数据分析python基础实战分析
数据分析python基础实战分析
安装python,建议安装Anaconda
【Anaconda下载链接】https://repo.anaconda.com/archive/
记得勾选上这个框框
安装完后,然后把这两个框框给取消掉再点完成
在电脑搜索框输入"Jupyter",牛马启动!
等待终端运行
运行完后会自动弹出网页
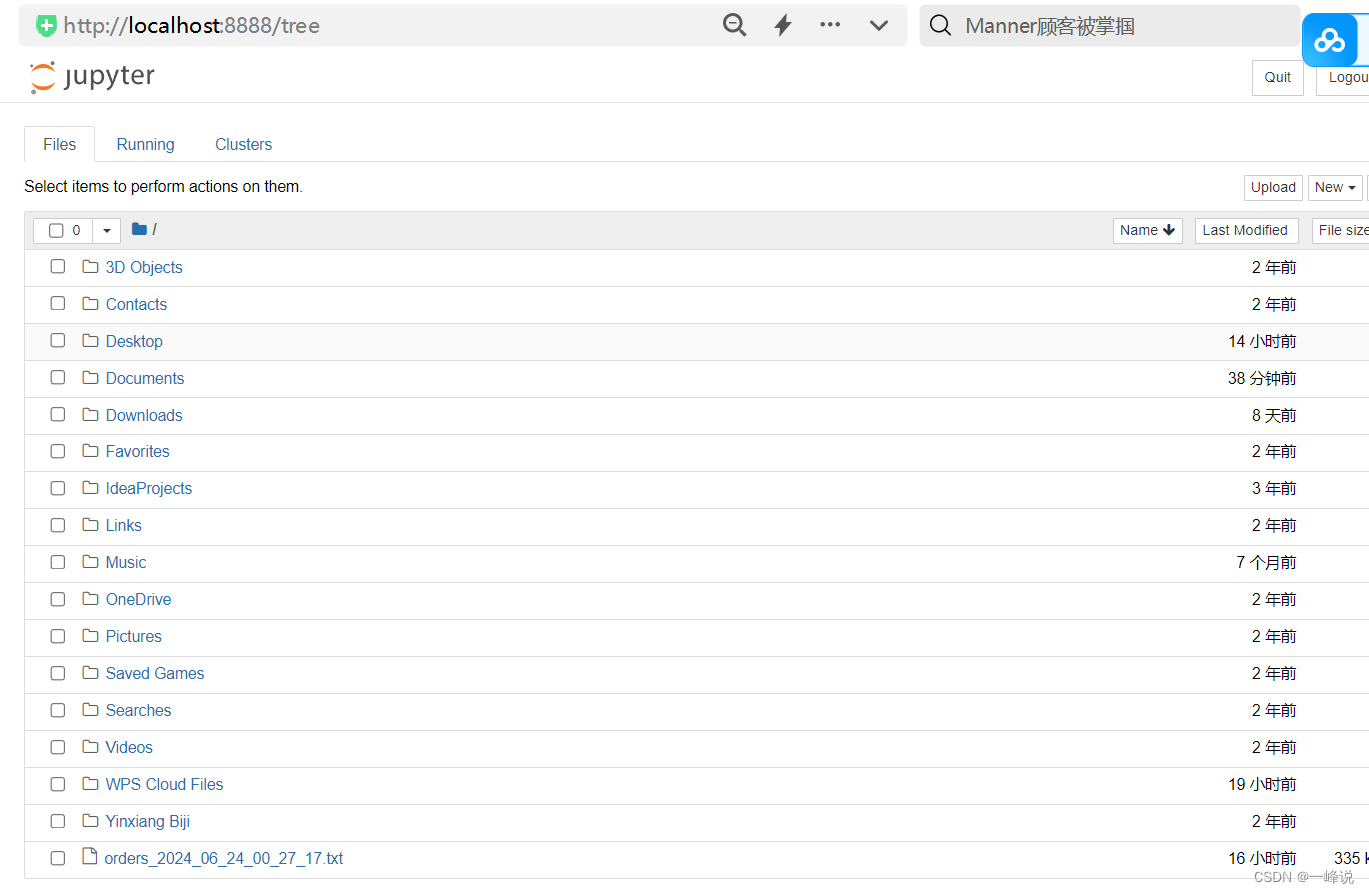
这里建议设置一下目录,以便后续创建的所有文件容易找到:
新建一个目录“python练习”

