动手学深度学习(Pytorch版)代码实践 -卷积神经网络-30Kaggle竞赛:图片分类
30Kaggle竞赛:图片分类
比赛链接: https://www.kaggle.com/c/classify-leaves
导入包
import torch
import torchvision
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import numpy as np
import pandas as pd
from torch import nn
import matplotlib.pyplot as plt
from PIL import Image
import os
from torch.nn import functional as F
import torch.optim as optim
import liliPytorch as lp
import torchvision.models as models
预处理:数据集分析
train_path = '../data/classify-leaves/train.csv'
test_path = '../data/classify-leaves/test.csv'
file_path = '../data/classify-leaves/'# # 读取训练和测试数据
train_data = pd.read_csv(train_path)
test_data = pd.read_csv(test_path)# 打印数据形状
print(train_data.shape) # (18353, 2)
print(test_data.shape) # (8800, 1)#生成描述性统计数据
print(train_data.describe())
"""image label
count 18353 18353
unique 18353 176
top images/0.jpg maclura_pomifera
freq 1 353
"""# 查看不同树叶的数量
print(train_data['label'].value_counts())
"""
label
maclura_pomifera 353
ulmus_rubra 235
prunus_virginiana 223
acer_rubrum 217
broussonettia_papyrifera 214...
cedrus_deodara 58
ailanthus_altissima 58
crataegus_crus-galli 54
evodia_daniellii 53
juniperus_virginiana 51
Name: count, Length: 176, dtype: int64
"""
1.数据处理与加载
train_path = '../data/classify-leaves/train.csv'
test_path = '../data/classify-leaves/test.csv'
file_path = '../data/classify-leaves/'# 树叶的名字统计
labels_unique = train_data['label'].unique()
# print(labels_unique)# 树叶标签的数量
labels_num = len(labels_unique)# 提取出树叶标签,并排序
leaves_labels = sorted(list(set(train_data['label'])))
# print(leaves_labels)# 将树叶标签对应数字
labels_to_num = dict(zip(leaves_labels, range(labels_num )))
# print(labels_to_num)# 将数字对应树叶标签(用于后续预测)
num_to_labels = {value : key for key, value in labels_to_num.items()}
# print(num_to_labels)class LeavesDataset(Dataset):def __init__(self, csv_path, file_path, mode='train', valid_ratio=0.2, resize_height=224, resize_width=224):"""初始化 LeavesDataset 对象。参数:csv_path (str): 包含图像路径和标签的 CSV 文件路径。file_path (str): 图像文件所在目录的路径。mode (str, optional): 数据集的模式。可以是 'train', 'valid' 或 'test'。默认值为 'train'。valid_ratio (float, optional): 用于验证的数据比例。默认值为 0.2。resize_height (int, optional): 调整图像高度的大小。默认值为 224。resize_width (int, optional): 调整图像宽度的大小。默认值为 224。"""# 存储图像调整大小的高度和宽度self.resize_height = resize_heightself.resize_width = resize_width# 存储图像文件路径和模式(train/valid/test)self.file_path = file_pathself.mode = mode# 读取包含图像路径和标签的 CSV 文件self.data_info = pd.read_csv(csv_path, header=0)# 获取样本总数self.data_len = len(self.data_info.index)# 计算训练集样本数self.train_len = int(self.data_len * (1 - valid_ratio))# 根据模式处理数据if self.mode == 'train':# 训练模式下的图像和标签self.train_img = np.asarray(self.data_info.iloc[0:self.train_len, 0])self.train_label = np.asarray(self.data_info.iloc[0:self.train_len, 1])self.image_arr = self.train_imgself.label_arr = self.train_labelelif self.mode == 'valid':# 验证模式下的图像和标签self.valid_img = np.asarray(self.data_info.iloc[self.train_len:, 0])self.valid_label = np.asarray(self.data_info.iloc[self.train_len:, 1])self.image_arr = self.valid_imgself.label_arr = self.valid_labelelif self.mode == 'test':# 测试模式下的图像self.test_img = np.asarray(self.data_info.iloc[:, 0])self.image_arr = self.test_img# 获取图像数组的长度self.len_image = len(self.image_arr)print(f'扫描所有 {mode} 数据,共 {self.len_image} 张图像')def __getitem__(self, idx):"""获取指定索引的图像和标签。参数: idx (int): 标签文本对应编号的索引返回:如果是测试模式,返回图像张量;否则返回图像张量和标签。"""