深入理解SQL优化:理论与实践的结合
深入理解SQL优化:理论与实践的结合
SQL优化是数据库性能优化的核心,通过优化SQL查询,可以极大地提高数据库的响应速度和资源利用效率。本文将以SQL优化的理论基础和实践应用为主线,结合具体案例,系统化地介绍如何有效地优化SQL查询。
一、SQL查询执行过程
理解SQL查询的执行过程是优化的基础。这一过程包括三个主要阶段:解析、优化和执行。
-
解析:
- SQL解析器将SQL语句解析为查询树,并检查其语法和语义。
- 解析树描述了查询的逻辑结构。
-
优化:
- 查询优化器生成多个可能的执行计划,并选择代价最低的计划进行执行。
- 优化器会考虑使用索引、选择连接顺序、以及其他优化策略。
-
执行:
- 执行器根据优化器选择的执行计划,逐步执行查询操作,最终返回结果。
二、SQL优化的基本原则
SQL优化的目的是减少查询的计算复杂度和资源消耗,以下是一些基本原则:
-
减少数据扫描:
- 优先使用索引,避免全表扫描。
- 适当的索引设计可以显著提高查询效率。
-
优化连接操作:
- 选择合适的连接方式(如嵌套循环连接、哈希连接、合并连接)和连接顺序,以减少计算量。
-
避免不必要的排序和聚合:
- 排序(如ORDER BY)和聚合操作(如GROUP BY)通常比较耗时,应尽量避免不必要的排序和聚合。
-
合理使用索引:
- 索引能够显著提高查询效率,但过多的索引也会增加维护成本。
- 选择合适的索引类型(如B-tree索引、哈希索引)和索引字段。
三、具体的SQL优化技巧
根据优化原则,以下是一些具体的SQL优化技巧:
-
选择合适的索引:
- B-tree索引适用于范围查询和排序操作。B-tree索引使用树结构,有序存储数据,并且支持范围查询和排序。
- 哈希索引适用于精确匹配查询。哈希索引使用哈希表,数据在哈希桶中无序存储,只支持快速的等值查询。
-
优化表设计:
- 垂直拆分:将经常使用的字段单独存放在一个表中,减少单个表的宽度。
- 水平分区:将数据按一定规则划分到多个表中,减少单个表的数据量。
-
使用执行计划分析工具查询计划:
- 使用数据库的执行计划分析工具,查看查询的执行计划,找到潜在的性能瓶颈。
- 例如
EXPLAIN命令:
EXPLAIN SELECT * FROM your_table WHERE your_condition; -
理解优化器的JOIN操作选择:
SQL优化器会根据查询条件、表大小、索引情况和系统统计信息自动选择最优的JOIN算法,以减少查询执行时间和系统资源消耗。开发人员可以通过编写清晰的SQL查询和设计合理的索引来帮助优化器做出最佳选择。如果查询执行计划不符合预期,可以使用EXPLAIN命令查看执行计划,并根据需要进行调整优化。
-
嵌套循环连接 (Nested Loop Join)
- 适用场景:当一个表(通常是较小的表)的连接操作。
- 工作原理:对于左边表中的每一行,嵌套循环连接会扫描右边表,找到与左边表当前行匹配的行。这种方法简单直观,但如果右表很大,效率可能较低。
- 优点:实现简单,不需要额外的内存空间。
- 缺点:当右表很大时,效率较低,因为需要对右表进行大量的随机访问。
-
**哈希连接 (Hash Join) **
- 适用场景:适用于连接大表之间的情况。
- 工作原理:哈希连接首先会对两个参与连接的表的连接列进行哈希处理,生成哈希表。然后基于哈希值进行连接操作。这种方法通常需要足够的内存来执行哈希操作,但对于大型数据集的连接效率较高。
- 优点:当参与连接的表很大时,哈希连接的效率很高。
- 缺点:需要足够的内存空间来存储哈希表,如果内存不足可能会降低性能。
-
合并连接 (Merge Join)
- 适用场景:适用于已经排序过的连接操作。
- 工作原理:合并连接将两个参与连接的表按照连接条件排序,然后顺序地比较并合并匹配的行。这种方法对于已经有序的大表连接操作效率很高,但是排序操作可能会成为性能瓶颈。
- 优点:当参与连接的表已经排序时,合并连接的效率很高。
- 缺点:需要对参与连接的表进行排序操作,如果表很大,排序可能会成为性能瓶颈。
-
-
避免使用SELECT * 查询:
- SELECT * 会查询表中所有字段,增加不必要的I/O开销,应该只选择需要的字段。
- 例如:
SELECT column1, column2 FROM your_table WHERE your_condition; -
使用缓存和临时表:
- 对于复杂的查询,可以使用缓存或临时表存储中间结果,减少重复计算。
-
分批处理大数据量操作:
- 对于大数据量的操作(如批量插入、更新),可以分批处理,减少单次操作的负载。
-
使用EXISTS代替IN:
- 当IN的参数是子查询时,使用EXISTS通常比IN更快,因为EXISTS在找到符合条件的第一条记录后就会停止搜索。
- 例如:
-- 慢 SELECT * FROM Class_A WHERE id IN (SELECT id FROM Class_B); -- 快 SELECT * FROM Class_A A WHERE EXISTS (SELECT * FROM Class_B B WHERE A.id = B.id); -
使用连接代替IN:
- 当IN的参数是子查询时,使用连接操作通常会更快。
- 例如:
-- 使用连接代替IN SELECT A.id, A.name FROM Class_A A INNER JOIN Class_B B ON A.id = B.id; -
避免排序操作:
- 尽量减少使用需要排序的操作,如ORDER BY、GROUP BY、DISTINCT等。
-
使用集合运算符的ALL选项:
- 当不在乎结果中是否有重复数据时,使用UNION ALL、INTERSECT ALL等操作避免排序。
-- 不使用ALL SELECT * FROM Class_A UNION SELECT * FROM Class_B; -- 使用ALL SELECT * FROM Class_A UNION ALL SELECT * FROM Class_B; -
使用EXISTS代替DISTINCT:
- 当需要对两张表的连接结果去重时,使用EXISTS代替DISTINCT可以避免排序操作。
-- 使用DISTINCT SELECT DISTINCT I.item_no FROM Items I INNER JOIN SalesHistory SH ON I.item_no = SH.item_no; -- 使用EXISTS SELECT item_no FROM Items I WHERE EXISTS (SELECT * FROM SalesHistory SH WHERE I.item_no = SH.item_no); -
在极值函数中使用索引(MAX/MIN):
- 对于MAX和MIN函数,尽量使用索引字段。
-- 这样写需要扫描全表 SELECT MAX(item) FROM Items; -- 这样写能用到索引 SELECT MAX(item_no) FROM Items; -
能写在WHERE子句里的条件不要写在HAVING子句里:
- 在聚合前使用WHERE子句过滤条件,效率更高。
-- 使用HAVING子句 SELECT sale_date, SUM(quantity) FROM SalesHistory GROUP BY sale_date HAVING sale_date = '2007-10-01'; -- 使用WHERE子句 SELECT sale_date, SUM(quantity) FROM SalesHistory WHERE sale_date = '2007-10-01' GROUP BY sale_date; -
在GROUP BY和ORDER BY子句中使用索引:
- 指定带索引的列作为GROUP BY和ORDER BY的列,可以实现高速查询。
-
避免不必要的索引扫描:
- 在索引字段上进行运算会导致无法使用索引,应尽量避免在索引字段上进行运算。
- 例如:
-- 不能用到索引
WHERE col_1 * 1.1 > 100;
-- 能用到索引
WHERE col_1 > 100 / 1.1;
-
使用IS NULL和IS NOT NULL时的注意事项:
- 通常,索引字段是不存在NULL的,所以指定IS NULL和IS NOT NULL的话会使得索引无法使用。
- 对于需要使用IS NOT NULL的情况,可以使用不等号并指定一个比最小值还小的数。
-
避免使用否定形式:
- 否定形式(如<>、!=、NOT IN)不能用到索引,尽量避免使用。
-
使用LIKE谓词进行前方一致匹配:
- 只有前方一致的LIKE匹配才能用到索引。
假设有一个名为
employees的表,其中包含一个名为last_name的字段,该字段有索引。现在我们需要查找所有姓为"Smith"的员工:-- 使用前方一致的LIKE匹配,能够使用索引 SELECT * FROM employees WHERE last_name LIKE 'Smith%';在上面的查询中,我们使用了前方一致的LIKE匹配(即在
Smith后面加上了%通配符),这样可以使用到last_name字段的索引,提高查询效率。但是,如果我们需要查找所有姓氏中包含"ith"的员工,那么就无法使用前方一致的LIKE匹配了:
-- 使用了中间通配符的LIKE匹配,无法使用索引 SELECT * FROM employees WHERE last_name LIKE '%ith%';
四、深入理解SQL优化的原理
进一步了解SQL优化的底层原理,有助于在实际应用中更加灵活地应用各种优化技巧。
- 查询优化器的工作原理:
- 优化器通过评估不同执行计划的代价(如I/O、CPU、内存消耗),选择最优的执行计划。
- 优化器通常会考虑索引使用、连接顺序、并行执行等因素。
- 索引的设计与维护:
- 索引可以极大地提高查询效率,但需要注意索引的创建和维护成本。
- 过多的索引会影响插入、更新操作的性能,因此应根据查询频率和类型合理设计索引。
- 数据库统计信息的重要性:
- 优化器依赖数据库的统计信息(如表的行数、字段的分布等)进行成本估算。
- 定期更新统计信息有助于优化器生成更准确的执行计划。
通过理解和应用这些SQL优化技巧,可以显著提高数据库查询的性能,使系统更加高效、稳定。希望这些方法能够在实际工作中对大家有所帮助。
相关文章:

深入理解SQL优化:理论与实践的结合
深入理解SQL优化:理论与实践的结合 SQL优化是数据库性能优化的核心,通过优化SQL查询,可以极大地提高数据库的响应速度和资源利用效率。本文将以SQL优化的理论基础和实践应用为主线,结合具体案例,系统化地介绍如何有效…...
)
PostgreSQL 高级功能与扩展(九)
1. JSONB 数据类型与操作 1.1 JSONB 简介 JSONB 是 PostgreSQL 中的一种数据类型,用于存储 JSON 格式的数据,并提供高效的查询和索引功能。 1.1.1 创建 JSONB 列 CREATE TABLE json_data ( id SERIAL PRIMARY KEY, data JSONB ); 1.2 JSONB 查询与索…...

【LinuxC语言】UDP数据收发
文章目录 前言udp流程图udp函数介绍bind函数recvfrom函数sendto函数示例代码总结前言 在计算机网络中,UDP(用户数据报协议)是一种无连接的传输层协议,它允许应用程序快速地发送短的消息或数据报。由于UDP不需要建立和断开连接,因此它的传输速度往往比其他协议更快,但它也…...
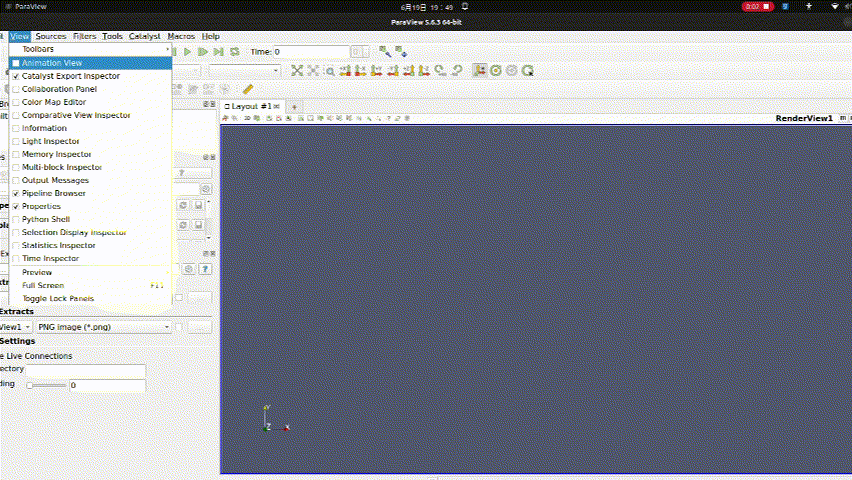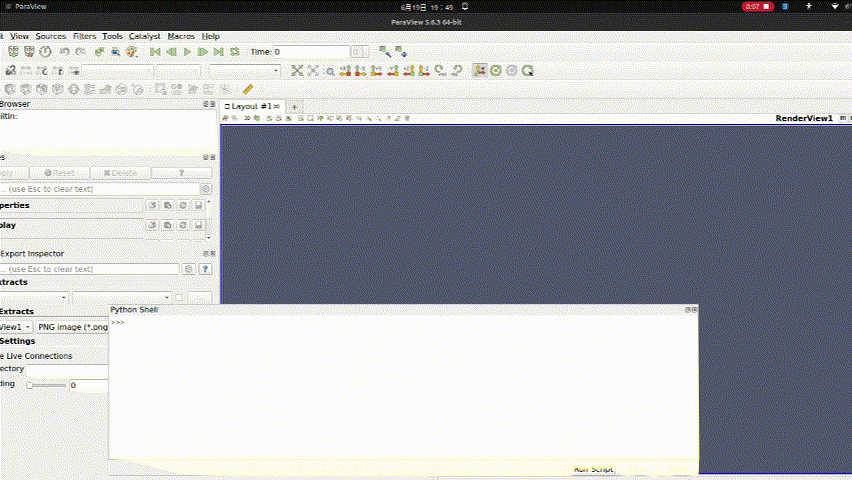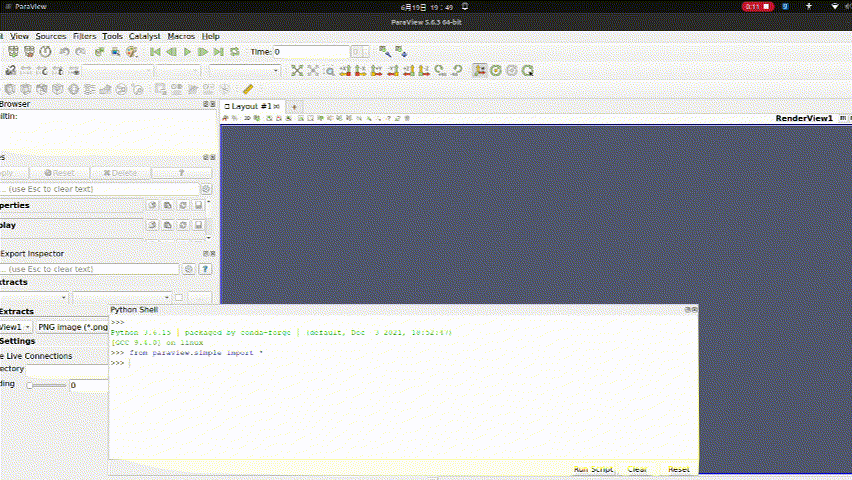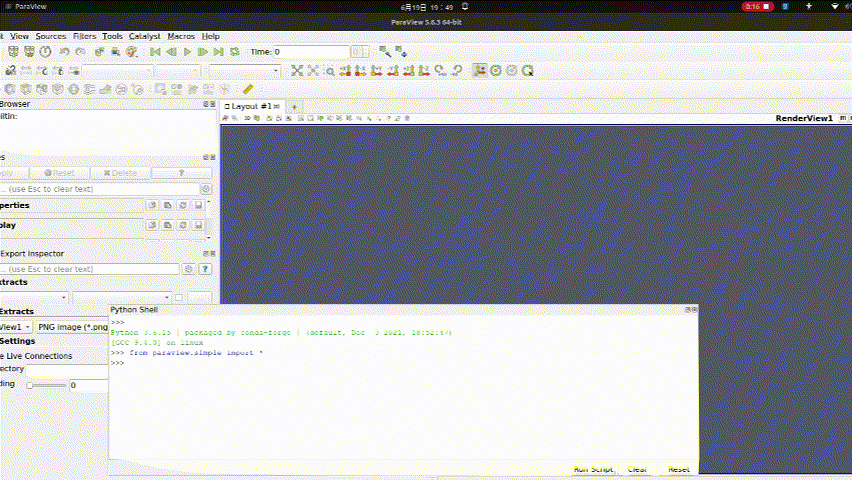
【深度学习驱动流体力学】计算流体力学openfoam-paraview与python3交互
目的1:配置 ParaView 中的 Python Shell 和 Python 交互环境 ParaView 提供了强大的 Python 接口,允许用户通过 Python 脚本来控制和操作其可视化功能。在 ParaView 中,可以通过 View > Python Shell 菜单打开 Python Shell 窗口,用于执行 Python 代码。要确保正确配置 …...
EWM学习之旅-1-EWM100
系统学习一个业务模块已经变得越来越重要,开始吧,EWM! EWM的Learning Journey中包括7本 ebook,100/110/115/120/125/130/140,一本一本的啃吧,相信很多内容是重复的。 EWM100很适合初学者,了解概念术语&…...

