大数据之Hadoop部署
文章目录
- 服务器规划
- 服务器环境准备
- 1. 网络测试
- 2. 安装额外软件包
- 3. 安装基础工具
- 4. 关闭防火墙
- 5. 创建用户并配置权限
- 6. 创建目录并设置权限
- 7. 卸载JDK
- 8. 修改主机名
- 9. 配置hosts文件
- 10. 重启服务器
- 配置免密登录
- 安装Java
- 安装Hadoop
- 1. Hadoop部署
- 2. 配置Hadoop
- 3. 格式化Hadoop文件系统
- 4. 启动Hadoop集群
- 5. 验证Hadoop集群
- 注意事项
- 参考文件

搭建一个Hadoop集群涉及到多个步骤,包括服务器规划, 服务器环境准备,配置SSH无密码登录,安装Java,安装Hadoop,配置Hadoop,以及格式化和启动Hadoop集群。以下是在三台CentOS系统服务器上搭建Hadoop集群的必要步骤和详细的描述:
服务器规划
- 准备三台服务器(Hadoop101、Hadoop102、Hadoop103), 确保都已经安装了
CentOS 7.9操作系统。 - 为每台服务器配置静态IP地址,确保它们在同一子网内,并且子网掩码、网关和DNS设置正确。
- 使得三台服务器之间可以互相ping通。
- 确保三台服务器都能够访问互联网。
- 角色规划
Hadoop101作为NameNode和ResourceManager,负责集群的文件系统命名空间和资源管理。Hadoop102作为SecondaryNameNode,辅助NameNode进行元数据备份,不直接处理客户端读写请求。Hadoop101、Hadoop102、Hadoop103作为DataNode和NodeManager,存储实际的数据块并提供计算能力
| Hadoop101 | Hadoop102 | Hadoop103 |
|---|---|---|
| NameNode | SecondaryNameNode | - |
| DataNode | DataNode | DataNode |
| ResourceManager | - | - |
| NodeManager | NodeManager | NodeManager |
服务器环境准备
对每台服务器做如下检查和配置, 下面是在root用户下进行操作。
1. 网络测试
- 确保虚拟机可以正常上网。
ping www.baidu.com
2. 安装额外软件包
- 安装
epel-release以获取更多软件包。yum install -y epel-release
3. 安装基础工具
- 如果是最小系统版,需要安装以下工具:
net-tools:包含ifconfig等网络配置命令。yum install -y net-toolsvim:文本编辑器。yum install -y vim
4. 关闭防火墙
- 停止并禁用防火墙服务。
systemctl stop firewalld systemctl disable firewalld.service
5. 创建用户并配置权限
- 创建
bigdata用户并设置密码。useradd bigdata passwd bigdata - 配置
bigdata用户具有root权限,无需密码即可执行sudo命令。vim /etc/sudoers- 在
/etc/sudoers文件中添加:bigdata ALL=(ALL) NOPASSWD:ALL
- 在
6. 创建目录并设置权限
- 在
/opt目录下创建module和software文件夹。mkdir /opt/module mkdir /opt/software - 修改文件夹的所有者和所属组为
bigdata。chown bigdata:bigdata /opt/module chown bigdata:bigdata /opt/software - 查看文件夹的所有者和所属组。
ls -al /opt
7. 卸载JDK
- 如果服务器预装了JDK,执行以下命令卸载:
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
8. 修改主机名
- 登录到目标服务器:使用SSH或其他远程登录方式登录到需要修改主机名的服务器。
- 编辑主机名配置文件:使用文本编辑器(如
vim)编辑/etc/hostname文件。sudo vim /etc/hostname - 设置新的主机名:在文件中输入新的主机名,例如
hadoop101,然后保存退出。 - 更新系统识别的主机名:使更改立即生效,可以使用以下命令:
sudo hostname -F /etc/hostname
9. 配置hosts文件
- 打开
hosts文件:编辑/etc/hosts文件,以将IP地址映射到相应的主机名。sudo vim /etc/hosts - 添加或更新条目:在文件中添加或更新映射关系,每条映射占一行,格式为
IP地址 空格 主机名。例如:
这里的IP地址替换为自己服务器的IP地址。192.168.10.101 hadoop101 192.168.10.102 hadoop102 192.168.10.102 hadoop103 - 确保无重复条目:检查
hosts文件以确保没有重复或冲突的条目,这可能会导致网络解析问题。 - 保存并关闭文件:完成编辑后,保存更改并关闭文本编辑器。
10. 重启服务器
- 完成配置后,重启服务器以应用更改。
reboot
配置免密登录
为了方便管理,需要在服务器之间使用bigdata用户配置SSH无密码登录。
-
切换到
bigdata用户su bigdata -
hadoop101生成SSH密钥对:ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa该命令会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)。
-
hadoop101上执行命令ssh-copy-id, 将hadoop101公钥复制到每台服务器的~/.ssh/authorized_keys:ssh-copy-id hadoop101 ssh-copy-id hadoop102 ssh-copy-id hadoop103
