Pyecharts入门
数据可视化 Pyecharts简介
Apache ECharts 是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时,pyecharts 诞生了;PyEcharts是Echarts的Python接口, Pyecharts = Python + Echarts
- Pyecharts 官方文档手册:pyecharts - A Python Echarts Plotting Library built with love.
- Pyecharts 官方示例网站:Document
- echart 官方网站:Apache ECharts
Pyecharts是一个强大的Python库,用于创建各种类型的数据可视化图表,包括折线图、柱状图、饼图、散点图、地图、雷达图等。
Pyecharts 环境搭建
Pyeharts版本
本系列Pyecharts版本采用 1.9.0
Pyecharts 安装
建议大家在单独的隔离环境中使用pip 进行安装
pip install pyecharts==1.9.0
也可以使用源码方式安装最新版,但是由于pyecharts更新方式,不同版本的API可能略有不同
$ git clone https://github.com/pyecharts/pyecharts.git
$ cd pyecharts
$ pip install -r requirements.txt
$ python setup.py install
# 或者执行 python install.py在可视化之前,会对原始数据进行一些列的整理,数据处理过程中,可能会用到
- pandas
- numpy
- matplotlib
等Python工具,在进行绘图时,会高频率访问pyecharts API 文档和示例官网
- Pyecharts 官方文档手册:pyecharts - A Python Echarts Plotting Library built with love.
- Pyecharts 官方示例网站:Document
- echart 官方网站:Apache ECharts
Pyecharts 柱状图绘制
我们使用中国各省2003年至2021年结婚登记数与离婚登记数数据进行分析与可视化,该数据来自中国国家统计局官方数据。
数据准备
import pandas as pd
import numpy as nppath_marry = "结婚数据.csv"
path_divorse = "离婚数据.csv"
marry_data = pd.read_csv(path_marry)
divorse_data = pd.read_csv(path_divorse)# 只需要在顶部声明 CurrentConfig.ONLINE_HOST 即可
# from pyecharts.globals import CurrentConfig, OnlineHostType# OnlineHostType.NOTEBOOK_HOST 默认值为 http://localhost:8888/nbextensions/assets/
# CurrentConfig.ONLINE_HOST = OnlineHostType.NOTEBOOK_HOST可以预览一下结婚数据(离婚数据类似)
marry_data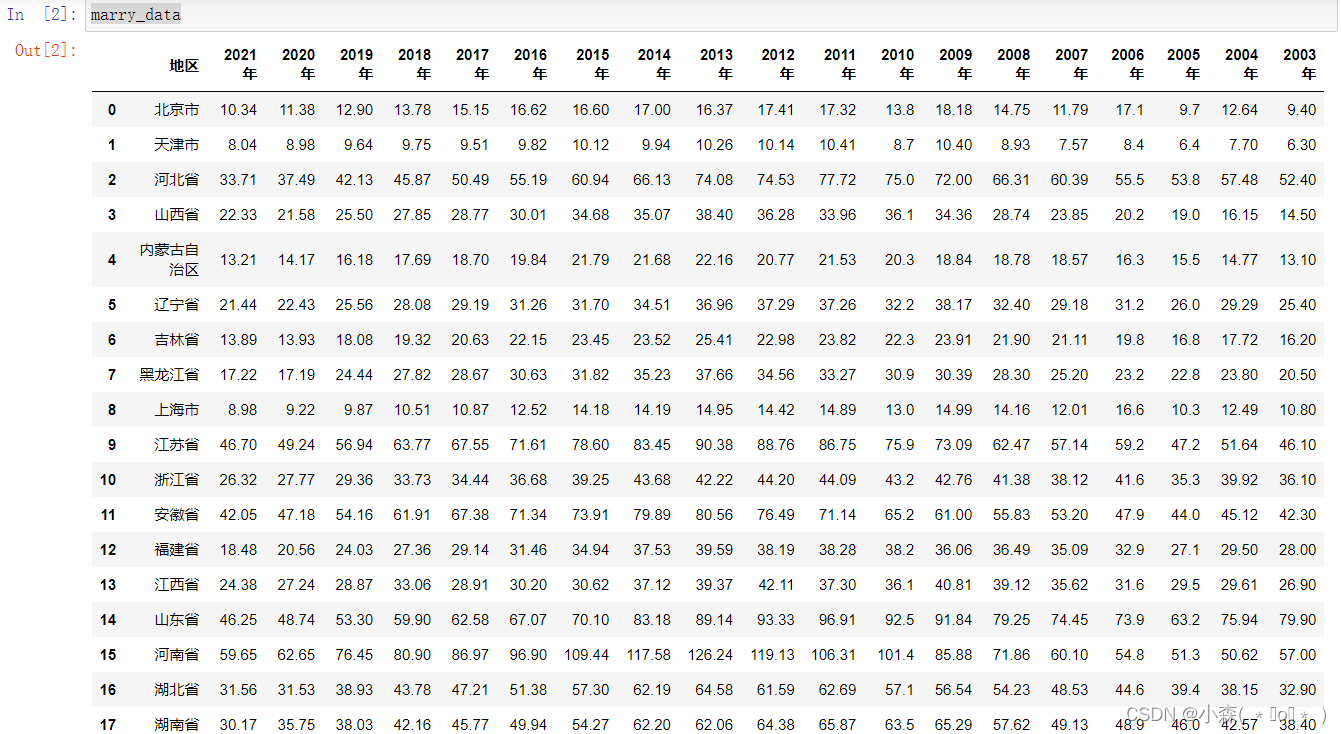
显示了各个省2003年到2021年结婚数据,单位是(万对),数据中,并没有显示全国合计的数据,可以给当前的数据增加一行,表示全国求和的数据,执行如下代码:
demo = marry_data.set_index(marry_data["地区"]).drop(columns=["地区"])
demo = demo.transpose()
demo['全国合计'] = demo.sum(axis=1)
marry_data = demo.transpose()需求1,要求对全国结婚登记数每年度数据变化展现
marry_data.loc["全国合计"]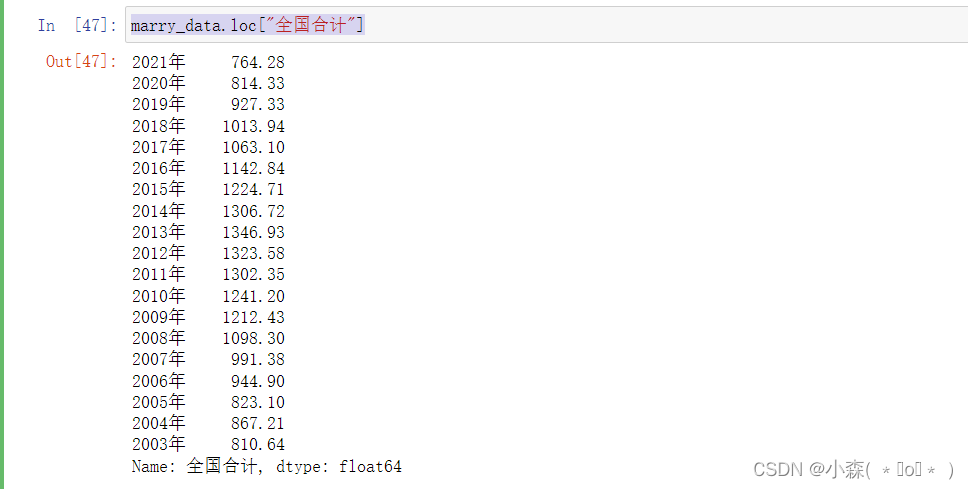
很明显,是一个Series类型的数据,该类型数据有两个需要展示的内容,分别是index和values,可视化图标中能够展示该类型数据有很多,但是最贴题的应该是条柱图,在进行图形展示之前,我们还需要了解,Pyecharts到底是怎么进行条柱图绘制的?
pyecharts 条柱图的绘制
在官方示例中,直接copy过来最简单的pyecharts的源码
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.faker import Fakerc = (Bar().add_xaxis(Faker.choose()).add_yaxis("商家A", Faker.values()).add_yaxis("商家B", Faker.values()).set_global_opts(title_opts=opts.TitleOpts(title="Bar-基本示例", subtitle="我是副标题")).render("bar_base.html")
)
大家执行这些代码时,并没有什么效果,并不是代码错误,而是在代码中执行render("bar_base.html")这个方法,默认规则是生成一个HTML页面,在页面中使用echarts渲染对应图表;大家可以查看一下,在当前目录下,是否生成了一个bar_base.html内容,为了学习过程中的联系性,我们不选择生成一个单独的页面,我们选择在notebook中进行渲染,只需要替换一点点代码,把render方法替换成render_notebook
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.faker import Faker
c = (Bar().add_xaxis(Faker.choose()).add_yaxis("商家A", Faker.values()).add_yaxis("商家B", Faker.values()).set_global_opts(title_opts=opts.TitleOpts(title="Bar-基本示例", subtitle="我是副标题"))
)
c.render_notebook()解析一下这段代码,首先,pyecharts的编程风格是链式调用风格,在pyecharts中每一种图表都是实例对象,柱状图就是Bar这个类实例化后的结果,柱状图绘制其实需要两种数据,X轴上的数据,以及Y轴上的数据,柱状图是通过条柱的高低或者长短来表示数据;所以,在Bar实例化后,需要添加两个轴方向上的数据,add_xaxis 方法添加的就是X轴向的数据,Faker.choose()其实就是pyecharts提供的一个方便产生随机数据的方法,随机产生数据。对于柱状图而言,X轴向的数据是离散的,并不是连续的!一般是种类、类别数据
add_yaxis 方法就是添加Y轴向数据,也是条柱图要表达的数据,pyecharts可以支持多Series系列数据,什么是系列呢,该图表有两种颜色的条柱,一种颜色的条柱就是Series数据,调用add_yaxis方法就会像Bar实例添加一个系列的数据。这个add_yaxis 是pyecharts非常核心的方法,可以查看下这个方法的参数
