【论文阅读】Answering Label-Constrained Reachability Queries via Reduction Techniques
Cai Y, Zheng W. Answering Label-Constrained Reachability Queries via Reduction Techniques[C]//International Conference on Database Systems for Advanced Applications. Cham: Springer Nature Switzerland, 2023: 114-131.
Abstract
许多真实世界的图都包含边缘标签,用于表示节点之间不同类型的关系,例如社交网络、生物网络和知识图谱。作为一项基本任务,标签约束可达性 (LCR) 查询询问给定顶点 s 是否可以到达另一个顶点 t,仅使用一组受限制的给定边标签。然而,现有工作构建了大量索引,同时花费了太多时间在线回答查询,在大型图上表现出较差的性能。为了进一步减小索引大小并加速索引构建和查询处理,我们引入了两种新颖的剪枝技术,包括 degree-one reduction 和 unreachable query filter。大量的实验表明,我们提出的技术大大促进了最先进的方法。
1 Introduction
为了模拟节点之间不同类型的关系,通常对许多现实世界图中的边进行标记,例如社交网络、生物网络和知识图谱[3,8,9,14,24]。例如,社交网络可能包含多个边缘标签,例如“follow”、“friendOf”和“relativeOf”。作为图挖掘最基础的任务之一,传统的可达性查询询问一个顶点是否可以到达另一个顶点[12,15,19,22]。然而,在许多实际场景中,用户可能只关心某些边类型下的可达性,即询问一个顶点 s 是否可以仅使用边缘标签 L 的子集到达另一个顶点 t。这种查询称为标签约束可达性 (LCR) [3],用 s→ t 表示。以图 1 中的图形 G 为例,给定查询 0 → 12,其中 L = {a, c},答案是 Y es,因为存在 s-t 路径0→ 1 → 2 → 12.但是当 L = {a, b} 时,查询 0 → 12 的答案是 N o。

LCR查询具有广泛的应用,例如社交网络上的反恐,生物网络上的蛋白质相互作用链检查,知识图谱上的常规路径查询等[3,9,14,24]。但是,为 LCR 查询构建有效的索引比传统的可访问性查询要复杂得多,因为查询的标签约束有 2 种可能的组合,其中 |L|是图形中边标签的数量。在现有的方法[3,8,9,14,24]中,修剪2跳指数(P2H)[8,9]是最先进的方法,它编码了所有边缘标签组合下所有顶点对之间的精确传递闭包。具体来说,对于每个顶点 v,P2H 使用相应的标签集将可以到达 v 或可以通过 v 到达的跳跃节点 u 具体化。对于查询 s → t,它返回 Yes如果存在一个跃点节点 u s.t. s 可以到达,你可以在标签约束 L 下到达 t。
尽管 P2H 明显优于之前的所有方法,但在本文中,我们发现在其在线查询和离线索引阶段都浪费了不必要的成本。基于我们的发现,提出了以下两种约简技术,以进一步提高处理LCR查询的时间效率。综上所述,本文提出以下贡献。
一级减少。许多真实世界的图是遵循幂律度分布的无标度网络[7],并且可能有很多顶点的度数为1。在 P2Hindex 中,我们注意到,如果顶点 v 具有 in-degree(out-degree)1,则其所有传入(传出)跳跃节点和标签集都可以从其唯一的父节点(子节点)推断出来。应该删除这些冗余条目以减小索引大小(例如,表 1),并且我们进一步设计了新的索引算法来直接生成减少的索引,而不是删除构建的 P2Hindex 中的条目。虽然它看起来很直观,但魔鬼正在讨论所有可能的情况,以使这样的索引听起来、完整且最小。
无法访问的查询筛选器。如果顶点 s 即使没有任何标签约束也无法到达 t,则 s −−→ t 的答案肯定是 N o。但是,P2H 需要在返回 N o 之前迭代 s 和 t 的所有索引条目,这可以通过引入另一个轻量级索引来加速,以在 O(1) 时间内排除大多数此类查询。它包含来自猫科动物指数[15]的三个坐标,以及两个旨在增强修剪能力的新坐标。
大量实验表明,配备上述简化技术,回答在线查询的速度比 P2H 快得多。此外,由于一级减少,索引时间和索引大小都可以大大减少。
2 Problem Definition and Preliminary
我们首先定义了标签约束可达性(LCR)问题,然后介绍了最先进的修剪2跳方法(P2H+)[8,9]。
2.1 Problem Definition
设G(V,E,L)表示一个有向边标记图,其中V为顶点集,L为标签集,E⊆V×V×L为边集。设e(u,v,l)∈E表示从顶点u到v的一条有向边标签l。顶点、边和标签的数量分别记为|V |、|E|和|L|。我们表示一个函数λ: E−→L映射一条边到它的标签,即λ(e(u,v,l))= l。对于任何转换ex v∈V,我们将其在特定标签l下的内邻集表示为Nin(v,l)= {u | e(u,v,l)∈|}。类似地,标签l下的v的外邻集用Nout(v,l)= {u | e(v,u,l)∈E}表示。顶点v的内度用din(v)=l∈L|Nin(v,l)|表示,而其出度dout(v)=l∈L|Nout(v,l)|表示。
给定源顶点s和目标顶点t,一个s-t路径p(s,t)= {s = v0,e0,v1,e1,···,vk−1,ek−1,vk=t}表示一个有向序列(k > 0),其中vi∈v和ei∈e为每个i。给定一个l⊆集合L⊆L,我们说p(s,t)是一个L约束的s-t路径,当且仅当∀∈p(s,t),λ(ei)∈L。
定义 1(标签约束的可达性查询,简称 LCR [14])。对于有向边标记图 G(V, E, L),给定查询 s → t,其中 s 和 t 是 G 中的两个不同顶点,标签集 L ⊆ L,任务是确定 G 中是否存在 L 约束的 s-t 路径。
LCR 查询询问顶点 s 是否只能使用 L 中的标签到达 t。为了便于表示,我们使用 s → t 表示 s 只能使用 L 中的标签到达 t,而 s → t 表示 s 不能仅使用 L 中的标签到达 t。
2.2 Pruned 2-Hop Index
2-hop cover 框架已广泛用于处理图查询,如距离查询 [1,6]、可达性查询 [2,19] 和路由规划 [16,17]。最近,剪枝的 2 跳方法 (P2H) [8,9] 首先将其应用于应答 LCR 查询,其中每个顶点 v ∈ V 都有一个入口集 I[v] = {〈u, L〉 | u −→ v} 和一个输出入口集 I[v] = {〈u, L〉 | v −→ u}。直观地说,如果存在跳节点 u s.t. s −→ 和 −→ t,则为 s −−→ t 为 Y es。因此,∃如果 〈u, L〉 ∈ I[s], 〈u, L〉 ∈ I[t] s.t. L⊆ L ∧ L⊆ L,则算法 1 返回 Y es。
P2H将G中的所有顶点视为跳节点,并从每个跳节点u进行前向和后向BFS。在前向 BFS 期间,它维护一个搜索队列 Q,其中每个元素 (v, L) 代表一个顶点 v,并附有一个标签集 L。它总是从具有最小标签集 L 的 Q 中取消元素 (v, L) 的队列,然后将索引条目 〈u, L〉 插入到 I[v] 中,如果查询 u −→− v 不能被现有索引回答。否则,它将跳过探索顶点 v,因为从 u 到 v 的可达性信息已经编入索引。跳过规则包括 (1) 检查 v 之前是否被处理过,以及 (2) 通过算法 1 查询 u −−→ v。同样,它进行反向 BFS 以索引 I。
例 1.假设图G(图1)中的顶点按顶点度数降序处理,即4、1、2、10、13、·接下来,我们假设第一个顶点 4 已经处理完毕,并展示如何处理以下顶点 1。通过迭代 1 的邻域,I[0] = I[9] = {〈1, b〉} 和 I[2] = {〈1, a〉}。请注意,我们
跳过 (4, a) 的探索,因为 1 −→ 4 可以由现有索引 〈4, a〉 ∈ I[1] 回答。此外,由于 〈4, a〉 ∈ I[1] 和 〈4, a〉 ∈ I[10] 表示 1 在标签集 {a} 下可以通过 4 达到 10,因此跳过了对 (10, a) 的探索。通过继续BFS,I[3] = {〈1, a〉}, I[12] = {〈1, ac〉}, I[13] = I[14] = {〈1, ab〉〈1, ac〉}。同样,从顶点 1 向后执行 BFS 后,I[0] = {〈1, c〉}。构建的P2Hindex如表1(a)所示。


