Python 算法交易实验73 QTV200第二步: 数据清洗并写入ClickHouse
说明
先检查一下昨天启动的worker是否正常工作,然后做一些简单的清洗,存入clickhouse。
内容
1 检查数据
from Basefuncs import *
# 将一般字符串转为UCS 名称
def dt_str2ucs_blockname(some_dt_str):some_dt_str1 =some_dt_str.replace('-','.').replace(' ','.').replace(':','.')return '.'.join(some_dt_str1.split('.')[:4])
'''
dt_str2ucs_blockname('2024-06-24 09:30:00')
'2024.06.24.09'
'''
# 测试队列声明
qm = QManager(redis_agent_host = 'http://192.168.0.4:xx/',redis_connection_hash = None,q_max_len= 1000000, batch_size=10000)
qm.info()
target_stream_name = 'xxx'
qm.stream_len(target_stream_name)
2804
获取数据(使用单worker,模式比较简单且性能足够)
data = qm.xrange(target_stream_name)['data']
data_df = pd.DataFrame(data)
keep_cols = ['rec_id', 'data_dt','open', 'close','high','low','vol', 'amt', 'data_source','code','market']
data_df1 = data_df[keep_cols].dropna().drop_duplicates(['rec_id'])# 第一次操作,把之前无关的数据删掉
data_df1 = data_df1[data_df1['data_dt'] >='2024-06-24 00:00:00']
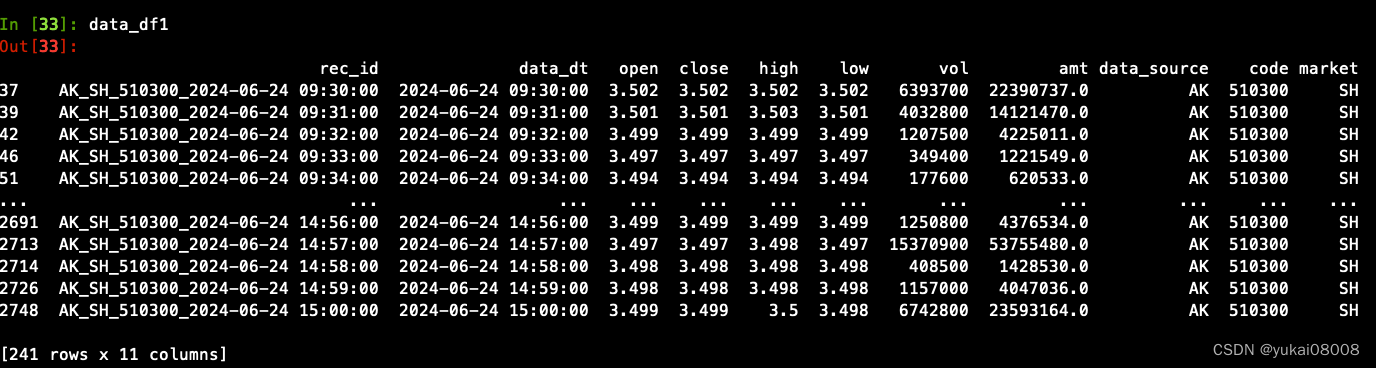
向clickhouse发起query,请求每个etf的最大时间,之后要使得新增的数据大于这个时间,另外目标表的字段形如

这是之前做的设计,因为隔的时间有点久都有点忘了。不过这个设计是合理的,后面会看到。
要做的转换也很简单:
- 1 将时间字符转为时间戳
- 2 从日期中分解出shard、part、block和brick
转换段
import timedata_df1['ts'] = data_df1['data_dt'].apply(inverse_time_str).apply(int)data_df1['brick'] = data_df1['data_dt'].apply(dt_str2ucs_blockname)
data_df1['block'] =data_df1['brick'].apply(lambda x: x[:x.rfind('.')])
data_df1['part'] =data_df1['block'].apply(lambda x: x[:x.rfind('.')])
data_df1['shard'] =data_df1['part'].apply(lambda x: x[:x.rfind('.')])data_df1['pid'] = data_df1['code'].apply(str) + '_' + data_df1['ts'].apply(str)keep_cols1 = ['data_dt','open','close','high','low', 'vol','amt', 'brick','block','part', 'shard', 'code','ts', 'pid']
data_df2 =data_df1[keep_cols1]

