不同表格式下的小文件治理方式(开源RC file/ORC/Text非事务表、事务表、Holodesk表格式..)
友情链接:
小文件治理系列之为什么会出现小文件问题,小文件过多问题的危害以及不同阶段下的小文件治理最佳解决手段
小文件过多的解决方法(不同阶段下的治理手段,SQL端、存储端以及计算端)
概览
在前两篇博文中,主要为读者从源头介绍了小文件出现的原因、对业务对集群的危害,以及在不同阶段下的处理手段,希望能为您理解以及治理小文件有所帮助。
本篇文章将为您介绍在不同表格式下如何处理。尤其是非事务表跟事务表,为什么要单独拎出这两个表格式后面会为您揭晓。
前情提要
存储端合并主要是合并已经写入到存储的文件,当表中有小文件或者小文件过多时,可以使用下述存储端合并的方式进行合并以达到减少文件数量、降低存储开销提高数据读写效率的目的。存储端合并的方式主要适用于以下原因导致的小文件问题:
- 频繁的写入数据;
- torc表compact多次合并失败后进入黑名单,导致小文件不再继续合并;
- 历史数据流程导致小文件问题,这些数据一般是从别的数据库迁移过来,后续没有进行治理;
需要注意的是,不同表格式的合并方式并不相同。
Torc事务表
Torc事务表是一种可以支持CRUD操作的的ORC表,其基本原理是对于每一次CRUD操作(insert,update,delete,merge into),都生成一个对应版本存放改动的数据(delta目录)。
星环的Inceptor系统中设计了compact机制(提供手动及自动方式),会定期对每个orc transaction进行合并,将多个版本合并成一个版本(base目录)。
操作实践
以星环TDH社区版核心组件Inceptor为例,因此下面将以具体例子来演示TORC表中Compact的过程:
1. 创建一张orc transaction表
create table orc_transaction_table(
id int, value1 int, value2 int, value3 int
) clustered by (id)
into 2 buckets
stored as orc tblproperties('transactional'='true');建好表之后用desc formatted orc_transaction_table命令来获取该表在hdfs上的位置
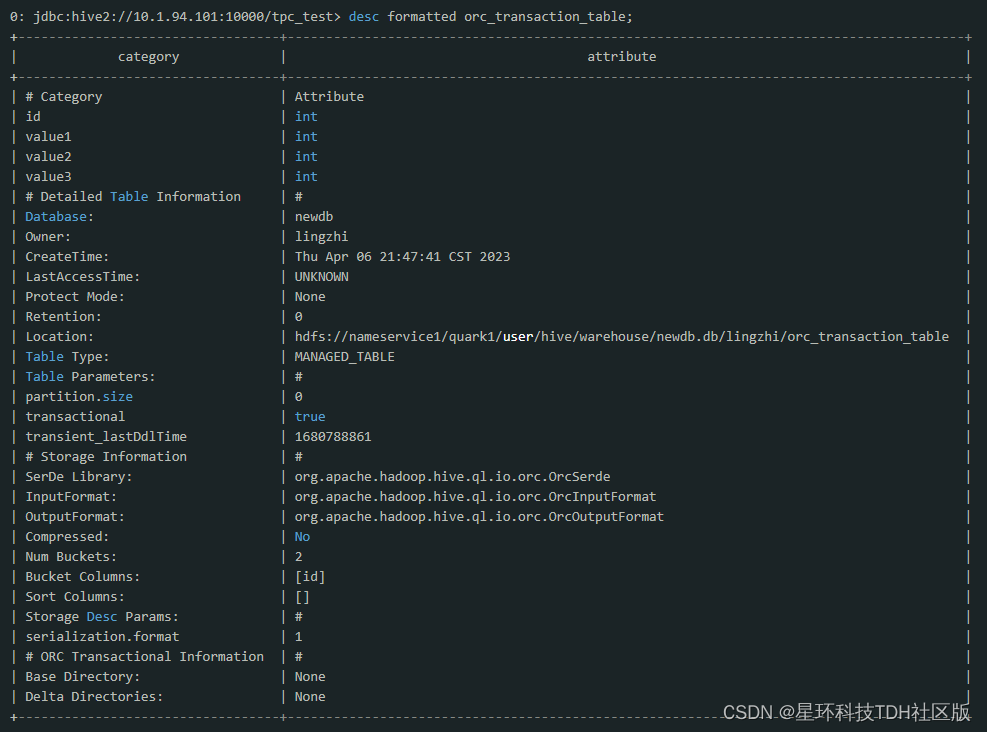
通过hdfs命令来看当前表所在目录下的内容

