多线程引发的安全问题
前言👀~
上一章我们介绍了线程的一些基础知识点,例如创建线程、查看线程、中断线程、等待线程等知识点,今天我们讲解多线程下引发的安全问题
线程安全(最复杂也最重要)
产生线程安全问题的原因
锁(重要)
synchronized 的特性
互斥性
刷新内存
可重入
死锁(重要)
volatile(重要)
JMM
volatile 和 synchronized 的区别
wait和notify方法
wait方法
notify方法
线程饿死
notifyAll方法
wait和sleep的区别
如果各位对文章的内容感兴趣的话,请点点小赞,关注一手不迷路,讲解的内容我会搭配我的理解用我自己的话去解释如果有什么问题的话,欢迎各位评论纠正 🤞🤞🤞
个人主页:N_0050-CSDN博客
相关专栏:java SE_N_0050的博客-CSDN博客 java数据结构_N_0050的博客-CSDN博客 java EE_N_0050的博客-CSDN博客

线程安全(最复杂也最重要)
首先我们来看下面这段代码,猜一下它的输出结果
public class Test2 {public static int count;public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {for (int i = 0; i < 15000; i++) {count++;}});Thread t2 = new Thread(() -> {for (int i = 0; i < 15000; i++) {count++;}});t1.start();t2.start();t1.join();t2.join();System.out.println(count);}
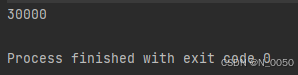
}输出结果:小于30000 不信的话可以去试试
