【AI编译器】triton学习:矩阵乘优化
Matrix Multiplication¶
主要内容:
块级矩阵乘法
多维指针算术
重新编排程序以提升L2缓存命
自动性能调整
Motivations¶
矩阵乘法是当今高性能计算系统的一个关键组件,在大多数情况下被用于构建硬件。由于该操作特别复杂,因此通常由软件提供商来进行实现,而不是使用者自己手动编写代码。这些库称为“内核库”(例如cuBLAS),可能会存在一定的版权限制,并且通常无法随意修改以适用于深度学习工作负载中的特殊需求(例如融合式活动函数)。本教程将带你了解如何使用 Triton 自行编写稳定、可扩展的矩阵乘法函数,以实现高性能计算系统所需的功能。
大概来说,我们将要写的内核实现下面这种固定步长算法,对一个(M、K)矩阵和一个(K、N)矩阵进行乘法运算:
# Do in parallel
for m in range(0, M, BLOCK_SIZE_M):# Do in parallelfor n in range(0, N, BLOCK_SIZE_N):acc = zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=float32)for k in range(0, K, BLOCK_SIZE_K):a = A[m : m+BLOCK_SIZE_M, k : k+BLOCK_SIZE_K]b = B[k : k+BLOCK_SIZE_K, n : n+BLOCK_SIZE_N]acc += dot(a, b)C[m : m+BLOCK_SIZE_M, n : n+BLOCK_SIZE_N] = acc
在每个嵌套程序的每次递归过程中,Triton 实例都会产生一个专门的计算机程序来执行。
Compute Kernel¶
上面算法的实现在Triton上其实并不困难。只是内部迭代过程中,对于要从A和B缓存区读取数据的记忆位置计算这一步骤会有些复杂。为了实现该操作,我们需要使用多维指针运算方式。
指针数学运算符号¶
如果 X 是一个行向矩阵,那么X[i,j]的存储位址为 &X[i,j] = X + istride_xi + jstride_xj。因此,可以将A[m:m+BLOCK_SIZE_M, k:k+BLOCK_SIZE_K]和 B[k:k+BLOCK_SIZE_K, n:n+BLOCK_SIZE_N]的块中存储地址表示成以下形式的虚拟代码:
&A[m : m+BLOCK_SIZE_M, k:k+BLOCK_SIZE_K] = a_ptr + (m : m+BLOCK_SIZE_M)[:, None]*A.stride(0) + (k : k+BLOCK_SIZE_K)[None, :]*A.stride(1);
&B[k : k+BLOCK_SIZE_K, n:n+BLOCK_SIZE_N] = b_ptr + (k : k+BLOCK_SIZE_K)[:, None]*B.stride(0) + (n : n+BLOCK_SIZE_N)[None, :]*B.stride(1);
这意味着在Triton软件中,我们可以将A和B两个向量的指针分段设置为0(即i=0)。且需要注意的是,当M与数据握的大小BLOCK_SIZE_M不是相匹配的时候,我们可以通过添加一个额外模式来处理这种情况,例如,在数据中往底部加上一些无用的值。此后我们将为K维度使用遮蔽式载入操作进行处理。
offs_am = (pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)) % M
offs_bn = (pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)) % N
offs_k = tl.arange(0, BLOCK_SIZE_K)
a_ptrs = a_ptr + (offs_am[:, None]*stride_am + offs_k [None, :]*stride_ak)
b_ptrs = b_ptr + (offs_k [:, None]*stride_bk + offs_bn[None, :]*stride_bn)
然后在内部循环中进行以下更新:
a_ptrs += BLOCK_SIZE_K * stride_ak;
b_ptrs += BLOCK_SIZE_K * stride_bk;
二级缓存的优化措施
如上所述,每个程序实例都会计算出一组长度为[BLOCK_SIZE_M,BLOCK_SIZE_N]的C语言代码块。这种方式非常重要,因为执行顺序可能导致该程序中L2缓存的命中率不同,而且令人遗憾的是,如果我们使用矩阵增量式顺序执行代码,则其性能将会受到影响。
pid = tl.program_id(axis=0)
grid_n = tl.cdiv(N, BLOCK_SIZE_N)
pid_m = pid // grid_n
pid_n = pid % grid_n
这根本不够用。
解决这个问题的一种方法是在排列块时采用数据重复使用的最佳组合。 我们可以“将所有 GROUP_M 行都集成到同一块中”,然后再按照对应的列进行排序:
# Program ID
pid = tl.program_id(axis=0)
# Number of program ids along the M axis
num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
# Number of programs ids along the N axis
num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)
# Number of programs in group
num_pid_in_group = GROUP_SIZE_M * num_pid_n
# Id of the group this program is in
group_id = pid // num_pid_in_group
# Row-id of the first program in the group
first_pid_m = group_id * GROUP_SIZE_M
# If `num_pid_m` isn't divisible by `GROUP_SIZE_M`, the last group is smaller
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
# *Within groups*, programs are ordered in a column-major order
# Row-id of the program in the *launch grid*
pid_m = first_pid_m + ((pid % num_pid_in_group) % group_size_m)
# Col-id of the program in the *launch grid*
pid_n = (pid % num_pid_in_group) // group_size_m
以下的矩阵乘法是每个矩阵块为九个,共有九个矩阵乘法操作。通过比较如果我们按行向量序排列输出的话,则需要在SRAM中加载90个元素来计算第一层的9个输出值,而若是以固定单元格为基础进行分组操作,只需加载54个元素。
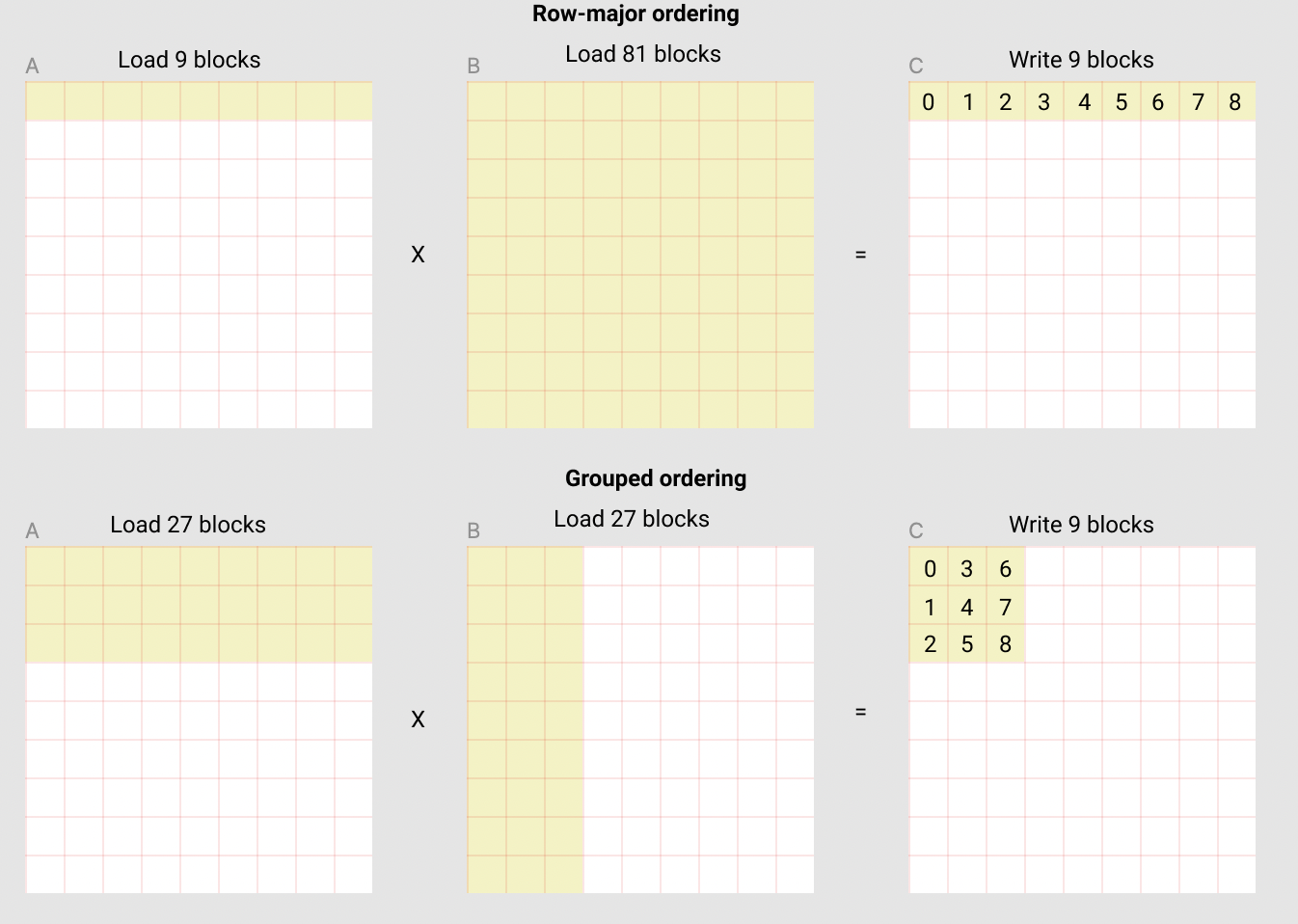
实际上,这会使我们矩阵乘法的算法执行效率提高超过10%(例如:A100在220至245TFLOPS之间)。
Final Result¶
import torchimport triton
import triton.language as tldef is_cuda():return triton.runtime.driver.active.get_current_target().backend == "cuda"def is_hip_mi200():target = triton.runtime.driver.active.get_current_target()return target.backend == 'hip' and target.arch == 'gfx90a'def get_cuda_autotune_config():return [triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 256, 'BLOCK_SIZE_K': 64, 'GROUP_SIZE_M': 8}, num_stages=3,num_warps=8),triton.Config({'BLOCK_SIZE_M': 64, 'BLOCK_SIZE_N': 256, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4,num_warps=4),triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 128, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4,num_warps=4),triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 64, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4,num_warps=4),triton.Config({'BLOCK_SIZE_M': 64, 'BLOCK_SIZE_N': 128, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4,num_warps=4),triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 32, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4,num_warps=4),triton.Config({'BLOCK_SIZE_M': 64, 'BLOCK_SIZE_N': 32, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=5,num_warps=2),triton.Config({'BLOCK_SIZE_M': 32, 'BLOCK_SIZE_N': 64, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=5,num_warps=2),# Good config for fp8 inputs.triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 256, 'BLOCK_SIZE_K': 128, 'GROUP_SIZE_M': 8}, num_stages=3,num_warps=8),triton.Config({'BLOCK_SIZE_M': 