Spark基于DPU的Native引擎算子卸载方案
1.背景介绍
Apache Spark(以下简称Spark)是一个开源的分布式计算框架,由UC Berkeley AMP Lab开发,可用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。Spark 使用内存加载保存数据并进行迭代计算,减少磁盘溢写,同时支持 Java、Scala、Python 和 R 等多种高级编程语言,这使得Spark可以应对各种复杂的大数据应用场景,例如金融、电商、社交媒体等。
Spark 经过多年发展,作为基础的计算框架,不管是在稳定性还是可扩展性方面,以及生态建设都得到了业界广泛认可。尽管Apache社区对Spark逐步引入了诸如钨丝计划、向量化 Parquet Reader 等一系列优化,整体的计算性能也有两倍左右的提升,但在 3.0 版本以后,整体计算性能的提升有所减缓,并且随着存储、网络以及IO技术的提升,CPU也逐渐成为Spark计算性能的瓶颈。如何在Spark现有框架上,增强大数据计算能力,提高CPU利用率,成为近年来业界的研究方向。
2.开源优化方案
Spark本身使用scala语言编写,整体架构基于 JVM 开发,只能利用到一些比较基础的 CPU 指令集。虽然有JIT的加持,但相比目前市面上的Native向量化计算引擎而言,性能还是有较大差距。因此考虑如何将具有高性能计算能力的Native向量引擎引用到 Spark 里来,提升 Spark 的计算性能,突破 CPU 瓶颈,成为一种可行性较高的解决方案。
随着Meta在2022年超大型数据库国际会议(VLDB)上发表论文《Velox:Meta's Unified Execution Engine》,并且Intel创建的Gluten项目基于Apache Arrow数据格式和Substrait查询计划的JNI API将Spark JVM和执行引擎解耦,从而将Velox集成到Spark中,这使得使用Spark框架+Native向量引擎的大数据加速方案成为现实。
3.DPU计算卡与软件开发平台
AI大模型的发展,金融、电商等领域数据处理需求的增加,生活应用虚拟化程度的加深,都对现代化数据中心提出严峻的考验。未来数据中心的发展趋势,逐步演变成CPU + DPU + GPU三足鼎立的情况,CPU用于通用计算,GPU用于加速计算,DPU则进行数据处理。将大数据计算卸载到具有高度定制化和数据处理优化架构的大规模数据计算DPU卡上,可以有效提高计算密集型应用场景下数据中心的性能和效率,降低其成本和能耗。
中科驭数CONFLUX®-2200D 大数据计算DPU卡主要应用于大数据计算场景。CONFLUX®-2200D通过计算DPU卸载加速,存储DPU卸载加速和网络DPU卸载加速实现大数据计算性能3-6倍提升。CONFLUX®-2200D是基于中科驭数自主知识产权的KPU(Kernel Processing Unit)架构、DOE(Data Offloading Engine)硬件数据库运算卸载引擎和LightningDMA中科驭数自主知识产权的基于DMA的直接内存写入技术提出的领域专用DPU卡。能够满足无侵入适配、自主可控、安全可靠,支持存算一体、存算分离等不同场景。
中科驭数HADOS是中科驭数推出的专用计算敏捷异构软件开发平台。HADOS®数据查询加速库通过提供基于列式数据的查询接口,供数据查询应用,目前Spark、PostgreSQL已通过插件的形式适配。支持Java、Scala、C和C++语言的函数调用,主要包括列数据管理、数据查询运行时函数、任务调度引擎、函数运算代价评估、内存管理、存储管理、硬件管理、DMA引擎、日志引擎等模块,目前对外提供数据管理、查询函数、硬件管理、文件存储相关功能API。
4.Spark框架+Gluten-Velox向量化执行引擎+DPU加速卡
4.1方案简介
随着SSD和万兆网卡普及以及I/O技术的提升,Spark用户的数据负载计算能力逐渐受到CPU性能瓶颈的约束。由于Spark本身基于JVM的Task计算模型的CPU指令优化,要远远逊色于其他的Native语言(C++等),再加上开源社区的Native引擎已经发展得比较成熟,具备优秀的量化执行能力,这就使得那些现有的Spark用户,如果想要获得这些高性能计算能力就需要付出大量的迁移和运维成本。