qt中的枚举值-QMetaEnum
QMetaEnum 测试代码hcpp 讲解 测试代码 h #include <QMainWindow> #include <QDebug>QT_BEGIN_NAMESPACE namespace Ui { class MainWindow; } QT_END_NAMESPACEclass MainWindow : public QMainWindow {Q_OBJECTpublic:MainWindow(QWidget *parent nullptr);~M…...

这才是CSDN最系统的网络安全学习路线(建议收藏)
01 什么是网络安全 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 无论网络、Web、移动、桌面、云等哪个领域,都有攻与防两面…...

微软Edge浏览器多用户配置文件管理:个性化浏览体验
在家庭或工作环境中,经常需要在同一台计算机上为多个用户创建和管理独立的浏览体验。微软Edge浏览器提供了多用户配置文件管理功能,允许用户为每个账户设置独立的书签、历史记录、密码、扩展和设置。本文将详细介绍如何在微软Edge中管理多个用户配置文件…...
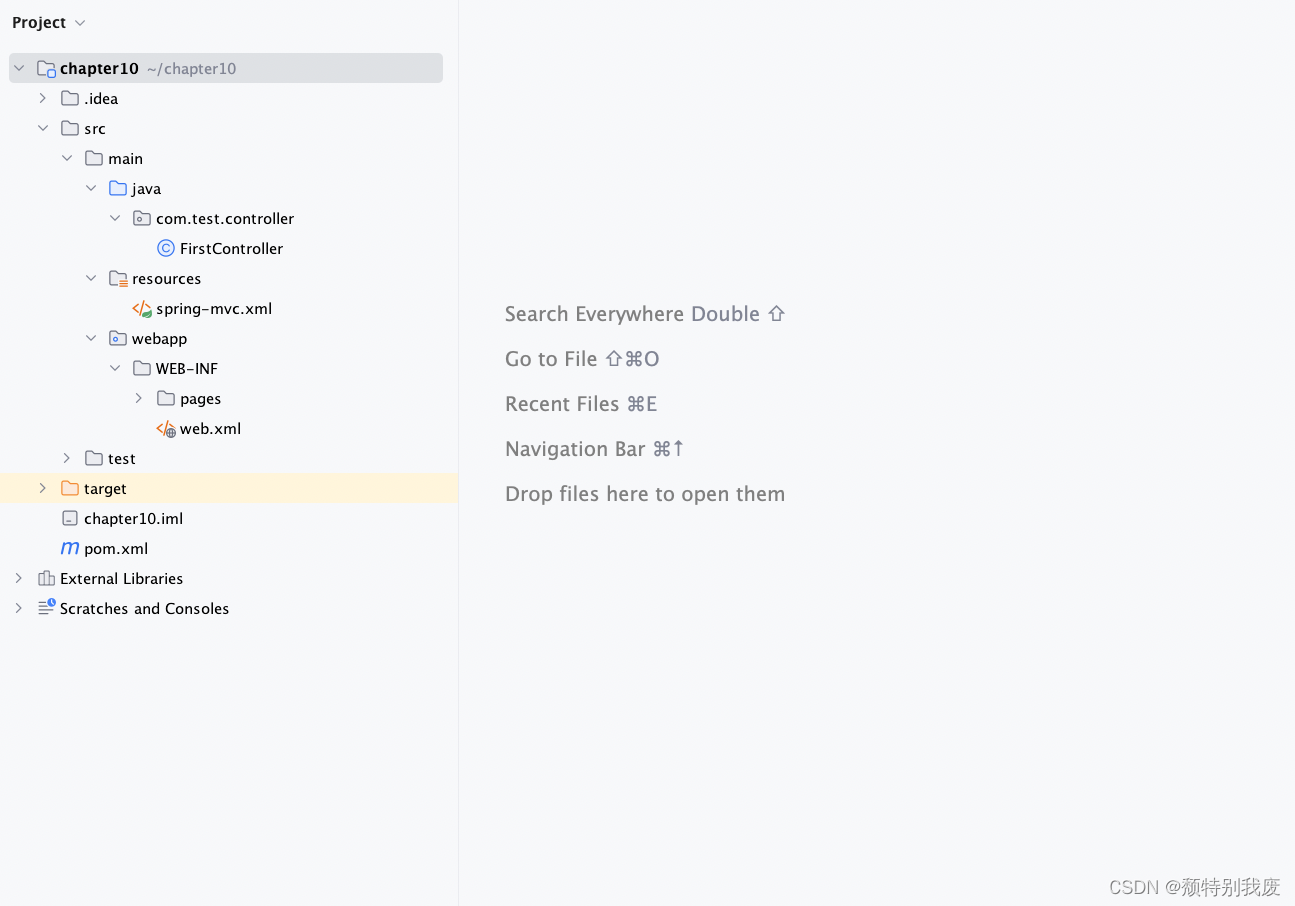
10.2 JavaEE——Spring MVC入门程序
要求在浏览器发起请求,由Spring MVC接收请求并响应,具体实现步骤如下。 一、创建项目 在IDEA中,创建一个名称为chapter10的Maven Web项目。 (一)手动设置webapp文件夹 1、单击IDEA工具栏中的File→“Project Structu…...

