【JVM】Java虚拟机运行时数据分区介绍
JVM 分区(运行时数据区域)
文章目录
- JVM 分区(运行时数据区域)
- 前言
- 1. 程序计数器
- 2. Java 虚拟机栈
- 3. 本地方法栈
- 4. Java 堆
- 5. 方法区
- 6. 运行时常量池
- 7. 直接内存
前言
之前在说多线程的时候,提到了JVM虚拟机的分区内存,如下所示,那次简单鸽了一下没有详细的介绍JVM的各个分区的主要功能/生命周期等内容,在这里补上。
本博客通过图文/代码示例等,详细的介绍了JVM的各个分区的功能,写作不易,求个关注!
参考资料《深入理解Java虚拟机》

1. 程序计数器
程序计数器是一块较小的内存空间,它是线程所有的,随着线程的出现而出现,随着线程的消亡而消亡,它可以看做是当前线程所执行的字节码的行号指示器。
Java虚拟机的多线程是通过线程轮流切换、分配处理器执行时间的方式来实现的,在任何一个确定时刻,一个处理器(对于多核处理器来说是一个内核)都只会执行一条线程中的指令。当线程执行时会被CPU调度,时间分片结束后会被再次挂起,直到再一次被CPU调度的时候,就会再次执行一个分片单位。为了保证线程在恢复调度时候能正确的在原有进度上继续向下执行,每条线程都需要有一个独立的程序计数器,各条线程之间计数器互不影响,独立存储。
**如果正在执行的是本地(Native)方法,这个计数器值值应该为空。**程序计数器是唯一一个没有规定任何OutOfMemoryError情况的区域。
2. Java 虚拟机栈
虚拟机栈也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的线程内存模型:每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧[1](Stack Frame)用于存储局部变量表、操作数栈、动态连接、方法出口等信息。每一个方法被调用直至执行完毕的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
局部变量表存放了编译期可知的各种Java虚拟机基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference类型,它并不等同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或者其他与此对象相关的位置)和returnAddress 类型(指向了一条字节码指令的地址)。
这些数据类型在局部变量表中的存储空间以局部变量槽(Slot)来表示,其中64位长度的long和double类型的数据会占用两个变量槽,其余的数据类型只占用一个。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在栈帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
如果线程请求的栈深度大于虚拟机所允许的深度,将会抛出StackOverflowError异常
如果Java虚拟机栈容量可以动态扩展,当栈扩展时无法申请到足够的内存会抛出OutOfMemoryError(OOM)异常
以下面代码为例,讲一下栈与栈帧:
public class TestA {public static void main(String[] args) {hello();}public static void hello() {System.out.println("Hello World!I'm Jim.kk!")}}
- 以上代码在开始执行的时候,会遇到main方法,此时main方法入栈
- 当遇到hello方法的时候,hello方法入栈
- hello方法内有一个print方法,print方法入栈
- print方法执行完毕,print方法出栈
- hello方法执行完毕,hello方法出栈
- main方法执行结束,main方法出栈
- 线程结束,栈消亡