Gluten解决了这一关键性问题,让Spark用户无需迁移,就能享受这些成熟的Native引擎带来的性能优势。Gluten最核心的能力就是通过Spark Plugin的机制,把Spark查询计划拦截并下发给Native引擎来执行,跳过原生Spark不高效的执行路径。整体的执行框架仍沿用Spark既有实现,并且对于Native引擎无法承接的算子,Gluten安排Fallback回正常的Spark执行路径进行计算,从而保证Spark任务执行的稳定性。同时Gluten还实现了Fallback、本地内存管理等功能,使得Spark可以更好利用Native引擎带来的高性能计算能力。
Velox是一个集合了现有各种计算引擎优化的新颖的C++数据加速库,其重新设计了数据模型以支持复杂数据类型的高效计算,并且提供可重用、可扩展、高性能且与上层软件无关的数据处理组件,用于构建执行引擎和增强数据管理系统。
由于Velox只接收完全优化的查询计划作为输入,不提供 SQL 解析器、dataframe层、其他 DSL 或全局查询优化器,专注于成为大数据计算的执行引擎。这就使得Gluten+Velox架构可以各司其职,从而实现数据库组件模块化。
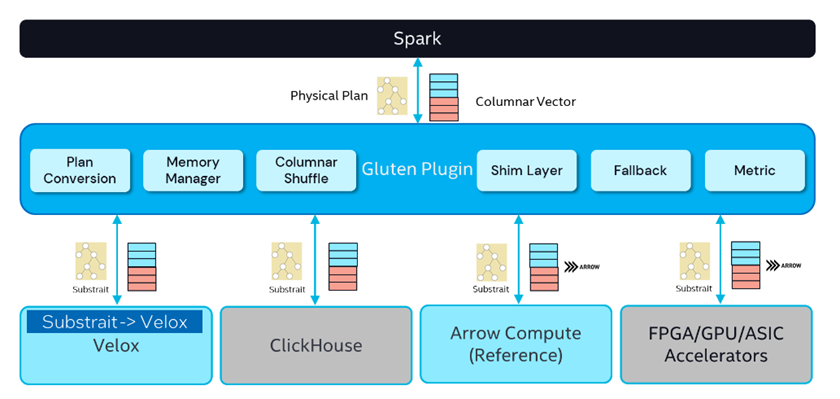
要将Gluten+Velox优化过的Spark计算任务卸载到DPU卡,还缺少一个异构中间层,为此中科驭数研发了HADOS异构执行库,该库提供列数据管理、数据查询运行时函数、任务调度引擎、函数运算代价评估、内存管理等多种DPU能力的API接口,并且支持Java,C++等多种大数据框架语言的调用,拥有极强的拓展性,以及与现有生态的适配性。HADOS敏捷异构软件平台可以适应复杂的大数据软件生态,在付出较小成本的情况下为多种计算场景提供DPU算力加速。Spark框架集成Gluten+Velox向量化执行引擎,然后使用HADOS平台,就可以将经过向量化优化的计算任务,利用DPU执行,从而彻底释放CPU,实现DPU高性能计算。
4.2 DPU算力卸载
velox是由C++实现的向量化计算引擎,其核心执行框架涵盖了任务(Task)、驱动(Driver)和操作器(Operator)等组件。velox将Plan转换为由PlanNode组成的一棵树,然后将PlanNode转换为Operator。Operator作为基础的算子,是实际算法执行的逻辑框架,也是实现DPU计算卸载的关键。
4.2.1 逻辑框架
Operator作为实际算法的逻辑框架,承载着各种表达式的抽象,每一个Operator中包含一个或多个表达式来实现一个复杂完整的计算逻辑块,表达式的底层是由function来具体实现。Velox向开发人员提供了API可以实现自定义scalar function,通过实现一个异构计算版本的function,然后将这个function注册到Velox的函数系统中,就可以将计算任务卸载到DPU卡上。任务执行过程如下图:
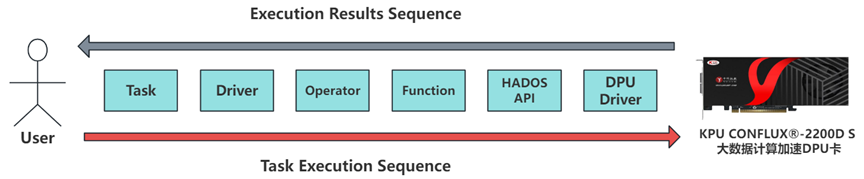
中科驭数的CONFLUX®-2200D S 大数据计算加速DPU卡可以实现列式计算,并且HADOS平台支持C++语言,所以可以直接解析Velox的向量化参数。对于列式存储的数据,经过对数据类型的简单处理之后,可以直接交给DPU执行计算任务,免去了数据行列转换的性能损失,同时也降低了DPU计算资源集成的运维难度,大大提高了Velox异构开发的效率。
4.2.2 算子卸载
以我们实现卸载的Filter算子为例,对于cast(A as bigint)>1这一具体的表达式,来探究如何实现”>”这一二元运算符的卸载。
Filter算子的Operator中会使用有一个 std::unique_ptr<ExprSet> exprs_的变量,用来执行过滤和投影的计算。ExprSet是Filter算子计算的核心,其本质是一颗表达式树。cast(A as bigint)>1的表达式树以及表达式树的静态节点类型如下:
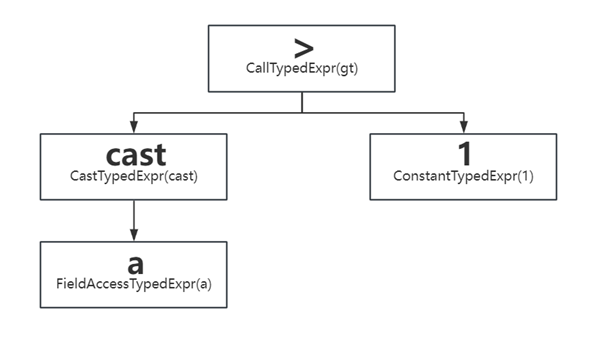
| 节点类型 | 作用 |
| FieldAccessTypedExpr | 表示RowVector中的某一列,作为表达式的叶子节点 |
