【深度强化学习】(4) Actor-Critic 模型解析,附Pytorch完整代码
大家好,今天和各位分享一下深度强化学习中的 Actor-Critic 演员评论家算法,Actor-Critic 算法是一种综合了策略迭代和价值迭代的集成算法。我将使用该模型结合 OpenAI 中的 Gym 环境完成一个小游戏,完整代码可以从我的 GitHub 中获得:
https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Model
1. 算法原理
根据 agent 选择动作方法的不同,可以把强化学习方法分为三大类:行动者方法(Actor-only),评论家方法(Critic-only),行动者评论家方法(Actor-critic)。
行动者方法中不会对值函数进行估计,直接按照当前策略和环境进行交互。通过交互后得到的立即奖赏值直接优化当前策略。例如:Policy Gradients
评论家方法没有需要维护的策略,评论家方法的策略是直接通过当前的值函数获得的,并通过值函数获得的策略与环境交互。交互得到的立即奖赏值用来优化当前值函数。例如:DQN
行动者评论家方法是由行动者和评论家两个部分构成。行动者用于选择动作,评论家评论选择动作的好坏。行动者选择动作的方法不是依据当前的值函数,而是依据存储的策略。评论家的评论一般采用时间差分误差的形式,时间差分误差是根据当前的值函数计算获得的。时间差分误差是是评论家的唯一输出,并且驱动了行动者和评论家之间的所有学习。

2. 公式推导
根据策略梯度算法的定义,策略优化目标函数如下:
令 ,,称
为优势函数。采用 n 步时序差分法求解时,
可以表示如下:
当 n 为一个完整的状态序列大小时,该算法与蒙特卡洛算法等价。
Actor-Critic 算法一共分为两个部分,Critic 和 Actor 网络。
Critic 是评判网络,当输入为环境状态时,它可以评估当前状态的价值,当输入为环境状态和采取的动作时,它可以评估当前状态下采取该动作的价值。
Actor 为策略网络,以当前的状态作为输入,输出为动作的概率分布或者连续动作值,再由 Critic 网络来评价该动作的好坏从而调整策略。Actor-Critic算法将动作价值评估和策略更新过程分开,Actor 可以对当前环境进行充分探索并缓慢进行策略更新,Critic 只需要负责评价策略的好坏,所以这种集成算法有相对较好的性能。
Critic 网络的输入一般有两种形式,(1)如果输入为状态,则该评价网络的作用为评价当前状态价值;(2)如果输入为状态和动作,则该评价网络的作用为评价当前状态的动作价值。
如果评价网络 Critic 为状态价值 state value 的评价网络,输入为状态。Critic 网络的损失函数计算公式采用均方误差损失函数,即 TD 误差值的累计平方值的均值,表达式如下:
Actor 网络的优化目标可以如下:
其中, 代表最优策略,由于该公式表达的含义为当 TD 误差值大于 0 时增强该动作选择概率,当 TD 误差值小于 0 时减小该动作选择概率,所以目标为最小化损失函数
如果评价网络 Critic 为动作价值 action value 的评价网络,即输入为状态和动作,则Critic 网络的损失函数如下:
其中, 的表达式变换如下:
Actor-Critic 算法流程如下:

3. 代码实现
Actor-Critic 模型部分的实现方式如下:
import torch
from torch import nn
from torch.nn import functional as F
import numpy as np# ------------------------------------ #
# 策略梯度Actor,动作选择
# ------------------------------------ #class PolicyNet(nn.Module):def __init__(self, n_states, n_hiddens, n_actions):super(PolicyNet, self).__init__()self.fc1 = nn.Linear(n_states, n_hiddens)self.fc2 = nn.Linear(n_hiddens, n_actions)# 前向传播def forward(self, x):x = self.fc1(x) # [b,n_states]-->[b,n_hiddens]x = F.relu(x) x = self.fc2(x) # [b,n_hiddens]-->[b,n_actions]# 每个状态对应的动作的概率x = F.softmax(x, dim=1) # [b,n_actions]-->[b,n_actions]return x# ------------------------------------ #
# 值函数Critic,动作评估输出 shape=[b,1]
# ------------------------------------ #class ValueNet(nn.Module):def __init__(self, n_states, n_hiddens):super(ValueNet, self).__init__()self.fc1 = nn.Linear(n_states, n_hiddens)self.fc2 = nn.Linear(n_hiddens, 1)# 前向传播def forward(self, x):x = self.fc1(x) # [b,n_states]-->[b,n_hiddens]x = F.relu(x)x = self.fc2(x) # [b,n_hiddens]-->[b,1]return x# ------------------------------------ #
# Actor-Critic
# ------------------------------------ #class ActorCritic:def __init__(self, n_states, n_hiddens, n_actions,actor_lr, critic_lr, gamma):# 属性分配self.gamma = gamma# 实例化策略网络self.actor = PolicyNet(n_states, n_hiddens, n_actions)# 实例化价值网络self.critic = ValueNet(n_states, n_hiddens)# 策略网络的优化器self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)# 价值网络的优化器self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)# 动作选择def take_action(self, state):# 维度变换numpy[n_states]-->[1,n_sates]-->tensorstate = torch.tensor(state[np.newaxis, :])# 动作价值函数,当前状态下各个动作的概率probs = self.actor(state)# 创建以probs为标准类型的数据分布action_dist = torch.distributions.Categorical(probs)# 随机选择一个动作 tensor-->intaction = action_dist.sample().item()return action# 模型更新def update(self, transition_dict):# 训练集states = torch.tensor(transition_dict['states'], dtype=torch.float)actions = torch.tensor(transition_dict['actions']).view(-1,1)rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1,1)next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float)dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1,1)# 预测的当前时刻的state_valuetd_value = self.critic(states)# 目标的当前时刻的state_valuetd_target = rewards + self.gamma * self.critic(next_states) * (1-dones)# 时序差分的误差计算,目标的state_value与预测的state_value之差td_delta = td_target - td_value# 对每个状态对应的动作价值用log函数log_probs = torch.log(self.actor(states).gather(1, actions))# 策略梯度损失actor_loss = torch.mean(-log_probs * td_delta.detach())# 值函数损失,预测值和目标值之间critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach()))# 优化器梯度清0self.actor_optimizer.zero_grad() # 策略梯度网络的优化器self.critic_optimizer.zero_grad() # 价值网络的优化器# 反向传播actor_loss.backward()critic_loss.backward()# 参数更新self.actor_optimizer.step()self.critic_optimizer.step()4. 案例演示
我们使用 OpenAI 的 gym 库中的环境,完成一个小案例。我们的目的是左右移动黑色小车使得黄色的杆子保持竖直。状态 state 的维度为 4,动作 action 有 2 个。

环境交互与训练部分的代码如下:
import numpy as np
import matplotlib.pyplot as plt
import gym
import torch
from RL_brain import ActorCritic# ----------------------------------------- #
# 参数设置
# ----------------------------------------- #num_episodes = 100 # 总迭代次数
gamma = 0.9 # 折扣因子
actor_lr = 1e-3 # 策略网络的学习率
critic_lr = 1e-2 # 价值网络的学习率
n_hiddens = 16 # 隐含层神经元个数
env_name = 'CartPole-v1'
return_list = [] # 保存每个回合的return# ----------------------------------------- #
# 环境加载
# ----------------------------------------- #env = gym.make(env_name, render_mode="human")
n_states = env.observation_space.shape[0] # 状态数 4
n_actions = env.action_space.n # 动作数 2# ----------------------------------------- #
# 模型构建
# ----------------------------------------- #agent = ActorCritic(n_states=n_states, # 状态数n_hiddens=n_hiddens, # 隐含层数n_actions=n_actions, # 动作数actor_lr=actor_lr, # 策略网络学习率critic_lr=critic_lr, # 价值网络学习率gamma=gamma) # 折扣因子# ----------------------------------------- #
# 训练--回合更新
# ----------------------------------------- #for i in range(num_episodes):state = env.reset()[0] # 环境重置done = False # 任务完成的标记episode_return = 0 # 累计每回合的reward# 构造数据集,保存每个回合的状态数据transition_dict = {'states': [],'actions': [],'next_states': [],'rewards': [],'dones': [],}while not done:action = agent.take_action(state) # 动作选择next_state, reward, done, _, _ = env.step(action) # 环境更新# 保存每个时刻的状态\动作\...transition_dict['states'].append(state)transition_dict['actions'].append(action)transition_dict['next_states'].append(next_state)transition_dict['rewards'].append(reward)transition_dict['dones'].append(done)# 更新状态state = next_state# 累计回合奖励episode_return += reward# 保存每个回合的returnreturn_list.append(episode_return)# 模型训练agent.update(transition_dict)# 打印回合信息print(f'iter:{i}, return:{np.mean(return_list[-10:])}')# -------------------------------------- #
# 绘图
# -------------------------------------- #plt.plot(return_list)
plt.title('return')
plt.show()绘制每回合的回报 return