3. 本地方法栈
本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别只是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的本地(Native)方法服务。
不过,《Java虚拟机规范》并没有强制规定本地方法栈一定要独立出来,因此有的Java虚拟机(如Hot-Spot虚拟机)直接把本地方法栈和虚拟机栈合二为一。
本地方法栈也会在栈深度溢出或栈扩展失败时分别抛出StackOverflowError和OutOfMemoryError异常。
4. Java 堆
Java堆(Java Heap)是虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,Java 世界里“几乎”所有的对象实例都在这里分配内存。
Java堆(Java Heap)是虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,Java 世界里“几乎”所有的对象实例都在这里分配内存。
Java堆(Java Heap)是虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,Java 世界里“几乎”所有的对象实例都在这里分配内存。
堆既可以被设计成事固定大小的,也可以被设计成事可扩展的,如果是可扩展的话,如果在Java堆中没有内存完成实例分配,并且堆也无法再扩展时,Java虚拟机将会抛出OutOfMemoryError异常。
以下内容存储在堆中:
public class JimTest {// 1. 实例变量|存储在堆中private int num1;public static void main(String[] args) {// 2. 普通对象|存储在堆中List<String> list = new ArrayList<>();// 3. 数组|存储在堆中int[] ints = new int[10];// 4. 字符串对象|存储在堆中(注意这里是字符串对象)String str1 = new String("CSDN/Jim.kk");// 字符串子面量|不不不不不不不存储在堆中(注意这里是不存在堆中)String str2 = "CSDN/Jim.kk";}
}
5. 方法区
方法区(线程共享),用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
在JDK7之前,程序员喜欢称呼方法区为“永久代”,但是永久代并不等价于方法区,只不过HotSpot的设计团队奖收集器的分带设计扩展至方法区,用永久代来实现方法区而已,这样就能够像管理Java堆一样管理这部分内存,省去专门为方法区编写内存管理代码的工作。但这并不是一个好主意,这种设计导致了Java应用更容易遇到内存溢出的问题(永久代有-XX:MaxPermSize的上限,即使不设置也有默认大小,而J9和JRockit只要没有触碰到进程可用内存的上限,例如32位系统中的4GB限制,就不会出问题),而且有极少数方法(例如String::intern())会因永久代的原因而导致不同虚拟机下有不同的表现。
在JDK 6的时候HotSpot开发团队就有放弃永久代,逐步改为采用本地内存(Native Memory)来实现方法区的计划了[1],到了JDK 7的HotSpot,已经把原本放在永久代的字符串常量池、静态变量等移出,而到了JDK 8,终于完全废弃了永久代的概念,改用与JRockit、J9一样在本地内存中实现的元空间(Meta-space)来代替,把JDK 7中永久代还剩余的内容(主要是类型信息)全部移到元空间中。
注意,JDK8开始,不存在永久代,取而代之的是元空间!
并非进入该区域的内容就是永久存在了,该区域的内存也会进行回收,回收目标主要是针对常量池的回收和对类型的卸载。
以下是一些存储在方法区中的内容:
public class MethodAreaExample {// 静态变量|存储在方法区中private static int staticVar = 42;// 构造方法|字节码存储在方法区中public MethodAreaExample(int value) {this.instanceVar = value;}// 静态方法|字节码存储在方法区中public static void staticMethod() {System.out.println("This is a static method.");}// 普通方法|字节码存储在方法区中public void instanceMethod() {System.out.println("This is an instance method.");}}在开发中我们经常会写一些工具类,里面有非常多的静态方法,我们可以通过
类名.方法名()的方式调用这些方法,同时我们也经常提到静态内容是属于类的,因此静态的信息成员属性、成员方法会被存储在方法区中,另外既然都叫方法去了,那么方法的字节码肯定也是存储在里面的。
6. 运行时常量池
运行时常量池(Runtime Constant Pool)是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池表(Constant Pool Table),用于存放编译期生成的各种基本类型的常量、字面量与符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中。
