Clickhouse 的性能优化实践总结
文章目录
- 前言
- 性能优化的原则
- 数据结构优化
- 内存优化
- 磁盘优化
- 网络优化
- CPU优化
- 查询优化
- 数据迁移优化
前言
ClickHouse是一个性能很强的OLAP数据库,性能强是建立在专业运维之上的,需要专业运维人员依据不同的业务需求对ClickHouse进行有针对性的优化。同一批数据,在不同的业务下,查询性能可能出现两极分化。
性能优化的原则
在进行ClickHouse性能优化时,有几条性能优化原则。这几条原则指导了ClickHouse性能优化的方向,在优化方法发生冲突时,应当以如下两条原则为判断标准。
先优化结构,再优化查询
- 合适的表结构和数据类型可以给性能带来非常显著的提升。在尚未进行结构优化的情况下,对SQL语句进行优化,对性能的影响比较小,甚至没有任何影响。ClickHouse的查询性能受底层结构的影响非常大,因此应当先进行结构优化,再进行查询优化。
- 在对结构进行优化时,应当首先对排序键进行优化。ClickHouse通过数据聚集提高查询性能,数据结构带来的加速效应小于数据聚集带来的加速效应。建议按照排序键、数据结构、索引、查询的顺序进行ClickHouse性能调优。
空间换时间
- ClickHouse的特性是查询速度快,因此必然会遇到使用空间换时间的场景。优先对排序键进行优化,排序键优化效果最好的是最左边的第一个排序条件。对于一张宽表,在不同的业务中,排序键优化的顺序不是固定不变的。
- 遇到这种情况,就需要用到空间换时间原则,即将数据按照新的排序键保存一个副本,使用多副本来应对不同的业务需求。
- ClickHouse本身会对数据进行压缩,即使是多个副本,也可能小于真实的数据量。遇到可以使用空间换时间的场景时,可以灵活创建副本,利用冗余实现性能优化。
数据结构优化
数据结构优化指针对表设计、字段类型选择等建表过程进行优化。
ClickHouse使用存储服务于计算的设计理念,其存储引擎和计算引擎绑定,共同协调优化。
由于ClickHouse高性能算法需要底层数据结构的支撑,因此将数据结构优化为适配ClickHouse高性能算法的类型,可以极大提高ClickHouse的查询性能。
巧用特殊编码类型
- 下表列出了ClickHouse支持的几个特殊编码类型,使用特殊编码类型可以极大提高压缩效率,降低数据的大小,从而起到降低磁盘I/O的作用,提高查询性能。
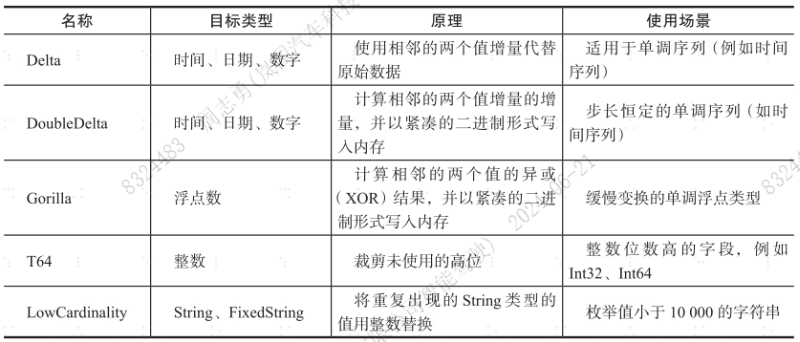
使用特殊编码类型的示例代码如下:
使用复制表作为分布式底层表
- ClickHouse的分布式表的本质是一个本地表的代理,如果其底层本地表有复制的需求,建议用户直接使用复制表,不要使用分布式表引擎提供的复制能力。
- 分布式表引擎的复制能力并不适合所有场景,有可能出现数据在两个副本中不一致的情况,从而导致查询结果出错。
设置字段类型
- 建议用户在使用ClickHouse时,按照字段的实际类型设置数据类型,不要像Hive数仓一样,全部使用String类型。
时间日期字段不要用整型的时间戳
- 在ClickHouse中,已经提供了原生的Date和DateTime类型,这两个类型底层使用时间戳保存数据,不需要针对时间日期进行优化。
- 原生的时间日期类型还可以使用ClickHouse提供的多种时间日期函数,利用ClickHouse的SIMD硬件优化查询性能。
使用默认值而不是Nullable
- ClickHouse使用Nullable标记某个字段列的数据允许为null。ClickHouse在处理null类型的数据时,会使用一个独立的数据文件来记录为null的数据,这会极大增加磁盘空间,增加磁盘I/O时间,降低查询速度。
- ClickHouse官方不建议用户使用Nullable,而是建议用户使用一个特殊意义的值配合表的默认值来处理允许为null的列。
以年龄列为例,可以定义-1为null,然后将年龄列的默认值设置为-1。通过这种方式避免Nullable对性能的影响。
使用字典代替Join操作中的表
- 对于经常参与Join操作的维度表,可以考虑是否使用ClickHouse提供的字典进行保存。
- ClickHouse的每个节点都会将配置文件中的字典载入内存,且支持动态更新字典。
- 在进行Join操作时,由于使用的字典已经预先分布到了集群中的各个节点上,所以Join操作的右表使用字典来代替可以跳过的数据传播过程,提高了查询效率。
内存优化
关闭虚拟内存
- 虚拟内存会降低ClickHouse的速度,也有可能和ClickHouse竞争磁盘I/O,所以在生产环境中最好关闭虚拟内存,以提高ClickHouse的查询性能。
尽可能使用大内存的配置
- ClickHouse在Join操作时默认使用哈希连接(Hash Join)算法,哈希连接算法会将右表载入内存进行操作。
- 如果内存不够,就会因内存溢出而导致查询失败,也可能使Join算法退化为磁盘上的Sort Merge Join算法而导致性能降低。如果业务场景中经常需要进行Join操作,那么用户应当尽可能选择大内存的配置。
磁盘优化
使用SSD
- 使用SSD(Solid-State Drive,固态硬盘)可以极大提高磁盘I/O。在条件允许的情况下,可以将ClickHouse的节点更换为SSD,以获得更好的性能。
冷热分层存储
- 使用全SSD的成本比较高,如果预算不够,那么也可以使用冷热分层存储的方案。
- 下面的代码展示了使用ClickHouse提供的TTL(Time To Live,生命周期)功能实现冷热分层的示例:

使用RAID
- 使用RAID(Redundant Array of Inexpensive Disks,磁盘阵列)提高磁盘I/O,可以防止硬盘损坏导致的数据丢失。
- ClickHouse官方建议在Linux上使用软件RAID。经过测试,建议读者首选RAID6,在保证数据安全的情况下,尽可能提高磁盘I/O速度,起到加速查询的作用。
分区粒度不宜过细
- ClickHouse的数据都在单机上,任务可能触及磁盘、CPU、内存的瓶颈,因此在单机上做并行可能是无效的。分区在ClickHouse上并不能加速查询,读者不应在ClickHouse上将分区粒度设置得太细,否则可能导致原本聚集的数据被打乱,反而影响查询速度。
做好磁盘I/O监控
- 在很多情况下,ClickHouse的瓶颈在磁盘上,建议读者做好磁盘I/O的监控。当磁盘I/O一直处于高位时,可以通过复制表分散一些查询,或者升级磁盘硬件,以获得更好的查询性能。
网络优化
网络优化的核心在于提高网卡带宽和优化网络拓扑布局,需要依照业务实际情况进行规划。
使用万兆或更高带宽的网卡
- ClickHouse集群中数据复制比较频繁,应该对ClickHouse的节点使用高性能网卡。建议使用万兆或更高带宽的网卡,高带宽的网卡可以提高网络传输的效率,提高分布式表的查询性能。
互为副本的机器安排在同一机架上
- 互为副本的集群经常需要进行数据复制,东西流量(East-West traffic)较大,为避免影响整个集群的干线网络,建议将互为副本的机器安排在同一个机架上,这样两个副本可以通过机架上的交换机进行流量传输,避免影响整个机房的带宽。
CPU优化
选择较多内核的CPU
- ClickHouse使用向量化计算引擎,会充分利用CPU的并行能力。
- 由于ClickHouse查询的大量时间都在磁盘I/O上,说明CPU经常处于等待状态,故主频对查询的影响较小。
- 在对ClickHouse硬件进行选型时,首选多核的CPU配置,避免选择CPU主频频率很高但CPU核数少的CPU配置。
选择支持SIMD的CPU
- ClickHouse计算引擎使用SIMD进行向量化加速,应该选择x86架构且支持SSE4.2指令集的CPU。生产环境尽可能不要选择ARM架构的CPU。
查询优化
Join操作时较小的表作为右表
- ClickHouse在Join操作会始终将右表载入内存,进行哈希连接。在编写Join语句时,应当将数据量比较小的表作为右表。
- 同时,在分布式表中,ClickHouse也会始终将右表广播到所有的分片上,将小表作为右表也能减少广播的数据量,提高查询速度。
使用批量写入,每秒不超过1个写入请求
- ClickHouse写入操作的成本比较高,建议使用批量写入的方法,而不要将数据一条一条地写入,尽可能保证每秒只有一个写入请求,也可以通过Buffer表进行缓冲。
对数据做好排序后再写入
- 在写入数据时,建议将数据按照表的排序键进行排序后再写入。鉴于ClickHouse的设计,每次遇到不同分区的数据都会创建一个新的临时分区,分区一旦完成写入,就会成为不可变对象。在极端情况下,未排序的数据多次创建新的临时分区,会引发too many parts的异常。批量写入数据时,事先对数据进行排序可以有效避免上述问题,从而获得很高的查询速度。
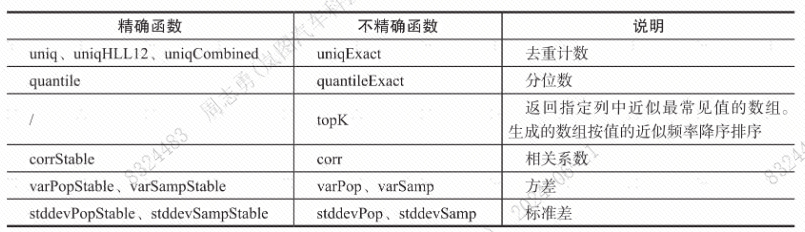
使用不精确函数以提升查询速度
- ClickHouse提供了不精确函数和精确函数两种统计函数。不精确函数只保证数据级准确,不保证精确,但查询速度快;精确函数保证数据的绝对精确,但是查询速度慢,可能触发全表扫描。在一些不需要精确数据的场景下,可以使用不精确函数进行查询。
- 下图展示了几个精确函数和不精确函数:
使用物化视图加速查询
- 物化视图的本质是一张物理表,将数据直接保存到磁盘中以提升查询速度。
- 比物理表更强大的是,物化视图还会检测底层表的变动,并自动将变动同步到物化视图的存储中。下面的代码展示了创建物化视图的方式:

Join下推
- ClickHouse并不适合超大表的Join操作,因此对于复杂的Join操作,建议将Join下推到Spark等大数据集群中实现,只将结果导入ClickHouse中供业务进行即席查询。
- 可以根据自身业务的实际情况,仔细考虑数仓的架构,对于数据量很大的业务场景,没有必要只靠ClickHouse来实现。ClickHouse只能在数据量较小的场景下取代大数据集群。
- 对于数据量庞大的场景,还是应当多种大数据技术并行,共同解决问题。
数据迁移优化
ClickHouse自带的工具具备部署简单、使用方便、维护方便等优点,但ClickHouse的原生数据迁移工具因为简单,无法支撑复杂的应用场景,建议使用Apache SeaTunnel进行数据迁移。
Apache SeaTunnel是一个优秀的高性能分布式大数据集成框架。SeaTunnel对ClickHouse进行了有针对性的优化,可以在大数据场景下更高效地进行数据迁移,为ClickHouse的用户提供了优于原生工具的使用体验。Apache SeaTunnel具备如下优势。
数据源支持丰富
- SeaTunnel定位为新一代的高性能分布式数据集成工具,官方支持二十多种数据源,这意味着使用SeaTunnel可以将多种数据源的数据导入ClickHouse,极大地补充了ClickHouse原生工具的短板。同时活跃的社区也保证工具的质量和对全新数据源的支持速度。
使用简单
- SeaTunnel是一个开箱即用的工具,部署完成后只需要通过向SeaTunnel提供配置文件即可使用,不需要配置数据库连接驱动,也不需要用户编写代码。
完全分布式
- SeaTunnel是一个完全的分布式架构,因此只需要向SeaTunnel提交任务,SeaTunnel会自动将任务进行分布式运行。借助SeaTunnel灵活的任务配置,可以更快速更简单地实现ClickHouse分布式表的数据迁移
相关文章:
Clickhouse 的性能优化实践总结
文章目录 前言性能优化的原则数据结构优化内存优化磁盘优化网络优化CPU优化查询优化数据迁移优化 前言 ClickHouse是一个性能很强的OLAP数据库,性能强是建立在专业运维之上的,需要专业运维人员依据不同的业务需求对ClickHouse进行有针对性的优化。同一批…...

变工况下转子、轴承数据采集及测试
1.固定工况下的数据采集 1.wireshark抓包 通过使用 Wireshark 抓包和 Linux 端口重放技术,可以模拟实际机械设备的运行环境,从而减少实地验证软件和算法的复杂性和麻烦。 打开设备正常运转,当采集器通过网口将数据发送到电脑时,…...