输入“jupyter notebook”然后回车,就会运行终端弹出浏览器
这样就得到一个干净的笔记本啦,可以右上角new新建python文件写代码运行
shift + enter 运行
数据类型
常见有整型int,浮点型float,布尔型bool,字符串string,列表list,字典dict,根据业务变量需要而变化。
变量与赋值
变量 = 数值,将数值赋值给变量
数据结构
list列表:数据量级大的时候,将多个数据一同存储到一个变量,方便后面使用。
dict字典:{key(唯一):值},如果懂什么叫映射就理解dict。excel里的表头就相当于key,如果列的表头带着多个值可以这样写:{key : [ 值1, 值2, 值3] }表示一列,key作表头,有3行值的数据;如果是多列可以写成:{key1 : [ 值1, 值2, 值3] ,key2 : [ 值1, 值2, 值3] ,key3 : [ 值1, 值2, 值3] } ;还有这种 [{key1 : 值1 , key2 : 值2 ,key3 : 值3 }, {key1 : 值1 , key2 : 值2 ,key3 : 值3 }, {key1 : 值1 , key2 : 值2 ,key3 : 值3 }]
数据结构检索与访问
检索:列表[0,3] 代表从第0个开始,共3个
访问:字典[‘key’] 返回对应key的值
分析数据过程:
1.取出数据,赋值给一个变量。例如有个字典ad_list, ad_1 = ad_list[0],打印ad_1
2.处理重复数据,例如del ad_1[‘成交金额’],打印ad_1
3.处理异常值,ad_1[‘GMV’] = ad_1[‘GMV’]/100, 打印ad_1
4.发现缺少某些指标,例如ROI, ad_1[‘ROI’] = round(ad_1[‘GMV’]/ ad_1[‘消耗’],2),打印ad_1,并且roi保留两位小数
5.查看广告策略,例如 ad_1[‘商品名称’] = ad_1 [‘广告计划名称’].split(‘‘)[0], ad_1[‘人群标签’] = ad_1 [‘广告计划名称’].split(’’)[1], ad_1[‘用户年龄’] = ad_1 [‘广告计划名称’].split(‘‘)[2], ad_1[‘用户等级’] = ad_1 [‘广告计划名称’].split(’’)[3]
for循环
for item in list:print(item)//range()范围,这里3的意思是会产生一个0到3的序列范围,左闭右开
//len()长度,list里面有多少个数值
for i in range(len(list)):print(list[i])
如果数据太长,可以用txt保存在用python进行读取:
with open('历史数据.txt', 'r', encoding = 'utf-8') as f:history = f.readline()
//打印结果为字符串
history
//将字符串转换成list
history = eval(history)
history
//如果history需要整合其他list,ad_list会追加到history后面
history.extend(ad_list)
IF语句
if 条件:do
else:do
if 条件:do
elif 条件:do
else:do
#如果要取出ROI大于1的数据
roi_list = []
for i range(len(hisotry)):if history[i]['roi']>=1:print(history[i])roi_list.append(history[i])elsepass
#打印
roi_list
自定义函数
#参数输入,有返回值
#f''字符串可以在字符串中嵌套变量
def nooddle_machine(water, flour):print('搅拌……')print(f'{water}和{flour}已经变成面团')print('正在挤压面团')return f'由{water}和{flour}制作而成的面条已经ok了'
#使用
bowl = nooddle_machine('水','面粉')
bowl
#没有输入参数,但有返回值
import datetime
def yesterday():date = datetime.datetim.now() -- datetime.timedelta(days=1)return date.date()
yesterday = yesterday()
yesterday
#有输入参数,但没有返回值
def upload_data(date):print(f'已经将{date}的数据上传至数据库')
upload_data('2024-06-25')
#没有输入参数,没有返回值
def upload_data():date = yesterday()print(f'已经将{date}的数据上传到数据库')
批量处理:
def batch_data(data_list):for i in range(len(data_list)):process_data(data_list[i])#比方说选出ROI大于1的数据
def filter_roi(data_list):roi_list = []for i range(len(data_list)):if data_list[i]['ROI'] >=1:print(data_list[i])roi_list.append(data_list[i])else:passreturn ros_list
模块与包
import pandas as pd
Series/DataFrame
Series: 属于一维的
# name相当于表头
# index索引
s1 = pd.Series(['a','b','c'],name = 'test', index=['1','2','3'])#如果需要将两个Series整合
pd.concat([s1],[s2], axis=1)
DataFrame: 二维, 本质上是字典,里面的值是列表,可以理解成是Series构成的
pandas读取和导出
读取
import pandas as pd
data = pd.read_excel(r'路径\文件.xlsx',converters={'uid': str, 'id':str })
//查看数据
data.info()
#另一种方式
data['id'] = data['id'].astype(str)
导出
#index = False 可以去掉导出后excel的索引
data.to_excel('test excel.xlsx', index = False)data.to_csv('test csv.csv', encoding='GB18030')//文字能识别成功,但是数值会被Excel使用科学计数法代替
data.to_csv('test csv.txt', sep='\t')
访问与筛选
访问
访问列:data[‘字段名’]; 如果是多个字段->data[[‘字段名1’,‘字段名2’,‘字段名3’]]
访问行:data.iloc[1]; data.iloc[1:6],左闭右开返回2到5行数据; data.iloc[1:6][‘字段名’],返回2到5行这个字段的数据
筛选
主要是通过True and false来判断
data[data[‘progress’] >= 100000 ]
去重筛选