可以看到表创建好时,目录是空的。
2. 插入数据
用insert语句向该表插入一条数据:
insert into orc_transaction_table values(1,2,3,4); 这时候重新查看hdfs再看表目录:

可以看到多了一个delta开始的目录,这种delta目录就对应了表的一个版本,delta中的数字代表该crud操作的transaction号。
3. 更新数据
用update命令更新该表并观察hdfs上的内容:
update orc_transaction_table set value3 = 10 where id = 1;重新查看

可见update操作为表添加了一个新的版本。
4. Compact机制
对于orc表的多个版本,inceptor系统中专门有compact机制来负责在合适的时候对多版本进行合并。目前compact由metastore的compact thread在后台自动检测并合并。同时也可以通过命令alter table tablename compact compactType来手动触发compact,例如:
alter table orc_transaction_table compact 'major';注意:alter table compact命令是异步的,该命令本身只是发出一个compact请求,其本身并不做compact操作,所以很快会结束。
目前,compact任务根据配置可以是一个mapreduce任务,也可以是spark任务(下面的示例我们将以mapreduce的方式进行compact)。
- 当设置orc.compact.service.provider=metastore 时,compact threads内嵌在metastore中,compact任务是一个mapreduce任务;我们可以在yarn的8088页面上看到(compact任务的名称类似与test-02-23-compactor-crud001.orc_transaction_table);
- 当设置orc.compact.service.provider=server时,compact threads内嵌在server中,compact任务是一个spark任务,我们可以在spark的4040页面上看到(compact任务的sql类似于compact xxx ‘major’);
查看compact由metastore还是compactservice执行:
show compact location;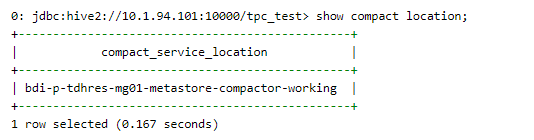
注:设置orc.compact.service.provider=metastore或者orc.compact.service.provider=server时要设置在hive-site里面, 不能直接beeline中set;或者也可以在manager里面加配置, 然后重启;
我们可以在yarn的8088页面上看到(compact任务的名称类似与test-02-23-compactor-crud001.orc_transaction_table);
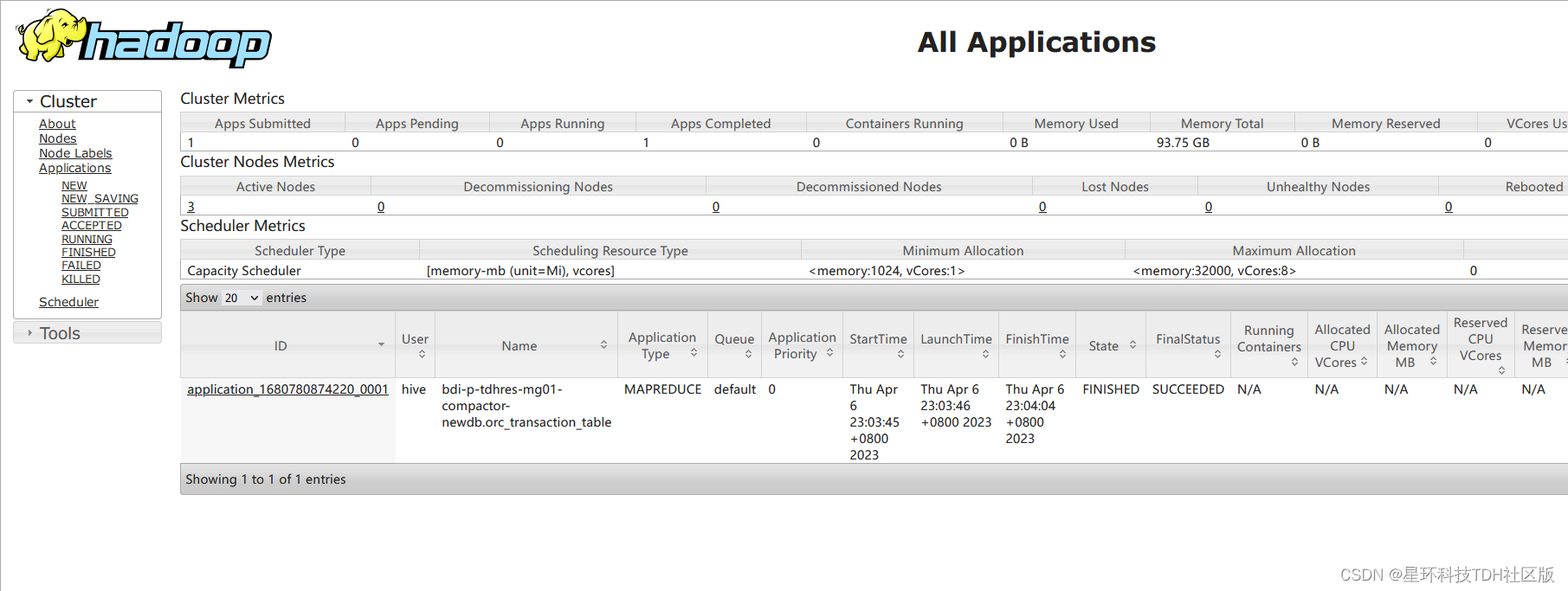
在compact任务成功结束之后,再观察hdfs上的内容:
可见major compact后,系统会产生一个base开始的目录,记录了到transaction号0000081为止,该表的全部内容。