注意,除了运行时常量池外,还有一个Class常量池,Class常量池是在编译的时候就能确定的,但是运行时常量池是动态的,Java并不要求常量一定只有编译期才会产生,也就是说,并非预置入Class文件中的常量池才能进入方法区运行时常量池,运行期间也可以将新的常量放入池中。比如我们通过反射创建的常量等。
以下是存储在常量池中的举例
public class CompileTimeConstantPoolExample {// 编译时常量池中的常量private static final int CONSTANT_INT = 42;private static final String CONSTANT_STRING = "CSDN/Jim.kk";public static void main(String[] args) {// 字符串字面量,存储在编译时常量池中String str1 = "CSDN/Jim.kk";// 比较字符串常量System.out.println(str1 == "CSDN/Jim.kk"); // true,因为常量池中的字符串是同一对象// 字符串对象,存储在堆中String str2 = new String("CSDN/Jim.kk");// 比较堆中的字符串对象和常量池中的字符串常量System.out.println(str1 == str2); // false,因为str2是在堆中新创建的对象}
}以下是存储在运行时常量池中的举例
public class RuntimeConstantPoolExample {public static void main(String[] args) {// 字符串字面量,存储在运行时常量池中String str1 = "CSDN/Jim.kk";// 通过 new 创建的字符串对象,存储在堆中String str2 = new String("CSDN/Jim.kk");// 调用 intern() 方法,将字符串对象添加到运行时常量池中,但是由于常量池中已经存在CSDN/Jim.kk字符串,因此这里其实是与str1共享一个字符串String str3 = str2.intern();// 比较引用System.out.println(str1 == str3); // true,因为 str3 是运行时常量池中的引用,与 str1 相同}
}7. 直接内存
直接内存并不是虚拟机内存的一部分,可以理解成是直接使用物理内存条上的地址。
由于在JDK1.4中新加入了NIO,引入了基于通道(Channel)与缓冲区(Buffer)的I/O方式,它可以使用Native函数库直接分配堆外内存,然后通过一个存储在Java堆里面的DirectByteBuffer对象作为这块内存的引用进行操作。这样的操作能够在一些场景中显著提高性能,因为避免了Java堆和Native堆中来回复制数据。
如果调用的内存超过物理机内存大小,依然会抛出OutOfMemoryError异常,毕竟没有了就没法继续申请了。
这里补充一嘴,在计算机体系结构中,32位和64位通常指的是处理器的数据总线宽度和寻址能力,这直接影响到系统可以支持的最大内存大小,一般来说32位可用的最大内存是232字节,即4GB,而64位的电脑可以使用264的内存,是17,179,869,184 GB,16,384 TB(但是一般都会受到CPU限制,比如现在的电脑虽然都是64位了,但是有的CPU最大仅支持32GB的内存条,有的最大支持64GB)。
对着一部分有疑问的话可以学一下NIO或者Netty。
相关文章:
【JVM】Java虚拟机运行时数据分区介绍
JVM 分区(运行时数据区域) 文章目录 JVM 分区(运行时数据区域)前言1. 程序计数器2. Java 虚拟机栈3. 本地方法栈4. Java 堆5. 方法区6. 运行时常量池7. 直接内存 前言 之前在说多线程的时候,提到了JVM虚拟机的分区内存…...
)
大数据面试题之Kafka(2)
目录 Kafka的工作原理? Kafka怎么保证数据不丢失,不重复? Kafka分区策略 Kafka如何尽可能保证数据可靠性? Kafka数据丢失怎么处理? Kafka如何保证全局有序? 生产者消费者模式与发布订阅模式有何异同? Kafka的消费者组是如何消费数据的 Kafka的…...
)
前端面试题(基础篇十一)
一、DOCTYPE 的作用是什么? <!DOCTYPE> 声明一般位于文档的第一行,它的作用主要是告诉浏览器以什么样的模式来解析文档。一般指定了之后会以标准模式来进行文档解析,否则就以兼容模式进行解析。在标准模式下,浏览器的解析规…...
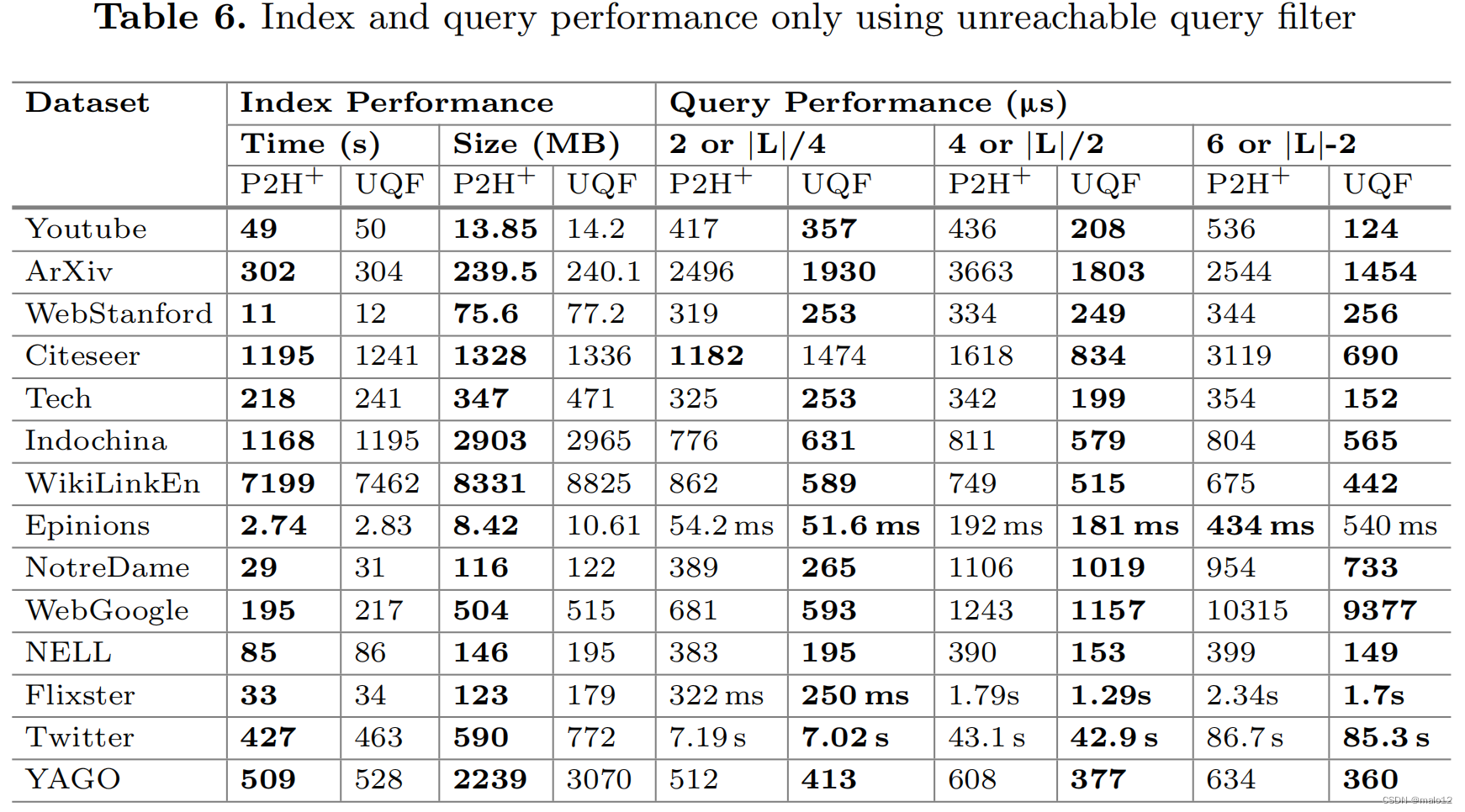
【论文阅读】Answering Label-Constrained Reachability Queries via Reduction Techniques
Cai Y, Zheng W. Answering Label-Constrained Reachability Queries via Reduction Techniques[C]//International Conference on Database Systems for Advanced Applications. Cham: Springer Nature Switzerland, 2023: 114-131. Abstract 许多真实世界的图都包含边缘标签…...