data.drop_duplicates(subset=‘uid’, keep =‘last’, inplace=True)
轴/合并/连接
轴:axis=0是行,axis=1是列,axis相当于方向
合并:concat_demo = pd.concat([data, data2], axis=0)
连接:pd.merge(左表, 右表, how=‘inner’, on=‘uid’)
如果名字不一样:
rename:左表.rename(columns = {‘uid’: ‘user_id’ }, inplace = True)
pd.merge(左表, 右表, how=‘inner’, left_on=‘uid’, right=‘user_id’)
排序与匿名函数
排序
data.sort_values([‘uid’,‘ctime’], ascending = [True, False])
匿名函数
add2 = lambda x: x+5
add3 = lambda x, y : x+y
分组/聚合/转换
分组:分组只会创建一个object,再用object去调用count方法
data_manager = data.groupby(‘字段’)->data_manager.count()
聚合
先groupby后再调用聚合方法
data_manager[[‘消耗’,‘GMV’]].sum()
data_manager[[‘消耗’,‘GMV’]].agg([‘max’,‘min’])//看每个字段的最大和最小
data_manager.agg({‘消耗’: [‘max’,‘min’], ‘GMV’ : ‘min’})
算最大值和最小值的差值
data_manager[[‘消耗’,‘GMV’]].agg(lambda x: x.max() - x.min())
转换
data_manager[‘GMV’].transform(func=‘sum’)
同效果:data_manager[‘GMV’].agg(func=‘sum’)
组内排名:
#每个投放日期内,广告计划ID和GMV排名
history['每日GMV排名'] = history.groupby('投放日期')['GMV'].rank(method = 'dense', ascending =False)
history['每日GMV排名'] = history['每日GMV排名'].astype(int)
history.head(20)
字符串,数据清洗
split::用什么符号分割
history[’广告计划名称‘].str.split('_', expand=True),返回一个DataFrame
contains:字符串中包含了什么内容
`history[history['商品名称'].str.contains('玩转'),返回值是布尔`值].reset_index(drop=True)
replace:
举例,将《》两个符号改成【】
history['商品名称'].str.replace('《','【').str.replace('》','】')
结合正则表达式,更简洁的方式:
正则表达式在线测试网站:https://regex101.com/
history['商品名称'].str.replace(r'《(.*?)》',r'【\1】',regex=True)
extract:提取一个数据里面的部分内容
history['广告计划名称'].str.extract(r'(.*?)_')
绘图
折线图:
history.groupby('投放日期')['GMV'].sum().plot(kind='line', x='投放日期', y='GMV')#如果想导入中文字体
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'SimHei'
柱状图:
history.groupby('广告计划ID')['GMV'].sum().plot(kind='bar', x='广告计划ID', y='GMV')
水平柱状图:
history.groupby('广告计划ID')['GMV'].sum().plot(kind='barh', x='广告计划ID', y='GMV')
直方图:
history['GMV'].plot(kind = 'hist')
散点图:
history.plot(kind ='scatter', x='GMV', y='消耗')
饼图:
history.groupby('广告计划ID')['GMV'].sum().plot(kind ='pie')
PyGWalker
安装:在电脑CMD输入
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pygwalker
使用:
import pygwalker as pw
pw.walk(history)
map/apply/applymap
map: 对列或行进行处理
将GMV列的数据转换成int型
history['GMV'].map(lambda x : int(x))
与apply不同的可以用字典:
history[‘人群标签’].map({‘数据分析’ : ‘数分’})
apply:
如果操作的数据类型式DataFrame,则使用apply或者applymap。
#举例,因为这个是从左往右相加,所以要用axis进行定义,args是对系数设置 :
coe = None
if condition1:coe = 0.8
elif condition2:coe = 0.5
elif condition3:coe = 0.3def demo(x, coe):formular = x['客单价'] + x['消耗'] +['直播间消耗']formular = formular + x['GMV']return formular * coehistory.apply(demo, axis=1, args=(coe,))
applymap:所有字段都需要做同一个处理,其实apply也能做到
办公自动化:
背景:老板需要提供抖音平台上男士护肤品牌的带货视频,将已有的excel数据转换成word文档展示给老板看。
首先明确python怎么操作word,再确认将excel整合到word的格式。
CMD安装python-docx
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple python-docx
1.导入pandas as pd获取excel数据
import pandas as pd
video_list = pd.read_excel('video_list.xlsx')
speech_text = pd.read_excel('speech_text.xlsx')#检查数据,用vide_list.info()发现id为转换成整型,应该需要字符串
video_list['AwemeId'] = video_list['AwemeId'].astype(str)
speech_text['VideoId'] = speech_text['VideoId'].astype(str)#将两个表连接一起
merge = pd.merge(video_list, speech_text, how = 'inner', left_on ='AwemeId', right_on ='VideoId')