如果在往该表插入新的记录,则会生产新的delta版本:

一段时间之后在查看hdfs目录可以发现这两个版本被自动合并成了一个新版本:

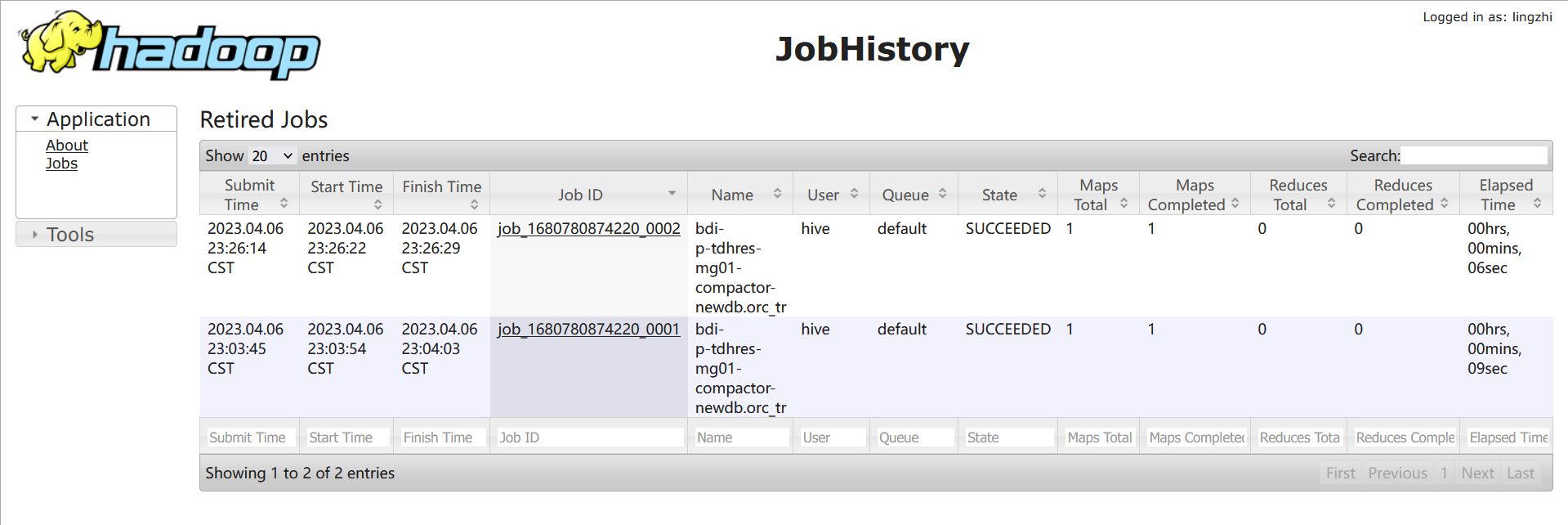
这是compact thread在后台自动做的compact,目前后台的compact触发条件是:
- 当系统中没有base版本,则当delta版本大于10时触发major compact;
- 当系统中有base版本,则当所有delta版本的数据量达到base版本数据量的10%或者delta版本个数大于50时,自动触发major compact;
这些触发条件都是可以配置的,分别对应于参数:
- hive.compactor.delta.num.threshold.without.base default value 10
- hive.compactor.delta.num.threshold default value 50
- hive.compactor.delta.pct.threshold default value 0.1
Compact结果校验方式
torc普通表
1) 通过desc formatted pre_torc1_2查看delta文件是否合并成了base文件
2) 表compaction_queue_v中的compaction_state的值
3) show compactions;
4) hdfs路径
torc分区表
1) 表compaction_queue_v中compaction_state的值
2) show compactions;
3) hdfs路径
由于篇幅原因,更多介绍、操作教程及常见报错与解决方案详见:https://community.transwarp.cn/article/271
Holodesk表
Inceptor作为一款批处理引擎已经逐渐成熟,在星环许多客户的生产实践中,提供了高性能的海量数据处理能力。
但是orc格式的表对于少量数据的随机查询场景,存在着一些不足,因此为了满足客户对于高性能数据分析场景的需求,星环于2016年推出Holodesk存储格式,针对随机读写进行了深度优化,实现了数倍于orc的分析性能。
Holodesk对满足以下特征的场景表现出了极强的处理能力,因此建议对这些场景创建Holodesk表:
-
当机器拥有很大的内存或者部署了SSD时。
-
过滤高的场景,包括单表扫描和多表MapJoin等。
-
聚合率高的场景,例如GROUP BY之后,信息被大量聚合
Holodesk表与Torc表delta跟base文件产生的条件不一样,其所有的写操作都会在底层写入一个新的文件,而不是写入已有文件中。其中,insert操作生成新的base文件, update/delete操作生成新的delta文件。对于Holodesk表星环同样提供了Compact机制,用户可以根据业务特点来设置一些参数自定义小文件的自动合并策略以平衡小文件数量和合并开销,比如设置定期合并策略或者设置触发阈值等。
针对Holodesk表用户还可以使用星环新推出的Compact Service(小文件合并专用服务)进行小文件合并任务。
常见的小文件合并功能是通过计算引擎服务来执行 Compact 任务的,可能会占用部分计算资源。新推出的Compact Service则在组件级别做了隔离,开启后不会影响到Quark的查询计算性能,合并效果更好。