相关文章:
【深度强化学习】(4) Actor-Critic 模型解析,附Pytorch完整代码
大家好,今天和各位分享一下深度强化学习中的 Actor-Critic 演员评论家算法,Actor-Critic 算法是一种综合了策略迭代和价值迭代的集成算法。我将使用该模型结合 OpenAI 中的 Gym 环境完成一个小游戏,完整代码可以从我的 GitHub 中获得…...

SQL注入——文件上传
目录 一,mysql文件上传要点 二,文件上传指令 一句话木马 三,实例 1,判断注入方式 2,测试目标网站的闭合方式: 3,写入一句话木马 4,拿到控制权 一,mysql文件上传…...

【ESP32+freeRTOS学习笔记之“ESP32环境下使用freeRTOS的特性分析(新的开篇)”】
目录【ESP32freeRTOS学习笔记】系列新的开篇ESP-IDF对FreeRTOS的适配ESP-IDF环境中使用FreeRTOS的差异性简介关于FreeRTOS的配置关于ESP-IDF FreeRTOS Applications结语【ESP32freeRTOS学习笔记】系列新的开篇 ESP-IDF对FreeRTOS的适配 FreeRTOS是一个可以适用于多个不同MCU开…...

Uipath Excel 自动化系列18-RefreshPivotTable(刷新透视表)
活动描述 RefreshPivotTable(刷新透视表):如果透视表的数据源发生变化,需使用刷新透视表活动,该活动需与Use Excel File 活动选择的 Excel 文件一起使用。 使用如下图: RefreshPivotTable(刷新透视表)属性 属性 作用 Display…...

设计模式之不变模式
在并行软件开发过程中,同步操作是必不可少的。当多线程对同一个对象进行读写操作时,为了保证对象数据的一致性和正确性,有必要对对象进行同步操作,但同步操作对系统性能有损耗。不变模式可以去除这些同步操作,提高并行…...