3 Degree-One Reduction
当一个顶点 v 只有一个内邻或外邻 u 时,可以很容易地从 u 中推断出 v 的可达性信息。此类属性有助于减少索引构造和联机查询的工作量。

索引构建。如果顶点 v 只有一个内邻(或外邻)u,则其内条目 I[v](out-entrytries I[v])可以从 2hop 索引中的 I[u] (I[u]) 推断出来。我们将此类内条目 I[v](out-entrytries I[v])称为冗余条目(在定义 2 中正式定义)。给定构建的 P2Hindex(例如,表 1(a)),可以删除所有冗余条目以减小索引大小(例如,表 1(b))。例如,表1(a)中的I[14]可以删除,因为顶点14只有一个相邻点13。第 3.2 节证明简化的索引是合理的、完整的和最小的。此外,我们提出了一种新的索引算法,该算法直接生成减少的索引,在索引构建过程中不保留任何冗余条目,而不是删除构建的P2H索引上的冗余条目。
在线查询。直观地说,查询过程(算法 1)变得更快,因为缩减索引中的条目更少。此外,如果唯一的内边(外边)的标签不满足标签约束,则可以提前停止。拿
查询 0 → 14 为例,由于顶点 14 的唯一内边有标签 A /∈ {bc},我们可以直接返回 N o,而无需检查索引条目。
在本节中,我们首先正式定义冗余条目和简化的 2 跳索引,然后引入利用简化索引的新查询函数,然后通过理论分析引入新的索引算法。
定义 2(冗余条目)。给定一个 2 跳索引,对于任何顶点 v s.t. din(v) = 1,其所有条目 I[v] 都是冗余条目。对于任何顶点 v s.t.dout(v) = 1,它的所有输出条目 I[v] 也是冗余条目。
定义 3(减少的 2 跳索引)。删除 P2H 索引中的所有冗余条目会导致 2 跳索引减少。
3.1 Online Querying
如图2(a)所示,对于查询s0?L−−→t0,如果s0只有一个标签l1∈L的外边缘,直观地我们可以移动到它唯一的后继者s1。如果s1也只有一个外邻居,我们保留mo当l2∈l时,这样的运动持续到s2,s3,···,直到有一个顶点sm s.t。dout (v) = 1,或dout (v) = 1,但其唯一的外边缘的标签不在L. Bas中基于上述直觉,新的查询函数见算法2。第1-6行迭代地跟踪源顶点s的唯一子节点。如图2(b)所示,当遇到目标顶点时t,它直接在第5行中返回Y es,因为我们已经找到了一个有效的l约束路径。请注意,我们可能会陷入一个循环时移动到已访问的顶点sk,如图2©.所示因此,我们在第1行中介绍所访问的集合。如果顶点s已被访问或唯一的外边e不满足标签约束,则为d立即返回第4行中的No。类似地,第7-12行跟踪目标顶点t的唯一父对象。最后,第13行通过使用算法1查询简化的2跳索引来返回结果。