泰迪智能科技与成都文理学院人工智能与大数据学院开展校企合作交流
近日,在推动高等教育与产业深度融合的背景下,成都文理学院人工智能与大数据学院携手广东泰迪智能科技股份有限公司开展“专业建设交流会”。人工智能与大数据学院院长胡念青、院长助理陈坚、骨干教师刘超超、孙沛、赵杰、文运、胡斌、邹杰出席本次交流会…...

ubuntu22.04安装初始化
目录 1. 概述2. 修改参数3. 修改限制4. 修改源6. 虚拟机关闭swap分区7. 配置系统信息7.1 设置主机名7.2 设置时区7.3 安装常用工具包7.4 设置时间同步7.5 关闭 selinux 1. 概述 CentOS 7 马上就停止支持服务了,未雨绸缪,整理Ubuntu 22.04的 初始化脚本。…...

学习新语言方法总结(一)
随着工作时间越长,单一语言越来越难找工作了,需要不停地学习新语言来适应,总结一下自己学习新语言的方法,这次以GO为例,原来主语言是PHP ,自学GO 了解语言特性,知道他是干嘛的 go语言࿰…...

Mysql数据的备份与恢复
一.备份概述 备份的主要目的是灾难恢复,备份还可以测试应用、回滚数据修改、查询历史数据、审计等。 1.数据备份的重要性 在企业中数据的价值至关重要,数据保障了企业业务的正常运行。因此,数据的安全性及数据的可靠性是运维的重中之重&…...

规上!西安市支持培育商贸企业达限纳统应统尽统申报奖励补助要求政策
西安市支持培育商贸企业达限纳统应统尽统工作方案 为加快培育消费市场主体,支持商贸企业扩大经营、做大做强,指导企业达限纳统、应统尽统,不断扩大我市限额以上商贸企业数量规模,促进全市经济社会高质量发展,结合我市…...

Go语言测试第二弹——基准测试
在前一篇文章中,我们讲解了Go语言中最基础的单元测试,还没有看过的可以自行去查看,这篇文章我们详细了解Go语言里面的基准测试。 基准测试 基准测试,也就是BenchmarkTest,基准测试是用来测试代码性能的的一种方法&…...

关于“刘亦菲为什么无人敢娶”的问题❗❗❗
关于“刘亦菲为什么无人敢娶”的问题, 实际上涉及到多个方面的因素, 以下是对这些因素的详细分析:1.事业心重:刘亦菲作为华语影视圈的知名女星,她的演艺事业非常成功, 这也意味着她将大量的时间和精力投…...

LeetCode:经典题之141、142 题解及延伸
系列目录 88.合并两个有序数组 52.螺旋数组 567.字符串的排列 643.子数组最大平均数 150.逆波兰表达式 61.旋转链表 160.相交链表 83.删除排序链表中的重复元素 389.找不同 1491.去掉最低工资和最高工资后的工资平均值 896.单调序列 206.反转链表 92.反转链表II 141.环形链表 …...
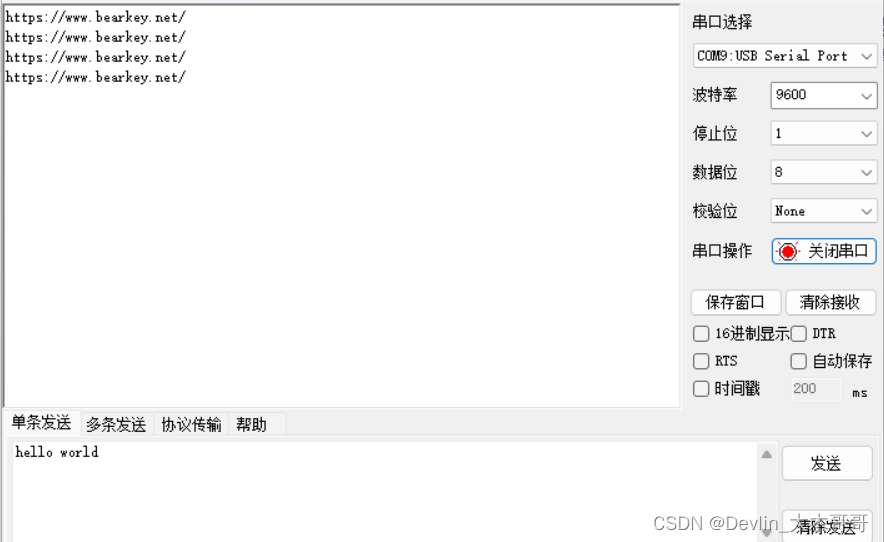
rk3568 OpenHarmony 串口uart与电脑通讯开发案例
一、需求描述: rk3568开发板运行OpenHarmony4.0,通过开发板上的uart串口与电脑进行通讯,相互收发字符串。 二、案例展示 1、开发环境: (1)rk3568开发板 (2)系统:OpenHar…...

