JAVA JVM 是怎么判定对象已经“死去”?
Java虚拟机(JVM)使用垃圾收集(Garbage Collection,GC)机制来自动管理内存,其中包括识别和回收不再使用的对象。JVM判定对象已经“死去”(即不再被任何引用所指向)的过程主要基于以下几个步骤:
1. 引用计数法:
这是一种简单的垃圾收集算法,通过为每个对象维护一个引用计数来实现。每当有一个新的引用指向该对象时,计数增加;每当一个引用被移除时,计数减少。当引用计数变为0时,对象被认为是“死去”的。然而,Java的JVM并不使用这种方法,因为它不能解决循环引用的问题。
下面V 哥介绍一下引用计数法的原理
引用计数法是一种简单的垃圾收集算法,其基本原理是为每个对象维护一个计数器,用来记录有多少个引用指向该对象。当对象被创建时,引用计数设置为1;每当有一个新的引用指向该对象时,计数器增加;每当一个引用被移除时,计数器减少。当引用计数达到0时,意味着没有任何引用指向该对象,该对象就可以被垃圾收集器回收。
然而,Java虚拟机(JVM)并没有采用引用计数法作为主要的垃圾收集策略,主要原因有:
-
循环引用问题:引用计数法无法处理循环引用的情况。如果两个对象相互引用,即使它们不再被其他任何对象所引用,它们的引用计数也不会降到0,因此不会被回收。
-
性能问题:维护每个对象的引用计数器需要额外的内存和处理时间,这可能会影响程序的性能。
-
线程安全问题:在多线程环境中,引用计数的更新需要同步,增加了实现的复杂性。
尽管JVM没有采用引用计数法作为主要的垃圾收集策略,但它确实实现了一种变体,称为“PhantomReference”(幻影引用)。PhantomReference是一种弱引用,它可以在对象被回收后进行一些清理工作,但不会阻止对象的回收。以下是PhantomReference的实现步骤:
-
创建PhantomReference:开发者创建一个PhantomReference对象,将目标对象和引用队列作为参数传递。
-
注册PhantomReference:将PhantomReference注册到一个引用队列中。当垃圾收集器准备回收目标对象时,会将PhantomReference放入引用队列。
-
垃圾收集:当垃圾收集器发现目标对象的引用计数为0时,会将其标记为可回收。但是,它不会立即回收对象,而是将其放入一个待处理的列表中。
-
处理PhantomReference:当垃圾收集器完成一轮垃圾收集后,会遍历待处理的列表,将PhantomReference放入它们注册的引用队列中。
-
执行清理工作:开发者可以在引用队列中检查是否有PhantomReference被放入,并执行一些清理工作,例如关闭文件或网络连接。
-
回收对象:在PhantomReference被处理之后,垃圾收集器最终会回收目标对象占用的内存。
PhantomReference提供了一种机制,允许开发者在对象被回收后执行一些必要的清理工作,但它并不改变JVM主要的垃圾收集策略,即基于可达性分析的标记-清除算法。
2. 可达性分析:
这是Java JVM实际使用的垃圾收集算法。从一系列被称为"GC Roots"的对象开始,所有能够从这些GC Roots直接或间接到达的对象都是活跃的。GC Roots通常包括:
- 栈中的局部变量
- 静态变量
- 活动线程的引用
- JNI全局引用
下面 V 哥介绍一下可达性分析的原理
可达性分析是Java虚拟机(JVM)中用于垃圾收集的一种算法,其核心原理是通过一系列被称为GC Roots的对象开始,遍历所有可达的对象,从而确定哪些对象是活跃的,哪些对象是不再被引用的(即“死去”的)。以下是可达性分析的详细步骤:
- 选择GC Roots:GC Roots是垃圾收集的起始点,它们是一些特殊的对象,垃圾收集器认为这些对象是活跃的。GC Roots包括:
- 栈中的局部变量
- 静态字段(如静态变量)
- 活动线程
- JNI全局引用(Java Native Interface)
-
从GC Roots开始遍历:垃圾收集器从GC Roots开始,递归地访问所有能够直接或间接到达的对象。
-
标记阶段:在遍历过程中,垃圾收集器会标记所有可达的对象。这些被标记的对象被认为是活跃的,不会被回收。
-
处理循环引用:可达性分析可以很好地处理循环引用问题。即使两个对象相互引用,只要它们不是从GC Roots直接或间接可达的,它们的引用计数就不会增加,最终会被垃圾收集器回收。
-
识别不可访问对象:在标记阶段结束后,所有未被标记的对象被认为是不可访问的,即“死去”的,它们将被垃圾收集器回收。
-
清除阶段:垃圾收集器会清除所有未被标记的对象,释放它们占用的内存。这个过程可能涉及到内存的整理,以避免内存碎片。
-
回收内存:最后,垃圾收集器会将回收的内存重新纳入可用内存池中,供新的对象使用。
-
并发处理:在多线程环境中,JVM需要处理对象引用的变化和垃圾收集的并发问题。这通常通过使用写屏障(Write Barrier)等技术来实现,确保在引用修改时,垃圾收集器能够正确地识别对象的可达性。
-
垃圾收集器的选择:JVM提供了多种垃圾收集器,它们在垃圾收集的效率和延迟方面有不同的权衡。开发者可以根据应用的需求选择合适的垃圾收集器。
