推动多模态智能模型发展:大型视觉语言模型综合多模态评测基准
随着人工智能技术的飞速发展,大型视觉语言模型(LVLMs)在多模态应用领域取得了显著进展。然而,现有的多模态评估基准测试在跟踪LVLMs发展方面存在不足。为了填补这一空白,本文介绍了MMT-Bench,这是一个全面的多模态基准测试,旨在评估LVLMs在需要专家知识和深思熟虑的视觉识别、定位、推理和规划的大量多模态任务上的表现。
MMT-Bench的构建
MMT-Bench是一个精心设计的多模态基准测试,用于全面评估大型视觉语言模型(LVLMs)在多任务理解方面的表现。MMT-Bench的构建过程分为两个主要部分:任务的分层结构和数据收集流程。
任务的分层结构
MMT-Bench的设计始于一个分层的任务结构,这有助于确保广泛的多模态任务得到覆盖。这个过程通过去重和筛选,最终确定了32个核心元任务。这些元任务进一步被细分为162个子任务,每个子任务都旨在评估模型在特定领域内的具体能力。
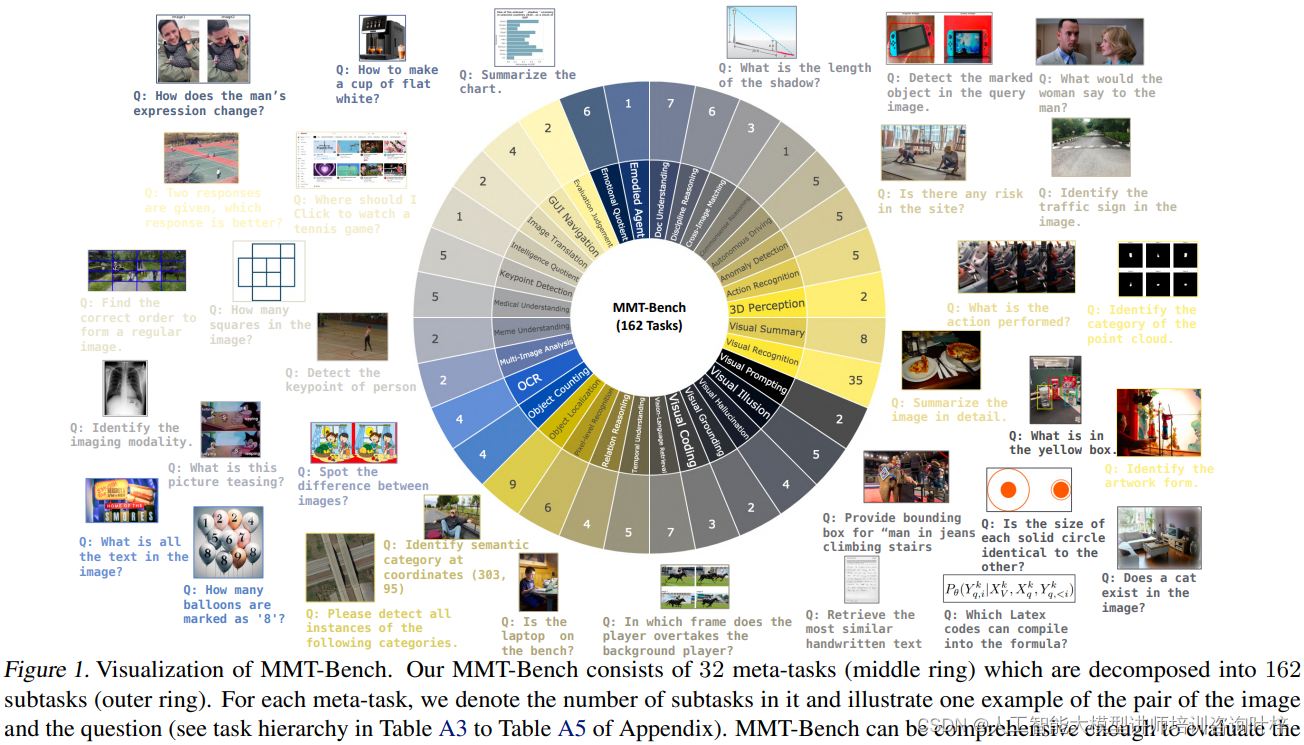
Figure 1 MMT-Bench的可视化内容展示了MMT-Bench由32个元任务(middle ring)组成,这些元任务进一步分解为162个子任务(outer ring)。
- 元任务的表示(Meta-tasks): Figure 1 中间层的环展示了32个元任务,这些元任务代表了多模态理解中的高层次分类。每个元任务都是围绕多模态处理和理解的一个特定领域,如视觉识别、文本理解、场景分析等。
- 子任务的分解(Subtasks): 外层环进一步将每个元任务细分为子任务。总共有162个子任务,这些子任务是评估模型在更具体、更细分领域能力的方式。例如,视觉识别元任务可能会被细分为物体检测、图像分类等子任务。
- 任务数量: 对于每个元任务,图中标注了包含的子任务数量,这提供了对每个领域内评估的深度和广度的直观理解。
- 图像和问题示例: 每个元任务旁边都展示了一个图像和问题对的例子,这有助于理解每个任务的具体内容和评估的类型。例如,一个问题可能要求模型识别图像中的物体或者解释图像中的场景。