canvas画布旋转问题
先说一下为什么要旋转的目的:因为在画布上签名,在不同的设备上我需要不同方向的签名图片,电脑是横屏,手机就是竖屏,所以需要把手机的签名旋转270,因此写了这个方法。 关于画布旋转的重点就是获取到你的画布…...

vue3 【提效】自动导入框架方法 unplugin-auto-import 实用教程
是否还在为每次都需要导入框架方法而烦恼呢? // 每次都需手动导入框架方法 import { ref } from vuelet num ref(0)用 unplugin-auto-import 来帮你吧,以后只需这样写就行啦! let num ref(0)官方示例如下图 使用流程 1. 安装 unplugin-au…...
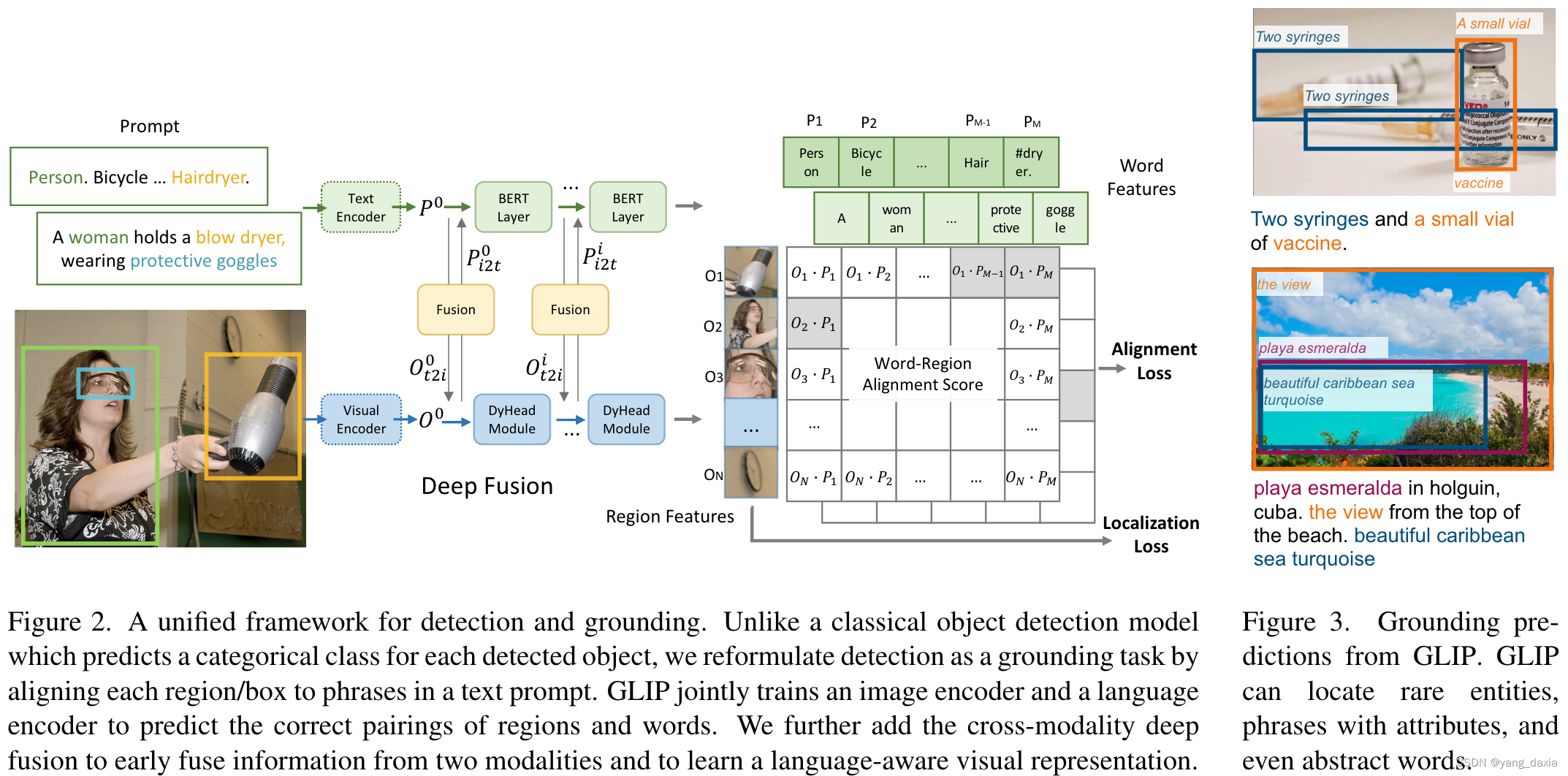
clip系列改进Lseg、 group ViT、ViLD、Glip
Lseg 在clip后面加一个分割head,然后用分割数据集有监督训练。textencoder使用clip,frozen住。 group ViT 与Lseg不同,借鉴了clip做了真正的无监督学习。 具体的通过group block来做的。使用学习的N个group token(可以理解为聚类…...