按道理应该是输出3000啊为什么呢?这是由于多线程不安全问题的原因,执行的顺序是随机的!!!多核心cpu处理不同的线程和单线程处理不同的线程都可能会引发线程不安全。首先就count++这个操作在cpu进行处理的时候会分为三个步骤,先拿操作数count然后自增最后保存到内存中。下图中只有前两个执行顺序是正确的,其他都是错误的。
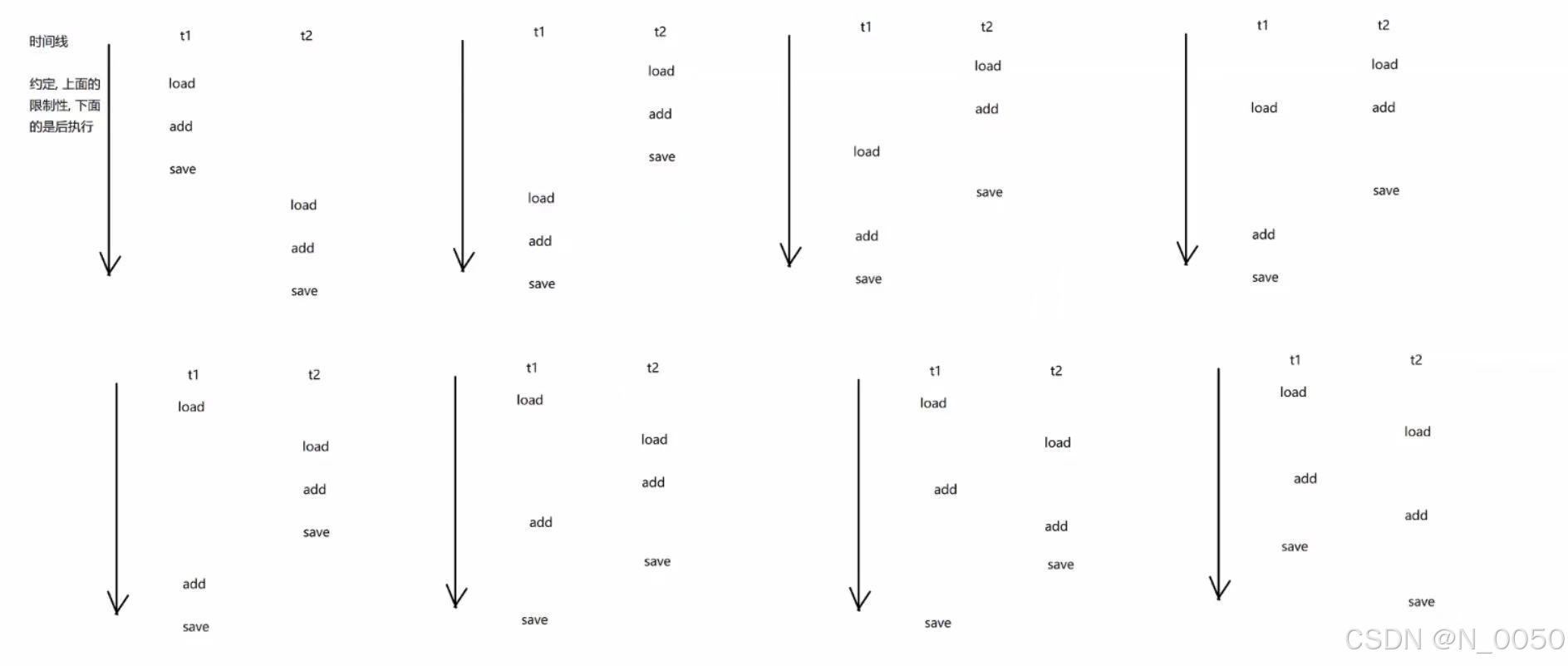
我们接着拆解细分,如果cpu都是按这个顺序去处理的话结果应该是预期的30000
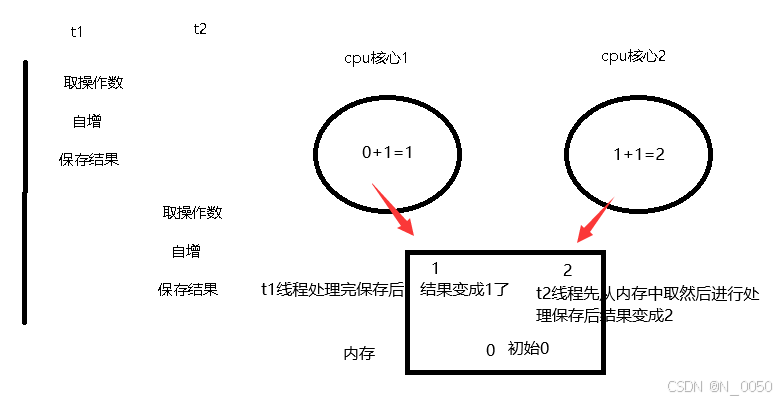
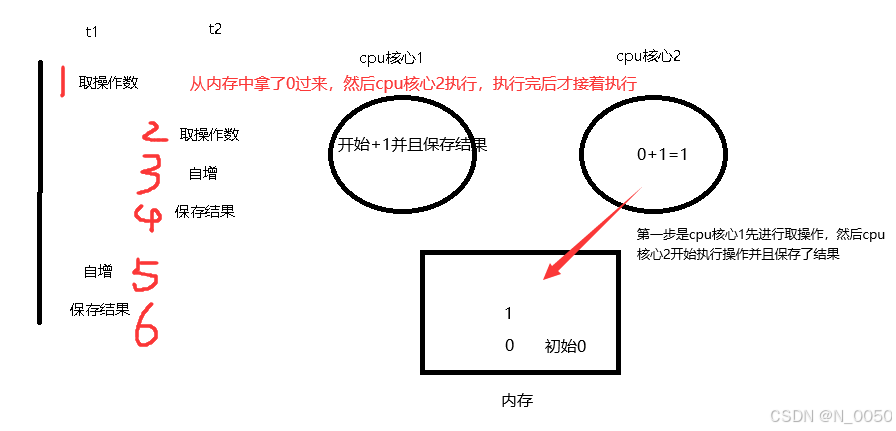
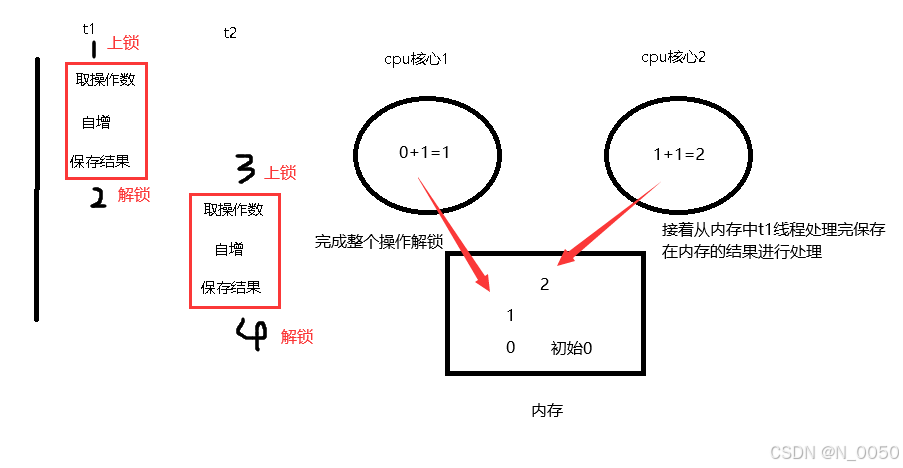
接着是不按套路出牌的,如下图所示,各执行了一次自增的操作但是结果count还是为1,这是因为不管单核心还是多核心在处理多线程时可能会被打断去执行其他线程的任务,都是因为该死的操作系统的调度器回根据一定的策略来分配cpu时间给不同的线程,导致执行的顺序是随机的不确定的
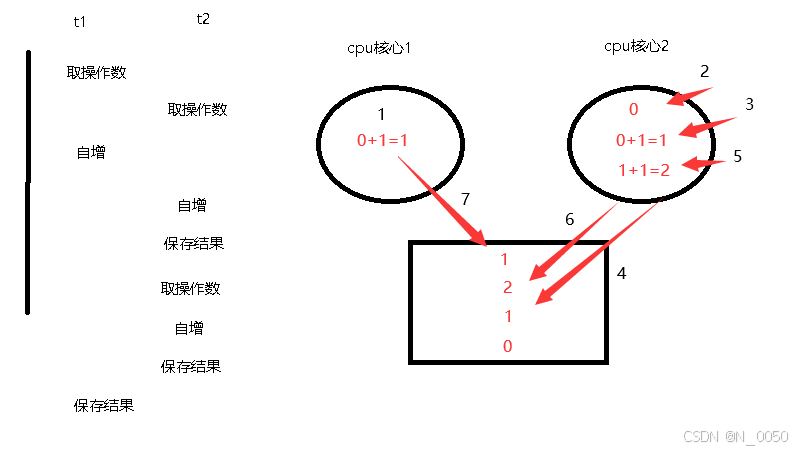
并且可能会出现结果小于15000,原因是因为可能在执行t1线程执行自增的操作后,然后去执行t2线程并且执行了两次自增,最后相当于就自增一次,如下图所示按照我标注的顺序看就能发现了
产生线程安全问题的原因
1.操作系统中线程调度的顺序是随机的(抢占式执行)
2.不同线程针对同一变量进行修改
3.修改操作不是原子级的(先读再修改),类似数据库的原子性
4.内存可见性问题
5.指令重排序问题
我们该如何解决呢?跟数据库类似加锁!
锁(重要)
通过加锁解决上述问题,如何给java中的代码加锁呢?
1.synchronized()关键字(最常用的办法):使用synchronized的时候搭配代码块{}使用,进入这个代码块就是加锁,出了代码块就是解锁。后面进行解释