可达性分析是一种高效的垃圾收集算法,它能够准确地识别出不再被引用的对象,同时处理循环引用问题,确保内存的有效利用。然而,它也可能带来一些性能开销,尤其是在对象图很大或者垃圾收集频繁的情况下。因此,JVM提供了多种垃圾收集策略和算法,以适应不同的应用场景。
3. 标记-清除:
在可达性分析之后,JVM会标记所有从GC Roots可达的对象。然后,清除那些没有被标记的对象,这些对象被认为是“死去”的。
下面 V 哥详细介绍一下标记-清除的原理
标记-清除(Mark-Sweep)是一种常见的垃圾收集算法,它分为两个主要阶段:标记阶段和清除阶段。以下是标记-清除算法的原理和JVM实现的详细步骤:
原理:
-
标记阶段:垃圾收集器遍历所有对象,从GC Roots开始,标记所有可达的对象。被标记的对象被认为是存活的,不会被回收。
-
清除阶段:在标记完成后,垃圾收集器遍历堆内存,识别出未被标记的对象,这些对象被认为是不再被引用的,随后将这些对象的内存释放。
JVM实现步骤:
-
启动GC:JVM的垃圾收集器根据一定的条件(如内存使用达到一定阈值)触发垃圾收集过程。
-
标记阶段:
- 从GC Roots开始,递归遍历所有可达对象。
- 为每个可达对象设置一个标记,表明它们是活跃的。
-
处理并发:在多线程环境中,JVM需要处理垃圾收集过程中对象引用的变化。这通常通过写屏障(Write Barrier)来实现,确保在引用修改时,垃圾收集器能够正确地识别对象的可达性。
-
暂停用户线程:在标记阶段,JVM可能会暂停所有用户线程,以确保标记过程的准确性。这是所谓的“Stop-the-World”事件。
-
清除阶段:
- 完成标记后,垃圾收集器开始清除未被标记的对象。
- 释放这些对象占用的内存。
-
处理内存碎片:清除过程可能会导致内存碎片。JVM可能会在这个阶段进行内存整理,以优化内存使用。
-
恢复用户线程:清除完成后,JVM恢复之前暂停的用户线程,让它们继续执行。
-
并发清除:在某些情况下,JVM的垃圾收集器可能会尝试并发执行标记和清除阶段,以减少对应用程序性能的影响。
-
优化和选择:JVM提供了多种垃圾收集器,它们在标记-清除算法的基础上进行了优化,以适应不同的应用场景和性能需求。
缺点:
- 内存碎片:标记-清除算法可能会导致内存碎片,因为对象被逐个清除,而不是成块清除。
- 效率问题:在标记和清除阶段,JVM可能需要暂停应用程序的执行,这在某些情况下会影响性能。
为了解决这些问题,JVM采用了其他算法,如复制算法(Copying),标记-整理算法(Mark-Compact),以及分代收集策略等,以提高垃圾收集的效率和减少对应用程序性能的影响。
4. 清除过程:
清除过程可能涉及到对象的内存释放和内存碎片的整理。这个过程可能在不同的GC算法中有所不同,例如标记-清除、复制算法、标记-整理算法等。
下面来详细介绍一下清除过程
清除过程是垃圾收集(Garbage Collection,GC)中的一个关键步骤,它发生在标记阶段之后。清除过程的目的是移除那些不再被引用的对象,从而回收它们占用的内存。以下是清除过程的原理和JVM实现的详细步骤:
原理:
清除过程的目标是高效地回收不再被使用的内存。这个过程通常涉及以下步骤:
-
识别未标记对象:在标记阶段结束后,所有未被标记的对象被认为是垃圾,即不再被任何引用所指向。
-
回收内存:垃圾收集器将这些未标记对象占用的内存释放,使其成为可用内存。
-
处理内存碎片:清除过程中可能会产生内存碎片。为了优化内存使用,可能需要进行内存整理。
JVM实现步骤:
-
触发GC:当JVM检测到内存使用达到一定阈值或满足其他GC触发条件时,开始执行垃圾收集。
-
标记阶段:从GC Roots开始,递归地标记所有可达的对象。这一阶段结束后,所有未被标记的对象都是垃圾。
-
用户线程暂停:在清除阶段开始之前,JVM可能会暂停所有用户线程,以确保清除过程不会与应用程序的执行发生冲突。
-
清除未标记对象:
- 垃圾收集器遍历堆内存,识别出未被标记的对象。
- 将这些对象的内存释放,使其成为可用内存。
- 处理内存碎片:清除后可能会产生内存碎片。JVM可以通过以下方式处理:
- 内存整理:移动存活对象,将它们紧凑地排列在一起,减少碎片。
- 内存压缩:在某些GC算法中,如标记-整理(Mark-Compact)算法,会重新排列对象来减少碎片。
-
恢复用户线程:清除完成后,JVM恢复之前暂停的用户线程,让它们继续执行。
-
并发清除:在某些垃圾收集器中,清除过程可以与应用程序的执行并发进行,以减少对性能的影响。
-
选择垃圾收集器:JVM提供了多种垃圾收集器,它们在清除算法的实现上有所不同,以适应不同的应用场景和性能需求。
-
优化和调整:JVM的垃圾收集器会根据应用程序的行为和性能反馈进行优化和调整,以提高垃圾收集的效率。
清除过程是垃圾收集中的关键环节,它直接影响到内存的回收效率和应用程序的性能。JVM通过多种策略和技术来优化清除过程,以确保内存的有效利用和应用程序的流畅执行。
5. 回收:
最后,JVM会回收那些被标记为“死去”的对象所占用的内存,并将这些内存重新纳入可用内存池中,供新的对象使用。
下面是 V 哥的详细介绍和理解
回收是垃圾收集(Garbage Collection,GC)的最终目标,即释放不再被使用的内存资源。在JVM中,回收的原理和实现步骤如下:
原理:
-