# 打开图像文件self.img = Image.open(self.file_path + self.image_arr[idx])if self.mode == 'train':# 训练模式下的数据增强trans = transforms.Compose([transforms.Resize((self.resize_height, self.resize_width)),transforms.RandomHorizontalFlip(p=0.5),transforms.RandomVerticalFlip(p=0.5),transforms.RandomRotation(degrees=30),# transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),# transforms.RandomResizedCrop(size=self.resize_height, scale=(0.8, 1.0)),transforms.ToTensor(),# transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])self.img = trans(self.img)else:# 验证和测试模式下的简单处理trans = transforms.Compose([transforms.Resize((self.resize_height, self.resize_width)),transforms.ToTensor(),# transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])self.img = trans(self.img)if self.mode == 'test':return self.imgelse:# 获取标签文本对应的编号self.label = labels_to_num[self.label_arr[idx]]return self.img, self.labeldef __call__(self, idx):"""使对象可以像函数一样被调用。参数:idx (int):标签文本对应编号的索引 返回: 调用 __getitem__ 方法并返回结果。"""return self.__getitem__(idx)def __len__(self):"""获取数据集的长度。返回: 数据集中图像的数量。"""return self.len_imagetrain_dataset = LeavesDataset(train_path, file_path)
valid_dataset = LeavesDataset(train_path, file_path, mode='valid')
test_dataset = LeavesDataset(test_path, file_path, mode='test')
2.模型构建Resnet
class Residual(nn.Module):def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)def forward(self, X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)Y += Xreturn F.relu(Y)b1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)def resnet_block(input_channels, num_channels, num_residuals, first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:blk.append(Residual(input_channels, num_channels, use_1x1conv=True, strides=2))else:blk.append(Residual(num_channels, num_channels))return blk#ResNet34
# b2 = nn.Sequential(*resnet_block(64, 64, 3, first_block=True))
# b3 = nn.Sequential(*resnet_block(64, 128, 4))
# b4 = nn.Sequential(*resnet_block(128, 256, 6))
# b5 = nn.Sequential(*resnet_block(256, 512, 3))#ResNet18
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))net = nn.Sequential(b1, b2, b3, b4, b5,nn.AdaptiveAvgPool2d((1, 1)),nn.Flatten(),nn.Linear(512, labels_num)
)
3.模型训练
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""用GPU训练模型参数:net (torch.nn.Module): 要训练的神经网络模型train_iter (torch.utils.data.DataLoader): 训练数据加载器test_iter (torch.utils.data.DataLoader): 测试数据加载器num_epochs (int): 训练的轮数lr (float): 学习率device (torch.device): 计算设备(CPU或GPU)"""# 初始化模型权重def init_weights(m):if(type(m) == nn.Linear or type(m) == nn.Conv2d):nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device)# 应用初始化权重函数# optimizer = torch.optim.SGD(net.parameters(), lr = lr)optimizer = torch.optim.Adam(net.parameters(), lr=lr, weight_decay = 0.001)# 每5个epoch学习率减少到原来的0.1倍# scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) loss = nn.CrossEntropyLoss() # 损失函数,使用交叉熵损失animator = lp.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])timer, num_batches = lp.Timer(), len(train_iter)for epoch in range(num_epochs):# 训练损失之和,训练准确率之和,样本数metric = lp.Accumulator(3)net.train() #训练模式for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad() # 梯度清零X, y = X.to(device), y.to(device)y_hat = net(X)# 前向传播l = loss(y_hat, y) # 计算损失l.backward()# 反向传播optimizer.step() # 更新参数with torch.no_grad():metric.add(l * X.shape[0], lp.accuracy(y_hat, y), X.shape[0]) # 更新指标timer.stop()train_l = metric[0] / metric[2] # 计算训练损失train_acc = metric[1] / metric[2] # 计算训练准确率# 每训练完一个批次或每5个批次更新动画if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))# 在验证集上计算准确率test_acc = lp.evaluate_accuracy_gpu(net, test_iter, device)animator.add(epoch + 1, (None, None, test_acc))# 打印当前epoch的训练损失,训练准确率和测试准确率print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')# scheduler.step()animator.show()print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')# 打印每秒处理的样本数# 超参数设置
lr, num_epochs, batch_size = 1e-5, 120, 128# 数据加载器
train_iter = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
valid_iter = DataLoader(valid_dataset, batch_size=batch_size, shuffle=False, num_workers=4)train_ch6(net, train_iter, valid_iter, num_epochs, lr, lp.try_gpu())
plt.show()# 保存模型参数
file_path_module = '../limuPytorch/module/'
torch.save(net.state_dict(), file_path_module + 'classify_leaves.params')