创建一个空的document:
from docx import Document
document = Document()
记得每次要新建的文件要重新赋值Document()
document = Document()
for i in range(len(merge)):#如果遇到同一个品牌的时候无须重复创建,i == 0 防止第一条查找时报错if merge.iloc[i]['品牌'] != merge.iloc[i-1]['品牌'] or i == 0:document.add_heading(merge.iloc[i]['品牌'],level = 1)document.add_heading(merge.iloc[i]['视频标题'],level = 2)document.add_paragraph(f'达人昵称:{merge.iloc[i]["BloggerName"]}')document.add_paragraph(f'视频链接:douyin.com/video/{merge.iloc[i]["AwemeId"]}')document.add_paragraph(merge.iloc[i]['视频文案'])
document.save('demo.docx')
探索分析
背景:得到一组弹幕数据,怎么做内容分析
数据处理
导入
import pandas as pduser_level = pd.read_excel('user_level.xlsx')
#将本地文件整合
import os
excel_list = []for item in os.listdir('./'):if 'xlsx' in item and 'user_level' not in item:excel_list.append(item)danmu = pd.DataFrame()
for item in excel_list:excel = pd.read_excel(item,converters = {'id': str, 'uid' : str, 'Awemeid' : str})#合并前新建一个字段区分每个表excel['视频标题'] = itemdanmu = pd.concat([danmu, excel], axis=0)
时间处理
时间维度
danmu['弹幕创建时间'] = danmu['ctime'].map(datetime.fromtimestamp)danmu['年'] = danmu['弹幕创建时间'].map(lambda x: x.year)
danmu['月份'] = danmu['弹幕创建时间'].map(lambda x: x.month)
danmu['星期'] = danmu['弹幕创建时间'].map(datetime.isoweekday)
danmu['小时'] = danmu['弹幕创建时间'].map(lambda x: x.hour)
时间可视化分析
#准备画图工具,字体设置微软雅黑
import matplotlib.pyplot as plt
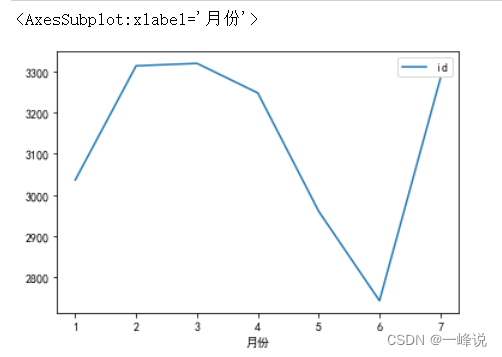
plt.rcParams['font.sans-serif'] = ['SimHei']danmu_year = danmu[danmu['年']==2022]
danmu_year.groupby('月份')[['id']].count().plot()
danmu_year.groupby('月份')[['uid']].nunique().plot()
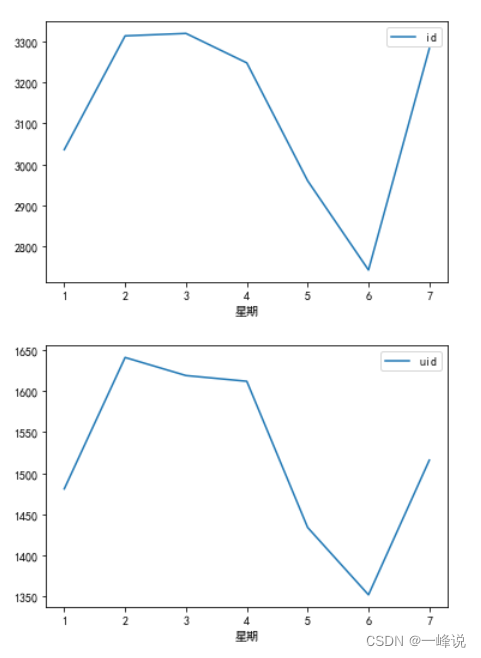
danmu_year.groupby('星期')[['id']].count().plot()
danmu_year.groupby('星期')[['uid']].nunique().plot()
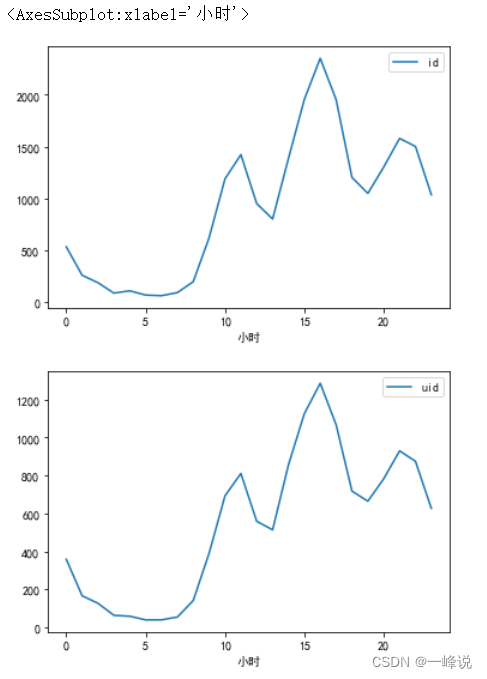
danmu_year.groupby('小时')[['id']].count().plot()
danmu_year.groupby('小时')[['uid']].nunique().plot()
用户画像:
用户处理
#统计用户弹幕的数
danmu['用户弹幕数'] = danmu.groupby('uid')['id'].transform('count')
#想加上另一个表的level字段,记得id号on的时候类型要保持一致,这里是字符串
user_level['uid'] = user_level['uid'].astype(str)
danmu_level = pd.merge(danmu, user_level, on = 'uid', how = 'inner')
弹幕内容
#按降序排弹幕数最多的用户,新建一个id列来存储count数
danmu_level.groupby('uid')[['id']].count().sort_values('id', ascending=False)
#限制300行数据,选定一个id用户来看
pd.set_option('display.max_rows',300)
danmu_level[danmu_level['uid'] == '6653485828143602809']
等级分布
#画出用户等级柱状图
danmu_level.groupby('level')[['id']].count().plot(kind='bar')
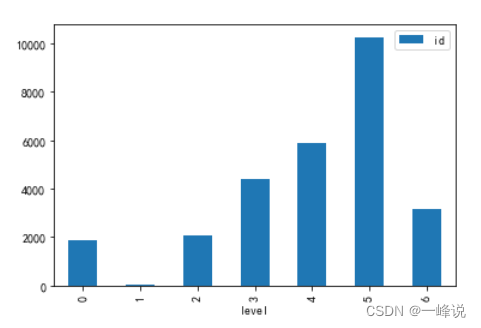
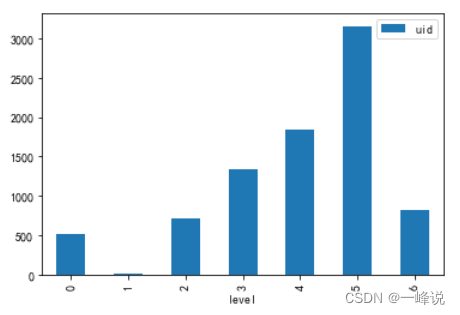
#看用户的唯一值,可用于验证假设
danmu_level.groupby('level')[['uid']].nunique().plot(kind='bar')
视频内容
视频内容处理
from time import strftime
from time import gmtimedanmu['视频进度'] = danmu['progress'].map(lambda x: strftime('%H:%M:%S',gmtime(x)))
#取时和分
danmu['视频进度【时分】'] = danmu['视频进度'].str[:5]
视频内容分析
p1 = danmu[danmu['视频标题']=='1、系统认识数据分析.xlsx']
p1.groupby('视频进度【时分】')[['id']].count().sort_values('id',ascending=False)#查看某时分的视频内容
p1[p1['视频进度【时分】'] == '00:11']
总结:
分析一个数据的时候可以从3个维度,时间,画像,内容进行分析, 时间维度可以提出猜想与假设,画像和内容可以判断出某些真实用户的情况,即可以提出某些结论;具体执行过程可以分为3步,1.先进行数据处理,2.再拿处理好的数据进行分析,3.提出假设,再看实际内容验证假设。
相关文章:
数据分析python基础实战分析
数据分析python基础实战分析 安装python,建议安装Anaconda 【Anaconda下载链接】https://repo.anaconda.com/archive/ 记得勾选上这个框框 安装完后,然后把这两个框框给取消掉再点完成 在电脑搜索框输入"Jupyter",牛马启动&am…...

