Transformers是SSMs:通过结构化状态空间对偶性的广义模型和高效算法(二)
文章目录
- 6、针对SSD模型的硬件高效算法
- 6.1、对角块
- 6.2、低秩块
- 6.3、计算成本
- 7、Mamba-2 架构
- 7.1、块设计
- 7.2、序列变换的多头模式
- 7.3、线性注意力驱动的SSD扩展
- 8、系统优化对于SSMs
- 8.1、张量并行
- 8.2、序列并行性
- 8.3、可变长度
- 9、实证验证
- 9.1、合成任务:联想记忆
- 9.2、语言建模
- 9.2.1、缩放定律
- 9.2.3、混合模型:将SSD层与MLP和注意力层结合
- 9.3、速度基准测试
- 9.4、架构消融实验
- 9.4.1、块设计
- 9.4.3 注意力核近似
- 10、相关工作和讨论
- 10.1、状态空间模型
- 10.2、结构化矩阵
- 10.3、(线性)注意力
- 10.4、相关模型
- 11、结论
- A 词汇表
- B、针对标量SSM扫描的高效算法(1-SS乘法)
- B.1、问题定义
- B.2、经典算法
- B.2.1、顺序递归
- B.2.2、并行结合扫描
- B.3、通过结构化矩阵分解的高效算法
- B.3.1、膨胀模式
- B.3.3、完全递归模式
- B.3.4 (并行)块分解模式
- B.3.5、关联扫描模式
- C、理论细节
- C.1、附加内容:SSM的封闭性质
- C.2、自回归掩码注意力是半可分结构的注意力
- D、实验细节
- D.1、MQAR 细节
- D.2、缩放定律细节
- D.3、下游评估细节
- D.4、消融实验细节
6、针对SSD模型的硬件高效算法
在SSM、注意力和结构化矩阵之间开发理论SSD框架的好处在于,可以利用这些联系来改进模型和算法。在本节中,我们将展示如何从计算结构化矩阵乘法的各种算法中推导出计算SSD模型的高效算法。
我们的主要计算结果是一个用于计算SSD模型的算法,该算法结合了线性(递归)模式和二次(注意力)模式。这个算法在计算效率上与SSM(序列长度的线性缩放)相当,同时在硬件友好性上与注意力机制(主要使用矩阵乘法)相当。
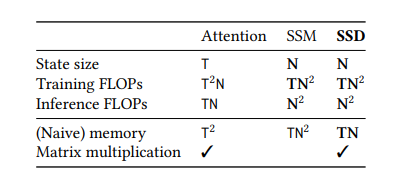
定理6.1. 考虑一个具有状态扩展因子 N \mathrm{N} N和头维度 P = N \mathrm{P}=\mathrm{N} P=N的SSD模型。存在一个算法,用于在任意输入 X ∈ R ( T , P ) X \in \mathbb{R}^{(\mathrm{T}, \mathrm{P})} X∈R(T,P)上计算该模型,该算法仅需要 O ( T N 2 ) O\left(\mathrm{TN}^{2}\right) O(TN2)的训练FLOPs(浮点运算次数), O ( T N ) O(\mathrm{TN}) O(TN)的推理FLOPs, O ( N 2 ) O\left(\mathrm{~N}^{2}\right) O( N2)的推理内存,并且其工作主要由矩阵乘法主导。
请注意,所有这些界限都是紧的,因为在一个状态空间模型中,当状态扩展为 N N N且操作的头大小为 N N N时,总状态大小为 N 2 N^2 N2(分别产生了训练和推理浮点运算次数(FLOPs)的下界 O ( T N 2 ) O(TN^2) O(TN2)和 O ( N 2 ) O(~N^2) O( N2))。此外,输入 X X X本身有 T N TN TN个元素,这产生了内存下界。
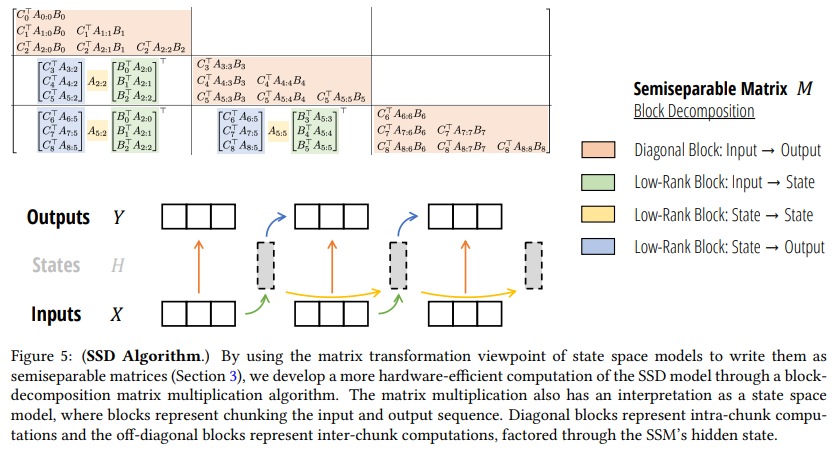
定理6.1背后的主要思想是将计算状态空间模型的问题视为半可分离矩阵乘法,但以一种新的方式利用它的结构。我们不是以递归模式或注意力模式计算整个矩阵,而是对矩阵进行块分解。对角块可以使用双注意力模式计算,这可以通过矩阵乘法高效地完成,而非对角块可以通过半可分离矩阵的秩结构进行分解,并简化为一个较小的递归。我们强调,列表1提供了SSD算法的一个自包含实现。与Gu和Dao(2023)的一般选择性SSM相比,这个实现更为简单,即使在原生的PyTorch中也是相对高效的,不需要特殊的底层内核。
首先,我们将矩阵 M M M划分为大小为 Q × Q Q \times Q Q×Q的子矩阵网格,网格的大小为 I Q × I Q \frac{I}{Q} \times \frac{I}{Q} QI×QI,其中 Q Q Q是某个块大小。注意,由于半可分离矩阵的定义特性(定义3.1),非对角块是低秩的。 5 {}^{5} 5

这可以通过一个例子来最简单地说明,例如当 T = 9 T=9 T=9时,我们将它分解为长度为 Q = 3 Q=3 Q=3的块。阴影单元格是半可分离矩阵非对角块的低秩分解。
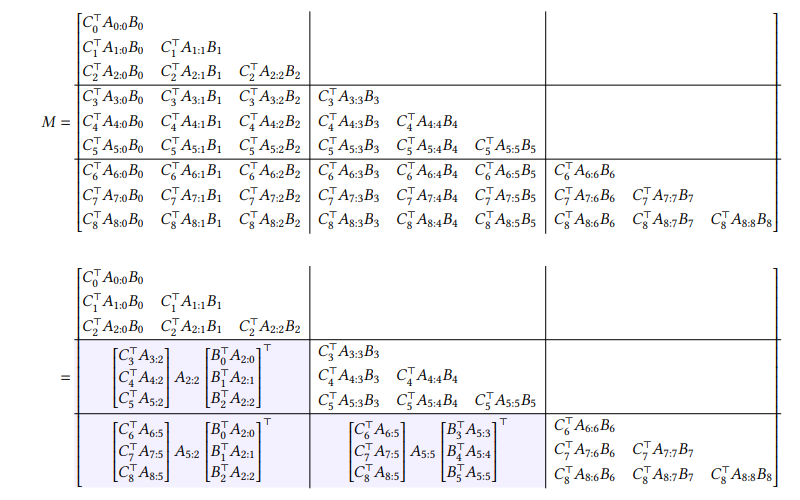
由此,我们可以将问题简化为这两部分。这也可以解释为将“块” y j Q : ( j + 1 ) Q y_{j Q:(j+1) Q} yjQ:(j+1)Q的输出分为两部分:块内输入 x j Q : ( j + 1 ) Q x_{j Q:(j+1) Q} xjQ:(j+1)Q的影响,以及块前输入 x 0 : j Q x_{0: j Q} x0:jQ的影响。
6.1、对角块
对角块很容易处理,因为它们只是较小规模的相似问题。第 j j j个块代表计算范围 R = j Q : ( j + 1 ) Q = ( j Q , j Q + 1 , … , j Q + Q − 1 ) R=j \mathrm{Q}:(j+1) \mathrm{Q}=(j \mathrm{Q}, j \mathrm{Q}+1, \ldots, j \mathrm{Q}+\mathrm{Q}-1) R=jQ:(j+1)Q=(jQ,jQ+1,…,jQ+Q−1)上的 SSM ( A R , B R , C R ) ( x R ) \operatorname{SSM}\left(A_{R}, B_{R}, C_{R}\right)\left(x_{R}\right) SSM(AR,BR,CR)(xR)的解。关键在于这个块可以使用任何期望的方法来计算。特别地,对于较短的块长度 Q \mathrm{Q} Q,这个问题使用双二次SMA形式来计算会更高效。此外,这些块可以并行计算。
这些子问题可以这样解释:如果每个块的初始状态为0,那么每个块的输出是什么?换句话说,对于第 j j j个块,这计算了仅考虑块输入 x j Q : ( j + 1 ) Q x_{j Q:(j+1) \mathrm{Q}} xjQ:(j+1)Q的正确输出。
6.2、低秩块
低秩分解由三个项组成,相应地,计算也由三个部分组成。在这种分解中,我们将使用以下术语:
- 像 [ B 0 ⊤ A 2 : 0 B 1 ⊤ A 2 : 1 B 2 ⊤ A 2 : 2 ] ⊤ \left[\begin{array}{c}B_{0}^{\top} A_{2: 0} \\ B_{1}^{\top} A_{2: 1} \\ B_{2}^{\top} A_{2: 2}\end{array}\right]^{\top} B0⊤A2:0B1⊤A2:1B2⊤A2:2 ⊤这样的项被称为右因子或 B B B块因子。
- 像 A 5 − 2 A_{5-2} A5−2这样的项被称为中心因子或 A A A块因子。
- 像 [ C 6 ⊤ A 6.5 C 7 ⊤ A 7.5 C 8 ⊤ A 8.5 ] \left[\begin{array}{c}C_{6}^{\top} A_{6.5} \\ C_{7}^{\top} A_{7.5} \\ C_{8}^{\top} A_{8.5}\end{array}\right] C6⊤A6.5C7⊤A7.5C8⊤A8.5 这样的项被称为左因子或 C C C块因子。
右因子。这一步计算低秩分解中右 B B B块因子的乘法。注意,对于每个块,这是一个 ( N , Q ) (\mathrm{N}, \mathrm{Q}) (N,Q)乘以 ( Q , P ) (\mathrm{Q}, \mathrm{P}) (Q,P)的矩阵乘法,其中 N \mathrm{N} N是状态维度, P \mathrm{P} P是头维度。结果是每个块的一个 ( N , P ) (\mathrm{N}, \mathrm{P}) (N,P)张量,其维度与展开的隐藏状态 h h h相同。
这可以解释为:假设每个块的初始状态为0,那么每个块的最终状态是什么。换句话说,这计算了 h j Q + Q − 1 h_{j Q+Q-1} hjQ+Q−1,假设 x 0 : j Q = 0 x_{0: j Q}=0 x0:jQ=0。
中心因子。这一步计算低秩分解中中心 A A A块因子项的影响。在前一步中,每个块的最终状态的总形状为 ( T / Q , N , P ) (\mathrm{T/Q}, \mathrm{N}, \mathrm{P}) (T/Q,N,P)。现在,它乘以由 A 2 Q − 1 : Q − 1 × , A 3 Q − 1 : 2 Q − 1 × , … , A T − 1 : T − Q − 1 × A_{2 Q-1: Q-1}^{\times}, A_{3 Q-1: 2 Q-1}^{\times}, \ldots, A_{\mathrm{T}-1: \mathrm{T}-\mathrm{Q}-1}^{\times} A2Q−1:Q−1×,A3Q−1:2Q−1×,…,AT−1:T−Q−1×生成的 1 − S S 1-\mathrm{SS} 1−SS矩阵。
这一步可以通过任何计算1-SS乘法(也称为标量SSM扫描或cumprodsum操作符)的算法来计算。
这可以解释为:考虑到所有先前的输入,每个块的实际最终状态是什么;换句话说,这计算了考虑到所有 x 0 : ( j + 1 ) Q x_{0:(j+1) Q} x0:(j+1)Q的真实隐藏状态 h j Q h_{j Q} hjQ。
左因子。这一步计算低秩分解中左 C C C块因子的乘法。对于每个块,这可以表示为一个矩阵乘法合约 ( Q N , N P → Q P ) (\mathrm{QN}, \mathrm{NP} \rightarrow \mathrm{QP}) (QN,NP→QP)。
这可以解释为:考虑到正确的初始状态 h j Q − 1 h_{j Q-1} hjQ−1,并假设输入 x j Q : ( j + 1 ) Q x_{j Q:(j+1) Q} xjQ:(j+1)Q为0,每个块的输出是什么。换句话说,对于块 j j j,这仅考虑先前的输入 x 0 : j Q x_{0:j Q} x0:jQ来计算正确的输出。
6.3、计算成本
我们定义符号 B M M ( B , M , N , K ) \mathrm{BMM}(\mathrm{B}, \mathrm{M}, \mathrm{N}, \mathrm{K}) BMM(B,M,N,K)来表示一个批处理矩阵乘法合约 ( M K , K N → M N ) (\mathrm{MK}, \mathrm{KN} \rightarrow \mathrm{MN}) (MK,KN→MN),其中B是批处理维度。从这个符号中,我们可以推断出效率的三个方面:
-
计算成本:总共需要 O ( B M N K ) O(\mathrm{B}\mathrm{MNK}) O(BMNK)次浮点运算(FLOPs)。
-
内存成本:总共需要 O ( B ( M K + K N + M N ) ) O(\mathrm{B}(\mathrm{MK}+\mathrm{KN}+\mathrm{MN})) O(B(MK+KN+MN))的空间。
-
并行化:较大的 M \mathrm{M} M, N \mathrm{N} N, K \mathrm{K} K项可以利用现代加速器上的专用矩阵乘法单元。
中心块。二次SMA(Self-Attention Matrix)计算的成本由三个步骤组成(见方程(16)):
- 计算核矩阵 C ⊤ B C^{\top} B C⊤B,其成本为 B M M ( T / Q , Q , Q , N ) \mathrm{BMM}(\mathrm{T} / \mathrm{Q}, \mathrm{Q}, \mathrm{Q}, \mathrm{N}) BMM(T/Q,Q,Q,N)。
- 与掩码矩阵相乘,这是一个在形状为(T/Q,Q,Q)的张量上进行的逐元素操作。
- 与 X X X值相乘,其成本为 B M M ( T / Q , Q , P , N ) \mathrm{BMM}(\mathrm{T} / \mathrm{Q}, \mathrm{Q}, \mathrm{P}, \mathrm{N}) BMM(T/Q,Q,P,N)。
低秩块:右因子。这一步是一个单一的矩阵乘法,其成本为 B M M ( T / Q , N , P , Q ) \mathrm{BMM}(\mathrm{T} / \mathrm{Q}, \mathrm{N}, \mathrm{P}, \mathrm{Q}) BMM(T/Q,N,P,Q)。
低秩块:中心因子。这一步是对 ( N , P ) (N,P) (N,P)独立通道上长度为 T / Q T/Q T/Q的标量SSM扫描(或1-SS乘法)。这个扫描的工作量是 T N P / Q TNP/Q TNP/Q,与其他因子相比是微不足道的。
请注意,由于分块操作将序列长度从 T T T减少到 T / Q T/Q T/Q,这个扫描的成本是纯SSM扫描(例如Mamba的选择性扫描)的 Q Q Q倍小。因此,我们观察到在大多数问题长度上,其他算法(附录B)可能更高效或更容易实现,而不会显著降低速度。例如,通过1-SS矩阵乘法来实现这一步的朴素实现具有 B M M ( 1 , T / Q , N P , T / Q ) \mathrm{BMM}(1, \mathrm{~T} / \mathrm{Q}, \mathrm{NP}, \mathrm{T} / \mathrm{Q}) BMM(1, T/Q,NP,T/Q)的成本,这更容易实现,并且可能比朴素的递归/扫描实现更高效。
低秩块:左因子。这一步是一个单一的矩阵乘法,其成本为 B M M ( T / Q , Q , P , N ) \mathrm{BMM}(T/Q, Q,P,N) BMM(T/Q,Q,P,N)。
总成本。如果我们设置 N = P = Q \mathrm{N}=\mathrm{P}=\mathrm{Q} N=P=Q(换句话说,状态维度、头维度和分块长度是相等的),那么上述所有的BMM项都会变成 B M M ( T / N , N , N , N ) \mathrm{BMM}(T/N,N,N,N) BMM(T/N,N,N,N)。其计算特性如下:
- 总浮点运算次数为 O ( T N 2 ) O(\mathrm{TN}^{2}) O(TN2)。
- 总内存为 O ( T N ) O(\mathrm{TN}) O(TN)。
- 主要工作是在形状为 ( N , N ) (\mathrm{N}, \mathrm{N}) (N,N)的矩阵上进行矩阵乘法。
请注意,内存消耗很紧张;输入和输出 x , y x, y x,y的形状为 ( T , P ) = ( T , N ) (\mathrm{T}, \mathrm{P})=(\mathrm{T}, \mathrm{N}) (T,P)=(T,N)。同时,浮点运算次数反映了额外的 N \mathrm{N} N因子,这是由自回归状态大小产生的成本,并且是所有模型共有的。
除了矩阵乘法之外,还有一个在 N P = N 2 \mathrm{NP}=\mathrm{N}^{2} NP=N2个特征和序列长度 T / Q \mathrm{T} / \mathrm{Q} T/Q上的标量SSM扫描。这个扫描的成本是 O ( T / Q N 2 ) O\left(\mathrm{~T} / \mathrm{Q} \mathrm{N}^{2}\right) O( T/QN2)次浮点运算(FLOPs)和 O ( log ( T / Q ) ) O(\log (\mathrm{T} / \mathrm{Q})) O(log(T/Q))的深度。尽管它不利用矩阵乘法,但它仍然是可并行的,并且与其他步骤相比,总工作量是可以忽略不计的;在我们的GPU实现中,这一步的成本也是可以忽略不计的。
与纯SSM和注意力模型的比较。二次注意力模型也非常硬件高效,仅利用矩阵乘法,但总浮点运算次数为 T 2 N \mathrm{T}^{2} N T2N。它在训练和推理时较慢的计算速度可以直接看作是状态大小较大的结果——标准注意力模型的状态大小随序列长度 T T T而缩放,因为它缓存了历史记录并且不压缩其状态。
线性SSM具有 T N P = T N 2 \mathrm{TNP}=\mathrm{TN}^{2} TNP=TN2的总浮点运算次数,这与SSD相同。然而,一个朴素的实现需要状态扩展(15a),这会占用额外的内存,以及一个标量操作(15b),它不利用矩阵乘法。
我们注意到,许多其他矩阵分解也是可能的(例如,见附录B,其中通过不同的结构化矩阵分解提供了1-SS乘法的算法汇编),这可能会导致更多针对SSD的算法,这些算法可能更适合其他特定设置。更广泛地说,我们注意到半可分离矩阵有着丰富的文献,除了我们使用的SSS形式(定义3.2)之外,还有更多的表示形式,甚至可能存在更高效的算法。
7、Mamba-2 架构
通过将SSM(选择性序列混合)和注意力机制相结合,SSD(选择性序列分解)框架允许我们为两者开发共享的词汇表和技术库。在本节中,我们将讨论一些使用最初为Transformer开发的想法来理解和修改SSD层的示例。我们讨论了几个设计选择,从而产生了Mamba-2架构。这些变化的维度在第9.4节中进行了消融实验。
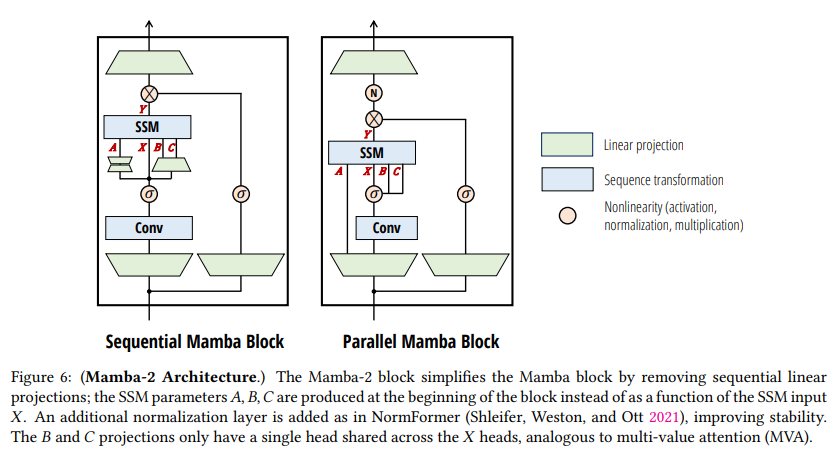
7.1、块设计
我们首先讨论与内部序列混合层(即SSD核心层之外)无关的神经网络块的修改。
并行参数投影。Mamba-1是基于SSM中心点的观点,将选择性SSM层视为从 X ↦ Y X \mapsto Y X↦Y的映射。SSM参数 A , B , C A, B, C A,B,C被视为辅助的,并且是SSM输入 X X X的函数。因此,定义 ( A , B , C ) (A, B, C) (A,B,C)的线性投影发生在创建 X X X的初始线性投影之后。
在Mamba-2中,SSD层被视为从 A , X , B , C ↦ Y A, X, B, C \mapsto Y A,X,B,C↦Y的映射。因此,在块的开始处使用单个投影并行生成 A , X , B , C A, X, B, C A,X,B,C是有意义的。注意这与标准注意力架构的类比,其中 X , B , C X, B, C X,B,C对应于并行创建的 Q , K , V Q, K, V Q,K,V投影。
请注意,为SSM的 A , B , C , X A, B, C, X A,B,C,X输入采用并行投影会稍微减少参数,更重要的是,通过使用标准的Megatron分片模式(Shoeybi et al. 2019),它更适应于大型模型的张量并行性。
在初步的实验中,我们发现在较大的模型中容易出现不稳定性。我们通过在最终输出投影之前的块中添加一个额外的归一化层(例如LayerNorm、GroupNorm或RMSNorm)来减轻这种不稳定性。这种归一化的使用与NormFormer架构(Shleifer, Weston, 和 Ott 2021)最为直接相关,NormFormer也在MLP(多层感知机)和MHA(多头注意力)块的末尾添加了归一化层。
我们还注意到,这一变化与从线性注意力视角衍生出来的其他近期模型类似,这些模型与Mamba-2相关。原始的线性注意力公式通过一个分母项进行归一化,这个分母项模拟了标准注意力中softmax函数的归一化。TransNormerLLM(Qin, Dong Li, 等人 2023)和RetNet(Y. Sun 等人 2023)发现这种归一化是不稳定的,因此在线性注意力层之后添加了一个额外的LayerNorm或GroupNorm。我们添加的额外归一化层与这些稍有不同,它出现在乘法门分支之后,而不是之前。
7.2、序列变换的多头模式
回顾一下,SSM(序列状态模型)被定义为一种序列变换(定义2.1),其中:
- 参数A、B、C具有状态维度 N \mathrm{N} N。
- 它们定义了一个序列变换 R T → R T \mathbb{R}^{\mathrm{T}} \rightarrow \mathbb{R}^{\mathrm{T}} RT→RT,例如可以表示为一个矩阵 M ∈ R ( T , T ) M \in \mathbb{R}^{(\mathrm{T}, \mathrm{T})} M∈R(T,T)。
- 这个变换在输入序列 X ∈ R ( T , P ) X \in \mathbb{R}^{(\mathrm{T}, \mathrm{P})} X∈R(T,P)上操作,且独立于 P \mathrm{P} P轴。
可以将这视为定义序列变换的一个头。
定义7.1(多头模式)。多头序列变换由 H \mathrm{H} H个独立的头组成,总模型维度为 D = d model \mathrm{D}=\mathrm{d}_\text{model} D=dmodel。这些参数可以在头之间共享,从而形成一个头模式。
状态大小 N \mathrm{N} N和头维度 P \mathrm{P} P分别与注意力的 Q K Q K QK头维度和 V V V头维度相对应。就像在现代Transformer架构中(Chowdhery等人 2023;Touvron, Lavril等人 2023),在Mamba-2中,我们通常选择这些维度为常数,大约在64或128左右;当模型维度D增加时,我们增加头的数量,同时保持头维度 N \mathrm{N} N和 P \mathrm{P} P不变。为了描述如何做到这一点,我们可以借鉴并推广多头注意力的想法,为SSM或任何一般的序列变换定义类似的模式。