MMT-Bench中包含的13种图像类型,如Figure 2所示这些图像类型要求模型能够解释各种视觉输入。这13种图像类型包括自然场景、合成图像、深度图、文本丰富的图像、绘画、截图、点云、医学图像等。
为了确保子任务的质量和相关性,研究团队制定了三个选择标准:子任务是否测试基本的多模态能力、是否对当前LVLMs构成挑战、以及测试样本是否可以公开获取。这些子任务覆盖了从视觉识别和定位到更复杂的推理和规划等多种能力。
数据收集流程
研究团队进行了数据集搜索,使用Google、Paper With Code、Kaggle和ChatGPT等多种来源,基于子任务的名称寻找相关的数据集。一旦确定了合适的数据集,团队就会下载并仔细评估它们的适用性,以确保它们能够用于评估特定的子任务。
接下来,研究团队构建了元数据(metadata),这是一种统一格式,用于整理下载的数据集。元数据包括图像和元信息,元信息包含了生成问题和答案所需的必要信息,如手动注释的所需能力和视觉提示类型。为了提高评估效率,在每个任务中,团队通过随机抽样的方式,将样本数量限制在200个以内。
研究团队为每个子任务生成了多选视觉问题和答案。这一步骤涉及到根据具体任务手动设计规则或使用ChatGPT生成问题和选项。例如,在草图到图像检索任务中,使用相应的图像作为正确答案,并从元数据中随机抽样生成其他选项。
MMT-Bench包含了31,325个多选视觉问题,涵盖了自然场景、合成图像、文本丰富的图像、医学图像等13种输入图像类型。这些问题覆盖了32个核心元任务和162个子任务,用于评估视觉识别、定位、推理、OCR、计数、3D感知、时间理解等14种多模态能力。
通过这一详尽的数据收集和任务设计流程,MMT-Bench能够全面评估LVLMs在多模态多任务理解方面的能力,为研究者提供了一个强大的工具,以推动多模态人工智能领域的发展。
实验
研究团队挑选了30种不同的公开可用模型,包括专有模型和开源模型,进行了深入的测试和分析。
这些模型中,包括了GPT-4V、GeminiProVision和InternVL-Chat等知名模型。GPT-4V和GeminiProVision作为专有模型,以其先进的性能和专有技术而闻名。而InternVL-Chat作为一个开源模型,代表了社区驱动的模型开发和协作精神。这些模型被选中是因为它们在视觉语言任务中展现出了卓越的能力,并且能够代表当前LVLMs的不同发展水平。
评估过程中,研究者采用了MMT-Bench中的多选视觉问题对这些模型进行了测试。这些问题覆盖了广泛的多模态任务,要求模型不仅要有出色的视觉识别能力,还需要有理解、推理和规划的能力。通过对模型在所有子任务上的表现进行综合评分,研究者能够得出每个模型的整体性能。