安装Java
下面的操作使用bigdata 用户在 hadoop101上进行操作。
-
切换到
/opt/software目录cd /opt/software -
使用
wget下载 Java 1.8 版本wget https://repo.huaweicloud.com/java/jdk/8u202-b08/jdk-8u202-linux-x64.tar.gz请检查链接是否有效,因为Oracle的下载链接可能会变化。
-
使用
tar解压文件到/opt/module目录tar -xzvf jdk-8u301-linux-x64.tar.gz -C /opt/module/ -
生成软链接
ln -s /opt/module/jdk1.8.0_301 /opt/module/jdk -
设置 JDK 的环境变量
-
新建
/etc/profile.d/bigdata_env.sh文件touch /etc/profile.d/bigdata_env.sh -
添加如下内容,然后保存(:wq)退出
#JAVA_HOME export JAVA_HOME=/opt/module/jdk export PATH=$PATH:$JAVA_HOME/bin -
让环境变量生效
source /etc/profile.d/bigdata_env.sh
-
-
验证安装
java -version echo $JAVA_HOME -
分发软件和环境变量
- 将
JAVA软件,JAVA软连接,环境变量配置文件分发到hadoop102和hadoop103上
# 分发到 hadoop102 rsync -av "/opt/module/jdk1.8.0_202" "hadoop102:/opt/module" rsync -av "/opt/module/jdk" "hadoop102:/opt/module" sudo rsync -av "/etc/profile.d/bigdata_env.sh" "hadoop102:/etc/profile.d" # 分发到 hadoop103 rsync -av "/opt/module/jdk1.8.0_202" "hadoop103:/opt/module/" rsync -av "/opt/module/jdk" "hadoop103:/opt/module/" sudo rsync -av "/etc/profile.d/bigdata_env.sh" "hadoop103:/etc/profile.d" - 将
安装Hadoop
1. Hadoop部署
下面的操作使用bigdata 用户在 hadoop101上进行操作。
-
进入Hadoop安装包路径
- 打开终端,使用命令
cd /opt/software/进入包含Hadoop安装包的目录。
- 打开终端,使用命令
-
下载Hadoop
从华为镜像下载Hadoop的tar.gz包,并解压到合适的目录。# 下载hadoop3.3.1 wget https://mirrors.huaweicloud.com/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz -
解压Hadoop安装文件
- 将Hadoop压缩包解压到
/opt/module/目录。tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
- 将Hadoop压缩包解压到
-
验证解压结果
- 通过执行命令
ls /opt/module/hadoop-3.1.3来检查Hadoop目录是否存在,以确认解压操作是否成功。
- 通过执行命令
-
创建Hadoop软连接
- 如果解压成功,创建软连接
hadoop,以简化路径。ln -s /opt/module/hadoop-3.1.3 /opt/module/hadoop
- 如果解压成功,创建软连接
-
编辑环境变量配置文件
-
首先,使用
pwd命令获取当前Hadoop安装目录的完整路径。 -
接着,使用
sudo vim /etc/profile.d/bigdata_env.sh命令以超级用户权限打开环境变量配置文件进行编辑。 -
在打开的配置文件中,滚动到文件末尾(使用
Shift + G)。 -
添加以下行来设置Hadoop的环境变量:
# HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin -
这些行将Hadoop的bin和sbin目录添加到系统的PATH环境变量中,使得可以在任何位置调用Hadoop的命令。
-
在Vim编辑器中,使用
:wq命令保存更改并退出编辑器。
-
-
使环境变量生效
- 在
hadoop101上执行下面的命令source /etc/profile.d/bigdata_env.sh
- 在
-
验证安装
- 通过下面命令验证安装是否成功,以及环境变量是否生效。
hadoop version echo $HADOOP_HOME
- 通过下面命令验证安装是否成功,以及环境变量是否生效。
-
分发软件和环境变量
- 将
Hadoop软件,Hadoop软连接,环境变量配置文件分发到hadoop102和hadoop103上# 分发到 hadoop102 rsync -av "/opt/module/hadoop-3.1.3" "hadoop102:/opt/module" rsync -av "/opt/module/hadoop" "hadoop102:/opt/module" sudo rsync -av "/etc/profile.d/bigdata_env.sh" "hadoop102:/etc/profile.d" # 分发到 hadoop103 rsync -av "/opt/module/hadoop-3.1.3" "hadoop103:/opt/module/" rsync -av "/opt/module/hadoop" "hadoop103:/opt/module/" sudo rsync -av "/etc/profile.d/bigdata_env.sh" "hadoop103:/etc/profile.d"