| ConstantTypedExpr | 表示常量值,作为表达式的叶子节点 |
| CallTypedExpr |
if/and/or/switch/cast/try/coalesce等 |
| CastTypedExpr | 类型转换 |
| LambdaTypedExpr | Lambda表达式,作为叶子节点 |
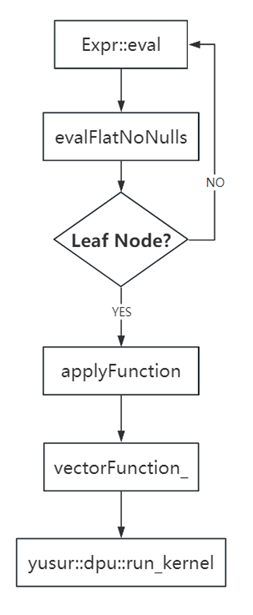
在表达式的所有子节点执行完后,会执行applyFunction,说明当前表达式节点是一个函数调用,然后调用vectorFunction_的apply来对结果进行处理,输入是inputValues_数组,该数组长度与函数的表达式叶子节点数相等(文中示例表达式的叶子节点为2),作为函数的参数,result为输出,结果为VectorPtr,程序流程图如下:
4.2.3 Fallback
现阶段我们只实现了Filter算子的部分表达式,后续还会继续支持更多的算子和表达式。对于一些无法执行的算子和表达式,还是需要退回给Velox,交由CPU执行,从而保证SQL的正常执行。由于处理的是列式数据,所以回退的执行计划可以不需要任何处理,就可以直接从HADOS退还给Velox,几乎无性能损失。
4.2.4 DPU资源管理
HADOS平台会对服务器的DPU资源进行统一管理。对于卸载的计算任务根据现有的DPU资源进行动态分配,从而实现计算资源的高效利用。同时HADOS平台还会对计算任务中所需的内存进行合理的分配,动态申请和释放系统内存,从而减少额外的内存开销。
4.3 加速效果
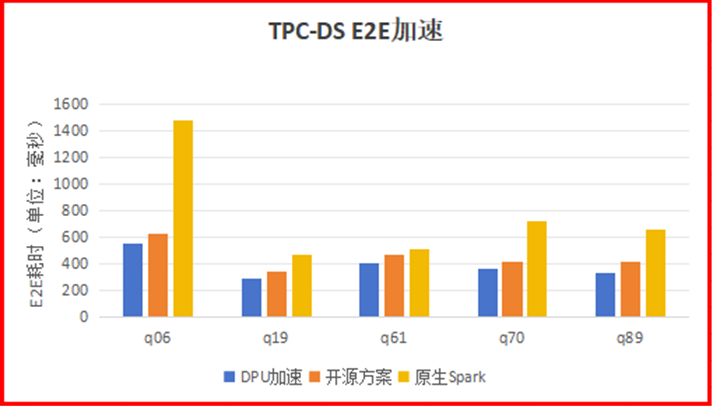
单机单线程local模式,使用1G数据集,仅卸载Filter算子的部分表达式的场景下,TPC-DS语句中有5条SQL语句,可以将使用开源方案的加速效果提升15-20%左右。q70语句,在开源方案提升100%的基础上,提升了15%;q89语句,在开源方案提升50%的基础上,提升了27%;q06在开源方案提升170%的基础上,提升了13%。
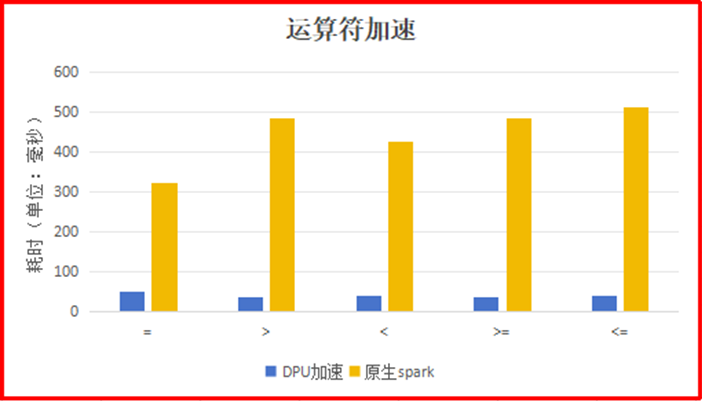
单一运算符场景下(SELECT a FROM t WHERE a = 100),使用DPU运算符相比 Spark原生的运算符的加速比最高达到12.7。
5.不足和展望
中科驭数HADOS敏捷异构软件平台可以十分轻松地与现有开源大数据加速框架相结合,并且为开源框架提供丰富的算力卸载功能。HADOS平台在完美发挥开源加速框架优势的前提下,为大数据任务提供硬件加速能力。由于现在我们只实现了较小部分算子卸载的验证,在执行具有复杂算子操作的SQL时无法发挥出DPU的全部实力,并且因为开源方案在设计之处并没有考虑到使用DPU硬件,所以在磁盘IO,算子优化等方面的性能还有待优化。后续我们也会从一下几个方面来进一步做特定优化:
- 开发更多较复杂的算子,例如重量级的聚合算子会消耗CPU大量的计算能力从而影响Spark作业,通过将聚合算子卸载到DPU硬件来解放CPU能力,从而使得加速效果更加明显;
- 优化DPU的磁盘读写,让DPU可以直接读取硬盘数据,省去数据在服务器内部的传输时间,可以减少数据准备阶段的性能损耗;
- RDMA技术,可以直读取远端内存数据,数据传输内容直接卸载到网卡,减少数据在系统内核中额外的数据复制与移动,可以减少大数据任务计算过程中的性能损耗。
相关文章:
Spark基于DPU的Native引擎算子卸载方案
1.背景介绍 Apache Spark(以下简称Spark)是一个开源的分布式计算框架,由UC Berkeley AMP Lab开发,可用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习&a…...
)
Mini2440 start.s 修改支持串口输出,方便调试 (四)
经常会遇到点板子的时候,板子没有任何反应!怎么知道板子有没有在正常启动,在uboot阶段 start.s 中加入串口打印信息是很有必要的! 输出串口信息 ***UART:mini-2440-uBoot*** ***UART:mini-2440-uBoot*** ***UART:mini-2440-uBoo…...