Python 处理大量数据的相关库和框架推荐
Python 处理大量数据的相关库和框架推荐 Python 生态系统中存在多个强大的库和框架,它们可以帮助开发者高效地处理大量数据。以下是一些广泛使用的推荐选项: 1. NumPy 一个用于大规模数值计算的科学计算库。提供多维数组对象和相应的操作。 2. Panda…...
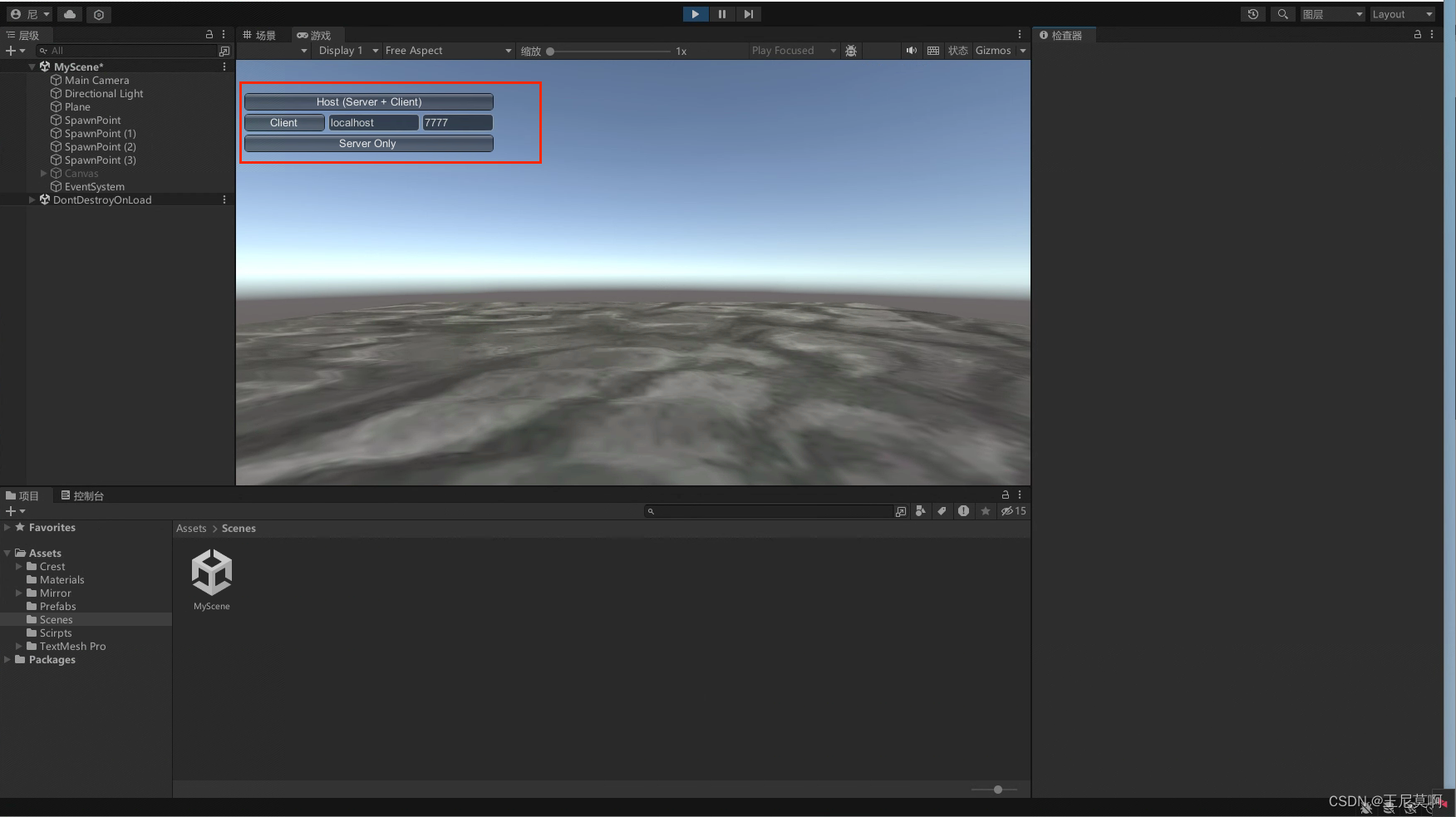
【unity笔记】七、Mirror插件使用
一、简介 Mirror 是一个用于 Unity 的开源多人游戏网络框架,它提供了一套简单高效的网络同步机制,特别适用于中小型多人游戏的开发。以下是 Mirror 插件的一些关键特点和组件介绍: 简单高效:Mirror 以其简洁的 API 和高效的网络…...
掌握SEO:如何优化用ChatGPT生成的文章以提升搜索排名
在数字化时代,搜索引擎优化(SEO)已经成为网站流量的重要来源。随着人工智能技术的进步,越来越多的人开始使用ChatGPT等AI工具来生成文章。然而,虽然这些工具可以快速生成内容,但要确保这些内容在搜索引擎中…...
Java面试问题(一)
一.Java语言具有的哪些特点 1.Java是纯面向对象语言,能够直接反应现实生活中的对象 2.具有平台无关性,利用Java虚拟机运行字节码文件,无论是在window、Linux还是macOS等其他平台对Java程序进行编译,编译后的程序可在其他平台上运行…...