C++11 map
C11中Map的使用Map是c的一个标准容器,她提供了很好一对一的关系,在一些程序中建立一个map可以起到事半功倍的效果,总结了一些map基本简单实用的操作!1. map最基本的构造函数;map<string , int >mapstring; map&l…...
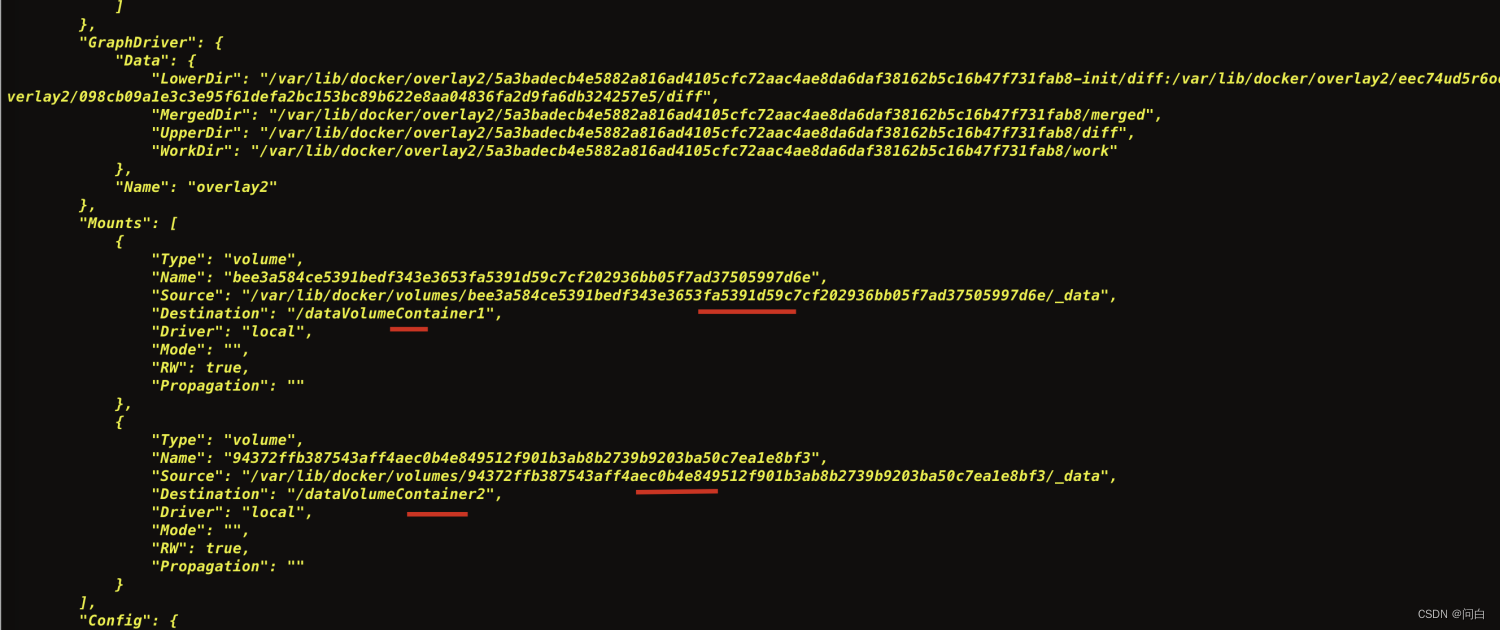
docker基本命令 - 数据卷
作用 ● 做数据持久化。防止容器一旦停止运行,该容器中运行产生的数据就没了 ● 不同容器之间的数据共享(大鲸鱼背上各个小集装箱之间可以共享数据) 交互式命令使用 docker run -it -v / 宿主机的绝对路径目录:/容器内绝对路径目录 镜像名 docker run -it -v / 宿…...

SQL查漏补缺
有这么一道题,先看题目,表的内容如下 显示GDP比非洲任何国家都要高的国家名称(一些国家的GDP值可能为NULL)。 错误的查询: SELECT name FROM bbcWHERE gdp > ALL (SELECT gdp FROM bbc WHERE region Africa)正确的查询: SE…...

偏向锁撤销
偏向状态 一个对象创建时: 如果开启了偏向锁(默认开启),那么对象创建后,markword 值为 0x05 即最后 3 位为 101,这时它的thread、epoch、age 都为 0。偏向锁是默认是延迟的,不会在程序启动时立…...
Qt版海康MV多相机的采集显示程序
创建对话框工程MultiCamera工程文件MultiCamera.pro#------------------------------------------------- # # Project created by QtCreator 2023-03-11T16:52:53 # #-------------------------------------------------QT core guigreaterThan(QT_MAJOR_VERSION, 4): …...
2023年江苏省职业院校技能大赛中职网络安全赛项试卷-教师组任务书
2023年江苏省职业院校技能大赛中职网络安全赛项试卷-教师组任务书 一、竞赛时间 9:00-12:00,12:00-15:00,15:00-17:00共计8小时。 二、竞赛阶段 竞赛阶段 任务阶段 竞赛任务 竞赛时间 分值 第一阶段 基础设施设置与安全加固、网络安全事件响应、数…...
零基础小白如何自学网络安全成为顶尖黑客?
在成为黑客之前,你需要做两点准备: 1、学一门编程语言。学哪一门不重要,但你要参考一下下面的条例: C语言是Unix系统的基础。它(连同汇编语言)能让你学习对黑客非常重要的知识:内存的工作原理…...