英语笔记-专升本
2024年6月23日15点01分,今天自己听老师讲了一张试卷,自己要开始不断地进行一个做事,使自己可以不断地得到一个提升,自己可以提升的内容, 英语试卷笔记 ------------------------------------ | 英语试卷笔记 …...
)
什么野指针(c++)
野指针定义 野指针(Wild Pointer)是指向不确定位置或者非法地址的指针。当一个指针指向的内存被释放后,如果没有将其设置为NULL,那么这个指针就变成了野指针。使用野指针会导致未定义行为,可能引发程序崩溃或数据损坏…...

【编译原理】绪论
1.计算机程序语言以及编译 编译是对高级语言的翻译 源程序是句子的集合,树可以较好的反应句子的结构 编译程序是一种翻译程序 2.编号器在语言处理系统中的位置 可重定位:在内存中存放的起始位置不是固定的 加载器:修改可重定位地址&#x…...

优化Docker部署:解决Java应用ExcelGenerateException并提速镜像构建
在开发和部署应用时,经常会遇到在本地环境运行正常,但迁移到Docker容器后出现特定错误的情况。本篇博客将聚焦于解决一个具体问题:当使用Docker部署包含Excel生成功能的Java应用程序时,遇到ExcelGenerateException的排查与解决方法…...

