Day15 —— 大语言模型简介
大语言模型简介
- 大语言模型基本概述
- 什么是大语言模型
- 主要应用领域
- 大语言模型的关键技术
- 大语言模型的应用场景
- NLP
- 什么是NLP
- NLP的主要研究方向
- word2vec
- word2vec介绍
- word2vec的两种模型
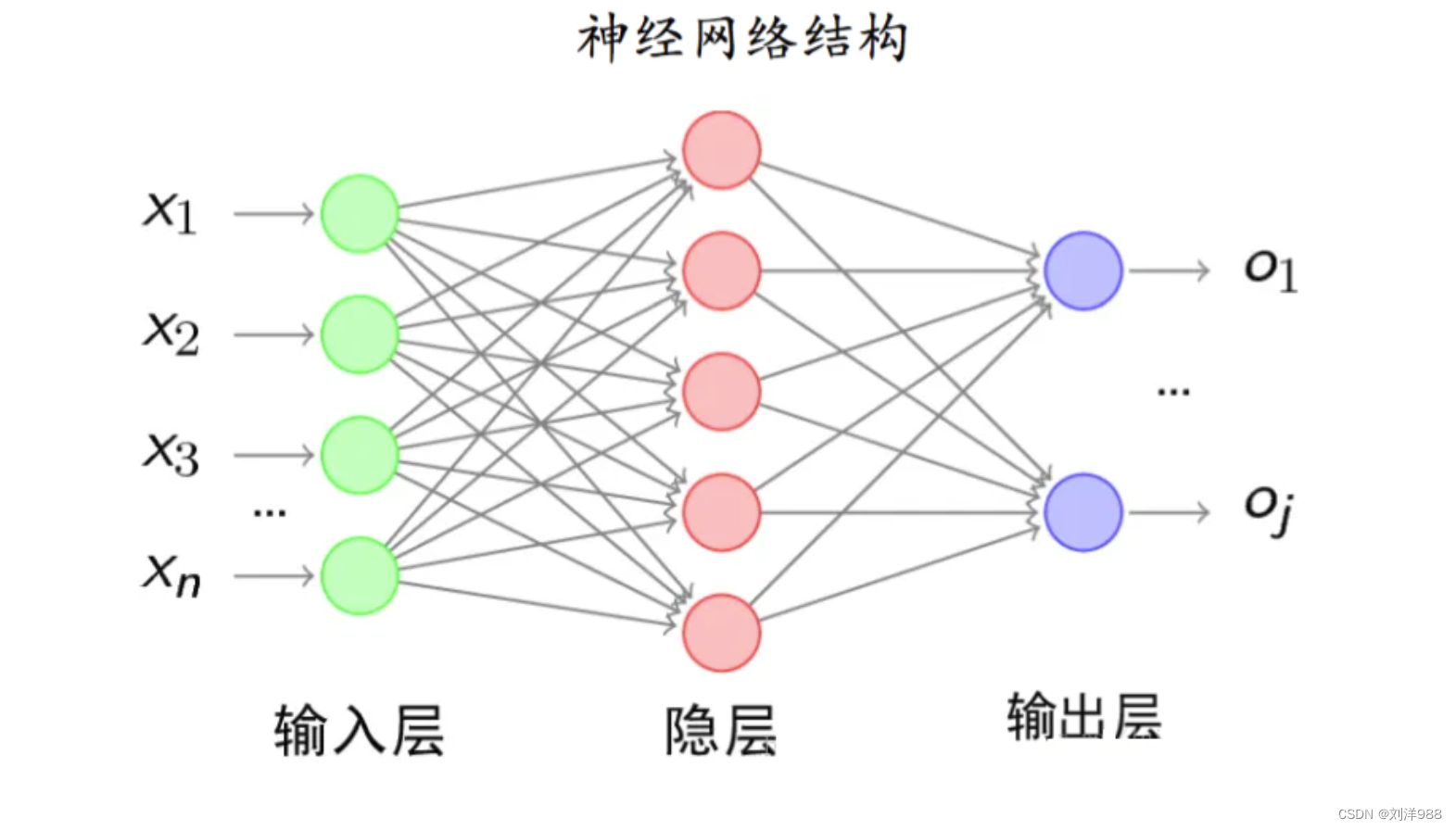
- 全连接神经网络
- 神经网络结构
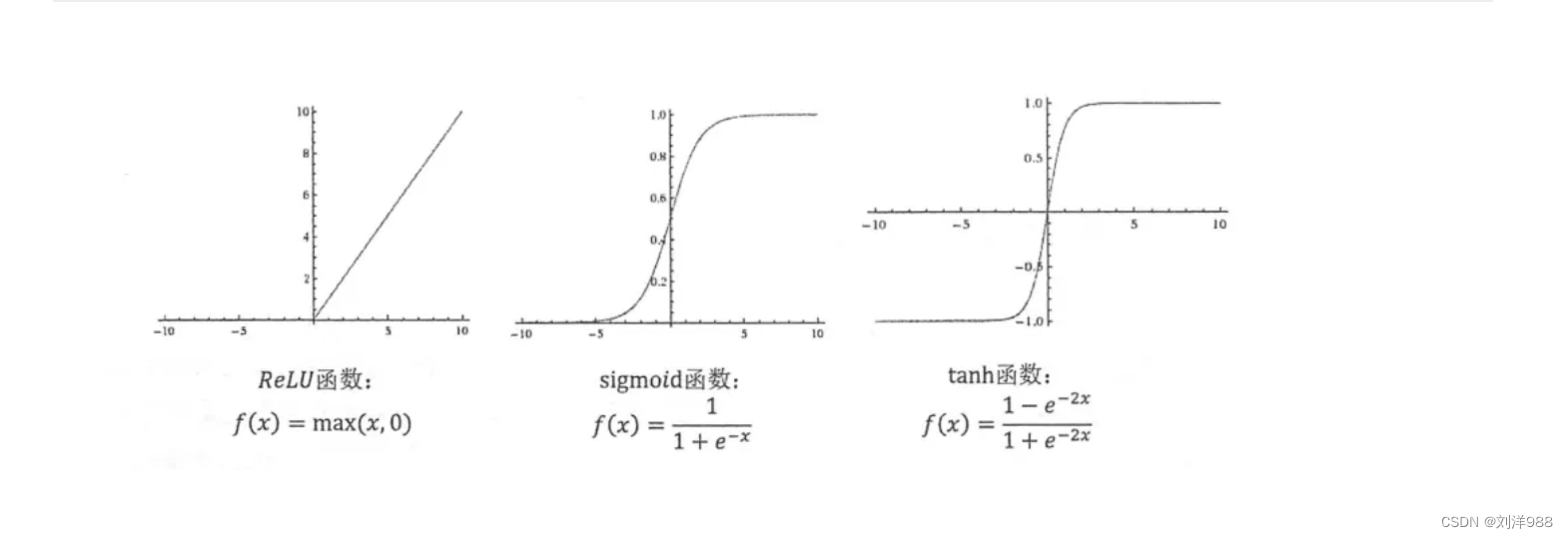
- 神经网络的激活函数
- 解决神经网络过拟合问题的方法
- 前向传播与反向传播
- 前向传播
- 反向传播(Back Propagation,BP)
- RNN
- 认识RNN
- RNN的应用领域
- 常见的RNN模型
- LSTM
- 认识LSTM
- LSTM的“门结构”
- Seq2Seq模型
- Seq2Seq表现形式
- Encoder+Decoder
- Attention模型
- 引入Attention模型的必要性
- Seq2Seq+Attention模型
- Encoder-Decoder框架
- Attention模型
- Attention机制的本质思想
- Attention 原理的3步分解
- Self Attention自注意力模型
- Transformer模型
大语言模型基本概述
什么是大语言模型
大语言模型(Large Language Models)是一种基于深度学习的自然语言处理(NLP)模型,用于处理和生成人类语言文本。
主要应用领域
- 自然语言理解(NLU)
- 文本分类
- 信息抽取
- 情感分析
- 命名实体识别
- 自然语言生成(NLG)
- 文本生成
- 摘要生成
- 机器翻译
- 对话生成与响应
大语言模型的关键技术
- 预训练技术:预训练语言模型,自回归模型,Transformer结构。
- 深度学习技术:神经网络,激活函数,注意力机制。
- 自然语言处理技术:分词技术,词向量表示,句法分析。
- 迁移学习技术:知识蒸馏,多任务学习,增量学习
大语言模型的应用场景
-
智能客服:
大语言模型可以通过理解客户的问题和需求,提供准确、及时的答案和建议,提高客户满意度。大语言模型可以针对常见问题编写自动化回复脚本,减轻人工客服的工作负担,提高服务效率。大语言模型可以通过情感分析技术,理解客户的情感和情绪,以便更好地满足客户需求。 -
智能写作
大语言模型可以运用自然语言生成技术,快速生成高质量的文章、新闻报道和文案等文本内容。大语言模型也可以进行诗歌创作,能够根据特定主题或要求,创作出具有意境和韵律的诗歌。大语言模型可以实现不同语言之间的文本翻译,为跨文化交流提供便利。 -
智能推荐