外贸建站如何提高搜索引擎排名,吸引更多潜在客户?
在如今全球贸易日益繁荣的背景下,越来越多的企业开始重视外贸建站,并寻求提高搜索引擎排名以吸引更多潜在客户。 那么,如何才能有效地提高外贸网站的搜索引擎排名呢?本文将为您详细介绍几个有效的方法。 一、关键词优化 关键词…...
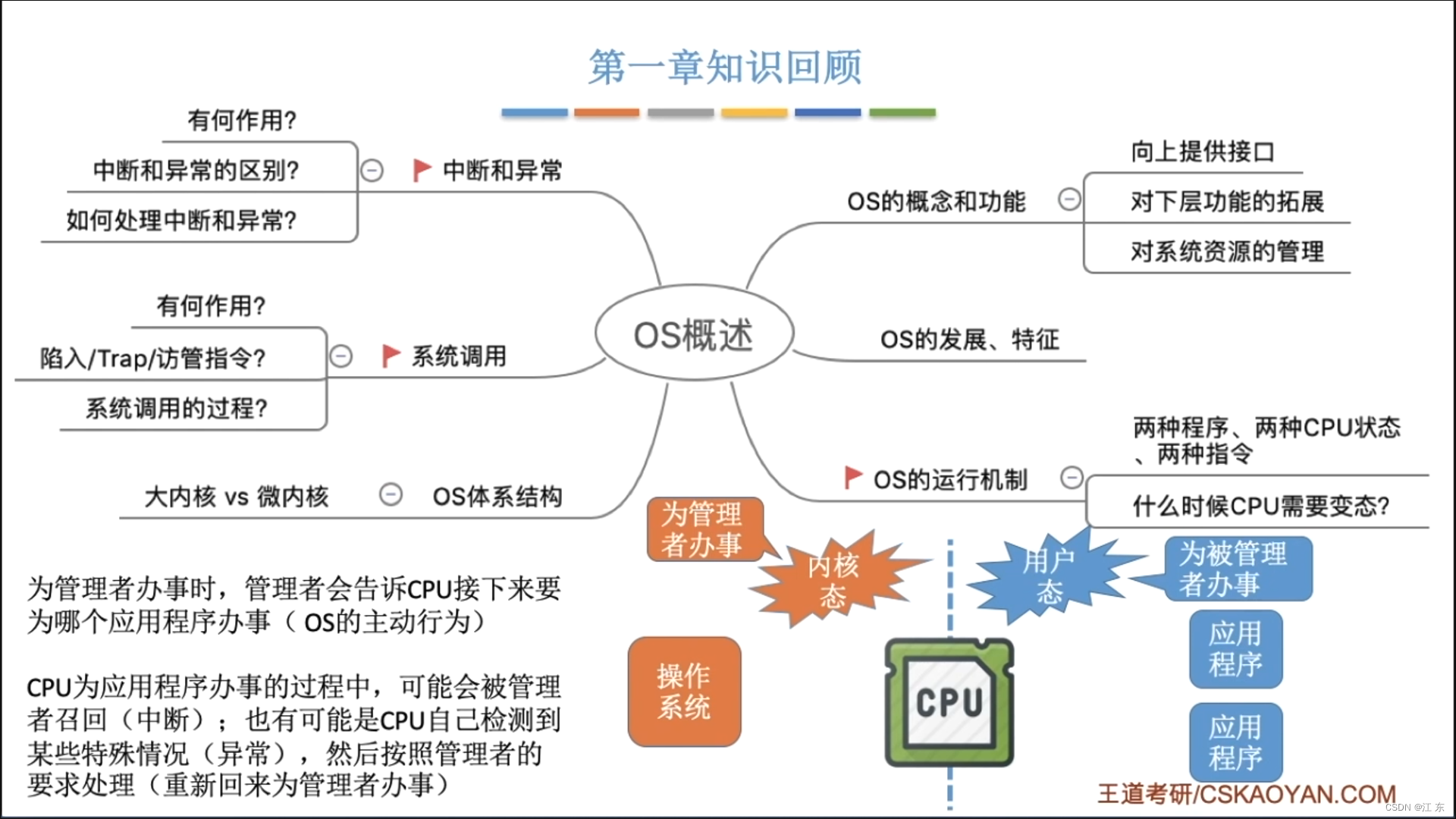
计算机网络考研-第一章学
计算机网学习总结第一章计算机系统概述1.1.1 导学1.1.2 操作系统的特征1.2 操作系统的发展与分类1.3 操作系统的运行环境1.3.1 操作系统的运行机制1.3.2 中断和异常1.3.3系统调用:1.3.4 操作系统的体系结构第一章总结第一章计算机系统概述 1.1.1 导学 1.1.2 操作系…...