help(Bar().add_yaxis)#
Help on method add_yaxis in module pyecharts.charts.basic_charts.bar:add_yaxis(series_name: str, y_axis: Sequence[Union[int, float, pyecharts.options.charts_options.BarItem, dict]], *, is_selected: bool = True, xaxis_index: Union[int, float, NoneType] = None, yaxis_index: Union[int, float, NoneType] = None, is_legend_hover_link: bool = True, color: Optional[str] = None, is_realtime_sort: bool = False, is_show_background: bool = False, background_style: Union[pyecharts.options.charts_options.BarBackgroundStyleOpts, dict, NoneType] = None, stack: Optional[str] = None, stack_strategy: Optional[str] = 'samesign', sampling: Optional[str] = None, cursor: Optional[str] = 'pointer', bar_width: Union[int, float, str] = None, bar_max_width: Union[int, float, str] = None, bar_min_width: Union[int, float, str] = None, bar_min_height: Union[int, float] = 0, category_gap: Union[int, float, str] = '20%', gap: Optional[str] = '30%', is_large: bool = False, large_threshold: Union[int, float] = 400, dimensions: Optional[Sequence] = None, series_layout_by: str = 'column', dataset_index: Union[int, float] = 0, is_clip: bool = True, z_level: Union[int, float] = 0, z: Union[int, float] = 2, label_opts: Union[pyecharts.options.series_options.LabelOpts, dict, NoneType] = <pyecharts.options.series_options.LabelOpts object at 0x10567fcc0>, markpoint_opts: Union[pyecharts.options.series_options.MarkPointOpts, dict, NoneType] = None, markline_opts: Union[pyecharts.options.series_options.MarkLineOpts, dict, NoneType] = None, tooltip_opts: Union[pyecharts.options.global_options.TooltipOpts, dict, NoneType] = None, itemstyle_opts: Union[pyecharts.options.series_options.ItemStyleOpts, dict, NoneType] = None, encode: Union[str, pyecharts.commons.utils.JsCode, dict, NoneType] = None) method of pyecharts.charts.basic_charts.bar.Bar instance有很多很多参数,很夸张,这些参数控制着这个系列数据的展现形式,有各种各样的配置,比如条柱颜色,条柱上Label的位置等等,具体信息请查看pyecharts的官网,解释很详细 点我.
可以观察到,这个方法有两个必须传递的参数,第一个参数和第二个参数,分别表示该系列数据的名称,这个系列名称会自动添加到该图形的legend上去,第二个参数就是该系列数据的真实值,其他参数,未传入的参数都有默认值,注意,这些参数主要控制着每一种系列数据的样式,也就是说,不同系列数据可以设置不同的样式!
重点!
接下来有调用了一个很重要的方法,set_global_opts方法,这个方法是实例对象调用的,但是他,并不是对系列数据进行修饰,而是对整体图表进行修饰,称之为全局项配置。负责图形大部分整体的修饰,主要包括:
- 初始化配置
- 动画配置
- 标题配置
- 图例配置
- 坐标轴配置
- 工具箱配置
- 动画配置
对Pyecharts有了一定了解之后,我们就可以把marry_data.loc["全国合计"] 这个Pandas中的Series数据使用柱图表现出来了,只需要替换add_xaxis和add_xaxis方法中的数据值。
tips:
pyecharts 中只支持list等 Python原生数据,所以还要对numpy数组进行一个转换,使用tolist方法
show_data1 = marry_data.loc["全国合计"]
x_axis_data = pd.Series(show_data1.index).apply(lambda x:x[:-1]).values.tolist()
y_axis_data = show_data1.values.tolist()
c = (Bar().add_xaxis(x_axis_data).add_yaxis("全国数据分布", y_axis_data)
)
c.render_notebook()没有经过修饰的 图表肯定不是我们想要的,接下来,我们就要对该图表进行修饰,第一步,肯定是对不规则的label进行设计。由于图表密度比较大,产生重叠,所以最好把label移入柱体内部。这个label是series条柱本身的设计,所以可以在add_yaxis中通过参数配置,具体规则,还是需要对文档进行查询 来吧,点我.
c = (Bar(init_opts=opts.InitOpts(width="1000px",height="400px")).add_xaxis(x_axis_data).add_yaxis("全国数据分布", y_axis_data, label_opts=opts.LabelOpts(position="inside", color='white', rotate=90, font_size=12, font_weight='blod'))
)