除了自动合并机制之外,用户也可以通过在星环运维管理平台DBA Service查看当前的小文件数量,管理Compact任务,如果检查发现小文件数量过多,可以通过同步或异步的方式手动执行小文件合并任务,减少小文件数量。
由于篇幅原因,更多操作教程及介绍详见:https://community.transwarp.cn/article/1056
Orc表/Text表
对于holodesk及torc表用户可以采用自动或手动的形式进行合并,或者使用最新的Compact Service,但是针对text及orc非事务表来说,一直以来没有一个很完美的合并方法。这是因为非事务表不像事务表有文件合并的逻辑。
非事务表与事务表的合并逻辑差异
事务表需要严格遵循ACID(原子性、一致性、隔离性、持久性)特性,确保在并发操作和错误恢复情况下数据的完整性和一致性。因此,为了维护这些特性,事务表需要复杂的机制来管理数据操作,比如锁机制和日志记录,其中也包括对文件进行合并以确保数据一致性和性能。
但是非事务表由于并不需要严格遵循ACID特性,适用于需要快速写入和读取的大数据应用以及分析和数据仓库的场景下,因此并不需要涉及复杂的事务管理机制。
因此不同的应用场景和需求决定了非事务表跟事务表在文件合并逻辑上的差异。
但是!!在实际业务比如跑批场景中,经常会涉及ORC等非事务表,随着每日增量数据的插入以及可能的数据重复插入,HDFS上的文件数与日俱增,达到千万甚至上亿的级别!!经常会发现集群中有上千万个大小仅有KB~MB之间的小文件。这些小文件数量严重的制约了集群的稳定运行,对HDFS以及Inceptor组件的稳定性影响也很大,比如出现长GC,OOM等。
因此,非事务表的合并机制也至关重要。
为什么星环要专门做一个合并功能,而非采用开源方案?
开源方案的弊端:
- 合并小文件需要根据每一张表的数据量和分布情况,手动编写任务进行重写来实现小文件合并的效果,在这个过程中,表只能读不能写;
- 由于小文件合并是一个资源密集型的操作,可能会影响到正在运行的任务的性能和资源利用率,所以开源方案的合并作业通常会放置于数据处理流程的末端,也就是数据存储到 HDFS 后的后处理阶段执行,无法及时清理;
前面的章节有提到,任务的各个流程跟步骤中都有可能会产生大量的小文件。所以开源方案在任务运行结束后再去扫描进行合并并不能从根本上预防以及根治小文件过多的问题,而且在这个过程中表相关的业务会受影响。
除了这个原因之外,开源方案的小文件合并机制在保障数据一致性与原子性方面也存在一些局限性。
原子性问题
- 小文件合并通常会涉及多个阶段,包括读取原始文件、将其内容写入新的大文件、删除原文件等等。但是,如果这些步骤不能在一个原子操作中完成(即要么全部成功,要么全部失败),就可能在合并过程中出现中间状态。比如,某些小文件已经被读取和写入新文件,但尚未删除旧文件,或者新文件还未完全写入完成。这种中间状态可能会导致数据的不一致性。
- 而且,如果在合并过程中发生故障(节点崩溃或网络中断),合并操作可能会中断,留下不完整的文件或重复的数据,最终导致原子性无法保障。
一致性问题
- 在分布式环境中,经常会出现多个进程同时尝试访问和操作相同的小文件的情况,可能会有新的数据写入或修改操作。但是非事务表本身在设计上没有像事务表一样有那么严格的锁机制或事务管理,所以这些并发操作极大可能会导致数据冲突和不一致。例如,一个进程正在读取和合并某些小文件,而另一个进程可能同时写入这些文件,最终会导致合并后的文件与原始数据不一致。