今天就到这里吧,明晚接着写。
Go on …
昨天疏忽了,数据不应该直接存库,而是应该整理好之后送到队列。然后由默认的worker将数据搬到clickhouse.
2 存数规则
第二步的输入队列BUFF.xxxstream_in,输出队列BUFF.xxx.stream_out。
第一次需要确保对应数据表的存在。clickhouse对数值的要求比较严格,为了避免麻烦,统一设置成Float32。(这样可以用统一的同步worker)。另外clickhouse不支持删除数据,这点倒是比较特别。
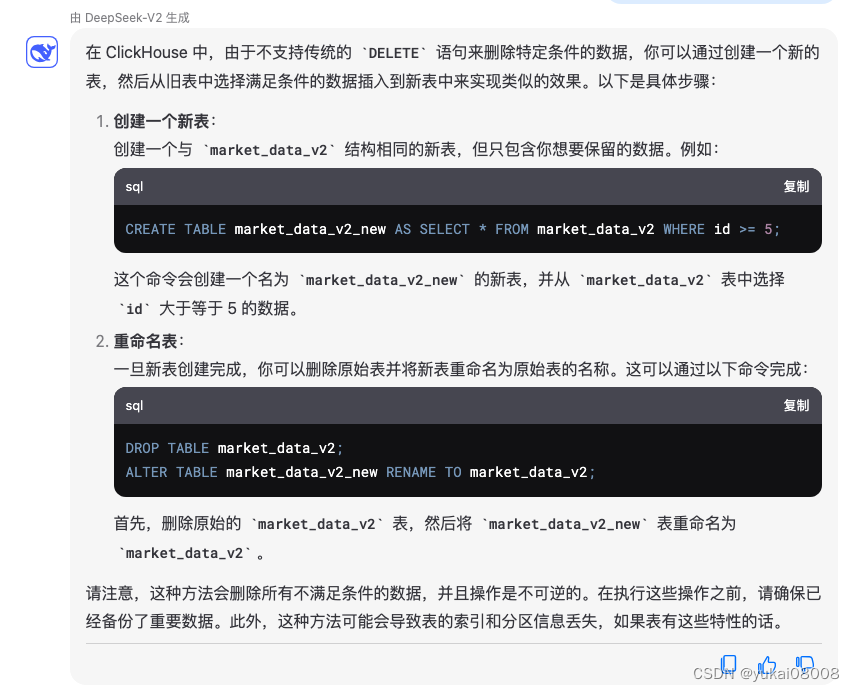
但可以支持全部删除数据(保留数据结构) TRUNCATE table market_data_v2
create_table_sql = '''
CREATE TABLE market_data_v2
(data_dt String,open Float32,close Float32,high Float32,low Float32,vol Float32,amt Float32,brick String,block String,part String,shard String,code String,ts Float32,pid String
)
ENGINE = MergeTree
ORDER BY (ts )
'''click_para = gb.getx('sp_global.buffer.lan.xxx.xxx.para')
chc = CHClient(**click_para)
chc._exe_sql(create_table_sql)
chc._exe_sql('show tables')
[('market_data',), ('market_data_v2',)]
etl_worker.py
# 0 记录日志
import logging
from logging.handlers import RotatingFileHandlerlogger = logging.getLogger('MyLogger')
handler = RotatingFileHandler('/var/log/workers.log', maxBytes=1024*1024*100, backupCount=5)
logger.addHandler(handler)
logger.setLevel(logging.INFO)# ---------------------------------------- 设置日志from Basefuncs import *
def tuple_list2dict(tuple_list):"""将包含三个元素的tuple列表转换为字典。参数:tuple_list (List[Tuple[K, V1, V2]]): 包含键和两个值的tuple的列表。返回:Dict[K, Tuple[V1, V2]]: 转换后的字典,其中值是包含两个元素的tuple。"""return {key:value1 for key, value1 in tuple_list}# 将一般字符串转为UCS 名称
def dt_str2ucs_blockname(some_dt_str):some_dt_str1 =some_dt_str.replace('-','.').replace(' ','.').replace(':','.')return '.'.join(some_dt_str1.split('.')[:4])
'''
dt_str2ucs_blockname('2024-06-24 09:30:00')
'2024.06.24.09'
'''
# ---------------------------------------- 基本函数# 测试队列声明
qm = QManager(redis_agent_host = 'http://192.168.0.4:xx/',redis_connection_hash = None,q_max_len= 1000000, batch_size=10000)
qm.info()
source_stream_name ='stream_in'
target_stream_name ='stream_out'
source_stream_len = qm.stream_len(source_stream_name)
target_stream_len = qm.stream_len(target_stream_name)
print('source',source_stream_len)
print('target', target_stream_len)
# qm.ensure_group(target_stream_name)
cur_dt_str = get_time_str1()
if source_stream_len:is_source_recs = True
else:is_source_recs = Falselogger.info('%s %s source No Recs' %(cur_dt_str,'etl_worker'))
# 获取数据(使用单worker,模式比较简单且性能足够)# ---------------------------------------- 队列取数,有数据才执行下面
if is_source_recs:# ---------------------------------------- 取数,取出消息列表和需要的列# worker 30 秒启动一次data = qm.xrange(source_stream_name)['data']data_df = pd.DataFrame(data)msg_id_list = list(data_df['_msg_id'])keep_cols = ['rec_id', 'data_dt','open', 'close','high','low','vol', 'amt', 'data_source','code','market']data_df1 = data_df[keep_cols].dropna().drop_duplicates(['rec_id'])# 