定理1。算法2只使用简化的2跳索引给出了正确的答案。证明。如上所述,证明第4、5、10或11行中返回的答案是正确的是微不足道的。当第13行被调用,dout (s) = 1和din (t) = 1。因此,P2H+索引中的冗余项将永远不会在算法2中使用,这在减少的2跳索引中被删除。因为所有的查询都可以是正确的通过P2H+索引[8,9]的回答,算法2总是返回正确的答案。
时间和空间复杂性。算法1花费了O((|Iout[s]| + |Iin[t]|)|L|)时间和O (1)空间[9]。对于算法2,假设我们完全访问了第3行(第9行)中的δs(δt)顶点,这是一个很大的sm在实践中比|V |更重要。因此,算法2花费了O((δs+++|Iout[s]|+|Iin[t]|)|L|)时间和O(δs + δt)空间。
3.2 Index Construction
根据定义3,我们可以首先构建P2H+索引,然后删除所有冗余条目,得到一个简化的2跳索引。由于花费了不必要的时间和空间,我们提出了一种新的索引算法直接生成简化的2跳索引,而不维护任何冗余的条目。算法3从每个跳节点u∈V同时进行正向和反向BFS。接下来,我们将重点关注向前的BFS (Algorithm 4),并省略了向后的BFS,因为它们以类似的方式工作。
在当前处理跳节点u的正向BFS过程中,当din (v) = 1时,直观的冗余项不应该插入到Iin[v]中,如算法4的第5行所示。假设我们正在探索中标签集L下的G顶点v,即索引uL−→v的可达性信息。如果它已经索引了uL−→v在L⊆L中,这样的探索应该被跳过。但是,由于缺少冗余的条目,P2H+的跳过规则无法正常工作,即一些不必要的探索没有成功完全跳过。因此,我们为减少的2跳索引精心设计了以下跳过规则。
规则1。如果顶点v是当前处理或处理的跳节点,我们跳过它,因为uL−→v已经被跳节点v索引。我们使用标记集来实现它。
规则2。如果v已经在标签集L⊆L下从u中探索过,则应该跳过顶点v。考虑以下情况。
案例1。当din(v)=1(图3(a)),如果∃进入u,L∈在[v]s.t。L⊆L,我们跳过探索v,如算法4的第13行所示。
案例2。当din(v)=1(图3(b))时,v不能在任何标签集L⊆L下从u中探索,即,我们不能跳过在标签集L下的探索v。当迭代跟踪v的唯一父项时,(1)如果你被满足了,这是你第一次从你访问v,因为从你到v只有一条路径。(2)如果你不被满足,就在那里必须是v.t的前身。din(v)=1,没有进入u,L∈Iin[v]满意访问v。L⊆L,否则我们在案例1中跳过了v,所以不可能到v。
规则3。顶点v应该被跳过,如果u?L→v可以由任何处理过的跳节点w来回答。考虑以下情况。
案例1。当dout (u) = 1∧din(v)=1(图3©)时,由于Iout[u]和Iin[v]被保留,我们跳过探索v,如果现有的2跳索引返回Y es作为查询u?在算法4的第18行中的L−−→v。
案例2。当dout (u)=1∧din(v)=1(图3(d))时,算法1总是返回No,因为Iout[u] =∅。然而,uL−→v可能已经被Iout[u]中的处理跳节点w索引,其中u是一个唯一的]你的山丘。因此,我们需要迭代地跟踪u的唯一子项,在此期间(1)如果v满足,我们不能跳过探索v(算法4的第17行),因为w在从u到的唯一路径上不满足v,否则我们就根据规则1跳过了它。(2)如果我们不见你,一定有的继任者。dout(u)=1,如果算法1返回?查询u?,我们跳过探索vL−−→ v in.算法4的第18行。
案例3。当din(v)=1(fig3(e)-(f)),uL−→v没有被索引,我们不能跳过标签集l下的探索v。具体地说,当迭代跟踪v的唯一父项时,(1)如果u是met,w不在从u到v的唯一路径上,否则我们跳过了规则1对w的探索,不可能访问v. (2),如果我们不遇到u,一定有v s.t的前身v。din (v)=1,现有索引不会返回Y es查询u?L→v,否则我们在案例1或案例2中跳过了探索v,也不可能访问v。
例子2。假设我们按照与示例1相同的顺序来处理所有的顶点。在处理了第一个跳点节点4后,已经存储了与它相关的索引条目,除了表1中的冗余条目(b).在跳节点1的前向BFS过程中,我们探索它所有的外邻,但通过规则1跳过顶点4,之后我们只将1,一个插入到Iin[2]中,因为其他邻居只有一个内边。下一个的我们访问顶点3而没有插入入口,之后我们再次访问顶点2,但是跳过探索,因为1,a∈Iin[2]根据规则2。我们也通过规则3跳过顶点10,因为1 {a}−−→10已经被4,a∈Iout[1]和4,a∈Iin[10]索引。
定理2。算法3构建了一个健全、完整和最小的2跳索引。证明。坚固性。每个条目都是通过在正向或后向BFS中找到一个l约束路径来添加的。因此,它永远不会生产假阳性答案。
完整性。在每个顶点u的前向和向后BFS中,如果当前可达性被索引,我们只跳过探索。因此,它涵盖了所有标签约束的可达性,没有假阴性可以产生否定性的答案。
最小性。假设算法3按顺序处理顶点u1、u2、···、u|V |。由于对称性,我们重点讨论入项,而省略出项。删除任何条目ui,L∈Iin[uj]会导致对ui的假否定答案?L−−→ uj .具体来说,在索引构建中从ui开始的前向BFS过程中,我们不跳过uj,因为ui L−→uj没有被处理过的跳节点u1覆盖,u2, ··· , ui−1.而修改后的BFS顺序[9]确保没有进入ui,L∈Iin[uj ] s.t。L⊂−→.此外,uiLuj不能被其他跳节点ui+1,ui+2,···,u|V |,因为我们跳过在BFS期间探索ui。
时间复杂性。算法4最多以O(2|L|)次访问每条边。在函数SkipOrNot中,假设第16行访问δ顶点,比|V |小得多。因为算法1取O ((|Iout[s]|+|Iin[t]|)|L|)=O(||2|L|)时间[9],索引构建需要O(||2|||22|L|)最糟糕的时间。
空间复杂性。对于每个顶点v,在Iin[v](Iout[v])中最多有(|V |−1)·2个|L|条目。因此,它在最坏的时候消耗了O(|V | 2·2|L|)空间。
4 Unreachable Query Filter
一个LCR查询的答案是什么?如果顶点s即使没有任何标签约束也不能到达t,则L−−→t绝对为否。在本节中,我们提出另一个名为不可达的轻量级查询索引排除这种无法访问的查询。具体来说,通过丢弃所有的边标签,我们可以将图G中的所有强连通分量压缩,得到一个DAG GA。取图1中的图G例如,图中。4(a)-(b)为转换后的DAG GA提供了一个映射MID,用于将G中的顶点ID映射到GA中的id。接下来,我们将重点关注可达性查询ˆs?GA中的−→tˆ,其中ˆs=MID[s]和tˆ= MID[t]
4.1 FELINE Index
拓扑顺序。在DAG GA中,分别将Xs和Xt表示为顶点s和t的拓扑顺序。如果Xs > Xt,那么我们直接返回No,因为s不能到达t。基于第一个拓扑结构阶X,[15]通过启发式决策进一步生成另一个拓扑阶Y。让Roots(简称R)是一个优先级队列,存储所有没有内边的顶点。具体来说,FELINE的迭代地运行以下3步,直到R为空。
-步骤1。从R中选择Xv值最大的顶点v来分配Yv。
–步骤2。删除v的所有外边,那么它的子节点w可能没有内边。
–步骤3。将每个没有边的w添加到R重复步骤1。
液位过滤器。每个顶点v也有一个级别索引级别。如果顶点v在GA中没有内边,其水平为=0。否则,level={level}+1,其中u是v的父。同样,我们直接当levels≥levelt时返回否。
例子3。DAG GA的FELINE指数如图4(a).所示

