T4打卡 学习笔记
所用环境
● 语言环境:Python3.11
● 编译器:jupyter notebook
● 深度学习框架:TensorFlow2.16.1
● 显卡(GPU):NVIDIA GeForce RTX 2070
设置GPU
from tensorflow import keras
from tensorflow.keras import layers,models
import os, PIL, pathlib
import matplotlib.pyplot as plt
import tensorflow as tfgpus = tf.config.list_physical_devices("GPU")if gpus:gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPUtf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpu0],"GPU")gpus
[]
导入数据
data_dir = r"C:\Users\11054\Desktop\kLearning\p4_learning\data"data_dir = pathlib.Path(data_dir)
查看数据
image_count = len(list(data_dir.glob('*/*.jpg')))print("图片总数为:",image_count)
图片总数为: 2142
Monkeypox = list(data_dir.glob('Monkeypox/*.jpg'))
PIL.Image.open(str(Monkeypox[0]))

batch_size = 32
img_height = 224
img_width = 224
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=123,image_size=(img_height, img_width),batch_size=batch_size)
Found 2142 files belonging to 2 classes.
Using 1714 files for training.
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed=123,image_size=(img_height, img_width),batch_size=batch_size)
Found 2142 files belonging to 2 classes.
Using 428 files for validation.
class_names = train_ds.class_names
print(class_names)
['Monkeypox', 'Others']
plt.figure(figsize=(20, 10))for images, labels in train_ds.take(1):for i in range(20):ax = plt.subplot(5, 10, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[labels[i]])plt.axis("off")