4.训练调参
resNet-18,num_epochs = 10,lr=1e-4,
loss 2.239, train acc 0.429, test acc 0.149
444.5 examples/sec on cuda:0resNet-34, num_epochs = 10,lr=1e-4
loss 1.991, train acc 0.443, test acc 0.147
270.7 examples/sec on cuda:0resNet-34,num_epochs = 50,lr=1e-4,train数据增强,使用Adam
loss 0.281, train acc 0.914, test acc 0.378
244.6 examples/sec on cuda:0resNet-34,num_epochs = 50,lr=1e-5,train数据增强,使用Adam
loss 0.189, train acc 0.925, test acc 0.398
258.0 examples/sec on cuda:0resNet-18,num_epochs = 50,lr=1e-4,train数据增强,使用Adam
loss 0.199, train acc 0.955, test acc 0.338
458.0 examples/sec on cuda:0resNet-18,num_epochs = 50,lr=1e-4,train数据增强,调整数据集比例8:2
数据增强过度导致测试准确率(test accuracy)曲线上下震荡resNet-18,num_epochs = 50,lr=1e-4,train数据增强,调整数据集比例为8:2
数据增强过度导致测试准确率(test accuracy)曲线上下震荡resNet-18,num_epochs = 50,lr=1e-4,train数据增强(仅旋转),调整数据集比例为8:2
loss 0.129, train acc 0.966, test acc 0.838
350.7 examples/sec on cuda:0resNet-18,num_epochs = 50,lr=1e-5,train数据增强,调整数据集比例为8:2
loss 0.808, train acc 0.788, test acc 0.701
420.6 examples/sec on cuda:0resNet-18,num_epochs = 100,lr=1e-5,train数据增强,调整数据集比例为8:2
loss 0.285, train acc 0.927, test acc 0.825
409.2 examples/sec on cuda:0
5.模型预测
def predict(model, data_loader, device):"""使用模型进行预测参数:model (torch.nn.Module): 要进行预测的模型data_loader (torch.utils.data.DataLoader): 数据加载器,用于提供待预测的数据device (torch.device): 计算设备(CPU或GPU)返回: all_preds (list): 包含所有预测结果的列表"""all_preds = [] # 存储所有预测结果model.to(device) # 将模型移动到指定设备model.eval() # 设置模型为评估模式with torch.no_grad(): # 在不需要计算梯度的上下文中进行for X in data_loader: # 遍历数据加载器X = X.to(device) # 将数据移动到指定设备outputs = model(X) # 前向传播,计算模型输出_, preds = torch.max(outputs, 1) # 获取预测结果all_preds.extend(preds.cpu().numpy()) # 将预测结果添加到列表中return all_preds # 返回所有预测结果# 克隆模型clone_net = net# 加载预训练模型参数clone_net.load_state_dict(torch.load(file_path_module + 'classify_leaves.params'))# 创建验证集的数据加载器valid_iter = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=2)# 进行预测predictions = predict(clone_net, valid_iter, lp.try_gpu())# 将预测结果映射到标签for i in predictions:predictions.append(num_to_labels[int(i)])# 读取测试数据test_data = pd.read_csv(test_path)# 将预测结果添加到测试数据中test_data['label'] = pd.Series(predictions)# 创建提交文件submission = pd.concat([test_data['image'], test_data['label']], axis=2)# 保存提交文件submission.to_csv(file_path + 'submission.csv', index=False)
7.扩展学习
# 模型构建
# 加载预训练的ResNet-18模型
#加载一个预训练的ResNet-18模型,这个模型已经在ImageNet数据集上进行了预训练。
#可以利用其提取特征的能力。
pretrained_net = models.resnet18(pretrained=True)# 克隆预训练的ResNet-18模型,用于分类叶子数据集
classify_leaves_net = pretrained_net# 修改最后的全连接层,将其输出特征数改为176(有176个类别)
# classify_leaves_net.fc.in_features 获取原始全连接层的输入特征数。
classify_leaves_net.fc = nn.Linear(classify_leaves_net.fc.in_features, 176)# 使用Xavier均匀分布初始化新的全连接层的权重
nn.init.xavier_uniform_(classify_leaves_net.fc.weight)# 模型训练部分更改优化器
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device,param_group=True):"""param_group (bool, optional): 是否对参数进行分组设置不同的学习率。默认值为True"""# optimizer = torch.optim.SGD(net.parameters(), lr = lr)# optimizer = torch.optim.Adam(net.parameters(), lr=lr, weight_decay = 0.001)if param_group:# 如果参数分组设置为True,分离出最后一层全连接层的参数# 列表params_1x,包含除最后一层全连接层外的所有参数。params_1x = [param for name, param in net.named_parameters()if name not in ["fc.weight", "fc.bias"]]optimizer = torch.optim.Adam([{'params': params_1x}, # 其他层的参数使用默认学习率{'params': net.fc.parameters(), 'lr': lr * 10} # 全连接层的参数使用更高的学习率], lr=lr, weight_decay=0.001)else:# 如果参数分组设置为False,所有参数使用相同的学习率optimizer = torch.optim.Adam(net.parameters(), lr=lr, weight_decay=0.001)相关文章:
代码实践 -卷积神经网络-30Kaggle竞赛:图片分类)
动手学深度学习(Pytorch版)代码实践 -卷积神经网络-30Kaggle竞赛:图片分类
30Kaggle竞赛:图片分类 比赛链接: https://www.kaggle.com/c/classify-leaves 导入包 import torch import torchvision from torch.utils.data import Dataset, DataLoader from torchvision import transforms import numpy as np import pandas as…...

