算法为基础的?ZAB流程?
15、Zookeeper的通知机制
16、Zookeeper脑裂问题
17、Zookeeper的Paxos算法
18、Zookeeper的协议有哪些?
19、Zookeeper如何保证数据的一致性?
20、Zookeeper的数据存储在什么地方?
21、Zookeeper从三台扩容到七台怎么做?
1、介绍下Zookeeper是什么?
ZooKeeper是一个分布式的、开放源码的分布式应用程序协调服务,它是Google的Chubby的一个开源实现,也是Hadoop和HBase等分布式系统的重要组件。以下是关于ZooKeeper的详细介绍:基本概念与定义:
ZooKeeper是一个为分布式应用提供一致性服务的软件,主要解决分布式系统中的一致性问题。
它封装了复杂易出错的关键服务,为用户提供简单易用的接口和性能高效、功能稳定的系统。
主要功能:
配置维护:ZooKeeper可以用来存储和管理分布式系统的配置信息,实现动态配置的更新和管理。
域名服务:提供命名服务,使客户端能够在分布式环境中找到特定的资源或服务。
分布式同步:通过提供分布式锁等机制,帮助多个进程或节点协调访问共享资源,避免竞争条件。
组服务:支持分布式系统中的组管理,如组成员的加入、离开等。
工作原理:
ZooKeeper基于Fast Paxos算法实现,通过选举产生一个leader(领导者),只有leader才能提交proposer。
基本运转流程包括选举Leader、同步数据等步骤,确保集群中数据的一致性。
特性:
全局数据一致性:每个服务器都保存一份相同的数据副本,客户端无论连接到集群的任意节点上,看到的目录树都是一致的。
可靠性:如果消息被其中一台服务器接收,那么将被所有的服务器接收。
顺序性:ZooKeeper保证全局有序和偏序,确保消息发布的顺序性。
数据更新原子性:一次数据更新要么成功(半数以上节点成功),要么失败,不存在中间状态。
实时性:ZooKeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息或服务器失效的信息。
应用场景:
分布式协调:作为可靠的“协调者”,帮助分布式系统中的各个节点进行信息共享和同步,确保数据一致性。
领导者选举:支持领导者选举算法,用于在分布式系统中选举出一个节点作为“领导者”,确保系统的高可用性。
配置管理:用于存储和管理分布式系统的配置信息。
命名服务:提供命名服务,使客户端能够在分布式环境中找到特定的资源或服务。
分布式锁:提供分布式锁机制,帮助多个进程或节点协调访问共享资源。
接口与语言支持:
ZooKeeper包含一个简单的原语集,提供Java和C的接口。其中,分布锁和队列有Java和C两个版本,选举只有Java版本。
综上:ZooKeeper是一个功能强大的分布式应用程序协调服务,通过提供一系列核心功能和特性,帮助开发人员解决分布式系统中的一致性、可用性和并发控制等问题。2、Zookeeper有什么作用?优缺点?有什么应用场景?
ZooKeeper是一个分布式的、开放源码的分布式应用程序协调服务,它在分布式系统中发挥着至关重要的作用。以下是关于ZooKeeper的详细介绍:ZooKeeper的作用
提供一致性服务:ZooKeeper为分布式应用提供了一致性服务,确保在分布式系统中各个节点之间的数据保持一致性。
管理元数据和状态信息:ZooKeeper存储和管理分布式系统中至关重要的元数据和状态信息,如配置参数、节点状态、节点分组和负载平衡信息等。
协调分布式系统:ZooKeeper负责协调分布式系统中多个节点之间的通信和数据管理,确保它们保持一致和可用。
保障可用性:ZooKeeper采用主从复制架构,在主节点故障的情况下,系统会自动选举一个新的主节点,保证服务的持续可用性。
简化开发:ZooKeeper提供了一个简单的API,使开发人员能够轻松地编写分布式应用程序,而无需考虑底层的复杂性。
ZooKeeper的优点
高可用性:ZooKeeper以集群方式部署,采用Leader-Follower模式,能够实现自动的Leader选举,保证服务的高可用性。
一致性:ZooKeeper使用ZAB协议保证了数据的一致性,确保所有写操作都由Leader处理并通过复制机制传播给Followers。
可靠性:ZooKeeper使用持久化日志来记录所有的写操作,即使Leader节点宕机,新的Leader也可以从日志中恢复数据。
高性能:ZooKeeper使用内存数据库存储数据,快速地响应读操作,并通过Leader-Follower模式进行并行处理,提高写操作的吞吐量。
分布式协调:ZooKeeper提供了丰富的原语,如锁、队列、通知等,支持复杂的分布式协调和通信操作。
ZooKeeper的缺点
单点故障:在ZooKeeper集群中,Leader是单点,如果Leader节点宕机,会导致整个集群的短暂不可用,尽管选举会尽快选出新的Leader。
写入性能:由于所有的写操作都由Leader处理,并且需要进行复制,因此在高负载情况下,写入性能可能受到影响。
数据限制:ZooKeeper的数据模型对于每个节点的数据有一定的大小限制,不适合存储大量的数据。
ZooKeeper的应用场景
配置管理:ZooKeeper可以用来管理分布式系统的配置信息,各个节点可以从ZooKeeper中获取配置信息,实现配置的动态更新和管理。
命名服务:ZooKeeper可以用作命名服务,允许应用程序在ZooKeeper上创建、删除和查找节点,实现简单的命名空间管理。
分布式锁:ZooKeeper提供了分布式锁的支持,允许多个节点在共享资源上进行协调,避免并发访问冲突。
分布式队列:ZooKeeper可以实现分布式队列,用于在多个节点之间传递消息和任务。
分布式选举:ZooKeeper的选举机制可以用来实现分布式系统中的Leader选举,确保在节点故障或变更时,集群中能够重新选举新的Leader。
综上:ZooKeeper是一个功能强大的分布式协调服务,它在分布式系统中具有广泛的应用场景,并以其高可用性、一致性、可靠性和高性能等优点赢得了广泛的认可。然而,ZooKeeper也存在一些缺点,如单点故障、写入性能和数据限制等,需要在使用时加以注意。3、Zookeeper的选举策略,leader和follower的区别?
Zookeeper的选举策略基于一种改进的Paxos算法,称为Fast Leader Election (FLE),旨在快速选出一个Leader节点以管理整个Zookeeper集群。选举过程大致遵循以下步骤:初始化:当Zookeeper集群启动时,每个节点(Server)都会进入LOOKING状态,表明它们正在寻找Leader。
选举发起:每个LOOKING状态的节点会发送一个选举请求(包含自身的服务器ID和最近接收的Zookeeper事务ID(ZXID),用(myid, ZXID)表示),这个请求会被广播给集群中的所有其他节点。
投票:节点收到选举请求后,会对比收到的(myid, ZXID)与自己的(myid, ZXID),按照以下规则投票:
优先选择ZXID较大的节点(更高的ZXID意味着更先进的数据状态)。
如果ZXID相同,则选择服务器ID较大的节点(因为较大的ID理论上代表较新的服务器)。
节点会投给自己一票,并将投票信息广播出去。
多数原则:当一个节点收到超过半数节点的投票(包括自己的投票)时,它将成为Leader。其他节点收到新Leader的通知后,会变为FOLLOWER状态,并与Leader建立连接,开始同步数据。
故障处理:如果选举过程中出现平票或Leader崩溃,集群会重新进入选举流程。
Leader和Follower的区别:Leader:
负责管理整个集群,处理写请求,将更新操作转换成事务 Proposal 并广播给所有的Follower。
接收并协调Follower的反馈,只有当大多数Follower确认了一个Proposal,这个事务才会被提交。
负责维护集群状态的一致性,确保数据同步。
Follower:
处理来自客户端的读请求,如果遇到写请求则转发给Leader处理。
跟随Leader,参与事务的投票,以维护数据的一致性。
定期向Leader发送心跳,保持与Leader的连接,并且根据Leader的指令进行数据同步,以保证自身数据副本的最新。
此外,Zookeeper集群中还有一种角色是Observer,它类似于Follower,但不参与选举过程和事务的投票,只同步数据并服务于客户端的读请求,这有助于扩展系统的读能力而不影响写操作的性能和一致性。4、介绍下Zookeeper选举算法
Zookeeper的选举算法是基于其原子消息广播协议ZooKeeper Atomic Broadcast (ZAB) 设计的,旨在快速且可靠地选举出一个Leader节点,以确保分布式系统中数据的一致性和高可用性。选举算法的核心目的是在集群启动时或Leader节点故障后,高效地确定一个新的Leader,同时确保大多数节点达成共识。以下是选举算法的基本步骤和原理:选举过程概览
初始化阶段:
所有节点初始状态为LOOKING,即都在寻找Leader状态。
每个节点启动时,会初始化自己的选举轮次(logicalclock),并为自己投票(Vote),投票内容包括服务器ID(myid)和最近接收到的事务ID(ZXID)。
发现和投票阶段:
每个节点广播自己的投票到其他所有节点。
收到投票的节点会比较收到的投票与自己的投票,基于ZXID的新旧(优先级更高)以及myid的大小来决定是否更改自己的投票。ZXID较新或在ZXID相同时myid较大的节点更优。
如果更改投票,节点会再次广播新的投票信息。
多数原则决策:
当一个节点收到超过半数节点相同的选择(包括自己的投票),则认为选举成功,该节点成为Leader。
其他节点收到新Leader的通知后,会变为FOLLOWER或OBSERVER状态,与Leader建立连接。
同步和广播阶段:
Leader负责将自身的数据同步给Follower,确保集群间数据的一致性。
一旦数据同步完成,Zookeeper集群即可对外提供服务,处理客户端的读写请求。
关键概念
ZXID:是一个64位的数字,高32位代表纪元(epoch),低32位代表事务ID。它用于确保事务的顺序性,ZXID越大表示事务越新。
myid:每个Zookeeper节点配置文件中设定的一个唯一ID,用于在选举时进行服务器的优先级排序。
logicalclock:每个节点的选举轮次计数器,每进入一轮选举,此值递增,用于防止旧的选举消息干扰新的选举。
特点
快速收敛:Zookeeper选举算法设计为快速收敛,确保在最短的时间内选出Leader,减少服务中断时间。
容错性:基于多数原则,确保即使部分节点故障,系统仍能选出有效的Leader。
一致性保证:通过确保Leader具有最新的数据视图,维持整个集群的数据一致性。
综上,Zookeeper的选举算法是一个复杂而精巧的机制,确保了在分布式环境中能够高效、可靠地选出Leader节点,是Zookeeper实现高可用和数据一致性的基石。5、Zookeeper的节点类型有哪些?分别作用是什么?
Zookeeper的节点类型主要分为两大类:一是节点角色(在集群中的角色),二是数据节点类型(根据生命周期和特性分类)。下面是具体介绍:节点角色类型:
领导者(Leader):
负责处理所有的写操作请求,维护集群的状态,以及协调和管理Follower和Observer节点。
领导者节点负责将更新操作转换为事务Proposal,并广播给集群中的Follower节点。
跟随者(Follower):
处理客户端的读请求,参与选举过程,并从Leader节点接收更新进行数据同步。
它们会响应Leader的提议,参与投票,以确保数据一致性和事务的原子性。
观察者(Observer):
观察者与Follower类似,但不参与选举过程及事务的投票过程。
它们只接收Leader的更新,提高集群的读取能力,而不会影响写操作的性能和一致性决策。