多头SSM(MHS)/多头注意力(MHA)模式。经典的多头注意力(MHA)模式假设头维度 P \mathrm{P} P能够整除模型维度 D \mathrm{D} D。头的数量定义为 H = D / P \mathrm{H}=\mathrm{D} / \mathrm{P} H=D/P。然后,通过为每个参数创建 H \mathrm{H} H个独立的副本,来创建 H \mathrm{H} H个核心序列变换的副本。请注意,虽然MHA模式最初是为注意力序列变换描述的,但它可以应用于符合定义2.1的任何内容。例如,一个多头的SSM层将接受形状符合等式(17)的输入,其中SSM算法在 H = n heads \mathrm{H}=n_\text{heads} H=nheads维度上进行广播。
多收缩SSM(MCS)/多查询注意力(MQA)模式。多查询注意力(Shazeer 2019)是一种巧妙的注意力优化技术,可以显著提高自回归推理的速度,该技术依赖于缓存 K K K和 V V V张量。该技术简单地避免了给 K K K和 V V V增加额外的头维度,换句话说,就是在 Q Q Q的所有头上广播一个 ( K , V ) (K, V) (K,V)的单头。
利用状态空间对偶性,我们可以定义与MQA等效的SSM版本,如等式(18)所示。在这里, X X X和 B B B(SSM中对应于注意力的 V V V和 K K K)在所有 H \mathrm{H} H个头上共享。我们也称这为多收缩SSM(MCS)头模式,因为控制SSM状态收缩的 C C C参数在每个头上都有独立的副本。
我们可以类似地定义一个多键注意力(MKA)或多扩展SSM(MES)头模式,其中 B B B(控制SSM扩展)在每个头上是独立的,而 C C C和 X X X在头之间是共享的。
多输入SSM(MIS)/多值注意力(MVA)模式。虽然由于KV缓存的原因,MQA对于注意力来说是有意义的,但它并不是SSM的自然选择。在Mamba中, X X X被视为SSM的主要输入,因此 B B B和 C C C是跨输入通道共享的参数。我们在等式(20)中定义了一个新的多值注意力(MVA)或多输入SSM(MIS)模式,这同样可以应用于任何序列变换,如SSD。
有了这些术语,我们可以更精确地描述原始的Mamba架构。
命题7.2. Mamba架构(Gu和Dao 2023)中的选择性SSM(S6)层可以视为具有
- 头维度 P = 1 P=1 P=1:每个通道都有独立的SSM动态 A A A。
- 多输入SSM(MIS)或多值注意力(MVA)头结构: B B B、 C C C矩阵(在注意力对偶性中对应于 K K K、 Q Q Q)在输入 X X X(在注意力中对应于 V V V)的所有通道之间是共享的。
当这些头模式变体应用于SSD时(第9.4.3节),我们也可以进行消融实验。有趣的是,尽管在参数数量和总状态维度上进行了控制,但在下游性能上仍存在显著差异。我们通过实验发现,Mamba中最初使用的MVA模式表现最好。
分组头模式。多查询注意力的思想可以扩展到分组查询注意力(Ainslie等人2023):不是只有一个 K K K和 V V V头,而是可以创建 G G G个独立的 K K K和 V V V头,其中 1 < G 1<G 1<G且 G G G能整除 H H H。这是出于两个动机:缩小多查询注意力和多头注意力之间的性能差异,以及通过将 G G G设置为多个分片数的倍数来实现更有效的张量并行性(第8节)。
类似地,Mamba-2中使用的多输入SSM头模式可以很容易地扩展到分组输入SSM(GIS),或者同义地称为分组值注意力(GVA)。这种推广是直接的,为了简化起见,我们省略了具体细节。
7.3、线性注意力驱动的SSD扩展
这里我们描述了一个由线性注意力驱动的SSD架构修改的例子。我们在第9.4.3节中将其作为负面结果进行了消融实验,发现这些修改并没有显著提高性能到足以将它们作为默认设置的程度。然而,这些例子说明了如何将关于注意力的广泛文献整合到SSD的变体中。在Mamba-2架构中,我们将核特征映射的选择视为一个超参数,并期望其他由注意力机制启发的简单修改也是可能的。
核注意力对Softmax注意力的近似。许多线性注意力或核注意力的变体都基于将注意力得分softmax ( Q K ⊤ ) \left(Q K^{\top}\right) (QK⊤)视为由以下两部分组成的:
- 指数核 Z = exp ( Q K ⊤ ) Z=\exp \left(Q K^{\top}\right) Z=exp(QK⊤),它可以通过 Z = ψ ( Q ) ψ ( K ) ⊤ Z=\psi(Q) \psi(K)^{\top} Z=ψ(Q)ψ(K)⊤来近似,其中 ψ \psi ψ是某种核特征映射。
- 通过 M = G / ( G 1 ⊤ 1 ) M=G / (G \mathbf{1}^{\top} \mathbf{1}) M=G/(G1⊤1)对核进行归一化,使得行和为1,其中除法是按元素进行的, 1 \mathbf{1} 1是元素全为1的向量。
指数核特征映射。在Mamba-2中,我们引入了一个灵活的核特征映射,并将其应用于 B B B和 C C C分支(对应于注意力中的 K K K和 V V V分支)。为了简单和对称,特征映射也可以选择性地应用于 X ( V ) X(V) X(V)分支。这在图6中由一个任意非线性函数表示。默认情况下,我们简单地将 ψ \psi ψ选择为逐元素的Swish/SiLU函数(Hendrycks和Gimpel 2016;Ramachandran, Zoph, 和 Le 2017)。我们在第9.4.3节的消融实验中探索了其他选项,包括Linear Attention、Performer、Random Feature Attention和cosFormer(第4.1.3节)中使用的特征映射。
引入归一化(分母)项。为了找到分母项,我们只需要计算 M 1 M\mathbf{1} M1。但请注意,模型的最终输出只是 Y = M X Y = MX Y=MX(方程(16))。因此,归一化项可以简单地通过在 X X X中添加一个额外的全1列来找到,从而得到一个形状为 ( T , P + 1 ) (\mathrm{T}, \mathrm{P}+1) (T,P+1)的张量。
请注意,在这种情况下,核特征映射 ψ \psi ψ必须是正的,以便总和也是正的。
8、系统优化对于SSMs
我们描述了针对SSMs,特别是Mamba-2架构的几种系统优化,以实现大规模的高效训练和推理。特别地,我们关注于张量并行和序列并行以实现大规模训练,以及可变长度的序列以实现高效的微调和推理。
8.1、张量并行
张量并行(TP)(Shoeybi等人,2019)是一种模型并行技术,它将每一层(例如注意力层、MLP)拆分到多个加速器(如GPU)上运行。这种技术在GPU集群上训练大多数大型模型(Brown等人,2020;Chowdhery等人,2023;Touvron, Lavril等人,2023;Touvron, L. Martin等人,2023)时被广泛使用,其中每个节点通常有4-8个GPU,并且配备了如NVLink这样的快速网络。TP最初是为Transformer架构开发的,将其直接应用于其他架构并不简单。我们首先展示了在Mamba架构中使用TP的挑战,然后展示了如何设计Mamba-2架构以使其支持高效的TP。
回顾Mamba架构,它有一个单一输入 u ∈ R L × d u \in \mathbb{R}^{L \times d} u∈RL×d(为了简化,不考虑批次处理),输入投影矩阵 W ( x ) , W ( z ) ∈ R d × e d W^{(x)}, W^{(z)} \in \mathbb{R}^{d \times ed} W(x),W(z)∈Rd×ed,其中 e e e是扩展因子(通常取2),以及输出投影矩阵 W ( o ) ∈ R e d × d W^{(o)} \in \mathbb{R}^{ed \times d} W(o)∈Red×d:
x = u W ( x ) ⊤ ∈ R L × e d z = u W ( z ) ⊤ ∈ R L × e d x c = conv1d ( x ) ∈ R L × e d (depthwise, independent along d ) Δ , B , C = low-rank projection ( x c ) y = S S M A , B , C , Δ ( x c ) ∈ R L × e d (independent along d ) y g = y ⋅ ϕ ( z ) (gating, e.g., with ϕ being SiLU) out = y g W ( o ) ⊤ ∈ R L × d . \begin{aligned} x & =u W^{(x)^{\top}} \in \mathbb{R}^{L \times e d} \\ z & =u W^{(z)^{\top}} \in \mathbb{R}^{L \times e d} \\ x_{c} & =\operatorname{conv1d}(x) \in \mathbb{R}^{L \times e d} \quad \text { (depthwise, independent along } d \text { ) } \\ \Delta, B, C & =\text { low-rank projection }\left(x_{c}\right) \\ y & =S S M_{A, B, C, \Delta}\left(x_{c}\right) \in \mathbb{R}^{L \times e d} \quad \text { (independent along } d \text { ) } \\ y_{g} & =y \cdot \phi(z) \quad \text { (gating, e.g., with } \phi \text { being SiLU) } \\ \text { out } & =y_{g} W^{(o)^{\top}} \in \mathbb{R}^{L \times d} . \end{aligned} xzxcΔ,B,Cyyg out =uW(x)⊤∈RL×ed=uW(z)⊤∈RL×ed=conv1d(x)∈RL×ed (depthwise, independent along d ) = low-rank projection (xc)=SSMA,B,C,Δ(xc)∈RL×ed (independent along d ) =y⋅ϕ(z) (gating, e.g., with ϕ being SiLU) =ygW(o)⊤∈RL×d.
在使用张量并行(TP)时,假设我们想要将计算沿2个GPU进行拆分。可以很容易地将输入投影矩阵 W ( x ) W^{(x)} W(x)和 W ( z ) W^{(z)} W(z)各自拆分为大小为 d × e d 2 d \times \frac{ed}{2} d×2ed的两个部分。然后,每个GPU将持有大小为 L × e d 2 L \times \frac{ed}{2} L×2ed的 x c x_{c} xc的一半。然而,我们注意到由于 Δ , B , C \Delta, B, C Δ,B,C是 x c x_{c} xc的函数,因此在计算 Δ , B , C \Delta, B, C Δ,B,C之前,我们需要在GPU之间进行额外的全归约操作以获取完整的 x c x_{c} xc。在那之后,两个GPU可以并行计算SSM,因为它们在 d d d维度上是独立的。最后,我们可以将输出投影矩阵 W ( o ) W^{(o)} W(o)拆分为两个大小为 e d 2 × d \frac{ed}{2} \times d 2ed×d的部分,并在最后进行一次全归约操作。与Transformer相比,我们将需要两次全归约而不是一次,这将使通信时间加倍。对于大规模Transformer训练,通信可能已经占据了相当一部分时间(例如10-20%),因此加倍的通信会使Mamba在大规模训练中的效率降低。
在Mamba-2中,我们的目标是让每个块仅执行一次全归约操作,类似于Transformer中的注意力或MLP块。为此,我们从 u u u而不是 x c x_c xc直接投影得到 Δ , B , C \Delta, B, C Δ,B,C,这使得我们能够拆分这些投影矩阵。这意味着不同的GPU上会有不同的 Δ , B , C \Delta, B, C Δ,B,C集合,这相当于在更大的“逻辑GPU”上有多个“组”的 Δ , B , C \Delta, B, C Δ,B,C。此外,我们在每个块内使用GroupNorm,其组数可以被张量并行(TP)的度数整除,这样TP组内的GPU在块内就不需要通信。
具体过程如下:
x = u W ( x ) ⊤ ∈ R L × e d z = u W ( z ) ⊤ ∈ R L × e d Δ , B , C = projection ( u ) (每个GPU上一组或多组 Δ , B , C ) x c = conv1d ( x ) ∈ R L × e d (深度可分离卷积,在 d 维度上独立) y = SSM A , B , C , Δ ( x c ) ∈ R L × e d (在 d 维度上独立) y g = y ⋅ ϕ ( z ) (门控,例如使用SiLU作为 ϕ ) y n = groupnorm ( y g ) (组数可被张量并行度数整除) out = y n W ( o ) ⊤ ∈ R L × d . \begin{array}{l} x = u W^{(x)^{\top}} \in \mathbb{R}^{L \times ed} \\ z = u W^{(z)^{\top}} \in \mathbb{R}^{L \times ed} \\ \Delta, B, C = \text{projection}(u) \quad \text{(每个GPU上一组或多组}\Delta, B, C\text{)} \\ x_{c} = \text{conv1d}(x) \in \mathbb{R}^{L \times ed} \quad \text{(深度可分离卷积,在}d\text{维度上独立)} \\ y = \text{SSM}_{A, B, C, \Delta}(x_{c}) \in \mathbb{R}^{L \times ed} \quad \text{(在}d\text{维度上独立)} \\ y_{g} = y \cdot \phi(z) \quad \text{(门控,例如使用SiLU作为}\phi\text{)} \\ y_{n} = \text{groupnorm}(y_{g}) \quad \text{(组数可被张量并行度数整除)} \\ \text{out} = y_{n} W^{(o)^{\top}} \in \mathbb{R}^{L \times d} . \end{array} x=uW(x)⊤∈RL×edz=uW(z)⊤∈RL×edΔ,B,C=projection(u)(每个GPU上一组或多组Δ,B,C)xc=conv1d(x)∈RL×ed(深度可分离卷积,在d维度上独立)y=SSMA,B,C,Δ(xc)∈RL×ed(在d维度上独立)yg=y⋅ϕ(z)(门控,例如使用SiLU作为ϕ)yn=groupnorm(yg)(组数可被张量并行度数整除)out=ynW(o)⊤∈RL×d.
通过这种方式,我们能够在不增加全归约次数的情况下实现Mamba的并行化,从而提高了在大规模训练中的效率。
我们看到,我们只需要拆分输入投影矩阵和输出投影矩阵,并且仅在块的末尾执行全归约操作。这与为注意力和MLP层设计的张量并行(TP)相似。特别是,如果我们有TP度数为2,我们会将 W ( x ) = [ W 1 ( x ) , W 2 ( x ) ] W^{(x)}=\left[W_{1}^{(x)}, W_{2}^{(x)}\right] W(x)=[W1(x),W2(x)]拆分为 W i ( x ) ∈ R d × e d / 2 W_{i}^{(x)} \in \mathbb{R}^{d \times ed / 2} Wi(x)∈Rd×ed/2, W ( z ) = [ W 1 ( z ) , W 2 ( z ) ] W^{(z)}=\left[W_{1}^{(z)}, W_{2}^{(z)}\right] W(z)=[W1(z),W2(z)]拆分为 W i ( z ) ∈ R d × e d / 2 W_{i}^{(z)} \in \mathbb{R}^{d \times ed / 2} Wi(z)∈Rd×ed/2,以及 W ( o ) = [ W 1 ( o ) W 2 ( o ) ] W^{(o)}=\left[\begin{array}{l}W_{1}^{(o)} \\ W_{2}^{(o)}\end{array}\right] W(o)=[W1(o)W2(o)]拆分为 W i ( o ) ∈ R e d / 2 × d W_{i}^{(o)} \in \mathbb{R}^{ed / 2 \times d} Wi(o)∈Red/2×d。对于 i = 1 , 2 i=1,2 i=1,2,TP Mamba-2层可以写成:
x ( i ) = u W i ( x ) ⊤ ∈ R L × e d / 2 z ( i ) = u W i ( z ) ⊤ ∈ R L × e d / 2 Δ ( i ) , B ( i ) , C ( i ) = projection ( u ) (每个GPU上一组或多组 Δ , B , C ) x c ( i ) = conv1d ( x ( i ) ) ∈ R L × e d / 2 y ( i ) = S S M A , B , C , Δ ( x c ( i ) ) ∈ R L × e d / 2 y g ( i ) = y ( i ) ⋅ ϕ ( z ( i ) ) y n ( i ) = groupnorm ( y g ( i ) ) (组数可被张量并行度数整除) out ( i ) = y g ( i ) W i ( o ) ⊤ ∈ R L × d / 2 out = ∑ i out ( i ) (通过全归约将所有GPU的输出相加) \begin{aligned} x^{(i)} &= u W_{i}^{(x)^{\top}} \in \mathbb{R}^{L \times ed / 2} \\ z^{(i)} &= u W_{i}^{(z)^{\top}} \in \mathbb{R}^{L \times ed / 2} \\ \Delta^{(i)}, B^{(i)}, C^{(i)} &= \text{projection }(u) \quad \text{(每个GPU上一组或多组}\Delta, B, C\text{)} \\ x_{c}^{(i)} &= \text{conv1d}\left(x^{(i)}\right) \in \mathbb{R}^{L \times ed / 2} \\ y^{(i)} &= SSM_{A, B, C, \Delta}\left(x_{c}^{(i)}\right) \in \mathbb{R}^{L \times ed / 2} \\ y_{g}^{(i)} &= y^{(i)} \cdot \phi\left(z^{(i)}\right) \\ y_{n}^{(i)} &= \text{groupnorm}\left(y_{g}^{(i)}\right) \quad \text{(组数可被张量并行度数整除)} \\ \text{out}^{(i)} &= y_{g}^{(i)} W_{i}^{(o)^{\top}} \in \mathbb{R}^{L \times d / 2} \\ \text{out} &= \sum_{i} \text{out}^{(i)} \quad \text{(通过全归约将所有GPU的输出相加)} \end{aligned} x(i)z(i)Δ(i),B(i),C(i)xc(i)y(i)yg(i)yn(i)out(i)out=uWi(x)⊤∈RL×ed/2=uWi(z)⊤∈RL×ed/2=projection (u)(每个GPU上一组或多组Δ,B,C)=conv1d(x(i))∈RL×ed/2=SSMA,B,C,Δ(xc(i))∈RL×ed/2=y(i)⋅ϕ(z(i))=groupnorm(yg(i))(组数可被张量并行度数整除)=yg(i)Wi(o)⊤∈RL×d/2=i∑out(i)(通过全归约将所有GPU的输出相加)
我们在图7(左)中展示了Mamba-2的张量并行。
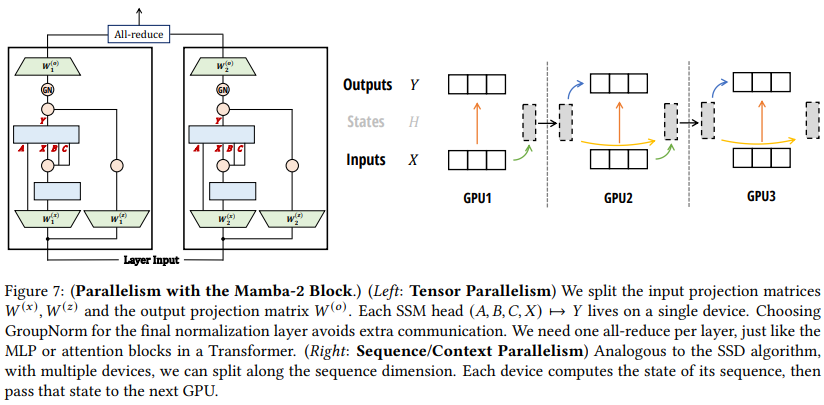
8.2、序列并行性
对于非常长的序列,我们可能需要沿着序列长度维度将输入和激活分配到不同的GPU上。主要有两种技术:
-
残差和归一化操作的序列并行性(SP):由Korthikanti等人(2023年)首次提出,该技术将TP中的全归约分解为归约散播(reduce-scatter)和全收集(all-gather)。注意到,在相同的TP组中,所有GPU都会对相同的输入执行残差和归一化操作,SP通过执行归约散播、残差和归一化,然后全收集,来沿着序列长度维度分割激活。
由于Mamba-2架构使用相同的残差和归一化结构,因此SP可以无修改地应用。 -
标记混合操作(注意力或SSM)的序列并行性,也称为“上下文并行性”(CP)。已经为注意力层开发了多种技术(例如,环形注意力(Liu, Yan等人 2024年;Liu, Zaharia和Abbeel 2023年)),其中使用了复杂的负载均衡技术(Brandon等人 2023年)。注意力中序列并行的难点在于,我们可以将查询和键分割成块,但每个查询块都需要与键块进行交互,导致通信带宽随工作节点数呈二次方增长。
对于SSM,我们可以以简单的方式分割序列:每个工作节点获取一个初始状态,根据它们的输入计算SSM,返回最终状态,并将该最终状态传递给下一个工作节点。通信带宽随工作节点数线性增长。这种分解与SSD算法(图5)中的块分解完全相同,即将序列分割成块/块段。我们在图7(右)中说明了这种上下文并行性。
8.3、可变长度
虽然预训练通常会在批次中使用相同的序列长度,但在微调或推理期间,模型可能需要处理不同长度的不同输入序列。一种简单处理这种情况的方法是,将批次中的所有序列右填充至最大长度,但如果序列长度差异很大,这种方法可能效率不高。对于变换器(Transformer),已经开发了复杂的技术来避免填充并在GPU之间进行负载均衡(Zeng等人 2022;Y. Zhai等人 2023),或者在同一批次中打包多个序列并调整注意力掩码(Ding等人 2024;Pouransari等人 2024)。对于SSM(状态空间模型)和特别是Mamba,我们可以通过将整个批次视为一个长序列来处理可变序列长度,并避免在单个序列之间传递状态。这等价于简单地设置 A t = 0 A_{t}=0 At=0,对于属于不同序列的标记 t t t,防止它将信息传递给标记 t + 1 t+1 t+1。
9、实证验证
我们通过在对于循环模型具有挑战性的合成回忆任务(第9.1节)以及标准语言建模预训练和下游评估(第9.2节)上实证评估Mamba-2。我们验证了我们的SSD算法比Mamba-1更加高效(第9.3节),并且对于中等序列长度,其效率与优化后的注意力机制相当。最后,我们对Mamba-2架构中的各种设计选择进行了消融实验(第9.4节)。
9.1、合成任务:联想记忆
合成联想记忆任务已经广泛用于测试语言模型在其上下文中查找信息的能力。大体上,这些任务包括向自回归模型输入成对的键值关联,然后提示模型在展示之前见过的键时产生正确的补全。多查询联想记忆(MQAR)任务是这种任务的一个特定形式,要求模型记住多个关联(Arora, Eyuboglu, Timalsina等人 2024)。原始的Mamba论文报告了与合成任务相关的结果,特别是选择性复制(Gu和Dao 2023)和归纳头(Induction Heads)(Olsson等人 2022),这些任务可以视为更简单的联想记忆任务。MQAR任务也与“电话簿查找”任务密切相关,后者已被证明对SSM(状态空间模型)等循环模型来说是一个挑战,因为它们的状态容量有限(De等人 2024;Jelassi等人 2024)。
我们与(Arora, Eyuboglu, Zhang等人 2024)中的MQAR设置的更具挑战性版本进行了比较,使用了更困难的任务、更长的序列和更小的模型。我们的基线包括标准的多头softmax注意力以及结合了卷积、局部注意力和线性注意力变种的Based架构。
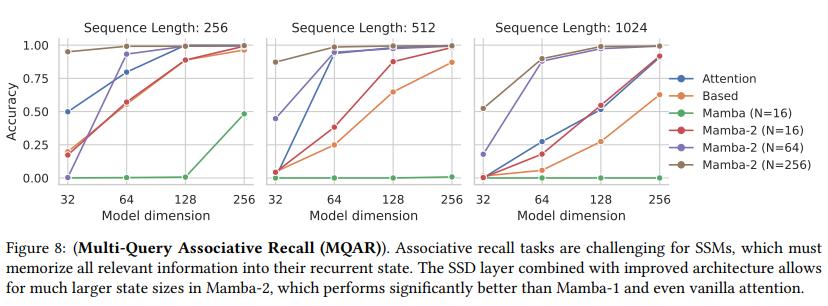
结果如图8所示。虽然Mamba-1在这个任务上表现挣扎,但Mamba-2在所有设置下都表现良好。令人惊讶的是,即使在控制状态大小( N = 16 \mathrm{N}=16 N=16)的情况下,Mamba-2也显著优于Mamba-1。(我们不确定架构的哪个方面是主导因素,这仍是一个未来工作需要探索的问题。)此外,这项任务验证了状态大小的重要性:从 N = 16 \mathrm{N}=16 N=16增加到 N = 64 \mathrm{N}=64 N=64和 N = 256 \mathrm{N}=256 N=256,MQAR的性能始终得到改善,因为更大的状态允许记住更多的信息(键值对)。
9.2、语言建模
遵循大型语言模型(LLMs)的标准协议,我们在标准自回归语言建模任务上训练和评估Mamba-2架构,并与其他架构进行比较。我们比较了预训练指标(困惑度)和零次学习评估。模型的大小(深度和宽度)遵循GPT3的规格,从 125 m 125 \mathrm{~m} 125 m到2.7B。我们使用Pile数据集(L. Gao, Biderman等人 2020),并遵循Brown等人(2020)描述的训练配方。这与Mamba(Gu和Dao 2023)中报告的设置相同;训练细节见附录D。
9.2.1、缩放定律
对于基线,我们与Mamba及其Transformer++配方(Gu和Dao 2023)进行比较,后者基于PaLM和LLaMa架构(例如,旋转嵌入、SwiGLU MLP、RMSNorm代替LayerNorm、无线性偏置和更高的学习率)。由于Mamba已经证明其性能优于标准的Transformer架构(GPT3架构)以及最近的次二次架构(H3(Dao, D. Y. Fu等人 2023)、Hyena(Poli等人 2023)、RWKV-4(B. Peng, Alcaide等人 2023)、RetNet(Y. Sun等人 2023)),为了清晰起见,我们在图中省略了这些基线(比较可见Gu和Dao 2023)。
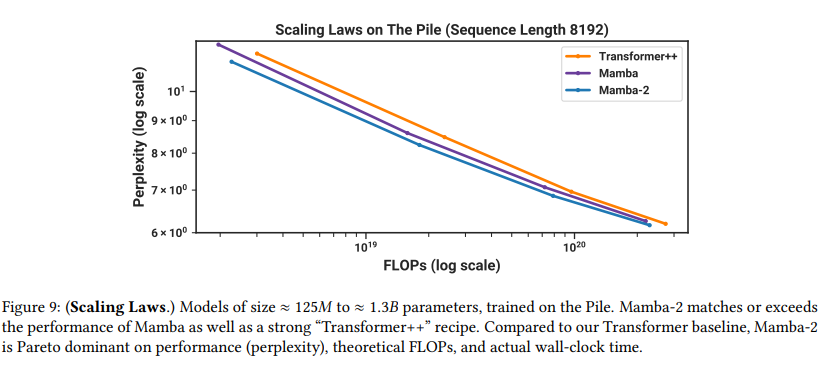
图9展示了在标准Chinchilla(Hoffmann等人 2022)协议下,从 ≈ 125 M \approx 125 \mathrm{M} ≈125M到 ≈ 1.3 B \approx 1.3 \mathrm{B} ≈1.3B参数的模型的缩放定律。
9.2.2 下游评估
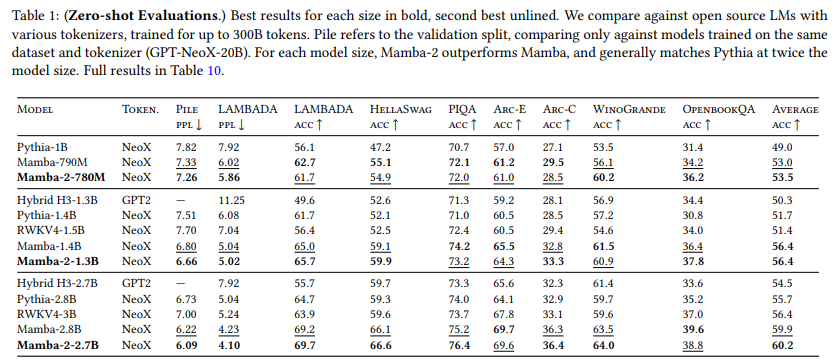
表1展示了Mamba-2在一系列流行的下游零次学习评估任务上的性能,与这些规模下最知名的开源模型进行了比较,最重要的是Pythia(Biderman等人 2023),该模型使用与我们的模型相同的分词器、数据集和训练长度(300B个标记)进行训练。
9.2.3、混合模型:将SSD层与MLP和注意力层结合
最近和同时期的工作(Dao, D. Y. Fu等人 2023;De等人 2024;Glorioso等人 2024;Lieber等人 2024)表明,具有SSM层和注意力层的混合架构可能在模型质量上优于Transformer或纯SSM(例如,Mamba)模型,特别是在上下文学习方面。我们探索了SSD层与注意力和MLP相结合的不同方式,以了解每种方式的益处。经验上我们发现,大约 10 % 10\% 10%的总层数是注意力层时性能最佳。将SSD层、注意力层和MLP结合使用也比纯Transformer++或Mamba-2表现更好。