结果显示,即使是这些先进的模型,在MMT-Bench上的准确率也仅在63.4%到61.6%之间。InternVL-Chat以63.4%的准确率略微领先,而GPT-4V和GeminiProVision分别以62.0%和61.6%的准确率紧随其后。这一发现揭示了即便是当前最顶尖的模型,也有很大的提升空间,特别是在多任务智能方面。
研究者还探讨了不同提示方法对模型性能的影响。提示方法是指在向模型提出问题时所采用的措辞和指令的方式。研究发现,某些任务在采用特定的提示方法时,模型的表现会有所提升。这表明,问题的表述方式对于模型的理解能力和最终的输出结果有着直接的影响。
例如,在视觉推理任务中,如果提示能够更精确地引导模型关注图像中的关键部分,模型的推理能力可能会得到增强。在图像描述任务中,开放式的提示可能会鼓励模型生成更丰富、更详细的描述。这些发现对于未来设计更有效的人机交互界面和改进模型的训练方法具有重要意义。
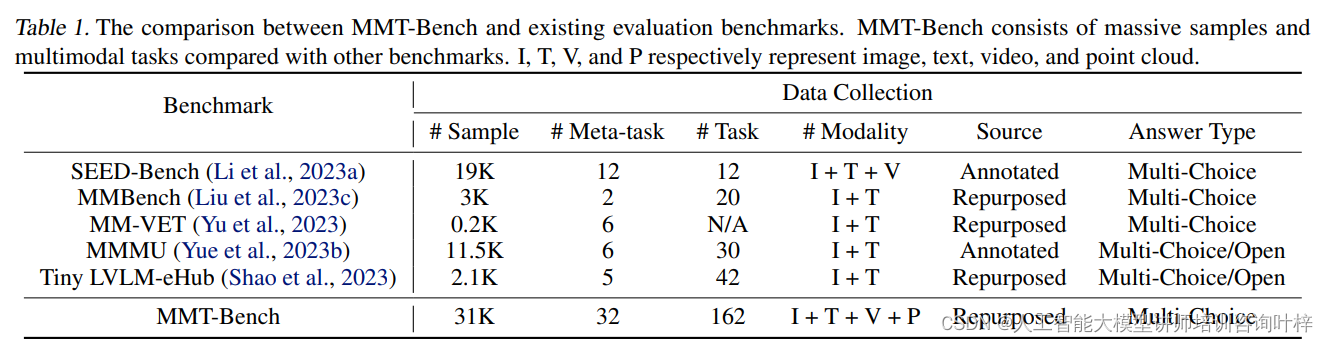
Table 1 比较了MMT-Bench与其他现有评估基准在OCR(光学字符识别)相关任务上的样本数据。表格中列出了不同基准的样本数量、任务类型、平均单词数、最小值、中位数、最大值以及标准差。它还提供了每个基准的元任务数量、任务数量、模态类型(如图像I、文本T、视频V、点云P)和答案类型(如多选题)。
例如,MME基准有40个样本,任务类型为1,平均单词数为2.5,最小值为1,最大值为5,标准差为1.6。相比之下,MMT-Bench有600个样本,平均单词数为14.8,最小值为1,最大值为103,标准差为22.7。这表明MMT-Bench在样本数量和单词数上都显著高于其他基准,意味着它提供了更丰富的数据集来评估模型的OCR能力。
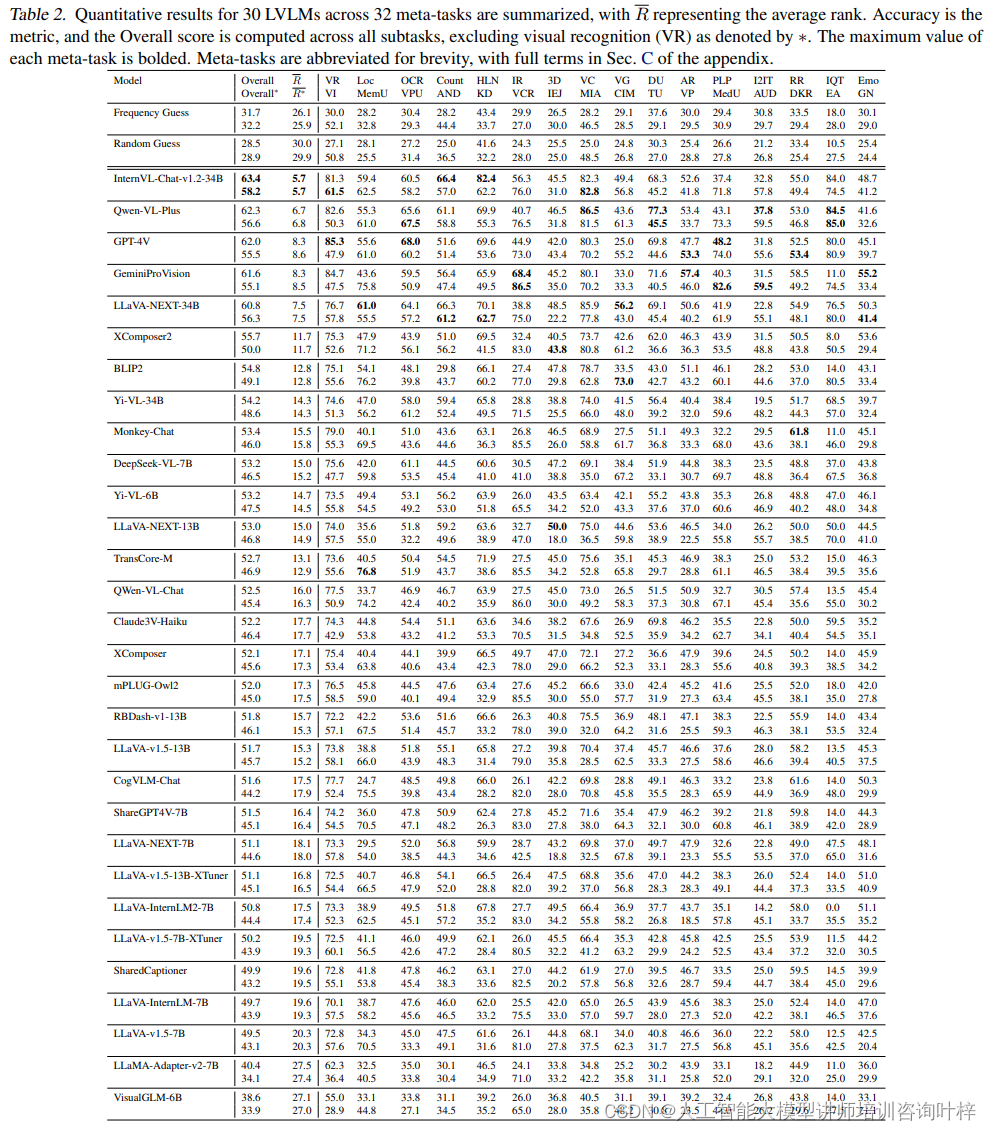
Table 2 汇总了30种不同的大型视觉语言模型(LVLMs)在MMT-Bench的32个元任务上的性能。表格列出了每个模型的总体准确率(Overall Accuracy)以及在每个元任务上的表现,包括视觉识别(VR)、定位(Loc)、OCR、计数(Count)、3D识别(3D)、视觉字幕(VC)等。
例如,InternVL-Chat-v1.2-34B模型在所有子任务上的总体准确率为63.4%,在视觉识别任务上达到了81.3%的准确率,而在文档理解(Doc Understanding)任务上准确率为58.7%。这些数据提供了对模型在不同任务类型上性能的深入洞察。
任务分析
任务分析部分利用MMT-Bench的广泛任务覆盖,对LVLMs进行了任务映射评估。
任务向量和Kendall's tau相关性度量
为了量化任务之间的关系,研究者采用了任务向量的概念。每个任务通过一个向量在高维空间中表示,这个向量基于模型在该任务上的微调权重与初始权重之间的差异。通过计算这些向量之间的余弦相似度,可以确定任务之间的接近程度。Kendall's tau是一种统计方法,用来衡量两组排名之间的相关性。在这项研究中,它被用来衡量模型在不同任务上的性能排名的相关性。