Firewalld防火墙基础
Firewalld 支持网络区域所定义的网络连接以及接口安全等级的动态防火墙管理工具 支持IPv4、IPv6防火墙设置以及以太网桥 支持服务或应用程序直接添加防火墙规则接口 拥有两种配置模式 运行时配置:临时生效,一旦重启或者重载即不生效 永久配置:…...

解决Java中多线程同步问题的方案
解决Java中多线程同步问题的方案 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在Java开发中,多线程同步问题是我们经常面对的挑战之一。正确处理…...

每日一练 - RSTP与STP收敛速度对比
01 真题题目 RSTP 收敛速度比 STP 要快,以下说法正确的是? A. 在 RSTP 中检测拓扑是发生变化只有一个标准.一个非边缘端口迁移到 Forwarding 状态 B. 在 STP 中,为了避免临时环路,至少要等待一个 Forwarding Delay 待全网端口确定,所有端口才能进行转发 C. P/A …...

ZS-20H型水泥胶砂振实台
一、 概述 水泥胶砂振实台是为我国水泥胶砂强度检验方法等同采ISO679国际标准而设计。该仪器符合 JC/T 682《水泥胶砂试体成型振实台》要求,适用于水泥强度检验所用试样的制备。 二、 技术数据 1、台盘(包括臂杆、压模框等)的总质量 13.75 …...

力扣377 组合总和Ⅳ Java版本
文章目录 题目描述代码 题目描述 给你一个由 不同 整数组成的数组 nums ,和一个目标整数 target 。请你从 nums 中找出并返回总和为 target 的元素组合的个数。 题目数据保证答案符合 32 位整数范围。 示例 1: 输入:nums [1,2,3], targe…...
昇思25天学习打卡营第3天 | 数据集 Dataset
数据是深度学习的基础,高质量的数据输入将在整个深度神经网络中起到积极作用。MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。其中Dataset是Pipel…...