256, 'BLOCK_SIZE_N': 128, 'BLOCK_SIZE_K': 128, 'GROUP_SIZE_M': 8}, num_stages=3,num_warps=8),triton.Config({'BLOCK_SIZE_M': 256, 'BLOCK_SIZE_N': 64, 'BLOCK_SIZE_K': 128, 'GROUP_SIZE_M': 8}, num_stages=4,num_warps=4),triton.Config({'BLOCK_SIZE_M': 64, 'BLOCK_SIZE_N': 256, 'BLOCK_SIZE_K': 128, 'GROUP_SIZE_M': 8}, num_stages=4,num_warps=4),triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 128, 'BLOCK_SIZE_K': 128, 'GROUP_SIZE_M': 8}, num_stages=4,num_warps=4),triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 64, 'BLOCK_SIZE_K': 64, 'GROUP_SIZE_M': 8}, num_stages=4,num_warps=4),triton.Config({'BLOCK_SIZE_M': 64, 'BLOCK_SIZE_N': 128, 'BLOCK_SIZE_K': 64, 'GROUP_SIZE_M': 8}, num_stages=4,num_warps=4),triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 32, 'BLOCK_SIZE_K': 64, 'GROUP_SIZE_M': 8}, num_stages=4,num_warps=4)]def get_hip_autotune_config():return [triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 256, 'BLOCK_SIZE_K': 16, 'GROUP_SIZE_M': 1, 'waves_per_eu': 2},num_warps=4, num_stages=0),triton.Config({'BLOCK_SIZE_M': 256, 'BLOCK_SIZE_N': 256, 'BLOCK_SIZE_K': 16, 'GROUP_SIZE_M': 4, 'waves_per_eu': 2},num_warps=8, num_stages=0),triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 128, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 1, 'waves_per_eu': 2},num_warps=8, num_stages=0),triton.Config({'BLOCK_SIZE_M': 64, 'BLOCK_SIZE_N': 128, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8, 'waves_per_eu': 3},num_warps=4, num_stages=0),triton.Config({'BLOCK_SIZE_M': 64, 'BLOCK_SIZE_N': 64, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 1, 'waves_per_eu': 8},num_warps=4, num_stages=0),]def get_autotune_config():if is_cuda():return get_cuda_autotune_config()else:return get_hip_autotune_config()# `triton.jit`'ed functions can be auto-tuned by using the `triton.autotune` decorator, which consumes:
# - A list of `triton.Config` objects that define different configurations of
# meta-parameters (e.g., `BLOCK_SIZE_M`) and compilation options (e.g., `num_warps`) to try
# - An auto-tuning *key* whose change in values will trigger evaluation of all the
# provided configs
@triton.autotune(configs=get_autotune_config(),key=['M', 'N', 'K'],
)
@triton.jit
def matmul_kernel(# Pointers to matricesa_ptr, b_ptr, c_ptr,# Matrix dimensionsM, N, K,# The stride variables represent how much to increase the ptr by when moving by 1# element in a particular dimension. E.g. `stride_am` is how much to increase `a_ptr`# by to get the element one row down (A has M rows).stride_am, stride_ak, #stride_bk, stride_bn, #stride_cm, stride_cn,# Meta-parametersBLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_N: tl.constexpr, BLOCK_SIZE_K: tl.constexpr, #GROUP_SIZE_M: tl.constexpr, #ACTIVATION: tl.constexpr #
):"""Kernel for computing the matmul C = A x B.A has shape (M, K), B has shape (K, N) and C has shape (M, N)"""# -----------------------------------------------------------# Map program ids `pid` to the block of C it should compute.# This is done in a grouped ordering to promote L2 data reuse.# See above `L2 Cache Optimizations` section for details.pid = tl.program_id(axis=0)num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)num_pid_in_group = GROUP_SIZE_M * num_pid_ngroup_id = pid // num_pid_in_groupfirst_pid_m = group_id * GROUP_SIZE_Mgroup_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)pid_m = first_pid_m + ((pid % num_pid_in_group) % group_size_m)pid_n = (pid % num_pid_in_group) // group_size_m# ----------------------------------------------------------# Create pointers for the first blocks of A and B.# We will advance this pointer as we move in the K direction# and accumulate# `a_ptrs` is a block of [BLOCK_SIZE_M, BLOCK_SIZE_K] pointers# `b_ptrs` is a block of [BLOCK_SIZE_K, BLOCK_SIZE_N] pointers# See above `Pointer Arithmetic` section for detailsoffs_am = (pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)) % Moffs_bn = (pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)) % Noffs_k = tl.arange(0, BLOCK_SIZE_K)a_ptrs = a_ptr + (offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak)b_ptrs = b_ptr + (offs_k[:, None] * stride_bk + offs_bn[None, :] * stride_bn)# -----------------------------------------------------------# Iterate to compute a block of the C matrix.# We accumulate into a `[BLOCK_SIZE_M, BLOCK_SIZE_N]` block# of fp32 values for higher accuracy.# `accumulator` will be converted back to fp16 after the loop.accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)for k in range(0, tl.cdiv(K, BLOCK_SIZE_K)):# Load the next block of A and B, generate a mask by checking the K dimension.