实验过程
研究者首先使用了一个预训练的模型作为探测模型,并针对每个子任务构建了任务数据集。然后,通过微调探测模型来获得每个任务的任务向量。这些向量随后被用于构建任务图,任务图上的每个点代表一个任务,点与点之间的距离表示任务之间的相似度。
结果分析
通过任务图,研究者观察到当两个任务在图上的距离较近时,模型在这些任务上的性能排名更为一致。这意味着如果两个任务在多模态能力上相似,模型在这些任务上的表现也应该相似。这种一致性为理解模型的多模态能力提供了有价值的见解,并可以帮助识别模型在特定类型的任务上可能存在的弱点。
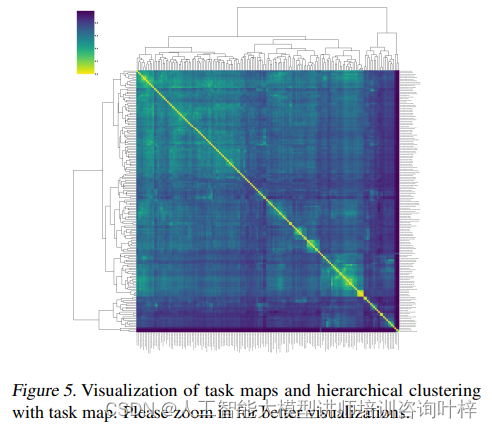
如图,研究者利用MMT-Bench广泛的任务覆盖,通过任务图来评估LVLMs的多模态性能。通过分析任务之间的关系,可以系统地解释不同任务在多模态能力中的作用。研究者使用了任务向量和Kendall's tau相关性度量来量化任务之间的关系和模型在不同任务上的性能排名。结果表明,当两个任务在任务图上距离较近时,模型在这些任务上的性能排名更为一致。通过这个图,可以观察到任务是如何被分组的,以及这些组与模型性能之间的相关性。
任务图和任务向量的分析不仅帮助研究者理解了不同任务之间的关系,而且还可以用来预测模型在新任务上的表现。如果一个新任务与任务图上的某个任务相近,那么可以预测模型在这个新任务上也可能有类似的表现。这种方法为模型的选择和优化提供了一种基于数据的决策支持。
MMT-Bench作为一个评估多模态多任务理解的全面基准测试,为衡量在多任务通用人工智能(AGI)发展道路上的进展提供了重要工具。通过这一基准测试,研究者可以识别当前LVLMs的强项和弱点,并为未来的模型改进和应用开发提供指导。我们期待MMT-Bench能够激励社区进一步推动LVLMs的研究与开发,使我们更接近真正智能的多模态系统的实现。
论文链接:https://arxiv.org/abs/2404.16006
相关文章:
推动多模态智能模型发展:大型视觉语言模型综合多模态评测基准
随着人工智能技术的飞速发展,大型视觉语言模型(LVLMs)在多模态应用领域取得了显著进展。然而,现有的多模态评估基准测试在跟踪LVLMs发展方面存在不足。为了填补这一空白,本文介绍了MMT-Bench,这是一个全面的…...
深度学习31-33
1.负采样方案 (1)为0是负样本,负样本是认为构造出来的。正样本是有上下文关系 负采样的target是1,说明output word 在input word之后。 2.简介与安装 (1)caffe:比较经常用于图像识别,有卷积网…...