for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break
(32, 224, 224, 3)
(32,)
配置数据集
# def mean_std_normalize(image):
# return image / 255
#
# train_ds = train_ds.map(lambda x, y: (mean_std_normalize(x), y))
# val_ds = val_ds.map(lambda x, y: (mean_std_normalize(x), y))
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
构建CNN网络
num_classes = 2"""
关于卷积核的计算不懂的可以参考文章:https://blog.csdn.net/qq_38251616/article/details/114278995layers.Dropout(0.4) 作用是防止过拟合,提高模型的泛化能力。
在上一篇文章花朵识别中,训练准确率与验证准确率相差巨大就是由于模型过拟合导致的关于Dropout层的更多介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/115826689
"""model = models.Sequential([layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)),layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样layers.Dropout(0.4),layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3layers.Dropout(0.3),layers.Flatten(), # Flatten层,连接卷积层与全连接层layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取layers.Dense(num_classes) # 输出层,输出预期结果
])model.summary() # 打印网络结构
Model: "sequential_13"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩ │ rescaling_2 (Rescaling) │ (None, 224, 224, 3) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ conv2d_39 (Conv2D) │ (None, 222, 222, 16) │ 448 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ average_pooling2d_26 │ (None, 111, 111, 16) │ 0 │ │ (AveragePooling2D) │ │ │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ conv2d_40 (Conv2D) │ (None, 109, 109, 32) │ 4,640 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ average_pooling2d_27 │ (None, 54, 54, 32) │ 0 │ │ (AveragePooling2D) │ │ │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dropout_26 (Dropout) │ (None, 54, 54, 32) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ conv2d_41 (Conv2D) │ (None, 52, 52, 64) │ 18,496 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dropout_27 (Dropout) │ (None, 52, 52, 64) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ flatten_13 (Flatten) │ (None, 173056) │ 0 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dense_26 (Dense) │ (None, 128) │ 22,151,296 │ ├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤ │ dense_27 (Dense) │ (None, 2) │ 258 │ └──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 22,175,138 (84.59 MB)
Trainable params: 22,175,138 (84.59 MB)
Non-trainable params: 0 (0.00 B)
编译
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=1e-4)model.compile(optimizer=opt,loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])
训练模型
from tensorflow.keras.callbacks import ModelCheckpointepochs = 50checkpoint = ModelCheckpoint(filepath='best_model.weights.h5', # Change to .weights.h5save_weights_only=True,monitor='val_loss',mode='min',save_best_only=True
)history = model.fit(train_ds,validation_data=val_ds,epochs=epochs,callbacks=[checkpoint])
Epoch 1/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m16s[0m 257ms/step - accuracy: 0.5094 - loss: 0.7558 - val_accuracy: 0.5350 - val_loss: 0.6751
Epoch 2/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 262ms/step - accuracy: 0.5925 - loss: 0.6632 - val_accuracy: 0.6005 - val_loss: 0.6564
Epoch 3/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 255ms/step - accuracy: 0.6289 - loss: 0.6556 - val_accuracy: 0.6308 - val_loss: 0.6436
Epoch 4/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m15s[0m 279ms/step - accuracy: 0.6565 - loss: 0.6333 - val_accuracy: 0.6402 - val_loss: 0.6487
Epoch 5/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 251ms/step - accuracy: 0.6738 - loss: 0.6020 - val_accuracy: 0.6963 - val_loss: 0.5978
Epoch 6/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 253ms/step - accuracy: 0.6961 - loss: 0.5812 - val_accuracy: 0.6659 - val_loss: 0.6477
Epoch 7/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m13s[0m 243ms/step - accuracy: 0.7291 - loss: 0.5505 - val_accuracy: 0.6752 - val_loss: 0.6096
Epoch 8/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m13s[0m 248ms/step - accuracy: 0.7211 - loss: 0.5350 - val_accuracy: 0.7196 - val_loss: 0.5285
Epoch 9/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m13s[0m 247ms/step - accuracy: 0.7731 - loss: 0.4832 - val_accuracy: 0.7243 - val_loss: 0.5279
Epoch 10/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m13s[0m 250ms/step - accuracy: 0.7680 - loss: 0.4829 - val_accuracy: 0.7383 - val_loss: 0.4957
Epoch 11/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m13s[0m 240ms/step - accuracy: 0.7907 - loss: 0.4464 - val_accuracy: 0.7336 - val_loss: 0.4979
Epoch 12/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m13s[0m 246ms/step - accuracy: 0.8025 - loss: 0.4156 - val_accuracy: 0.7500 - val_loss: 0.4833
Epoch 13/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m10s[0m 175ms/step - accuracy: 0.8184 - loss: 0.4268 - val_accuracy: 0.7944 - val_loss: 0.4716
Epoch 14/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m7s[0m 128ms/step - accuracy: 0.8452 - loss: 0.3810 - val_accuracy: 0.7991 - val_loss: 0.4530
Epoch 15/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m7s[0m 127ms/step - accuracy: 0.8464 - loss: 0.3660 - val_accuracy: 0.7827 - val_loss: 0.4764
Epoch 16/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m10s[0m 181ms/step - accuracy: 0.8320 - loss: 0.3806 - val_accuracy: 0.7967 - val_loss: 0.4451