4.2 False-Positive Reduction
给定一个查询s?−→t,如果Xs < Xt∧Ys < Yt∧levels<levelt,但实际上s不能在GA中达到t,猫指数产生一个假阳性答案。例如,顶点3在GA中不能达到10(图4(a)),但它没有返回No,因为X3 < X10∧Y3 < Y10∧level3<level10。请注意,所有导致这种假阳性答案的关键顶点都可以被发现为[12],我们称它们为假阳性所有的贡献者(简称FPC)。为了减少FELINE索引中的假阳性答案,我们基于FPC生成了另外两个坐标Hα和Hβ。
寻找假阳性的贡献者(FPC)。在得到FELINE指数的第一拓扑阶X后,在生成坐标Y [12]时可以找到FPC。具体来说,顶点v被处理已分配Y坐标,否则v未处理。回想一下,优先级队列R包含了在GA中没有内边的所有顶点。我们还可以维护一个称为候选自由节点的顶点集es(简称CFN),包含所有未处理的顶点v s.t。v∈R和至少一个v的父级已经被处理。当从R弹出顶点u时,另一个顶点v∈FPC ivfv∈CFN∧Xw < Xu,当顶点w在所有未处理的v [12]的父节点中Xw值最大。
例子4。对于图4(a)中的GA,我们首先从R弹出顶点0,然后,我们从R弹出顶点6,∃顶点7∈CFN.t。X2 < X6,表示顶点7∈FPC。类似地,当弹出顶点2时,∃反转ex 10 ∈ CFN s.t.X9 < X2和顶点10∈FPC也是如此。最后,FPC = {7,10}。请注意,猫科动物索引中的所有假阳性查询都可以归因于FPC [12]中的至少一个顶点。第一个错误的位置inie贡献者7使它不能为查询6返回否?→7和6?→8,而顶点10对查询2的假阳性答案贡献?→ 10, 2 ?→ 11, 3 ?→ 10, 3 ?→ 11, 4 ?→ 10, 4 ?→ 11, 5 ?→10,和5?→ 11。
给定计算出的FPC,我们可以生成新的坐标来为那些假阳性的查询对返回No。这些幼稚的想法呈现如下。
新坐标的天真想法。直观地说,对于每个假阳性的贡献者vi∈FPC,我们可以为GA中的顶点添加一个新的坐标H (i)。具体来说,H (i)六=水平,H (i) u =水平第六世的前任和后代。对于其他的顶点w,我们有H (i) w =水平+ max{H (i) u }。给定一个查询s?−→t,如果∃和H (i)坐标s.t,我们可以返回−→。H (i) s ≥ H (i) t .
例子5。对于图4(a)中的GA,根据示例4,FPC={7,10}。图4©显示了第一个新的坐标H (1),以避免由顶点7引起的假阳性答案。对于查询6吗?−→7和6 ?−→8具有来自猫科动物指数的假阳性答案,新的坐标H (1)有助于返回No,因为H6 (1) > H7 (1)和H6 (1) > H8 (1)。图4(d)显示了为sec构建的新坐标H (2)假阳性贡献者是为了避免猫犯的其他错误。
虽然FELINE指数产生的所有假阳性答案都可以避免,但FPC的大小可能很大,而且在网上检查所有新的坐标都是昂贵的。接下来,我们建议只生成两个new坐标Hα和Hβ基于FPC,s.t。如果Hs α≥Ht α或Hs β≥Ht β,我们可以安全地为查询s返回否?−→t,避免尽可能多的假阳性答案。
新的坐标生成。为了生成第一个坐标Hα,我们按levelv的升序处理每个vi∈FPC,而在生成Hβ时按降序处理它们。自以来Hα和Hβ的离子只在过程顺序上有所不同,接下来我们将关注生成Hα。
定义4。(v的附属节点,简称ANv)。当处理v∈FPC时,u∈ANv iff: (1) Hu α没有被分配,(2) u和v被连接,忽略了边缘方向,并且(3) u不能被被任何未经处理的w∈FPC处理。
以图5(a)中的DAG Gτ为例,其中FPC = {v1、v2、v3、v4}和Ci表示带有内边的顶点子集。从vi到Cj(从Cj到vi)的每条定向虚线都意味着vi可以到达Cj中的顶点(可以到达)。为了生成Hα坐标,我们按顺序处理v1、v2、v3和v4。请考虑以下步骤,如图5(b).所示