Docker多种场景下设置代理
20240623 - 公司内网环境下需要对Docker进行代理设置;此时需要对拉取镜像的时候的命令设置代理;例如平时经常使用的wget设置代理一样。但对docker进行设置,并不能简单的直接export。 文章[1]指出,拉取镜像的时候实际执行的是doc…...
node 实现导出, 在导出excel中包含图片(附件)
如果想查看 node mySql 实现数据的导入导出,以及导入批量插入的sql语句,连接如下 node mySql 实现数据的导入导出,以及导入批量插入的sql语句-CSDN博客https://blog.csdn.net/snows_l/article/details/139998373 一、效果如图: 二…...
【ai】trition:tritonclient yolov4:ubuntu18.04部署python client成功
X:\05_trition_yolov4_clients\01-python server代码在115上,client本想在windows上, 【ai】trition:tritonclient.utils.shared_memory 仅支持linux 看起来要分离。 【ai】tx2 nx:ubuntu18.04 yolov4-triton-tensorrt 成功部署server 运行 client代码远程部署在ubuntu18.0…...
oracle 主从库中,从库APPLIED为YES ,但是主库任然为NO
主库 从库 从库已经APPLIED但是主库为APPLIED, 主数据库和备用数据库之间的ARCH-RFS心跳Ping负责更新主数据库上v$archived_log的APPLICED列。 在主数据库上有一个指定的心跳ARCn进程来执行此Ping。如果此进程开始挂起,它将不再与远程RFS进程通信&#…...
VS 在多线程中仅调试某个线程
调试多线程程序时,只想观察某个线程的运行情况; 但是,由于线程切换执行,会导致调试时焦点在几个代码块之间跳来跳去,故需要解决这个问题。 参考文章: C#使用线程窗口调试多线程程序。 1 打开线程窗口&…...
系统全新升级!)
全球无界,语言无阻——魔众帮助中心(多语言)系统全新升级!
🎉亲爱的用户们,你们好!今天,我要向大家隆重介绍一个颠覆传统,助力全球用户的利器——魔众帮助中心(多语言)系统的全新升级版本!🌟 🌐在这个日益全球化的时代,魔众帮助中…...