第一次操作,把之前无关的数据删掉# data_df1 = data_df1[data_df1['data_dt'] >='2024-06-24 00:00:00']import timedata_df1['ts'] = data_df1['data_dt'].apply(inverse_time_str).apply(int)data_df1['brick'] = data_df1['data_dt'].apply(dt_str2ucs_blockname)data_df1['block'] =data_df1['brick'].apply(lambda x: x[:x.rfind('.')])data_df1['part'] =data_df1['block'].apply(lambda x: x[:x.rfind('.')])data_df1['shard'] =data_df1['part'].apply(lambda x: x[:x.rfind('.')])data_df1['pid'] = data_df1['code'].apply(str) + '_' + data_df1['ts'].apply(str)keep_cols1 = ['data_dt','open','close','high','low', 'vol','amt', 'brick','block','part', 'shard', 'code','ts', 'pid']data_df2 =data_df1[keep_cols1]# ------------------------------------- 获取当前数据库已有的数据# 获取各code最大值click_para = {'database': 'xx','host': '192.168.0.4','name': 'xx','password': 'xx','port': xxx,'user': 'xx'}chc = CHClient(**click_para)'''这个 SQL 语句的作用是按照 `code` 分组,并为每个 `code` 找到对应的最新日期(`data_dt`),这个最新日期是基于 `ts` 字段的最大值来确定的。`argMax` 函数在这里用于找到每个分组中 `ts` 值最大时对应的 `data_dt` 值。具体来说,`argMax(data_dt, ts)` 会返回每个 `code` 分组中使得 `ts` 达到最大值的 `data_dt` 值。这意味着对于每个 `code`,查询会找到 `ts` 字段的最大值,并返回对应的 `data_dt` 值,即每个 `code` 的最新数据日期。最终,这个查询会返回一个结果集,其中包含每个 `code` 以及对应的最新数据日期(`last_data_dt`)。这对于分析每个代码的最新市场数据非常有用。'''latest_sql = '''SELECTcode,argMax(data_dt, ts) AS last_data_dtFROMmarket_data_v2GROUP BYcode'''# 更新时latest_date_tuple_list = chc._exe_sql(latest_sql)latest_date_dict = tuple_list2dict(latest_date_tuple_list)# ------------------------------------- 使用时间进行过滤# 筛选新数据data_df2['existed_dt'] = data_df2['code'].map(latest_date_dict).fillna('')output_sel = data_df2['data_dt'] > data_df2['existed_dt']output_df = data_df2[output_sel][keep_cols1]output_data_listofdict = output_df.to_dict(orient='records')output_data_listofdict2 = slice_list_by_batch2(output_data_listofdict, qm.batch_size)for some_data_listofdict in output_data_listofdict2:qm.parrallel_write_msg(target_stream_name, some_data_listofdict)del_msg = qm.xdel(source_stream_name, msg_id_list)logger.info('%s %s del source %s Recs' %(cur_dt_str,'etl_worker',del_msg['data'] ))将该脚本发布为任务,30秒执行一次同步。
exe_qtv200_etl_worker.sh
#!/bin/bash# 记录
# sh /home/test_exe.sh com_info_change_pattern running# 有些情况需要把source替换为 .
# . /root/anaconda3/etc/profile.d/conda.sh
# 激活 base 环境(或你创建的特定环境)
source /root/miniconda3/etc/profile.d/conda.sh#conda init
conda activate basecd /home/workers && python3 etl_worker.py
存数成功,后续就自动运行了。
相关文章:
Python 算法交易实验73 QTV200第二步: 数据清洗并写入ClickHouse
说明 先检查一下昨天启动的worker是否正常工作,然后做一些简单的清洗,存入clickhouse。 内容 1 检查数据 from Basefuncs import * # 将一般字符串转为UCS 名称 def dt_str2ucs_blockname(some_dt_str):some_dt_str1 some_dt_str.replace(-,.).re…...