- 合并小文件不仅涉及数据文件本身,还涉及元数据。像HDFS是使用NameNode来管理文件系统的元数据的,其中包括文件的目录结构和文件块的位置。小文件合并通常会涉及对元数据的多次修改(比如更新文件块信息、删除旧文件记录等)。如果这些修改不能保证在所有NameNode副本之间的一致性,可能就会导致NameNode视图与实际数据不一致。
所以综上所述,目前开源方案针对小文件合并机制还面临着诸多挑战,这些挑战主要源于非事务表原生不支持事务操作,这使得很难在多个文件操作间保持严格的一致性和原子性。
因此如果想要实现在确保小文件合并效率的同时充分保障文件操作间的一致性与原子性,还需要额外设计一些机制以及逻辑控制。
这就是为什么星环要设计一个新的合并方案来解决开源方案中的不足。
星环Galactus应运而生!!Galactus可以自动检测到小文件自动合并掉,用户无需担心因为处理不及时或有疏漏影响到业务系统,更加贴合生产上的需求。(该功能已在新版本社区版中进行支持,感兴趣的读者可以下载体验,下载地址:TDH社区版-TDH Community Edition-星环科技)
星环是怎么做的?为什么不采用TORC Compact的逻辑?
TORC Compact是靠事务锁和事务ID来保证原子性以及读数的正确性的。所以事务表在合并一开始便会获取读锁,其他会造成影响的如truncate需要获取排他锁,所以truncate必须等到整个合并完成,这样才能保证合并过程的原子性;同时在读数的时候根据base的事务ID去过滤掉事务ID比它小的base和delta,保证了不会多读数。
但是对于非事务表来说,是没有这两个属性的,需要强行加上类似的锁机制和类事务ID来保证原子性以及确保不会多读数。
所以,星环的非事务表小文件合并设计方案设计了一些算法以及采用editlog reply机制实现了在没有事务控制下保证合并过程中的原子性以及不会多读数的目标。
对于实际业务来说,星环方案有哪些独特的优势?
- 在Compaction过程中,计算引擎端(quark)的业务,表的读,写,删除等操作能够不被长时间阻塞,并成功执行不报错;
- 即使客户通过HDFS CLIENT操作数据目录,合并也不会造成数据的丢失或增加;
- 开源产品如Hive/Spark也能用该方案解决小文件问题;
- 完善的回退机制,保证了数据的正确性以及editlog能被原HDFS正常重放,恢复到合并前;
- 该方案针对多次访问文件产生的大量开销做了优化,并且针对多个异常现象,如NN重启或者主从切换、合并前/中/后发生了目录或文件的mv,cp,truncate等操作,该方案都做了完备的处理机制,以保障系统整体的一致性、原子性以及正确性。
客户案例
星环某一客户系统中共有72个库,近万张表,其中Quark 数据目录下共约3600万个文件,除此之外,每天平均入库40~50万个文件。
在开启Galactus一周后,系统文件数量减少了13%,每天合并80万个小文件,充分覆盖了增量文件。整体的绩效业务跑批性能提升了一倍以上。
截至目前,该功能共计为客户合并了9000w+个小文件,文件对象从8600w+降低至6900w+。
由于篇幅原因,更多使用demo以及最佳实践教程详见:小文件救星来了!!Text/ORC非事务表合并最佳方式
相关文章:
不同表格式下的小文件治理方式(开源RC file/ORC/Text非事务表、事务表、Holodesk表格式..)
友情链接: 小文件治理系列之为什么会出现小文件问题,小文件过多问题的危害以及不同阶段下的小文件治理最佳解决手段 小文件过多的解决方法(不同阶段下的治理手段,SQL端、存储端以及计算端) 概览 在前两篇博文中&am…...