SSD和注意力层 我们发现SSD和注意力层是互补的:单独使用时(例如在Mamba-2架构与Transformer++之间),它们的性能(通过困惑度来衡量)几乎相同,但SSD和注意力层的混合表现优于纯Mamba-2或Transformer++架构。我们展示了一些结果(表2)用于 350 M 350 \mathrm{M} 350M模型(48层),在Pile数据集上使用GPT-2分词器训练至 7 B 7 \mathrm{~B} 7 B标记(相同的参数数量、相同的超参数、相同的训练和验证集)。仅仅添加几个注意力层就已经带来了显著的改进,并在质量和效率之间取得了最佳平衡。我们假设SSM层作为一般的序列到序列映射功能表现良好,而注意力层则充当一种检索机制,以便快速引用序列中的先前标记,而不是强迫模型将所有上下文压缩到其内存中(SSM状态)。
具有SSD、MLP和注意力的混合模型 我们比较了SSD与(门控)MLP和注意力层结合的不同方式,并在2.7B规模(64层)上进行了评估,该模型在Pile数据集上训练至 300 B 300 \mathrm{~B} 300 B标记(相同的参数数量、相同的超参数、相同的训练和验证集、相同的数据顺序):
- Transformer++:32个注意力层和32个门控MLP层,交替排列。
- Mamba-2:64个SSD层。
- Mamba-2-MLP:32个SSD层和32个门控MLP层,交替排列。
- Mamba-2-Attention:58个SSD层和6个注意力层(位于索引9,18,27,36,45,56)^6。
- Mamba-2-MLP-Attention:28个SSD层和4个注意力层,与32个门控MLP层交替排列。
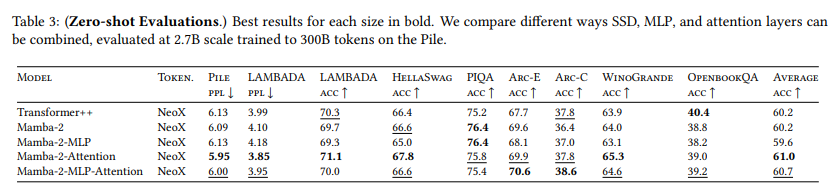
我们在表3中报告了在Pile验证集上的困惑度以及零次学习评估的结果。总体来说,Transformer++和Mamba-2模型的质量大致相同。我们观察到,仅仅添加6个注意力层就显著优于纯Mamba-2模型(也优于Transformer++)。添加MLP层会降低模型质量,但可以(i)由于MLP层的简单性和硬件效率而加速训练和推理(ii)通过用混合专家替换MLP层来更容易地升级到MoE模型。
9.3、速度基准测试
我们对SSD算法与Mamba的扫描实现以及FlashAttention-2进行了速度基准测试(如图10所示)。SSD通过重新设计使用矩阵乘法作为子程序,可以利用GPU上的专用矩阵乘法(matmul)单元,也称为张量核心。因此,它比不利用matmul单元的Mamba融合关联扫描快2-8倍。由于SSD在序列长度上的线性扩展,从序列长度 2 K 2K 2K开始,SSD比FlashAttention-2更快。
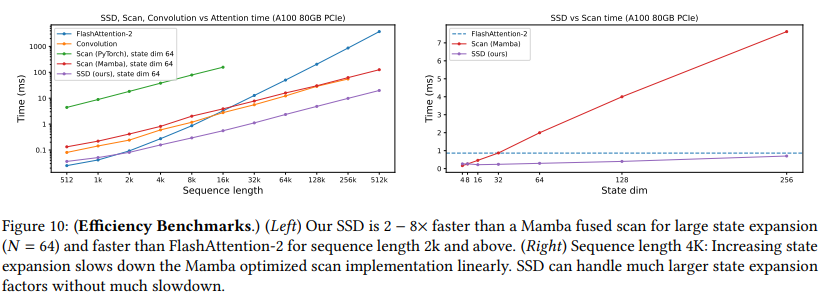
然而,我们注意到,对于较短的序列长度(例如 2 K 2K 2K),Mamba-2模型整体上的训练效率可能不如Transformer。因为一个拥有 L L L层的Transformer会有 L 2 \frac{L}{2} 2L个MLP层和 L 2 \frac{L}{2} 2L个注意力层,而具有相同参数数量的Mamba-2模型会有 L L L个SSD层。一般来说,MLP层由于只包含简单的矩阵乘法和逐点线性性,因此在硬件上非常高效。如第9.2.3节所示,也可以将 L 2 \frac{L}{2} 2L个SSD层和 L 2 \frac{L}{2} 2L个MLP层结合起来,以在较短的序列长度上加速训练。
9.4、架构消融实验
9.4.1、块设计
第7.1节介绍了Mamba-2块,它对Mamba-1块进行了一些小的修改,这些修改部分上受到与注意力机制的联系的启发,同时也为了提高Mamba-2的可扩展性。表4对这些块架构的变更进行了消融实验,这些变更发生在核心SSM层之外。