Git Flow 工作流学习要点
Git Flow 工作流学习要点 Git Flow — 流程图Git Flow — 操作指令优点:缺点:Git Flow 分支类型Git Flow 工作流程简述关于 feature 分支关于 Release 分支关于 hotfix 分支 总结 Git Flow — 流程图 图片来源:https://nvie.com/posts/a-succ…...

blender 快捷键 常见问题
一、快捷键 平移视图:Shift 鼠标中键旋转视图:鼠标中键缩放视图:鼠标滚动框选放大模型:Shift B线框预览和材质预览切换:Shift Z 二、常见问题 问题:导入模型成功,但是场景中看不到。 解…...

HTTP详解:TCP三次握手和四次挥手
一、TCP协议概述 TCP协议是互联网协议栈中传输层的核心协议之一,它提供了一种可靠的数据传输方式,确保数据包按顺序到达,并且没有丢失或重复。TCP的主要特点包括: 面向连接:TCP在传输数据之前需要建立连接。可靠传输&…...

详解HTTP:有了HTTP,为何需要WebSocket?
在日常生活中,HTTP 常用于请求数据。例如,当你打开一个天气预报网站时,浏览器会发送一个 HTTP 请求到服务器,请求当前的天气数据,服务器返回响应,浏览器解析并显示这些数据。 但是,当涉及到需要…...

