【深度学习】记录为什么没有调用GPU
排查CLIP为什么评测推理没有调用GPU,主要是这个代码:https://github.com/OFA-Sys/Chinese-CLIP/blob/master/cn_clip/eval/extract_features.py
第一次认为:因为model并没有to.cuda()。
但是又发现,model.cuda(args.gpu) # 已经加载到GPU上了。
并且,pytorch中 model.cuda() 和mode.to(cuda) 没有区别。
第二次,还是在P40上启动一下,使用nvidia-smi看看GPU是否被使用了。
以下from GPT-4o,
在使用图像模型提取图片特征时,GPU利用率为0可能是由于多种原因导致的。以下是一些常见的原因和解决方法:
1. 确认使用了GPU
确保你的代码实际上是使用了GPU而不是CPU。以下是一些检查和设置GPU使用的步骤:
-
TensorFlow:
import tensorflow as tf print("Num GPUs Available: ", len(tf.config.list_physical_devices('GPU'))) -
PyTorch:
import torch print("Is CUDA available: ", torch.cuda.is_available())
2. 确认GPU驱动和CUDA版本
确保你安装了正确版本的GPU驱动和CUDA工具包,并且它们与所使用的深度学习框架兼容。
-
检查CUDA版本:
nvcc --version -
检查驱动版本:
nvidia-smi
3. 确认模型和数据在GPU上
确保你的模型和数据都被正确地加载到GPU上。
-
TensorFlow:
with tf.device('/GPU:0'):# Your model and data operations -
PyTorch:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model.to(device) inputs = inputs.to(device)
4. 检查批处理大小
如果批处理大小(batch size)太小,GPU利用率可能会很低。尝试增加批处理大小以更好地利用GPU。
5. 确认数据加载器的效率
数据加载器可能成为瓶颈,导致GPU等待数据。确保数据加载器使用了多线程或多进程来加速数据加载。
-
TensorFlow:
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE) -
PyTorch:
data_loader = torch.utils.data.DataLoader(dataset, batch_size=32, num_workers=4, pin_memory=True)
6. 确认模型推理代码
确保你在进行特征提取时,模型推理代码没有问题,并且确实在GPU上运行。
7. 确认没有GPU内存不足
如果GPU内存不足,可能会导致程序回退到CPU。使用nvidia-smi查看GPU内存使用情况。
8. 确认GPU没有被其他进程占用
使用nvidia-smi查看当前GPU的使用情况,确保没有其他进程占用GPU资源。
9. 检查框架和库的版本
确保你使用的深度学习框架和相关库是最新版本,因为旧版本可能存在性能问题或不支持某些功能。
10. 检查代码逻辑
确保你的代码逻辑没有问题,特别是数据预处理和模型推理部分。
示例代码
以下是一个简单的示例代码,展示了如何在PyTorch中确保模型和数据在GPU上运行:
import torch
import torchvision.models as models
from torchvision import transforms
from PIL import Image# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加载预训练模型并将其移动到GPU
model = models.resnet50(pretrained=True)
model = model.to(device)
model.eval()# 加载并预处理图像
image = Image.open("path_to_image.jpg")
preprocess = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(image)
input_batch = input_tensor.unsqueeze(0) # 创建一个批次# 将输入数据移动到GPU
input_batch = input_batch.to(device)# 确保模型在GPU上进行推理
with torch.no_grad():output = model(input_batch)# 提取特征
features = output.cpu().numpy()
print(features)
通过上述步骤和检查,你应该能够找到GPU利用率为0的原因并解决问题。
相关文章:

【深度学习】记录为什么没有调用GPU
排查CLIP为什么评测推理没有调用GPU,主要是这个代码:https://github.com/OFA-Sys/Chinese-CLIP/blob/master/cn_clip/eval/extract_features.py 第一次认为:因为model并没有to.cuda()。 但是又发现,model.cuda(args.gpu) # 已经加…...

vite 创建vue3项目 集成 ESLint、Prettier、Sass等
在网上找了一大堆vue3脚手架的东西,无非就是vite或者vue-cli,在vue2时代,vue-cli用的人挺多的,也很好用,然而vue3大多是和vite搭配搭建的,而且个人感觉vite这个脚手架并没有那么的好用,搭建项目时只能做两个…...

计算机系统基础知识(上)
目录 计算机系统的概述 计算机的硬件 处理器 存储器 总线 接口 外部设备 计算机的软件 操作系统 数据库 文件系统 计算机系统的概述 如图所示计算机系统分为软件和硬件:硬件包括:输入输出设备、存储器,处理器 软件则包括系统软件和…...

[深度学习]循环神经网络RNN
RNN(Recurrent Neural Network,即循环神经网络)是一类用于处理序列数据的神经网络,广泛应用于自然语言处理(NLP)、时间序列预测、语音识别等领域。与传统的前馈神经网络不同,RNN具有循环结构&am…...