消融实验验证了并行投影以创建 ( A , B , C , X ) (A, B, C, X) (A,B,C,X)可以节省参数,并且比Mamba的顺序投影稍微表现得更好。更重要的是,这种修改适用于更大模型规模下的张量并行性(第8节)。此外,额外的归一化层也稍微提高了性能。更重要的是,在更大规模上的初步实验观察到,它还有助于提高训练稳定性。
9.4.2 头结构
第7.2节描述了如何将 B , C , X B, C, X B,C,X投影的维度视为类似于多头注意力和多查询注意力的超参数。我们还展示了原始的Mamba架构如何类似于多值注意力(命题7.2),这是从状态空间模型的角度自然发展出来的一种选择,之前并未进行消融实验。
表5对Mamba-2架构中的多头结构选择进行了消融实验。令人惊讶的是,我们发现多值和多查询或多键头模式之间存在很大差异,尽管它们看起来非常相似。请注意,这并不是由总状态大小来解释的,因为对于所有这些模式,总状态大小都是相同的(等于HPN或头数、头维度和状态维度的乘积)。
我们还与 C , B , X C, B, X C,B,X(类似于 Q , K , V Q, K, V Q,K,V)头数相等的多头模式进行了比较。我们与标准的多头模式进行了比较,以及一个具有激进共享模式的版本,其中所有头只有1个头。请注意,在后一种情况下,模型仍然有 H \mathrm{H} H个不同的序列混合器 M M M,因为每个头仍然有不同的 A A A。在参数匹配的情况下,这些多头模式的表现相似,介于MVA(多值注意力)和MQA/MKA(多查询/多键注意力)模式之间。
9.4.3 注意力核近似
第7.3节指出,SSD(状态空间分解)可以与线性注意力文献中的思想相结合,如各种形式的核近似。我们在表6中消融了之前工作中提出的这些建议的几种变体。这些包括cosFormer(Qin, Weixuan Sun等人,2022年)、随机特征注意力(H. Peng等人,2021年)和正随机特征(Performer)(Choromanski等人,2021年)。
我们还对添加一个归一化项进行了消融,类似于标准注意力中softmax函数的分母。我们发现这给大多数变体带来了不稳定性,但对于ReLU激活函数 ψ \psi ψ稍微提高了性能。
表7还测试了最近提出的用于改进线性注意力的建议,这些建议涉及扩展特征维度(Based(Arora, Eyuboglu, Zhang等人,2024年)和ReBased(Aksenov等人,2024年))。这些线性注意力扩展旨在用二次近似来逼近exp核。ReBased还建议将 Q K \mathrm{QK} QK激活函数替换为层归一化;从SSM(状态空间模型)为中心的角度来看,我们在应用SSM函数之前在 ( B , C ) (B, C) (B,C)上应用归一化。
我们注意到,这项技术已被独立提出作为softmax注意力的“QK-Norm”(Team 2024年)和Mamba的“内部归一化”(Lieber等人,2024年)。
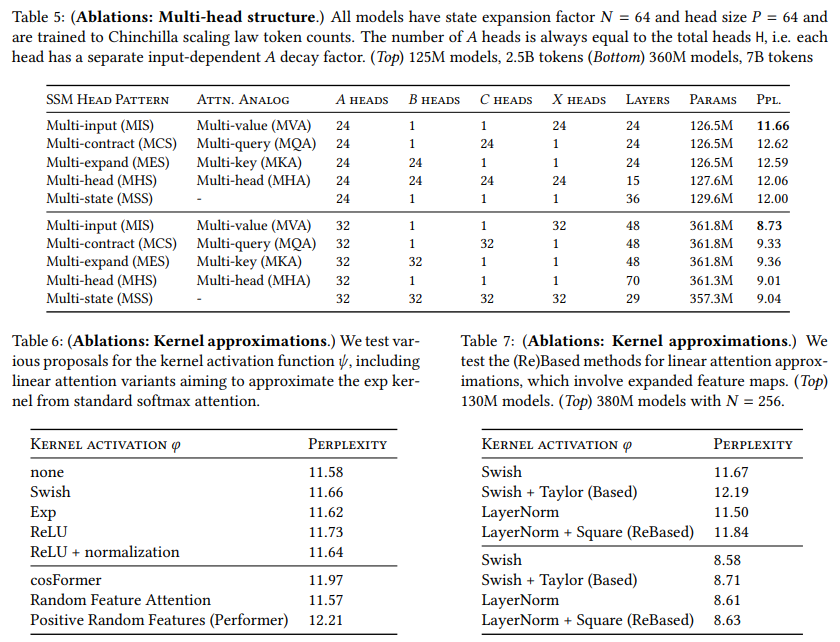
总体来说,表6和表7发现我们尝试的核近似方法似乎并没有比简单的逐点非线性激活函数 ψ \psi ψ有所改进。因此,对于Mamba-2,我们默认设置 ψ ( x ) = Swish ( x ) \psi(x)=\text{Swish}(x) ψ(x)=Swish(x)以遵循Mamba-1,但我们建议完全移除这个激活函数可能是一个我们没有广泛测试的更简单选择。
然而,我们强调SSD(状态空间分解)和纯线性注意力在是否包含1-半可分离掩码 L L L方面是不同的,而文献中的各种线性注意力方法是为了近似不包含这一项的softmax注意力而推导出来的;因此,我们的负面结果可能是可以预料的。
10、相关工作和讨论
状态空间对偶性框架在SSM(状态空间模型)、结构化矩阵和注意力之间建立了联系。我们更深入地讨论了SSD与这些概念之间的广泛关系。利用每个观点的思想,我们还提出了一些SSD框架在未来工作中可能扩展的方向。
10.1、状态空间模型
结构化状态空间模型可以根据以下维度进行描述:
(i) 它是时不变的还是时变的。
(ii) 系统的维度。
(iii) 递归转换 A A A上的结构。
SSD可以被描述为一个具有SISO(单输入单输出)维度和标量恒等结构的选择性SSM。
时间变化性(选择性)。原始的结构化SSM(S4)是线性时不变(LTI)系统(Gu 2023; Gu, Goel, and Ré 2022),其动机是连续时间的在线记忆(Gu, Dao, 等人 2020; Gu, Johnson, Goel, 等人 2021; Gu, Johnson, Timalsina, 等人 2023)。已经提出了许多结构化SSM的变体(Dao, D. Y. Fu, 等人 2023; Gu, Gupta, 等人 2022; Gupta, Gu, and Berant 2022; Ma 等人 2023; J. T. Smith, Warrington, and Linderman 2023),包括一些放弃递归并专注于LTI SSM的卷积表示的变体(D. Y. Fu 等人 2023; Y. Li 等人 2023; Poli 等人 2023; Qin, Han, Weixuan Sun, B. He, 等人 2023)。
SSD是一个时变的结构化SSM,也称为在Mamba中引入的选择性SSM(Gu and Dao 2023)。选择性SSM与RNN的门控机制密切相关,包括经典的RNN如LSTM(Hochreiter and Schmidhuber 1997)和GRU(J. Chung 等人 2014),以及更现代的变体如QRNN(Bradbury 等人 2016),SRU(Lei 2021; Lei 等人 2017),RWKV(B. Peng, Alcaide, 等人 2023),HGRN(Qin, Yang, and Zhong 2023),和Griffin(Botev 等人 2024; De 等人 2024)。这些RNN在参数化上有所不同,最重要的是它们没有状态扩展。
维度和状态扩展。SSD的一个重要特性,与其血统中的先前SSM(S4, H 3 H^3 H3,Mamba)相同,它是一个单输入单输出(SISO)系统,其中输入通道被独立处理。这导致了一个更大的有效状态大小 N D ND ND,其中 N N N是SSM状态大小(也称为状态扩展因子), D D D是标准模型维度。传统的RNN要么有 N = 1 N=1 N=1,要么是带有密集 B , C B, C B,C矩阵的多输入多输出(MIMO)系统,这两者都会导致较小的状态。虽然MIMO SSM在某些领域被证明是有效的(Lu 等人 2023; Orvieto 等人 2023; J. T. Smith, Warrington, 和 Linderman 2023),但Mamba表明,对于信息密集的领域(如语言)来说,状态扩展是至关重要的。SSD的主要优势之一是允许更大的状态扩展因子而不会减慢模型的速度。自此之后,许多后续工作都采用了状态扩展(第10.4节)。
结构。与先前的结构化SSM相比,SSD的主要限制在于状态转换 A t A_t At的表现力。我们注意到,更一般的SSM,如对角 A t A_t At的情况,在理论效率上与SSD相同,但不太适合硬件。这是因为对偶二次形式失去了类似注意力的解释,并且计算起来更加困难。因此,与Mamba相比,SSD仅在略微更限制性的对角 A t A_t At形式上有所不同,并以这种表现力为代价换取了更高的硬件效率(和实施的简便性)。
我们假设,可能可以通过改进我们的结构化矩阵算法来改进到一般的对角SSM情况。
10.2、结构化矩阵
状态空间对偶的第一个观点是将这些模型视为矩阵序列变换或“矩阵混合器”:可以表示为沿序列维度 T T T(通过 T × T T \times T T×T矩阵)进行矩阵乘法的序列变换(定义2.1)。
之前已经提出了几种这样的矩阵混合器,其中主要的变化轴是矩阵的表示。这些包括MLP-Mixer(Tolstikhin 等人 2021)(非结构化矩阵)、FNet(Lee-Thorp 等人 2021)(傅里叶变换矩阵)、M2(Dao, B. Chen, 等人 2022; Dao, Gu, 等人 2019; Dao, Sohoni, 等人 2020; D. Fu 等人 2024)(蝴蝶/帝王蝶矩阵)、Toeplitz矩阵(Poli 等人 2023; Qin, Han, Weixuan Sun, B. He, 等人 2023),以及更奇特的结构(De Sa 等人 2018; Thomas 等人 2018)。
一个重要的特点是,有效的(次二次)矩阵序列变换恰好是那些具有结构化矩阵混合器的变换。SSD框架的一个核心结果是将SSM视为具有特定结构——半可分离矩阵(第3节)——的矩阵混合器。线性与二次对偶的形式就变成了结构化矩阵乘法与朴素矩阵乘法。
结构化矩阵表示通过特定半可分离矩阵的块分解导致了我们高效的SSD算法(第6节)。我们注意到,科学计算文献中已经对半可分离矩阵进行了深入研究,将这些思想融入其中可能是对状态空间模型进行更多改进的有希望的途径。我们还建议,关注矩阵混合器的观点可以为序列模型带来更有成效的方向,例如设计Mamba的有原则的非因果变体,或者通过分析它们的矩阵变换结构来找到表征和弥合softmax注意力和次二次模型之间差距的方法。
10.3、(线性)注意力
与标准(因果)注意力相比,SSD只有两个主要区别。
首先,SSD不使用标准注意力中的softmax激活函数(Bahdanau, Cho, 和 Bengio 2015; Vaswani 等人 2017),这是注意力机制具有二次复杂度的原因。当去掉softmax时,序列可以通过线性注意力框架(Katharopoulos 等人 2020)实现线性缩放计算。
其次,SSD将logits矩阵乘以一个依赖于输入的1-半可分离掩码。因此,这个掩码可以看作是替换了标准注意力中的softmax。
这个半可分离掩码也可以看作是提供位置信息。元素 a t a_{t} at在RNN的意义上充当“门”的角色,或者是一个“选择”机制(参见Mamba论文中的讨论),而它们的累积乘积 a j : i a_{j:i} aj:i控制着位置 i i i和 j j j之间允许多少交互。位置嵌入(例如正弦波嵌入(Vaswani 等人 2017)、AliBi(Press, N. Smith, 和 Lewis 2022)以及RoPE(Su 等人 2021))是Transformers的重要组成部分,通常被视为启发式方法,而SSD的1-SS掩码可以被视为一种更有原则的相对位置嵌入形式。我们注意到,这一观点也同时由GateLoop(Katsch 2023)提出。
状态空间对偶的第二个观点是我们更一般的结构化掩码注意力(SMA)框架的一个特例,其中对偶性表现为简单四路张量收缩的不同收缩顺序。SMA是线性注意力的一个强大泛化,它比SSD更为通用;其他形式的结构化掩码可能导致具有与SSD不同属性的高效注意力的更多变体。
除了引导新模型的发展外,这些与注意力的联系还可以引导对SSM(结构化状态模型)理解的其他方向。例如,我们好奇对于Mamba模型是否存在“注意力陷阱”的现象(Darcet 等人 2024; Xiao 等人 2024),以及更广泛地,是否可以将可解释性技术转移到SSM上(Ali, Zimerman, 和 Wolf 2024)。
最后,已经提出了许多线性注意力的其他变体(Arora, Eyuboglu, Timalsina, 等人 2024; Arora, Eyuboglu, Zhang, 等人 2024; Choromanski 等人 2021; H. Peng 等人 2021; Qin, Han, Weixuan Sun, Dongxu Li, 等人 2022; Qin, Weixuan Sun, 等人 2022; Schlag, Irie, 和 Schmidhuber 2021; Zhang 等人 2024; Zheng, C. Wang, 和 Kong 2022)(参见第4.1.3节对其中一些的描述),我们预计许多技术可以转移到SSM上(例如第7.3节)。
我们强调,SSD并没有泛化标准的softmax注意力,或者对注意力核矩阵的任何其他变换,这些变换没有有限的特征映射 ψ \psi ψ。与一般的注意力相比,SSD的优势在于具有可控的状态扩展因子 N \mathrm{N} N,这可以压缩历史信息,相比于二次注意力中存储整个历史信息的缓存,其规模随序列长度 T ≫ N T \gg N T≫N增长。同时,已有工作开始研究这些表示之间的权衡,例如在复制和上下文学习任务中(Akyürek 等人 2024; Grazzi 等人 2024; Jelassi 等人 2024; Park 等人 2024)。我们注意到,Mamba-2在这些能力方面显著优于Mamba(例如,如第9.1节中MQAR结果所示),但仍有更多待理解的内容。
10.4、相关模型
我们最后强调了一系列最近和同期的研究工作,这些工作开发了与Mamba和Mamba-2非常相似的序列模型。
- RetNet(Y. Sun等人 2023)和TransNormerLLM(Qin, Dong Li等人 2023)使用衰减项而不是累积和来泛化线性注意力,并提出了双并行/循环算法以及混合的“分块”模式。这些算法可以被视为SSD的一个实例化,其中 A t A_{t} At是时不变的(对所有 t t t都是常数);在SMA解释中,掩码矩阵 L L L将是一个衰减矩阵 L i , j = γ i − j L_{i, j}=\gamma^{i-j} Li,j=γi−j。这些模型在架构上也存在各种差异。例如,由于它们是从以注意力为中心的角度推导出来的,它们保留了多头注意力(MHA)模式;而Mamba-2是从以SSM为中心的模式推导出来的,它保留了多值注意力(MVA)或多扩展SSM(MES)模式,我们展示了其优势(第9.4节)。
- GateLoop(Katsch 2023)同时提出了使用依赖于输入的衰减因子 A t A_{t} At,并开发了与SSD中相同的双二次形式,他们称之为“代理注意力”形式。
- 门控线性注意力(GLA)(Yang等人 2024)提出了一种具有数据依赖门控的线性注意力的变体,以及计算分块模式的高效算法和硬件感知实现。
- HGRN(Qin, Yang, 和 Zhong 2023)引入了一个具有输入依赖门控的RNN,它在HGRN2(Qin, Yang, Weixuan Sun等人 2024)中得到了改进,以纳入状态扩展。
- Griffin(De等人 2024)和RecurrentGemma(Botev等人 2024)展示了具有输入依赖门控的RNN与局部注意力相结合,可以与强大的现代Transformer相竞争。Jamba也展示了将Mamba与几层注意力相结合在语言建模任务上表现非常好(Lieber等人 2024)。
- xLSTM(Beck等人 2024)通过采用状态扩展的想法以及其他门控、归一化和稳定技术来改进xLSTM。
- RWKV(-4)(B. Peng, Alcaide等人 2023)是一种基于不同线性注意力近似的RNN(无注意力Transformer(S. Zhai等人 2021))。最近,它通过采用选择性和状态扩展的想法被改进为RWKV-5/6(Eagle和Finch)架构(B. Peng, Goldstein等人 2024)。
11、结论
我们基于研究充分的结构化矩阵类别,提出了一个理论框架,弥合了SSM和注意力变体之间的概念差距。这个框架为最近SSM(例如Mamba)如何在语言建模方面与Transformer表现相当提供了见解。此外,我们的理论工具通过连接双方的算法和系统进步,为改进SSM(以及潜在的Transformer)提供了新的想法。作为展示,该框架指导我们设计了SSM和结构化注意力交叉点的新架构(Mamba-2)。
致谢
我们感谢Angela Wu关于如何以数值稳定的方式高效计算 Δ \Delta Δ的梯度的建议。我们感谢Sukjun Hwang和Aakash Lahoti在MQAR实验中的协助。
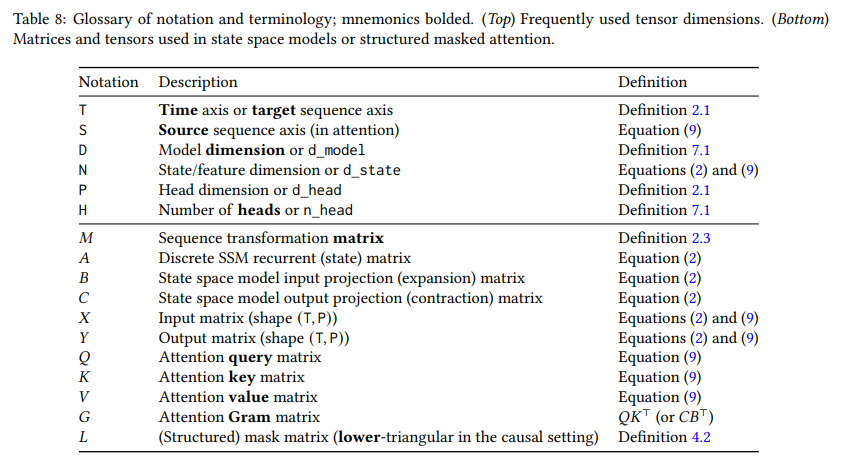
A 词汇表
B、针对标量SSM扫描的高效算法(1-SS乘法)
在本节中,我们将通过结构化矩阵分解的视角,详细阐述计算标量SSM扫描的各种算法。标量SSM扫描被定义为在计算离散SSM(7)的循环部分时,当 N = 1 N=1 N=1(即 A A A是一个标量)的情况。这通常用于递归计算SSM;特别地,当 A A A具有对角结构时,结构化SSM的情况就简化为这种操作,如S5(J. T. Smith, Warrington, and Linderman 2023)和S6(Gu and Dao 2023)模型。
本节的目标是支持本文的一个中心主题,即序列模型的高效算法可以视为结构化矩阵乘法算法。我们在这里展示的各种矩阵分解想法与用于推导快速SSM算法(第6节)的想法相关,同时也直接用作子程序。
B.1、问题定义
令 a : ( D , ) a: (D,) a:(D,)和 b : ( D , ) b: (D,) b:(D,)为标量序列。标量SSM扫描定义为
h t = a t h t − 1 + b t h_{t} = a_{t} h_{t-1} + b_{t} ht=atht−1+bt
这里 h − 1 h_{-1} h−1可以是一个任意值,代表SSM递归之前的隐藏状态;除非另有说明,我们假设 h − 1 = 0 h_{-1} = 0 h−1=0。
我们也称方程(21)为cumprodsum(累积乘积和)。请注意,当 b = 0 b=0 b=0是加法恒等元时,cumprodsum简化为cumprod(累积乘积),而当 a = 1 a=1 a=1是乘法恒等元时,它简化为cumsum(累积和)。
最后,请注意,在矢量化形式下,我们可以写为