还是刚才的代码我们给它加上锁看看结果
public class Test2 {public static int count;public static void main(String[] args) throws InterruptedException {Object lock = new Object();Thread t1 = new Thread(() -> {for (int i = 0; i < 15000; i++) {synchronized (lock) {count++;}}});Thread t2 = new Thread(() -> {for (int i = 0; i < 15000; i++) {synchronized (lock) {count++;}}});t1.start();t2.start();t1.join();t2.join();System.out.println(count);}
}输出结果,我们会发现这回输出的结果符合预期就是30000
为什么加锁了结果就正确了呢?看了下面的图你就能明白了,不明白的话我举个例子你去银行的ATM取款机取钱,你进入这个ATM就相当于加锁了这时候别人进不来,只能等你存或取完钱了然后出来了才能进去
synchronized 的特性
互斥性
重点就是我们并不关注这个锁对象,关注的是不同线程的锁对象是不是同一对象。
如果当前线程进入加锁的状态,另外一个线程也尝试进行加锁,就会产生锁冲突/锁竞争,后面这个线程就会阻塞等待,等到前一个线程解锁为止。synchronized后面的括号()是填需要进行加锁的对象,对象不重要,重要的是通过这个对象用来区分两个线程是否在竞争同一个锁。如果两个线程针对同一个对象加锁的时候,会有锁冲突/锁竞争。如果不是就没有锁竞争,仍然并发执行。有了这样的规则就把并发执行转为串行执行。抓住一个原则就是两个线程是不是针对同一个对象加锁!