【C++:list】
list概念 list是一个带头的双向循环链表,双向循环链表的特色:每一个节点拥有两 个指针进行维护,俩指针分别为prev和next,prev指该节点的前一个节点,next为该节点的后一个节点 list的底层实现中为什么对迭代器单独写一个结构体进行…...

解锁 Apple M1/M2 上的深度学习力量:安装 TensorFlow 完全指南
前言 随着 Apple M1 和 M2 芯片的问世,苹果重新定义了笔记本电脑和台式机的性能标准。这些强大的芯片不仅适用于日常任务,还能处理复杂的机器学习和深度学习工作负载。本文将详细介绍如何在 Apple M1 或 M2 芯片上安装和配置 TensorFlow,助你…...

Apache Iceberg:现代数据湖存储格式的未来
Apache Iceberg 是一个开源的表格式,用于在分布式数据湖中管理大规模数据集。它由 Netflix 开发,并捐赠给 Apache 基金会。Iceberg 的设计目标是解决传统数据湖存储格式(如 Apache Hive 和 Apache Parquet)在大规模数据管理中的一…...

【离散数学·图论】(复习)
一、基本概念 1.一些基本术语: 2.点u,v邻接(或相邻): 边e称为关联顶点u和v,or e连接u和v; 3.G(V,E)中,顶点v所有邻居的集合:N(v), 成为v的邻域。 4.度 : deg(v) 5.悬挂点:度为1的…...

【ONLYOFFICE震撼8.1】ONLYOFFICE8.1版本桌面编辑器测评
随着远程工作的普及和数字化办公的发展,越来越多的人开始寻找一款具有强大功能和便捷使用的办公软件。在这个时候,ONLYOFFICE 8.1应运而生,成为了许多用户的新选择。ONLYOFFICE 8.1是一种办公套件软件,它提供了文档处理、电子表格…...

Shell 脚本编程保姆级教程(上)
一、运行第一个 Shell 脚本 1.1 Shell 脚本 Shell 脚本(shell script),是一种为 shell 编写的脚本程序。 业界所说的 shell 通常都是指 shell 脚本,但读者朋友要知道,shell 和 shell script 是两个不同的概念。 由…...

凸优化相关文章汇总
深度学习/机器学习入门基础数学知识整理(三):凸优化,Hessian,牛顿法_深度学习和凸优化-CSDN博客 深度学习/机器学习入门基础数学知识整理(四):拟牛顿法、BFGS、L-BFGS、DFP、共轭梯…...
Java鲜花下单预约系统源码小程序源码
让美好触手可及 🌸一、开启鲜花新篇章 在繁忙的都市生活中,我们总是渴望那一抹清新与美好。鲜花,作为大自然的馈赠,总能给我们带来无尽的惊喜与愉悦。但你是否曾因为工作繁忙、时间紧张而错过了亲自挑选鲜花的机会?今…...

网络变压器和RJ45接线的方法
网络变压器在以太网硬件电路设计中扮演着重要的角色,它主要用于信号电平耦合、隔离外部干扰、实现阻抗匹配以及增加传输距离。而RJ45接口则是以太网连接的标准化接口,它提供了与网络电缆的连接点。 网络变压器与RJ45的接线方法通常遵循以下步骤…...

Matlab/simulink三段式电流保护
电流1段仿真波形如下所示 电流2段仿真波形如下所示 电流3段仿真波形如下所示...

OOXML入门学习
进入-飞入 <par> <!-- 这是一个并行动画序列的开始。"par"代表并行,意味着在这个标签内的所有动画将同时开始。 --><cTn id"5" presetID"2" presetClass"entr" presetSubtype"4" fill"hold&…...

k8s集群node节点加入失败
出现这种情况: [preflight] FYI: You can look at this config file with kubectl -n kube-system get cm kubeadm-config -o yaml [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kub…...

layui+jsp项目中实现table单元格嵌入下拉选择框功能,下拉选择框可手动输入内容或选择默认值,修改后数据正常回显。
需求 table列表中的数据实现下拉框修改数据,当默认的下拉框不符合要求时,可手动输入内容保存。内容修改后表格显示修改后的值同时表格不刷新。 实现 layui框架下拉框组件只能选择存在的数据,不支持将输入的内容显示在input中的功能&#x…...