h = M b M = [ 1 a 1 1 a 2 a 1 a 2 1 ⋮ ⋮ ⋱ ⋱ a T − 1 … a 1 a T − 1 … a 2 … a T − 1 1 ] \begin{aligned} h &= M b \\ M &= \left[\begin{array}{ccccc} 1 & & & & \\ a_{1} & 1 & & & \\ a_{2} a_{1} & a_{2} & 1 & & \\ \vdots & \vdots & \ddots & \ddots & \\ a_{T-1} \ldots a_{1} & a_{T-1} \ldots a_{2} & \ldots & a_{T-1} & 1 \end{array}\right] \end{aligned} hM=Mb= 1a1a2a1⋮aT−1…a11a2⋮aT−1…a21⋱…⋱aT−11
换句话说,这只是一个1-SS矩阵 M M M与向量 b b b的矩阵-向量乘积。
因此,我们有三种等价的视角来看待这个基本的原始操作:
- 一个(标量)SSM扫描。
- 一个cumprodsum(累积乘积和)。
- 一个1-SS矩阵-向量乘法。
B.2、经典算法
我们首先描述之前工作中使用的计算SSM扫描(21)的两种经典方法。
B.2.1、顺序递归
顺序递归模式只是简单地一次计算一个时间步 t t t的(21)。从1-SS乘法的角度来看,这在第3.4.1节中也进行了描述。
B.2.2、并行结合扫描
其次,一个重要的观察是,这个递归可以被转化为一个结合扫描(E. Martin 和 Cundy 2018; J. T. Smith, Warrington, 和 Linderman 2023)。这个事实并不完全显而易见。例如,S5定义了正确的结合扫描操作符,然后通过机械计算展示了操作符的结合性。
一个稍微更清晰的方法来看待这种计算是否可以通过结合扫描来实现,是将多项递归转化为一个大小为2(而非1)的隐藏状态的单项递归:
h t = a t h t − 1 + b t [ h t 1 ] = [ a t b t 0 1 ] [ h t − 1 1 ] . \begin{aligned} h_{t} &= a_{t} h_{t-1} + b_{t} \\ \left[\begin{array}{c} h_{t} \\ 1 \end{array}\right] &= \left[\begin{array}{cc} a_{t} & b_{t} \\ 0 & 1 \end{array}\right]\left[\begin{array}{c} h_{t-1} \\ 1 \end{array}\right] . \end{aligned} ht[ht1]=atht−1+bt=[at0bt1][ht−11].
然后计算所有的 h t h_{t} ht就等同于取这些 2 × 2 2 \times 2 2×2矩阵的累积乘积。由于矩阵乘法是结合的,这可以通过结合扫描来计算。这个结合二元操作符就是这些特定矩阵的矩阵乘法:
[ a t b t 0 1 ] [ a s b s 0 1 ] = [ a t a s a t b s + b t 0 1 ] . \left[\begin{array}{cc} a_{t} & b_{t} \\ 0 & 1 \end{array}\right]\left[\begin{array}{cc} a_{s} & b_{s} \\ 0 & 1 \end{array}\right]=\left[\begin{array}{cc} a_{t} a_{s} & a_{t} b_{s}+b_{t} \\ 0 & 1 \end{array}\right] . [at0bt1][as0bs1]=[atas0atbs+bt1].
将第一行等同起来就得到了与 S 5 \mathrm{S} 5 S5定义的相同的结合扫描操作符:
( a t , b t ) ⊗ ( a s , b s ) = ( a t a s , a t b s + b t ) . (a_{t}, b_{t}) \otimes (a_{s}, b_{s}) = (a_{t} a_{s}, a_{t} b_{s} + b_{t}) . (at,bt)⊗(as,bs)=(atas,atbs+bt).
结合扫描之所以重要,是因为它们可以使用分治算法进行并行化(Blelloch 1990)。我们省略了这个算法的细节,而是展示如何通过矩阵分解从头开始推导出整个结合SSM扫描算法(附录B.3.5)。
B.3、通过结构化矩阵分解的高效算法
我们讨论了几种计算SSM扫描的算法,这些算法都通过寻找1-SS矩阵 M M M的结构化矩阵分解来实现。这些算法或计算模式包括:
- 膨胀模式,其中信息每次以 1 , 2 , 4 , 8 , … 1,2,4,8,\ldots 1,2,4,8,…的步长传播。
- 状态传递模式,其中信息以块的形式向前传播。
- 完全递归模式,它每次递增一步,是状态传递模式的一个特例。
- 块分解并行模式,其中 M M M被分为层次化的块。
- 扫描模式,其中 M M M被分为大小相等的块,并递归地减少。
B.3.1、膨胀模式
这种模式通过特定的方式分解1-SS矩阵,涉及不断增加的“步长”。这最好通过一个具体的例子来说明:
(注:这里缺少具体的矩阵分解示例)
请注意,这非常类似于膨胀卷积的计算。
我们还注意到,这种分解表明1-SS矩阵是蝴蝶矩阵的一个特例,蝴蝶矩阵是另一种广泛且基本的结构化矩阵类型(Dao, Gu等人 2019;Dao, Sohoni等人 2020)。
备注8. 这种算法有时被描述为“工作效率不高但更易并行化”的前缀和算法(Hillis和Steele fr 1986),因为它使用了 O ( T log ( T ) ) O(T \log (T)) O(Tlog(T))次操作,但深度/跨度只有工作效率高的结合扫描算法的一半。
B.3.2 状态传递(分块)模式
这种模式可以被视为标准递归模式的一个泛化。在这种模式中,我们并不是每次只向前传递递归状态 h h h一步,而是在任意长度 k k k的块上计算结果,并通过块传递状态。这也可以从1-SS矩阵的简单块分解中推导出来。
备注9. 尽管我们称之为“状态传递”来指代状态如何从一个局部段传递到另一个局部段,但这与相关模型提出的“分块”算法是相关的(Y. Sun等人 2023;Yang等人 2024)。
考虑在“块”中计算 h = M b h=Mb h=Mb:对于某些索引 k ∈ [ T ] k \in[T] k∈[T],我们希望计算 h 0 − k h_{0-k} h0−k或直到索引 k k k的输出,并有一种方法将问题简化为索引 [ k : T ] [k: T] [k:T]上的较小问题。
我们将 M M M写为
M = [ a 0 : 0 a 1 : 0 a 1 : 1 ⋮ ⋱ a k − 1 : 0 … … a k − 1 : k − 1 a k : 0 … … a k : k − 1 a k : k ⋮ ⋮ ⋮ ⋱ a T − 1 : 0 … … a T − 1 : k − 1 a T − 1 : k … a T − 1 : T − 1 ] M=\left[\begin{array}{ccccccc} a_{0: 0} & & & & & & \\ a_{1: 0} & a_{1: 1} & & & & & \\ \vdots & & \ddots & & & & \\ a_{k-1: 0} & \ldots & \ldots & a_{k-1: k-1} & & & \\ a_{k: 0} & \ldots & \ldots & a_{k: k-1} & a_{k: k} & & \\ \vdots & & & \vdots & \vdots & \ddots & \\ a_{T-1: 0} & \ldots & \ldots & a_{T-1: k-1} & a_{T-1: k} & \ldots & a_{T-1: T-1} \end{array}\right] M= a0:0a1:0⋮ak−1:0ak:0⋮aT−1:0a1:1………⋱………ak−1:k−1ak:k−1⋮aT−1:k−1ak:k⋮aT−1:k⋱…aT−1:T−1
让左上三角形为 M L M_{L} ML,右下三角形为 M R M_{R} MR(左和右子问题),左下三角形为 M C M_{C} MC。同样地,将 b b b分为 b L = b 0 : k b_{L}=b_{0: k} bL=b0:k和 b R = b k : T b_{R}=b_{k: T} bR=bk:T。注意
M b = [ M L b L M R b R + M C b L ] Mb=\left[\begin{array}{c} M_{L} b_{L} \\ M_{R} b_{R}+M_{C} b_{L} \end{array}\right] Mb=[MLbLMRbR+MCbL]
此外, M C M_{C} MC具有秩-1分解(这本质上是半可分矩阵的定义性质)
M C = [ a k : k ⋮ a T − 1 : k ] a k [ a k − 1 : 0 ⋯ a k − 1 : k − 1 ] M_{C}=\left[\begin{array}{c} a_{k: k} \\ \vdots \\ a_{T-1: k} \end{array}\right] a_{k}\left[\begin{array}{ccc} a_{k-1: 0} & \cdots & a_{k-1: k-1} \end{array}\right] MC= ak:k⋮aT−1:k ak[ak−1:0⋯ak−1:k−1]
因此
M C b L = [ a k : k ⋮ a T − 1 : k ] a k ⋅ ( M b ) k − 1 . M_{C} b_{L}=\left[\begin{array}{c} a_{k: k} \\ \vdots \\ a_{T-1: k} \end{array}\right] a_{k} \cdot (Mb)_{k-1} . MCbL= ak:k⋮aT−1:k ak⋅(Mb)k−1.
在这里,我们将 ( M b ) k − 1 = h k − 1 (Mb)_{k-1}=h_{k-1} (Mb)k−1=hk−1视为左块的“最终状态”,因为 M C M_{C} MC分解中的行向量与 M L M_{L} ML的最后一行相同。此外,请注意 M C M_{C} MC分解中的列向量与 M R M_{R} MR的最后一列相同。因此
M R b R + M C b L = M R [ a k h k − 1 + b k b k + 1 ⋮ b T − 1 ] M_{R} b_{R}+M_{C} b_{L}=M_{R}\left[\begin{array}{c} a_{k} h_{k-1}+b_{k} \\ b_{k+1} \\ \vdots \\ b_{T-1} \end{array}\right] MRbR+MCbL=MR akhk−1+bkbk+1⋮bT−1
最后,我们观察到 M L M_{L} ML和 M R M_{R} MR与原始矩阵 M M M是自相似的;这两个较小的1-SS矩阵乘法的答案可以使用任何算法任意计算。总的来说,算法按照以下步骤进行:
- 使用任何期望的方法(即本节中任何用于1-SS乘法的方法)计算答案的左半部分 h 0 : k h_{0: k} h0:k。
- 计算最终状态 h k − 1 h_{k-1} hk−1。
- 通过一步增加状态来修改 b k b_{k} bk。
- 使用任何期望的方法计算答案的右半部分 h k : T h_{k: T} hk:T。
换句话说,我们将左子问题视为一个黑盒,将其最终状态传递给右问题,并将右子问题视为一个黑盒进行计算。
这种方法的实用性来自于更复杂的设置,例如在一般的 N N N-半可分情况下,以及当输入 b b b具有额外的“批次”维度时(或者换句话说,这是矩阵-矩阵乘法而不是矩阵-向量乘法)。在这种情况下,我们可以为块(对应于通过 M L M_{L} ML和 M R M_{R} MR的矩阵乘法)使用一种替代算法,该算法不会具体化完整的隐藏状态 h h h。相反,我们跳过隐藏状态,以另一种方式直接计算最终状态 h k − 1 h_{k-1} hk−1,然后将状态“传递”给下一个块。
复杂度。这种方法可以非常高效,因为步骤2-3只需要常数时间。因此,假设两个子问题(步骤1和4)是线性时间的,整个方法也是线性时间的。
缺点是这也是顺序的。
B.3.3、完全递归模式
请注意,完全递归模式,其中递归是按步骤发展的(21),实际上是状态传递模式的一个实例,其块大小为 k = 1 k=1 k=1。
B.3.4 (并行)块分解模式
这与状态传递模式使用相同的矩阵分解,但以不同的顺序计算子问题,从而在计算和并行化之间进行权衡。
我们通常将 M M M写作
M = [ 1 a 1 1 a 2 a 1 a 2 1 ⋮ ⋮ ⋱ ⋱ a T − 1 … a 1 a T − 1 … a 2 … a T − 1 1 ] = [ 1 − a 1 1 0 − a 2 1 ⋮ ⋮ ⋱ ⋱ 0 0 … − a T − 1 1 ] M=\left[\begin{array}{ccccc} 1 & & & & \\ a_{1} & 1 & & & \\ a_{2} a_{1} & a_{2} & 1 & & \\ \vdots & \vdots & \ddots & \ddots & \\ a_{T-1} \ldots a_{1} & a_{T-1} \ldots a_{2} & \ldots & a_{T-1} & 1 \end{array}\right]=\left[\begin{array}{ccccc} 1 & & & & \\ -a_{1} & 1 & & & \\ 0 & -a_{2} & 1 & & \\ \vdots & \vdots & \ddots & \ddots & \\ 0 & 0 & \ldots & -a_{T-1} & 1 \end{array}\right] M= 1a1a2a1⋮aT−1…a11a2⋮aT−1…a21⋱…⋱aT−11 = 1−a10⋮01−a2⋮01⋱…⋱−aT−11
关键的观察再次是 M M M的左下角是秩为1的。除了直接观察外,另一种方法是使用右侧矩阵(RHS),观察到其左下角是一个简单的秩为1的矩阵(除了右上角是 − a T / 2 -a_{T/2} −aT/2外,其余都是0),并使用Woodbury逆矩阵公式来看出左侧矩阵(LHS)的左下角也必须是秩1。这也提供了一种推导秩1分解的方法,可以通过检查来验证:
M lower-left-quadrant = [ ( a T / 2 … a 1 ) … a T / 2 ⋮ ⋱ ⋮ ( a T − 1 … a T / 2 a T / 2 − 1 … a 1 ) … ( a T − 1 … a T / 2 ) ] = [ a T / 2 ⋮ a T − 1 … a T / 2 ] [ ( a T / 2 − 1 … a 1 ) … a T / 2 − 1 1 ] . \begin{array}{l} M_{\text{lower-left-quadrant }}=\left[\begin{array}{ccc} \left(a_{T / 2} \ldots a_{1}\right) & \ldots & a_{T / 2} \\ \vdots & \ddots & \vdots \\ \left(a_{T-1} \ldots a_{T / 2} a_{T / 2-1} \ldots a_{1}\right) & \ldots & \left(a_{T-1} \ldots a_{T / 2}\right) \end{array}\right] \\ =\left[\begin{array}{c} a_{T / 2} \\ \vdots \\ a_{T-1} \ldots a_{T / 2} \end{array}\right]\left[\begin{array}{lllll} \left(a_{T / 2-1} \ldots a_{1}\right) & \ldots & a_{T / 2-1} & 1 \end{array}\right] . \end{array} Mlower-left-quadrant = (aT/2…a1)⋮(aT−1…aT/2aT/2−1…a1)…⋱…aT/2⋮(aT−1…aT/2) = aT/2⋮aT−1…aT/2 [(aT/2−1…a1)…aT/2−11].
第二个观察是这个矩阵是自相似的:任何主子矩阵都具有相同的形式。特别是,左上角和右下角两个象限都是1-SS矩阵。
这提供了一种容易的方式来执行矩阵 M M M的乘法:并行地递归处理两个半部分(即左上角和右下角),然后考虑左下角子矩阵。在分治算法中的“组合”步骤很容易,因为子矩阵的秩为1。这导致了一个并行算法。
复杂度。与状态传递算法类似,这种方法使用了秩结构化半可分矩阵的相同块分解。不同之处在于我们并行递归处理两个子问题,而状态传递算法则是先处理左子问题再处理右子问题。这降低了算法的深度/跨度,从线性降低到 log ( T ) \log (T) log(T)。然而,这种权衡是组合步骤(考虑秩为1的左下角子矩阵)需要线性而非常数工作,因此总工作量为 O ( T log ( T ) ) O(T \log (T)) O(Tlog(T))而非线性。
还值得注意的是,在递归中,我们可以随时停止并以其他方式计算子问题。这是SSD算法(第6节)背后的主要思想,其中我们在小的子问题上切换到对偶二次注意力公式。
B.3.5、关联扫描模式
状态传递(分块)算法具有线性工作量,但也涉及顺序操作。
块矩阵约简和膨胀模式是可并行的:它们具有 log ( T ) \log (T) log(T)的深度/跨度。然而,它们做了额外的工作( O ( T log ( T ) ) O(T \log (T)) O(Tlog(T)))。如附录B.2.2所述,有一种算法通过利用关联扫描(也称为前缀扫描)算法(Baker等人,1996年)同时实现了 O ( log T ) O(\log T) O(logT)的深度和 O ( T ) O(T) O(T)的工作量。这种算法最容易从SSM扫描或累积乘积和的角度来观察,即使这样也不是显而易见的:它需要单独推导出一个关联操作符(22),然后利用并行/关联/前缀扫描算法作为黑盒(Blelloch,1990年)。