# If it is out of bounds, set it to 0.a = tl.load(a_ptrs, mask=offs_k[None, :] < K - k * BLOCK_SIZE_K, other=0.0)b = tl.load(b_ptrs, mask=offs_k[:, None] < K - k * BLOCK_SIZE_K, other=0.0)# We accumulate along the K dimension.accumulator = tl.dot(a, b, accumulator)# Advance the ptrs to the next K block.a_ptrs += BLOCK_SIZE_K * stride_akb_ptrs += BLOCK_SIZE_K * stride_bk# You can fuse arbitrary activation functions here# while the accumulator is still in FP32!if ACTIVATION == "leaky_relu":accumulator = leaky_relu(accumulator)c = accumulator.to(tl.float16)# -----------------------------------------------------------# Write back the block of the output matrix C with masks.offs_cm = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)offs_cn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)c_ptrs = c_ptr + stride_cm * offs_cm[:, None] + stride_cn * offs_cn[None, :]c_mask = (offs_cm[:, None] < M) & (offs_cn[None, :] < N)tl.store(c_ptrs, c, mask=c_mask)# We can fuse `leaky_relu` by providing it as an `ACTIVATION` meta-parameter in `matmul_kernel`.
@triton.jit
def leaky_relu(x):return tl.where(x >= 0, x, 0.01 * x)
我们现在可以创建一个操作简单的函数包装器,具有两个输入张量参数(), 该函数:(1)检查输入张量是否符合任何形状要求;(2)分配输出;(3)调用上面所示的核心计算。
def matmul(a, b, activation=""):# Check constraints.assert a.shape[1] == b.shape[0], "Incompatible dimensions"assert a.is_contiguous(), "Matrix A must be contiguous"M, K = a.shapeK, N = b.shape# Allocates output.c = torch.empty((M, N), device=a.device, dtype=torch.float16)# 1D launch kernel where each block gets its own program.grid = lambda META: (triton.cdiv(M, META['BLOCK_SIZE_M']) * triton.cdiv(N, META['BLOCK_SIZE_N']), )matmul_kernel[grid](a, b, c, #M, N, K, #a.stride(0), a.stride(1), #b.stride(0), b.stride(1), #c.stride(0), c.stride(1), #ACTIVATION=activation #)return c
Unit Test¶
我们可以对自定义的矩阵乘法运算与原生执行操作的Torch进行测试(即cuBLAS)。
torch.manual_seed(0)
a = torch.randn((512, 512), device='cuda', dtype=torch.float16)
b = torch.randn((512, 512), device='cuda', dtype=torch.float16)
triton_output = matmul(a, b)
torch_output = torch.matmul(a, b)
print(f"triton_output_with_fp16_inputs={triton_output}")
print(f"torch_output_with_fp16_inputs={torch_output}")
# Bigger tolerance for AMD MI200 devices.
# MI200 devices use reduced precision fp16 and bf16 and flush input and
# output denormal values to zero. Detailed info is at: https://pytorch.org/docs/stable/notes/numerical_accuracy.html#reduced-precision-fp16-and-bf16-gemms-and-convolutions-on-amd-instinct-mi200-devices
rtol = 1e-2 if is_hip_mi200() else 0
if torch.allclose(triton_output, torch_output, atol=1e-2, rtol=rtol):print("✅ Triton and Torch match")
else:print("❌ Triton and Torch differ")TORCH_HAS_FP8 = hasattr(torch, "float8_e5m2")
if TORCH_HAS_FP8 and is_cuda():torch.manual_seed(0)a = torch.randn((512, 512), device="cuda", dtype=torch.float16)b = torch.randn((512, 512), device="cuda", dtype=torch.float16)a = a.to(torch.float8_e5m2)# pre-transpose b for efficiency.b = b.Tb = b.to(torch.float8_e5m2)triton_output = matmul(a, b)torch_output = torch.matmul(a.to(torch.float16), b.to(torch.float16))print(f"triton_output_with_fp8_inputs={triton_output}")print(f"torch_output_with_fp8_inputs={torch_output}")if torch.allclose(triton_output, torch_output, atol=0.125, rtol=0):print("✅ Triton and Torch match")else:print("❌ Triton and Torch differ")
triton_output_with_fp16_inputs=tensor([[-10.9531, -4.7109, 15.6953, ..., -28.4062, 4.3320, -26.4219],[ 26.8438, 10.0469, -5.4297, ..., -11.2969, -8.5312, 30.7500],[-13.2578, 15.8516, 18.0781, ..., -21.7656, -8.6406, 10.2031],...,[ 40.2812, 18.6094, -25.6094, ..., -2.7598, -3.2441, 41.0000],[ -6.1211, -16.8281, 4.4844, ..., -21.0312, 24.7031, 15.0234],[-17.0938, -19.0000, -0.3831, ..., 21.5469, -30.2344, -13.2188]],device='cuda:0', dtype=torch.float16)
torch_output_with_fp16_inputs=tensor([[-10.9531, -4.7109, 15.6953, ..., -28.4062, 4.3320, -26.4219],[ 26.8438, 10.0469, -5.4297, ..., -11.2969, -8.5312, 30.7500],[-13.2578, 15.8516, 18.0781, ..., -21.7656, -8.6406, 10.2031],...,[ 40.2812, 18.6094, -25.6094, ..., -2.7598, -3.2441, 41.0000],[ -6.1211, -16.8281, 4.4844, ..., -21.0312, 24.7031, 15.0234],[-17.0938, -19.0000, -0.3831, ..., 21.5469, -30.2344, -13.2188]],device='cuda:0', dtype=torch.float16)
✅ Triton and Torch match
triton_output_with_fp8_inputs=tensor([[-21.4375, 13.1719, 6.0352, ..., 28.7031, 8.6719, -40.7500],[ 10.0000, 37.0000, -5.5664, ..., 20.9844, 46.8125, 30.8281],[ 19.5625, -3.0078, -20.0469, ..., -2.1309, -8.0625, 12.5625],...,[-18.1562, -34.1562, -27.4219, ..., -27.3906, -24.0938, -12.3516],[ -3.3945, -8.6250, -23.6562, ..., -4.1094, -3.5332, -16.0781],[-23.9688, -3.2637, -33.6875, ..., 17.3125, -36.6250, 25.8594]],device='cuda:0', dtype=torch.float16)