识别垃圾:通过垃圾收集算法(如标记-清除、复制、标记-整理等)识别出不再被引用的对象。
-
释放内存:将这些垃圾对象占用的内存释放,使其可以被JVM重新利用。
-
内存管理:确保内存的高效使用,避免内存碎片,优化内存分配策略。
JVM实现步骤:
-
触发GC:JVM根据内存使用情况或特定的GC触发条件,启动垃圾收集过程。
-
选择GC Roots:确定GC Roots,这些是垃圾收集的起始点,包括栈中的局部变量、静态变量、JNI全局引用等。
-
可达性分析:从GC Roots开始,进行可达性分析,标记所有可达的对象。
-
标记阶段:遍历对象图,标记所有可达的对象,未被标记的对象被认为是垃圾。
-
用户线程暂停:在某些GC算法中,可能需要暂停用户线程以保证GC的准确性。
-
回收阶段:
- 清除未标记的对象,释放它们占用的内存。
- 处理内存碎片,可能通过内存整理或压缩来优化内存布局。
-
内存整理:在某些GC算法中,如标记-整理算法,会移动存活对象,减少内存碎片。
-
恢复用户线程:GC完成后,恢复用户线程的执行。
-
并发收集:在并发GC算法中,部分GC工作可以与用户线程并发执行,以减少停顿时间。
-
内存分配:回收的内存被纳入空闲内存池,供新对象分配使用。
-
化和调整:JVM的垃圾收集器会根据应用程序的行为和性能反馈进行优化和调整。
-
选择垃圾收集器:JVM提供了多种垃圾收集器,每种收集器针对不同的应用场景和性能需求,有不同的回收策略。
回收策略:
-
分代收集:JVM通常将堆内存分为新生代和老年代,采用不同的收集策略。新生代使用复制算法,老年代可能使用标记-清除或标记-整理算法。
-
并发收集:一些垃圾收集器(如G1、ZGC、Shenandoah)支持并发收集,减少GC对应用程序性能的影响。
-
增量收集:通过分步骤执行GC,减少单次GC的停顿时间。
-
实时收集:某些垃圾收集器(如Real-Time Collector)旨在提供可预测的低延迟GC。
通过这些策略,JVM能够有效地管理内存,确保应用程序的高效运行。垃圾收集是JVM性能调优的重要组成部分,开发者需要根据应用程序的特点选择合适的垃圾收集器和参数。
5. 并发问题:
在多线程环境中,JVM还需要处理对象引用的变化和垃圾收集的并发问题。这通常通过使用写屏障(Write Barrier)等技术来实现。
在多线程环境中,垃圾收集(Garbage Collection,GC)需要处理并发问题,以确保在进行内存回收的同时,应用程序的其他线程可以继续执行,并且不会干扰垃圾收集器的工作。以下是并发问题的原理和JVM处理这些并发问题的步骤:
并发问题的原理:
-
对象引用变化:在多线程环境中,对象的引用可能随时发生变化。一个对象可能在一个线程中被引用,而在另一个线程中被取消引用。
-
内存一致性:需要保证在多线程环境下,内存操作的可见性和顺序性,确保垃圾收集器能够看到最新的对象引用状态。
-
避免Stop-the-World:长时间的GC停顿(Stop-the-World)会影响应用程序的响应时间和吞吐量。
6. 垃圾收集器的选择:
JVM提供了多种垃圾收集器,它们在垃圾收集的效率和延迟方面有不同的权衡。开发者可以根据应用的需求选择合适的垃圾收集器。
选择垃圾收集器的策略需要考虑多个因素,包括应用程序的特点、预期的性能目标、硬件环境等。以下是一些常见的选择策略和考虑因素,结合了不同应用场景的需求:
-
吞吐量优先:如果应用程序的目标是最大化CPU的利用率,即尽可能减少垃圾收集时间,提高应用程序的吞吐量,可以选择如Parallel Scavenge或G1这样的收集器。
-
低延迟优先:对于需要快速响应用户请求的应用程序,如Web应用或交易系统,可以选择CMS或G1收集器,这些收集器的设计目标是减少GC引起的停顿时间。
-
大堆内存管理:对于拥有大堆内存的应用程序,G1收集器是一个不错的选择,因为它可以很好地处理大堆并且停顿时间可控。
-
内存占用考虑:在内存资源受限的环境中,Serial收集器可能是一个好选择,尤其是对于单核处理器或小型应用。
-
多核CPU利用:对于多核CPU系统,可以利用并行或并发收集器,如Parallel Scavenge、Parallel Old或G1,这些收集器可以有效地利用多核处理器的计算能力。
-
应用的交互性:对于需要高交互性的应用程序,应选择能够提供快速响应的收集器,如CMS,以保持较好的用户体验。
-
硬件环境:考虑服务器的CPU核心数和内存大小,选择与之相匹配的收集器。例如,Parallel Scavenge和Parallel Old适合多核服务器。
-
JVM默认设置:了解不同JDK版本下的默认垃圾收集器,如JDK 1.9中G1成为默认收集器,并根据需要进行调整。
-
性能测试和监控:通过性能测试和监控来评估不同收集器的效果,根据实际运行情况选择最合适的收集器。
-
JVM参数调优:使用JVM参数来指定垃圾收集器,并根据应用程序的需要进行调优,如设置最大GC停顿时间或调整堆大小。
选择垃圾收集器并没有一劳永逸的解决方案,通常需要根据具体的应用场景和性能要求进行综合评估和调整。通过理解每种收集器的特点和工作原理,可以更好地进行性能调优和选择合适的垃圾收集器。
最后
JVM通过一系列复杂的机制来判定对象是否“死去”,并进行垃圾收集,以确保内存的有效利用和避免内存泄漏。
相关文章:

JAVA JVM 是怎么判定对象已经“死去”?
Java虚拟机(JVM)使用垃圾收集(Garbage Collection,GC)机制来自动管理内存,其中包括识别和回收不再使用的对象。JVM判定对象已经“死去”(即不再被任何引用所指向)的过程主要基于以下…...

springboot加载注入bean的方式
在SpringBoot的大环境下,基本上很少使用之前的xml配置Bean,主要是因为这种方式不好维护而且也不够方便。 springboto注入bean主要采用下图几种方式,分为本地服务工程注解声明的bean和外部依赖包中的bean。 一、 springboot装配本地服务工程…...
)
PostgreSQL 数据库设计与管理(四)
1. 数据库设计原则 1.1 规范化 规范化是组织数据库结构的一种方法,旨在减少数据冗余并提高数据完整性。常用的规范化范式包括: 第一范式(1NF): 确保每列都是原子的,不可再分。第二范式(2NF&a…...
Studying-代码随想录训练营day21| 669.修建二叉搜索树、108.将有序数组转换为二叉搜索树、538.把二叉搜索树转换为累加树、二叉树总结
第21天,二叉树最后一篇,冲💪 目录 669.修建二叉搜索树 108.将有序数组转换为二叉搜索树 538.把二叉搜索树转换为累加树 二叉树总结 669.修建二叉搜索树 文档讲解:代码随想录修建二叉搜索树 视频讲解:手撕修建二叉…...
GraphQL:简介
GraphQL 图片来源: 我们将探索GraphQL 的基础知识,并学习如何使用Apollo将其与 React 和 React Native 等前端框架连接起来。这将帮助您了解如何使用 GraphQL、React、React Native 和 Apollo 构建现代、高效的应用程序。 什么是 GraphQL?…...