还是刚才那段代码这也是为什么最后执行结果和我们预期的相符合的,就是因为锁的是对象是同一个,导致另外一个线程进入阻塞状态,等上个线程解锁了才能上锁
public class Test2 {public static int count;public static void main(String[] args) throws InterruptedException {Object lock = new Object();Thread t1 = new Thread(() -> {for (int i = 0; i < 15000; i++) {synchronized (lock) {count++;}}});Thread t2 = new Thread(() -> {for (int i = 0; i < 15000; i++) {synchronized (lock) {count++;}}});t1.start();t2.start();t1.join();t2.join();System.out.println(count);}
}注意1:上一个线程解锁之后, 下一个线程并不是立即就能获取到锁. 而是要靠操作系统来 "唤醒". 这也就是操作系统线程调度的一部分工作
注意2:假设有 A B C 三个线程, 线程 A 先获取到锁, 然后 B 尝试获取锁, 然后 C 再尝试获取锁, 此时 B 和 C 都在阻塞队列中排队等待. 但是当 A 释放锁之后, 虽然 B 比 C 先来的, 但是 B 不一定就能获取到锁, 而是和 C 重新竞争, 并不遵守先来后到的规则。这就是之前说的系统调度的随机性
对象头:
synchronized用的锁是存在Java对象头里的,java的一个对象,对应的内存空间中除了你自己定义的属性之外还有自带的属性。这些自带的属性就可以称为对象头中,对象头中,其中有属性表示当前对象是否加锁

对象头可以简单理解为, 每个对象在内存中存储的时候, 都存有一块内存表示当前的 "锁定" 状态,就像公共厕所的把手的颜色,红色代表有人你要等人出来了才能进去,绿色就是可以直接进去
补充:synchronized 除了可以修饰代码块,还可以修饰成员方法和静态方法
修饰成员方法:此时this就是锁对象
class Java {public int count;synchronized public void increase() {count++;}//上面是下面的简写public void increase1() {synchronized (this) {count++;}}
}public class Test3 {public static void main(String[] args) {Java java = new Java();java.increase1();System.out.println(java.count);}
}
修饰静态方法:针对类对象加锁
class Java {public static int count;synchronized public static void increase() {count++;}//上面是下面的简写public static void increase1() {synchronized (Java.class) {count++;}}}public class Test3 {public static void main(String[] args) {Java java = new Java();Java.increase1();System.out.println(Java.count);}
}刷新内存
synchronized 的工作过程:
1. 获得互斥锁
2. 从主内存拷贝变量的最新副本到工作的内存
3. 执行代码
4. 将更改后的共享变量的值刷新到主内存
5. 释放互斥锁
所以 synchronized 也能保证内存可见性. 具体代码参见后面 volatile 部分.