Epoch 17/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 255ms/step - accuracy: 0.8550 - loss: 0.3492 - val_accuracy: 0.7897 - val_loss: 0.4656
Epoch 18/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 250ms/step - accuracy: 0.8770 - loss: 0.3161 - val_accuracy: 0.7477 - val_loss: 0.4867
Epoch 19/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 268ms/step - accuracy: 0.8535 - loss: 0.3309 - val_accuracy: 0.8154 - val_loss: 0.4552
Epoch 20/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 266ms/step - accuracy: 0.8941 - loss: 0.2848 - val_accuracy: 0.7967 - val_loss: 0.4495
Epoch 21/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 256ms/step - accuracy: 0.8743 - loss: 0.2957 - val_accuracy: 0.8131 - val_loss: 0.4250
Epoch 22/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m13s[0m 245ms/step - accuracy: 0.8794 - loss: 0.2941 - val_accuracy: 0.8201 - val_loss: 0.4460
Epoch 23/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 252ms/step - accuracy: 0.8551 - loss: 0.3300 - val_accuracy: 0.8294 - val_loss: 0.4210
Epoch 24/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 251ms/step - accuracy: 0.8998 - loss: 0.2713 - val_accuracy: 0.8131 - val_loss: 0.4808
Epoch 25/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m13s[0m 246ms/step - accuracy: 0.8802 - loss: 0.2752 - val_accuracy: 0.7897 - val_loss: 0.5133
Epoch 26/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 253ms/step - accuracy: 0.8714 - loss: 0.2991 - val_accuracy: 0.8481 - val_loss: 0.4189
Epoch 27/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m13s[0m 248ms/step - accuracy: 0.9051 - loss: 0.2461 - val_accuracy: 0.8435 - val_loss: 0.4028
Epoch 28/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m13s[0m 242ms/step - accuracy: 0.8978 - loss: 0.2519 - val_accuracy: 0.8411 - val_loss: 0.4060
Epoch 29/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m13s[0m 242ms/step - accuracy: 0.9127 - loss: 0.2319 - val_accuracy: 0.8294 - val_loss: 0.4254
Epoch 30/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m13s[0m 246ms/step - accuracy: 0.9162 - loss: 0.2175 - val_accuracy: 0.8575 - val_loss: 0.4212
Epoch 31/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 255ms/step - accuracy: 0.9306 - loss: 0.1994 - val_accuracy: 0.8435 - val_loss: 0.4504
Epoch 32/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m13s[0m 246ms/step - accuracy: 0.9094 - loss: 0.2175 - val_accuracy: 0.8294 - val_loss: 0.4103
Epoch 33/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 252ms/step - accuracy: 0.9161 - loss: 0.1994 - val_accuracy: 0.8481 - val_loss: 0.3999
Epoch 34/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m13s[0m 249ms/step - accuracy: 0.9201 - loss: 0.1888 - val_accuracy: 0.8341 - val_loss: 0.4599
Epoch 35/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 250ms/step - accuracy: 0.9113 - loss: 0.2096 - val_accuracy: 0.8178 - val_loss: 0.4632
Epoch 36/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 251ms/step - accuracy: 0.9378 - loss: 0.1745 - val_accuracy: 0.8551 - val_loss: 0.4268
Epoch 37/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 255ms/step - accuracy: 0.9438 - loss: 0.1538 - val_accuracy: 0.8575 - val_loss: 0.4274
Epoch 38/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 253ms/step - accuracy: 0.9433 - loss: 0.1420 - val_accuracy: 0.8364 - val_loss: 0.4363
Epoch 39/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 252ms/step - accuracy: 0.9325 - loss: 0.1676 - val_accuracy: 0.8458 - val_loss: 0.4268
Epoch 40/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 251ms/step - accuracy: 0.9487 - loss: 0.1396 - val_accuracy: 0.8458 - val_loss: 0.4373
Epoch 41/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 252ms/step - accuracy: 0.9435 - loss: 0.1709 - val_accuracy: 0.8481 - val_loss: 0.4572
Epoch 42/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m13s[0m 249ms/step - accuracy: 0.9519 - loss: 0.1419 - val_accuracy: 0.8435 - val_loss: 0.4637
Epoch 43/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 256ms/step - accuracy: 0.9304 - loss: 0.1656 - val_accuracy: 0.8248 - val_loss: 0.5690
Epoch 44/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 252ms/step - accuracy: 0.9233 - loss: 0.2013 - val_accuracy: 0.8551 - val_loss: 0.4235
Epoch 45/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 252ms/step - accuracy: 0.9634 - loss: 0.1338 - val_accuracy: 0.8481 - val_loss: 0.4394
Epoch 46/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 251ms/step - accuracy: 0.9442 - loss: 0.1380 - val_accuracy: 0.8458 - val_loss: 0.4698
Epoch 47/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 254ms/step - accuracy: 0.9368 - loss: 0.1555 - val_accuracy: 0.8458 - val_loss: 0.4358
Epoch 48/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 253ms/step - accuracy: 0.9529 - loss: 0.1199 - val_accuracy: 0.8505 - val_loss: 0.4860
Epoch 49/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 251ms/step - accuracy: 0.9416 - loss: 0.1373 - val_accuracy: 0.8528 - val_loss: 0.4813
Epoch 50/50
[1m54/54[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m14s[0m 255ms/step - accuracy: 0.9595 - loss: 0.1228 - val_accuracy: 0.8621 - val_loss: 0.4528
模型评估
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(epochs)plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