-步骤1。我们处理第一个假阳性贡献者v1,并让Hu α =水平到∪ANv1中的所有顶点,其中ANv1 = C1。注意,虽然v1可以达到C3,C3⊂ANv1自非进程sed v2∈FPC也可以达到C3。
–步骤2。当处理v2时,Hu α =水平+Ω在{v2}∪ANv2中的顶点,其中ANv2 = C2∪C3。注意,Ω是一个偏移量,确保所有Hα值分配了current步骤大于前面步骤中分配的任何Hα。
–步骤3-5。每一步都如图5(b).所示
在生成Hα之前,对于DAG中的每个顶点u,我们预先计算了一个集合Γu = {w∈FPC | w可以到达u而不通过任何w∈FPC}。在处理v∈FPC时,为ANv中的顶点分配Hα值,我们ev的复孔和访问满足Hα的顶点没有被分配,(2)Γu{v}中的所有顶点都已经被处理。例如,对于Gτ中的每个u∈C3,Γu={v1,v2}。
时间复杂性。生成猫指数成本O(|V | log |V |+|E|)。计算每个顶点u的Γu的代价是O(γ|E|),其中γ是Γu的最大大小,在实际应用中比|V |要小得多。热纳拉使用Hα和Hβ成本O(|V |+|E|)。因此,构建不可达查询过滤器的成本为O(|V | log |V | + γ|E|)。
空间复杂性。在不可达查询过滤器中,每个顶点u有5个坐标(Xu,Yu,levelu,Hu α,Hu β),它完全需要O(|V |)空间。
5 Experiments
5.1 Experimental Setup
数据集。如表2所示,我们使用了来自不同域[4,5,10,21]的14个真实图。对于那些没有边缘标签的作品,我们生成合成标签的方法与之前的作品[8,9,14],相同以λ = |L|/1.7呈指数分布。对于每个数据集,我们有三个查询集,使用不同数量的查询标签|L|,其中|L| = {|L|/4,|L|/2,|L|−2} for |L|≤8,而|L| = {2、4、6}对于较大的|、L、|。每个查询集包含1000个随机生成的查询。
实施。所有算法在索引构建过程中都使用度降序处理跳节点。根据P2H+方法,对于具有|L| > 12的图形,选择了6个最常见的标签作为主标签,而其他标签则平均分为6个虚拟标签进行构建索引。我们在Linux服务器上进行实验,使用Intel®E5-2596v4-25uzCPU,2.2GHz和128G RAM。项目在C++中实现,并使用-O3优化进行编译。
5.2 Online Query
在线查询的效率对于LCR查询至关重要,不同大小的查询标签集也会影响性能。表3报告了通过使用所有查询进行的1000个查询的总查询时间我们的简化技术,包括降级减少和不可访问的查询过滤器。通过改变不同的查询标签大小|L|,简化技术始终提高所有的查询效率数据集,与最先进的方法P2H+进行了比较。得益于减少的搜索空间,当|L| = 6时,它在图ArXiv、引用和Flixeser上运行速度甚至快了3倍,这表明对于具有大尺寸标签集的查询,改进变得更加重要。

5.3 Index Construction
我们还在表4中报告了索引性能(包括索引时间和索引大小),并将所提出的简化技术与P2H+方法进行了比较。如第3节中,一级还原率索引大小,通过删除所有冗余的条目。因为在本节中是不可访问的查询过滤器。4建立一个轻量级指数,总体指数大小和时间可能略大于P2H+指数图,这仍然是可以接受的,因为它提高了查询效率。

5.4 Effects of Degree-One Reduction
为了弄清楚单一约简技术如何同时影响索引和查询性能,在本节中,我们只采用一度约简(简称DOR)来执行缩减。如表5所示,它如预期的那样,在所有数据集上实现更小的索引大小。通过使用1度减少,构建减少的2跳索引需要更少的索引时间,因为我们需要查询现有的2跳索引在指数构建过程中确保最小性,这也能更快地受益于较小的指数规模。