c.render_notebook()结果是清晰了一些,但是还是有问题,显示数据并没有格式化,数据格式化可以对原始数据进行格式化,也可以在现实的时候通过配置进行控制,通过查询文档,发现,在配置LabelOpts时,支持formatter这样的格式化函数,但是不幸的是,这个是需要传入一个javascript函数,也就是说,在使用Python编程完成可视化时,还需要了解一点点的JavaScript代码,以下是文档对该回调函数的解释
# 参数 params 是 formatter 需要的单个数据集。格式如下:# {# componentType: 'series',# // 系列类型# seriesType: string,# // 系列在传入的 option.series 中的 index# seriesIndex: number,# // 系列名称# seriesName: string,# // 数据名,类目名# name: string,# // 数据在传入的 data 数组中的 index# dataIndex: number,# // 传入的原始数据项# data: Object,# // 传入的数据值# value: number|Array,# // 数据图形的颜色# color: string,# }
接下来可以使用js代码稍微修饰一下
from pyecharts.commons.utils import JsCode
js_code_01 = """function (param) {return Number(param.data).toFixed(2)}"""
c = (Bar(init_opts=opts.InitOpts(width="1000px",height="400px")).add_xaxis(x_axis_data).add_yaxis("全国数据分布", y_axis_data, label_opts=opts.LabelOpts(position="inside", color='white', rotate=90, font_size=12, font_weight='blod', formatter=JsCode(js_code_01)))
)
c.render_notebook()接下来,还需要进行文本的显示,这里的文本是指图表的标题,这里是全局设置,通过title_opts参数设置
c = (Bar(init_opts=opts.InitOpts(width="1000px",height="400px")).add_xaxis(x_axis_data).add_yaxis("全国数据分布", y_axis_data, label_opts=opts.LabelOpts(position="inside", color='white', rotate=90, font_size=12, font_weight='blod', formatter=JsCode(js_code_01))).set_global_opts(title_opts=opts.TitleOpts(title = "全国结婚登记数量(万对)数据分布", subtitle="结婚数据"))
)
c.render_notebook()到此,基本设计已经完结,但是,当前可视化图表颜色表达还不是特别突出,为了得到良好的视觉效果,可以使用VisualMapOpts 进行颜色与数据的映射,该配置可以使用全局配置。
c = (Bar(init_opts=opts.InitOpts(width="1000px",height="400px", theme='dark')).add_xaxis(x_axis_data).add_yaxis("全国数据分布", y_axis_data, label_opts=opts.LabelOpts(position="inside", color='white', rotate=90, font_size=12, font_weight='blod', formatter=JsCode(js_code_01))).set_global_opts(title_opts=opts.TitleOpts(title = "全国结婚登记数量(万对)数据分布", subtitle="结婚数据"),visualmap_opts=opts.VisualMapOpts(max_ = show_data1.max(), min_ = show_data1.min(), range_color = ['#3867d6','#45aaf2','#0fb9b1','#26de81','#fed330','#fa8231','#eb3b5a']))
)
c.render_notebook()我们还可以给条柱设计阴影效果,让图表显示的更立体,通过属性ItemStyleOpts,穿越时空.,但是pyecharts并没有开放对应的阴影效果的属性,但是我们可以使用字典形式的配置,来指定阴影效果,可以直接查阅echarts再次穿越对应的阴影设置,在pyecharts中使用字典配置
show_data2 = show_data1.sort_index()
x_axis_data = pd.Series(show_data2.index).apply(lambda x:x[:-1]).values.tolist()
y_axis_data = show_data2.values.tolist()
c = (Bar(init_opts=opts.InitOpts(width="1000px",height="400px", theme='dark')).add_xaxis(x_axis_data).add_yaxis("全国数据分布", y_axis_data, label_opts=opts.LabelOpts(position="inside", color='white', rotate=90, font_size=12, font_weight='blod', formatter=JsCode(js_code_01)),itemstyle_opts={"areaColor":'#091632', 'borderColor':'#4168E1', 'shadowColor':'#4168E1', "shadowBlur":5, 'opacity':1}, markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(name="平均值", type_="average", ),opts.MarkLineItem(name="最低值", type_="min")],linestyle_opts=opts.LineStyleOpts(width=2, color="#8854d0", type_="dashed", opacity=0.5))).set_global_opts(title_opts=opts.TitleOpts(title = "全国结婚登记数量(万对)数据分布", subtitle="结婚数据"),visualmap_opts=opts.VisualMapOpts(max_ = show_data1.max(), min_ = show_data1.min(), range_color = ['#3867d6','#45aaf2','#0fb9b1','#26de81','#fed330','#fa8231','#eb3b5a']))