torch_output_with_fp8_inputs=tensor([[-21.4375, 13.1719, 6.0352, ..., 28.7031, 8.6719, -40.7500],[ 10.0000, 37.0000, -5.5664, ..., 20.9844, 46.8125, 30.8281],[ 19.5625, -3.0078, -20.0469, ..., -2.1309, -8.0625, 12.5625],...,[-18.1562, -34.1562, -27.4219, ..., -27.3906, -24.0938, -12.3516],[ -3.3945, -8.6250, -23.6562, ..., -4.1094, -3.5332, -16.0781],[-23.9688, -3.2637, -33.6875, ..., 17.3125, -36.6250, 25.8594]],device='cuda:0', dtype=torch.float16)
✅ Triton and Torch match
Benchmark¶
性能指标¶
我们可以对现有的内核与cuBLAS或rocBLAS进行比较,这里以对方阵为例,但也能够根据你自定义需求对其他矩阵形状进行性能测试。
ref_lib = 'cuBLAS' if is_cuda() else 'rocBLAS'configs = []
for fp8_inputs in [False, True]:if fp8_inputs and (not TORCH_HAS_FP8 or not is_cuda()):continueconfigs.append(triton.testing.Benchmark(x_names=["M", "N", "K"], # Argument names to use as an x-axis for the plotx_vals=[128 * i for i in range(2, 33)], # Different possible values for `x_name`line_arg="provider", # Argument name whose value corresponds to a different line in the plot# Possible values for `line_arg`# Don't compare to cublas for fp8 cases as torch.matmul doesn't support fp8 at the moment.line_vals=["triton"] if fp8_inputs else [ref_lib.lower(), "triton"], # Label name for the linesline_names=["Triton"] if fp8_inputs else [ref_lib, "Triton"], # Line stylesstyles=[("green", "-"), ("blue", "-")],ylabel="TFLOPS", # Label name for the y-axisplot_name="matmul-performance-" +("fp16" if not fp8_inputs else "fp8"), # Name for the plot, used also as a file name for saving the plot.args={"fp8_inputs": fp8_inputs},))@triton.testing.perf_report(configs)
def benchmark(M, N, K, provider, fp8_inputs):a = torch.randn((M, K), device='cuda', dtype=torch.float16)b = torch.randn((K, N), device='cuda', dtype=torch.float16)if TORCH_HAS_FP8 and fp8_inputs:a = a.to(torch.float8_e5m2)b = b.Tb = b.to(torch.float8_e5m2)quantiles = [0.5, 0.2, 0.8]if provider == ref_lib.lower():ms, min_ms, max_ms = triton.testing.do_bench(lambda: torch.matmul(a, b), quantiles=quantiles)if provider == 'triton':ms, min_ms, max_ms = triton.testing.do_bench(lambda: matmul(a, b), quantiles=quantiles)perf = lambda ms: 2 * M * N * K * 1e-12 / (ms * 1e-3)return perf(ms), perf(max_ms), perf(min_ms)benchmark.run(show_plots=True, print_data=True)
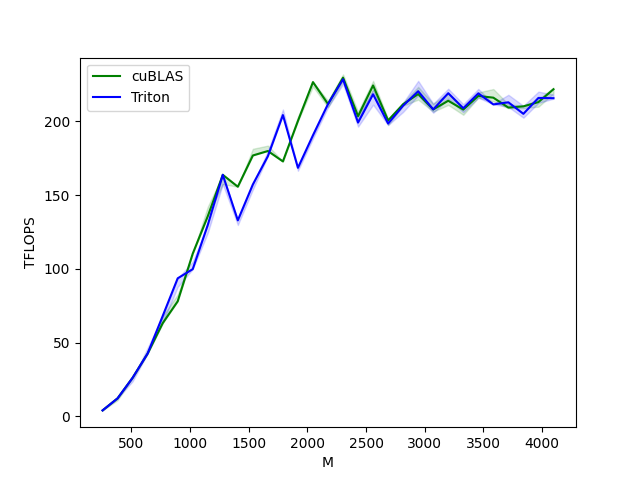
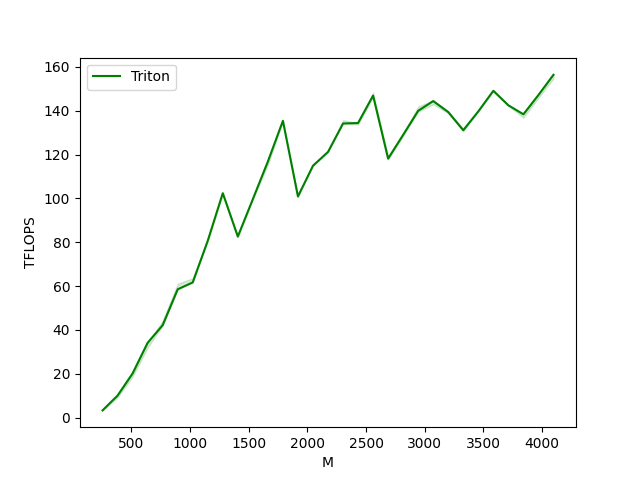
matmul-performance-fp16:M N K cuBLAS Triton
0 256.0 256.0 256.0 4.096000 4.096000
1 384.0 384.0 384.0 12.288000 12.288000
2 512.0 512.0 512.0 26.214401 26.214401
3 640.0 640.0 640.0 42.666665 42.666665
4 768.0 768.0 768.0 63.195428 68.056616
5 896.0 896.0 896.0 78.051553 93.661869
6 1024.0 1024.0 1024.0 110.376426 99.864382
7 1152.0 1152.0 1152.0 135.726544 129.825388
8 1280.0 1280.0 1280.0 163.840004 163.840004
9 1408.0 1408.0 1408.0 155.765024 132.970149
10 1536.0 1536.0 1536.0 176.947204 157.286398
11 1664.0 1664.0 1664.0 179.978245 176.449258
12 1792.0 1792.0 1792.0 172.914215 204.353162
13 1920.0 1920.0 1920.0 200.347822 168.585369
14 2048.0 2048.0 2048.0 226.719125 190.650180
15 2176.0 2176.0 2176.0 211.827867 211.827867
16 2304.0 2304.0 2304.0 229.691080 228.592087
17 2432.0 2432.0 2432.0 203.583068 199.251522
18 2560.0 2560.0 2560.0 224.438347 218.453323
19 2688.0 2688.0 2688.0 200.704002 198.602388
20 2816.0 2816.0 2816.0 211.719459 210.696652
21 2944.0 2944.0 2944.0 218.579083 220.513412
22 3072.0 3072.0 3072.0 208.173173 208.173173
23 3200.0 3200.0 3200.0 214.046818 219.178074
24 3328.0 3328.0 3328.0 208.067338 208.973281
25 3456.0 3456.0 3456.0 217.308808 219.080343
26 3584.0 3584.0 3584.0 216.142772 211.565625
27 3712.0 3712.0 3712.0 209.428397 213.000737
28 3840.0 3840.0 3840.0 210.250955 205.179974
29 3968.0 3968.0 3968.0 213.142249 215.971570
30 4096.0 4096.0 4096.0 221.847481 215.784121
matmul-performance-fp8:M N K Triton
0 256.0 256.0 256.0 3.276800
1 384.0 384.0 384.0 10.053818
2 512.0 512.0 512.0 20.164923
3 640.0 640.0 640.0 34.133334
4 768.0 768.0 768.0 42.130286
5 896.0 896.0 896.0 58.538665
6 1024.0 1024.0 1024.0 61.680940
7 1152.0 1152.0 1152.0 80.702267
8 1280.0 1280.0 1280.0 102.400003
9 1408.0 1408.0 1408.0 82.602666
10 1536.0 1536.0 1536.0 99.688560
11 1664.0 1664.0 1664.0 116.868992
12 1792.0 1792.0 1792.0 135.414749
13 1920.0 1920.0 1920.0 100.905113
14 2048.0 2048.0 2048.0 114.912434
15 2176.0 2176.0 2176.0 121.226797
16 2304.0 2304.0 2304.0 134.201527
17 2432.0 2432.0 2432.0 134.423269
18 2560.0 2560.0 2560.0 146.941707
19 2688.0 2688.0 2688.0 118.171514
20 2816.0 2816.0 2816.0 129.036114
21 2944.0 2944.0 2944.0 139.988852
22 3072.0 3072.0 3072.0 144.446699
23 3200.0 3200.0 3200.0 139.433550
24 3328.0 3328.0 3328.0 131.131689
25 3456.0 3456.0 3456.0 139.725414
26 3584.0 3584.0 3584.0 149.113421
27 3712.0 3712.0 3712.0 142.506914
28 3840.0 3840.0 3840.0 138.413021
29 3968.0 3968.0 3968.0 147.194128
30 4096.0 4096.0 4096.0 156.430916
相关文章:
【AI编译器】triton学习:矩阵乘优化
Matrix Multiplication 主要内容: 块级矩阵乘法 多维指针算术 重新编排程序以提升L2缓存命 自动性能调整 Motivations 矩阵乘法是当今高性能计算系统的一个关键组件,在大多数情况下被用于构建硬件。由于该操作特别复杂,因此通常由软件提…...