5.5 Effects of Unreachable Query Filter
我们还研究了所提出的不可达的查询过滤器(简称UQF)的影响。表6显示了仅使用UQF时的总体性能。在索引时间和指数大小方面,我们发现与P2H+方法相比,其附加成本边际较小。它可以大大减少大多数数据集的在线查询时间,因为它只花费O (1)个时间来回答大多数不可到达的查询,而P2H+需要迭代查询顶点的所有索引条目。请注意,对于少数数据集上的某些查询标签大小,即使迭代所有数据集,对于速度足以返回No的情况,也可能没有回报2跳索引条目。
6 Related Work
6.1 Reachability Queries
现有的回答可达性查询的工作可以分为两类,即仅使用索引搜索和索引搜索。仅索引方法(例如,[12,19,23])压缩完全传递闭包of输入图G,只检查在线查询顶点对的索引,没有图遍历。索引搜索方法(例如,[11,13,15,18,20])构造的索引比仅使用索引的方法要小得多但由于在线搜索,他在回答查询时花费了更多的时间。由于在图G中压缩所有强连接组件(SCCs)会导致一个保留可达性信息的DAG,因此需要过境DAG [22]的简化和等价缩减可以进一步加速查询处理。
6.2 Label-Constrained Reachability Queries
Jin等人[3]引入了LCR查询,并提出了一个基于树的索引,由生成树和部分传递闭包组成。Zou等人通过将输入图G分解为SCCs,[24]构建当G包含较大的SCCs时,不能有效工作的完整索引。LI+ index [14]包含基于地标和非地标的索引,用于回答LCR查询,它不能扩展到大型gr由于较大的索引大小。解决LCR问题的最先进的方法是P2H+,它构建了一个2跳的覆盖物,以保存所有受标签约束的可达性信息。然而,如程序所示在索引构建和查询处理过程中,仍然存在不必要的时间和空间成本。
7 Conclusion
在本文中,我们研究了回答标签约束可达性查询的问题,并引入了新的约简技术来提高索引构造和在线查询效率。需要度一个减少直接建立了一个简化的2跳索引,删除了顶点的冗余索引项,这被证明是健全的、完整的和最小的。不可达的查询过滤器利用五个坐标来避免为不可访问的查询迭代所有条目。大量的实验证实,我们提出的减少策略取得了显著的更好的性能比较d与最先进的方法。
相关文章:
【论文阅读】Answering Label-Constrained Reachability Queries via Reduction Techniques
Cai Y, Zheng W. Answering Label-Constrained Reachability Queries via Reduction Techniques[C]//International Conference on Database Systems for Advanced Applications. Cham: Springer Nature Switzerland, 2023: 114-131. Abstract 许多真实世界的图都包含边缘标签…...

Git Flow 工作流学习要点
Git Flow 工作流学习要点 Git Flow — 流程图Git Flow — 操作指令优点:缺点:Git Flow 分支类型Git Flow 工作流程简述关于 feature 分支关于 Release 分支关于 hotfix 分支 总结 Git Flow — 流程图 图片来源:https://nvie.com/posts/a-succ…...

blender 快捷键 常见问题
一、快捷键 平移视图:Shift 鼠标中键旋转视图:鼠标中键缩放视图:鼠标滚动框选放大模型:Shift B线框预览和材质预览切换:Shift Z 二、常见问题 问题:导入模型成功,但是场景中看不到。 解…...

HTTP详解:TCP三次握手和四次挥手
一、TCP协议概述 TCP协议是互联网协议栈中传输层的核心协议之一,它提供了一种可靠的数据传输方式,确保数据包按顺序到达,并且没有丢失或重复。TCP的主要特点包括: 面向连接:TCP在传输数据之前需要建立连接。可靠传输&…...

详解HTTP:有了HTTP,为何需要WebSocket?
在日常生活中,HTTP 常用于请求数据。例如,当你打开一个天气预报网站时,浏览器会发送一个 HTTP 请求到服务器,请求当前的天气数据,服务器返回响应,浏览器解析并显示这些数据。 但是,当涉及到需要…...

Spring Boot 启动流程是怎么样的
引言 SpringBoot是一个广泛使用的Java框架,旨在简化基于Spring框架的应用程序的开发过程。在这篇文章中,我们将深入探讨SpringBoot应用程序的启动流程,了解其背后的机制。 Spring Boot 启动概览 SpringBoot应用程序的启动通常从一个包含 m…...
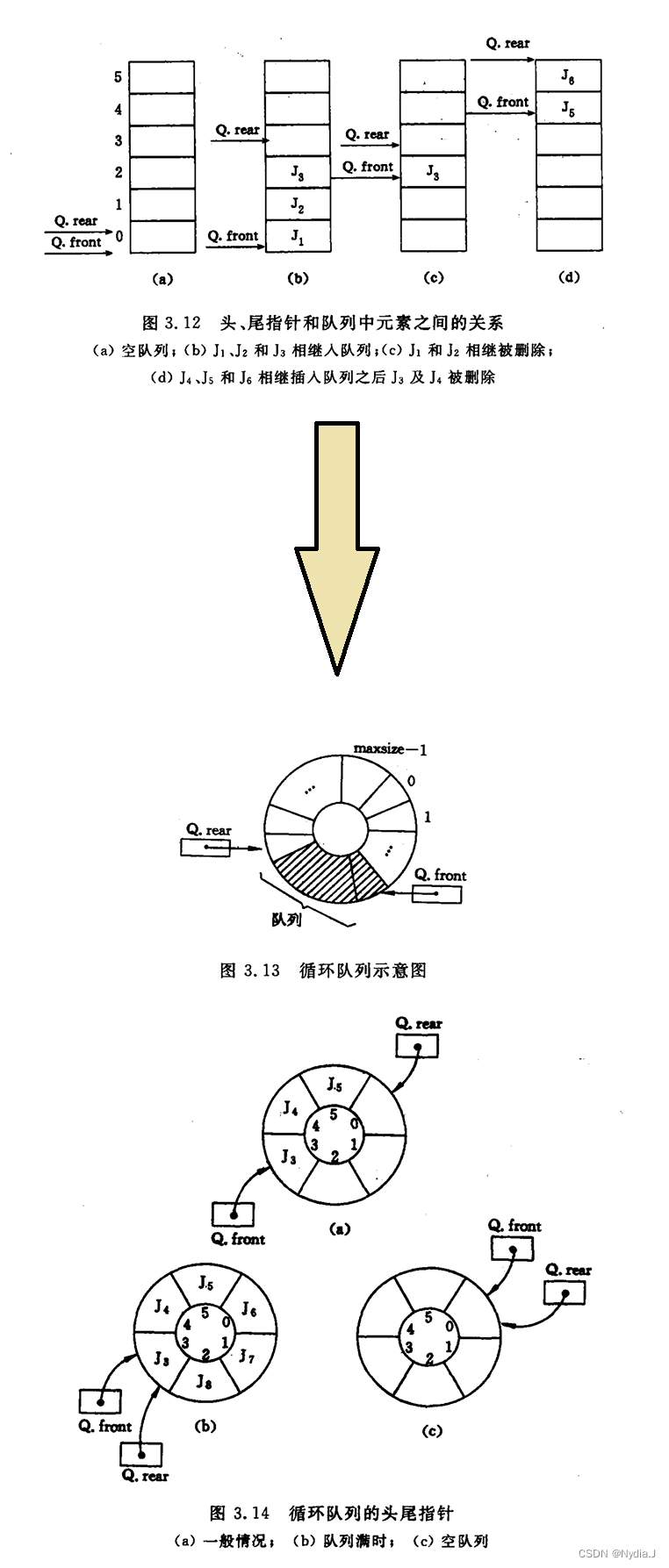
【学习笔记】数据结构(三)
栈和队列 文章目录 栈和队列3.1 栈 - Stack3.1.1 抽象数据类型栈的定义3.1.2 栈的表示和实现 3.2 栈的应用举例3.2.1 数制转换3.2.2 括号匹配的检验3.2.3 迷宫求解3.2.4 表达式求值 - 波兰、逆波兰3.2.5 反转一个字符串或者反转一个链表 3.3 栈与递归的实现3.4 队列 - Queue3.4…...