大语言模型可以通过分析用户的历史行为和喜好,实现个性化推荐,提高用户满意度。大语言模型可以根据用户的兴趣和行为,精准投放广告,提高广告效果和转化率。大语言模型可以分析大量内容,过滤掉不良信息,为用户提供更加安全、健康的内容环境。
NLP
什么是NLP
NLP(Natural Language Processing),即“自然语言处理”,主要研究使用计算=机来处理、理解及运用人类语言的各种理论和方法,属于人工智能的一个重要研究方向。简单来说,NLP就是如何让计算机理解人类语言。
NLP的主要研究方向
NLP是一个庞大的技术体系,研究方向主要包括机器翻译、信息检索、文档分类、问答系统、自动摘要、文本挖掘、知识图谱、语音识别、语音合成等。相较于CNN重点应用于计算机视觉领域,RNN则更多地应用于NLP方向。
word2vec
word2vec介绍
word2vec是一种基于神经网络的词嵌入技术,通过训练神经网络得到一个关于输入X和输出Y之间的语言模型,获取训练好的神经网络权重,这个权重是用来对输入词汇X进行向量化表示的。
word2vec的两种模型
-
CBOW模型
CBOW(Continuous Bag-of-Words Model),即“连续词袋模型”,其应用场景是根据上下文预测中间词,输入X是每个词汇的one-hot向量,输出Y为给定词汇表中每个词作为目标词的概率。
-
Skip-gram模型
也称为"跳字模型",应用场景是根据中间词预测上下文词,所以输入X为任意单词,输出Y为给定词汇表中每个词作为上下文词的概率。
全连接神经网络
神经网络结构
神经网络的激活函数
解决神经网络过拟合问题的方法
-
正则化
与很多机器学习算法一样,可以在待优化的目标函数上添加正则化项(例如L1、L2正则),可以在一定程度减少过拟合的程度。
-
Dropout(随机失活)
可以将Dropout理解为对神经网络中的每一个神经元加上一道概率流程,使得在神经网络训练时能够随机使某个神经元失效。
前向传播与反向传播
前向传播
计算输出值的过程称为“前向传播”:将上一层的输出作为下一层的输入,并计算下一层的输出,一直到运算到输出层为止。
反向传播(Back Propagation,BP)
反向传播(BP)根据根据J的公式对W和b求偏导,也就是求梯度。因为我们需要用梯度下降法来对参数进行更新,而更新就需要梯度。
RNN
认识RNN
RNN(Recurrent Neural Network),即"循环神经网络",是在基础神经网络模型中增加了循环机制。具体的表现形式为网络会对前面的信息进行记忆并应用于当前的计算中,即当前时刻利用了上一时刻的信息,这便是“循环”的含义。
RNN的应用领域
- 语音识别
- OCR识别(optical character recognition)