Spring Boot 启动流程是怎么样的
引言 SpringBoot是一个广泛使用的Java框架,旨在简化基于Spring框架的应用程序的开发过程。在这篇文章中,我们将深入探讨SpringBoot应用程序的启动流程,了解其背后的机制。 Spring Boot 启动概览 SpringBoot应用程序的启动通常从一个包含 m…...
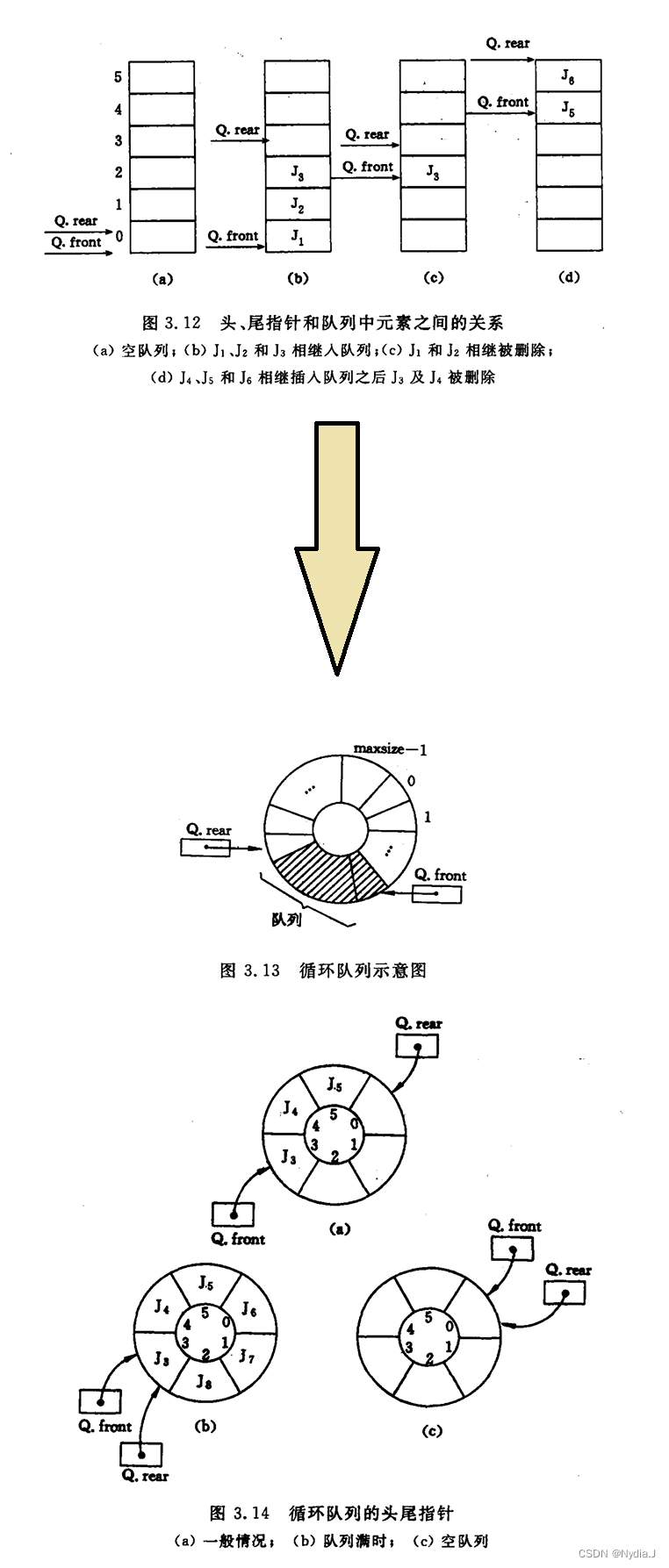
【学习笔记】数据结构(三)
栈和队列 文章目录 栈和队列3.1 栈 - Stack3.1.1 抽象数据类型栈的定义3.1.2 栈的表示和实现 3.2 栈的应用举例3.2.1 数制转换3.2.2 括号匹配的检验3.2.3 迷宫求解3.2.4 表达式求值 - 波兰、逆波兰3.2.5 反转一个字符串或者反转一个链表 3.3 栈与递归的实现3.4 队列 - Queue3.4…...

