深度学习二分类评估详细解析与代码实战
深度学习二分类的实战代码:使用 Trainer API 微调模型. https://huggingface.co/learn/nlp-course/zh-CN/chapter3/3
如果你刚接触 自然语言处理,huggingface 是你绕不过去的坎。但是目前它已经被墙了,相信读者的实力,自行解决吧。
设置代理,如果不设置的话,那么huggingface的包无法下载;
import os
os.environ['HTTP_PROXY'] = 'http://127.0.0.1:7890'
os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
在探讨二分类问题时,经常会遇到四种基本的分类结果,它们根据样例的真实类别与分类器的预测类别来定义。以下是对这些分类结果的详细解释:
这四个定义均由两个字母组成,它们各自代表了不同的含义。
第一个字母(True/False)用于表示算法预测的正确性,而第二个字母(Positive/Negative)则用于表示算法预测的结果。
- 第1个字母(True/False):描述的是分类器是否预测正确。True表示分类器判断正确,而False则表示分类器判断错误。
- 第2个字母(Positive/Negative):表示的是分类器的预测结果。Positive代表分类器预测为正例,而Negative则代表分类器预测为负例。
- 真正例(True Positive,TP):当样例的真实类别为正例时,如果分类器也预测其为正例,那么我们就称这个样例为真正例。简而言之,真实情况与预测结果均为正例。
- 假正例(False Positive,FP):有时,分类器可能会将真实类别为负例的样例错误地预测为正例。这种情况下,我们称该样例为假正例。它代表了分类器的“过度自信”或“误报”现象。
- 假负例(False Negative,FN):与假正例相反,假负例指的是真实类别为正例的样例被分类器错误地预测为负例。这种情况下的“遗漏”或“漏报”是分类器性能评估中需要重点关注的问题。
- 真负例(True Negative,TN):当样例的真实类别和预测类别均为负例时,我们称其为真负例。这意味着分类器正确地识别了负例。
数据准备
做深度学习的同学应该都默认装了 torch,跳过 torch的安装
!pip install evaluate
导包
import torch
import random
import evaluate
随机生成二分类的预测数据 pred 和 label;
label = torch.tensor([random.choice([0, 1]) for i in range(20)])
pred = torch.tensor([random.choice([0, 1, label[i]]) for i in range(20)])
sum(label == pred)
下述是随机生成的 label 和 pred
# label
tensor([0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0])# pred
tensor([0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0])
使用 random.choice([0, 1, label[i]] 是为了提高 pred 的 准确率; 因为 label[i] 是真实的 label;
下述的是计算TP、TN、FP、FN的值:
Tips:
pred : 与第2个字母(Positive/Negative)保持一致,
label: 根据第一个字母是否预测正确,再判断填什么
TP = sum((label == 1) & (pred == 1))
TN = sum((label == 0) & (pred == 0))
FP = sum((label == 0) & (pred == 1))
FN = sum((label == 1) & (pred == 0))
| 标签 | Value |
|---|---|
| TP | 6 |
| TN | 8 |
| FP | 2 |
| FN | 4 |
准确率 Accuracy
准确率(Accuracy): 分母通常指的是所有样本的数量,即包括真正例(True Positives, TP)、假正例(False Positives, FP)、假负例(False Negatives, FN)和真负例(True Negatives, TN)的总和。而分子中的第一个字母为“T”(True),意味着我们计算的是算法预测正确的样本数量,即TP和TN的总和。