- 将
2. 配置Hadoop
进入hadoop配置目录cd /opt/module/hadoop/etc/hadoop/, 修改Hadoop配置文件core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml, workers ,设置集群模式和相关参数。
-
文件
core-site.xml配置:<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop101:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop/data</value></property><!-- 配置HDFS网页登录使用的静态用户为bigdata --><property><name>hadoop.http.staticuser.user</name><value>bigdata</value></property><!-- 配置该bigdata(superUser)允许通过代理访问的主机节点 --><property><name>hadoop.proxyuser.bigdata.hosts</name><value>*</value></property><!-- 配置该bigdata(superUser)允许通过代理用户所属组 --><property><name>hadoop.proxyuser.bigdata.groups</name><value>*</value></property><!-- 配置该bigdata(superUser)允许通过代理的用户--><property><name>hadoop.proxyuser.bigdata.users</name><value>*</value></property> </configuration> -
文件
hdfs-site.xml配置:<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop101:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop102:9868</value></property><!-- 测试环境指定HDFS副本的数量1 --><property><name>dfs.replication</name><value>3</value></property> </configuration> -
文件
yarn-site.xml配置<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop101</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!--yarn单个容器允许分配的最大最小内存 --><property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>4096</value></property><!-- yarn容器允许管理的物理内存大小 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><!-- 关闭yarn对物理内存和虚拟内存的限制检查 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>true</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property> </configuration> -
文件
mapred-site.xml配置<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property> </configuration> -
文件
workers配置hadoop101 hadoop102 hadoop103 -
分发配置文件
- 将配置文件分发到
hadoop102和hadoop103上# 分发到 hadoop102 rsync -av "/opt/module/hadoop/etc/hadoop" "hadoop102:/opt/module/hadoop/etc/" # 分发到 hadoop103 rsync -av "/opt/module/hadoop/etc/hadoop" "hadoop103:/opt/module/hadoop/etc/"
- 将配置文件分发到
3. 格式化Hadoop文件系统
-
在NameNode服务器上(
hadoop101)格式化Hadoop文件系统。hdfs namenode -format
4. 启动Hadoop集群
-
启动Hadoop集群的所有守护进程。
start-dfs.sh start-yarn.sh
5. 验证Hadoop集群
-
使用
jps命令检查Java进程,确认Hadoop守护进程是否启动。jps # hadoop101 上启动以下进程 6084 DataNode 6552 NodeManager 6426 ResourceManager 5935 NameNode # hadoop102 上启动以下进程 30834 ResourceManager 28487 SecondaryNameNode 28695 NodeManager 28379 DataNode # hadoop103 上启动以下进程 2466 NodeManager 2340 DataNode -
页面查看
-
hdfs 页面地址
http://hadoop101:9870
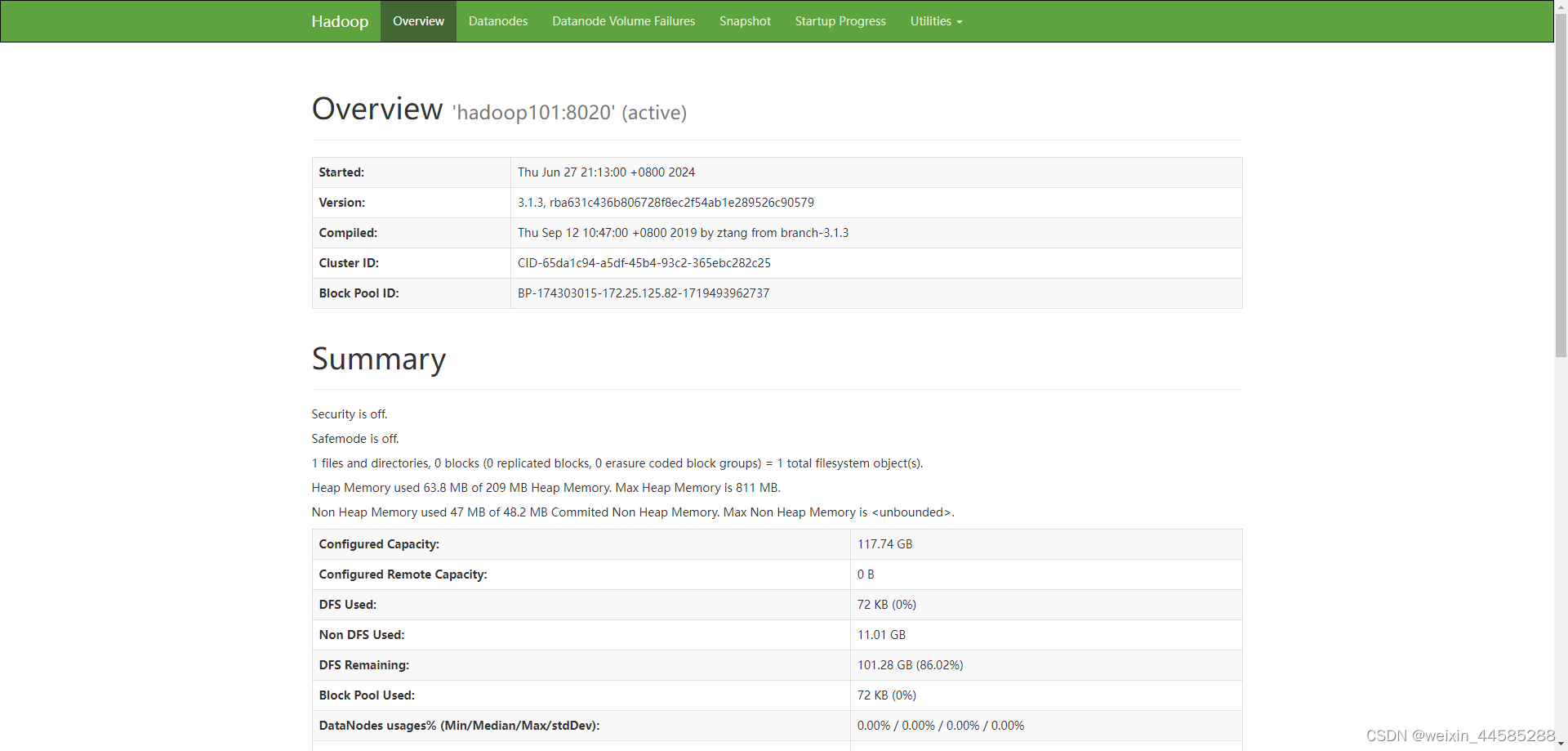
-
yarn 页面地址
http://hadoop101:8088