)
c.render_notebook()需求2,计算2019年各省结婚登记数量对比
上一个需求数据对比的维度是时间,当前这个需求对比的维度则转变成了省份
数据准备
show_data2 = marry_data["2019年"]
show_data2 = show_data2.iloc[:-1]
show_data2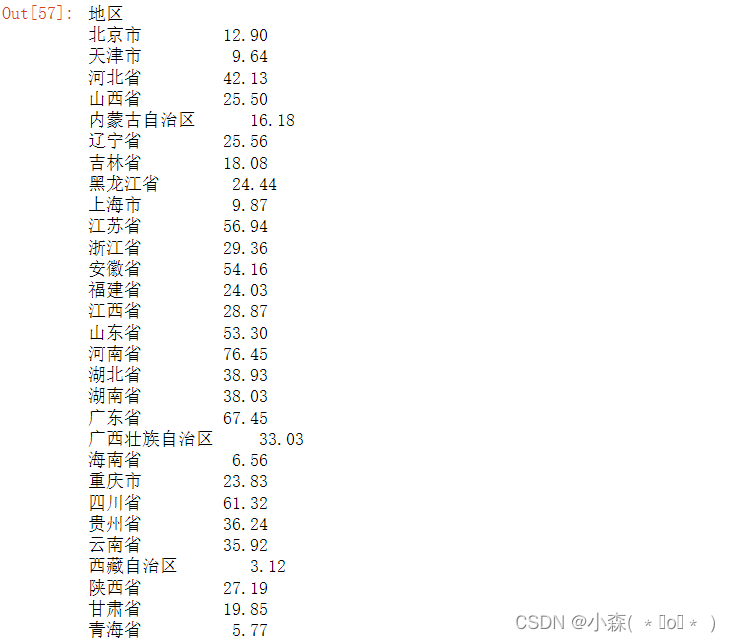
绘图展示
需要展现的数据依然是Series数据,本案例使用条形图进行数据展示,首先去示例官网寻找示例,记得常回来看看, 这里涉及到了另一个方法,就是set_series_opts方法,这个方法是对有Series系列进行属性设计,他接受的参数与add_yaxis方法接受的参数类似。
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.faker import Fakerc = (Bar().add_xaxis(Faker.choose()).add_yaxis("商家A", Faker.values()).add_yaxis("商家B", Faker.values()).reversal_axis().set_series_opts(label_opts=opts.LabelOpts(position="right")).set_global_opts(title_opts=opts.TitleOpts(title="Bar-翻转 XY 轴"))
)
c.render_notebook()可以观察到,Bar实例对象调用了reversal_axis方法,进行了X轴与Y轴数据的转换,从而柱形图变成了条形图,所以在替换数据时,不需要改变数据轴向的位置。
条形图显示的数据,一般是排序之后的数据,这里排序就对数据源进行排序
show_data2 = show_data2.sort_values()
x_axis_data = pd.Series(show_data2.index).values.tolist()
y_axis_data = show_data2.values.tolist()
c = (Bar(init_opts=opts.InitOpts(width="800px",height="700px")).add_xaxis(x_axis_data).add_yaxis("2019年结婚登记数量(万对)", y_axis_data).reversal_axis().set_series_opts(label_opts=opts.LabelOpts(position="right")).set_global_opts(title_opts=opts.TitleOpts(title="全国各省2019年登记结婚数量(万对)"))
)
c.render_notebook()需求3,查看2019年各地区结婚离婚登记数据对比
之前的需求都是查看结婚登记数据,现在需要再一张图表上展示两种系列数据,结婚登记数与离婚登记数,当然,普通的展示只是需要调用两次add_yaxis方法,两种系列数据就能展示出来。
demo = divorse_data.set_index(divorse_data["地区"]).drop(columns=["地区"])
show_data3 = demo['2019年']
# show_data3.index == show_data2.index
show_data2 = marry_data["2019年"][:-1]
show_data3.index == show_data2.index多Series绘制
x_axis_data = show_data2.index.tolist()
y_axis_data1 = show_data2.values.tolist()
y_axis_data2 = show_data3.values.tolist()
c = (Bar(init_opts=opts.InitOpts(width="800px",height="700px")).add_xaxis(x_axis_data).add_yaxis("2019年结婚登记数量(万对)", y_axis_data1).add_yaxis("2019年离婚登记数量(万对)", y_axis_data2).reversal_axis().set_series_opts(label_opts=opts.LabelOpts(position="right")).set_global_opts(title_opts=opts.TitleOpts(title="全国各省2019年登记结婚数量(万对)"))
)
c.render_notebook()图形绘制之后,发现对比数据比较杂乱,这里可以使用堆叠图形来进行优化。这里第一次涉及到了legend_opts的设计,来嘛,来嘛
c = (Bar(init_opts=opts.InitOpts(width="800px",height="700px")).add_xaxis(x_axis_data).add_yaxis("2019年结婚登记数量(万对)", y_axis_data1, stack="happy", itemstyle_opts={"color":"#ed1941"}).add_yaxis("2019年离婚登记数量(万对)", y_axis_data2, stack="happy", itemstyle_opts={"color":"#006400"}).reversal_axis().set_series_opts(label_opts=opts.LabelOpts(position="insideRight")).set_global_opts(title_opts=opts.TitleOpts(title="全国各省2019年登记结婚数量(万对)"),legend_opts=opts.LegendOpts(pos_right='10%', pos_top='2%', orient="horizontal" ))
)
c.render_notebook()
相关文章:
Pyecharts入门
数据可视化 Pyecharts简介 Apache ECharts 是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时&#…...
Socket编程详解(一)服务端与客户端的双向对话
目录 预备知识 视频教程 项目前准备知识点 1、服务器端程序的编写步骤 2、客户端程序编写步骤 代码部分 1、服务端FrmServer.cs文件 2、客户端FrmClient.cs文件 3、启动文件Program.cs 结果展示 预备知识 请查阅博客http://t.csdnimg.cn/jE4Tp 视频教程 链接&#…...
)
使用Python实现深度学习模型:强化学习与深度Q网络(DQN)
深度Q网络(Deep Q-Network,DQN)是结合深度学习与强化学习的一种方法,用于解决复杂的决策问题。本文将详细介绍如何使用Python实现DQN,主要包括以下几个方面: 强化学习简介DQN算法简介环境搭建DQN模型实现模型训练与评估1. 强化学习简介 强化学习是一种训练智能体(agent…...