在这里,我们展示了实际上可以通过利用不同的矩阵分解来推导这种并行扫描:
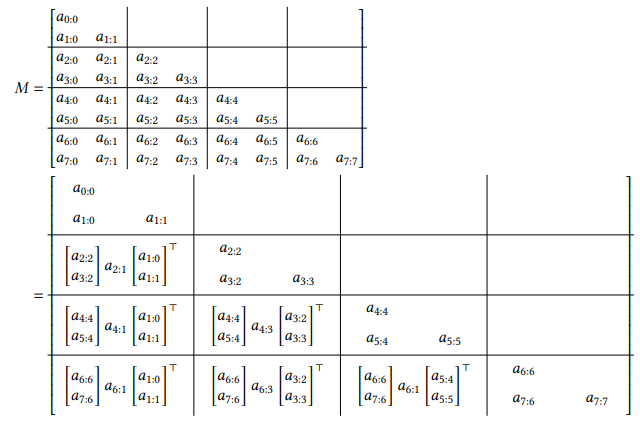
现在我们分三个阶段进行。
阶段1。首先,我们计算乘法 M b M_b Mb中每个对角块的答案。这会产生两个数,但第一个元素是不变的。例如,第二个块会计算 b 2 b_{2} b2和 a 3 b 2 + b 3 a_{3}b_{2}+b_{3} a3b2+b3。
阶段2。现在考虑矩阵严格下三角部分中作为秩1矩阵分解的每个 2 × 2 2 \times 2 2×2块。请注意,右侧的每一行向量都与所在列的对角块的底部行向量相同:特别是 [ a 1 : 0 a 1 : 1 ] , [ a 3 : 2 a 3 : 3 ] \left[a_{1: 0} a_{1: 1}\right],\left[a_{3: 2} a_{3: 3}\right] [a1:0a1:1],[a3:2a3:3],和 [ a 5 : 4 a 5 : 5 ] \left[a_{5: 4} a_{5: 5}\right] [a5:4a5:5]行。
因此,我们已经在阶段1中得到了这些答案,这是阶段1中所有 T / 2 T/2 T/2个子问题的第二个元素。如果我们称这个元素数组为 b ′ b^{\prime} b′(大小为 b b b的一半),那么我们需要将 b ′ b^{\prime} b′乘以由 a 3 : − 1 , a 3 : 1 , a 5 : 3 , a 7 : 5 a_{3:-1}, a_{3: 1}, a_{5: 3}, a_{7: 5} a3:−1,a3:1,a5:3,a7:5生成的1-SS矩阵。
阶段3。最后,阶段2的每个答案都可以通过乘以左侧列向量来广播为两个最终答案:特别是 [ a 2 : 2 a 3 : 2 ] ⊤ , [ a 4 : 4 a 5 : 4 ] ⊤ \left[\begin{array}{ll}a_{2: 2} & a_{3: 2}\end{array}\right]^{\top},\left[\begin{array}{ll}a_{4: 4} & a_{5: 4}\end{array}\right]^{\top} [a2:2a3:2]⊤,[a4:4a5:4]⊤,和 [ a 6 : 6 a 7 : 6 ] ⊤ \left[\begin{array}{ll}a_{6: 6} & a_{7: 6}\end{array}\right]^{\top} [a6:6a7:6]⊤向量。
请注意,这可以通过对索引进行一些偏移来稍微修改。查看此算法的另一种等效方式是将其视为三步矩阵分解。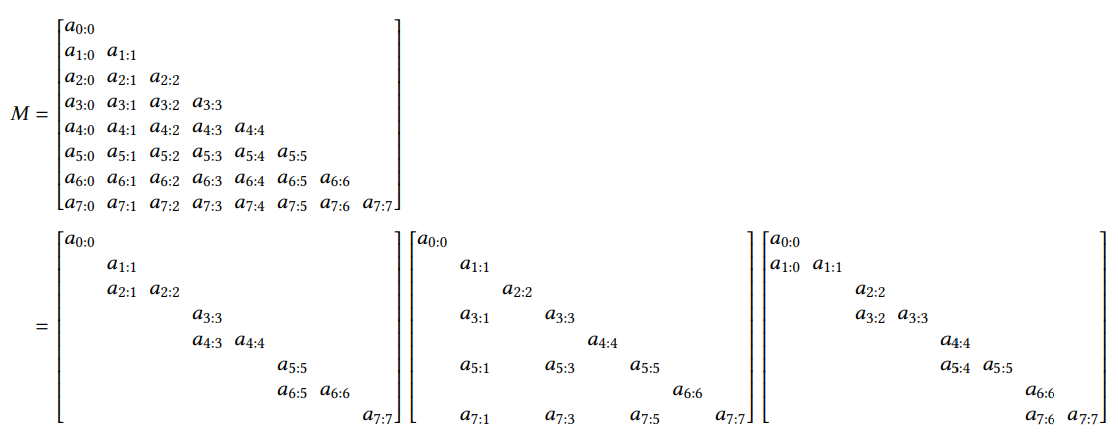
注意,阶段1和阶段3需要 O ( T ) O(T) O(T)的工作量,而阶段2减少为一个大小减半的自相似问题。很容易检查到,这总共需要 O ( T ) O(T) O(T)的工作量,并且具有 O ( log T ) O(\log T) O(logT)的深度/跨度。
备注10. 事实上,可以看出这个算法的计算图与附录B.2.2中描述的关联扫描算法的计算图是相同的。关键点在于,不同于(1)识别出 M M M定义了一个递推关系(2)观察到这个递推关系可以用一个结合的二元运算符来定义;这里有一个完全不同的视角,即只是为 M M M找到一个结构化的矩阵分解算法。
C、理论细节
C.1、附加内容:SSM的封闭性质
我们在这里介绍半可分矩阵的一些额外性质,以说明它们的灵活性和实用性。这一节不是理解我们核心结果所必需的。
命题C.1(SSM的封闭性质)。半可分矩阵在几种基本运算下是封闭的。
- 加法:一个 N N N-SS矩阵和一个 P P P-SS矩阵的和最多是 ( N + P ) (N+P) (N+P)-SS矩阵。
- 乘法:一个 N N N-SS矩阵和一个 P P P-SS矩阵的乘积是 ( N + P ) (N+P) (N+P)-SS矩阵。
- 逆:一个 N N N-SS矩阵的逆最多是 ( N + 1 ) (N+1) (N+1)-SS矩阵。
加法和乘法的性质很容易看出。逆的性质有多种证明方法;其中一种方法直接来自Woodbury逆公式,该公式在结构SSM文献中也占有重要地位(Gu, Goel, 和 Ré 2022)。
反过来,这些性质意味着状态空间模型的封闭性质。
例如,加法性质表明,两个并行SSM模型的和仍然是一个SSM。乘法性质表明,顺序组合或链接两个SSM仍然可以看作是一个SSM,其总状态大小是加性的——这是一个稍微非平凡的事实。
最后,逆的性质可以让我们将SSM与其他类型的模型联系起来。例如,人们可以注意到带状矩阵是半可分的,所以它们的逆也是半可分的。(事实上,半可分结构家族通常是由带状矩阵的逆得到的(Vandebril等人,2005))。此外,半可分矩阵的快速递归性质可以看作是它们的逆是带状矩阵的结果。
备注11. 1-SS矩阵是简单递推(7)的事实与1-SS矩阵的逆是2-带状矩阵的事实是等价的:
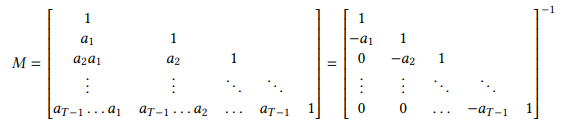
因此, y = M x ↔ M − 1 y = x y = M x \leftrightarrow M^{-1} y = x y=Mx↔M−1y=x,或者
[ 1 − a 1 1 0 − a 2 1 ⋮ ⋮ ⋱ ⋱ 0 0 … − a T − 1 1 ] y = x \left[ \begin{array}{ccccc} 1 & & & & \\ -a_{1} & 1 & & & \\ 0 & -a_{2} & 1 & & \\ \vdots & \vdots & \ddots & \ddots & \\ 0 & 0 & \ldots & -a_{T-1} & 1 \end{array} \right] y = x 1−a10⋮01−a2⋮01⋱…⋱−aT−11 y=x
或者按元素表示,
y t − a t y t − 1 = x t y t = a t y t − 1 + x t \begin{array}{l} y_{t} - a_{t} y_{t-1} = x_{t} \\ y_{t} = a_{t} y_{t-1} + x_{t} \end{array} yt−atyt−1=xtyt=atyt−1+xt
反过来,我们也利用这些封闭性质的结果来证明(在某些假设下)自回归结构化注意力必须是SSM,这使我们能够展示包括注意力变体在内的更广泛的高效序列模型家族可以简化为状态空间模型(附录C.2)。
C.2、自回归掩码注意力是半可分结构的注意力
我们证明5.2节中的定理5.2。在4.3节中,我们将结构化注意力定义为掩码注意力的一种广泛泛化,其中核注意力的高效性(即线性时间形式的核注意力)被抽象为结构化矩阵乘法的高效性。然而,除了计算效率之外,标准的线性注意力(Katharopoulos等人,2020)还有两个重要的属性。首先,它是因果的,这对于如自回归建模这样的设置是必要的。此外,它还具有高效的自回归生成。换句话说,自回归步骤的成本——即在已经看到并预处理了 x 0 : T x_{0: T} x0:T后,看到 x T x_{T} xT时计算输出 y T y_{T} yT的增量成本——仅需要常数时间。
这里我们描述哪些SMA实例具有高效的自回归。
在SMA的框架中,因果性等价于掩码 L L L是一个下三角矩阵的约束。
描述具有高效自回归的 L L L矩阵空间更加困难。我们将使用自回归过程的狭义技术定义,借鉴时间序列文献中的经典定义(例如ARIMA过程(Box等人,2015))。
定义C.2. 我们将 x ∈ R T x \in \mathbb{R}^{T} x∈RT到 y ∈ R T y \in \mathbb{R}^{T} y∈RT的 k k k阶自回归变换定义为每个输出 y t y_{t} yt仅取决于当前输入和前 k k k个输出的变换:
y t = μ t x t + ℓ t 1 y t − 1 + ⋯ + ℓ t k y t − k . y_{t} = \mu_{t} x_{t} + \ell_{t1} y_{t-1} + \cdots + \ell_{tk} y_{t-k} . yt=μtxt+ℓt1yt−1+⋯+ℓtkyt−k.
请注意,当 L L L是累加和矩阵时,它是一个特殊情况,其中 k = 1 k=1 k=1,因此 y t = x t + y t − 1 y_{t} = x_{t} + y_{t-1} yt=xt+yt−1。有了这个定义,通过半可分矩阵的性质就可以推导出高效自回归线性变换的空间。定理C.3正式化并证明了定理5.2。
定理C.3. 令 L ∈ R T × T L \in \mathbb{R}^{T \times T} L∈RT×T是 k k k阶高效自回归变换。那么 L L L是 k + 1 k+1 k+1阶的状态空间模型。
证明. 令 ( x , y ) (x, y) (x,y)为输入和输出序列,使得 y = L x y=Lx y=Lx。重新排列定义(23),
y t − ℓ t 1 y t − 1 − ⋯ − ℓ t k y t − k = μ t x t . y_{t} - \ell_{t1} y_{t-1} - \cdots - \ell_{tk} y_{t-k} = \mu_{t} x_{t} . yt−ℓt1yt−1−⋯−ℓtkyt−k=μtxt.
对 t t t进行矢量化,这可以表示为矩阵变换
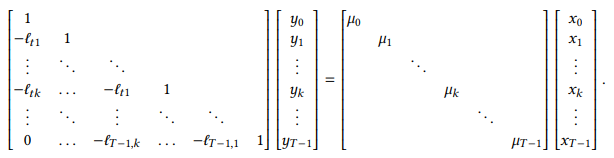
μ \mu μ对角矩阵可以移到左边并与 ℓ \ell ℓ系数矩阵合并,合并后仍然是一个 k + 1 k+1 k+1带的下三角矩阵。但我们还知道 L − 1 y = x L^{-1}y=x L−1y=x,所以 L L L是这个矩阵的逆。
接下来,注意到由半可分性的秩特征(定义3.1)可知, k + 1 k+1 k+1带矩阵是 k + 1 k+1 k+1半可分的。根据命题C.1,逆矩阵 L L L因此最多是 k + 2 k+2 k+2半可分的。但由于带状矩阵的额外结构,可以获得稍微更强的 k + 1 k+1 k+1的界限。最后, L L L作为 k + 1 k+1 k+1阶状态空间模型的表征来自定理3.5。
换句话说,高效自回归注意力是可半分离的SMA(状态空间模型)。
D、实验细节
D.1、MQAR 细节
我们使用一个基于(Arora, Eyuboglu, Zhang 等人,2024)提出的更难的任务版本,其中不是查询/键/值的标记被随机标记替换。我们还使用了比先前工作使用的MQAR常规变体更多的键-值对、更长的序列和更小的模型大小,这些都使得任务更具挑战性。
对于每个序列长度 T ∈ { 256 , 512 , 1024 } T \in\{256,512,1024\} T∈{256,512,1024},我们使用 T / 4 T / 4 T/4个键-值对。总词汇量是8192。
我们使用一种课程训练形式,其中训练周期通过数据集使用( T / 32 , T / 16 , T / 8 , T / 4 T / 32, T / 16, T / 8, T / 4 T/32,T/16,T/8,T/4)键-值对,每个数据集有 2 18 ≈ 250000 2^{18} \approx 250000 218≈250000个示例,总共通过每个数据集进行8个周期的训练(总共有 2 28 ≈ 2.7 × 1 0 7 2^{28} \approx 2.7 \times 10^{7} 228≈2.7×107个示例)。总批次大小是 2 18 ≈ 0.25 × 1 0 6 2^{18} \approx 0.25 \times 10^{6} 218≈0.25×106个标记(例如,对于 T = 1024 T=1024 T=1024,批次大小是256)。
所有方法都使用具有默认设置的2层网络;注意力基线额外接收位置嵌入。对于每种方法,我们遍历模型维度 D = { 32 , 64 , 128 , 256 } D=\{32,64,128,256\} D={32,64,128,256}和学习率 { 1 0 − 3.5 , 1 0 − 2 , 1 0 − 2.5 } \left\{10^{-3.5}, 10^{-2}, 10^{-2.5}\right\} {10−3.5,10−2,10−2.5}。我们使用线性衰减计划,在每个周期结束时降低学习率(例如,最后一个周期的学习率将是最大/起始学习率的 1 / 8 1 / 8 1/8)。
D.2、缩放定律细节
所有模型都在Pile数据集上进行训练。对于缩放定律实验,我们使用了GPT2的分词器。
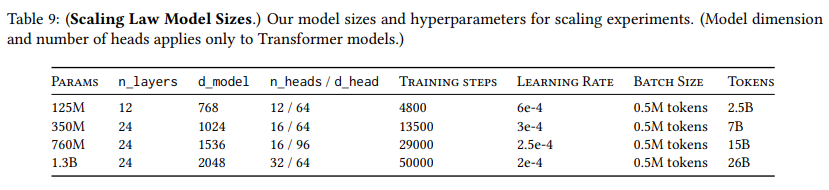
模型大小。表9指定了我们在遵循GPT3(Brown等人,2020)之后的缩放定律中使用的模型大小。首先,为了保持一致性,我们将 1.3 B 1.3 \mathrm{~B} 1.3 B模型的批次大小从 1 M 1 \mathrm{M} 1M标记改为 0.5 M 0.5 \mathrm{M} 0.5M标记。其次,我们改变了训练步数和总标记数,以大致匹配Chinchilla缩放定律(Hoffmann等人,2022),该定律指定训练标记数应该与模型大小成比例增加。
训练配方。所有模型都使用了AdamW优化器,参数如下:
- 梯度裁剪值为1.0
- 权重衰减为0.1
- 不使用dropout
- 线性学习率预热与余弦衰减
默认情况下,峰值学习率是GPT3规范中指定的。
与GPT3配方相比,我们使用了“改进配方”,这是受到流行的大型语言模型(如PaLM(Chowdhery等人,2023)和LLaMa(Touvron, Lavril等人,2023))采用的更改的启发。这些改进包括:
- 线性学习率预热与余弦衰减至 1 e − 5 1 \mathrm{e}-5 1e−5,峰值是GPT3值的 5 5 5倍
- 不使用线性偏置项
- 使用RMSNorm代替LayerNorm
- AdamW超参数 β = ( . 9 , . 95 ) \beta=(.9, .95) β=(.9,.95)(GPT3的值),而不是PyTorch默认的 β = ( . 9 , . 999 ) \beta=(.9, .999) β=(.9,.999)
D.3、下游评估细节
为了评估完全训练后的下游性能,我们在Pile数据集上使用GPTNeoX(Black等人,2022)分词器对Mamba-2进行了300B标记的训练。
我们使用与缩放实验相同的超参数,但对于 1.3 B 1.3 \mathrm{~B} 1.3 B和 2.7 B 2.7 \mathrm{~B} 2.7 B模型,我们将批次大小设置为 1 M 1 \mathrm{M} 1M。对于 2.7 B 2.7\mathrm{B} 2.7B模型,我们还遵循GPT3的规范(32层,维度2560)。
对于所有模型,我们使用了对应GPT3模型学习率的 5 5 5倍。
在下游评估中,我们使用了EleutherAI的LM评估框架(L. Gao, Tow等人,2021),与Mamba(Gu和Dao,2023)相同的任务,并增加了一个额外的任务:
- LAMBADA(Paperno等人,2016)
- HellaSwag(Zellers等人,2019)
- PIQA(Bisk等人,2020)
- ARC-challenge(P. Clark等人,2018)
- ARC-easy:ARC-challenge的一个简单子集
- WinoGrande(Sakaguchi等人,2021)
- OpenBookQA(Mihaylov等人,2018)
D.4、消融实验细节
(重新)基于的细节。我们在第9.4.3节中的消融实验考虑了Based(Arora, Eyuboglu, Zhang等人,2024)和ReBased(Aksenov等人,2024)模型。
Based使用二次泰勒展开 exp ( x ) ≈ 1 + x + x 2 / 2 \exp(x) \approx 1+x+x^{2} / 2 exp(x)≈1+x+x2/2来近似exp核,这可以通过特征映射实现:
Ψ Taylor ( x ) = concatenate ( 1 , x , 1 / 2 x ⊗ x ) \Psi_{\text{Taylor}}(x) = \text{concatenate}(1, x, 1 / \sqrt{2} x \otimes x) ΨTaylor(x)=concatenate(1,x,1/2x⊗x)。
ReBased建议使用更简单的特征映射 ψ Quadratic ( x ) = x ⊗ x \psi_{\text{Quadratic}}(x) = x \otimes x ψQuadratic(x)=x⊗x,它对应于核变换 x 2 x^{2} x2,但在此之前还应用了层归一化。我们将层归一化视为我们默认Swish激活函数的替代非线性激活函数,并对这些组合进行了消融实验。
相关文章:
Transformers是SSMs:通过结构化状态空间对偶性的广义模型和高效算法(二)
文章目录 6、针对SSD模型的硬件高效算法6.1、对角块6.2、低秩块6.3、计算成本 7、Mamba-2 架构7.1、块设计7.2、序列变换的多头模式7.3、线性注意力驱动的SSD扩展8、系统优化对于SSMs8.1、张量并行8.2、序列并行性8.3、可变长度 9、实证验证9.1、合成任务:联想记忆9…...
Segment any Text:优质文本分割是高质量RAG的必由之路
AI应用开发相关目录 本专栏包括AI应用开发相关内容分享,包括不限于AI算法部署实施细节、AI应用后端分析服务相关概念及开发技巧、AI应用后端应用服务相关概念及开发技巧、AI应用前端实现路径及开发技巧 适用于具备一定算法及Python使用基础的人群 AI应用开发流程概…...