0.7 模拟电视标准 PAL 简介
0.7 模拟电视标准PAL PAL 是一种用于模拟电视的彩色编码系统,全名为逐行倒相(Phase Alternating Line)。它是三大模拟彩色电视标准之一,另外两个标准是 NTSC 和 SECAM。“逐行倒相”的意思是每行扫描线的彩色信号会跟上一行倒相&…...

vue项目中封装element分页组件
我们都知道封装组件是为了方便在项目中使用,全局封装之后哪个模块使用直接复制就行了,分页在后台项目中用到的地方也是很多的,所以我们就全局封装一下分页组件,以后也方便在项目中使用,接下来封装的这个分页也是elemen…...

linux下docker安装与镜像容器管理
linux下docker安装与镜像容器管理 原文链接:linux下docker安装与镜像容器管理 导言 ubuntu22.04-docker engine安装,以及镜像容器管理 docker非常简单介绍 docker就是一个虚拟化容器,image是镜像,就是一个dockerfile指明这个镜…...
关卡编辑器之角色编辑)
【Unity】RPG2D龙城纷争(六)关卡编辑器之角色编辑
更新日期:2024年6月26日。 项目源码:第五章发布(正式开始游戏逻辑的章节) 索引 简介一、角色编辑模式1.将字段限制为只读2.创建角色(刷角色)3.预览所有角色4.编辑选中角色属性5.移动角色位置6.移除角色简介 上一篇完成的关卡编辑器已支持创建关卡环境(主要由地块单元组…...