【LeetCode】每日一题:数组中的第K大的元素
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。 请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。 你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。 解题思路 第一种是快排,快…...
安装)
Keil5.38ARM,旧编译器(V5)安装
站内文章KEIL5MDK最新版(3.37)安装以及旧编译器(V5)安装_keil5 mdk-CSDN博客...

【perl】脚本编程的一些坑案例
引言 记录自己跳进的【perl】编程小坑,以己为鉴。 1、eq $str1 "12345\n"; $str2 "12345"; if ($str1 eq $str2) { print "OK" } 上述代码不会打印 OK。特别在读文件 ,匹配字符串时容易出BUG。 案例说明: 有…...

MIX OTP——使用 GenServer 进行客户端-服务器通信
在上一章中,我们使用代理来表示存储容器。在 mix 的介绍中,我们指定要命名每个存储容器,以便我们可以执行以下操作: 在上面的会话中,我们与“购物”存储容器进行了交互。 由于代理是进程,因此每个存储容器…...

2024年云安全发展趋势预测
《2024年云安全发展趋势预测》 摘要: 云计算的普及带来了新的安全挑战。本文汇总了多家云安全厂商、专业媒体和研究机构对2024年云安全发展趋势的预测,为企业组织提供了洞察云安全威胁的新视角。 云计算的灵活性和可扩展性使其成为企业关键任务负载的首…...
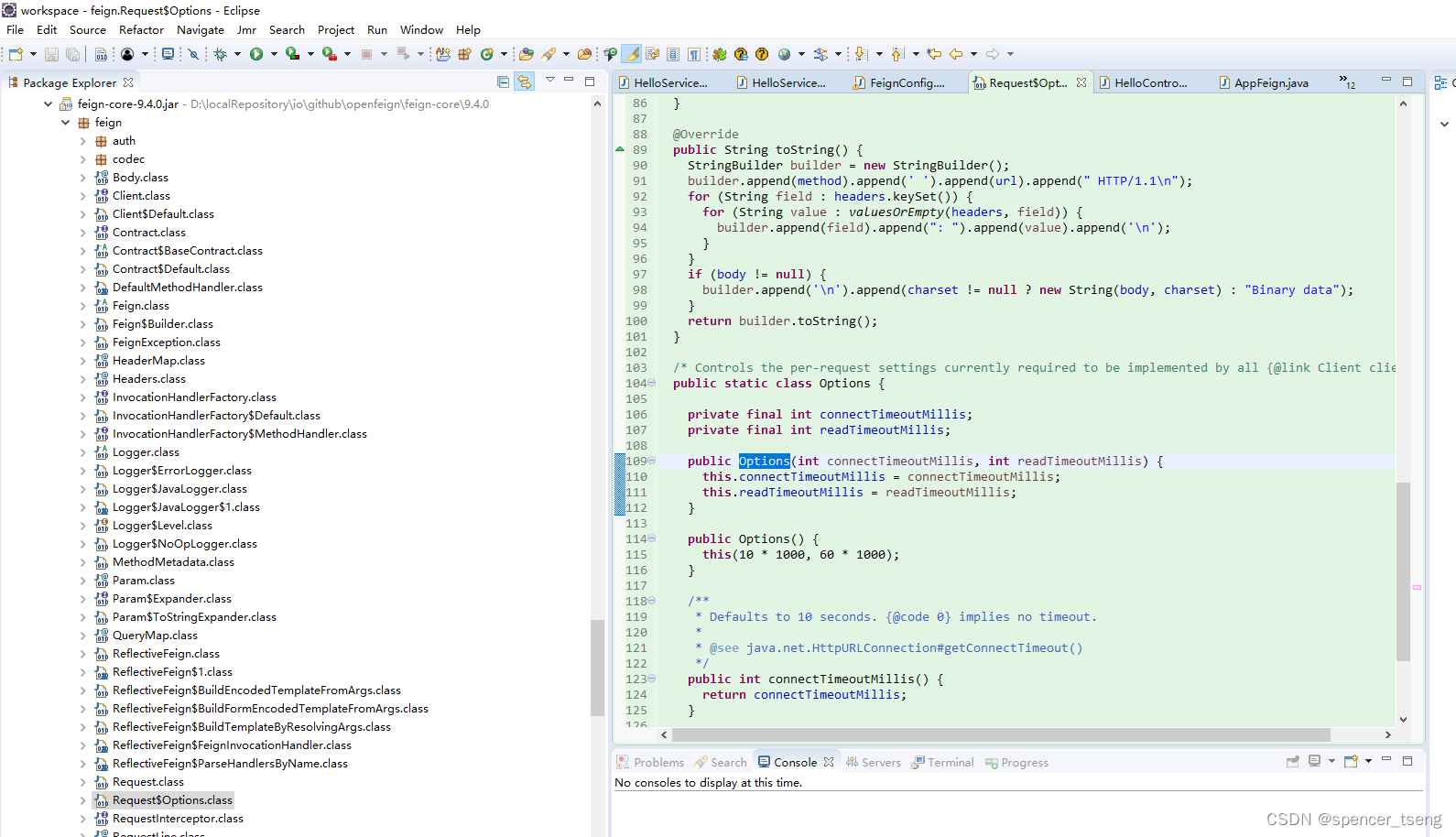
java.io.eofexception:ssl peer shut down incorrectly
可能是因为 1)https设置 2)超时设置 FeignConfig.java package zwf.service;import java.io.IOException; import java.io.InputStream; import java.security.KeyStore;import javax.net.ssl.SSLContext; import javax.net.ssl.SSLSocketFactory;import org.apac…...