Ubuntu下TensorRT与trtexec工具的安装
新版(这里测试的是10.1版)的onnx转tensorrt engine工具trtexec已经集成在TensorRT中,不需要额外单独安装。 教程来源于此网页:https://medium.com/moshiur.faisal01/install-tensorrt-with-command-line-wrapper-trtexec-on-unun…...

MySQL定时任务
事件调度器操作 查看事件调度器是否开启:ON 表示已开启。 show variables like %event_scheduler%; ------------------------ | Variable_name | Value | ------------------------ | event_scheduler | ON | ------------------------ 开启和关闭事件调度器…...

Pandas实用Excel数据汇总
Pandas 是一个开源的 Python 库,由 Wes McKinney 开发,专门用于高效地处理和分析数据,无论是小规模的数据实验还是大规模的数据处理任务。它构建在 NumPy 之上,这意味着它利用了 NumPy 的高性能数组计算能力。Pandas 的核心数据结…...
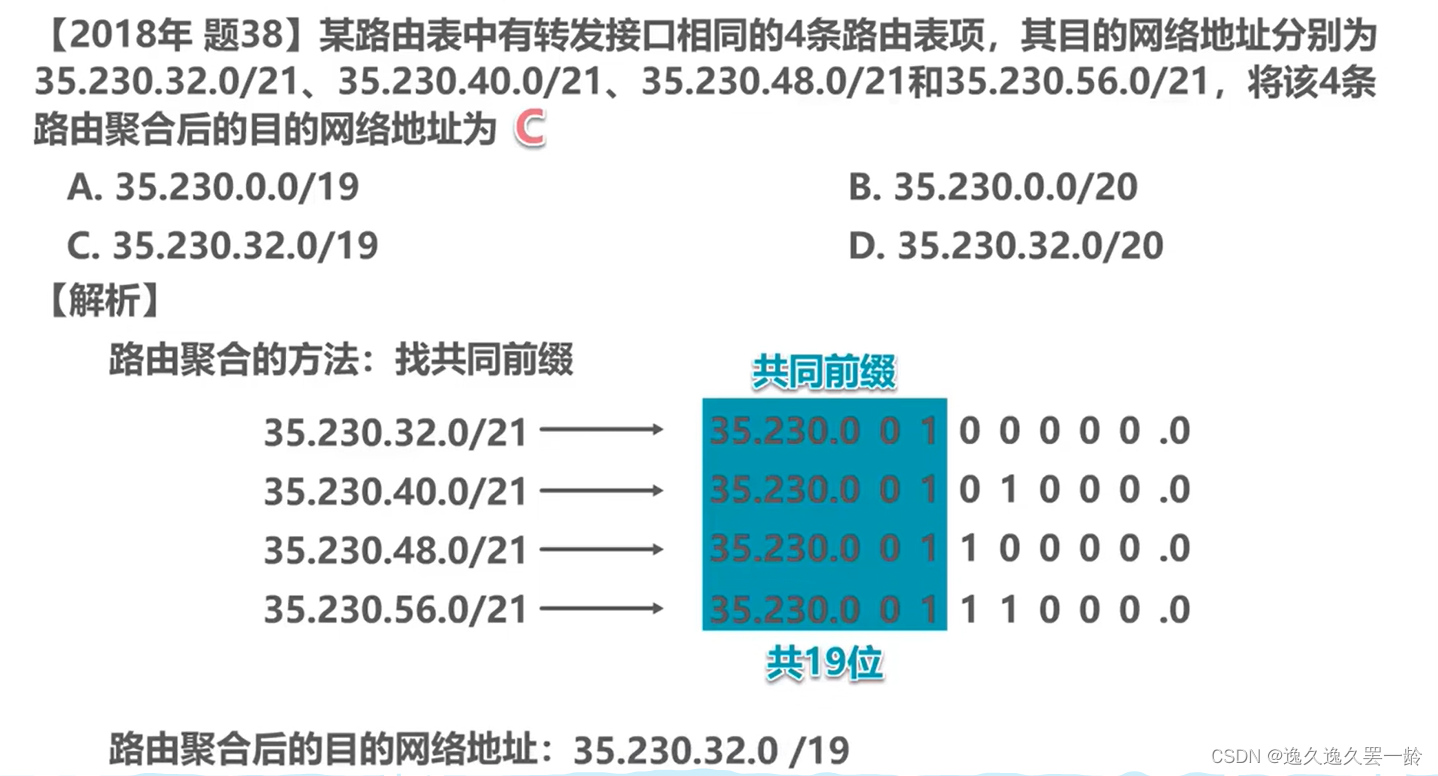
【计算机网络】[第4章 网络层][自用]
1 概述 (1)因特网使用的TCP/IP协议体系(四层)的网际层,提供的是无连接、不可靠的数据报服务; (2)ATM、帧中继、X.25的OSI体系(七层)中的网络层,提供的是面向连接的、可靠的虚电路服务。 (3)路由选择分两种: 一种是由用户or管理员人工进行配置(只适用于规…...