- 机器翻译
- 文本分类
- 视频动作识别
- 序列标注
常见的RNN模型
LSTM
认识LSTM
LSTM是Long-Short Term Memory的缩写,中文名叫长短期记忆网络,它是RNN的改进版本。为了更好地解决“梯度爆炸”和“梯度消失”的问题,让RNN具备更强、更好的记忆,于是就出现了LSTM。
LSTM的“门结构”
LSTM的关键就是记忆细胞(在最上面的贯穿水平线上)。记忆细胞提供了记忆的功能,使得记忆信息在网络各层之间很容易保持下去。
- 遗忘门(Forget Gate)
遗忘门的作用是控制t-1时刻到t时刻时允许多少信息进入t时刻的门控设备
遗忘门的计算公式如下:
Γ t f = σ ( w f [ a t − 1 , x t ] + b f ) \Large \Gamma_t^f=\sigma(w_f[a_{t-1},x_t]+b_f) Γtf=σ(wf[at−1,xt]+bf)
其中,xt是当前时刻的输入,at-1是上一时刻隐状态的值
- 输入门(Input Gate)
输入门的作用是确定需要将多少信息存入记忆细胞中。除了计算输入门外,还需要使用tanh计算记忆细胞的候选值c't
Γ t i = σ ( w i [ a t − 1 , x t ] + b i ) c t ′ = t a n h ( w c [ a t − 1 , x t ] + b c ) \Large \Gamma_t^i=\sigma(w_i[a_{t-1},x_t]+b_i) \\ \Large c'_t = tanh(w_c[a_{t-1},x_t]+b_c) Γti=σ(wi[at−1,xt]+bi)ct′=tanh(wc[at−1,xt]+bc)
然后,就可以对当前时刻的记忆细胞进行更新了
c t = Γ t f c t − 1 + Γ t i c t ′ \Large c_t=\Gamma_t^fc_{t-1}+\Gamma_t^ic'_t ct=Γtfct−1+Γtict′
- 输出门(Output Gate)
输出门是用来控制t时刻状态值对外多少是可见的门控设备
输出门与t时刻隐层节点输出值得公式为:
Γ t o = σ ( w o [ a t − 1 , x t ] + b o ) a t = Γ t o t a n h ( c t ) \Large \Gamma_t^o=\sigma(w_o[a_{t-1},x_t]+b_o) \\ \Large a_t=\Gamma_t^otanh(c_t) Γto=σ(wo[at−1,xt]+bo)at=Γtotanh(ct)
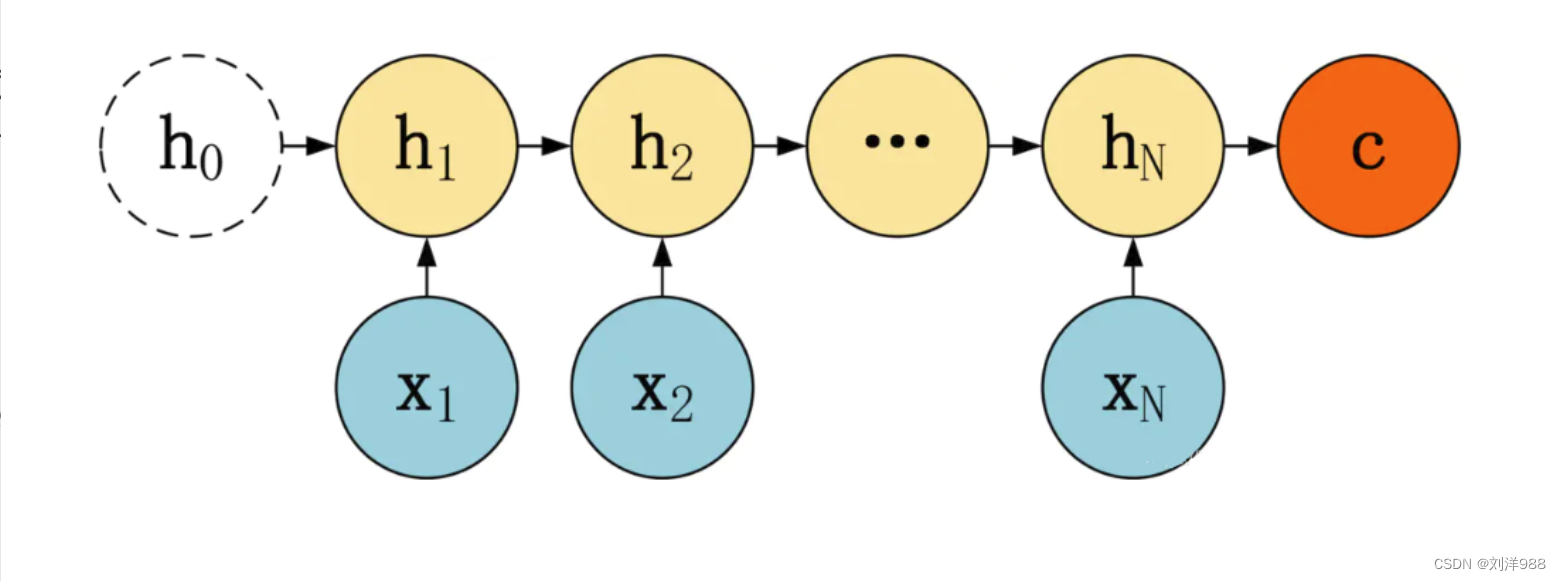
Seq2Seq模型
Seq2Seq表现形式