AI大模型安全挑战和安全要求解读
引言 随着人工智能技术的飞速发展,大模型技术以其卓越的性能和广泛的应用前景,正在重塑人工智能领域的新格局。然而,任何技术都有两面性,大模型在带来前所未有便利的同时,也引发了深刻的安全和伦理挑战。 大模型&…...

前端面试题-token的存放位置
哈喽小伙伴们大家好,本系列是一个专门针对前端开发岗的面试题系列,每周将会不定期分享一些面试题,希望对大家有所帮助. 面试官:token 一般在客户端存在哪儿 求职者:Token一般在客户端存在以下几个地方: (1)Cookie:Token可以存储在客户端的Cookie中。服…...

深入探讨计算机网络中的各种报文
在计算机网络中,报文(Packet)是数据传输的基本单位。不同的协议使用不同类型的报文来实现数据传输的各种功能。本文将详细探讨计算机网络中常见的几种报文类型,并通过举例说明其具体应用。 一、TCP/IP协议栈中的报文 TCP/IP协议…...

Debezium系列之:Mysql和SQLServer数据库字段类型覆盖测试
Debezium系列之:Mysql和SQLServer数据库字段类型覆盖测试 一、需求背景二、类型对比三、完整流程三、Mysql数据库全字段类型覆盖测试四、SQLServer数据库字段类型覆盖测试一、需求背景 Debezium版本升级迭代,要做字段类型测试,确保版本间字段类型的差异下游能够自动适应,或…...
Mathtype7在Word2016中闪退(安装过6)
安装教程:https://blog.csdn.net/Little_pudding10/article/details/135465291 Mathtype7在Word2016中闪退是因为安装过Mathtype6,MathPage.wll和MathType Comm***.dotm),不会随着Mathtype的删除自动删除,而新版的Mathtype中的文件…...

SQL面试题练习 —— 合并用户浏览行为
目录 1 题目2 建表语句3 题解 1 题目 有一份用户访问记录表,记录用户id和访问时间,如果用户访问时间间隔小于60s则认为时一次浏览,请合并用户的浏览行为。 样例数据 ------------------------ | user_id | access_time | ---------------…...

【Docker】docker 替换宿主与容器的映射端口和文件路径
every blog every motto: You can do more than you think. https://blog.csdn.net/weixin_39190382?typeblog 0. 前言 docker 替换宿主与容器的映射端口和文件夹 1. 正文 1.1 关闭docker 服务 systemctl stop docker1.2 找到容器的配置文件 cd /var/lib/docker/contain…...

GPU算力租用平台推荐
推荐以下几家GPU算力租用平台: 1. AWS (Amazon Web Services) EC2 - AWS提供多种GPU实例,适合不同的计算需求,如机器学习、深度学习和图形渲染等。 - 优点:全球覆盖面广,稳定性高,服务支持全面。 …...
)
定个小目标之刷LeetCode热题(31)
238. 除自身以外数组的乘积 给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。请 不要使用除法&#…...