数据节点类型:
持久节点(Persistent):
一旦创建,除非被显式删除,否则一直存在。即使创建该节点的客户端会话结束,节点及其数据依然保留。
适用于存储那些需要长期存在的配置信息或状态信息。
临时节点(Ephemeral):
绑定到客户端会话,当会话结束(客户端断开连接或崩溃),这些节点会被自动删除。
适合实现分布式锁、服务注册与发现等场景,代表短暂存在的状态或资源。
持久顺序节点(Persistent Sequential):
结合了持久节点和顺序特性,创建时会在节点名后自动追加一个由父节点维护的单调递增序列号。
适用于实现分布式锁、队列等,顺序号可以帮助确定节点创建的先后顺序。
临时顺序节点(Ephemeral Sequential):
同时具备临时节点和顺序节点的特点,会话结束后节点消失,创建时也带有序列号。
在分布式系统中用于确保操作的唯一性和顺序,如实现公平锁、负载均衡选择等。
容器节点(Container,3.5版本后引入):
类似于持久节点,但是ZooKeeper服务端会监视此类节点的子节点数量,若子节点数为0,则自动删除容器节点。
适用于需要自动清理的场景,如动态服务发现和管理中的临时服务组。
持久TTL节点(Persistent TTL,需特殊配置开启):
带有生存时间(Time-To-Live)的持久节点,如果节点在一段时间内没有更新或没有子节点,将自动删除。
提供了自动清理过期数据的能力,适合存储周期性更新或有时效性的数据。
这些节点类型的设计满足了分布式系统中多样化的协调需求,如状态管理、配置同步、锁机制、队列服务等。6、Zookeeper的节点数怎么设置比较好?
Zookeeper集群的节点数量设置应该基于对容错性、性能和资源消耗的综合考量。以下是一些推荐的设置原则:最小节点数:Zookeeper推荐的最小节点数量是3。这是因为奇数个节点可以在出现网络分区(脑裂)的情况下,确保至少有一半以上的节点(即多数节点)能够达成共识,选举出Leader,从而避免服务不可用。
常见配置:对于小型至中型集群,常见的配置是3个或5个节点。3个节点是最基本的配置,可以提供基本的容错能力,但如果有任何一台节点故障,剩余节点刚好满足多数原则,这时再失去任何一个节点都会导致集群不可用。而5个节点的配置提供了更高的容错性,允许两台节点故障而不影响集群的正常运行。
大型集群:对于需要更高可用性和性能的大规模部署,可以配置7个或更多节点。更多的节点可以进一步分散负载,提高系统的整体吞吐量,并增强容错能力。
奇数原则:无论是小型还是大型集群,推荐使用奇数个节点,以确保在进行选举时,能够明确区分出多数和少数,避免选票分裂的情况,保持集群的决策效率。
资源与成本:虽然增加节点可以提升系统的稳定性和性能,但也意味着更高的硬件成本、运维复杂度以及网络通信的开销。因此,选择节点数量时也需要考虑实际的业务需求、预算和运维能力。
综上所述,Zookeeper集群的节点数应当基于业务的具体需求和资源条件来决定,但至少需要3个节点来保证基本的可用性和数据一致性。对于大多数场景,5个节点是一个较为平衡的选择,既提供了足够的容错性,又不至于过度消耗资源。在设计大规模或有特定容错需求的系统时,可以考虑配置更多的节点。7、Zookeeper架构
Zookeeper的架构设计旨在提供一个高度可靠的分布式协调服务,确保分布式环境下的数据一致性。其核心组件和设计原则如下:核心组件
客户端(Zookeeper Client):
应用程序通过Zookeeper客户端与Zookeeper集群进行交互,执行数据读写操作,注册监听事件等。
客户端可以连接到集群中的任意一个服务器,并自动处理连接失败和重连问题。
服务器(Zookeeper Server):
Zookeeper集群通常由多个服务器节点组成,分为Leader、Follower和Observer三种角色。
Leader: 单个节点,负责处理写请求,管理集群成员关系,以及数据同步。
Follower: 跟随Leader,处理读请求,并参与Leader选举过程。
Observer: 类似于Follower,但不参与选举过程和写操作的投票,仅用于扩展读取能力。
集群模式
Quorum(法定人数)模式:这是生产环境中常用的模式,要求集群中有超过一半的节点正常工作,才能确保服务的可用性。集群大小通常为奇数,以简化决策过程。
Standalone模式:单机部署,仅供测试或开发环境使用,不具备高可用性。
数据模型
Znode:Zookeeper的数据模型基于一个类似文件系统的树形结构,每个节点(称为Znode)都可以存储数据,并且可以有子节点。Znodes可以是持久的或者临时的,还可以是顺序的。
选举机制
Leader Election:利用Fast Leader Election (FLE) 算法进行Leader选举,确保在集群启动或Leader故障时快速选出新的Leader。选举过程基于服务器ID和事务ID(ZXID),确保选出拥有最新数据视图的节点作为Leader。
同步与复制
ZAB协议(Zookeeper Atomic Broadcast):确保数据更新操作能原子性地广播到所有Follower,保证了数据的一致性。
数据复制:Leader负责将更新操作同步给Follower,确保集群中的数据副本一致。
监听与通知
Watch机制:客户端可以对Znode设置监听,当Znode发生变化时,Zookeeper会触发一个事件,通知客户端,实现了事件驱动的编程模型。
容错与可靠性
奇数节点部署:为了确保高可用,Zookeeper集群通常部署为奇数个节点,这样即使有节点故障,也能维持多数节点的正常运行。
会话管理:每个客户端与Zookeeper之间建立会话,通过心跳机制维护连接,如果客户端长时间未发送心跳,其会话会被标记为已过期。
综上,Zookeeper的架构设计围绕着提供一个简单、强大、一致性的分布式协调服务,通过其独特的数据模型、选举机制、数据复制策略和监听通知系统,支撑了大量分布式系统的关键服务。8、Zookeeper的功能有哪些
ZooKeeper作为一个分布式协调服务,提供了多种关键功能,支撑着分布式系统中的众多应用场景。以下是ZooKeeper的主要功能:配置管理:允许分布式系统中的所有节点从ZooKeeper集中获取和更新配置信息,确保所有节点的配置一致性。当配置发生变化时,相关节点可以实时得到通知并作出相应的调整。
命名服务:提供类似目录服务的命名空间,使得分布式系统中的应用能够通过一个路径式的名称来定位和访问资源、服务或其他实体,便于管理和发现。
分布式锁与同步:ZooKeeper提供了一套分布式锁机制,使得多个分布式进程能够以互斥或同步的方式访问共享资源,避免并发冲突。
组服务:支持组成员管理和组内通信,包括组成员的加入、离开、选举Leader等操作,适用于构建分布式系统中的主备切换、任务分配等场景。
分布式队列:实现先进先出(FIFO)或特定逻辑的队列,帮助实现任务的有序处理或消息的传递。
选举与领导选举:通过ZAB协议实现快速且可靠地选举出一个Leader节点,确保在任何时候都有一个主控节点来处理写操作和协调集群行为。
数据发布/订阅(配置中心):允许发布者将数据发布到ZooKeeper上,订阅者可以实时获取和订阅这些数据,实现配置的集中管理和动态更新。
负载均衡:虽然ZooKeeper本身不直接提供负载均衡服务,但它可以与其他组件结合,通过服务发现机制间接支持负载均衡,例如配合服务发现工具将服务实例注册到ZooKeeper,客户端从ZooKeeper获取服务列表进行负载均衡。
分布式通知与协调:借助ZooKeeper的Watcher机制,客户端可以注册监听节点变化的事件,当节点数据或状态发生变化时,ZooKeeper会实时通知客户端,实现分布式系统间的事件驱动协同。
高可用性保障:通过复制数据到多个ZooKeeper服务器,确保即使部分服务器失效,服务依然可用。
这些功能使得ZooKeeper成为构建分布式系统不可或缺的组件,广泛应用于配置管理、服务发现、分布式锁、主备切换、负载均衡等多种场景。9、Zookeeper的数据结构(树)?基于它实现的分布式锁?基于它实现的Master选举?基于它的集群管理? Zookeeper的注册(watch)机制使用场景?
Zookeeper的数据结构(树)
Zookeeper的数据结构是一个层次化的节点树,类似于文件系统的目录结构。这个树形结构的每个节点被称为Znode。每个Znode可以存储少量数据(默认不超过1MB),并且可以拥有子节点,形成一个树状层级。Znodes可以是持久节点(Persisten)、临时节点(Ephemeral)或带有顺序标识的节点(Sequential)。这种结构不仅支持数据存储,还通过节点路径和属性实现丰富的元数据管理。基于Zookeeper实现的分布式锁
分布式锁利用Zookeeper的临时顺序节点和Watcher机制。实现步骤如下:锁创建:客户端在特定的锁目录下创建一个临时顺序节点。
锁判断:客户端检查自己创建的节点是否为该目录下的最小序号节点,如果是,则获得锁;如果不是,找到比自己小的最近节点并对其设置Watcher。
锁等待:当Watcher触发,表明前一个节点已被删除(即持有锁的客户端已完成操作),当前客户端再次尝试获取锁。
锁释放:客户端完成操作后,删除自己创建的临时节点,从而释放锁。
基于Zookeeper实现的Master选举
Master选举通过创建临时节点实现:选举过程:所有候选节点尝试在特定选举路径下创建临时节点,第一个成功的节点成为Master。
监控变更:非Master节点监控Master节点的Znode,一旦Master节点因故障下线(其临时节点自动删除),剩余节点中的一个将重新创建临时节点并成为新的Master。
平滑过渡:通过Watcher机制,所有节点能立即感知到Master状态的变化,确保服务的连续性。
基于Zookeeper的集群管理
Zookeeper用于集群管理主要体现在以下几个方面:配置同步:集中存储集群配置,各节点可从Zookeeper获取并实时更新配置。
健康监测:通过心跳检测和Watcher机制监控集群节点状态,及时发现异常。
服务发现:服务提供者在Zookeeper注册服务,消费者动态发现服务地址,实现服务的动态扩展和负载均衡。
主备切换:利用选举机制,自动进行主备节点切换,确保服务高可用。
Zookeeper的注册(Watch)机制使用场景
Zookeeper的Watch机制允许客户端注册监听某个Znode的变化(数据更新、子节点变化或节点删除),一旦发生变化,Zookeeper会异步通知客户端。这一机制广泛应用于:实时数据更新:客户端监听配置节点,实现配置的实时推送。
事件驱动编程:基于节点变化触发的业务流程,如状态变更后的自动处理。
通知与协调:在分布式系统中,用于通知其他节点进行状态同步或行动。
故障恢复:监控关键节点,实现快速故障检测和恢复逻辑。
总之,Zookeeper的数据结构、分布式锁、Master选举、集群管理以及Watch机制共同构成了一个强大的分布式协调框架,广泛应用于现代分布式系统的设计与实现中。10、介绍下Zookeeper消息的发布订阅功能
ZooKeeper 提供了一种高效的消息发布与订阅功能,常用于分布式系统中的配置管理、状态同步和通知服务。这一功能基于其核心的Watcher机制和节点数据变更通知特性来实现。以下是关于Zookeeper发布订阅功能的详细介绍:核心概念
数据节点(ZNode):ZooKeeper的数据模型是一个树形结构,每个节点(ZNode)可以存储数据,客户端可以通过路径访问这些节点。
Watcher机制:ZooKeeper的Watcher是一种轻量级的一次性触发器,客户端可以在读取数据或检查节点是否存在时设置Watcher。当被监视的ZNode发生变更(数据更新、子节点增删、节点删除)时,ZooKeeper会异步通知相关的客户端。
发布订阅流程