在RNN的结构中,最常见的就是不等长的多对多结构,即输入、输出虽然都是多个,但是并不相等。这种不等长的多对多结构就是Seq2Seq(序列对序列)模型。
例如,汉译英的机器翻译时,输入的汉语句子和输出的英文句子很多时候并不是等长的,这时就可以用Seq2Seq模型了。
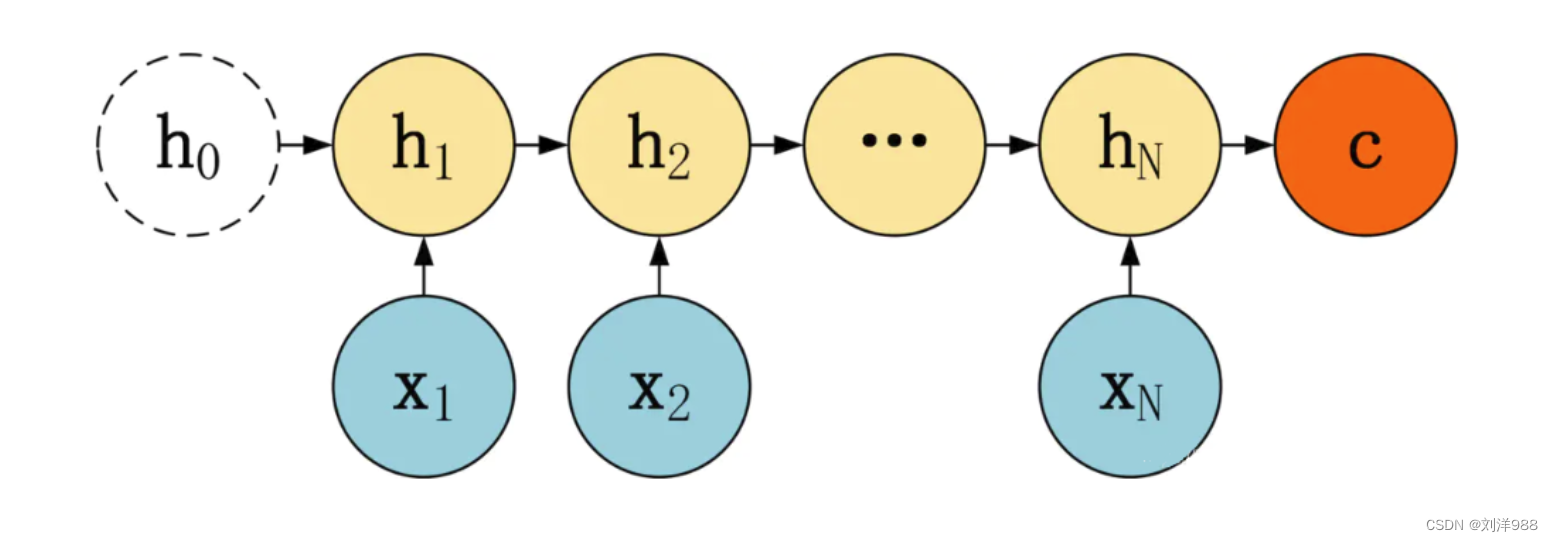
Encoder+Decoder
Seq2Seq由一个编码器(Encoder)和一个解码器(Decoder)构成,编码器先将输入序列转化为一个上下文向量C(理解序列),然后再用一个解码器将C转化为最终输出(生成序列)。
- 编码器(Encoder)
-
解码器(Decoder)
Attention模型
引入Attention模型的必要性
Seq2Seq作为一种通用的编码-解码结构,在编码器将输入编码成上下文向量C后,在解码时每一个输出Y都会不加区分地使用这个C进行解码,这样并不能有效地聚焦到输入目标上。
Seq2Seq+Attention模型
Seq2Seq引入Attention模型后,Attention模型(注意力模型)通过描述解码中某一时间步的状态值和所有编码中状态值的关联程度(即权重),计算出对当前输出更友好的上下文向量,从而对输入信息进行有选择性的学习。
y 1 = f ( C 1 ) y 2 = f ( C 2 , y 1 ) y 3 = f ( C 3 , y 1 , y 2 ) . . . \Large y_1=f(C_1) \\ \Large y_2=f(C_2,y_1) \\ \Large y_3=f(C_3,y_1,y_2) \\ ... y1=f(C1)y2=f(C2,y1)y3=f(C3,y1,y2)...
Encoder-Decoder框架
Encoder-Decoder框架是一种深度学习领域的研究模式,应用场景非常广泛。上图是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示。
文本处理领域的Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对<Source,Target>,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成:
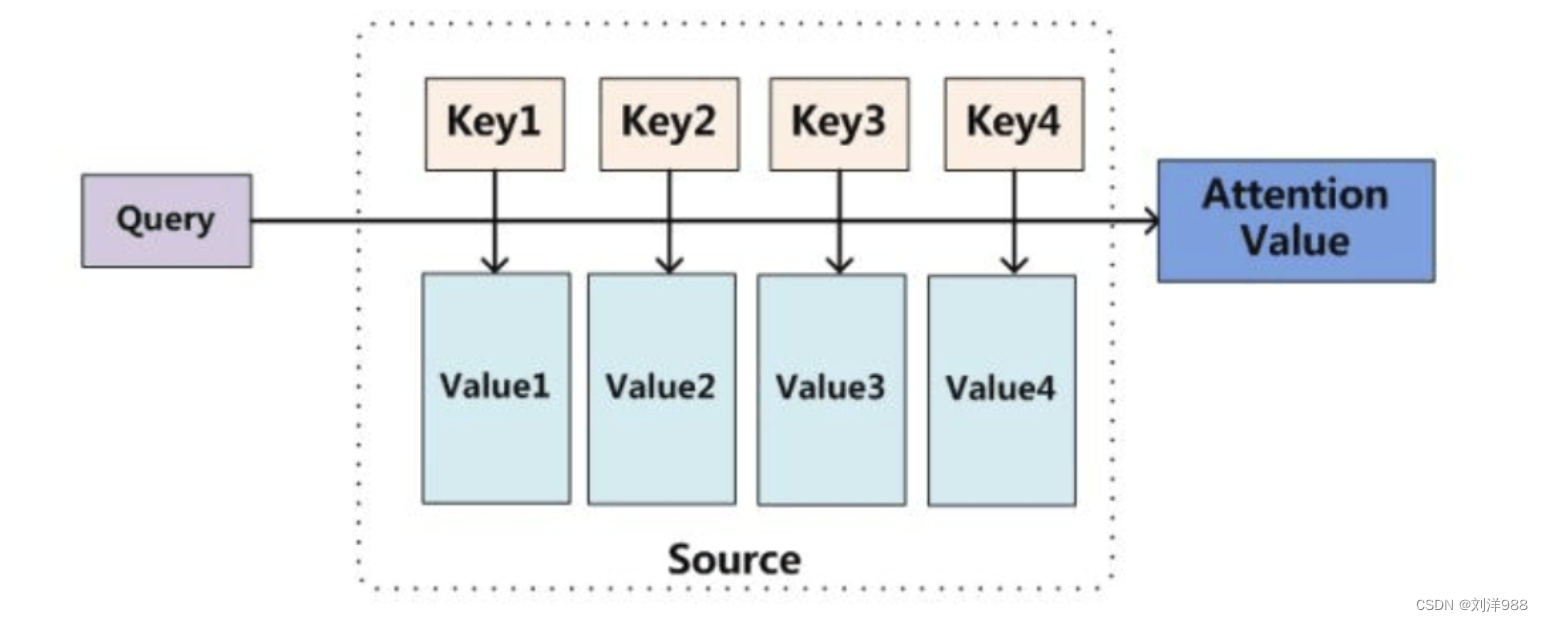
Attention模型
Attention机制的本质思想
Attention 原理的3步分解
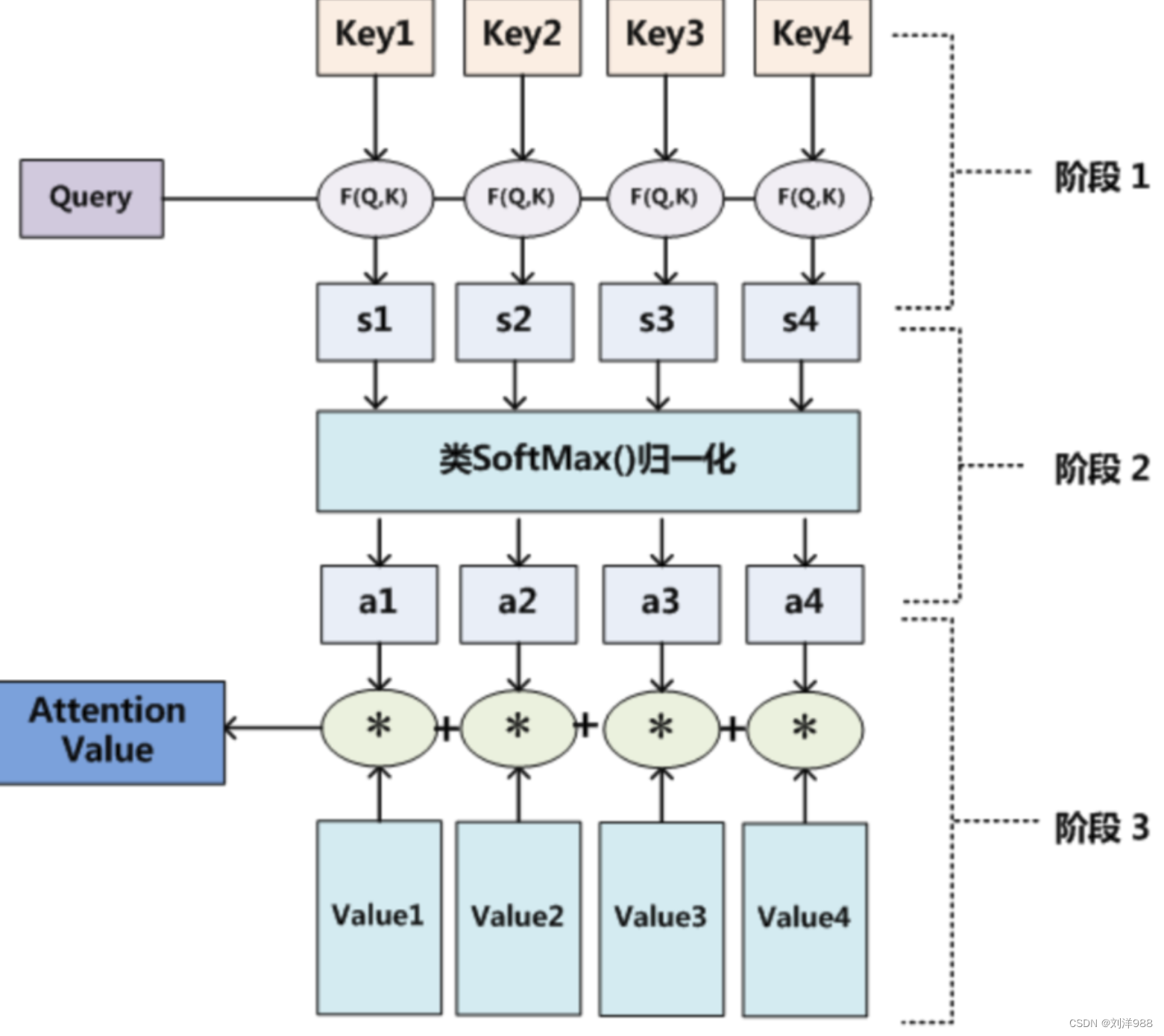
本质上Attention机制是对Source中元素(将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成)的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。