【教程】几种不同的RBF神经网络
本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com 目录 一、经典RBF神经网络1.1.经典径向基神经网络是什么1.2.经典径向基神经网络-代码与示例 二、广义回归神经网络GRNN2.1.广义回归神经网络是什么2.2.广义回归神经网络是什么-代码与示例 三、概率…...
【Liunx-后端开发软件安装】Liunx安装FDFS并整合nginx
【Liunx-后端开发软件安装】Liunx安装nacos 文章中涉及的相关fdfs相关软件安装包请点击下载: https://download.csdn.net/download/weixin_49051190/89471122 一、简介 FastDFS是一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括…...

【Java笔记】Flyway数据库管理工具的基本原理
文章目录 1. 工作流程2. 版本号校验算法3. 锁机制3.1 为什么数据库管理工具需要锁3.2 flyway的锁机制 Reference 最近实习做的几个项目都用到了Flyway来做数据库的版本管理,顺便了解了下基本原理,做个记录。 详细的使用就不写了,网上教程很多…...

国际数字影像产业园创业培训,全面提升创业能力!
国际数字影像产业园作为数字影像产业的创新高地,致力于提供全面的创业支持服务。其中,创业培训作为重要的组成部分,旨在通过系统的课程设置和专业的讲师团队,为创业者提供从基础到进阶的全方位指导,帮助他们在数字影像…...
pyqt5 制作视频剪辑软件,切割视频
该软件用于切割视频,手动选取视频片段的起始帧和结束帧并保存为json文件。gui界面如下:包含快进、快退、暂停等功能, 代码如下: # codingUTF-8 """ theme: pyqt5实现动作起始帧和结束帧的定位,将定位到…...