IDEA 学习之 编译内存问题
目录 1. 正常的 IDEA build 日志2. 编译工具内存不足日志 (内存从小变大)2.1. 干脆无法启动2.2. Ant 任务执行报错2.3. 内存溢出:超出 GC 上限2.4. 内存溢出:超出 GC 上限,编译报错2.5. 内存溢出: 堆空间2.…...

如何将本地项目推送到gitee仓库
目录 为何用gitee管理自己项目: 如何将自己的项目推送到gitee仓库,步骤如下: 1.下载git 2.生成公钥 3.在gitee上添加公钥 4.在gitee上创建仓库 5.将本地项目推送到gitee仓库 为何用gitee管理自己项目: 1.可以使用多台电脑…...

产品经理基础入门
一、产品基础(需求收集、需求管理、需求分析、结构图、流程图、原型、PRD文档、用户画像、后台的角色管理) 产品经理定义: 1.市场分析:找准市场方向,确定哪个市场是值得进入的。 2.用户分析:针对目标市场…...
五子棋纯python手写,需要的拿去
import pygame,sys from pygame import * pygame.init()game pygame.display.set_mode((600,600)) gameover False circlebox [] # 棋盘坐标点存储 box [] def xy():for x in range(0,800//40): for y in range(0,800//40): box.append((x*40,y*40)) xy() defaultColor wh…...