我在高职教STM32——LCD液晶显示(3)
大家好,我是老耿,高职青椒一枚,一直从事单片机、嵌入式、物联网等课程的教学。对于高职的学生层次,同行应该都懂的,老师在课堂上教学几乎是没什么成就感的。正因如此,才有了借助 CSDN 平台寻求认同感和成就…...

uniapp横屏移动端卡片缩进轮播图
uniapp横屏移动端卡片缩进轮播图 效果: 代码: <!-- 简单封装轮播图组件:swiperCard --> <template><swiper class"swiper" circular :indicator-dots"true" :autoplay"true" :interval"10000&quo…...

整合Spring Boot和Apache Solr进行全文搜索
整合Spring Boot和Apache Solr进行全文搜索 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在现代应用开发中,全文搜索是许多应用不可或缺的功能之…...

网络治理新模式:Web3时代的社会价值重构
随着Web3技术的崛起,传统的网络治理模式正在经历革新,这不仅仅是技术的进步,更是对社会价值观念的挑战和重构。本文将深入探讨Web3时代的网络治理新模式,其背后的技术基础、社会影响以及未来的发展方向。 1. 引言 Web3时代&#…...

[个人感悟] MySQL应该考察哪些问题?
前言 数据存储一直是软件开发中必不可少的一环, 从早期的文件存储txt, Excel, Doc, Access, 以及关系数据库时代的MySQL,SQL Server, Oracle, DB2, 乃至最近的大数据时代f非关系型数据库:Hadoop, HBase, MongoDB. 此外还有顺序型数据库InfluxDB, 图数据库Neo4J, 分布式数据库T…...
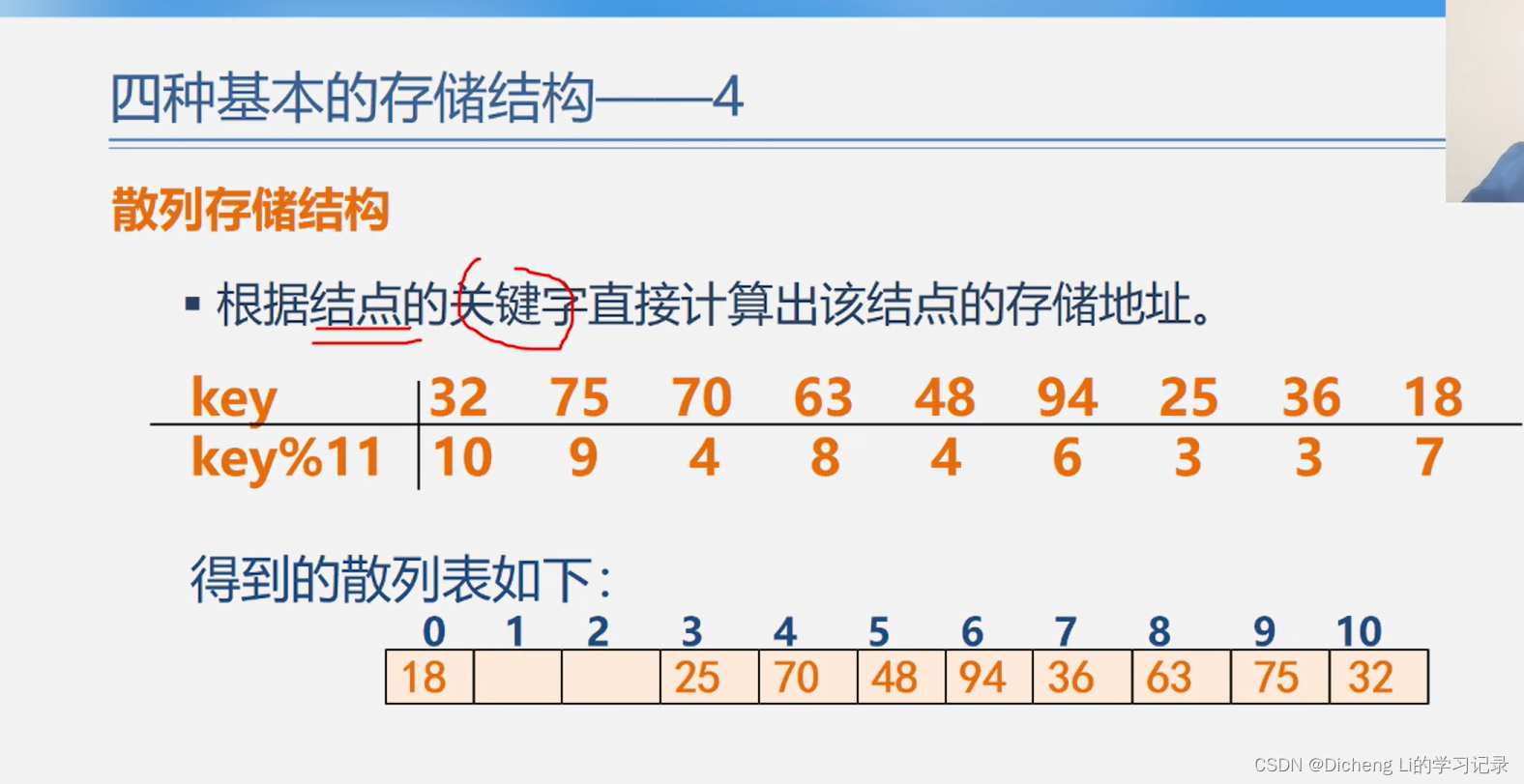
《数据结构与算法基础》学习笔记——1.2基本概念和术语
一、本章结构 二、四个数据相关专业名词的解释 两者的区别 三、数据结构相关内容 四、逻辑结构的分类 五、存储结构的分类及四种基本存储结构...