Self Attention自注意力模型
在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容
是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是
对应的翻译出的中文句子,Attention机制发生在Target的元素Query和
Source中的所有元素之间。而Self Attention顾名思义,指的不是Target和
Source之间的Attention机制,而是Source内部元素之间或者Target内部元
素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下
的注意力计算机制。其具体计算过程是一样的,只是计算对象发生了变化而
已。引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
Transformer模型
Transformer模型是在论文《Attention Is All You Need》里面提出来的,用来生成文本的上下文编码,传统的上下问编码大多数是由RNN来完成的,不过,RNN很难处理相隔比较远的两个单词之间的信息。
Transformer 是一种使用注意力机制(attention mechanism)的神经网络模型,能够有效地处理序列数据,如句子或文本。
它的设计灵感来自于人类在理解上下文时的方式。
简单来说,Transformer 会将输入的序列分成若干个小块,并通过计算注意力得分来决定每个块在输出中的重要性。
它能够同时处理整个序列,而不需要依赖循环神经网络(RNN)等逐步处理的方法。
- Transformer模型中包含了多层encoder和decoder,每一层都由多个注意力机制模块和前馈神经网络模块组成。encoder用于将输入序列编码成一个高维特征向量表示,decoder则用于将该向量表示解码成目标序列。
- Transformer模型的核心是自注意力机制(Self-Attention Mechanism),其作用是为每个输入序列中的每个位置分配一个权重,然后将这些加权的位置向量作为输出。
相关文章:
Day15 —— 大语言模型简介
大语言模型简介 大语言模型基本概述什么是大语言模型主要应用领域大语言模型的关键技术大语言模型的应用场景 NLP什么是NLPNLP的主要研究方向word2vecword2vec介绍word2vec的两种模型 全连接神经网络神经网络结构神经网络的激活函数解决神经网络过拟合问题的方法前向传播与反向…...