【分布式版本控制系统Git】| Git概述、Git安装、Git常用命令
目录 一:概述 1.1. 何为版本控制 1.2. 为什么需要版本控制 1.3. 版本控制工具 1.4. Git 简史 1.5. Git 工作机制 1.6. Git和代码托管中心 二:安装 2.1. Git安装 三:常用命令 3.1 设置用户签名 3.2 初始化本地库 3.3 查看本地库…...
【人脸识别】ssd + opencv Eigenfaces 和 LBPH算法进行人脸监测和识别
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言ssd opencv Eigenfaces 和 LBPH算法进行人脸监测和识别1. ssd 目标监测2.opencv的三种人脸识别方法2.1 Eigenfaces2.2 LBPH前言 ssd opencv Eigenfaces 和 LB…...
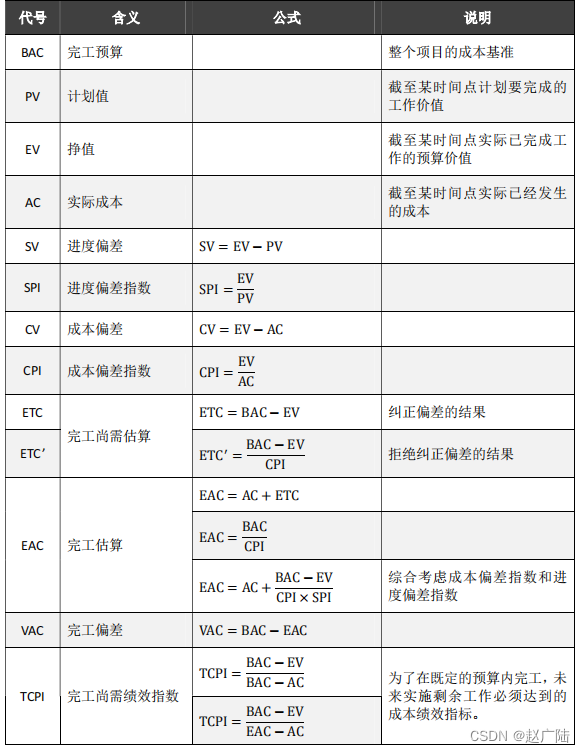
PMP项目管理项目成本管理
目录1 项目成本管理概述2 规划成本管理3 估算成本4 制定预算5 控制成本1 项目成本管理概述 项目成本管理包括为使项目在批准的预算内完成而对成本进行规划、估算、预测、融资、筹资、管理和控制的各个过程,从而确保项目在批准的预算内完工。核心概念 项目成本管理旨…...

Vue3视频播放器组件Vue3-video-play入门教程
Vue3-video-play适用于 Vue3 的 hls.js 播放器组件 | 并且支持MP4/WebM/Ogg格式。 1、支持快捷键操作 2、支持倍速播放设置 3、支持镜像画面设置 4、支持关灯模式设置 5、支持画中画模式播放 6、支持全屏/网页全屏播放 7、支持从固定时间开始播放 8、支持移动端,移动…...

操作系统经典问题——消费者生产者问题
今日在学习操作系统的过程中遇到了这个问题,实在是很苦恼一时间对于这种问题以及老师上课根据这个问题衍生的问题实在是一头雾水。在网络上寻找了一些大佬的讲解之后算是暂时有了点茅塞顿开的感觉。 首先第一点什么是生产者——消费者问题: 系统中有一…...