可重入
可重入锁:指的是一个线程连续针对一把锁,加锁两次,不会出现死锁,满足这个要求,就是可重入锁,不满足就是不可重入锁(死锁),synchronized不会有这种情况,你可以去试试对两把不同的锁进行加锁
下面这个代码表示的就是可重入锁,对同一线程针对一把锁加锁两次
public class Test2 {public static int count;public static void main(String[] args) throws InterruptedException {Object lock = new Object();Thread t1 = new Thread(() -> {synchronized (lock) {synchronized (lock) {count++;}}});t1.start();t1.join();System.out.println(count);}
}在上面的代码中有没有想过,如果一个锁加锁后另外一个锁怎么进行加锁的?不应该等另外一个锁解锁后,后面这个锁才能进行加锁的嘛?如果是串行的那没什么事情,但是现在是嵌套的并行的情况。代码执行的时候,进入第一层锁到结束的位置我标注1,进入后就视为加锁了,此时第二层锁要想加锁得等第一层锁解锁后才能加锁,按道理应该第二层处于阻塞等待状态。然后接着走我们要想第一层锁解锁,就要把里面的代码执行完才能解锁吧,但是此时第二层怎么执行下去呢?第一层都没解锁第二层怎么能加锁呢?第一层要想解锁还得执行完第二层的代码,此时就出现死锁的情况(线程卡死)
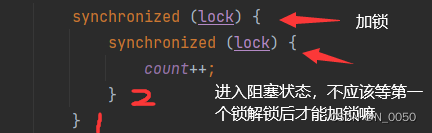
加锁:让锁记录一下是哪个线程把它锁住的,后续如果再进行加锁的时候,如果加锁线程就是持有锁的线程就直接加锁成功。如果是同一线程就直接加锁成功就是说我在一个线程进行加锁后,让锁记录一下是哪个线程把它锁住的,后续再在对这个锁进行加锁的话,直接判断被加锁的线程和要加锁的线程是不是同一个线程,是的话直接加锁并且计数。如果不是当前线程并且被还没解锁,则阻塞当前线程
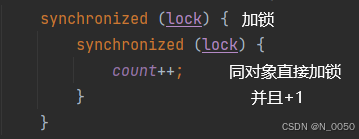
解锁:引入计数,锁会记录当前线程的加锁次数,直到解锁次数与加锁次数匹配时才真正释放锁,就是加锁+1,解锁-1,直至为0才能解锁。直白说要执行到最外层才能解锁
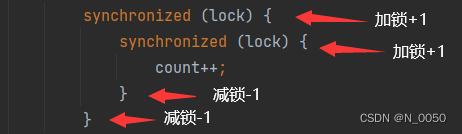
注意:无论是否嵌套,加锁就加1,解锁就减1!!!
死锁(重要)
死锁:可以理解两个渣男都有自己的女朋友的情况下,互相看上对方的女朋友,但是呢这么做不好,只能等,等其中一对分手了才有机会脚踏两条船😂,专业点说就是在多线程的情况下,一个线程持有资源的情况去请求获取另外一个线程持有的资源而而产生的阻塞等待
1.一个线程连续针对一把锁,加锁两次,如果是不可重入锁就是死锁,synchronized不会出现这种情况
2.两个线程,两把锁(无论是不是可重入锁,都会死锁),就是t1线程获取锁A,t2线程获取锁B,t1线程又获取锁B,t2线程获取锁A。什么意思呢?举个例子你此时需要获取两把钥匙,钥匙A用来开门,钥匙B用来开车,此时钥匙A在你手里,可是你要开车又需要钥匙B,但是呢钥匙B被你女朋友获取了在你女朋友那,而恰恰相反她想要钥匙A打开门,而此时你在世界最北端,她在最右端
public class Test2 {public static Object lock1 = new Object();public static Object lock2 = new Object();public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {synchronized (lock1) {try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}synchronized (lock2) {System.out.println("t1加锁成功");}}});Thread t2 = new Thread(() -> {synchronized (lock2) {try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}synchronized (lock1) {System.out.println("t2加锁成功");}}});t1.start();t2.start();t1.join();t2.join();}