SpringCloud集成OpenFeign
一、简介 OpenFeign客户端是一个web声明式http远程调用工具,直接可以根据服务名称去注册中心拿到指定的服务IP集合,提供了接口和注解方式进行调用,内嵌集成了Ribbon本地负载均衡器。 二、SpringCloud集成OpenFeign 版本说明: S…...
Vue - 第3天
文章目录 一、Vue生命周期二、Vue生命周期钩子三、工程化开发和脚手架1. 开发Vue的两种方式2. 脚手架Vue CLI基本介绍:好处:使用步骤: 四、项目目录介绍和运行流程1. 项目目录介绍2. 运行流程 五、组件化开发六、根组件 App.vue1. 根组件介绍…...

21.智能指针(上)
目录 一、概念二、Box\<T\>2.1 概念与应用场景2.2 简单应用2.3 递归类型的创建 三、通过Deref trait将智能指针当作常规引用处理3.1 常规引用3.2 像引用一样使用Box\<T\>3.3 自定义智能指针3.4 函数和方法的隐式解引用强制转换3.5 解引用强制转换与可变性交互 四、…...
Jenkins+gitee流水线部署springboot项目
目录 前言 一、软件版本/仓库 二、准备工作 2.1 安装jdk 11 2.2 安装maven3.9.7 2.3 安装docker 2.4 docker部署jenkins容器 三、jenkins入门使用 3.1 新手入门 3.2 jenkins设置环境变量JDK、MAVEN、全局变量 3.2.1 jenkins页面 3.2.2 jenkins容器内部终端 3.2.3 全…...
函数使用(超详细))
python--os.walk()函数使用(超详细)
在Python 3.7中,os.walk()函数的用法与早期版本(包括Python 3.4及之后)保持一致。os.walk()是一个用于遍历目录树的生成器函数,它生成给定目录中的文件名。这个函数没有直接的参数(除了你要遍历的目录路径,…...