VUE----通过nvm管理node版本
使用 NVM(Node Version Manager)来管理和切换 Node.js 版本是一个很好的选择。以下是在 苹果电脑macos系统 上使用 NVM 安装和切换 Node.js 版本的步骤: 1. 安装 NVM 如果你还没有安装 NVM,可以按照以下步骤进行安装:…...

R语言进行字符的替换和删减gsub,substr函数
目录 R语言读文件“-“变成“.“ 提取列字符前几个 提取列字符末尾几个 进行字母替换 paste0函数使用 长宽数据转换 R语言读文件“-“变成“.“ R语言读文件“-“变成“.“_r语言 列名中的-变成了点-CSDN博客 怎样将"."还原为"-" rm(list = ls()…...

2024年6月27日,欧盟REACH法规新增第31批1项SVHC高关注物质
ECHA公布第31批1项SVHC,物质已增至241项 2024年6月27日,ECHA公布第31批1项SVHC,总数达241项。新增物质未包括磷酸三苯酯,仍在评议中。REACH法规要求SVHC含量超0.1%需告知下游,出口超1吨须通报ECHA。SCIP通报要求SVHC含…...
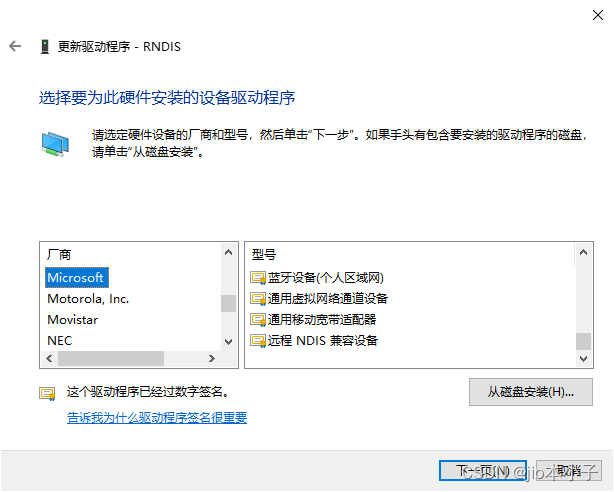
高通410-linux棒子设置网络驱动
1.首先打开设备管理器 2.看到其他设备下的RNDIS,右键更新驱动程序 3.点击浏览我的电脑… 最后一个...

PostgreSQL的系统视图pg_stat_archiver
PostgreSQL的系统视图pg_stat_archiver 在 PostgreSQL 数据库中,pg_stat_archiver 视图提供了关于归档进程(archiver process)的统计信息。归档进程负责将 WAL(Write-Ahead Logging)日志文件复制到归档存储࿰…...