动静分离网络
动静分离网络的主要目的是分别处理视频帧中的静止区域和运动区域,以便对不同区域采用不同的去噪策略。这里提供一个实现思路,通过两个分支网络分别处理静止区域和运动区域,然后将两者的输出融合起来。 实现步骤 帧差图生成:计算…...
——Python数据分析的应用①Matplotlib数据可视化基础)
Python商务数据分析知识专栏(三)——Python数据分析的应用①Matplotlib数据可视化基础
Python商务数据分析知识专栏(三)——Python数据分析的应用①Matplotlib数据可视化基础 Matplotlib数据可视化基础1.掌握绘图基本语法与常用绘图2.分析特征间关系3.分析特征内部数据分布与分散情况 Matplotlib数据可视化基础 1.掌握绘图基本语法与常用绘…...
DataV大屏组件库
DataV官方文档 DataV组件库基于Vue (React版 (opens new window)) ,主要用于构建大屏(全屏)数据展示页面即数据可视化,具有多种类型组件可供使用: 源码下载...

paraview跨节点并行渲染
参考: https://cloud.tencent.com/developer/ask/sof/101483588 ParaView 支持使用其内置的网络拓扑来进行跨节点的并行渲染。以下是一个简单的步骤来设置和运行跨节点的并行渲染: 确保你的计算环境支持多节点计算,比如通过SSH、MPI或其他集…...