网络安全工程师在面试安全岗位时,哪些内容是加分项?
金三银四已经来了,很多小伙伴都在困惑,面试网络安全工程师的时候,有哪些技能是加分项呢?接下来,我简单说说! 去年我在微博上贴了一些在面试安全工作时会加分的内容,如下: 1. wooyu…...
)
UniApp实战:如何安全高效地在安卓10+设备上实现本地数据存储(附权限配置避坑指南)
UniApp安卓10本地数据存储实战:权限配置与高性能方案设计 当你的UniApp在安卓10设备上突然无法保存用户配置时,控制台那行冰冷的"Permission denied"可能让整个开发团队陷入深夜加班。这不是简单的API调用问题,而是安卓存储机制变革…...

macOS高效录屏工具实战指南:从入门到专业的QuickRecorder应用技巧
macOS高效录屏工具实战指南:从入门到专业的QuickRecorder应用技巧 【免费下载链接】QuickRecorder A lightweight screen recorder based on ScreenCapture Kit for macOS / 基于 ScreenCapture Kit 的轻量化多功能 macOS 录屏工具 项目地址: https://gitcode.com…...

DoL-Lyra构建系统:5分钟学会自动化游戏MOD打包
DoL-Lyra构建系统:5分钟学会自动化游戏MOD打包 【免费下载链接】DOL-CHS-MODS Degrees of Lewdity 整合 项目地址: https://gitcode.com/gh_mirrors/do/DOL-CHS-MODS DOL-CHS-MODS(Degrees of Lewdity汉化美化整合包)是一款专为Degree…...

vLLM-v0.17.1效果展示:vLLM在中文古诗生成任务中的韵律保持能力
vLLM-v0.17.1效果展示:vLLM在中文古诗生成任务中的韵律保持能力 1. vLLM框架简介 vLLM是一个专为大型语言模型(LLM)设计的高性能推理和服务库,以其出色的速度和易用性著称。这个项目最初由加州大学伯克利分校的天空计算实验室开发,现在已经…...

还在手工整理IT报表?这套自动化模板让你彻底解放双手
在不断变化的IT管理环境中,透明度和合规性已成为企业生存和发展的基石。面对日益繁杂的法规与标准,组织需要精细的报表与审计流程来支撑业务稳健运行。作为一款专为现代IT打造的尖端平台,Endpoint Central不仅大幅减轻了合规负担,…...

【信号处理】基于预设性能的无模型自适应分数阶快速终端滑模控制在MIMO非线性系统中的研究附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...
| 彻底吃透:自定义 JWT 认证 + 全局登录中间件)
Django 学习日记(补充1)| 彻底吃透:自定义 JWT 认证 + 全局登录中间件
大家好,这是我 Django 学习日记的第三篇。上一篇我们把路由、反向解析、DRF 自动路由、媒体文件、跨域全部讲明白了。今天我们进入整个项目最核心、最安全、最关键的部分:用户登录认证体系(在进入视图前的一篇补充文章)。本文将从…...

Obsidian移动端深度评测:安卓/iOS同步技巧+5个必装生产力插件
Obsidian移动端深度评测:安卓/iOS同步技巧5个必装生产力插件 在移动办公场景下,Obsidian作为一款强大的知识管理工具,其跨平台能力与插件生态为商务人士和学生群体提供了独特的价值。本文将深入解析Obsidian在Android和iOS平台的核心差异&…...
)
别再死记命令了!用EVE-NG模拟器5分钟搞定思科GRE隧道(附OSPF联动配置)
5分钟玩转思科GRE隧道:EVE-NG实战中的高效学习法 第一次在EVE-NG里搭建GRE隧道时,我盯着满屏的命令行发呆——这些配置到底在做什么?为什么tunnel接口要配源和目的地址?OSPF又是怎么和隧道联动的?直到我用Wireshark抓到…...

s2-pro效果展示:会议纪要转语音+重点语句强调式播报实录
s2-pro效果展示:会议纪要转语音重点语句强调式播报实录 1. 专业语音合成新体验 s2-pro作为Fish Audio开源的专业级语音合成模型镜像,正在重新定义文本转语音的标准。不同于常见的聊天式语音工具,它专注于提供高质量的语音合成服务ÿ…...