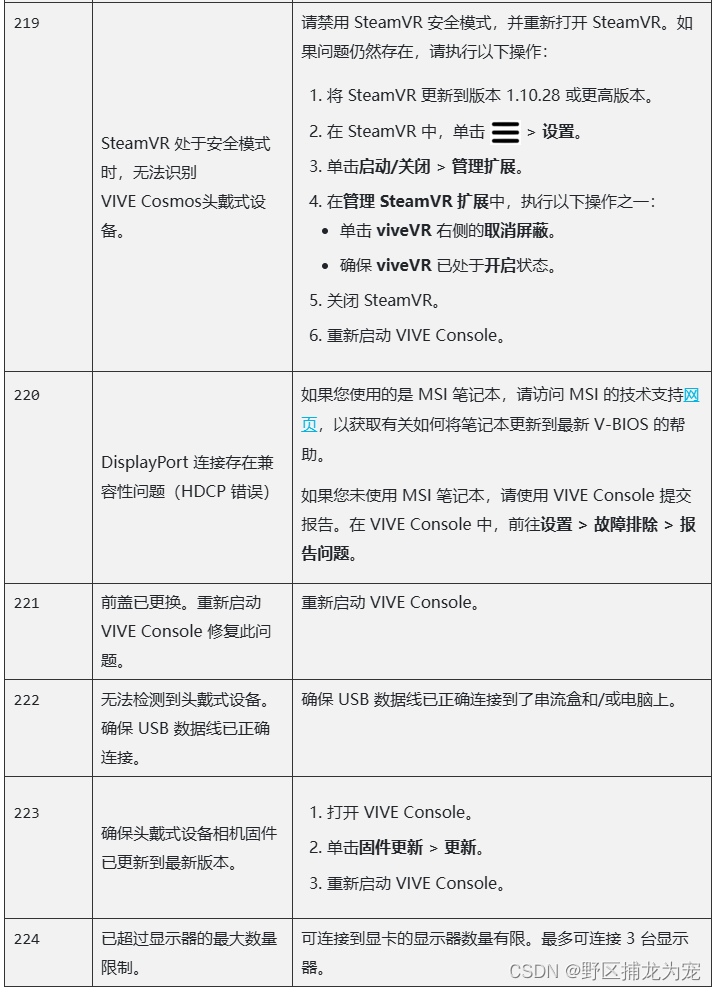
Unity之HTC VIVE Cosmos环境安装(适合新手小白)(一)
提示:能力有限,错误之处,还望指出,不胜感激! 文章目录 前言一、unity版本电脑配置相关关于unity版本下载建议:0.先下载unity Hub1.不要用过于旧的版本2.不要下载最新版本或者其他非长期支持版本 二、官网下…...
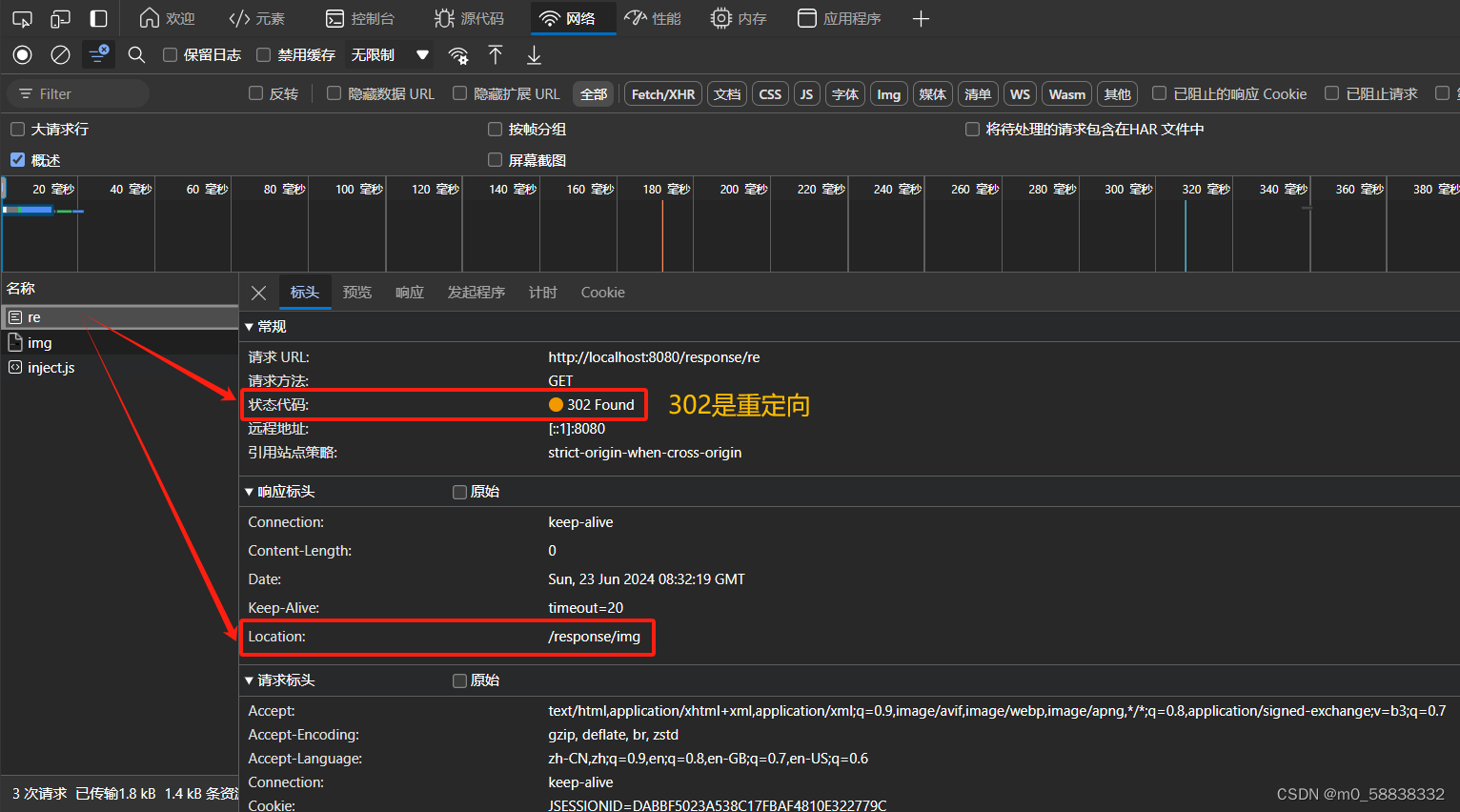
入门JavaWeb之 Response 验证码和重定向
Response 写验证码: package com.demo.response;import javax.imageio.ImageIO; import javax.servlet.ServletException; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse…...