数据发布:发布者(可以是任何客户端或服务)将数据写入或更新到ZooKeeper的一个或多个指定的ZNode上。这一步骤相当于将消息“发布”到ZooKeeper。
数据订阅:订阅者(客户端)通过向ZooKeeper注册Watcher来“订阅”感兴趣的ZNode。这意味着订阅者告诉ZooKeeper,当这些ZNode的状态发生变化时,希望得到通知。
通知触发:一旦发布者更新了ZNode,ZooKeeper会根据先前注册的Watcher,向所有订阅了该节点变化的客户端发送事件通知。这一步骤是“推送”模式的体现,尽管ZooKeeper的推送实际上是客户端通过Watcher触发的拉取。
数据拉取:接收到通知的客户端通过Watcher回调函数得知变化,然后需要主动向ZooKeeper发起请求以获取最新的数据内容。这里体现了“拉取”模式,因为最终的数据获取是由客户端发起的。
使用场景
配置管理:应用程序可以订阅配置ZNode,当配置发生变化时,所有订阅者都能即时更新配置,无需重启服务。
服务发现:服务提供者将自身信息写入ZooKeeper,服务消费者订阅相应节点,自动发现可用服务实例。
分布式锁与同步:通过监控锁节点的变化,实现分布式锁的获取与释放,以及任务的协调同步。
集群管理:管理集群成员信息,当集群状态变化时,及时通知所有成员,便于进行主备切换、负载均衡等操作。
特点总结
实时性:Watcher机制保证了数据变化的实时通知。
灵活性:客户端可以根据需要订阅任意节点,实现灵活的消息订阅模式。
轻量级:Watcher是一次性的,每次通知后需重新注册,减少系统负担。
可靠性:结合ZooKeeper的高可用特性,确保了消息通知的可靠性。
综上,ZooKeeper的消息发布与订阅功能,通过其独特的Watcher机制,为分布式系统提供了高效、灵活的事件通知服务,是构建复杂分布式应用的重要基础。11、Zookeeper的分布式锁实现方式?
Zookeeper 实现分布式锁的常见方式是利用临时有序节点(Ephemeral Sequential Node)和Watcher事件监听机制。下面是分布式锁实现的具体步骤:实现步骤:
创建临时有序节点:
当客户端想要获取锁时,会在Zookeeper预先定义的一个锁节点(通常是一个父节点,如/locks/)下创建一个临时的有序节点。由于是有序节点,Zookeeper会自动为每个节点添加一个唯一的序号,这样就可以根据节点序号来确定锁的顺序。
判断是否获得锁:
客户端读取/locks/下的所有子节点,并对它们进行排序。如果客户端创建的节点序号是最小的,那么就认为它获得了锁。
等待锁:
如果客户端发现自己创建的节点不是最小的,它就需要等待。这时,客户端会对它前一个节点(即序号比它小的那个节点)设置一个Watcher监听。这样,当这个前驱节点被删除(意味着锁被释放)时,Zookeeper会触发Watcher通知,客户端收到通知后会再次尝试获取锁。
获取锁成功:
当客户端收到Watcher通知,说明前一个节点已经被删除,此时客户端再次检查自己是否成为了最小的节点。如果是,则认为获取锁成功,可以执行临界区代码。
释放锁:
当客户端完成操作后,需要释放锁。这很简单,只需删除之前创建的临时节点即可。由于是临时节点,当客户端与Zookeeper的会话断开时(例如客户端崩溃),Zookeeper也会自动删除该节点,从而实现锁的自动释放。综上:Zookeeper确保了分布式锁的互斥性和可靠性,有效解决了分布式系统中多线程或多进程间资源竞争的问题。12、Zookeeper怎么保证一致性的
ZooKeeper保证数据一致性的核心在于其使用的ZAB(Zookeeper Atomic Broadcast,Zookeeper原子广播)协议。以下是ZAB协议确保一致性的关键步骤和机制:Leader选举:
当ZooKeeper集群启动或领导者(Leader)失效时,所有服务器进入选举状态,使用如FastLeaderElection等算法选出一个新的Leader。选举过程中考虑服务器的ID和最近的事务ID(ZXID),确保选出具有最新数据视图的服务器作为Leader。
崩溃恢复模式:
一旦Leader被选举出来,集群进入崩溃恢复模式。Leader需要确保所有Follower节点的数据与自己一致。Leader会发送自己的最后一条事务的ZXID给Follower,Follower根据这个ZXID进行数据同步,如果发现自己的数据不一致或落后,会从Leader或其他拥有最新数据的Follower那里同步数据。
消息广播模式:
数据同步完成后,集群转为消息广播模式。所有客户端的写请求都必须通过Leader处理。Leader接收到写请求后,会生成一个事务Proposal(提议),并为该Proposal分配一个唯一的ZXID,然后将其广播给所有Follower。Follower接收到Proposal后,会将其以事务日志的形式写入本地磁盘,并向Leader发送ACK确认。
事务提交:
Leader收到半数以上Follower的ACK后,会向所有Follower发送Commit消息,指示它们可以提交该事务到内存数据库中,这样事务就完成了提交。这样确保了同一事务在所有服务器上按照相同的顺序提交,保持数据一致性。
顺序保证:
ZooKeeper确保所有事务请求按照其接收的顺序被处理,这一特性通过其原子广播协议和Leader的顺序分配ZXID来实现。每个事务都有一个唯一的ZXID,它是全局递增的,确保了任何时刻,所有服务器上的事务序列都是相同的。
会话与 watches:
ZooKeeper还通过维护客户端会话和watcher机制来提供一定程度的一致性视图。会话帮助跟踪客户端的状态,而watches允许客户端注册对特定数据节点变化的监听,当数据发生变化时,相关客户端会收到通知,从而能够及时更新其本地缓存或状态。
综上:通过ZAB协议的严格流程和Leader选举、数据同步、消息广播等机制,ZooKeeper确保了在分布式环境中数据的一致性和高可用性。13、Zookeeper的zab协议(原子广播协议)?
ZooKeeper Atomic Broadcast (ZAB) 协议是专为ZooKeeper设计的一种支持崩溃恢复的原子广播协议。它是ZooKeeper实现分布式数据一致性与高可用性的核心算法。ZAB协议确保在部分服务器失败的情况下,仍然能够保证客户端观察到的数据一致性。ZAB协议有两个主要阶段:崩溃恢复(Crash Recovery)和消息广播(Message Broadcasting)。崩溃恢复(Crash Recovery)
选举Leader:在ZooKeeper集群启动或Leader节点崩溃时,所有节点进入选举状态,通过一系列投票过程选出一个新的Leader。选举过程中考虑了节点的ID和最近的事务提议ID,确保选出的Leader拥有最新的数据视图。
数据同步:新Leader负责将自身的数据状态同步给其它Follower节点,确保所有Follower节点数据与Leader保持一致。这个过程可能包括事务日志的传输和快照的分发,以完成数据同步。
确认Leader:一旦所有Follower节点与Leader完成了数据同步,崩溃恢复阶段结束,进入消息广播阶段。
消息广播(Message Broadcasting)
原子广播:在消息广播阶段,客户端的所有写操作请求都会被转发给Leader。Leader将这些请求转换成事务提案(Proposal),并使用ZAB协议的原子广播机制将提案广播给所有的Follower。
事务提交:Leader等待超过半数的Follower确认接收提案(即Quorum确认),然后才提交事务,这个过程保证了事务的原子性和持久性。一旦事务被提交,Leader会向所有Follower发送Commit消息,Follower接收到Commit消息后会提交事务到本地存储。
客户端响应:Leader在事务被大多数Follower确认后,才会通知客户端操作成功,确保了客户端看到的是已提交的事务结果。
关键特性
崩溃恢复优先:ZAB协议设计上优先保证集群可以从崩溃状态恢复,之后再处理客户端的读写请求。
强一致性:通过确保所有更新操作被按顺序应用,ZAB协议保证了所有客户端看到的数据视图是一致的。
主备模型:ZAB协议促使ZooKeeper采用主备架构,Leader负责处理写请求并广播更新,Follower则负责服务读请求和参与协议的投票过程。
ZAB协议借鉴了Paxos算法的思想,但针对ZooKeeper的需求进行了特定优化,尤其是在处理崩溃恢复的场景上,更强调快速恢复和数据一致性。14、ZAB是以什么算法为基础的?ZAB流程?
ZAB(ZooKeeper Atomic Broadcast)算法是基于Paxos思想来实现的一种保证分布式架构中数据一致性的算法。ZAB协议主要包含了原子广播协议和崩溃恢复协议两部分。以下是ZAB协议的主要流程和特点:ZAB算法基础
Paxos思想:ZAB算法的设计借鉴了Paxos的分布式一致性算法思想,确保在分布式系统中各个节点之间数据的一致性。
ZAB流程
1. 原子广播协议
原子性:保证操作要么全部完成,要么全部不完成,不存在中间状态。
广播机制:在分布式多节点中,不是所有节点都会接收到广播,但会过半通过。
处理流程:
客户端发送请求给Follower。
Follower将请求转发给Leader。
Leader将请求转化为事务提议,并为其分配一个事务序列号(ZXID)。
Leader将提议广播给所有的Follower,并放入对应Follower的FIFO队列中。
Follower执行提议并反馈结果给Leader。
如果集群中有过半的Follower正确反馈,Leader将广播commit消息,提交提议。
2. 崩溃恢复协议
Leader选举:在Leader节点崩溃后,从Follower节点中通过一定的选举机制(如Quorum选举)选出一个新的Leader。
数据同步:新Leader确保自己拥有最新数据后,将最新数据同步给其他Follower节点,以保持集群数据的一致性。
3. ZAB算法的四个阶段(参考文章3)
Election(选举):选举出一个预主节点(预Leader)。
Discovery(发现):预主节点将自己的epoch同步给所有Follower,并同步最新的数据。
Synchronization(同步):完成数据同步操作,确保集群数据的一致性。
Boardcast(广播):预主节点成为真正的Leader后,开始接受客户端请求,并将请求广播给Follower节点。
总结
ZAB协议通过原子广播和崩溃恢复两个主要部分,以及上述的详细流程,确保了ZooKeeper分布式系统中数据的一致性和可用性。15、Zookeeper的通知机制
Zookeeper的通知机制是基于一种观察者模式(Watcher机制)实现的,它允许客户端注册监听特定事件并在这些事件发生时接收通知。以下是Zookeeper通知机制的关键特点和工作流程:关键特点:
一次性触发:Zookeeper中的Watcher是一次性触发器,即一旦触发并通知客户端后,该Watcher就会被自动删除。如果客户端需要持续监听某个事件,必须在收到通知后重新注册Watcher。
轻量级:Watcher通知非常轻量,仅包含少量信息,如事件类型、状态和相关路径,实际数据并不随通知发送。客户端在接收到通知后,通常需要发起另一个请求来获取具体的数据变化。
异步回调:通知机制是异步的,这意味着客户端注册Watcher后不会阻塞,而是在事件触发时通过回调函数通知客户端。
工作流程:
客户端注册Watcher:当客户端调用如getData(), getChildren()或exists()等API时,可以同时传递一个Watcher对象。这个操作实质上是在Zookeeper服务器端为指定的ZNode注册了一个监听。
服务端处理Watcher:Zookeeper服务器会保存这些Watcher,并在相应的ZNode发生更改(数据更新、子节点增删、节点删除等)时处理这些Watcher。