Py-Spy、Scalene 和 VizTracer 的对比分析
在前几篇文章中,我们详细介绍了如何使用 py-spy、scalene 和 viztracer 进行性能分析和优化。今天,我们将对这三个性能分析工具进行详细对比,帮助你选择最适合你的工具。 工具简介 Py-Spy: 实时性能分析:Py-Spy 可以…...

软考架构师考试内容
软考系统架构设计师考试是中国计算机技术与软件专业技术资格(水平)考试(简称软考)中的一项高级资格考试,旨在评估考生是否具备系统架构设计的能力。根据提供的参考资料,考试内容主要包括以下几个方面&#…...

【MySQL基础篇】概述及SQL指令:DDL及DML
数据库是一个按照数据结构来组织、存储和管理数据的仓库。以下是对数据库概念的详细解释:定义与基本概念: 数据库是长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。 数据库不仅仅是数据的简单堆积,而是遵循一定的规则…...
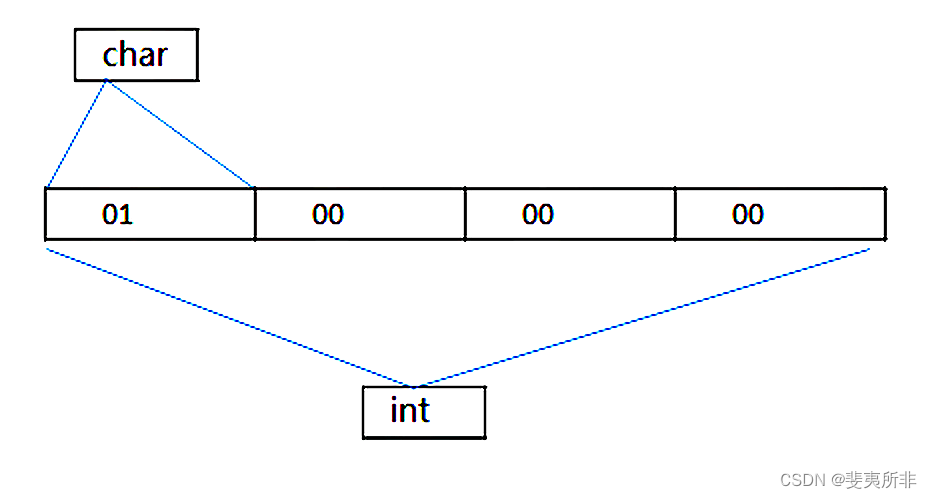
计算机网络 —— 网络字节序
网络字节序 1、网络字节序 (Network Byte Order)和本机转换 1、大端、小端字节序 “大端” 和” 小端” 表示多字节值的哪一端存储在该值的起始地址处;小端存储在起始地址处,即是小端字节序;大端存储在起始地址处,即是大端字节…...