学习python笔记:10,requests,enumerate,numpy.array
requests库,用于发送 HTTP 请求的 Python 库。 requests 是一个用于发送 HTTP 请求的 Python 库。它使得发送 HTTP 请求变得简单且人性化。以下是一些基本的 requests 函数及其用途: requests.get(url, **kwargs) 发送一个 GET 请求到指定的 URL。 i…...

经典神经网络(13)GPT-1、GPT-2原理及nanoGPT源码分析(GPT-2)
经典神经网络(13)GPT-1、GPT-2原理及nanoGPT源码分析(GPT-2) 2022 年 11 月,ChatGPT 成功面世,成为历史上用户增长最快的消费者应用。与 Google、FaceBook等公司不同,OpenAI 从初代模型 GPT-1 开始,始终贯彻只有解码器࿰…...

MySQL库与表的操作
目录 一、登录并进入数据库 1、登录 2、USE 命令 检查当前数据库 二、库的操作 1、创建数据库语法 2、举例演示 3、退出 三、字符集和校对规则 1、字符集(Character Set) 2、校对集(Collation) 总结 3、操作命令 …...

TTS 语音合成技术学习
TTS 语音合成技术 TTS(Text-to-Speech,文字转语音)技术是一种能够将文字内容转换为自然语音的技术。通过 TTS,机器可以“说话”,这大大增强了人与机器之间的互动能力。无论是在语音助手、导航系统还是电子书朗读器中&…...

小公司做自动化的困境
1. 人员数量不够 非常常见的场景, 开发没几个, 凭什么测试要那么多, 假设这里面有3个测试, 是不是得有1个人会搞框架? 是不是得有2人搞功能测试, 一个人又搞框架, 有些脚本, 真来得及吗? 2. 人员基础不够 现在有的大公司, 是这样子协作的, 也就是某模块需求谁谁测试的, 那么…...

基于pytorch框架的手写数字识别(保姆级教学)
1、前言 本文基于PyTorch框架,采用CNN卷积神经网络实现MNIST手写数字识别,不仅可以在GPU上,同时也可以在CPU上运行。方便即使只有CPU的小伙伴也可以运行该模型。本博客手把手教学,如何手写网络层(3层),以及模型训练,详细介绍各参数含义与用途。 2、模型源码解读 该模型…...

注意力机制在大语言模型中的应用
在大语言模型中,注意力机制(Attention Mechanism)用于捕获输入序列中不同标记(token)之间的关系和依赖性。这种机制可以动态地调整每个标记对当前处理任务的重要性,从而提高模型的性能。具体来说࿰…...

qt 实现对字体高亮处理原理
在Qt中实现对文本的字体高亮处理,通常涉及到使用QTextDocument、QTextCharFormat和QSyntaxHighlighter。下面是一个简单的例子,演示如何为一个文本编辑器(假设是QTextEdit)添加简单的关键词高亮功能: 步骤 1: 定义关键…...
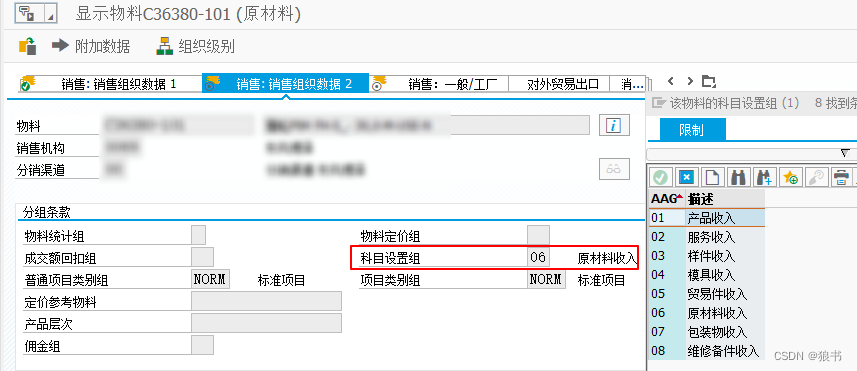
SAP中通过财务科目确定分析功能来定位解决BILLING问题实例
接用户反馈,一笔销售订单做发货后做销售发票时,没有成功过账到财务,提示财户确定错误。 这个之前可以通过VF02中点击小绿旗来重新执行过财动作,看看有没有相应日志来定位问题。本次尝试用此方法,也没有找到相关线索。 …...