-
注意事项
- 企业开发中,单个服务器的防火墙通常是关闭的,但公司整体会设置安全的防火墙。
参考文件
Java | 华为镜像仓库
相关文章:
大数据之Hadoop部署
文章目录 服务器规划服务器环境准备1. 网络测试2. 安装额外软件包3. 安装基础工具4. 关闭防火墙5. 创建用户并配置权限6. 创建目录并设置权限7. 卸载JDK8. 修改主机名9. 配置hosts文件10. 重启服务器 配置免密登录安装Java安装Hadoop1. Hadoop部署2. 配置Hadoop3. 格式化Hadoop…...

Java异常处理中的“throw”与“throws”的区别
在Java中,throw 和 throws 是两个用于处理异常的关键词,它们的使用场景和目的有所不同 1. throw throw 关键字用于在Java程序中显式地抛出一个异常。当你检测到某些条件(通常是错误条件)时,你可以使用 throw 来抛出一…...
英语智汇学习系统
目 录 1 软件概述 1.1 项目研究背景及意义 2 系统相关技术 2.1 HTML、WXSS、JAVASCRIPT技术 2.2 Vanilla框架 2.3 uni-app框架 2.4 MYSQL数据库 3 需求分析 3.1 可行性分析 3.2 功能需求分析 3.3 系统用户及用例分析 3.4 非功能需求分析 3.5 数据流图…...