使用模型预测
# 加载效果最好的模型权重
model.load_weights('best_model.weights.h5')
from PIL import Image
import numpy as npimg = Image.open(r"C:\Users\11054\Desktop\kLearning\p4_learning\data\Others\NM01_01_00.jpg")
image = tf.image.resize(img, [img_height, img_width])img_array = tf.expand_dims(image, 0)predictions = model.predict(img_array) # 这里选用你已经训练好的模型
print("预测结果为:",class_names[np.argmax(predictions)])
[1m1/1[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 86ms/step
预测结果为: Others
个人总结
使用了新版本的tensorflow,layers.Rescaling(1./255, input_shape=(img_height, img_width, 3))方法与旧版本调用有所不同,尝试了将归一化注释,结果显示收敛精度显著降低
相关文章:
T4打卡 学习笔记
所用环境 ● 语言环境:Python3.11 ● 编译器:jupyter notebook ● 深度学习框架:TensorFlow2.16.1 ● 显卡(GPU):NVIDIA GeForce RTX 2070 设置GPU from tensorflow import keras from tensorflow.keras…...
抖音矩阵云混剪系统源码 短视频矩阵营销系统V2(全开源版)
>>>系统简述: 抖音阵营销系统多平台多账号一站式管理,一键发布作品。智能标题,关键词优化,排名查询,混剪生成原创视频,账号分组,意向客户自动采集,智能回复,多…...
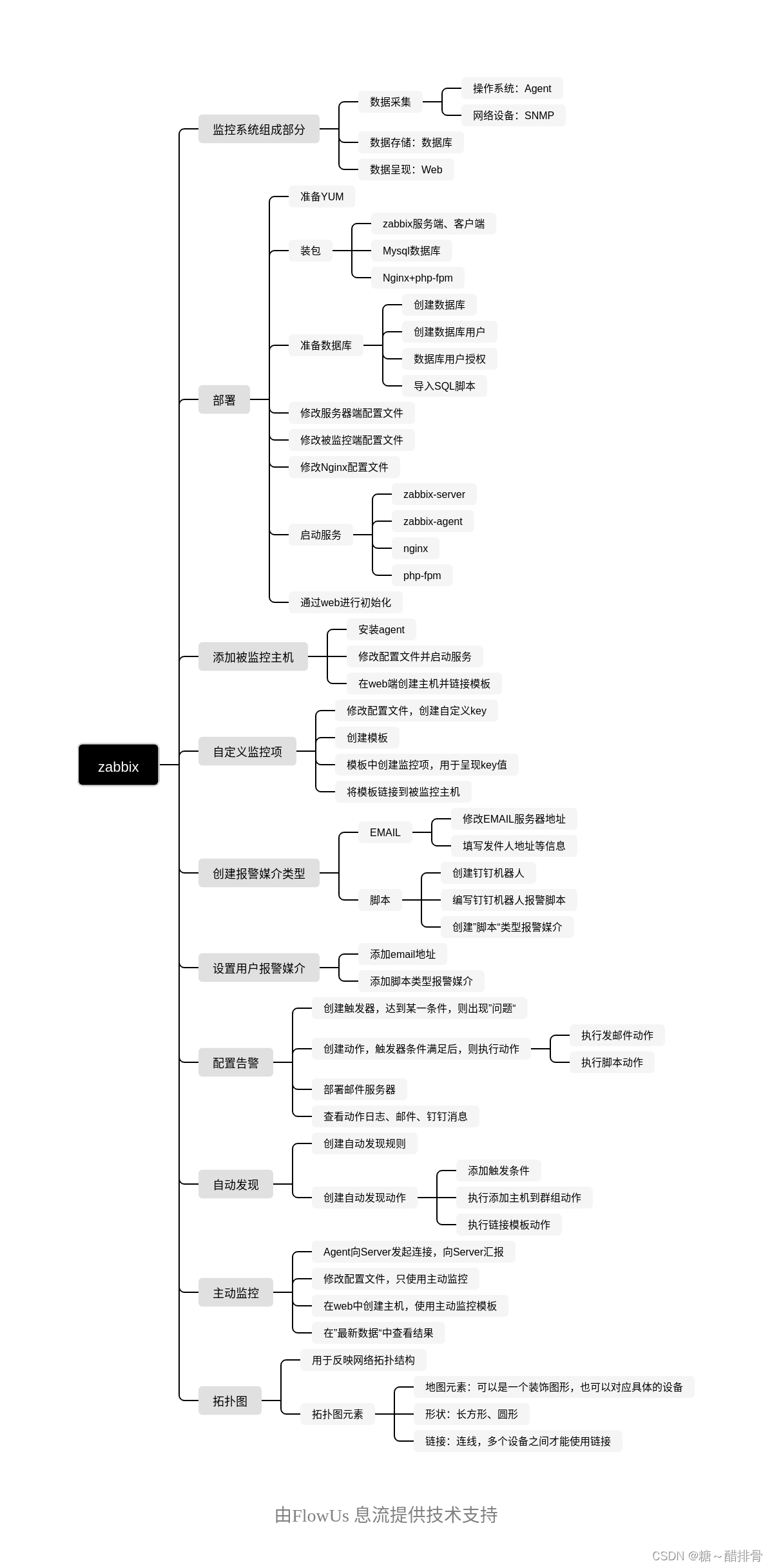
zabbix报警机制
zabbix思路流程...