然而,准确率作为一个评价指标存在一个显著的缺陷,那就是它对数据样本的均衡性非常敏感。当数据集中的正负样本数量存在严重不均衡时,准确率往往不能准确地反映模型的性能优劣。
例如,假设有一个测试集,其中包含90%正样本和仅10%负样本。若模型将所有样本都预测为正样本,那么它的准确率将轻松达到90%。从准确率这一指标来看,模型似乎表现得非常好。但实际上,这个模型对于负样本的预测能力几乎为零。
因此,在处理样本不均衡的问题时,需要采用其他更合适的评价指标,如精确度(Precision)、召回率(Recall)、F1分数(F1 Score)等,来更全面地评估模型的性能。这些指标能够更准确地反映模型在各类样本上的预测能力,从而帮助我们做出更准确的决策。
精准率的公式如下:
A c c u r a c y = T P + T N T P + T N + F P + F N = T P + T N 所有样本数 Accuracy = \frac{TP + TN}{TP + TN + FP +FN} = \frac{TP + TN}{所有样本数} Accuracy=TP+TN+FP+FNTP+TN=所有样本数TP+TN
accuracy = evaluate.load("accuracy")
accuracy.compute(predictions=pred, references=label)
Output:
{'accuracy': 0.7}
下述三种方法都可以用来计算 accuracy:
print((TP + TN) / (TP + TN + FP +FN),(TP + TN) / len(label),sum((label == pred)) / 20
)
Output:
tensor(0.7000) tensor(0.7000) tensor(0.7000)
使用公式计算出来的与通过evaluate库,算出来的结果一致,都是 0.7。
precision 精准率
P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP + FP} Precision=TP+FPTP
precision = evaluate.load("precision")
precision.compute(predictions=pred, references=label)
Output:
{'precision': 0.75}
TP / (TP + FP)
recall 召回率
R e c a l l = T P T P + F N Recall = \frac{TP}{TP + FN} Recall=TP+FNTP
recall = evaluate.load("recall")
recall.compute(predictions=pred, references=label)
Output:
{'recall': 0.6}
TP / (TP + FN)
F1
f1 = evaluate.load("f1")
f1.compute(predictions=pred, references=label)
Output:
{'f1': 0.6666666666666666}
F 1 = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l F1 = \frac{2 \times {Precision} \times {Recall}}{{Precision} + {Recall}} F1=Precision+Recall2×Precision×Recall
2 * 0.7500 * 0.6000 / (0.7500 + 0.6000)
Output:
0.6666666666666665
希望这篇文章,通过代码实战,能够帮到你加深印象与理解!概念说再多遍,不如代码实现一遍。
参考资料
- 如何在python代码中使用代理下载Hungging face模型. https://www.jianshu.com/p/209528bed023
- [机器学习] 二分类模型评估指标—精确率Precision、召回率Recall、ROC|AUC. https://blog.csdn.net/zwqjoy/article/details/78793162
- 使用 Trainer API 微调模型. https://huggingface.co/learn/nlp-course/zh-CN/chapter3/3
- Huggingface Evaluate 文档. https://huggingface.co/docs/evaluate/index
相关文章:

深度学习二分类评估详细解析与代码实战
深度学习二分类的实战代码:使用 Trainer API 微调模型. https://huggingface.co/learn/nlp-course/zh-CN/chapter3/3 如果你刚接触 自然语言处理,huggingface 是你绕不过去的坎。但是目前它已经被墙了,相信读者的实力,自行解决吧。…...

c++笔记容器详细介绍
C标准库提供了多种容器来存储和管理数据。这些容器属于<vector>, <list>, <deque>, <map>, <set>, <unordered_map>, <unordered_set>等头文件中。这些容器各有优缺点,适用于不同的场景。下面详细介绍几种主要的容器及其…...
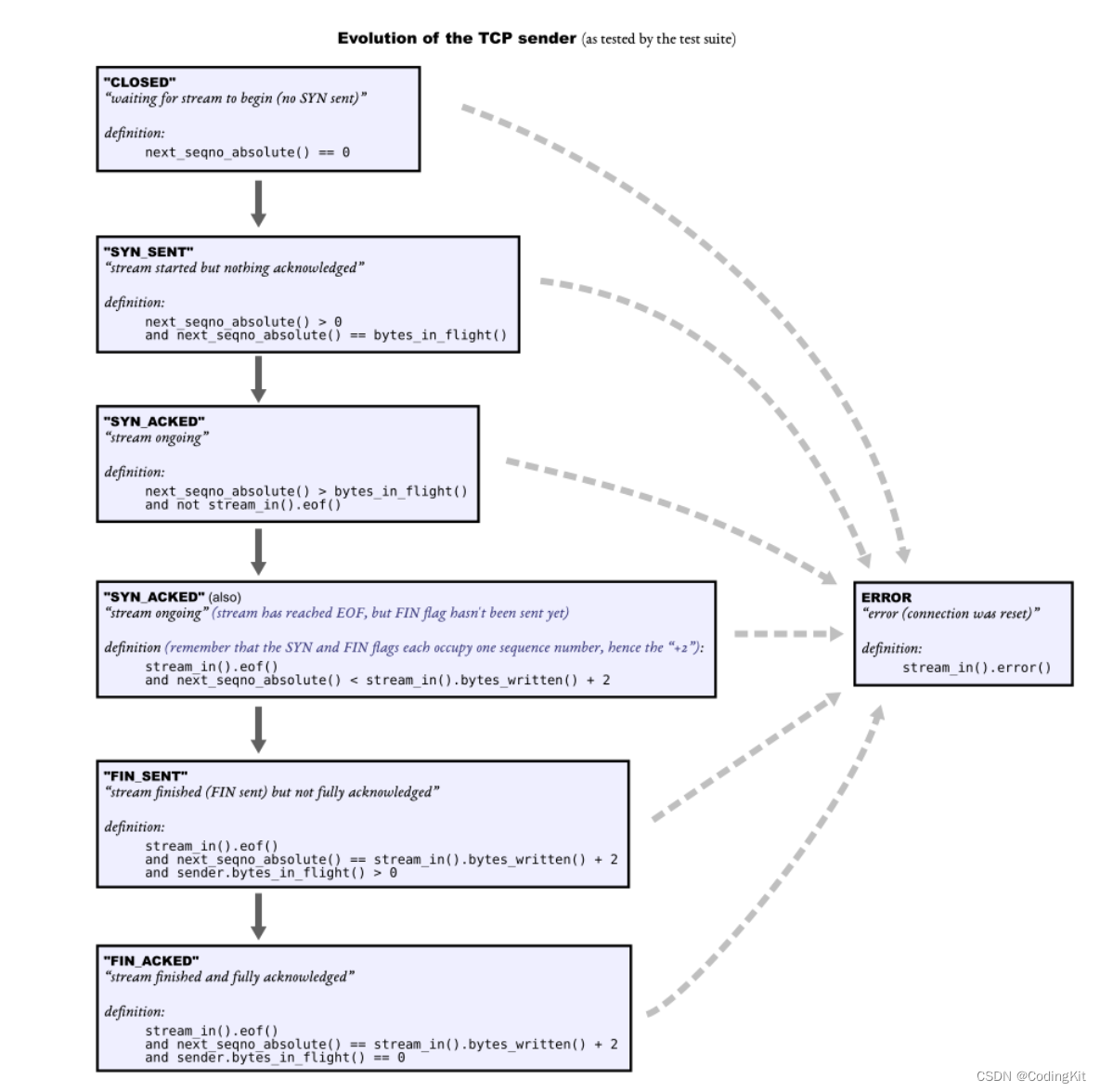
CS144 Lab3 TCPSender复盘
一.基础概念 1.TCPSender在TCPSocket中的地位与作用 Lab0中实现了基于内存模拟的流控制-字节流(ByteStream),底层使用std::deque实现,根据最大容量Capacity进行容量控制。个人理解它相当于应用层的输入输出缓存区,用户…...

建筑可视化中使用云渲染的几大理由
在建筑行业中,可视化技术已成为不可或缺的一部分。无论是设计方案的展示、施工进度的模拟,还是最终效果的呈现,建筑可视化都发挥着至关重要的作用。 建筑可视化是指通过计算机技术和图形学算法,将建筑设计、规划和施工过程中的数据…...

Python数据可视化-地图可视化
1.首先绘制实现数据可视化的思维导图 具体要实现什么功能-怎么处理,先把思路写好 数据来源: 爬取的数据 运行结果: 部分代码: 完整代码请在下方↓↓↓👇获取 转载请注明出处!...

leetcode 动态规划(基础版)单词拆分
题目: 题解: 一种可行的dp做法是基于完全背包问题,将s看成是一个背包,wordDict看作是物品,然后往s中放入物品判断最终是否可以变为给定的s即可。这道题和上一题都用到了在dp如何枚举连续子串和状态表示:枚…...
Ubuntu/Linux调试安装南京来可CAN卡
准备好USB rules文件和can driver文件备用! 必做:放置USB rules文件到对应位置处理权限问题 而后:安装内核driver并编译。需求众多依赖编译环境,视情况安装填补。如GCC,G,make等等 进入对应64bit文件夹中,添加权限,执…...

vue2+TS获取到数据后自动叫号写法
1.父组件写法 初始化: //引入子组件 <odialog ref"odialogRef" onSure"onSurea"></odialog> //子传父private onSurea() {// 初始化信息/重新叫号来的数据this.initTabelData()setTimeout(() > {// 播放声音的数据this.search…...