学习python笔记:10,requests,enumerate,numpy.array
requests库,用于发送 HTTP 请求的 Python 库。 requests 是一个用于发送 HTTP 请求的 Python 库。它使得发送 HTTP 请求变得简单且人性化。以下是一些基本的 requests 函数及其用途: requests.get(url, **kwargs) 发送一个 GET 请求到指定的 URL。 i…...

经典神经网络(13)GPT-1、GPT-2原理及nanoGPT源码分析(GPT-2)
经典神经网络(13)GPT-1、GPT-2原理及nanoGPT源码分析(GPT-2) 2022 年 11 月,ChatGPT 成功面世,成为历史上用户增长最快的消费者应用。与 Google、FaceBook等公司不同,OpenAI 从初代模型 GPT-1 开始,始终贯彻只有解码器࿰…...

MySQL库与表的操作
目录 一、登录并进入数据库 1、登录 2、USE 命令 检查当前数据库 二、库的操作 1、创建数据库语法 2、举例演示 3、退出 三、字符集和校对规则 1、字符集(Character Set) 2、校对集(Collation) 总结 3、操作命令 …...

TTS 语音合成技术学习
TTS 语音合成技术 TTS(Text-to-Speech,文字转语音)技术是一种能够将文字内容转换为自然语音的技术。通过 TTS,机器可以“说话”,这大大增强了人与机器之间的互动能力。无论是在语音助手、导航系统还是电子书朗读器中&…...

小公司做自动化的困境
1. 人员数量不够 非常常见的场景, 开发没几个, 凭什么测试要那么多, 假设这里面有3个测试, 是不是得有1个人会搞框架? 是不是得有2人搞功能测试, 一个人又搞框架, 有些脚本, 真来得及吗? 2. 人员基础不够 现在有的大公司, 是这样子协作的, 也就是某模块需求谁谁测试的, 那么…...

基于pytorch框架的手写数字识别(保姆级教学)
1、前言 本文基于PyTorch框架,采用CNN卷积神经网络实现MNIST手写数字识别,不仅可以在GPU上,同时也可以在CPU上运行。方便即使只有CPU的小伙伴也可以运行该模型。本博客手把手教学,如何手写网络层(3层),以及模型训练,详细介绍各参数含义与用途。 2、模型源码解读 该模型…...

注意力机制在大语言模型中的应用
在大语言模型中,注意力机制(Attention Mechanism)用于捕获输入序列中不同标记(token)之间的关系和依赖性。这种机制可以动态地调整每个标记对当前处理任务的重要性,从而提高模型的性能。具体来说࿰…...

qt 实现对字体高亮处理原理
在Qt中实现对文本的字体高亮处理,通常涉及到使用QTextDocument、QTextCharFormat和QSyntaxHighlighter。下面是一个简单的例子,演示如何为一个文本编辑器(假设是QTextEdit)添加简单的关键词高亮功能: 步骤 1: 定义关键…...
SAP中通过财务科目确定分析功能来定位解决BILLING问题实例
接用户反馈,一笔销售订单做发货后做销售发票时,没有成功过账到财务,提示财户确定错误。 这个之前可以通过VF02中点击小绿旗来重新执行过财动作,看看有没有相应日志来定位问题。本次尝试用此方法,也没有找到相关线索。 …...

充电站,正在杀死加油站
最近,深圳公布了一组数据,深圳的超级充电站数量已超过传统加油站数量,充电枪数量也已超过加油枪数量。 从全国范围看,加油站关停的速度在加快。 充电站正在杀死加油站。 加油站,未来何去何从? 01. 减少 我…...