}上述代码的输出结果,什么也不会输出,线程卡死了,也就是死锁的情况,因为t1线程先拿到锁lock1然后进入休眠,t2线程拿到锁lock2进入休眠,此时t1线程尝试去拿锁lock2,会发现已经被t2线程拿了,此时要想获取需要等到t2线程解锁后才能获取
解决这个问题的死锁很简单,我把这个休眠方法去掉就行了,这样就变成串行了
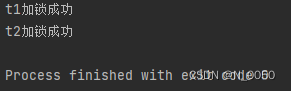
public class Test2 {public static Object lock1 = new Object();public static Object lock2 = new Object();public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {synchronized (lock1) {synchronized (lock2) {System.out.println("t1加锁成功");}}});Thread t2 = new Thread(() -> {synchronized (lock2) {synchronized (lock1) {System.out.println("t2加锁成功");}}});t1.start();t2.start();t1.join();t2.join();}
}输出结果
3.N个线程,M把锁,更容易出现死锁的情况(哲学家就餐问题),这个情况和上面的情况差不多
public class Test2 {public static Object lock1 = new Object();//左筷子 lock3的右筷子public static Object lock2 = new Object();//左筷子 lock3的右筷子public static Object lock3 = new Object();//左筷子 lock2的右筷子public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {synchronized (lock1) {try {Thread.sleep(3000);} catch (InterruptedException e) {throw new RuntimeException(e);}synchronized (lock2) {System.out.println("t1加锁成功");}}});Thread t2 = new Thread(() -> {synchronized (lock2) {try {Thread.sleep(2000);} catch (InterruptedException e) {throw new RuntimeException(e);}synchronized (lock3) {System.out.println("t2加锁成功");}}});Thread t3 = new Thread(() -> {synchronized (lock3) {try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}synchronized (lock1) {System.out.println("t3加锁成功");}}});t1.start();t2.start();t3.start();t1.join();t2.join();t3.join();}
}解释一下为什么上面这段代码会产生死锁,首先t1线程获取一把锁lock1然后进入休眠,接着t2线程获取一把锁lock2然后进入休眠,接着t3线程获取一把锁lock3然后休眠,然后t1线程接着往下执行去获取锁lock2,但是锁lock2被t2线程占着所以无法加锁(无法获取锁lock2)进入阻塞状态后面t2线程和t3线程也是一样的结果,相互之间有依赖关系,最终导致产生死锁,解决办法也很简单把休眠去掉,让一个线程先执行完。
产生死锁的四种必要条件
在上面的讲解中,我们拎出了几种产生死锁的场景。总结一下产生死锁的四种必要条件
1.互斥(锁的机制):当一个线程拿到一把锁之后,另外一个线程再想拿到这把锁,要等到上个线程解锁后才能获取,在此期间这个线程进入阻塞等待