你了解RabbitMQ、RocketMQ和Kafka吗?
是的,我了解 RabbitMQ、RocketMQ 和 Kafka。以下是对这三种消息队列系统的详细介绍: RabbitMQ 概念 RabbitMQ 是一个由 Pivotal 开发的开源消息代理,基于 AMQP(Advanced Message Queuing Protocol)协议。它支持多种…...
python实现可视化大屏(django+pyechars)
1.实现效果图 2.对数据库进行迁移 python manage.py makemigrations python manage.py migrate 3.登录页面 {% load static%} <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport"…...
)
Leetcode 力扣 125. 验证回文串 (抖音号:708231408)
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。 字母和数字都属于字母数字字符。 给你一个字符串 s,如果它是 回文串 ,返回 true ;否则&#…...
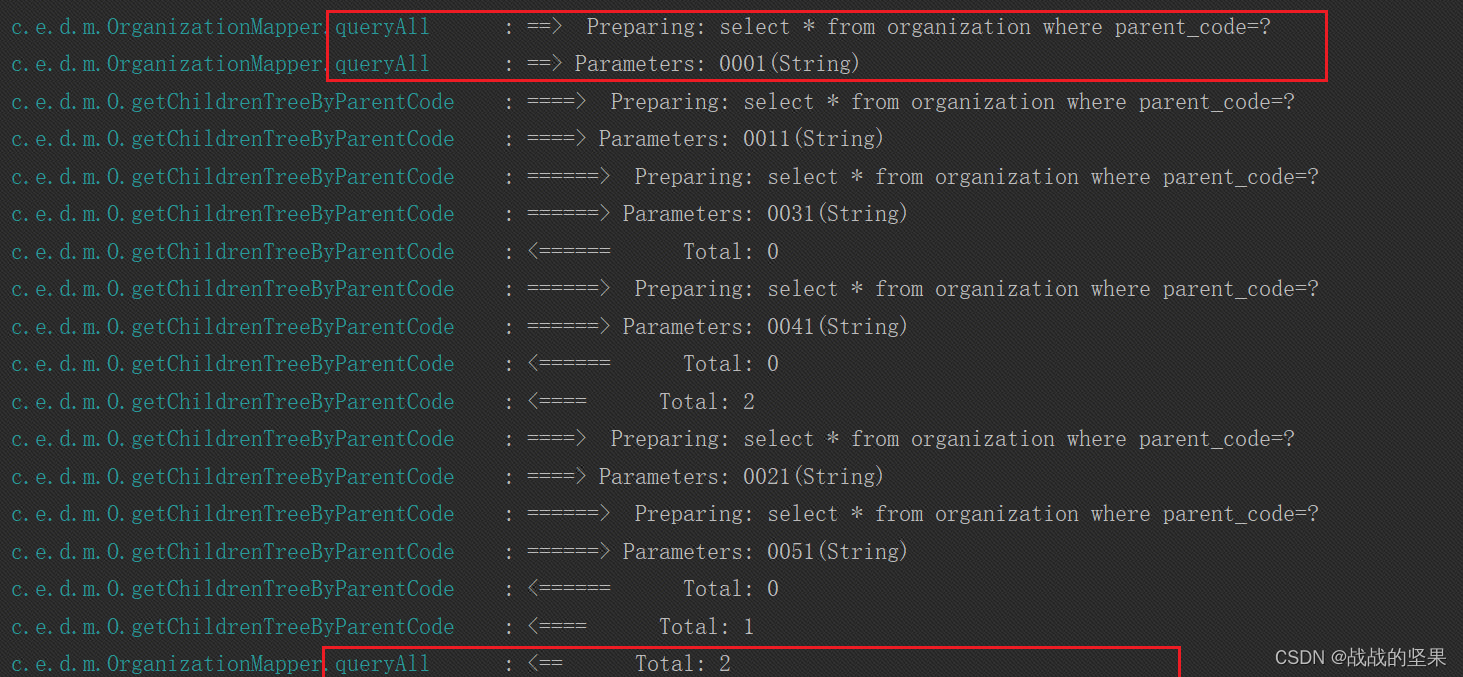
Java程序递归及mybatis递归查询
之前项目组有个需求,定时同步机构的信息。已知三方接口由于返回数据量很大,所以最后需要三方提供一个可根据机构编号获取当前机构及子机构信息的接口。而不是一次性返回全部机构信息! 由于这次需求也用到了递归,所以记录下&#…...
苹果电脑安装双系统步骤 教你苹果电脑如何装双系统
许多人刚买来苹果电脑时,对苹果的IOS操作系统比较陌生,显得非常不适应,都会去想吧苹果电脑去安装一个自己熟悉的Windows系统,方便自己办公娱乐,那么苹果电脑安装双系统的步骤怎么样呢 小编给大家介绍下吧。 许多人刚买…...
Axios-入门
介绍 Axios对原生Ajax进行了封装,简化书写,快速开发 官网:Axios中文文档 | Axios中文网 (axios-http.cn) 入门 1引入Axios的js文件 <script src"js/axios.js"></script> 2使用Axios发送请求,并获取响应…...