哪个牌子的超声波清洗机好?四样超卓超声波清洗机独具特色!
眼镜是许多人日常生活中必不可少的工具,然而,相信很多人都有过清洗眼镜的烦恼。传统的清洗眼镜的方法往往不够彻底,容易留下污渍或者划伤镜片。因此,超声波洗眼镜机成为了现代人清洗眼镜的新选择。超声波洗眼镜机通过利用超声波震…...
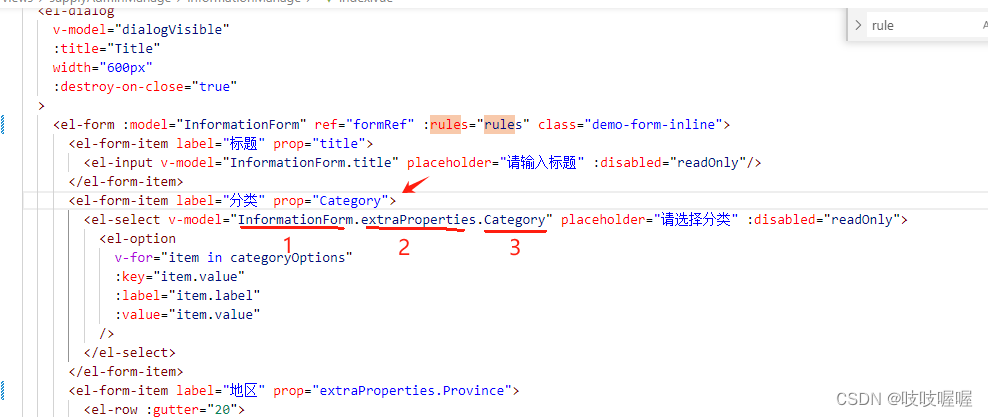
vue3中若v-model绑定的响应字段出现三级,该如何实现rules验证规则
比如以下内容: 配置的rules内容 const rulesref({title:[{required:true,message:"请输入标题",trigger:"blur"},{max:50,message:"最大不能超过256个字",trigger:"blur"}],Category:[{required:true,message:"请选择…...

Docker-Compose一键部署项目
Docker-Compose一键部署项目 目录 Docker-Compose一键部署项目介绍部署Django项目项目目录结构 docker-compose.ymlnginx的default.conf文件后端Dockerfile文件mysql.env一键部署DNS域名解析引起的跨域问题 介绍 Docker Compose 是一个用于定义和运行多容器 Docker 应用程序的…...

死锁四大必要条件解析
好的,针对“死锁考点与高频面试题”,我将直接进行核心内容解构与推演,并生成符合规范的答案。死锁是多线程并发编程中的核心难点与高频考点,其核心围绕定义、条件、场景、检测、预防与避免展开。一、 死锁核心定义与必要条件死锁是…...

KG与LLM:大模型时代的智能规划
这些文章给出的“推荐思路”可以浓缩成一句话 先用 Planner 产出 subgoal dependency acceptance criteria。再让 Router 判断每个子任务该走 向量RAG、KG、数据库还是工具。对需要关系、多跳、时序、因果的问题,用 KG / event graph 做结构化检索,而…...

5分钟Git指南
Git——一个版本控制系统 了解Git当你建立了一个Git版本库,那么存放.git(也就是版本库)的文件夹就被称为工作区,.git内部有一个暂存区,一个叫做master的分支,一个HEAD指针能够指向分支中不同版本的文件&…...

C盘空间管理完全指南:从清理到预防,根治飘红
你的C盘是否在不知不觉中已经飘红?在清理文件的路上,你是否曾因误删系统文件而追悔莫及? C盘告急的普遍困境 每当Windows系统运行缓慢,或安装新软件时弹出磁盘空间不足的提示,用户的第一反应往往是查看C盘使用情况。…...

从零到一:UNet环境搭建与自定义数据集实战指南
1. 环境准备:从Anaconda到PyTorch的完整配置 第一次接触UNet时,我最头疼的就是环境配置。记得当时为了跑通一个细胞分割的demo,整整折腾了两天。现在回头看,其实只要掌握几个关键步骤,整个过程可以非常顺畅。 首先需要…...

别再只会用WinHex看十六进制了!这5个隐藏功能帮你搞定90%的数据恢复难题
WinHex高阶数据恢复实战:5个被低估的杀手级功能解析 在数据恢复领域,WinHex早已超越了简单的十六进制编辑器定位。这款由X-Ways公司开发的专业工具集成了磁盘编辑、内存分析、数据解释等多项强大功能,但大多数用户仅停留在基础的文件浏览和简…...

技术人必备的Chrome插件清单:第7个让调试效率翻倍
对于软件测试从业者而言,浏览器早已不是单纯的信息浏览窗口,而是集接口调试、性能分析、元素定位、辅助功能验证于一体的核心工作站。面对日益复杂的Web应用和紧迫的交付周期,一套精悍的Chrome插件组合往往能带来远超预期的效率回报。本文从测…...

AI时代工程师的超能力进化
好的,这是一篇关于AI时代工程师能力进化的技术文章大纲: 标题: AI时代工程师的“超能力”进化论:从工具使用者到智能架构师 导言: 简述AI技术的迅猛发展及其对各行业的深刻影响。提出问题:在AI成为强大“…...

光子储层计算在无人机动态补偿中的创新应用
1. 深度光子储层计算在无人机动态补偿中的创新应用在无人机控制领域,传统PID控制器面对复杂流体环境时往往力不从心。当无人机在狭窄空间或近地面飞行时,地面效应、天花板效应以及湍流再循环等未建模动力学因素会导致显著的性能下降。我在参与某城市峡谷…...

AI应用着陆页模板:快速构建专业产品门户的实战指南
1. 项目概述:一个面向AI应用落地的着陆页模板 最近在折腾AI应用开发的朋友,估计都遇到过同一个问题:模型和算法好不容易调好了,后端API也搭起来了,但一到“怎么让用户用起来”这一步,就卡壳了。尤其是那个…...