客户端回调触发:一旦触发了Watcher,Zookeeper服务器会向客户端发送一个事件通知包。客户端接收到通知后,会执行之前注册的Watcher所关联的回调函数,进而客户端可以根据通知内容作出相应的处理。
客户端重新注册Watcher:由于Watcher是一次性的,因此客户端在收到事件通知并处理完逻辑后,如果需要继续监控相同事件,需要重新注册Watcher。
使用场景:
数据变更通知:监控特定ZNode的数据变化,以便及时更新本地缓存或触发业务逻辑。
节点存在性监控:检查某个节点是否存在,用于资源存在性校验或初始化检查。
子节点变更:监控目录节点的子节点列表变化,适用于服务发现、配置更新等场景。
主选举与状态同步:在分布式系统中,用于监控领导者节点变化或进行状态同步。
Zookeeper的通知机制为分布式系统提供了强大的事件驱动能力,使得系统各组件能高效地响应状态变化,从而实现了灵活的协调和管理功能。16、Zookeeper脑裂问题
Zookeeper中的脑裂问题是指在一个Zookeeper集群中,由于某种原因(如网络故障、配置错误等),导致多个节点同时认为自己是leader(领导者),而其他节点则认为自己是follower(跟随者),从而导致整个集群无法正常工作的情况。可能导致Zookeeper脑裂问题的原因:
网络故障:Zookeeper集群中的节点需要通过网络进行通信。如果网络出现故障或通信链路出现问题,导致节点之间的通信中断,就可能出现脑裂问题。
节点故障:集群中的节点可能由于硬件故障、网络故障或软件错误等原因而出现故障。当一个节点失效时,Zookeeper集群可能会将其视为一个不同的节点,从而导致脑裂问题的出现。
配置错误:Zookeeper集群的配置可能存在错误,例如节点数量不正确、网络配置不正确或配置文件中的错误参数值等。这些配置错误可能导致Zookeeper集群无法正常工作,从而引发脑裂问题。
分布式系统问题:在分布式系统中,由于网络延迟、数据同步等问题,可能导致Zookeeper集群中的一些节点无法正确地接收其他节点的更新。这可能导致Zookeeper集群中的一些节点认为其他节点已经失效或不存在,从而导致脑裂问题的出现。
Zookeeper脑裂问题的解决方案:
使用可靠的分布式网络:确保Zookeeper集群之间的网络连接稳定、可靠,减少网络故障的发生。
使用可靠的节点故障检测机制:及时发现并处理故障节点,避免因为节点故障导致脑裂问题。
配置检查和调整:对Zookeeper集群的配置进行检查和调整,确保集群的配置正确和一致性。
Quorums(法定人数)方式:通过设定Quorums(如3个节点的集群,Quorums=2),确保集群中超过半数节点投票才能选举出Leader。这种方式可以确保leader的唯一性,避免脑裂问题的出现。
Redundant communications(冗余通信)方式:在集群中采用多种通信方式,防止一种通信方式失效导致集群中的节点无法通信。
Fencing(共享资源)方式:使用共享资源来确保只有一个节点能够获得资源锁并成为Leader,其他节点则无法成为Leader。
心跳检测:在Zookeeper集群中添加心跳检测机制,确保节点之间的通信正常。当检测到某个节点的心跳丢失时,可以触发相应的处理逻辑,如重新选举Leader等。
通过以上措施,可以有效地减少Zookeeper脑裂问题的发生,确保Zookeeper集群的稳定运行。17、Zookeeper的Paxos算法
Zookeeper中的Paxos算法是一种基于消息传递的具有高容错性的一致性算法,主要用于在分布式系统中就某个值(决议)达成一致。以下是Paxos算法在Zookeeper中的清晰描述:1. Paxos算法简介
提出者:Paxos算法由莱斯利·兰伯特(Leslie Lamport)在1990年提出。
目标:解决在分布式系统中如何就某个值(决议)达成一致的问题。
基础:基于消息传递的通信模型,适用于可能发生异常(如机器宕机、网络异常等)的分布式系统。
2. Paxos算法中的角色
Proposer(提案者):负责提出提案的节点。
Acceptor(接受者):负责投票并决定是否接受提案的节点。
Learner(学习者):当提案被选定后,同步并执行提案的节点。
3. Paxos算法流程
Paxos算法包含两个阶段:准备阶段(Prepare)和接受阶段(Accept)。准备阶段(Prepare):提案编号:Proposer生成一个全局唯一且递增的提案编号N。
发送Prepare请求:Proposer向所有Acceptor发送Prepare(N)请求,试探性地询问是否支持该编号的提案。
Acceptor响应:
如果Acceptor接受的提案编号大于或等于N,则它不会响应Prepare(N)请求。
如果Acceptor接受的提案编号小于N,则它会承诺不再接受编号小于N的提案,并返回之前接受的提案中编号最大的那个提案的Value和编号。
接受阶段(Accept):选择提案:Proposer从多数Acceptor的响应中选择编号最大的提案的Value,作为本次要发起的提案。
发送Propose请求:Proposer携带当前提案编号和Value,向所有Acceptor发送Propose请求。
Acceptor接受提案:Acceptor在不违背之前承诺的情况下,接受并持久化当前提案的编号和Value。
形成决议:当Proposer收到多数Acceptor的Accept响应后,决议形成,并将形成的决议发送给所有Learner。
4. Paxos算法的保证
一致性保证:Paxos算法保证了在分布式系统中,即使存在故障和网络异常,也能就某个值达成一致。
安全性:Paxos算法的前提是信道是安全、可靠的且不被篡改的,这在大多数局域网部署的系统中是成立的。
容错性:Paxos算法具有高度容错性,能够在多个节点故障的情况下继续工作。
5. 与Zookeeper的关系
Zookeeper是一个分布式协调服务,用于维护配置信息、命名、提供分布式同步和提供组服务等。Zookeeper使用了Paxos算法来保证其数据在多个副本之间的一致性。特别是在leader选举和写操作等关键场景中,Paxos算法确保了Zookeeper集群的稳定性和可靠性。18、Zookeeper的协议有哪些?
ZooKeeper主要依赖于一个核心的协议来保证其分布式环境中数据的一致性和服务的高可用性,这个协议就是ZooKeeper Atomic Broadcast (ZAB)。ZAB协议是特别为ZooKeeper设计的,旨在提供一种崩溃恢复和原子广播的消息传递协议,确保在任何时候,即使面对网络分割或者服务器故障,集群中的所有服务器都能达到一致的状态。ZAB协议主要包含以下两个关键阶段:崩溃恢复(Crash Recovery):在集群启动或领导者(Leader)节点失效时,ZAB协议会进入崩溃恢复模式,通过选举产生新的Leader,并确保所有Follower节点与Leader的数据同步,以此来恢复服务。
消息广播(Atomic Broadcast):一旦集群处于稳定状态,即Leader已经选举出来且所有Follower都与其同步完成,ZAB协议就会进入消息广播模式。在这个阶段,客户端的写请求会被Leader转化为事务提案(Proposal),并通过ZAB协议的原子广播机制发送给所有Follower,确保事务的有序性和一致性。
除了ZAB协议之外,ZooKeeper在客户端与服务器之间交互时,还广泛采用了Watcher机制,这是一种事件通知机制,虽然不算是协议,但它是ZooKeeper提供服务的基础特性之一。Watcher允许客户端注册对ZNode的监视,当这些ZNode的状态发生变化时,ZooKeeper服务器会向客户端发送一个事件通知,触发客户端的回调处理逻辑。总的来说,ZooKeeper的核心协议是ZAB,用于维护集群状态的一致性,而Watcher机制则是ZooKeeper提供的一个重要的客户端交互方式,两者共同支撑起ZooKeeper在分布式环境中的协调服务。19、Zookeeper如何保证数据的一致性?
Zookeeper 保证数据一致性主要通过以下几种方式:
原子广播:Zookeeper 使用一种称为 ZAB(ZooKeeper Atomic Broadcast)的原子广播协议。所有的写操作都必须通过 Leader 节点,Leader 会将操作以事务的形式广播到所有的 Follower 节点,并确保大多数节点成功响应后,才认为该操作提交成功。
顺序一致性:Zookeeper 为每个更新操作分配一个全局唯一的递增事务 ID(zxid)。客户端的读请求只会看到已经完成的事务,保证了操作的顺序一致性。
数据副本:Zookeeper 中的数据在多个节点上进行复制存储。Follower 节点会从 Leader 节点同步数据,以保持数据的一致性。
会话机制:客户端与 Zookeeper 服务器建立会话。在会话期间,服务器会跟踪客户端的状态,并确保客户端能够及时感知到数据的变化。
故障恢复:当 Leader 节点出现故障时,Zookeeper 能够快速进行选举,选出新的 Leader 节点,并保证新 Leader 节点拥有最新的已提交事务,从而继续提供一致的数据服务。
综上所述,通过这些机制的协同作用,Zookeeper 有效地保证了数据的一致性。20、Zookeeper的数据存储在什么地方?
Zookeeper 中的数据主要存储在内存中。
Zookeeper 将所有数据存储在内存中的一棵数据树(ZNode Tree)中,采用了类似文件系统的层级树状结构进行管理。每个节点称为 ZNode,ZNode 可以存储数据以及一些属性信息。
Zookeeper 还会将数据的变更记录到事务日志中,以便在服务器重启或出现故障时进行数据恢复。事务日志可以存储在磁盘上,以保证数据的持久性。
此外,Zookeeper 还可以定期将内存中的数据快照保存到磁盘上,以便在需要时快速恢复数据。
Zookeeper 的数据存储方式使其能够提供高效的数据访问和快速的故障恢复能力,适用于分布式系统中的协调和管理任务。21、Zookeeper从三台扩容到七台怎么做?
Zookeeper 可以通过扩容来增加服务器数量,以提高性能和可靠性。以下是一般的扩容步骤:
准备新服务器:选择新的服务器,并在其上安装 Zookeeper 软件。确保新服务器与现有服务器具有相同的硬件配置和操作系统。
配置 Zookeeper:在新服务器上,修改 Zookeeper 的配置文件(通常是 zoo.cfg),添加新服务器的信息。指定新服务器的 IP 地址和端口号,并设置其他相关参数,如数据目录和日志文件路径。
启动新服务器:启动新服务器上的 Zookeeper 进程。可以使用启动脚本或命令来启动 Zookeeper 服务。
连接到现有集群:在现有 Zookeeper 集群中的一台服务器上,使用 Zookeeper 客户端连接到集群。可以使用命令行工具或编程语言提供的 Zookeeper 客户端库来连接。
添加新服务器到集群:使用 Zookeeper 客户端,执行添加新服务器的操作。这通常涉及向 Zookeeper 集群发送请求,将新服务器的信息添加到集群中。
同步数据:一旦新服务器被添加到集群中,Zookeeper 会自动进行数据同步。新服务器将从现有服务器获取数据,并与其他服务器保持一致。
测试和验证:在扩容完成后,进行测试和验证以确保新服务器正常工作。可以检查服务器的状态、数据的一致性,并进行一些读写操作来验证集群的性能和可靠性。
需要注意的是,具体的扩容步骤可能因 Zookeeper 的版本和配置而有所不同。在进行扩容之前,建议参考 Zookeeper 的官方文档、相关的技术资料,并根据实际情况进行适当的调整和测试。
此外,还需要考虑一些因素,如服务器的性能、网络带宽、数据分布等,以确保扩容后的集群能够正常运行,并满足系统的需求。如果可能的话,可以在测试环境中进行模拟和测试,以验证扩容方案的可行性。参考:大数据面试题V3.0,约870篇牛客大数据面经480道面试题_牛客网
通义千问、文心一言、豆包
相关文章:

大数据面试题之Zookeeper面试题
目录 1、介绍下Zookeeper是什么? 2、Zookeeper有什么作用?优缺点?有什么应用场景? 3、Zookeeper的选举策略,leader和follower的区别? 4、介绍下Zookeeper选举算法 5、Zookeeper的节点类型有哪些?分别作用是什么? 6、Zookeeper的节点数怎么设置比较好? …...
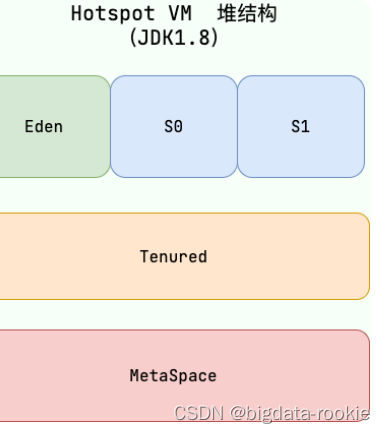
JVM 内存区域
一、运行时数据区域 Java 虚拟机在执行 Java 程序的过程中,会把它管理的内存划分成若干个不同的数据区域。 JDK 1.8 和之前的版本略有不同,这里介绍 JDK 1.7 和 JDK 1.8 两个版本。 JDK 1.7: 线程私有: 程序计数器虚拟机栈本地…...