记录:有趣的C#多元运算符 ? : 表达式写法
有时候用 if //...Whatre you she wanna go else if //...do do do else //...and i know something just like this... 感觉代码太多了怎么优雅的、高端的替换? 看个高端的栗子菊: LedCOM["parity"] ledData[4] "N" ? …...

华宽通中标长沙市政务共性能力建设项目,助力智慧政务建设新飞跃
在数字化浪潮的推动下,长沙市政府正积极拥抱智慧城市建设,以科技力量提升政务服务效能。华宽通凭借其卓越的技术实力与丰富的项目经验,成功中标长沙市政务共性能力建设项目,这无疑是对华宽通在智慧城市领域实力的高度认可。 华宽…...

[面试题]计算机网络
[面试题]Java【基础】[面试题]Java【虚拟机】[面试题]Java【并发】[面试题]Java【集合】[面试题]MySQL[面试题]Maven[面试题]Spring Boot[面试题]Spring Cloud[面试题]Spring MVC[面试题]Spring[面试题]MyBatis[面试题]Nginx[面试题]缓存[面试题]Redis[面试题]消息队列[面试题]…...

企业级低代码开发效率变革赋能业务增长
企业级低代码开发已经成为当今软件开发领域的一大趋势,它为企业带来了前所未有的效率变革,从而赋能业务增长。本文将围绕这一主题,深入探讨低代码开发的概念、优势以及如何在企业级应用中实现高效的低代码开发,以助力我国企业实现…...

2024最新总结:1500页金三银四面试宝典 记录35轮大厂面试(都是面试重点)
学习是你这个职业一辈子的事 手里有个 1 2 3,不要想着去怼别人的 4 5 6,因为还有你不知道的 7 8 9。保持空瓶心态从 0 开始才能学到 10 全。 毕竟也是跳槽高峰期,我还是为大家准备了这份1500页金三银四宝典,记录的都是真实大厂面…...

使用Spring Boot和Thymeleaf构建动态Web页面
使用Spring Boot和Thymeleaf构建动态Web页面 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天,我们将探讨如何利用Spring Boot和Thymeleaf构建动…...

扫盲之webSocket
介绍 webSocket 是一种协议,设计用于在客户端和服务器之间提供低延迟、全双工、和长期运行的连接。 全双工:通信的两个参与方可以同时发送和接收数据,不需要等待对方的响应或传输完成 websocket就是为了解决实时通信的问题 建立webSocke…...