28、架构-边界:微服务的粒度
微服务的粒度 在设计微服务架构时,确定微服务的粒度是一个关键问题。粒度过大或过小都会带来不同的问题,因此需要找到合理的粒度来划分微服务。下面详细探讨微服务粒度的合理范围及其影响因素。 1. 微服务粒度的上下界 微服务的粒度不应该只有唯一正确…...
开源API网关-ApacheShenYu首次按照启动遇到的问题
一.背景 公司有API网关产品需求,希望有图形化的后台管理功能。看到了ApacheShenYu,作为Apache的顶级项目,直接认可了。首先,感谢各位大神的付出,初步看这个项目是国内大厂中的大神创立的,在此表示膜拜&…...
uniapp获取证书秘钥、Android App备案获取公钥、签名MD5值
一、 uniapp获取证书秘钥 打开uniapp开发者中心下载证书打开cmd输入以下这段代码,下载提供查看到的密钥证书密码就可以了!下载证书在 java 环境下运行才可以 // your_alias 换成 证书详情中的别名,your_keystore.keystore 改成自己的证书文件…...
)
QT 如何储存多种数据类型(QVariant )
QVariant 是 Qt 框架中用于存储各种数据类型的类。它提供了一个强大的类型系统,允许你在运行时存储和检索多种类型的数据,而不需要在编译时确定类型。QVariant 的主要优点在于它的灵活性和通用性,这使得它在 Qt 的很多组件和机制中都被广泛使…...
)
持续总结中!2024年面试必问的操作系统面试题(九)
上一篇地址:持续总结中!2024年面试必问的操作系统面试题(八)-CSDN博客 十七、解释什么是操作系统的安全性和它的重要性。 操作系统的安全性(Operating System Security)是指操作系统采取的一系列措施来保…...

操作系统入门 -- 文件管理
操作系统入门 – 文件管理 1.文件管理概述 1.1 文件系统基本功能 目前,计算机内存的容量依然有限,并且其特性决定了数据无法长时间保存,因此把执行的数据以文件形式保存在外存中,等到需要使用时再调入内存。所以,操…...
)
由浅入深,走进深度学习(2)
今天分享的学习内容主要就是神经网络里面的知识啦,用到的框架就是torch 在这里我也是对自己做一个学习记录,如果不符合大家的口味,大家划走就可以啦 可能没有什么文字或者原理上的讲解,基本上都是代码,但是我还是想说…...
【Python Tips】创建自己的函数包并安装进Anaconda,像引入标准包一样直接import导入
目录 一、引言 二、方法步骤 步骤一:创建包目录结构 步骤二:配置__init__.py文件 步骤三:文件夹外配置setup.py文件 步骤四:终端Pip安装 三、结尾 一、引言 在编写项目代码的时候,有些自定义功能的函数是可以复用的。…...

【Python机器学习实战】 | 基于支持向量机(Support Vector Machine, SVM)进行分类和回归任务分析
🎩 欢迎来到技术探索的奇幻世界👨💻 📜 个人主页:一伦明悦-CSDN博客 ✍🏻 作者简介: C软件开发、Python机器学习爱好者 🗣️ 互动与支持:💬评论 &…...

备份和还原
stai和dnta snat:源地址转换 内网---外网 内网ip转换成可以访问外网的ip 内网的多个主机可以使用一个有效的公网ip地址访问外部网络 DNAT:目的地址转发 外部用户,可以通过一个公网地址访问服务内部的私网服务。 私网的ip和公网ip做一个…...