Java中相等比较详解
本文对Java中的相等判断进行详细解释,包括,equals和compareTo等。 一、 运算符 1. 用途 基本数据类型:用于比较两个基本数据类型的值是否相等。 引用类型:用于比较两个对象引用是否指向同一个对象。 2. 示例 // 基本数据类型比…...

HBuilder X 小白日记01
1.创建项目 2.右击项目,可创建html文件 3.保存CtrlS,运行一下 我们写的内容,一般是写在body里面 注释的快捷键:Ctrl/ h标签 <h1> 定义重要等级最高的(最大)的标题。<h6> 定义最小的标题。 H标签起侧重、强调的作用…...

使用Protocol Buffers优化数据传输
使用Protocol Buffers优化数据传输 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 什么是Protocol Buffers? Protocol Buffers(简称P…...
如何把mkv转成mp4?介绍一下将mkv转成MP4的几种方法
如何把mkv转成mp4?如果你有一个MKV格式的视频文件,但是需要将其转换为MP4格式以便更广泛地在各种设备和平台上播放和共享,你可以通过进行简单的文件格式转换来实现。转换MKV到MP4格式可以提供更好的兼容性,并确保你的视频文件能够…...
PHP语言学习02
好久不见,学如逆水行舟,不进则退,真是这样。。。突然感觉自己有点废。。。 <?php phpinfo(); ?> 新生第一个代码。 要想看到运行结果,打开浏览器(127.0.0.1/start/demo01.php) 其中,…...