【鸿蒙】鸿蒙的Stage和 FA 有什么区别
鸿蒙的Stage模型和FA(Feature Ability)模型在多个方面存在显著的区别。以下是它们之间的主要差异点: 设计思想和出发点: Stage模型:设计基于为复杂应用而开发的出发点,旨在提供一个更好的开发方式ÿ…...
JAVA小知识29:IO流(上)
IO流是指在计算机中进行输入和输出操作的一种方式,用于读取和写入数据。IO流主要用于处理数据传输,可以将数据从一个地方传送到另一个地方,例如从内存到硬盘,从网络到内存等。IO流在编程中非常常见,特别是在文件操作和…...

大学生毕业季,寄物流快递避雷指南
随着毕业季的来临,大学生们纷纷开始整理自己的行李,准备离开校园,踏入社会。 在这个过程中,寄送快递成为了一个不可或缺的环节。然而,在寄送快递的过程中,如果不注意一些细节,很容易遭遇各种“…...
如何提高项目风险的处理效率?5个重点
提高项目风险的处理效率,有助于迅速识别和应对风险,减少风险导致的延误,降低成本,提升项目质量,确保项目按时交付。如果项目风险处理效率较低,未能及时发现和处理风险,导致问题累积,…...
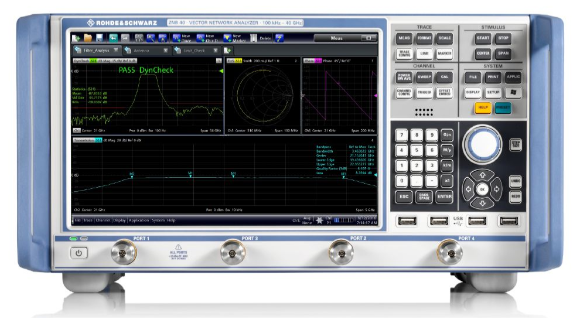
ZNB40 矢量网络分析仪
ZNB40 矢量网络分析仪 100kHz至40GHz的宽频率范围,具有四个端口和附加信号发生器 概述 R&SZNB40 提供 100 kHz 至 40 GHz 的宽频率范围,具有四个端口和附加信号发生器。 罗德与施瓦茨带四个端口和附加内部信号源的 40 GHz 中档矢量网络分析仪&…...

ingress代理前后端服务跨域
一、前言 ingress对于前后端服务的代理有不同的方式可以实现,前后端服务可以通过不同的域名实现流量的分流策略,不过这需要解决前后端域名不同产生的跨域问题,也可以通过不同的path实现流量的分流策略,该方式不会产生跨域的问题 …...

Python 使用 Thick 方式连接 Oracle Database BaseDB 23ai
Python 使用 Thick 方式连接 Oracle Database BaseDB 23ai 1. 下载Basic.zip 和SQL*Plus(.zip)2. 配置环境变量3. 连接 23ai 1. 下载Basic.zip 和SQL*Plus(.zip) 到 https://www.oracle.com/database/technologies/instant-clien…...
)
Java操作Redis(通过Jedis)
一、环境搭建 这里我使用的SpringBoot版本是2.6.3,所以我引入的Jedis相关版本也不是很高 <dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.2.0</version></dependency><…...

JVM专题二:Java如何进行编译的
编程语言分类 通常我们将编程语言分为高级语言和低级语言,通常高级语言因为其易用性和可移植性而被广泛使用,而低级语言在需要对硬件进行精细控制时非常有用,例如在嵌入式系统编程或操作系统开发中。 高级语言更接近人类语言,易于…...
道路元素位置和方向的坐标系统: 点 线 面 连接点
道路元素位置和方向的坐标系统: 下图道路元素在地球坐标系中的位置,该位置由三个坐标轴(x, y, z)组成的笛卡尔坐标系来确定。这种描述特别适用于三维建模和地理信息系统(GIS)中,其中道路被视为一个三维模型…...

二、Docker常用命令
一、帮助启动类命令 1、启动docker [rootlocalhost ~]# systemctl start docker 2、停止docker [rootlocalhost ~]# systemctl stop docker 3、重启docker [rootlocalhost ~]# systemctl stop docker 4、查看docker状态 [rootlocalhost ~]# systemctl status docker 5、开机自…...