基础名词概念
了解以下基础名词概念/定义: IP地址、子网掩码、网关、DNS、DHCP、MAC地址、网络拓扑、路由器、交换机、VPN、端口、TCP、UDP、HTTP、HTTPS、OSI模型、ARP、NAT、VLAN、FTP、SMTP、IMAP、SSL、ICMP、链路聚合、TRUNK、直连路由、静态路由、动态路由、IPV6 端口&am…...

ArkTS开发系列之Web组件的学习(2.9)
上篇回顾:ArkTS开发系列之事件(2.8.2手势事件) 本篇内容: ArkTS开发系列之Web组件的学习(2.9) 一、知识储备 Web组件就是用来展示网页的一个组件。具有页面加载、页面交互以及页面调试功能 1. 加载网络…...

postman接口工具的详细使用教程
Postman 是一种功能强大的 API 测试工具,可以帮助开发人员和测试人员轻松地发送 HTTP 请求并分析响应。以下是对 Postman 接口测试工具的详细介绍: 安装与设置 安装步骤 访问 Postman 官网,点击右上角的“Download”按钮。 选择你的操作系统…...

C语言经典例题-17
1.最小公倍数 正整数A和正整数B的最小公倍数是指能被A和B整除的最小的正整数,设计一个算法,求输入A和B的最小公倍数。 输入描述:输入两个正整数A和B。 输出描述:输出A和B的最小公倍数。 输入:5 7 输出:…...
)
鸿蒙学习(-)
.ets文件结构 //页面入口 Entry //组件 Component struct test{//页面结构build(){//容器 **一个页面只能有一个根容器,父容器要有大小设置**}1、Column 组件 沿垂直方向布局的组件,可以包含子组件 接口 Column({space}) space的参数为string | numbe…...

【TB作品】MSP430G2553,单片机,口袋板, 烘箱温度控制器
题3 烘箱温度控制器 设计一个基于MSP430的温度控制器,满足如下技术指标: (1)1KW 电炉加热,最度温度为110℃ (2)恒温箱温度可设定,温度控制误差≦2℃ (3)实时显…...
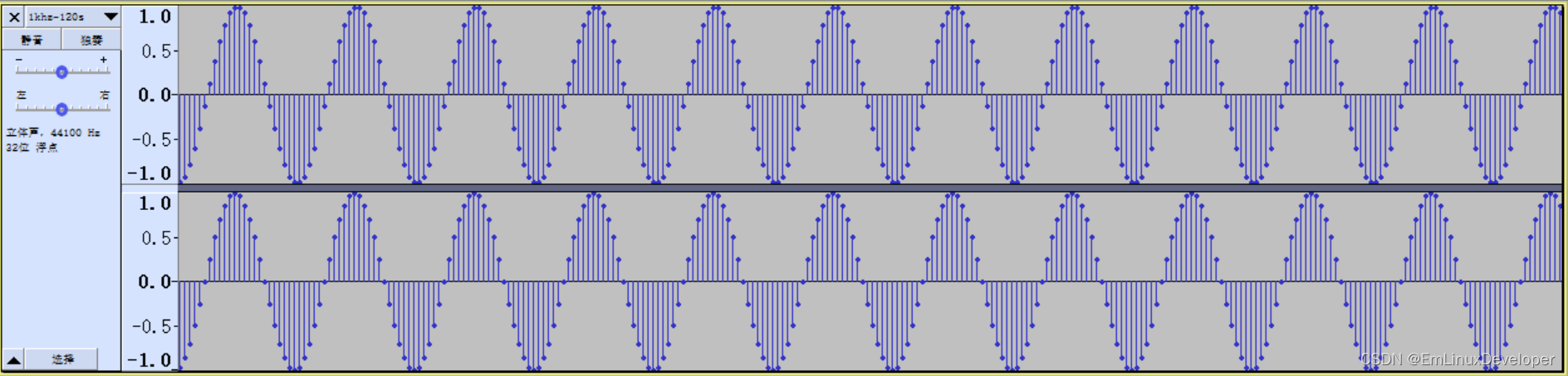
PCM、WAV,立体声,单声道,正弦波等音频素材
1)PCM、WAV音频素材,分享给将要学习或者正在学习audio开发的同学。 2)内容属于原创,若转载,请说明出处。 3)提供相关问题有偿答疑和支持。 常用的Audio PCM WAV不同采样率,不同采样深度&#…...