2.不可剥夺(锁的机制):跟上面的差不多意思,就是A线程拿到锁之后,B线程不能把这个锁抢过来,只能等线程A解锁
3.请求和保持(代码结构):一个线程因请求资源而阻塞,并且对已有的资源保持不放。简单点说就是一个线程想要获取多把锁,上面的例子中提到的就是这个问题。t1线程持有锁A的情况又想获取锁B,但此时锁B被线程t2线程占有,t1线程不断请求获取锁B,并且锁A也没有解锁
4.循环等待(代码结构):和上面的情况差不多,只是形成回路了,彼此之间依赖,什么意思呢?t1线程占有锁A,t2线程占有锁B,t3线程占有锁C,此t1线程又想要获取锁B,t2线程又想要获取锁C,t3线程又想要获取锁A
解决死锁
首先根据产生死锁的条件进行分析,第1条和第2条我们无法进行干涉,因为是锁的机制自带的。我们从第3条入手,这种情况我们要避免"锁嵌套的结构",从并行转为串行的结构这样就能解决死锁的问题。但是呢如果有些场景就是这样的结构呢?设置好加锁的顺序,什么意思呢?看下面这段代码
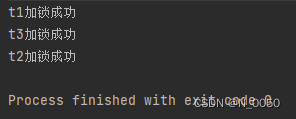
public class Test2 {public static Object lock1 = new Object();//左筷子 lock3的右筷子public static Object lock2 = new Object();//左筷子 lock3的右筷子public static Object lock3 = new Object();//左筷子 lock2的右筷子public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {synchronized (lock1) {synchronized (lock2) {System.out.println("t1加锁成功");}}});Thread t2 = new Thread(() -> {synchronized (lock2) {synchronized (lock3) {System.out.println("t2加锁成功");}}});Thread t3 = new Thread(() -> {synchronized (lock3) {synchronized (lock1) {System.out.println("t3加锁成功");}}});t1.start();t2.start();t3.start();t1.join();t2.join();t3.join();}
}输出结果如下图,我来解释一下,我们先让t1线程拿到锁lock1并且再次拿到锁lock2,然后全拿到后输出语句,完成后解锁。接着让t2线程拿到锁lock2再拿到锁lock3,然后输出语句后解锁。t3线程也是一样。我们会发现没有产生死锁的情况,这就是设置好加锁的顺序,可以理解为先让一个线程拿到想要的所有锁,记住锁的机制(在此间别的锁要想获取这个锁等到这个线程解锁后才能获取),然后等这个线程解锁完后,再让下个线程获取。
volatile(重要)
首先先说volatile关键字的作用保证内存可见性(什么意思呢?直白点说叫编译器别优化,别瞎操心,下面对编译器优化进行了解释)和禁止指令重排序(之后会讲解)
内存可见性问题:在多线程下产生的问题,一个线程进行读,一个线程进行修改产生的内存可见性问题,这个问题需要结合当时的场景进行判断,下面进行详细介绍
首先我们要知道一个问题,我们知道计算机运行的程序/代码,经常需要访问数据,而这些需要处理和访问的数据呢都会先存在内存当中,当我们要进行处理的时候cpu会先从内存当中取数据,就例如count++的操作,count会先放到内存当中,cpu要想处理这个count的话要先从内存中取count放到cpu的寄存器中,然后进行运算。cpu在读取内存的时候,这个速度是很慢的,但是对比读取硬盘肯定是快很多的。cpu一般的操作都是很快的,唯独到了读/写内存的时候,速度就慢下来了。这个问题其实是由于cpu的高速缓存存储器导致的。为了解决上面的问题,编译器会对代码进行优化,对于读/写内存的操作,优化成读取寄存器。这样就能减少读取内存的次数,从而提高程序整体的效率
注意:这里的编译器指的是java中的编译器,java中的编译器有分为 java编译器,也就是我们之前用的javac,另一个就是即时编译器,也就是jit,这里说的编译器就是这个jit
接下来使用代码演示这个问题