通过docker启动Jenkins容器报错
项目场景: 通过docker启动Jenkins容器 问题描述 Jenkins容器启动失败,通过sudo docker logs -f jenkins命令 查看日志如下: touch: cannot touch ‘/var/jenkins_home/copy_reference_file.log’: Permission denied Can not write to /var…...

webui automatic1111上可以跑stable diffusion 3的方法
stable diffusion 3 可以简单句子生成高质量图形,可以生成准确的文字,甚至可以支持中文。 stable diffusion 3 最初只支持API调用,最后把模型也完全开放了。Comfyui因为天生架构优势,第一时间跑起来了。既支持远程API模型调用&am…...

基于顺序表基础实现通讯录项目
基于顺序表基础实现通讯录项目 前言通讯录的实现 前言 Hello,亲爱的CSDN的小伙伴们,你们好!基于上一篇博客的基础上,今天我来带领大家实现通讯录项目,上一篇博客在这里哦!顺序表的实现 通讯录的实现 顺序表的实现在…...

加班的员工,循环的电池
宁德时代回应"896" 6月17日,宁德时代因内部宣告「实行 895 工作制,大干 100 天,外籍人员不强制」冲上热搜,虽后来辟谣 只是发出号召,并无强制员工实行"895"工作制,但舆论并无消退。 昨…...

爱普生SG-8201CJ石英可编程振荡器:精准频率控制,高效能工业级应用首选
引言在电子设计中,晶振是不可或缺的元器件,它为整个系统提供精准的时间基准。然而,面对市场上琳琅满目的晶振产品,工程师们常常感到选型困难,特别是在需要高精度、高稳定性和快速交付的情况下。今天,我们就…...

AI赋能Anki:基于LLM与Prompt工程的智能制卡技能全解析
1. 项目概述:当Anki遇上AI,一个卡片技能的革命如果你和我一样,是个重度Anki用户,那你一定经历过这样的时刻:面对一本厚厚的教科书,或者一篇几十页的论文,想要把里面的核心知识点做成记忆卡片&am…...

2026届最火的五大AI论文助手推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 由于人工智能生成内容也就是AIGC被广泛运用,互联网里到处都是由AI生成的&#x…...

京东自动评价工具:Python智能购物助手终极指南
京东自动评价工具:Python智能购物助手终极指南 【免费下载链接】jd_AutoComment 自动评价,仅供交流学习之用 项目地址: https://gitcode.com/gh_mirrors/jd/jd_AutoComment 想要轻松完成京东购物后的评价任务吗?jd_AutoComment 是一款基于Python开…...

iOS 17-26越狱终极指南:5个安全解锁iPhone隐藏功能的专业方法
iOS 17-26越狱终极指南:5个安全解锁iPhone隐藏功能的专业方法 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项…...

告别Keil!用STM32CubeIDE给STM32F103C8T6做双路ADC采样,DMA+中断实战避坑
从Keil到STM32CubeIDE:双路ADC采样与DMA中断实战全解析 当传统嵌入式开发遇上现代化工具链,迁移过程中的技术决策往往比想象中更复杂。对于长期使用Keil MDK的开发者而言,转向STM32CubeIDE不仅意味着开发环境的改变,更涉及从寄存器…...

tchMaterial-parser:基于智能解析引擎的教育资源去中心化获取方案
tchMaterial-parser:基于智能解析引擎的教育资源去中心化获取方案 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容。…...

GHelper终极指南:3步掌握华硕笔记本性能控制秘籍
GHelper终极指南:3步掌握华硕笔记本性能控制秘籍 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expertb…...

自建个人知识库:基于开源项目构建私有化数字记忆管理系统
1. 项目概述:一个为数字记忆打造的私人保险库 如果你和我一样,在数字世界里积攒了海量的信息碎片——可能是随手保存的网页文章、偶然看到的精彩推文、一段触动心弦的播客片段,或者仅仅是某个深夜迸发的灵感火花——那么你一定也面临过同样的…...

如何用 curl 命令快速测试 Taotoken 的 API 是否连通
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何用 curl 命令快速测试 Taotoken 的 API 是否连通 在接入大模型服务时,直接使用 curl 命令测试 API 是最基础、最直…...