全网最强剖析Spring AOP底层原理
相信各位读者对于Spring AOP的理解都是一知半解,只懂使用,却不懂原理。网上关于Spring AOP的讲解层出不穷,但是易于理解,让人真正掌握原理的文章屈指可数。笔者针对这一痛点需求,决定写一篇关于Spring AOP原理的优质博…...

Vscode中的行尾序列CRLF/LF不兼容问题
最近开发的的时候,打开项目文件经常会出现爆红错误提示信息,显示如下图: 这东西太烦人了,毕竟谁都不希望在遍地都是爆红的代码里写东西,就像能解决这个问题,根据提示可以知道这是vscode中使用的prettier插件…...

常见加密方式:MD5、DES/AES、RSA、Base64
16/32位的数据,最有可能就是使用md5加密的 使用对称加密的时候,双方使用相同的私钥 私钥:单独请求/隐藏在前端的隐藏标签当中 二、RSA非对称密钥加密 公钥加密,私钥解密 私钥是通过公钥计算生成的 加密解密算法都在js源文件当…...

如何在 C++/Qt/CMake 项目中构建 Rust 代码
问题描述 我有一个使用 CMake 构建的现有 C/Qt 项目,我想开始添加 Rust 代码,并能够从主 C 代码库中调用这些 Rust 代码。应该如何组织项目结构? 现有项目结构 ./CMakeLists.txt ./subproject-foo/CMakeLists.txt ./subproject-foo/src/..…...