一些硬件知识(十二)
1、请说明一下滤波磁珠和滤波电感的区别。 因此磁珠通常用于模数地的连接。 磁珠由导线穿过铁氧体组成,直流电阻很小,在低频时阻抗也很小,对直流信号几乎没有影响。 在高频(几十兆赫兹以上)时磁珠阻抗比较大࿰…...

Adobe Acrobat编辑器最新版下载安装 Adobe Acrobat版本齐全!
功能强大,Adobe Acrobat无疑是PDF文档处理领域的翘楚。这款软件集多种PDF文档处理功能于一身,不仅使得用户可以轻松地编辑PDF文档,更能轻松应对转换和合并等多种需求。 在编辑功能上,Adobe Acrobat的表现尤为出色。无论是添加文字…...

k8s如何使用 HPA 实现自动扩展
使用Horizontal Pod Autoscaler (HPA) 实验目标: 学习如何使用 HPA 实现自动扩展。 实验步骤: 创建一个 Deployment,并设置 CPU 或内存的资源请求。创建一个 HPA,设置扩展策略。生成负载,观察 HPA 如何自动扩展 Pod…...

Hi3861 OpenHarmony嵌入式应用入门--0.96寸液晶屏 iic驱动ssd1306
使用iic驱动ssd1306,代码来源hihope\hispark_pegasus\demo\12_ssd1306 本样例提供了一个HarmonyOS IoT硬件接口的SSD1306 OLED屏驱动库,其功能如下: 内置了128*64 bit的内存缓冲区,支持全屏刷新;优化了屏幕刷新速率,…...

代码随想录训练营第二十二天 77组合
第一题: 原题链接:77. 组合 - 力扣(LeetCode) 思路: 经典的回溯模板题: 终止条件,当中间变量用来存储单个结果的大小等于k,则将中间变量存放到结果数组中。 一个for循环横向遍历…...
Unity踩坑记录
1. 如果同时在父物体和子物体上挂载BoxCollider,那么当使用: private void OnTriggerEnter2D(Collider2D collision){if (collision.CompareTag("CardGroup")){_intersectCardGroups.Add(collision.GetComponent<CardGroup>());}} 来判…...

内容安全复习 1 - 信息内容安全概述
文章目录 信息内容安全简介网络空间信息内容安全大模型 人工智能简介 信息内容安全简介 网络空间 网络空间是融合物理域、信息域、认知域和社会域,控制实体行为的信息活动空间。 上图展示了网络空间安全的结构。可以看到将网络空间划分为了网络域和内容域两个部分。…...

【深度学习】python之人工智能应用篇--跨模态生成技术
跨模态生成技术概述 跨模态生成技术是一种将不同模态的数据(如文本、图像、音频、视频等)进行融合和转换的技术。其目标是通过将一个模态的数据作为输入,生成与之对应的另一个模态的输出。这种技术对于突破单一模态的局限性,提高…...

springboot中获取某个注解下面的某个方法的方法名,参数值等等详细实例
在Spring Boot应用中,获取某个类或方法上的注解及其相关信息,包括方法名称、参数值等,通常涉及到反射和Spring的AOP(面向切面编程)特性。下面是一个示例,展示如何利用Spring AOP的Around注解来拦截带有特定…...

代码随想录——跳跃游戏Ⅱ(Leetcode 45)
题目链接 贪心 class Solution {public int jump(int[] nums) {if(nums.length 1){return 0;}int count 0;// 当前覆盖最远距离下标int curDistance 0;// 下一步覆盖距离最远下标int nextDistance 0;for(int i 0; i < nums.length; i){nextDistance Math.max(nums[…...

从0-1搭建一个web项目(package.json)详解
本章分析package.json文件详解 本文主要对packge.json配置子文件详解 ObJack-Admin一款基于 Vue3.3、TypeScript、Vite3、Pinia、Element-Plus 开源的后台管理框架。在一定程度上节省您的开发效率。另外本项目还封装了一些常用组件、hooks、指令、动态路由、按钮级别权限控制等…...