ExtractAItoTEXT 提取Adobe illustrator AI文件中的文字到文本文件翻译并写回到Adobe illustrator AI文件
Extract Text from Adobe illustrator to text for translate and write back to Adobe illustrator after translate in text file. Originally script from marceloliaohotmail.com during his work in SDL. Updated by me. 从Adobe illustrator中提取文本以进行翻译&#x…...

ms17-010 ms12-020 ms-08-067
MS17-010是一个由微软发布的安全公告编号,它指代了一个严重级别的安全漏洞,该漏洞存在于Microsoft Windows的Server Message Block 1.0 (SMBv1)协议处理中。这个漏洞被命名为“永恒之蓝”(EternalBlue),因为它最初是由…...

【海思Hi3403V100】多目拼接相机套板硬件规划方案
海思Hi3403V100 是专业超高清智能网络摄像头 SoC。该芯片最高支持四路 sensor 输入,支持最高 4K60fps 的 ISP 图像处理能力,支持 3F 、WDR、多级降噪、六轴防抖、硬件拼接、多光谱融合等多种传统图像增强和处理算法,支持通过AI 算法对输入图像…...

AI的赚钱风向,彻底变了!
从2023年3月起,生成式AI技术的浪潮席卷全球,让不少人开始焦虑中国AI技术与美国的差距。然而,最近的趋势显示,AI创业的盈利模式已经发生了根本性的变化。今年,我们见证了AIGC(人工智能生成内容)企…...

服务器重启后jenkins任务内容不见了,并且新建任务也不见了
服务器centos7.4 背景:服务器异常重启后,jenkins上面的任务只剩下一些前端项目,后端的任务都不展示了,jenkins版本是Jenkins 2.346.3 解决方案:根据显示,jenkins很多的插件引用失败,显示需要升…...

如何选择合适的WordPress主机?
选择合适的WordPress主机需要考虑多个因素,包括性能、速度、存储空间、带宽、硬件配置、操作系统、支持的软件版本以及安全性等。以下是一些详细的建议: 性能和速度:选择一个能够提供快速加载速度和稳定性能的主机至关重要。快速加载的网站不…...

面试突击:Java 集合知识体系梳理
本文已收录于:https://github.com/danmuking/all-in-one(持续更新) 前言 哈喽,大家好,我是 DanMu。在 Java 开发中,集合类对象绝对是被使用最频繁的对象之一。因此,深入了解集合类对象的底层数…...

AI智能管理系统设计文档
AI智能管理系统设计文档 1. 引言 本设计文档旨在开发一套全面的AI智能管理系统,以优化生产运营效率和决策质量。该系统将利用先进的AI技术和数据分析能力,提供自动化流程控制、预测性维护、智能决策支持等功能。 2. 需求分析与目标设定 2.1 业务需求…...

干涉阵型成图参数记录【robust】
robust 这个玩意经常忘记,就是取2的时候是更加显示大尺度的结构,取-2更加显示小尺度结果,一般取0就是正常就好了...

React Native工程运行时下载gradle超时问题
React Native工程在运行Android的时候会下载gradle,但是由于众所周知的问题,总是下载失败,这时可以通过修改 <APP_ROOT>/android/wrapper/gradle-wrapper.properties 文件中 distributionUrl 参数使用国内 gradle 镜像来提高下载速度。…...

本地离线模型搭建指南-LLaMA-Factory训练框架及工具
搭建一个本地中文大语言模型(LLM)涉及多个关键步骤,从选择模型底座,到运行机器和框架,再到具体的架构实现和训练方式。以下是一个详细的指南,帮助你从零开始构建和运行一个中文大语言模型。 本地离线模型搭…...

数智化金融采购系统特点
数智化金融采购系统是郑州信源公司结合众多金融行业采购特点,采用流程优化再造的理念,为银行、保险、证券、交易所等金额机构打造的细分行业产品,助力金融行业采购合规管理、风险防范、成本管理和效率提升。 系统特点 1、全业务覆盖&#x…...

使用 SwiftUI 为 macOS 创建类似于 App Store Connect 的选择器
文章目录 前言创建选择器组件使用选择器组件总结前言 最近,我一直在为我的应用开发一个全新的界面,它可以让你查看 TestFlight 上所有可用的构建,并允许你将它们添加到测试群组中。 作为这项工作的一部分,我需要创建一个组件,允许用户从特定构建中添加和删除测试群组。我…...

Python26 Lambda表达式
1.什么是lambda表达式 lambda 是 Python 中的一个关键字,用于定义简单的匿名函数。与 def 关键字定义的标准函数不同,lambda 函数主要用于需要一个函数对象作为参数的简短操作。lambda 函数的设计哲学是简洁,因此它只能包含一条表达式&#…...