PX2资料及问题记录
PX2的一些资料 官方论坛:https://devtalk.nvidia.com/default/board/182/drive-px2/ 官方网站:https://www.nvidia.com/en-us/self-driving-cars/ap2x/ 开发网站:https://developer.nvidia.com/drive/downloads docker docker run --devic…...
Jenkins容器的部署
本文主要是记录如何在Centos7上安装docker,以及在docker里面配置tomcat、mysql、jenkins等环境。 一、安装docker 1.1 准备工作 centos7、VMware17Pro 1.2 通过yum在线安装dokcer yum -y install docker1.3 启动docker服务 systemctl start docker.service1.4 查看docke…...

QT 自绘树形控件
资源来自:https://gitee.com/qt-open-source-collection/NavListView/blob/master/navlistview.h 1、解决的问题:一处编译报错;空白区域绘制背景;点击页面崩溃 2、源码: #ifndef NAVLISTVIEW_H #define NAVLISTVIEW_H/*** 作者:feiyangqingyun(QQ:517216493) 2016-10-1…...
axios之CancelToken取消请求
从 v0.22.0 开始,Axios 支持以 fetch API 方式—— AbortController 取消请求 此 API 从 v0.22.0 开始已被弃用,不应在新项目中使用 官网链接 1. 背景 最近项目中遇到一个场景,当连续触发一个请求时,如果是同一个接口…...

Unity | API鉴权用到的函数汇总
目录 一、HMAC-SHA1 二、UriEncode 三、Date 四、Content-MD5 五、参数操作 六、阿里云API鉴权 一、HMAC-SHA1 使用 RFC 2104 中定义的 HMAC-SHA1 方法生成带有密钥的哈希值: private static string CalculateSignature(string secret, string data){byte[] k…...
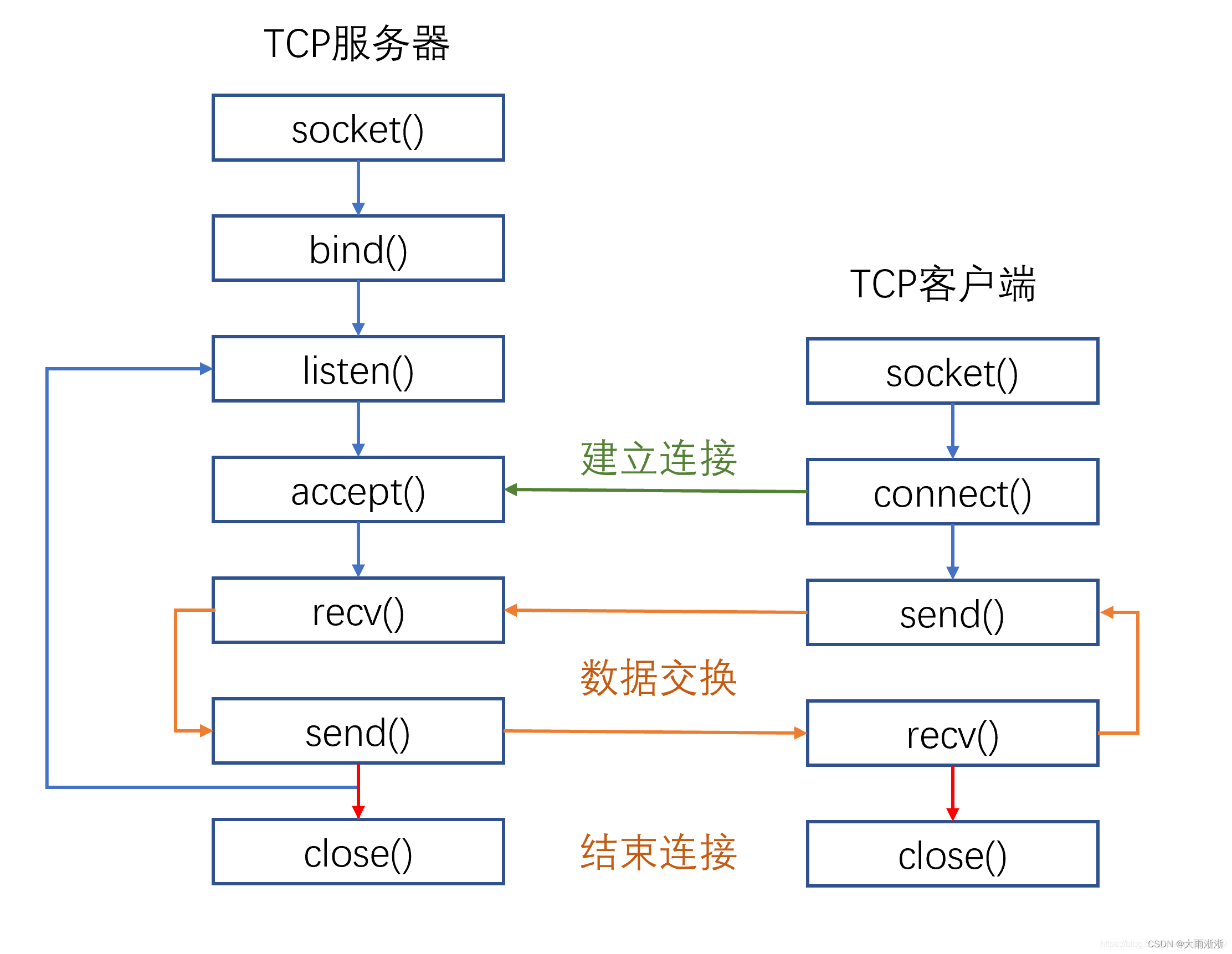
【python】socket通信代码解析
目录 一、socket通信原理 1.1 服务器端 1.2 客户端 二、socket通信主要应用场景 2.1 简单的服务器和客户端通信 2.2 并发服务器 2.3 UDP通信 2.4 文件传输 2.5 HTTP服务器 2.6 邮件发送与接收 2.7 FTP客户端 2.8 P2P文件共享 2.9 网络游戏 三、python中Socket编…...