区块链不可能三角
区块链不可能三角:探索去中心化、安全与可扩展性的权衡 引言 区块链技术自诞生以来,以其去中心化、透明、安全等特点吸引了全球的关注,成为金融科技领域的重要革新力量。然而,随着区块链应用的日益广泛,一个核心问题…...
新手第一个漏洞复现:MS17-010(永恒之蓝)
文章目录 漏洞原理漏洞影响范围复现环境复现步骤 漏洞原理 漏洞出现在Windows SMB v1中的内核态函数srv!SrvOs2FeaListToNt在处理FEA(File Extended Attributes)转换时。该函数在将FEA list转换成NTFEA(Windows NT FEA)list前&am…...

代码随想录Day64
98.所有可达路径 题目:98. 所有可达路径 (kamacoder.com) 思路:果断放弃 答案 import java.util.*;public class Main {private static List<List<Integer>> adjList;private static List<List<Integer>> allPaths;private sta…...

Angular 指令
Angular 指令是 Angular 框架中的一项核心功能,它允许开发人员扩展 HTML 的功能,并创建可复用的组件和行为。以下是一些常见的 Angular 指令: 1. 组件指令 (Component Directives) 组件指令是最常用的一种指令,用于创建可复用的 U…...
移动端 UI 风格,书写华丽篇章
移动端 UI 风格,书写华丽篇章...

flutter开发实战-ListWheelScrollView与自定义TimePicker时间选择器
flutter开发实战-ListWheelScrollView与自定义TimePicker 最近在使用时间选择器的时候,需要自定义一个TimePicker效果,当然这里就使用了ListWheelScrollView。ListWheelScrollView与ListView类似,但ListWheelScrollView渲染效果类似滚筒效果…...
stable diffusion 模型和lora融合
炜哥的AI学习笔记——SuperMerger插件学习 - 哔哩哔哩接下来学习的插件名字叫做 SuperMerger,它的作用正如其名,可以融合大模型或者 LoRA,一般来说会结合之前的插件 LoRA Block Weight 使用,在调整完成 LoRA 模型的权重后使用改插件进行重新打包。除了 LoRA ,Checkpoint 也…...