2024年数据、自动化与智能计算国际学术会议(ICDAIC 2024)
全称:2024年数据、自动化与智能计算国际学术会议(ICDAIC 2024) 会议网址:http://www.icdaic.com 会议地点: 厦门 投稿邮箱:icdaicsub-conf.com投稿标题:ArticleTEL。投稿时请在邮件正文备注:学生投稿&#…...
cuda 学习笔记4
一 基本函数 在GPU上开辟空间,无论定义的数据是float还是int ,还是****gpu_int,分配空间的函数都是下面固定的形式 (void**)& 1.函数定义,global void 是配套使用的,是在GPU上定义,也就是GPU上执行,CPU上调用的函数…...
ZSWatch 开源项目介绍
前言 因为时不时逛 GitHub 会发现一些比较不错的开源项目,突发奇想想做一个专题,专门记录开源项目,内容不限于组件、框架以及 DIY 作品,希望能坚持下去,与此同时,也会选取其中的开源项目做专题分析。希望这…...

LangForce方法:强化VLA模型语言依赖,提升分布外泛化能力并保留语言核心功能
LangForce方法:强化VLA模型语言依赖,提升分布外泛化能力并保留语言核心功能当前VLA模型常依赖视觉线索而非语言指令,在新场景下表现不佳。论文提出的LangForce方法,通过引入对数似然比损失,强化模型对语言的依赖&#…...

ArcGIS Pro新手教程:用‘创建常量栅格’和‘镶嵌’工具,5步精准提取中国区域气温NC数据
ArcGIS Pro精准提取中国区域气温数据的5步进阶指南 当全球气象数据遇上区域研究需求,如何高效提取目标范围信息成为地理信息科学领域的常见挑战。以中国陆地区域气温分析为例,传统方法往往面临数据冗余、边界锯齿和格式转换三大痛点。本文将揭示一套基于…...

智能手机如何重塑芯片市场:从基带到SoC的平台化竞争
1. 市场格局的剧变:一部智能手机如何重塑芯片江湖如果你在2007年问一个半导体行业的从业者,手机核心芯片市场的格局会怎样,他大概率会给你描绘一个由德州仪器、飞思卡尔、英飞凌等传统巨头主导的图景。然而,仅仅五年后,…...
)
从零到一:51单片机蓝牙遥控车实战指南(附避坑要点)
1. 项目背景与准备 作为一个非硬件专业的爱好者,我第一次接触51单片机时完全是一头雾水。记得当时因为特殊原因在家闲着,突发奇想做个蓝牙遥控车玩玩。没想到这个简单的想法,让我踩遍了新手能遇到的所有坑。现在回头看,其实用51单…...

2026届学术党必备的AI写作网站实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 作为学术研究启动时核心的前置材料的开题报告,要完成文献梳理,要搭建…...

MediaCreationTool.bat:解决Windows安装媒体创建痛点的灵活工具
MediaCreationTool.bat:解决Windows安装媒体创建痛点的灵活工具 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat …...

带拉杆雨篷的拉杆和耳板的设置原则
带拉杆雨篷的拉杆和耳板的设置原则 同纯悬挑雨篷一样,带拉杆雨篷也常常被设计为静定体系,传力路径中某一环节发生问题,即可导致整体结构体系的破坏,结构容错能力较差。无法形成超静定结构体系所有的多道设防机制,对于设计或者施工缺陷过于敏感,这是带拉杆雨篷事故发生的…...

SimCSE中文实战避坑指南:从数据准备、模型训练到效果评估的完整流程
SimCSE中文实战避坑指南:从数据准备到效果评估的全流程解析 在自然语言处理领域,语义相似度计算一直是核心挑战之一。SimCSE作为一种简单却高效的对比学习方法,近年来在中文场景下展现出惊人的潜力。但当你真正尝试将其应用于自己的中文项目时…...

如何用wxlivespy实现微信视频号直播数据实时抓取与分析
如何用wxlivespy实现微信视频号直播数据实时抓取与分析 【免费下载链接】wxlivespy 微信视频号直播间弹幕信息抓取工具 项目地址: https://gitcode.com/gh_mirrors/wx/wxlivespy wxlivespy是一款专业级的微信视频号直播间弹幕信息抓取工具,能够实时捕获弹幕、…...

AzurLaneAutoScript:基于图像识别与智能调度的碧蓝航线全自动脚本架构解析
AzurLaneAutoScript:基于图像识别与智能调度的碧蓝航线全自动脚本架构解析 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoSc…...