【D3.js in Action 3 精译】第一部分 D3.js 基础知识
第一部分 D3.js 基础知识 欢迎来到 D3.js 的世界!可能您已经迫不及待想要构建令人惊叹的数据可视化项目了。我们保证,这一目标很快就能达成!但首先,我们必须确保您已经掌握了 D3.js 的基础知识。这一部分提到的概念将会在您后续的…...
)
面试经验分享 | 渗透测试工程师(实习岗)
所面试的公司:某安全厂商 所在城市:南京 面试职位:渗透测试工程师实习岗位 面试过程: 腾讯会议(视频) 面试过程:整体流程就是自我介绍加上一些问题问题balabalabala。。。由于面的岗位是渗透…...
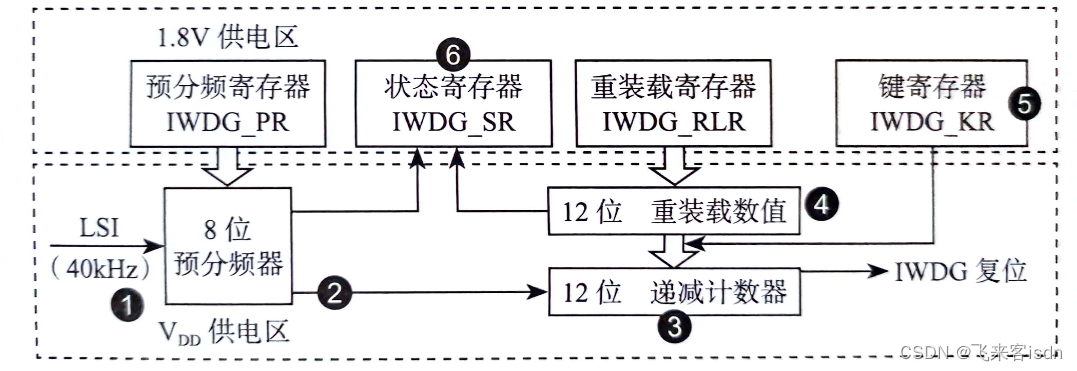
STM32 IWDG(独立看门狗)
1 IWDG简介 STM32有两个看门狗:一个是独立看门狗(IWDG),另外一个是窗口看门狗。独立看门狗也称宠物狗,窗口看门狗也称警犬。本文主要分析独立看门狗的功能和它的应用。 独立看门狗用通俗一点的话来解释就是一个12位的…...

ios swift5 获取wifi列表
参考博客: iOS之Wifi开发探究 - 稀土掘金 iOS 无法获取 WiFi 列表?一定是因为你不知道这个框架 - 稀土掘金 iOS获取Wifi列表详解 - 简书...

回溯法c++学习 解决八皇后问题
使用回溯法解决八皇后问题 八皇后问题是一个以国际象棋为背景的问题:如何能够在88 的国际象棋棋盘上放置八个皇后,使得任何一个皇后都无法直接吃掉其他的皇后?为了达到此目的,任两个皇后都不能处于同一条横行、纵行或斜线上。这…...
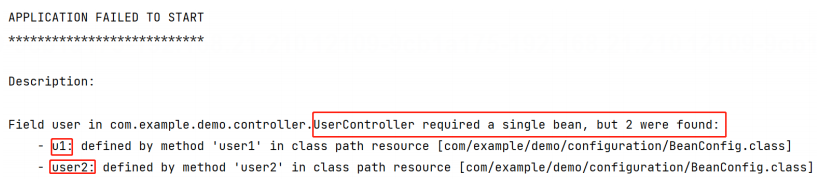
5. Spring IoCDI ★ ✔
5. Spring IoC&DI 1. IoC & DI ⼊⻔1.1 Spring 是什么?★ (Spring 是包含了众多⼯具⽅法的 IoC 容器)1.1.1 什么是容器?1.1.2 什么是 IoC?★ (IoC: Inversion of Control (控制反转))总…...
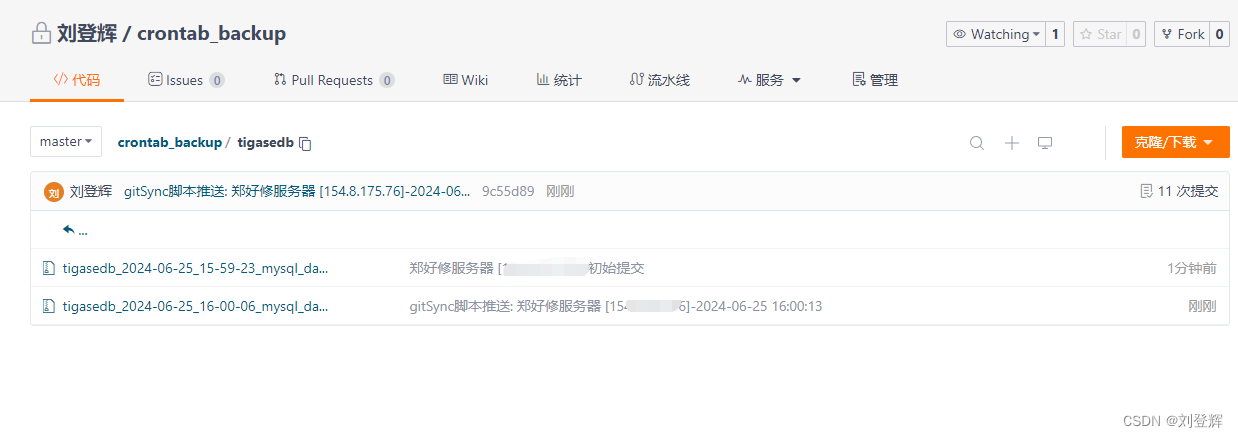
数据库自动备份到gitee上,实现数据自动化备份
本人有个不太好的习惯,每次项目的数据库都是在线上创建,Navicat 连接线上数据库进行处理,最近有一个项目需要二次升级,发现老项目部署的服务器到期了,完蛋,数据库咩了!!!…...