Python22 Pandas库
Pandas 是一个Python数据分析库,它提供了高性能、易于使用的数据结构和数据分析工具。这个库适用于处理和分析输入数据,常见于统计分析、金融分析、社会科学研究等领域。 1.Pandas的核心功能 Pandas 库的核心功能包括: 1.数据结构ÿ…...
不同表格式下的小文件治理方式(开源RC file/ORC/Text非事务表、事务表、Holodesk表格式..)
友情链接: 小文件治理系列之为什么会出现小文件问题,小文件过多问题的危害以及不同阶段下的小文件治理最佳解决手段 小文件过多的解决方法(不同阶段下的治理手段,SQL端、存储端以及计算端) 概览 在前两篇博文中&am…...

0.7 模拟电视标准 PAL 简介
0.7 模拟电视标准PAL PAL 是一种用于模拟电视的彩色编码系统,全名为逐行倒相(Phase Alternating Line)。它是三大模拟彩色电视标准之一,另外两个标准是 NTSC 和 SECAM。“逐行倒相”的意思是每行扫描线的彩色信号会跟上一行倒相&…...

vue项目中封装element分页组件
我们都知道封装组件是为了方便在项目中使用,全局封装之后哪个模块使用直接复制就行了,分页在后台项目中用到的地方也是很多的,所以我们就全局封装一下分页组件,以后也方便在项目中使用,接下来封装的这个分页也是elemen…...

linux下docker安装与镜像容器管理
linux下docker安装与镜像容器管理 原文链接:linux下docker安装与镜像容器管理 导言 ubuntu22.04-docker engine安装,以及镜像容器管理 docker非常简单介绍 docker就是一个虚拟化容器,image是镜像,就是一个dockerfile指明这个镜…...
关卡编辑器之角色编辑)
【Unity】RPG2D龙城纷争(六)关卡编辑器之角色编辑
更新日期:2024年6月26日。 项目源码:第五章发布(正式开始游戏逻辑的章节) 索引 简介一、角色编辑模式1.将字段限制为只读2.创建角色(刷角色)3.预览所有角色4.编辑选中角色属性5.移动角色位置6.移除角色简介 上一篇完成的关卡编辑器已支持创建关卡环境(主要由地块单元组…...