NAT 类型详解:四种 NAT 的数据流与原理解析
NAT 类型详解:四种 NAT 的数据流与原理解析摘要:NAT(Network Address Translation)是 P2P 通信中绕不开的关卡。不同的 NAT 类型决定了内网设备能否被外部直接访问,直接影响 WebRTC 等 P2P 技术的穿透成功率。本文通过…...

集成三相桥驱动的MCU:AiP8F7201电机控制方案解析
1. 项目概述:为什么我们需要“集成三相桥式驱动的微控制器”?在电机控制领域,尤其是消费电子、家电、工业自动化这些我们每天都会接触到的场景里,工程师们一直在和一堆“麻烦”作斗争。想象一下,你要设计一个驱动无刷直…...

自行车轮POV显示:基于视觉暂留与微控制器的DIY空中光绘
1. 项目概述:在车轮上“画”出光之画卷几年前,我第一次在夜间的公园里看到一辆飞驰而过的自行车,它的轮辐间竟然清晰地显示着一行发光的文字和图案,那种瞬间的震撼感至今难忘。那不是魔法,而是视觉暂留原理与微控制器精…...

终极指南:3分钟掌握Mouse Jiggler鼠标模拟器完整使用方法
终极指南:3分钟掌握Mouse Jiggler鼠标模拟器完整使用方法 【免费下载链接】mousejiggler Mouse Jiggler is a very simple piece of software whose sole function is to "fake" mouse input to Windows, and jiggle the mouse pointer back and forth. …...

文献综述效率提升300%?NotebookLM在区域地理分析中的7个颠覆性用法,含真实课题复现代码
更多请点击: https://intelliparadigm.com 第一章:NotebookLM地理学研究辅助 NotebookLM 是 Google 推出的基于用户上传文档进行深度语义理解与问答的 AI 工具,其在地理学研究中展现出独特价值——尤其适用于处理多源异构的地理文献、野外调…...

AI驱动编辑预设生成:从风格迁移到创意工作流的自动化实践
1. 项目概述:AI驱动的编辑预设库最近在折腾视频和图片后期,发现一个挺有意思的项目,叫kaushalrao/ai-editor-presets。这名字听起来有点技术范儿,但说白了,它就是一个用人工智能技术来生成和优化各类编辑软件预设文件的…...

LDAP认证失败率下降92%!DeepSeek集成最佳实践,含OpenLDAP/Active Directory双环境配置清单
更多请点击: https://intelliparadigm.com 第一章:LDAP认证失败率下降92%!DeepSeek集成最佳实践,含OpenLDAP/Active Directory双环境配置清单 在企业级AI平台落地过程中,统一身份认证是安全与体验的基石。DeepSeek模型…...

高速串行链路均衡技术解析与工程实践
1. 高速串行链路均衡技术概述在现代数字通信系统中,高速串行数据链路是实现高带宽数据传输的核心技术。随着数据速率攀升至6.25Gbps甚至更高,信号在传输过程中会遭遇严重的信道损耗问题。典型FR4 PCB走线在6.25Gbps速率下,第一谐波处的插入损…...

LLM应用开发框架llmflows:轻量级工作流编排实战指南
1. 项目概述:一个为LLM应用构建量身定制的轻量级框架最近在折腾大语言模型应用开发的朋友,估计都经历过类似的“甜蜜的烦恼”:想法很美好,但真要把想法变成可运行、可维护的代码,中间隔着无数个坑。从Prompt的反复调试…...

嵌入式GUI设计:资源受限下的高效人机交互实践
1. 嵌入式GUI设计的核心挑战与价值定位在咖啡机、车载仪表、医疗设备等嵌入式系统中,图形用户界面(GUI)承担着人机交互的关键桥梁作用。与桌面端或移动端GUI不同,嵌入式GUI面临三大独特约束:首先,硬件资源极度受限——典型嵌入式处…...