使用了CDN,局部访问慢,如何排查
如果是局部访问慢,则可从如下角度查看 是否DNS设置错误导致? 个别用户可能存在local DNS设置错误,导致出现跨地域或跨运营商访问。因为CDN的权威DNS是基于用户请求的localDNS来判断所属的地区和运营商,从而将请求引导至对应最近…...

谈谈SQL优化
SQL优化是数据库性能优化中的关键环节,旨在提高查询执行的效率和响应速度。下面是一些常见的SQL优化技巧和策略,涵盖索引、查询设计、表结构设计等方面: 1. 索引优化 创建索引:为常用查询的过滤条件(WHERE 子句&…...

力扣随机一题 6/26 哈希表 数组 思维
博客主页:誓则盟约系列专栏:IT竞赛 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ 题目一: 2869.收集元素的最少操作次数【简单】 题目ÿ…...

自动化办公04 使用pyecharts制图
目录 一、柱状图 二、折线图 三、饼图 四、地图 1. 中国地图 2. 世界地图 3. 省会地图 五、词云 Pyecharts是一个用于数据可视化的Python库。它基于Echarts库,可以通过Python代码生成各种类型的图表,如折线图、柱状图、饼图、散点图等。 Pyecha…...

【Elasticsearch】在es中实现mysql中的FIND_IN_SET查询条件
需求场景: 有个文章表里面有个type字段,它存储的是文章类型,有 1头条、2推荐、3热点、4图文等等 。 商品表中有一个type字段,储存的事商品类型例如:1.热销单品,2.品类TOP10,3.销量榜TOP10等等 它的type字段值很有可能是1,2,3,4 在mysql中实现语句 select * from produc…...

内网一键部署k8s-kubeshpere,1.22.12版本
1.引言 本文档旨在指导读者在内网环境中部署 Kubernetes 集群。Kubernetes 是一种用于自动化容器化应用程序部署、扩展和管理的开源平台,其在云原生应用开发和部署中具有广泛的应用。然而,由于一些安全或网络限制,一些组织可能选择在内部网络…...
Python数据分析第一课:Anaconda的安装使用
Python数据分析第一课:Anaconda的安装使用 1.Anaconda是什么? Anaconda是一个便捷的获取包,并且对包和环境进行管理的虚拟环境工具,Anaconda包括了conda、Python在内的超过180多个包和依赖项 简单来说,Anaconda是包管理器和环境…...

数据结构——
1. 什么是并查集? 在计算机科学中,并查集(英文:Disjoint-set data structure,直译为不数据结构交集)是一种数据结构,用于处理一些不交集(Disjoint sets,一系列没有重复元…...

微信小程序建议录音机
在小程序中实现录音机功能,可以通过使用小程序提供的wx.getRecorderManager() API来获取录音管理对象,然后使用这个对象的start()方法来开始录音,使用stop()方法来停止录音,并使用onStop()方法来监听录音的结束。以下是一个简单的…...