【Matlab】-- 飞蛾扑火优化算法
文章目录 文章目录 01 飞蛾扑火算法介绍02 飞蛾扑火算法伪代码03 基于Matlab的部分飞蛾扑火MFO算法04 参考文献 01 飞蛾扑火算法介绍 飞蛾扑火算法(Moth-Flame Optimization,MFO)是一种基于自然界飞蛾行为的群体智能优化算法。该算法由 Sey…...

全面体验ONLYOFFICE 8.1版本桌面编辑器
ONLYOFFICE官网 在当今的数字化办公环境中,选择合适的文档处理工具对于提升工作效率和团队协作至关重要。ONLYOFFICE 8.1版本桌面编辑器,作为一款集成了多项先进功能的办公软件,为用户提供了全新的办公体验。今天,我们将深入探索…...

建议csdn赶紧将未经作者同意擅自锁住收费的文章全部解锁,别逼我用极端手段让你们就范
前两天我偶然发现csdn竟然将我以前发表的很多文章锁住向读者收费才让看。 csdn这种无耻行径往小了说是侵犯了作者的版权著作权,往大了说这是在打击我国IT领域未来的发展,因为每一个做过编程工作的人都知道,任何一个程序员的学习成长过程都少不…...

Pycharm一些问题解决办法
研究生期间遇到关于Pycharm一些问题报错以及解决办法的汇总 ModuleNotFoundError: No module named sklearn’ 安装机器学习库,需要注意报错的sklearn是scikit-learn缩写。 pip install scikit-learnPyCharm 导包提示 unresolved reference 描述:模块…...
ONLYOFFICE 桌面编辑器 8.1 发布:全新 PDF 编辑器、幻灯片版式、增强 RTL 支持及更多本地化选项