【鸿蒙】鸿蒙的Stage和 FA 有什么区别
鸿蒙的Stage模型和FA(Feature Ability)模型在多个方面存在显著的区别。以下是它们之间的主要差异点: 设计思想和出发点: Stage模型:设计基于为复杂应用而开发的出发点,旨在提供一个更好的开发方式ÿ…...
JAVA小知识29:IO流(上)
IO流是指在计算机中进行输入和输出操作的一种方式,用于读取和写入数据。IO流主要用于处理数据传输,可以将数据从一个地方传送到另一个地方,例如从内存到硬盘,从网络到内存等。IO流在编程中非常常见,特别是在文件操作和…...

大学生毕业季,寄物流快递避雷指南
随着毕业季的来临,大学生们纷纷开始整理自己的行李,准备离开校园,踏入社会。 在这个过程中,寄送快递成为了一个不可或缺的环节。然而,在寄送快递的过程中,如果不注意一些细节,很容易遭遇各种“…...

别再被ipykernel报错困扰:三种方法修复Jupyter中argparse的argument错误
彻底解决Jupyter中ipykernel与argparse冲突的工程指南 当你在Jupyter Notebook中运行包含argparse模块的Python代码时,是否遇到过这样的报错: ipykernel_launcher.py: error: argument --no-cuda: expected one argument这个看似简单的错误背后ÿ…...
)
实验室小白避坑指南:在浪潮AiStation上从零部署PyTorch项目(含离线环境打包)
实验室科研实战:浪潮AiStation离线部署PyTorch全流程解析 当实验室服务器遭遇网络隔离与资源限制时,如何高效部署深度学习项目成为每个科研新手的必修课。本文将针对浪潮AiStation平台的特殊性,系统梳理从环境准备到代码运行的完整闭环&#…...

书匠策AI官网www.shujiangce.com:期刊论文从“渡劫“到“躺赢“,中间只差这一个工具
家人们,今天不讲课,今天带你们"开箱"一个我私藏很久的论文神器。 先说结论——书匠策AI( 官网直达:www.shujiangce.com) 的期刊论文功能,是我今年用过最"懂科研人"的AI工具ÿ…...

SLO-Warden:云原生时代SLO自动化管理的工程实践
1. 项目概述:当SLO成为运维的“紧箍咒”在云原生和微服务架构成为主流的今天,服务的稳定性和可靠性不再是锦上添花,而是业务的生命线。对于运维工程师和SRE(站点可靠性工程师)而言,我们每天都在和各种指标、…...

硅与锗PN结实战对比:手把手测量导通电压VF与温度系数
硅与锗PN结实战对比:手把手测量导通电压VF与温度系数 在电子工程实践中,PN结的特性测量是理解半导体器件行为的基础。硅(Si)和锗(Ge)作为两种经典半导体材料,其PN结在导通电压(VF)和温度特性上表现出显著差异。本文将带领读者通过实际测量&a…...

arXiv论文源码怎么复用?手把手教你用Overleaf导入、编译与二次创作
arXiv论文源码复用指南:Overleaf导入、编译与二次创作全解析 当你从arXiv下载了一篇论文的LaTeX源码压缩包,却发现本地环境配置复杂、依赖缺失或路径错误导致编译失败时,这篇文章将成为你的救星。我们将以Overleaf为工具,深入解决…...

GitHub代码仓库导航:开发者如何高效构建与使用技术资源地图
1. 项目概述:一个面向开发者的代码仓库导航 最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫 yeabnoah/vx_code 。乍一看这个标题,可能会有点摸不着头脑, vx_code 是什么?是某种新的编程语言…...

从需求到建表:我是如何用一张ER图搞定客户复杂业务逻辑的
从需求到建表:我是如何用一张ER图搞定客户复杂业务逻辑的 接手电商系统重构项目的第一天,客户甩过来二十多页需求文档和五张不同版本的Excel表。"这些数据都要关联起来",产品经理指着密密麻麻的字段说,"但具体怎么…...

别再被SAR图像上的‘雪花点’骗了!手把手教你理解相干斑噪声的底层原理
别再被SAR图像上的‘雪花点’骗了!手把手教你理解相干斑噪声的底层原理 第一次接触SAR图像时,那些密密麻麻的"雪花点"总让人误以为是设备故障或数据损坏。这种视觉上的"噪声"其实是合成孔径雷达(SAR)成像中特…...

在OpenClaw中配置Taotoken作为其AI模型供应商的详细步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw中配置Taotoken作为其AI模型供应商的详细步骤 OpenClaw是一个功能强大的AI智能体开发框架,它允许开发者灵活…...