Unity3D Entity_CacheService实现详解
Unity3D是一款广泛使用的游戏开发引擎,它提供了丰富的功能和工具来帮助开发者创建高质量的游戏和互动体验。在Unity开发过程中,资源管理是一个重要的环节,特别是当项目规模逐渐增大,资源数量变多时。为了优化资源的加载和管理&…...
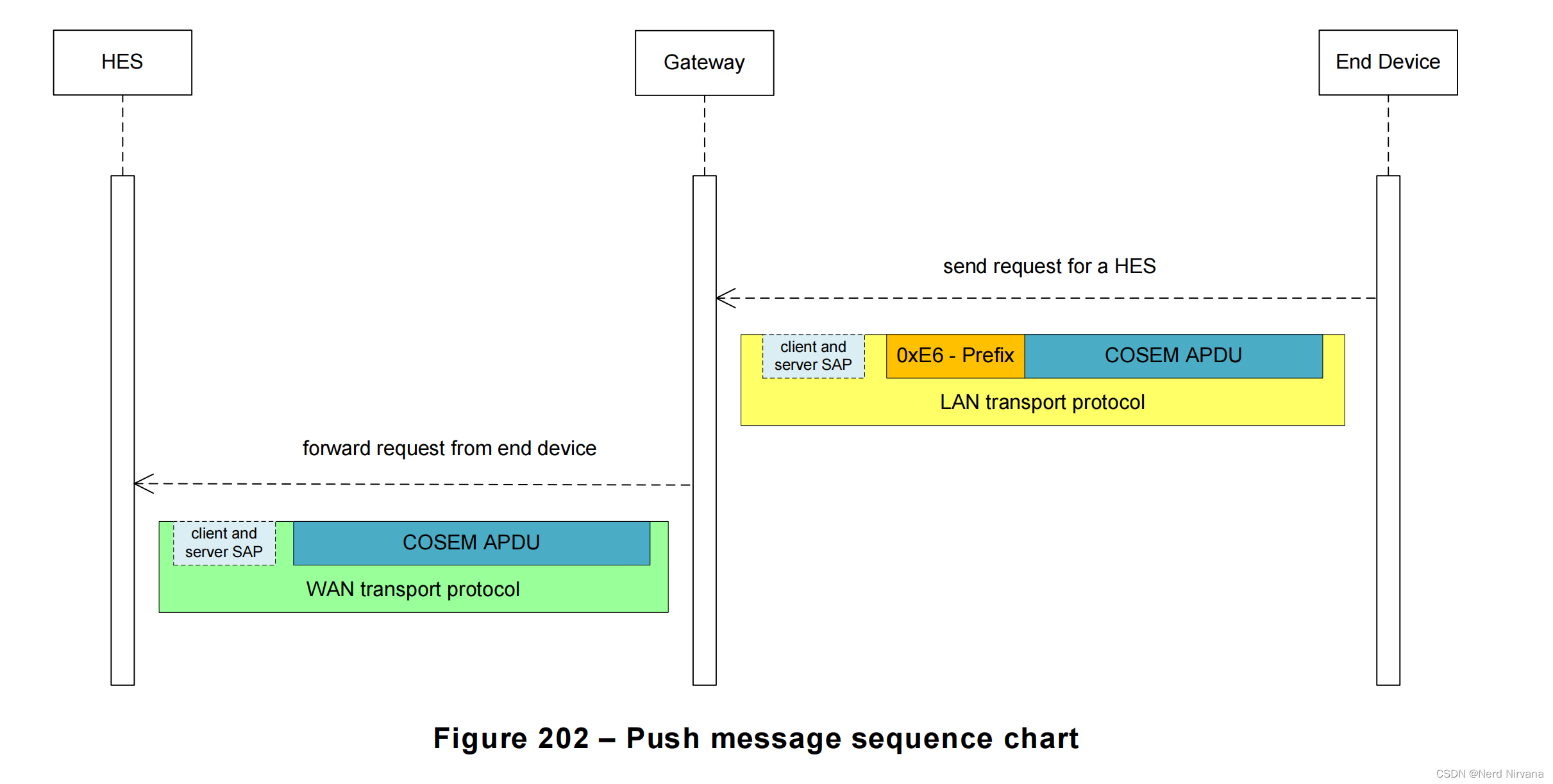
DLMS/COSEM协议—(Green-Book)Gateway protocol
DLMS/COSEM协议 — Gateway protocol 10.10 Gateway protocol (网关协议)10.10.1 概述10.10.2 网关协议 (The gateway protocol)10.10.3 HES在WAN/NN中作为发起者(拉取操作)10.10.4 LAN中的终端设备作为发起…...