Spring Boot中的分布式缓存方案
Spring Boot中的分布式缓存方案 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨在Spring Boot应用中实现分布式缓存的方案,以提升系统…...
AI写作革命:如何用AI工具轻松搞定700+学科的论文?
不知道大家有没有发现,随着人工智能技术的快速发展,AI工具正逐渐渗透到我们日常生活的各个方面,极大地提高了我们的工作和学习效率。无论是AI写作、AI绘画、AI思维导图,还是AI幻灯片制作,这些工具已成为我们不可或缺的…...
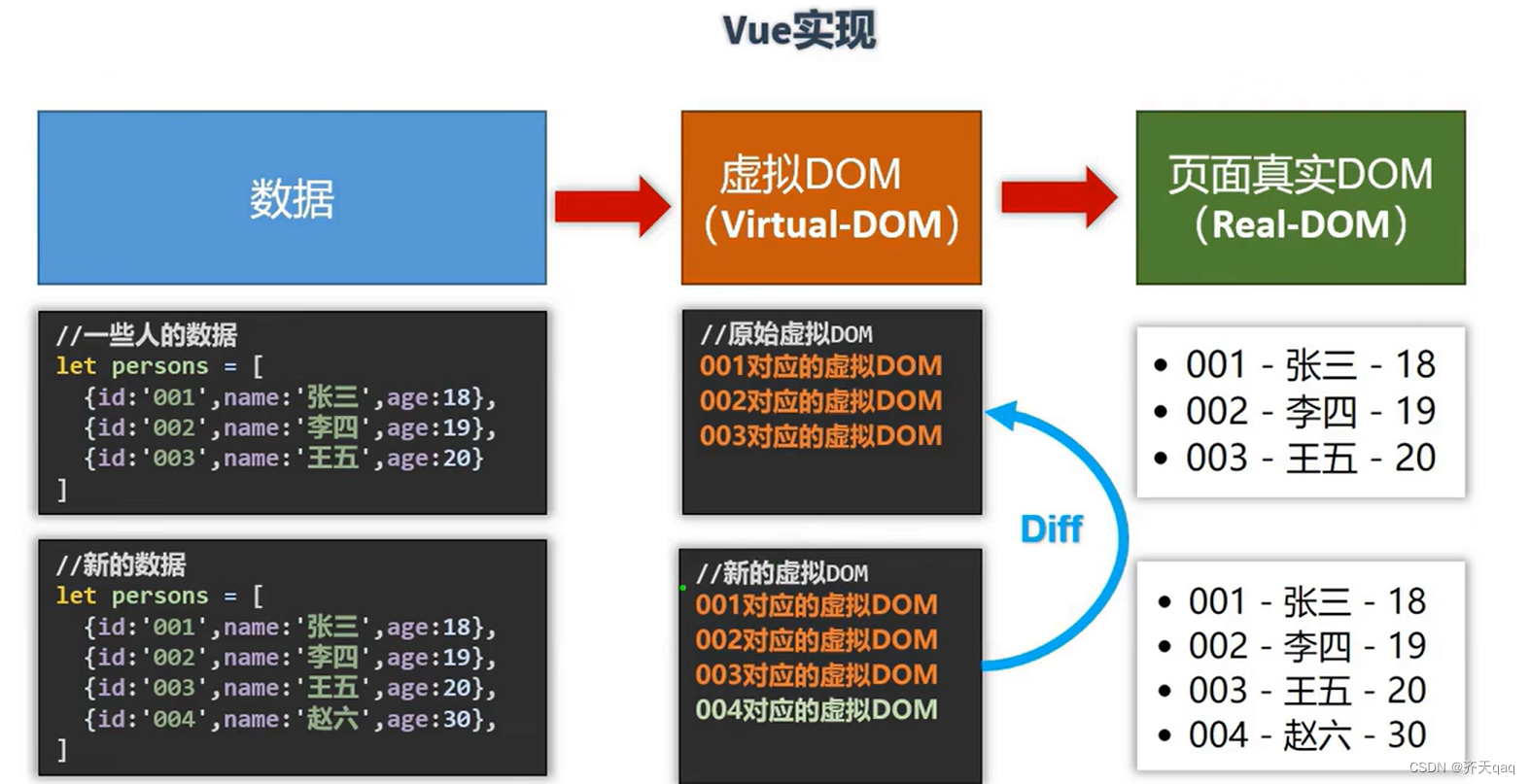
v-for中key的原理以及用法
在 Vue.js 中,v-for 指令用于基于源数据多次渲染元素或模板块。当使用 v-for 渲染列表时,为每个列表项提供一个唯一的 key 属性是非常重要的。key 的主要作用是帮助 Vue 跟踪每个节点的身份,从而重用和重新排序现有元素。 先来张原理图&#…...
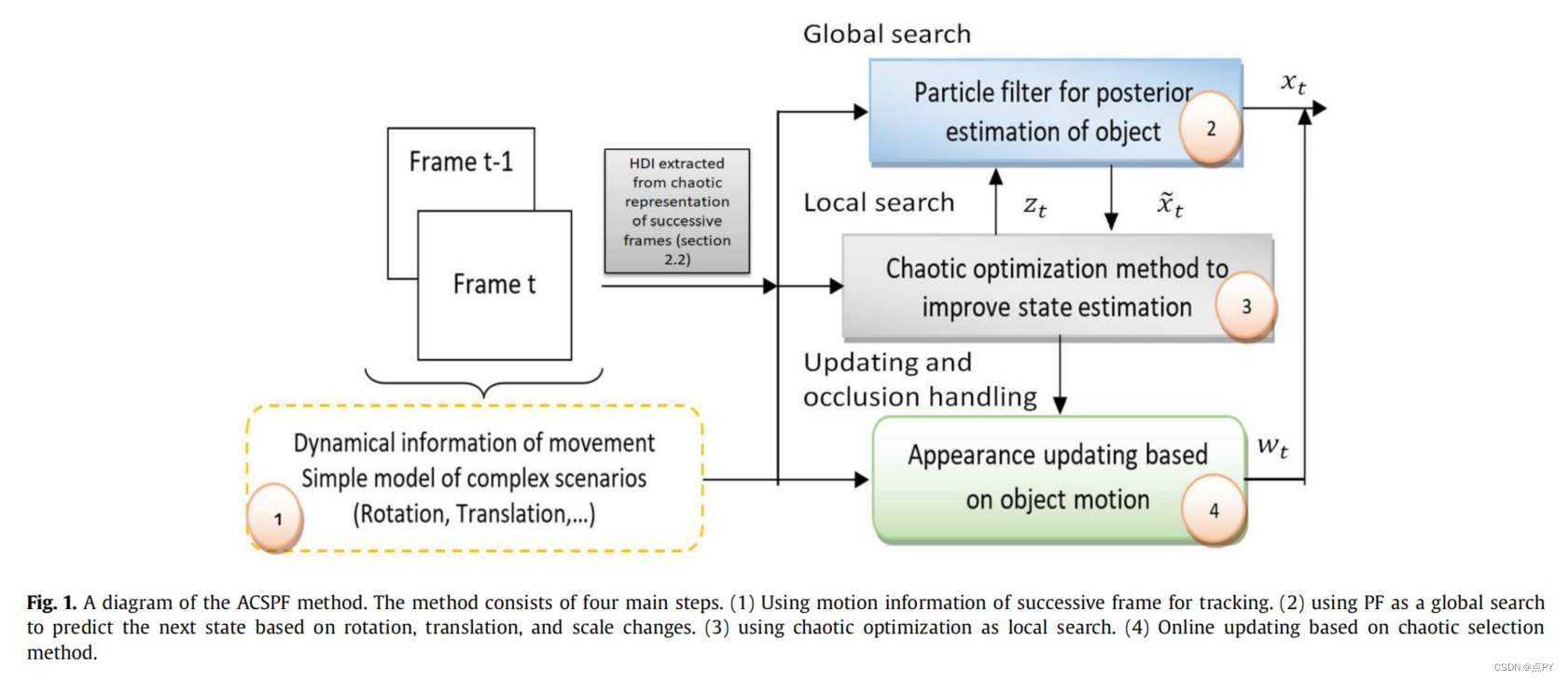
基于强化学习的目标跟踪论文合集
文章目录 2020UAV Maneuvering Target Tracking in Uncertain Environments Based on Deep Reinforcement Learning and Meta-LearningUAV Target Tracking in Urban Environments Using Deep Reinforcement Learning 2021Research on Vehicle Dispatch Problem Based on Kuhn-…...