目录 什么是ONLYOFFICE? ONLYOFFICE 主要特点包括: 官网信息: 1. 功能齐全的 PDF 编辑器 1.1 编辑 PDF 文本 1.2 插入和修改对象 1.3 创建和填写表单 2. 幻灯片版式功能 2.1 快速应用幻灯片版式 2.2 动画窗格的改进 3. 文档编辑、…...
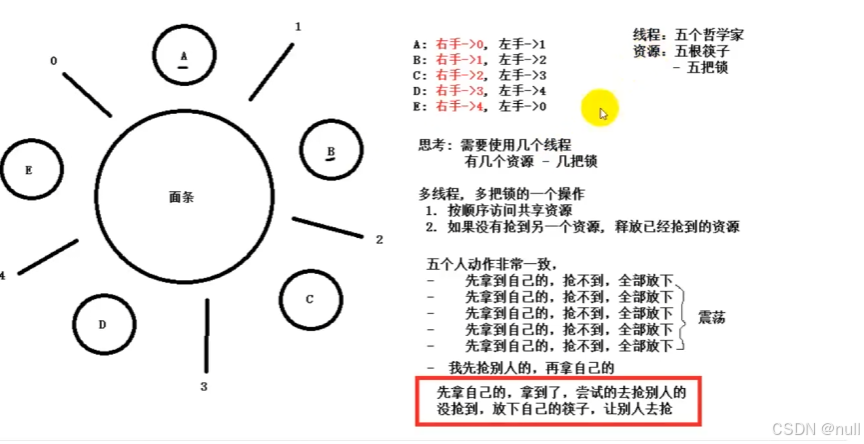
Linux高并发服务器开发(六)线程
文章目录 1. 前言2 线程相关操作3 线程的创建4 进程数据段共享和回收5 线程分离6 线程退出和取消7 线程属性(了解)8 资源竞争9 互斥锁9.1 同步与互斥9.2 互斥锁 10 死锁11 读写锁12 条件变量13 生产者消费者模型14 信号量15 哲学家就餐 1. 前言 进程是C…...
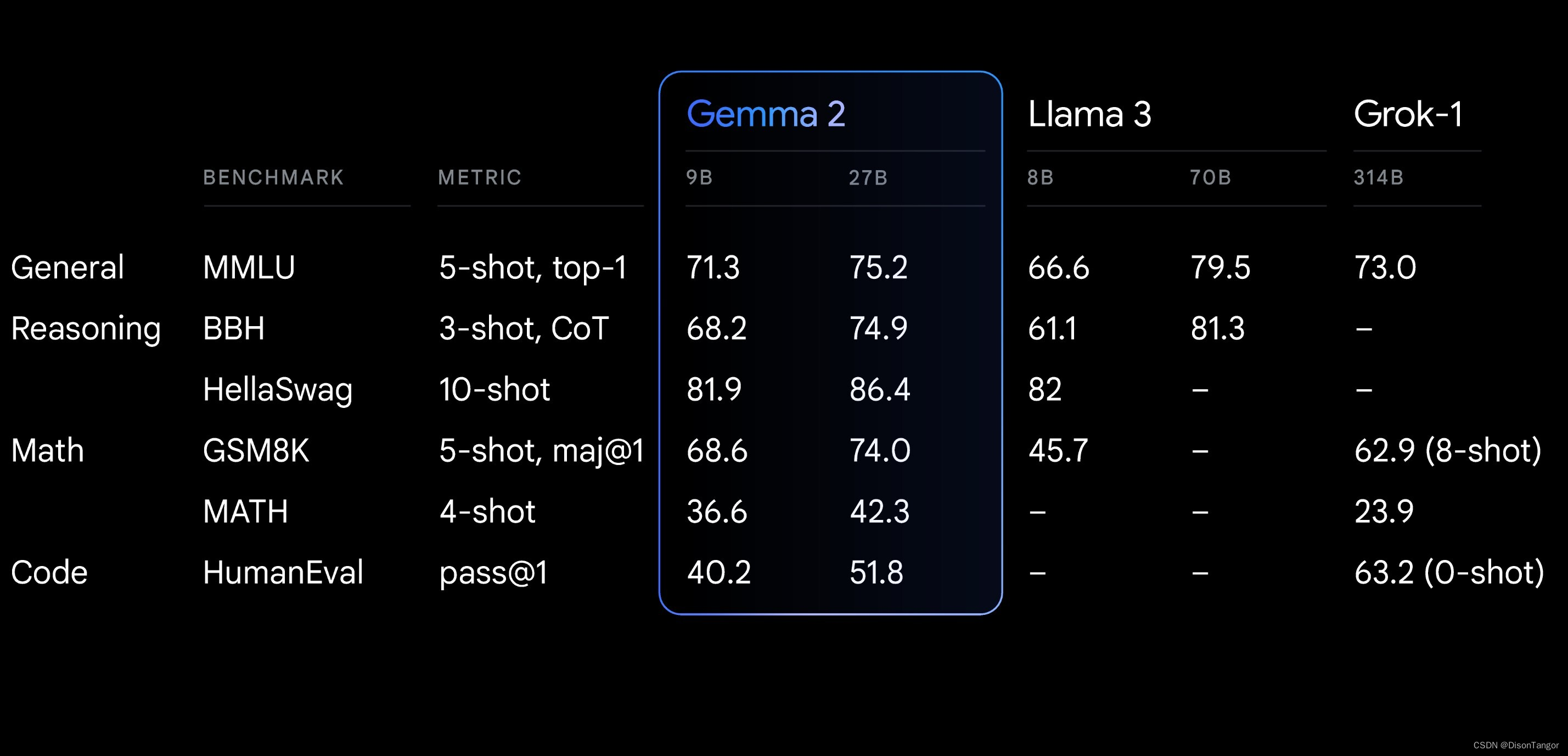
Google发布Gemma 2轻量级开放模型 以极小的成本提供强大的性能
除了 Gemini 系列人工智能模型外,Google还提供 Gemma 系列轻量级开放模型。今天,他们发布了 Gemma 2,这是基于全新架构设计的下一代产品,具有突破性的性能和效率。 Gemma 2 有两种规格:90 亿 (9B) 和 270 亿 (27B) 个参…...
精品UI知识付费系统源码网站EyouCMS模版源码
这是一款知识付费平台模板,后台可上传本地视频,批量上传视频连接, 视频后台可设计权限观看,免费试看时间时长,会员等级观看,付费观看等功能, 也带软件app权限下载,帮助知识教育和软件…...