2024-06-26 问AI: 在大数据模型中,deep speed 是什么?
文心一言 在大数据模型中,DeepSpeed是一个由微软开发并维护的开源深度学习优化库。其主要目的是提高大规模模型训练的效率和可扩展性,帮助开发者更有效率地管理及优化大模型的训练、部署任务。以下是DeepSpeed的主要特点和功能: 提高效率和…...

mobaxterm x11 转发Ubuntu mac
目录 royal tsx —— 一款Mac平台MobaXterm平替工具 mobaxterm x11 转发Ubuntu 软件 royal tsx —— 一款Mac平台MobaXterm平替工具 Royal Apps Termius Mac mobaxterm x11 转发Ubuntu 软件 所以直接在 ssh 的时候加上 - X 就可以了 ssh -X -p xxx usernameIP 运行 xclock …...
)
python数据分析实训任务三(‘职业’)
import pandas as pd import matplotlib.pyplot as plt data pd.read_csv(rC:\Users\XXGC\Desktop\职业2.csv,\ encodinggb2312) # 创建 DataFrame df pd.DataFrame(data) # 分析年龄和工资的关系 plt.scatter(df[年龄], df[工资]) plt.xlabel(年龄) pl…...
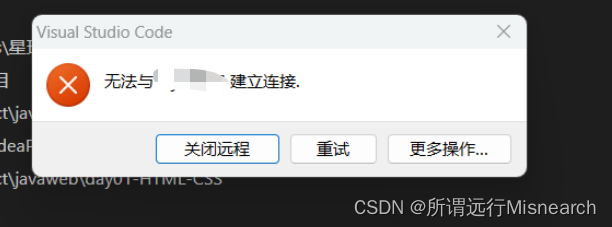
vscode连接SSH
1、安装Remote-SSH插件 2、点击左下角,选择SSH 3、点击连接到主机后,添加新的SSH主机,示例ssh 用户ip 4、点击服务器,输入密码登录服务器 5、可在远程资源管理器选项卡中查看 6、可以在ssh设置中打开ssh配置文件 config中的文件…...

金融科技行业创新人才培养与引进的重要性及挑战
金融科技行业作为金融与科技的深度融合产物,正以前所未有的速度改变着传统金融业的格局。在这一变革中创新人才的培养与引进成为了行业发展的核心驱动力。然而,尽管其重要性不言而喻,但在实际操作中却面临着诸多挑战。 一、创新人才培养与引进…...
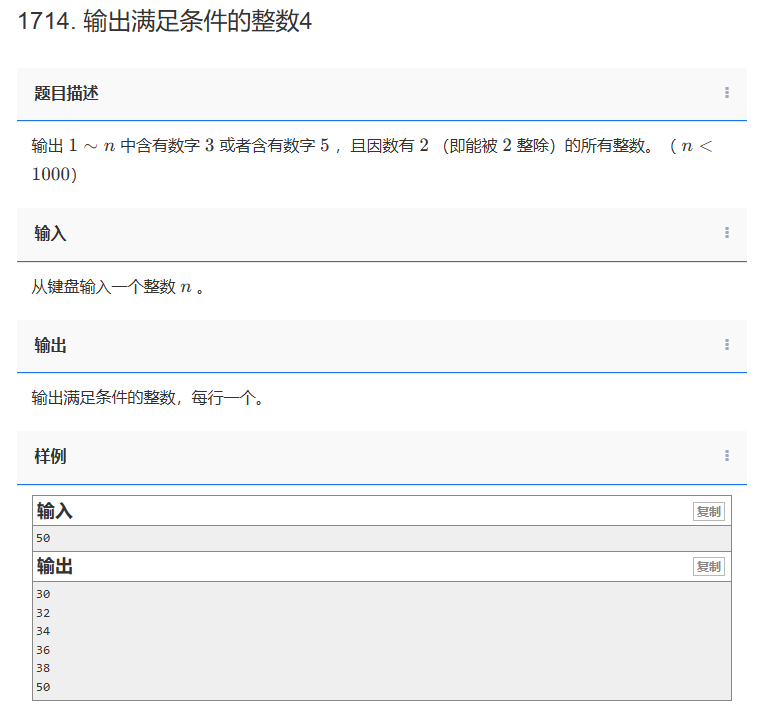
【C++题解】1714. 输出满足条件的整数4
问题:1714. 输出满足条件的整数4 类型:简单循环 题目描述: 输出 1∼n 中含有数字 3 或者含有数字 5 ,且因数有 2 (即能被 2 整除)的所有整数。(n<1000) 输入: 从键盘输入一个…...

如何安装和配置 Django 与 Postgres、Nginx 和 Gunicorn
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 先决条件 本教程假设您已经在Debian 7或类似的Linux发行版(如Ubuntu)上设置了您的droplet(VPS&#…...

Graphwalker基于模型的自动化测试
Graphwalker 基于模型的自动化测试 基于模型的自动化测试(Model-Based Testing,MBT)作为一种创新的测试方法,正逐渐受到广泛关注。Graphwalker 作为一款强大的基于模型的自动化测试工具,为我们提供了一种高效、全面的…...

Macbook M1 Fusion安装Debian/Linux
背景 本人主力工作电脑已经迁移到苹果芯片m1的macbook上,曾经尝试使用Fusion安装CentOS、OpenEuler、Ubuntu的一些版本,都没有安装成功。最近开始研究Linux/Unix系统编程,迫切需要通过VMware Fusion安装一台Linux操作系统的虚拟机。 Linux安…...