2024年客户体验的几个预测
数字化转型、以客户为中心的理念、数字技术的发展和产品的不断创新,都为客户体验带来了巨大的改变。 目前,我们看到很多公司都在致力于塑造一种以客户为中心的商业模式。企业开始用更多技术、更多数据和更多产品来强化自己在客户体验方面的能力。 那么&a…...
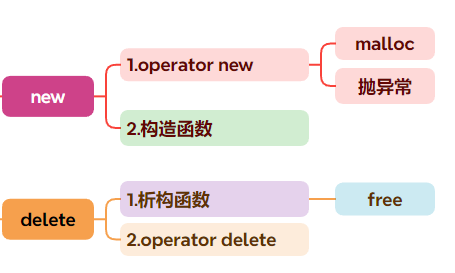
【C++】动态内存管理new和delete
文章目录 一、C的内存管理方式二、new和delete的用法1.操作内置类型2.操作自定义内置类型 三、new和delete的底层实现1.operator new和operator delete函数2.new和delete的实现原理 四、定位new表达式五、malloc/free和new/delete的区别 一、C的内存管理方式 之前在C语言的动态…...
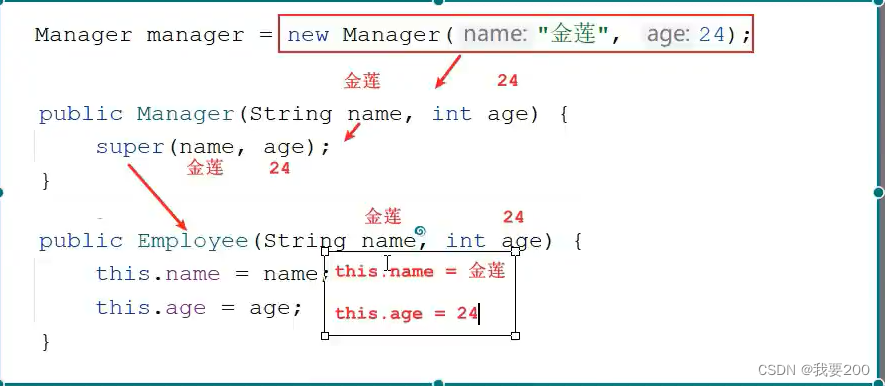
Java面向对象特性
Java继承: 继承的概念: 在Java中,继承(inheritance)是面向对象编程的一个重要概念,它允许一个类(子类)继承另一个类(父类)的属性和方法。通过继承,…...

喜马拉雅音频下载器:三分钟学会批量保存心爱内容
喜马拉雅音频下载器:三分钟学会批量保存心爱内容 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-qt5 在数字音频内容日益丰…...

如何通过 Pretty TypeScript Errors 提升开发效率:下载量激增背后的成功秘诀 [特殊字符]
如何通过 Pretty TypeScript Errors 提升开发效率:下载量激增背后的成功秘诀 🔥 【免费下载链接】pretty-ts-errors 🔵 Make TypeScript errors prettier and human-readable in VSCode 🎀 项目地址: https://gitcode.com/gh_mi…...

3分钟快速搞定Windows苹果设备驱动安装:Apple-Mobile-Drivers-Installer终极指南
3分钟快速搞定Windows苹果设备驱动安装:Apple-Mobile-Drivers-Installer终极指南 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: h…...

深度解析Layui formSelects:现代Web应用中的多选下拉框终极解决方案
深度解析Layui formSelects:现代Web应用中的多选下拉框终极解决方案 【免费下载链接】layui-formSelects Layui select多选小插件 项目地址: https://gitcode.com/gh_mirrors/la/layui-formSelects 在当今的Web开发领域,表单交互体验直接影响着用…...

Unity项目瘦身实战:彻底搞懂Library文件夹,轻松清理几十个G的缓存
Unity项目瘦身实战:彻底搞懂Library文件夹,轻松清理几十个G的缓存 当你打开资源管理器,发现Unity项目的Library文件夹已经吞噬了50GB磁盘空间时,那种窒息感就像发现衣柜里塞满了十年没穿过的旧衣服。这个隐藏在项目根目录下的&quo…...

MiGPT终极指南:如何将小爱音箱改造成AI语音助手
MiGPT终极指南:如何将小爱音箱改造成AI语音助手 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 在智能家居日益普及的今天࿰…...

ScrollNice:用虚拟滚动区域替代鼠标滚轮的Windows效率工具
1. 项目概述:当鼠标滚轮失灵时,我们如何优雅地“滚动”?作为一名长期与代码和文档打交道的开发者,我深知一个顺手的鼠标滚轮有多重要。但现实往往很骨感——无论是用了多年的老鼠标滚轮开始“打滑”,还是在某些需要单手…...

自动化规则同步:从设计原理到Go/Python实战实现
1. 项目概述:一个自动化同步规则的“守门人”在运维和网络安全领域,我们每天都在和各种规则打交道:防火墙规则、入侵检测规则、内容过滤规则……这些规则是保障系统安全、优化网络流量的核心防线。然而,随着业务扩展和多环境部署&…...

从零学会基础算法前缀和差分:数组区间求和离散化基础
首先祝大家劳动节快乐!开学两个月来学的东西不多,主要掌握了两块内容:前缀和/差分/离散化 和 数学基础。本文是第一篇,重点整理前缀和相关内容。 编程语言:C 排版助手:AI一、数组的三个简化技巧 1. 前缀和 …...

5分钟快速上手:用FanControl打造你的Windows电脑静音散热系统
5分钟快速上手:用FanControl打造你的Windows电脑静音散热系统 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tren…...