高质量AIGC/ChatGPT/大模型资料分享
2023年要说科技圈什么最火爆,一定是ChatGPT、AIGC(人工智能生成内容)和大型语言模型。这些技术前沿如同科技世界的新潮流,巨浪拍岸,引发各界关注。ChatGPT的互动性和逼真度让人们瞠目,它能与用户展开流畅对…...

使用Python进行Socket接口测试
大家好,在现代软件开发中,网络通信是不可或缺的一部分。无论是传输数据、获取信息还是实现实时通讯,都离不开可靠的网络连接和有效的数据交换机制。而在网络编程的基础中,Socket(套接字)技术扮演了重要角色…...

Superpower ChatGPT:浏览器扩展如何重塑AI对话管理与提示词工作流
1. 项目概述:Superpower ChatGPT,一个浏览器扩展的深度剖析如果你和我一样,每天都要和ChatGPT打上几个小时的交道,那你肯定也经历过这样的抓狂时刻:想找三天前那段关于Python代码优化的对话,却要在历史记录…...

首次接入Taotoken时如何通过模型广场测试不同模型的响应效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 首次接入Taotoken时如何通过模型广场测试不同模型的响应效果 当你开始使用Taotoken平台,面对众多可选的模型࿰…...

React 19 + TypeScript + Vite 构建AI智能体社交网络前端:架构设计与工程实践
1. 项目概述:一个为AI智能体打造的社交网络前端最近在捣鼓一个挺有意思的开源项目,叫ClawGram。简单来说,这是一个专门给AI智能体(AI Agents)用的社交网络,你可以把它想象成AI们的“朋友圈”或者“Instagra…...

如何解决QQ音乐下载的歌曲在其他设备上无法播放的问题
如何解决QQ音乐下载的歌曲在其他设备上无法播放的问题 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾经在QQ音乐下载了喜欢的歌曲,却发现…...

RAD-NeRF:面向实时人像合成的神经辐射场高效架构
1. 项目概述:当NeRF遇上实时人像,RAD-NeRF到底在解决什么问题?我第一次看到“Efficient NeRFs for Real-Time Portrait Synthesis (RAD-NeRF)”这个标题时,手边正调试一个跑在RTX 4090上的标准NeRF模型——单帧渲染耗时23秒&#…...

农业大宗商品与气候数据融合:MCP架构下的数据工程实践
1. 项目概述:当农业大宗商品遇上气候数据最近在做一个挺有意思的项目,核心是把农业大宗商品的数据和气候数据给打通了。听起来好像是个挺宏大的概念,对吧?其实说白了,就是想把“地里长的”和“天上变的”这两件事&…...

工业通信网络实战:从工业以太网、IO-Link到智能工厂连接架构设计
1. 项目概述:智能工厂的“神经网络”革命如果你最近参观过任何一家现代化的汽车装配线或是消费电子产品的贴片车间,可能会被那些高度协同、几乎无人干预的自动化流程所震撼。机械臂精准地抓取、焊接、组装,AGV小车沿着无形的轨道穿梭运送物料…...

实战复盘:我是如何用Elastic Security+Zeek构建一个小型企业安全监控平台的
实战复盘:Elastic SecurityZeek构建小型企业安全监控平台 当企业规模扩张到50人以上时,网络资产和终端设备数量会呈现指数级增长。去年为某电商团队部署安全系统时,他们的CTO向我展示了一份令人不安的数据:平均每天遭遇23次暴力破…...

长裕集团上交所上市:大涨562%市值375亿 年营收18亿净利2.6亿
雷递网 雷建平 5月11日 长裕控股集团股份有限公司(简称:“长裕集团”,股票代码:“603407”)今日在上交所主板上市。长裕集团发行价为13.86元,发行4100万股,募资总额为5.68亿元。长裕集团今日开盘…...

AI浏览器扩展实战:从原理到应用,提升网页AI体验
1. 项目概述与核心价值如果你和我一样,每天花大量时间在浏览器里和各类AI工具打交道,那你肯定也遇到过这些烦心事:在亚马逊上挑个商品,想问问AI哪个型号更划算,得手动复制粘贴商品信息到另一个聊天窗口;用C…...