ERP收费模式是怎样的?SAP ERP是如何收费的?
一、购置SAP ERP系统的费用组成 1、软件费用 传统的ERP系统大多为许可式,即企业在购买ERP服务时付清所有费用,将ERP系统部署于自己的服务器中。根据所购买ERP系统品牌的不同,价格上也有一定的差异。采购ERP系统许可后,后续维护、…...

如何实现免交互
如何实现免交互 一、免交互 交互:我们发出指令控制程序的运行,程序在接收到指令之后按照指令的效果做出对应的反应 免交互:间接的通过第三方的方式把指令传送给程序,不用直接的下达指令 Here Document免交互:这是命…...

AI 驱动多态钓鱼攻击机理与行为防御体系研究
摘要 生成式 AI 技术推动网络钓鱼从规模化群发转向实时动态变异的多态化攻击模式,以每 15–20 秒生成唯一邮件、链接与附件,彻底颠覆基于重复特征与静态规则的传统防御逻辑。Cofense 2025 年威胁数据显示,76% 的恶意 URL 具备唯一性、82% 的恶…...

Anno 1800 Mod Loader终极指南:如何轻松解锁《纪元1800》无限模组潜力
Anno 1800 Mod Loader终极指南:如何轻松解锁《纪元1800》无限模组潜力 【免费下载链接】anno1800-mod-loader The one and only mod loader for Anno 1800, supports loading of unpacked RDA files, XML merging and Python mods. 项目地址: https://gitcode.com…...

【NotebookLM企业级部署避坑清单】:37家技术团队踩过的12个合规/安全/集成雷区,现在不看下周就宕机
更多请点击: https://intelliparadigm.com 第一章:NotebookLM企业级部署的核心价值与适用边界 NotebookLM 作为 Google 推出的基于文档理解的 AI 助手,其企业级部署并非简单地将 Web 版本私有化,而是围绕数据主权、合规闭环与业…...

CANoe各版本软件包怎么找?从Demo到Full Installer的下载指南与版本选择建议
CANoe版本管理与资源获取全攻略:从Demo到Full Installer的深度实践指南 在汽车电子开发与测试领域,Vector公司的CANoe软件堪称行业标准工具。但许多工程师在实际工作中常遇到这样的困境:项目需要特定历史版本进行兼容性测试,而官网…...

从IR压降到远程采样:大电流PCB供电设计的实战经验与陷阱规避
1. 项目背景与问题浮现几年前,我参与了一个项目,主电源是一个标准的开放式机架电源,需要为一个位于机箱内相对较远的模块提供5V、约20A的直流电。最初的供电路径设计是依靠PCB走线,我们使用了1盎司铜厚的板材。问题很快就出现了&a…...

给每个 Agent 装上专属工具集:Multi-Agent 权限隔离的三种设计模式一次讲透
我第一次写多 Agent 系统时犯过一个错误:把所有工具塞进一个 tools 数组,然后把这个数组挂给每个 Agent。结果上线后发现:负责写文章摘要的 Agent,有时候莫名其妙地调用了删除接口;负责检索资料的 Agent,偶…...

芯片行业变革:开源硬件、可重构芯片与商业模式创新
1. 行业拐点:传统芯片商业模式为何难以为继?干了十几年芯片设计,从流片工程师到项目负责人,我亲眼见证了行业从“黄金时代”到如今“卷成本、卷工艺”的艰难转型。最近和几个老同事聊天,大家不约而同地提到一个词&…...

Adobe-GenP 3.0:Adobe CC通用补丁工具终极完整指南
Adobe-GenP 3.0:Adobe CC通用补丁工具终极完整指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款功能强大的Adobe CC通用补丁工具…...

终极指南:如何用免费3D模型库打造你的Cherry MX个性化键帽
终极指南:如何用免费3D模型库打造你的Cherry MX个性化键帽 【免费下载链接】cherry-mx-keycaps 3D models of Chery MX keycaps 项目地址: https://gitcode.com/gh_mirrors/ch/cherry-mx-keycaps 想为你的机械键盘打造一套独一无二的键帽吗?Cherr…...
)
Ubuntu 20.04黑屏救星:手把手教你用tty2命令行重装NVIDIA驱动(附内核更新关闭指南)
Ubuntu 20.04黑屏救援实战:从tty2命令行到图形界面恢复全指南 当你满心欢喜地启动Ubuntu 20.04,准备开始一天的工作时,迎接你的却是一片漆黑——这是许多Linux用户都曾遭遇过的噩梦场景。NVIDIA驱动问题导致的系统黑屏不仅令人沮丧࿰…...