双指针:移动零
题目链接:. - 力扣(LeetCode) 乍一看有点难度,但也是快慢指针的模板。和26. 删除有序数组中的重复项类似,只不过多了一步填充0。 class Solution {public int removeDuplicates(int[] nums) {int fast 1,slow 1;wh…...

图像亮度和对比度的调整
在网上找了很多图像亮度的调整算法,下面是其中一种,可以通过条形框进行调整,并实时的查看对应参数值后的效果。 图像亮度处理公式: y [x - 127.5 * (1 - B)] * k 127.5 * (1 B); x 是输入像素值 y 是输出像素值 B 是亮度值, …...

Linux加固-权限管理_chattr之i和a参数
一、参数i i:如果对文件设置了i属性,不允许对文件进行删除、改名,也不能添加和修改数据;如果对目录设置了i属性,那么只能修改目录下文件的数据,但不允许建立和删除文件。(相当于把文件给锁住了,…...
windows10/win11截图快捷键 和 剪贴板历史记录 快捷键
后知后觉的我今天又学了两招: windows10/win11截图快捷键 按 Windows 徽标键 Shift S。 选择屏幕截图的区域时,桌面将变暗。 默认情况下,选择“矩形模式”。 可以通过在工具栏中选择以下选项之一来更改截图的形状:“矩形模式”…...

上海计算机考研避雷,25考研慎报
上大计算机一直很热 408考研er重来没有让我失望过,现在上大的专业课是11408,按理说,这个专业课的难度是很高的,但是408er给卷出了新高度,大家可以去上大官网看看今年最新的数据,我也帮大家统计了24年最新的…...
第九次作业
BookInfoMapper.xml <?xml version"1.0" encoding"UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace"com.rabbite…...
A股探底回升,跑出惊天大阳,你们知道为什么吗?
今天的A股,探底回升,让人惊呆了,你们知道是为什么吗?盘面上出现3个重要信号,一起来看看: 1、今天A股市场炸锅了,AI人工智能、国产软件、存储芯片迎来了涨停潮,惊呆了,科技…...
jenkins nginx自动化部署 php项目
在当今快速发展的IT领域,自动化部署已成为提高工作效率和减少错误的关键。Jenkins作为持续集成/持续部署(CI/CD)的佼佼者,结合Docker容器技术和PHP编程语言,以及Ansible自动化工具,可以实现高效、可靠的自动…...
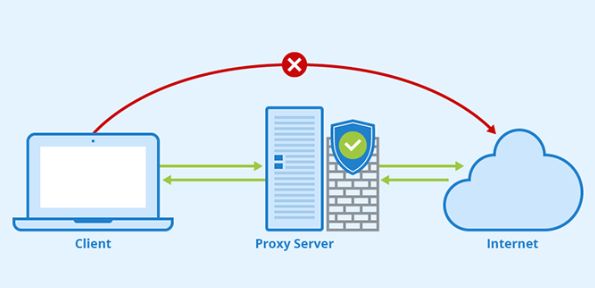
海外代理IP哪个可靠?如何测试代理的稳定性?
在数字化时代,互联网已成为我们日常生活的重要组成部分。然而,随着网络活动的增加,我们面临的安全威胁也随之增加。 黑客攻击、数据泄露、网络钓鱼等安全事件频发,严重威胁着我们的个人隐私和网络安全。代理服务器在当今的互联网世…...
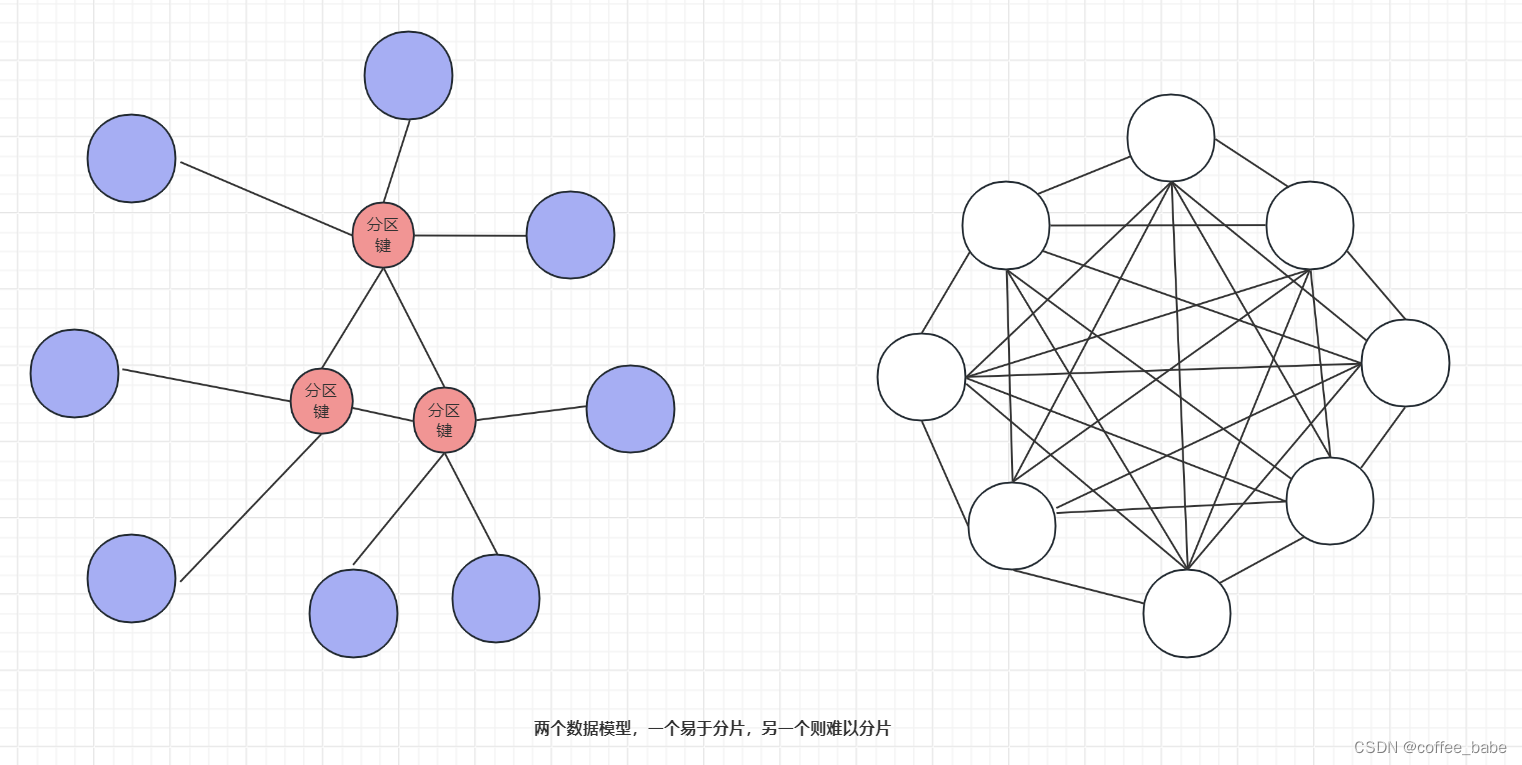
MySQL之可扩展性(四)
可扩展性 向外扩展 分片?还是不分片? 这是一个问题,对吧?答案很简单:如非必要,尽量不分片。首先看是否能通过性能调优或者更好的应用或数据库设计来推迟分片。如果能足够长时间地推迟分片,也许可以直接购买更大地服…...