封装了一个优雅的iOS转场动画
效果图 代码 // // LBTransition.m // LBWaterFallLayout_Example // // Created by mac on 2024/6/16. // Copyright © 2024 liuboliu. All rights reserved. //#import "LBTransition.h"interface LBPushAnimation:NSObject<UIViewControllerAnimated…...
数据中心技术:大数据时代的机遇与挑战
在大数据时代,数据中心网络对于存储和处理大量信息至关重要。随着云计算的出现,数据中心已成为现代技术的支柱,支持社交媒体、金融服务等众多行业。然而,生成和处理的大量数据带来了一些挑战,需要创新的解决方案。在这…...

29、架构-技术方法论之向微服务迈进
治理:理解系统复杂性 微服务架构的引入增加了系统的复杂性,这种复杂性不仅体现在技术层面,还包括组织、管理和运维等各个方面。本节将详细探讨微服务架构的复杂性来源,并介绍一些应对复杂性的治理策略。 1. 什么是治理 治理是指…...

点云处理实操 1. 求解点云法向
目录 一、点云法向的定义 二、如何计算计算法向量 三、实操 四、代码 main.cpp CMakeList.txt 一、点云法向的定义 点云法向量是指点云中某个点的局部表面法向量(Normal Vector)。法向量在三维空间中用来描述表面在该点处的方向属性,它是表面几何特征的重要描述工具。…...

XSS+CSRF组合拳
目录 简介 如何进行实战 进入后台创建一个新用户进行接口分析 构造注入代码 寻找XSS漏洞并注入 小结 简介 (案例中将使用cms靶场来进行演示) 在实战中CSRF利用条件十分苛刻,因为我们需要让受害者点击我们的恶意请求不是一件容易的事情…...
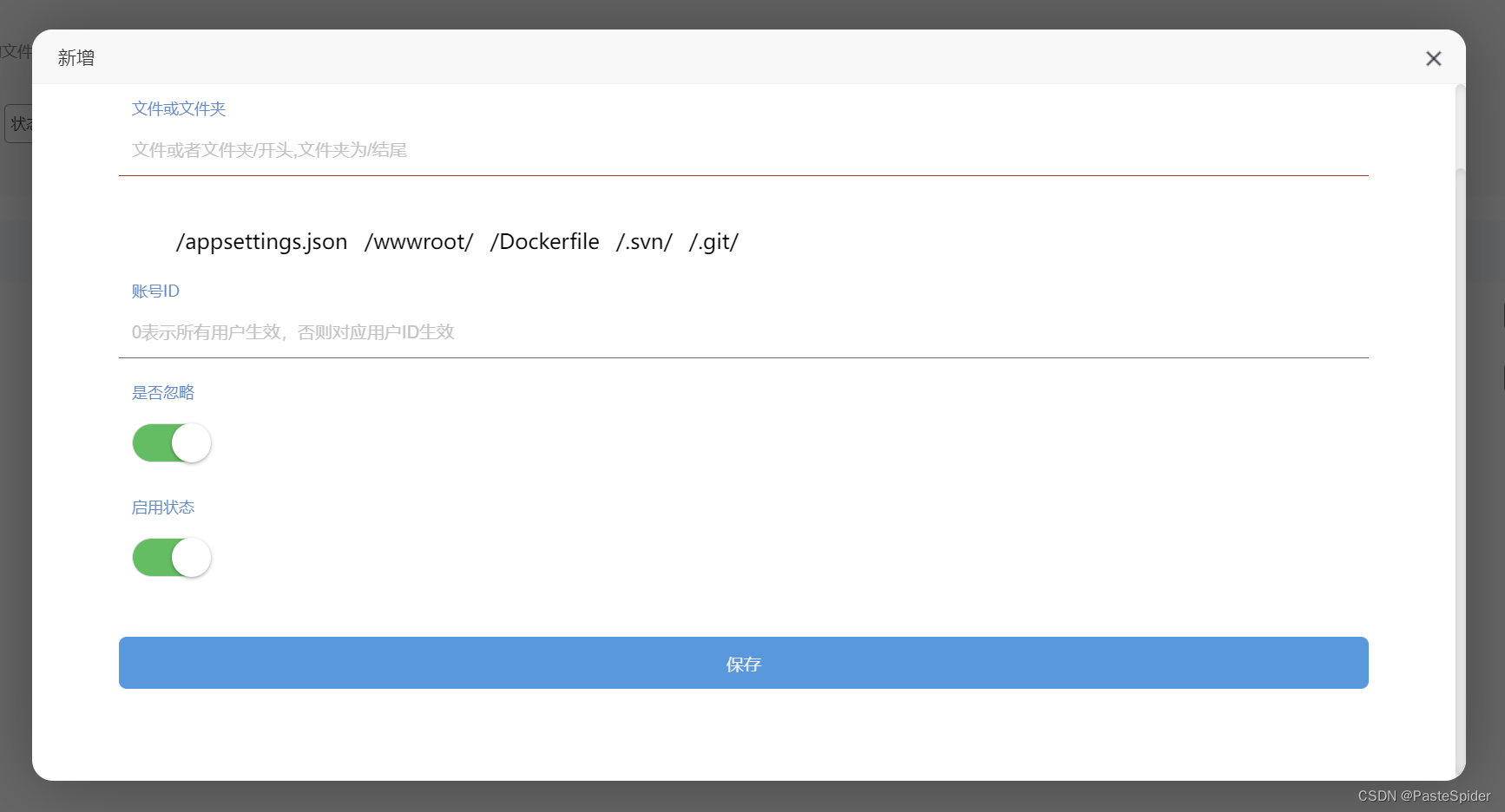
PasteSpiderFile文件同步管理端使用说明(V24.6.21.1)
PasteSpider作为一款适合开发人员的部署管理工具,特意针对开发人员的日常情况做了一个PasteSpiderFile客户端,用于windows上的开发人员迅速的更新发布自己的最新代码到服务器上! 虽然PasteSpider也支持svn/git的源码拉取,自动编译…...

NLP中两种不同的中文分词形式,jieba和spaCy
1. jieba分词 import jiebatext在中国古代文化中,书法和绘画是艺术的重要表现形式。古人常说,‘文字如其人’,通过墨迹可以窥见作者的性情和气质。而画家则以笔墨搏击,表现出山川河流、花鸟虫鱼的灵动。这些艺术形式不仅仅是技艺…...
)
【数据库】四、数据库编程(SQL编程)
四、数据库编程 另一个大纲: 5.1存储过程 5.1.1存储过程基本概念 5.1.2创建存储过程 5.1.3存储过程体 5.1.4调用存储过程 5.1.5删除 5.2存储函数 5.2.1创建存储函数 5.2.2调用存储函数 5.2.3删除存储函数 目录 文章目录 四、数据库编程1.SQL编程基础1.1常量1.2变…...