AI编程助手效率革命:结构化配置与提示词工程实战
1. 项目概述:一个为AI编程时代量身定制的开发者工具箱如果你和我一样,日常开发已经离不开像 Cursor 和 Claude 这样的 AI 编程助手,那你肯定也遇到过类似的困扰:每次开启一个新项目,或者在不同项目间切换时,…...

离线AI教育工具开发实战:模型轻量化、边缘计算与五大应用场景
1. 项目概述:当AI导师走进离线课堂“每个学生都值得拥有一位AI导师”——这个想法听起来很美好,但在全球范围内,一个残酷的现实是:稳定、高速的网络连接并非理所当然。在许多乡村学校、资源匮乏的地区,甚至在城市里信号…...

初次使用Taotoken平台从注册到完成API调用的全程指引
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用Taotoken平台从注册到完成API调用的全程指引 对于初次接触大模型API的开发者而言,从注册平台到成功发出第一个…...
)
arXiv论文智能检索革命(Perplexity深度集成实战白皮书)
更多请点击: https://intelliparadigm.com 第一章:arXiv论文智能检索革命(Perplexity深度集成实战白皮书) 传统 arXiv 检索依赖关键词匹配与手动筛选,面对日均超 2000 篇新增论文,科研人员常陷入信息过载困…...

大模型风口已至:月薪30K+的AI Agent开发岗,你准备好了吗?
文章介绍了如何借助不同版本的Agents实现智能自动化,并详细描述了AI应用工程师和大模型算法工程师的岗位职责和任职要求。文章还强调了AI学习的重要性,指出最先掌握AI的人将具有竞争优势,并提供了大模型AI学习和面试资料,帮助读者…...

Antigravity AI 助手“装死”?一招解决 Git 配置引发的无响应崩溃
我们在使用 Antigravity AI IDE 进行开发时,有时会遇到一个令人头疼的现象:在对话框输入任何 Prompt 后,AI 助手仿佛“装死”一般毫无反应。没有生成提示,也没有错误弹窗,即使重启 IDE 或清理对话历史也无济于事。这不…...

从OCP协议到3D寄生提取:EDA/IP技术演进与工程实践深度解析
1. 行业动态综述:从新闻简报到深度洞察每周追踪EDA(电子设计自动化)和IP(知识产权核)领域的动态,已经成了我从业十几年来的一个习惯。这不仅仅是看看新闻,更像是定期参加一场虚拟的行业技术交流…...

伺服电机控制模式全解析:位置、速度、扭矩模式到底怎么选?手把手配置教程
伺服电机控制模式深度实战指南:从原理到参数调优 在工业自动化领域,伺服系统的精准控制直接决定了设备性能的上限。面对位置控制(PT)、速度控制(S)、扭矩控制(T)以及混合模式这四种核心控制策略,许多工程师常陷入选择困境——不同模式对应着截…...

无人机、自动驾驶如何搞定GNSS模糊度?快速固定技巧与RTKLib实战
无人机与自动驾驶中的GNSS模糊度快速固定:RTKLib实战指南 在动态环境中实现厘米级定位的关键,往往取决于GNSS信号中整周模糊度的快速准确固定。对于无人机飞控开发者而言,模糊度固定速度直接关系到飞行轨迹的平滑性;自动驾驶工程师…...
)
ZCU102开发板新手避坑:从官网下载MIG例程到LED闪烁的完整流程(Vivado 2023.1)
ZCU102开发板新手避坑:从官网下载MIG例程到LED闪烁的完整流程(Vivado 2023.1) 刚拿到ZCU102开发板时,那种既兴奋又忐忑的心情我至今记忆犹新。作为Xilinx旗下的高端FPGA开发平台,ZCU102强大的性能和丰富的接口让它成为…...