探索 Spring Cloud Gateway:构建微服务架构的关键一环
1. 简介 在当今的分布式系统中,微服务架构已经成为了一种流行的架构模式。在微服务架构中,服务被拆分为小型、可独立部署的服务单元,这些服务单元能够通过网络互相通信,形成一个整体的应用系统。然而,随着微服务数量的…...

终极免费风扇控制软件:如何让你的电脑既安静又凉爽
终极免费风扇控制软件:如何让你的电脑既安静又凉爽 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/Fa…...

如何快速修复分区表:开源数据恢复工具的完整指南
如何快速修复分区表:开源数据恢复工具的完整指南 【免费下载链接】testdisk TestDisk & PhotoRec 项目地址: https://gitcode.com/gh_mirrors/te/testdisk 你是否曾因为误删除重要文件而懊恼不已?是否遇到过分区丢失导致数据无法访问的困境&a…...

Cursor Pro功能完全解锁指南:三步实现免费无限使用体验
Cursor Pro功能完全解锁指南:三步实现免费无限使用体验 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tr…...

终极开源Spotify音乐下载指南:永久保存你的音乐收藏
终极开源Spotify音乐下载指南:永久保存你的音乐收藏 【免费下载链接】spotify-downloader Download your Spotify playlists and songs along with album art and metadata (from YouTube if a match is found). 项目地址: https://gitcode.com/gh_mirrors/spotif…...

Java动态代理终极指南:JDK与CGLIB原理对比详解
Java动态代理终极指南:JDK与CGLIB原理对比详解 【免费下载链接】CodeGuide :books: 本代码库是作者小傅哥多年从事一线互联网 Java 开发的学习历程技术汇总,旨在为大家提供一个清晰详细的学习教程,侧重点更倾向编写Java核心内容。如果本仓库能…...

AI智能体通信基站:统一HTTP请求管理,提升开发效率与稳定性
1. 项目概述:一个为AI智能体构建的“通信基站”如果你正在开发一个AI智能体(Agent),并且需要让它与各种外部服务(比如OpenAI、Anthropic的Claude,或者任何自定义的HTTP API)进行对话,…...

小红书内容采集全攻略:XHS-Downloader开源工具完整指南
小红书内容采集全攻略:XHS-Downloader开源工具完整指南 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&am…...
)
别再只调API了!手把手教你用C#的PrintDocument类搞定小票打印(附完整源码)
别再只调API了!手把手教你用C#的PrintDocument类搞定小票打印(附完整源码) 在零售、餐饮等行业的软件开发中,小票打印功能几乎是标配。很多开发者习惯性地寻找第三方库或现成的报表控件,却忽略了.NET Framework中强大的…...

AI法律助手:基于RAG与LLM的垂直领域应用实践
1. 项目概述:当AI遇见法律,一个开源法律助手的诞生最近在GitHub上看到一个挺有意思的项目,叫imyuanx/ai-lawyer。光看名字,你大概就能猜到它的方向——一个AI驱动的法律助手。作为一名在技术和应用交叉领域摸爬滚打多年的从业者&a…...
)
基于YOLO26深度学习的钢铁腐蚀生锈识别检测系统(项目源码+数据集+模型权重+UI界面+python+深度学习+远程环境部署)
摘要 钢铁材料在工业基础设施中广泛应用,但其长期暴露于潮湿、氧化环境中极易发生腐蚀生锈现象,严重影响结构安全与使用寿命。为实现钢铁腐蚀区域的自动化检测,本研究基于YOLO26目标检测算法构建了一套钢铁腐蚀识别系统。系统采用单类别检测…...