Java数组的初始化方法
Java数组的初始化方法 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!在Java编程中,数组是一种非常基础也非常重要的数据结构,它能够存储…...

通过分离有色和无色pdf页面减少打印费
前言 该工具是我认识的一位中科大的大佬在本科毕业的时候做的一个小工具,去打印店打印全彩的毕业论文的话会比较贵,他想到有没有一种方案可以实现有彩色页面的pdf和没有彩色页面的pdf分开打印,前者打印彩色,后者打印黑白…...

Orama混合搜索实战:从全文检索到向量搜索的轻量级实现
1. 项目概述:从“全文搜索”到“向量搜索”的现代演进如果你做过Web开发,尤其是需要处理大量文本内容的应用,比如博客站、文档中心或者电商平台,那么“搜索”功能绝对是你绕不开的核心需求。传统上,我们可能会直接想到…...

Sonos语音控制功能大揭秘:常用指令、局限与第三方助手对比
ZDNET核心要点Sonos音箱内置语音助手,其语音控制虽不如其他助手智能,但并非一无是处,每日闹钟、天气预报和定时器能提升使用体验。Sonos语音控制使用体验并非智能家居爱好者,但家里有好几台Sonos智能音箱。虽不太喜欢自动语音助手…...

3个真实问题告诉你:DdddOcr如何成为你的免费离线验证码识别助手
3个真实问题告诉你:DdddOcr如何成为你的免费离线验证码识别助手 【免费下载链接】ddddocr 带带弟弟 通用验证码识别OCR pypi版 项目地址: https://gitcode.com/gh_mirrors/dd/ddddocr 当你在自动化测试、数据采集或系统集成中遇到验证码时,是否曾…...

CV论文工业落地避坑指南:从复现到部署的四大过滤维度
1. 这不是论文清单,而是一份“CV研究者晨间速读指南” 如果你每天打开arXiv、CVPR官网或Twitter刷到一堆标题带“Vision Transformer”“Diffusion”“Multimodal Alignment”的新论文,却总在摘要第一句就卡住——“We propose a novel hierarchical tok…...

为AI编程助手构建持久化项目记忆库:告别上下文遗忘,提升团队协作效率
1. 项目概述:为AI编程助手构建持久化项目记忆库如果你和我一样,每天都要和Claude Code、Cursor这些AI编程助手打交道,肯定遇到过这个烦人的问题:每次新开一个对话,AI就像得了失忆症,完全不记得你刚才在做什…...

从仿真结果到科研图表:手把手教你用Tonyplot处理Silvaco TCAD数据
从仿真结果到科研图表:手把手教你用Tonyplot处理Silvaco TCAD数据 在半导体器件研究中,TCAD仿真数据的可视化呈现往往决定着研究成果的传达效果。许多研究者花费大量时间完成Silvaco仿真后,却苦于无法将原始数据转化为符合学术出版要求的专业…...

别再搞混了!改进DH与标准DH参数在IRB1200建模中的关键差异与选择
别再搞混了!改进DH与标准DH参数在IRB1200建模中的关键差异与选择 当你在为ABB IRB1200这类六轴工业机器人构建运动学模型时,是否曾被两种不同的DH参数表示法困扰?标准DH(Denavit-Hartenberg)和改进DH(Modif…...

如何快速掌握歌词滚动姬:新手到专家的5个终极秘籍
如何快速掌握歌词滚动姬:新手到专家的5个终极秘籍 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 还在为音乐配上精准的LRC歌词而烦恼吗?歌词…...
)
别再死记公式了!用Python的NumPy和Matplotlib玩转坐标转换(附象限处理代码)
用Python实战坐标转换:从数学公式到可视化应用 坐标转换是计算机图形学、机器人学和数据可视化中的基础操作。传统教学中,我们往往被要求死记硬背转换公式,却很少有机会直观理解其实际应用场景。本文将带你用NumPy和Matplotlib这两个Python利…...

WaveTools终极指南:免费解锁鸣潮120FPS帧率限制的完整方案
WaveTools终极指南:免费解锁鸣潮120FPS帧率限制的完整方案 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools WaveTools是一款专为《鸣潮》PC版设计的开源工具箱,通过创新技术方案帮助…...