图解ReentrantLock的基石AQS-独占锁的获取与释放
大家好,我是呼噜噜,我们之前聊过Java中以互斥同步的方式保证线程安全:Sychronized,这次我们来再聊聊另一种互斥同步的方式Lock,本文会介绍ReentrantLock及其它的基石AQS的源码解析,一个非常重要的同步框架 …...

Wireshark 命令行实战指南 ———— 自动化抓包与高效分析
1. 为什么需要Wireshark命令行模式 很多网络工程师第一次接触Wireshark时,都是通过图形界面进行操作。鼠标点点就能开始抓包,确实很方便。但当你需要处理以下场景时,图形界面就显得力不从心了: 服务器环境没有图形界面,…...

基于本地AI的语音转文字工具OpenWhisp:隐私优先的离线生产力方案
1. 项目概述:一个完全本地的语音转文字工具 作为一个长期在效率工具和本地AI应用领域折腾的开发者,我一直在寻找一个能让我彻底摆脱网络延迟和隐私顾虑的语音输入方案。市面上的云服务要么有订阅费,要么有数据上传的隐忧,直到我看…...

如何快速上手Podgrab:5分钟搭建个人播客下载中心完整指南
如何快速上手Podgrab:5分钟搭建个人播客下载中心完整指南 【免费下载链接】podgrab A self-hosted podcast manager/downloader/archiver tool to download podcast episodes as soon as they become live with an integrated player. 项目地址: https://gitcode.…...

Vite+React+TypeScript构建个人作品集网站:从技术选型到GitHub Pages自动化部署
1. 项目概述:一个现代开发者如何构建自己的技术名片最近刚把自己的个人作品集网站重构上线,地址是https://yucco-k.github.io。这不仅仅是一个展示作品的静态页面,更是一个我用来实践和整合现代前端技术栈的“游乐场”。对于开发者而言&#…...

从零构建开源任务管理中枢:TaskWing部署、插件化与自动化实战
1. 项目概述:从零到一,打造你的个人任务管理中枢如果你和我一样,每天被各种待办事项、项目进度、临时想法和会议记录搞得焦头烂额,那么你肯定不止一次地想过:有没有一个工具,能真正“懂”我,能把…...
)
告别一堆转换头!一个自研小工具搞定USB、网口、485、232、TTL全互连(附配置软件)
极简主义工程师的终极武器:全协议互连调试工具实战指南 每次出差调试设备,我的背包里总塞满了各种转换头——USB转串口、网口转485、232电平转换器...直到上个月在客户现场,当我蹲在机柜旁手忙脚乱切换第五个转换器时,螺丝刀不小心…...

构建现代化图片编辑器的Vue与Fabric.js实践指南
构建现代化图片编辑器的Vue与Fabric.js实践指南 【免费下载链接】vue-fabric-editor 快图设计-基于fabric.js和Vue的开源图片编辑器,可自定义字体、素材、设计模板。fabric.js and Vue based image editor, can customize fonts, materials, design templates. 项…...

MILCOM 2011技术风向:软件定义无线电、GaN与宽带测试的军用射频演进
1. 展会现场直击:MILCOM 2011的技术脉搏作为一名在射频微波和测试测量领域摸爬滚打了十几年的工程师,我对MILCOM(军事通信会议)这类展会总有一种特殊的感情。它不像那些消费电子展那样光鲜亮丽,人头攒动,但…...

WindowsCleaner终极指南:3步彻底解决Windows系统卡顿与C盘爆红问题
WindowsCleaner终极指南:3步彻底解决Windows系统卡顿与C盘爆红问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经面对Windows系统日益缓慢…...

终极歌词获取方案:163MusicLyrics让你轻松获取网易云和QQ音乐LRC歌词
终极歌词获取方案:163MusicLyrics让你轻松获取网易云和QQ音乐LRC歌词 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为寻找准确歌词而烦恼吗?…...