基于MCP协议构建AI知识库:解决会话失忆,实现知识持久化
1. 项目概述:让AI拥有自己的“亚历山大图书馆”如果你和我一样,长期与Claude Code、Cursor这类AI编程助手打交道,一定会遇到一个核心痛点:会话失忆。每次开启一个新对话,AI助手就像一张白纸,它对你项目的历…...

网络安全入门:2026年转行网络安全完整路径图
网络安全入门:2026 年转行网络安全完整路径图 导语:2026 年,网络安全人才缺口达 150 万,平均薪资较传统 IT 岗位高出 30%。但 70% 的转行者因路径不清晰而失败。本文详解 2026 年转行网络安全的完整路径:学习路线、证…...

macOS桌面歌词神器LyricsX:免费开源歌词同步工具完整指南
macOS桌面歌词神器LyricsX:免费开源歌词同步工具完整指南 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics LyricsX是一款专为macOS设计的开源桌面歌词显示工具…...

Kubernetes配置管理神器Monokle:可视化IDE提升YAML开发效率
1. 项目概述:一个被低估的Kubernetes配置管理神器如果你和我一样,每天都在和成堆的YAML文件、复杂的Kubernetes资源关系以及让人头疼的配置漂移问题打交道,那你一定理解那种在终端、IDE和Dashboard之间反复横跳的疲惫感。几年前,当…...

FreeVA:零训练成本,用图像大模型实现视频理解的新范式
1. 项目概述:一个无需训练的“零成本”视频助手 最近在折腾多模态大模型(MLLM)的时候,我发现了一个挺有意思的现象:大家一提到让模型理解视频,第一反应就是得搞“视频指令微调”。简单说,就是拿…...

CMS三十年:从“手工建站”到“智能基座”
一个从业者的观察与思考不知不觉,跟CMS打交道已经十几年了。从早期的织梦、帝国,到后来的WordPress,再到现在的各类无头CMS和低代码平台,这个领域的变化比想象中要快得多。写这篇文章,算是对CMS发展历程的一次梳理&…...

从高通苹果专利战看芯片产业博弈:技术、商业与供应链的纠缠
1. 从一场专利诉讼看移动通信产业的权力游戏最近翻看一些老资料,看到一篇2017年关于高通、苹果和三星的行业评论,感触颇深。那会儿高通刚对苹果发起新一轮专利诉讼,要求禁售部分iPhone;三星则靠着存储芯片的行情,眼看要…...

MagiskBoot:Android启动镜像解构与重构引擎深度解析
MagiskBoot:Android启动镜像解构与重构引擎深度解析 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk MagiskBoot作为Magisk生态系统的核心组件,专门负责Android启动镜像的多格式解…...

电源设计和效率优化案例C01
本文重点讲清楚三个非常重要的问题: 手把手教会计算电源的效率计算,包括线性电源和开关电源等 1-电源的上下管的 Qg和Rdson为什么是一对矛盾量? 2-单相30A的电流输出电源要求,对上下管子应该如何取舍这两个参数,为什么? 电源设计是硬件设计的核心组成部分,尤其事目前…...

3步精通MOOTDX:量化投资数据接口实战指南
3步精通MOOTDX:量化投资数据接口实战指南 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx MOOTDX是一个专为量化投资和数据分析设计的Python库,它提供了高效、便捷的通达信数…...