FastGPT 手动部署错误:MongooseServerSelectionError: getaddrinfo EAI_AGAIN mongo
在运行 FastGPT 时,mongodb 报如下错误: MongooseServerSelectionError: getaddrinfo EAI_AGAIN mongo 这是因为 mongo 没有解析出来,在 hosts 文件中添加如下信息: 127.0.0.1 mongo 重新运行 FastGPT 即可。 参考链接ÿ…...

用英文介绍芝加哥(1):Making Modern Chicago Part 1 Building a Boomtown
Making Modern Chicago | Part 1: Building a Boomtown Link: https://www.youtube.com/watch?vpNdX0Dm-J8Y&listPLmSQiOQJmbZ7TU39cyx7gizM9i8nOuZXy&index4 Summary Summary of Chicago’s History and Development Urban Planning and Growth Chicago, often r…...
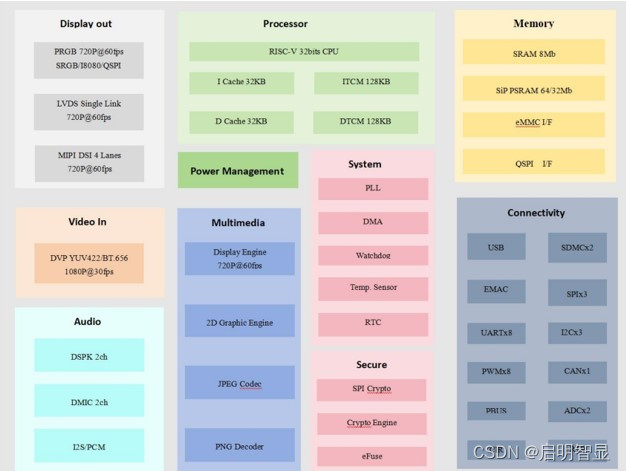
【启明智显分享】低成本RISC-V工业级HMI方案推荐
伴随着工业4.0的迅猛发展,工业HMI以方便、快捷的特点逐渐成为工业的日常应用,成为备受追捧的全新多媒体交互设备。 什么是工业HMI?工业HMI是用于工业自动化系统中的人机交互界面,通常由触摸屏、按钮、指示灯、显示器等组成&#…...

深入探索STM32的SPI功能:W25Q64 Flash存储器全攻略
摘要 随着嵌入式系统对存储需求的增长,选择合适的存储设备变得尤为重要。W25Q64 Flash存储器以其8Mbit的存储容量和SPI接口的便捷性,成为STM32微控制器项目中的优选存储方案。本文将深入探索STM32的SPI功能,提供W25Q64 Flash存储器的全面集成…...

掌握Windows风扇控制:FanControl软件从零到精通指南
掌握Windows风扇控制:FanControl软件从零到精通指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/F…...

CANN/asc-devkit NodeIoNum API文档
NodeIoNum 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/…...

WpfDesigner终极指南:5分钟掌握WPF可视化设计工具,告别手写XAML代码
WpfDesigner终极指南:5分钟掌握WPF可视化设计工具,告别手写XAML代码 【免费下载链接】WpfDesigner The WPF Designer from SharpDevelop 项目地址: https://gitcode.com/gh_mirrors/wp/WpfDesigner 还在为复杂的WPF界面设计而烦恼吗?W…...

BetterRTX:为Minecraft基岩版开启专业级光影体验的现代化安装器
BetterRTX:为Minecraft基岩版开启专业级光影体验的现代化安装器 【免费下载链接】BetterRTX-Installer The Powershell Installer for BetterRTX! BetterRTX is a Ray-Tracing mod for Minecraft Bedrock. 项目地址: https://gitcode.com/gh_mirrors/be/BetterRTX…...

金融APP加固公司指南:从苹果审核到防破解的实战经验分享
金融类APP(银行、证券、支付)是所有移动应用中安全防护等级最高、合规要求最严、被攻击价值最大的一类。代码一旦被逆向,交易协议、用户数据、核心算法将直接暴露,带来的不仅是经济损失,更是监管处罚和品牌信誉崩塌。因…...

开源AI智能体记忆服务:构建持久化共享记忆中枢
1. 项目概述:为AI智能体构建持久化共享记忆中枢 如果你正在构建或使用基于LangGraph、CrewAI、AutoGen这类框架的多智能体系统,或者你厌倦了每次与Claude、Cursor等AI助手开启新会话时都要重复解释项目背景,那么你很可能正面临一个核心痛点&…...
)
OpenClaw Windows11 保姆级安装部署教程(专属优化、一次成功)
OpenClaw Windows11 保姆级安装部署教程(专属优化、一次成功)一、前言OpenClaw(圈内俗称「小龙虾」)是 GitHub 星标 28W 的开源本地 AI 智能体,主打全自动电脑操控能力,支持自动操作电脑、整理文件、浏览器…...

基于微信小程序的校园水果配送商城毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于微信小程序的校园水果配送商城系统以解决传统校园水果采购与配送模式中存在的效率低下问题。当前高校后勤管理普遍面临供应链管理复杂、信…...
| 系统提权)
渗透测试技巧(七)| 系统提权
系统提权基础 实战过程中,你通过漏洞(上传漏洞、弱口令、Web 漏洞)打进服务器,一般只能对应应用服务的账户权限。这个权限常常属于低权限账户,无法查看账号密码、配置系统文件、获取敏感数据等,这时就需要提权!提权就是把低权限账号升级为系统最高权限,从而完全控制服…...

基于 base-admin 人事管理系统开源项目学习与功能扩展实战笔记
最近跟着课程实战拆解了base-admin 人事管理系统开源项目,这是一款基于 SpringBoot 搭建的企业级后台管理平台,遵循 Apache 2.0 开源协议,非常适合 Java 后端和软件工程入门练手。项目整体采用经典三层架构,Controller、Service、…...