充电站,正在杀死加油站
最近,深圳公布了一组数据,深圳的超级充电站数量已超过传统加油站数量,充电枪数量也已超过加油枪数量。 从全国范围看,加油站关停的速度在加快。 充电站正在杀死加油站。 加油站,未来何去何从? 01. 减少 我…...

XSP25全协议 100W PD快充诱骗芯片_串口读电压电流信息
在Type-C快充技术普及的今天,快充诱骗协议芯片成为小家电、智能硬件、锂电设备等产品实现高效取电的核心器件。XSP25作为汇铭达推出的Type‑C受电端(Sink)多功能快充取电芯片,以全协议兼容、100W大功率输出、串口智能通信、极简外…...

实证论文不用愁!虎贲等考 AI 数据分析:零代码跑模型,图表 + 结论一键生成
在本科、硕士毕业论文写作中,数据分析往往是最让学生头疼的章节。不会数据清洗、不懂模型选择、跑不出稳健结果、图表不会做、文字不会写,即便前面内容写得再完整,第四章一塌糊涂,整篇论文直接被导师打回。 传统软件如 Stata、Py…...

Llama.cpp Docker镜像部署指南:快速搭建本地大模型运行环境
1. 项目概述:为什么需要为Llama.cpp准备Docker镜像? 在本地部署和运行大型语言模型(LLM)这件事上,Llama.cpp 几乎成了开源社区的“标准答案”。它用纯C/C编写,通过高效的量化技术,让我们能在消费…...
)
从手动导入到自动溯源:Perplexity提问→Mendeley定位原文→高亮引用段落→一键生成BibTeX(全流程图解)
更多请点击: https://intelliparadigm.com 第一章:从手动导入到自动溯源:Perplexity提问→Mendeley定位原文→高亮引用段落→一键生成BibTeX(全流程图解) 科研写作中,文献溯源与引用管理长期面临“知其然不…...
AITranslate:本地化AI翻译工作流框架,构建可编程翻译管道
1. 项目概述与核心价值最近在折腾一个挺有意思的项目,叫AITranslate。这名字一看就知道,它想用AI来干翻译的活儿。但说实话,现在市面上翻译工具多如牛毛,从老牌的谷歌翻译、DeepL,到各种大厂出的AI翻译插件,…...

开源状态监控工具openclaw-status:从原理到部署的完整实践指南
1. 项目概述:一个开源状态监控工具的诞生最近在折腾一个开源项目,叫openclaw-status,是vibe-with-me-tools组织下的一个子项目。简单来说,这是一个用于监控和展示各种服务、应用、设备状态的工具。听起来是不是有点像那些商业化的…...

基于MCP协议构建AI助手业务工具适配器:从原理到实践
1. 项目概述:用MCP协议为AI助手装上“业务之眼”如果你和我一样,日常开发中需要频繁地在Stripe看支付数据、在Sentry查线上错误、在Notion里翻文档、在Linear跟进任务状态,那你一定懂那种在十几个浏览器标签页和不同SaaS平台间反复横跳的疲惫…...

数据库完整性约束与安全机制全解析
一、数据库完整性约束1、数据库完整性基本概念与核心机制(1)完整性定义与作用数据库完整性(Database Integrity)是指在任何情况下保证数据的正确性(Validity)和一致性(Consistency)&…...

中国地址生成器:快速生成真实地址数据的开发者利器
中国地址生成器:快速生成真实地址数据的开发者利器 【免费下载链接】chinese-address-generator 中国地址生成器 - 三级地址 四级地址 随机生成完整地址 项目地址: https://gitcode.com/gh_mirrors/ch/chinese-address-generator 在开发测试、数据填充、表单…...

大模型压缩实战:量化、剪枝与知识蒸馏技术解析与应用
1. 项目概述:当大模型遇见“瘦身”革命最近在跟几个做AI应用落地的朋友聊天,大家普遍都在吐槽一个事儿:现在的大语言模型(LLM)能力是强,但动辄几十亿、上百亿的参数规模,部署成本高得吓人&#…...