C# Winform按钮避免重复点击以及解决WinForm中设置Enabled=False为什么还会响应Click事件
1、C# Winform按钮避免重复点击 代码如下 btn.Enablefalse; //执行任务的函数或代码 btn.Enabletrue; 在btn.Enabletrue前添加Application.DoEvents(); 就是让应用程序的消息队列自动走完(即在按钮为Ture前清空消息队列)。 2、解决WinForm中设置Enabl…...
谷歌SEO是什么意思?
谷歌SEO(Search Engine Optimization)是通过优化网站内容和结构,使其在谷歌搜索引擎中排名更高的策略和技术。这不仅仅是提高网站排名,更是吸引目标受众、增加流量并最终提升业务转化的关键方法之一。谷歌搜索引擎优化(…...
IPFoxy Tips:匿名海外代理IP的使用方法及注意事项
在互联网上,隐私和安全问题一直备受关注。为了保护个人隐私和数据安全,使用匿名代理IP是一种常用的方法。匿名代理IP可以隐藏用户的真实IP地址,使用户在访问网站时更加隐秘和安全。 本文将介绍匿名代理IP的基本原理和核心功能。 基本原则 匿…...

【MySQL进阶之路 | 小结篇】MySQL键约束KEY与索引INDEX
1. 键约束 关键字key 比如UNIQUE KEY就是一个唯一性约束,用于确保表中的某一列或多列的组合具有唯一性,不允许有重复值.当定义一个唯一性约束的时候,会自动创建一个唯一性索引来支持这一约束,这意味着它同时也起到了索引的作用.…...

【中学教资科目二】02中学课程
02中学课程 第一节 课程概述1.1 课程的分类 第二节 课程组织2.1 课程内容的文本表现形式2.2 课程评价 第三节 基础教育课程改革3.1 基础教育改革的目标3.2 新课改的课程结构 第一节 课程概述 1.1 课程的分类 学校课程有多种类型,其中最利于学生系统掌握人类所取得的…...

Stable Diffusion 亲测这几个SDXL大模型,真的非常好用!
大家好我是极客菌,前两周Stable Diffusion WebUI1.6.0发布了,新增了很多对SDXL生态的支持。 而ControlNET也对SDXL的支持也逐渐稳定。 SDXL的生态终于有一点起色了,我也觉得是时候,可以来写一篇SDXL的大模型推荐了。 在推荐之前…...

DLS策略洞察:如何应对AI数据中心网络交换机市场的爆发式增长?
摘要: 随着AI技术的发展和应用,AI数据中心对网络交换机的需求日益增加。摩根士丹利预计,2023-2026年间,AI数据中心网络交换机的收入复合年增长率(CAGR)将达到55%。本文将详细分析AI数据中心网络交换机市场…...

数据仓库架构设计
数据仓库架构设计是为了有效地收集、存储、处理和分析大规模数据,从而支持商业智能和数据分析活动。一个良好的数据仓库架构需要考虑数据源的多样性、数据存储的结构化、数据处理的高效性和数据分析的灵活性。以下是数据仓库架构设计的详细介绍。 数据仓库架构的层…...

EasyExcel动态表头多sheet录入,单元格操作样式,自动修改单元格格式
EasyExcel动态表头多sheet录入,单元格操作样式,自动修改单元格格式 说明 EasyExcel是一款开源的Java库,用于读取、写入和操作Excel文件。它是阿里巴巴集团开发的一款高效、功能丰富且易于使用的Excel操作工具。 EasyExcel提供了简洁的API,使得读写Excel…...

Linux的设备模型
在设备模型出现以前,Linux的驱动存在以下问题: 1,设备和驱动没有分离。也就是说设备的信息是硬编码在驱动代码中的,这给驱动程序造成了极大的限制。如果硬件有所改动,那么必然要修改驱动代码。比如LED如果修改了管脚,那么就必然要修改驱动程序。这样就导致驱动的通用性很…...
初始化一个Android项目时,Android Studio会自动生成一些文件和目录结构,以帮助你快速上手开发
当你初始化一个Android项目时,Android Studio会自动生成一些文件和目录结构,以帮助你快速上手开发。这些文件和目录各自有其特定的功能和用途。下面我为你解释一下这些自动生成的内容: 1. app 目录 这是你的应用模块的根目录,包…...

社区团购小程序开发
在快节奏的现代生活中,人们越来越追求便利与效率。社区团购小程序应运而生,以其独特的优势成为连接社区居民与优质商品的重要桥梁。本文将探讨社区团购小程序的特点、优势以及未来发展趋势,为大家揭示这一新型购物模式的魅力。 社区团购小程序…...
数据分析python基础实战分析
数据分析python基础实战分析 安装python,建议安装Anaconda 【Anaconda下载链接】https://repo.anaconda.com/archive/ 记得勾选上这个框框 安装完后,然后把这两个框框给取消掉再点完成 在电脑搜索框输入"Jupyter",牛马启动&am…...

英语笔记-专升本
2024年6月23日15点01分,今天自己听老师讲了一张试卷,自己要开始不断地进行一个做事,使自己可以不断地得到一个提升,自己可以提升的内容, 英语试卷笔记 ------------------------------------ | 英语试卷笔记 …...

如何用RecastNavigation构建高效AI导航系统:5个实战技巧揭秘
如何用RecastNavigation构建高效AI导航系统:5个实战技巧揭秘 【免费下载链接】recastnavigation Navigation-mesh Toolset for Games 项目地址: https://gitcode.com/gh_mirrors/re/recastnavigation 你是否曾为游戏中的AI角色设计路径规划而头疼?…...

逆向视角看iOS加固:从机器码到伪代码,手把手教你分析加固效果与潜在风险
逆向视角看iOS加固:从机器码到伪代码的深度解析 当你在App Store下载一个应用时,可能不会想到这个看似简单的IPA文件背后隐藏着怎样的技术博弈。作为iOS开发者或安全研究员,我们常常需要从另一个角度思考——不是如何保护自己的应用…...

HackBGRT:UEFI启动界面定制的极简实施指南
HackBGRT:UEFI启动界面定制的极简实施指南 【免费下载链接】HackBGRT Windows boot logo changer for UEFI systems 项目地址: https://gitcode.com/gh_mirrors/ha/HackBGRT HackBGRT是一款专注于UEFI系统的开源工具,为用户提供安全高效的启动画面…...
)
别再重复积分了!手把手教你用IMU预积分优化LIO-SAM(附代码避坑点)
激光SLAM实战:IMU预积分在LIO-SAM中的高效实现与调优指南 当你在深夜调试LIO-SAM时,是否曾被重复积分导致的性能瓶颈折磨得抓狂?IMU预积分技术正是解决这一痛点的银弹。不同于传统惯性积分对初始状态的强依赖,预积分将相对运动量…...

YOLOv5实战:如何用Python手写IoU计算函数提升目标检测精度
YOLOv5实战:手写IoU计算函数提升目标检测精度的Python实现 在目标检测任务中,边界框的定位精度直接影响模型性能。IoU(Intersection over Union)作为衡量预测框与真实框重合度的核心指标,其计算准确性对模型优化至关重…...

如何快速完成亚马逊SP-API注册:AWS IAM策略与角色配置详解
亚马逊SP-API高效注册指南:从AWS IAM配置到应用上线的全流程解析 当你的电商业务需要与亚马逊平台深度集成时,SP-API(Selling Partner API)将成为不可或缺的工具。作为亚马逊新一代的开发者接口,它比传统的MWS提供了更…...
)
宇视NVR接入AS-V1000平台全流程指南(含SDK端口配置避坑)
宇视NVR对接AS-V1000平台实战手册:从配置到排障的深度解析 当监控系统需要整合多品牌设备时,宇视NVR与AS-V1000平台的对接成为典型场景。不同于标准化的协议对接,SDK接入方式往往隐藏着诸多"暗礁"——从端口冲突到能力集匹配&#…...

从零搭建Vulnstack内网靶场:一次完整的渗透测试实战复盘
1. 环境准备与靶场搭建 第一次接触Vulnstack靶场时,我完全被内网渗透的复杂性震撼到了。这个靶场模拟了真实企业内网环境,包含域控制器、Web服务器和普通办公主机等多种设备。搭建过程就像拼装一台精密仪器,每个部件都要准确定位。 靶机环境需…...

RMBG-2.0效果对比:不同光照/背景复杂度下头发分割准确率实测数据表
RMBG-2.0效果对比:不同光照/背景复杂度下头发分割准确率实测数据表 头发,无疑是图像背景去除(抠图)领域公认的“硬骨头”。无论是电商商品图、人像写真还是短视频素材,发丝边缘的精细度直接决定了最终效果的成败。今天…...

Vitis HLS避坑指南:hls::stream深度设置不当,你的FPGA设计可能卡死
Vitis HLS实战:如何避免hls::stream深度配置引发的硬件死锁 在FPGA加速器开发中,数据流设计是最常见的性能优化手段之一。Vitis HLS提供的hls::stream模板类,让C代码能够直接映射到高效的硬件数据流结构。但许多开发者都遇到过这样的困境&…...