使用Apache POI库在Java中导出Excel文件的详细步骤
使用Apache POI库在Java中导出Excel文件的详细步骤 学习总结 1、掌握 JAVA入门到进阶知识(持续写作中……) 2、学会Oracle数据库入门到入土用法(创作中……) 3、手把手教你开发炫酷的vbs脚本制作(完善中……) 4、牛逼哄哄的 IDEA编程利器技…...

基于C#在WPF中使用斑马打印机进行打印
最近在项目中接手了一个比较有挑战性的模块——用斑马打印机将需要打印的内容打印出来。苦苦折腾了两天,总算有所收获,就发到网上来骗骗分数-_-|| 项目中使用的打印机型号为GX430t的打印机,接手的时候,自己对于打印机这块儿是眼前…...

六、资产安全—信息分级资产管理与隐私保护练习题(CISSP)
六、资产安全—信息分级资产管理与隐私保护(CISSP): 六、资产安全—信息分级资产管理与隐私保护(C...

使用 AutoGen 的 AI 智能体设计模式
1.Auto Gen框架 在Auto中,每种智能体分别扮演不同的角色。 ConversableAgent 作为最高级别的智能体抽象,为所有具体智能体提供了基础的通信能力。这包括发送和接收信息的能力,以及基于这些信息进行内部状态更新的能力。所有从这个类派生的智能体都继承了这些基本功能…...

Android InputChannel连接
InputChannel是InputDispatcher 和应用程序 (InputTarget) 的通讯桥梁,InputDispatcher 通知应用程序有输入事件,通过InputChannel中的socket进行通信。 连接InputDispatcher和窗口 WinodwManagerService:addwindow: WMS 添加窗口时,会创建…...

爬虫笔记17——selenium框架的使用
selenium框架的使用 1、python程序安装selenium框架2、下载Chrome谷歌驱动3、selenium的基本使用4、多个标签页切换顺序混乱的问题 1、python程序安装selenium框架 # 在安装过程中最好限定框架版本为4.9.1 # pip install selenium 没有制定版本,非镜像下载也会比较…...

[BUUCTF从零单排] Web方向 02.Web入门篇之『常见的搜集』解题思路(dirsearch工具详解)
这是作者新开的一个专栏《BUUCTF从零单排》,旨在从零学习CTF知识,方便更多初学者了解各种类型的安全题目,后续分享一定程度会对不同类型的题目进行总结,并结合CTF书籍和真实案例实践,希望对您有所帮助。当然࿰…...
深度相机识别物体——实现数据集准备与数据集分割
一、数据集准备——Labelimg进行标定 1.安装labelimg——pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple 2.建立相应的数据集存放文件夹 3.打开labelimg,直接在命令行输入labelimg即可,并初始化 4.开始标注,设置标注好…...