5个简单步骤彻底解决MoviePilot连接TheMovieDb异常问题
5个简单步骤彻底解决MoviePilot连接TheMovieDb异常问题 【免费下载链接】MoviePilot NAS媒体库自动化管理工具 项目地址: https://gitcode.com/gh_mirrors/mo/MoviePilot MoviePilot作为一款优秀的NAS媒体库自动化管理工具,为你提供了便捷的影视资源管理体验…...

基于Adafruit Trinket的光控互动玩具:嵌入式系统入门实战
1. 项目概述:给毛绒玩具注入灵魂几年前,我女儿的一个旧毛绒玩具被冷落在角落,除了偶尔被当作抱枕,几乎失去了“玩具”的活力。这让我萌生了一个想法:能不能用一些简单的电子元件,让这些静态的玩偶重新“活”…...

一键部署本地大模型:基于vLLM与Hermes的AI对话服务搭建指南
1. 项目概述与核心价值最近在折腾本地大语言模型(LLM)部署的朋友,估计都绕不开一个名字:Hermes。这个名字背后,通常指的是由 NousResearch 团队发布的 Hermes 系列模型,它们以出色的指令遵循能力和对话质量…...

LaTeX-PPT:如何在3分钟内将专业数学公式融入PowerPoint演示
LaTeX-PPT:如何在3分钟内将专业数学公式融入PowerPoint演示 【免费下载链接】latex-ppt Use LaTeX in PowerPoint 项目地址: https://gitcode.com/gh_mirrors/la/latex-ppt 还在为PowerPoint中编辑复杂数学公式而头疼吗?LaTeX-PPT这款开源插件彻底…...

前台测试想转后台优化?这4个条件缺一不可,否则别折腾
很多做前台测试的兄弟都问过同一个问题:我能不能转后台?今天这篇文章,一次性把后台工程师的准入清单说清楚。一、基础条件:5条缺一不可年龄20-50岁太小的缺经验,太大的学新东西慢,这个区间刚刚好。有网优基…...

Zotero插件市场:告别繁琐安装,开启高效学术插件管理新时代
Zotero插件市场:告别繁琐安装,开启高效学术插件管理新时代 【免费下载链接】zotero-addons Zotero Add-on Market | Zotero插件市场 | Browsing, installing, and reviewing plugins within Zotero 项目地址: https://gitcode.com/gh_mirrors/zo/zoter…...

盛立体育足球场人造草坪
盛立体育足球场人造草坪湖北盛立体育科技有限公司是一家规模较大的集研发设计、生产制造、销售和安装于一体的人造草坪厂家。公司拥有自己的生产研发工厂,目前主营:足球场人造草坪,幼儿园人造草坪,塑胶跑道、各类仿真草坪等系列产…...

基于CircuitPython与Adafruit CLUE的创意灵感生成器开发指南
1. 项目概述:用硬件激发创意的火花你有没有过这样的时刻——面对空白的画布、闪烁的光标,或者一堆零散的电子元件,脑子里却一片空白,急需一个点子来点燃创作的引擎?这种“创意阻塞”几乎是每个创作者都会遇到的难题。传…...

虚拟机开发环境中如何通过Taotoken管理多个项目的API Key与用量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 虚拟机开发环境中如何通过Taotoken管理多个项目的API Key与用量 应用场景类,开发者在同一虚拟机中维护多个不同项目&am…...

服务网格流量管理:智能控制微服务间通信
服务网格流量管理:智能控制微服务间通信 一、服务网格流量管理的核心概念 1.1 服务网格的演进历程 服务网格(Service Mesh)是一种用于管理微服务间通信的基础设施层,它通过Sidecar代理模式实现透明的流量控制和可观测性。 阶段特征…...