17.RedHat认证-Ansible自动化运维(下)
17.RedHat认证-Ansible自动化运维(下) 这个章节讲ansible的变量,包括变量的定义、变量的规则、变量范围、变量优先级、变量练习等。 以及对于tasks的控制,主要有loop循环作业、条件判断等 变量 介绍 Ansible支持变量功能,能将value存储到…...
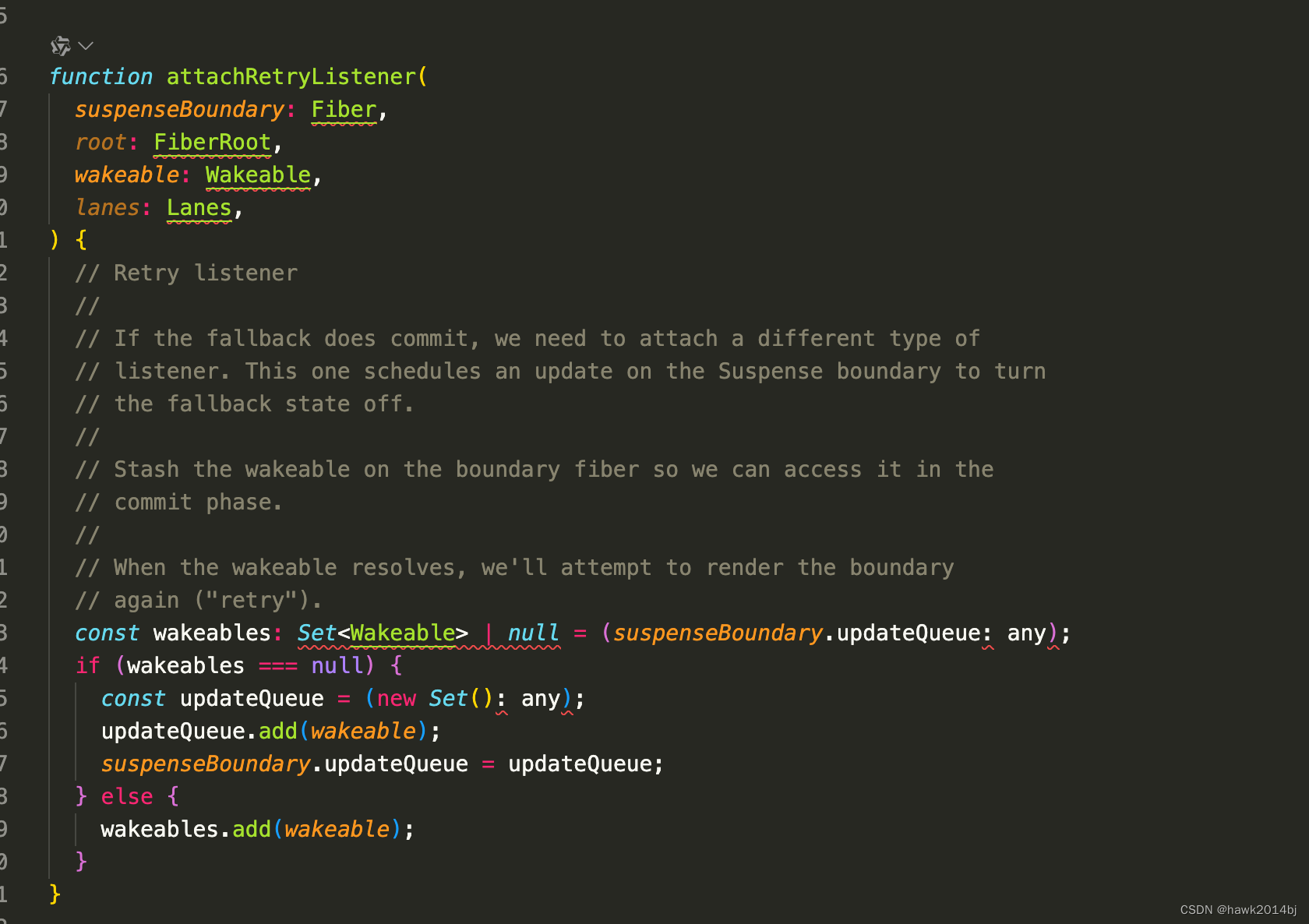
React Suspense的原理
React Suspense组件的作用是当组件未完成加载时,显示 fallback 组件。那么 Suspense 是如何实现的呢?React 的渲染是通过 Fiber 进行的,Suspense 的更新机制也是要围绕 Fiber 架构进行的。Suspense 是由两部分组成,实际 UI 子组件…...

React的生命周期函数详解
import React,{Component} from "react";import SonApp from ./sonAppclass App extends Component{state{hobby:爱吃很多好吃的}// 是否要更新数据,这里返回true才会更新数据shouldComponentUpdate(nextProps,nextState){console.log("app.js第一步…...

DoubleSummaryStatistics 及其相关类之-简介
1. DoubleSummaryStatistics 使用简介 在Java 8中,DoubleSummaryStatistics 类被引入作为 java.util 包的一部分。它是一个用于收集统计数据(如计数、最小值、最大值、和、平均值等)的类,特别适用于处理 double 类型的数据。 Do…...

java线程间的通信 - join 和 ThreadLocal
你好,我是 shengjk1,多年大厂经验,努力构建 通俗易懂的、好玩的编程语言教程。 欢迎关注!你会有如下收益: 了解大厂经验拥有和大厂相匹配的技术等 希望看什么,评论或者私信告诉我! 文章目录 一…...

差分GPS原理
双差RTK(Real-Time Kinematic)算法是基于差分全球卫星导航系统(GNSS)技术的一种高精度定位方法。它利用至少两个接收机(一个为基站,其他为移动站)接收自同一组卫星的信号来实现精确测量。双差处…...

Kubernetic:提升Kubernetes管理效率的桌面客户端工具
1. 项目概述:一个为Kubernetes而生的桌面客户端 如果你和我一样,每天的工作都离不开Kubernetes,那你肯定对 kubectl 命令行工具又爱又恨。爱的是它功能强大、无所不能;恨的是它那陡峭的学习曲线和需要时刻记忆的大量命令与参数。…...
)
给娃规划信奥路?先看懂CSP-J/S初赛分数线背后的“地域密码”(2019-2024年数据解读)
解码CSP-J/S初赛分数线:家长必知的地域竞争策略(2019-2024实战指南) 当孩子第一次接触信息学奥赛时,大多数家长都会面临相似的困惑:为什么同样的分数在A省能轻松晋级,在B省却可能止步初赛?过去…...

电子认证合规护航跨境数字身份互认、国际数字身份互信
在数字中国建设与高水平对外开放协同推进的背景下,跨境贸易、金融合作与数字服务加速线上化,数字信任成为打通跨境交互壁垒的核心因素。电子认证作为网络空间信任体系的基石,其全流程合规不仅是自身服务运营的要求,更是护航跨境数…...

算法联盟·全域数学公理体系下黑洞标量毛发与LVK引力波O4全维理论、求导、证明、计算、验证、分析
算法联盟全域数学公理体系下黑洞标量毛发与LVK引力波O4全维理论、求导、证明、计算、验证、分析 算法联盟 全域数学公理体系下黑洞标量毛发与 LVK 引力波O4 全维理论、求导、证明、计算、验证、分析 所属体系:算法联盟 ROOT 全域数学网格第一性原理(AI科…...

开源镜像站架构与部署实战:APT、Docker、PyPI同步与性能优化
1. 项目概述:一个面向中文开发者的开源镜像站如果你是一名在国内的开发或运维工程师,对“镜像站”这个词一定不会陌生。无论是安装Python的pip包,还是更新Ubuntu的apt源,又或是拉取Docker镜像,我们常常会受限于网络环境…...

AI代理环境交互SDK:TypeScript实现标准化观察与动作接口
1. 项目概述:一个为AI代理构建交互式环境的TypeScript SDK如果你正在尝试构建一个能够与现实世界应用(比如浏览器、IDE、甚至操作系统)进行交互的AI代理,那么你很可能已经遇到了一个核心难题:如何让代理“看见”并“操…...

亚朵季报图解:营收28亿 净利4.6亿 预计全年增长24%到28%
雷递网 雷建平 5月14日亚朵(NASDAQ:ATAT)昨日发布截至2026年3月31日的财报,财报显示,亚朵2026年第一季度营收28.11亿(约4.07亿美元),较上年同期的19亿元增长48%。亚朵2026年第一季来自Manachise…...

VSCode扩展一键克隆Git仓库:告别终端切换,提升开发效率
1. 项目概述:在VSCode里直接克隆仓库,告别终端切换如果你和我一样,每天的工作流都离不开Git和VSCode,那你一定经历过这个场景:在浏览器上看到一个不错的开源项目,复制它的GitHub链接,然后切到终…...

超薄OLED字符显示屏技术解析与工业应用
1. 超薄OLED字符显示屏的技术革新 在工业控制和嵌入式系统领域,显示模块的选择往往需要在可视性、功耗和空间占用之间寻找平衡点。Newhaven Display最新推出的超薄OLED字符显示屏系列,通过突破性的结构设计将厚度压缩至5mm,同时实现了10,000:…...

如何在Windows上安装安卓应用?APK安装器完整指南
如何在Windows上安装安卓应用?APK安装器完整指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想要在Windows电脑上直接运行安卓应用,却不想安…...