交换机三层架构及对流量的转发机制
交换机的作用: 区别集线器(HUB); HUB 为物理层设备,只能直接转发电流 交换机为数据链路层设备,可以将电流与二进制转换,实现了以下功能: 无限的传输距离 彻底解决了冲突-所有的接口可以同时收发数据 二…...

Windows11下DOSBox从零到精通的完整配置与实战指南
1. 为什么要在Windows11上使用DOSBox? 很多年轻朋友可能都没见过DOS系统长什么样。作为上世纪80年代到90年代的主流操作系统,DOS虽然界面简陋,但它孕育了无数经典软件和游戏。直到今天,学习汇编语言、运行老式工业控制程序、怀旧经…...

从‘一核有难,多核围观’到雨露均沾:深入Linux内核看网卡中断与RSS/RPS
从“一核有难,多核围观”到雨露均沾:Linux内核网络中断负载均衡实战解析 当服务器网卡吞吐量突然暴跌时,很多工程师的第一反应是检查带宽和协议栈参数,却忽略了最底层的CPU中断分配机制。我曾处理过一台数据库服务器,在…...

美颜SDK如何选择?直播APP开发最容易忽略的几个问题
这几年,直播行业的竞争已经从“有没有功能”,逐渐演变成了“用户体验够不够好”。很多团队在做直播APP时,往往会把重点放在推流、连麦、礼物、私域运营这些显性功能上,却忽略了一个对用户留存影响极大的核心模块——美颜SDK。尤其…...

番茄小说下载器:从网页到电子书的完整离线阅读解决方案
番茄小说下载器:从网页到电子书的完整离线阅读解决方案 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 番茄小说下载器是一款基于Rust语言开发的开源工具ÿ…...

每日大赛间歇期通过Taotoken模型广场探索新模型特性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 每日大赛间歇期通过Taotoken模型广场探索新模型特性 对于每日参与各类AI应用开发或创意大赛的选手而言,比赛间歇期并非…...

C语言实现热水器温度控制PID算法详解与嵌入式实战
1. 项目概述与核心价值最近在整理一些嵌入式开发的老项目,翻出来一个用C语言写的热水器温度控制PID算法示例。这玩意儿虽然代码量不大,但麻雀虽小五脏俱全,把PID控制的核心思想、参数整定、抗积分饱和这些关键点都体现出来了。对于刚接触自动…...

开源机械爪资源宝库:从入门到进阶的完整实践指南
1. 项目概述:一个为开源“机械爪”而生的资源宝库如果你对机器人、自动化或者开源硬件感兴趣,最近又在琢磨着给自己的项目加个能抓取、能操作的“手”,那么你很可能已经听说过或者正在寻找“OpenClaw”相关的资料。vincentkoc/awesome-opencl…...

UE5保姆级教程:用Electra Player插件在场景里放视频,从导入MP4到带声音播放
UE5实战指南:Electra Player插件实现场景视频播放全流程解析 在虚幻引擎5的沉浸式场景中,视频播放功能已成为增强环境叙事的关键技术。无论是商场里的动态广告屏、科幻场景中的全息投影,还是角色手持设备的交互界面,流畅的视频播放…...

通用运放设计挑战:扫地机器人传感器信号调理实战解析
1. 项目概述:当扫地机器人遇上通用放大器最近在帮一个做智能硬件的朋友优化他们新一代扫地机器人的主控板,聊到传感器信号调理这块,他跟我大倒苦水。他说,现在的扫地机为了更“聪明”,身上集成的传感器越来越多&#x…...

联想刃7000k BIOS深度解锁技术实现与性能优化指南
联想刃7000k BIOS深度解锁技术实现与性能优化指南 【免费下载链接】Lenovo-7000k-Unlock-BIOS Lenovo联想刃7000k2021-3060版解锁BIOS隐藏选项并提升为Admin权限 项目地址: https://gitcode.com/gh_mirrors/le/Lenovo-7000k-Unlock-BIOS 联想刃7000k作为一款高性能游戏主…...