STM32第十一课:ADC采集光照
文章目录 需求一、ADC概要二、实现流程1.开时钟,分频,配IO2.配置ADC工作模式3.配置通道4.复位校准5.数值的获取 三、需求的实现总结 需求 通过ADC转换实现光照亮度的数字化测量,最后将实时测量的结果打印在串口上。 一、ADC概要 ADC全称是A…...

利用Taotoken模型广场为不同业务场景快速选型合适模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为不同业务场景快速选型合适模型 为聊天机器人、代码生成助手或内容创作工具挑选一个合适的大模型࿰…...

如何用嘎嘎降AI处理期刊投稿论文:SCI核心期刊论文全流程降AI4.8元完整操作教程
如何用嘎嘎降AI处理期刊投稿论文:SCI核心期刊论文全流程降AI4.8元完整操作教程 第一次用降AI工具会遇到很多不确定的地方——传什么格式、选哪个模式、怎么验收效果。 这篇教程把常见问题都覆盖了,主要基于嘎嘎降AI(www.aigcleaner.com&…...

ARM7TDMI AHB Wrapper设计与时钟门控技术解析
1. ARM7TDMI AHB Wrapper架构概述在嵌入式处理器设计中,总线接口单元(BIU)作为处理器核与系统总线之间的桥梁,其设计质量直接影响整个系统的性能和可靠性。ARM7TDMI处理器采用的AHB Wrapper设计,通过精妙的时钟控制和状…...

3PEAK思瑞浦 TP2272-SO1R SOP8 精密运放
特性 增益带宽积:7MHz 高斜率:20V/us 宽电源范围:3.1V至36V或2.25V至18V 低失调电压:0.5mV(最大值) 低输入偏置电流:30pA(典型值) 轨到轨输出电压范围 单位增益稳定: 工作温度范围:-40C至125C...
【玩转PB级数仓GaussDB(DWS)】)
windows系统下操作GaussDB(DWS)【玩转PB级数仓GaussDB(DWS)】
数据仓库服务GaussDB(DWS) 是一种基于华为云基础架构和平台的在线数据处理数据库,提供即开即用、可扩展且完全托管的分析型数据库服务。GaussDB(DWS)是基于华为融合数据仓库GaussDB产品的云原生服务 ,兼容标准ANSI SQL 99和SQL 2003,同时兼容…...

NoFences终极指南:免费开源桌面分区工具彻底解决Windows桌面混乱问题
NoFences终极指南:免费开源桌面分区工具彻底解决Windows桌面混乱问题 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为杂乱的Windows桌面而烦恼吗࿱…...

如何用FanControl终极解决Windows风扇噪音与散热难题
如何用FanControl终极解决Windows风扇噪音与散热难题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanControl.…...

如何5步掌握ComfyUI MixLab插件:打造专业AI创作工作流的完整指南
如何5步掌握ComfyUI MixLab插件:打造专业AI创作工作流的完整指南 【免费下载链接】comfyui-mixlab-nodes Workflow-to-APP、ScreenShare&FloatingVideo、GPT & 3D、SpeechRecognition&TTS 项目地址: https://gitcode.com/gh_mirrors/co/comfyui-mixla…...

3步快速上手:Windows电脑直接安装安卓应用的终极指南
3步快速上手:Windows电脑直接安装安卓应用的终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否渴望在Windows电脑上直接运行安卓应用ÿ…...
JiT源码深度剖析:从Denoiser到Transformer的完整实现
JiT源码深度剖析:从Denoiser到Transformer的完整实现 【免费下载链接】JiT PyTorch implementation of JiT https://arxiv.org/abs/2511.13720 项目地址: https://gitcode.com/gh_mirrors/jit8/JiT JiT(Just image Transformer)是一个…...