public class Test5 {public static int count = 0;public static void main(String[] args) {Thread t1 = new Thread(() -> {while (count == 0) {}System.out.println("结束");});t1.start();Thread t2 = new Thread(() -> {Scanner scanner = new Scanner(System.in);System.out.print("请输入:");count = scanner.nextInt();});t2.start();}
}输出结果
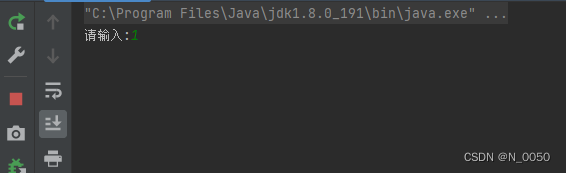
通过jconsole关键发现输入1后t1线程并没有停下来

问题详解:创建t1线程后开始执行任务,进入循环判断满不满足条件,满足则接着执行,不满足则输出结束。就判断条件这个操作在cpu上执行的时候分为两步,一步是load从内存中读取操作数放到寄存器中,一步是cmp比较操作数是不是满足条件,这个速度是很快的,一下子执行了非常多次,不断的重复这两个操作。编译器/JVM发现load这么多次都是一样的结果,于是对其进行优化在执行一次load后后续不再进行load操作,因为一次load操作可以执行很多次cmp操作。就在第一次从内存读取后(编译器是个二百五,无法确定它会什么时候进行优化以及不优化,所以不一定是第一次后,后面也会有例子进行解释),后续不在从内存读取,直接从寄存器中读取。导致内存可见性问题产生,编译器的bug
解决办法
1.解决办法给count使用volatile关键字,让编译器禁止优化问题就解决了,volatile 修饰的变量, 能够保证 "内存可见性",就是说一个线程对共享变量值的修改,能够及时地被其它线程看到
public class Test5 {public static volatile int count = 0;public static void main(String[] args) {Thread t1 = new Thread(() -> {while (count == 0) {}System.out.println("结束");});t1.start();Thread t2 = new Thread(() -> {Scanner scanner = new Scanner(System.in);System.out.print("请输入:");count = scanner.nextInt();});t2.start();}
}输出结果,这时候输入1,t1线程输出结束然后就销毁了

2.不使用volatile关键字也可以解决这个问题
public class Test5 {public static int count = 0;public static void main(String[] args) {Thread t1 = new Thread(() -> {while (count == 0) {try {Thread.sleep(100);} catch (InterruptedException e) {throw new RuntimeException(e);}}System.out.println("结束");});t1.start();Thread t2 = new Thread(() -> {Scanner scanner = new Scanner(System.in);System.out.print("请输入:");count = scanner.nextInt();});t2.start();}
}输出结果和上面一样,为什么呢?通过休眠让cpu执行这些操作的次数减少了开销就小了,编译器就没有做出优化了,也就不会出现内存可见性的问题

总结:由于编译器是个二百五,我们无法确定它会什么时候进行优化以及不优化,碰到这种问题建议使用volatile关键字
JMM
关于内存可见性涉及的关键性概念JMM(Java Memory Model,java内存模型),存储空间划分如下图
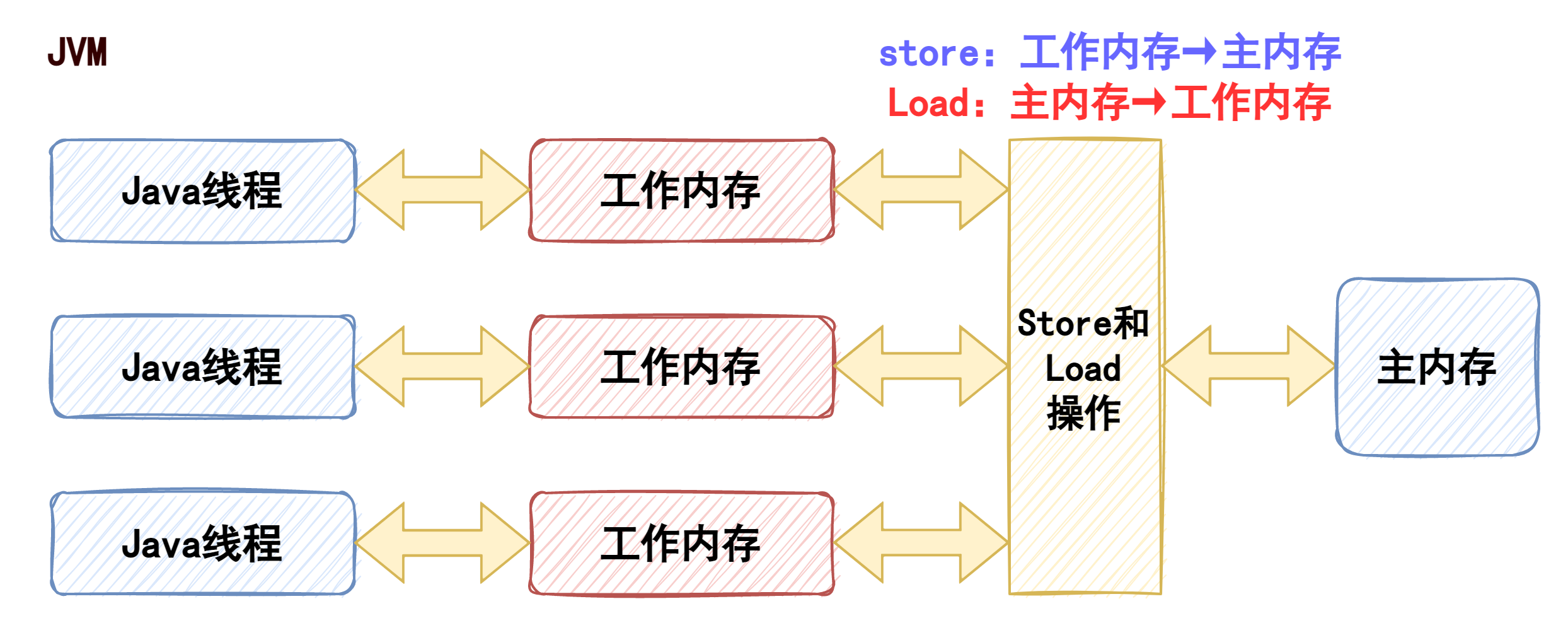
为什么java要搞一个JMM出来呢?实现跨平台性,要兼容不同的cpu、操作系统以及各种硬件设备等等。不同的cpu上的寄存器以及高速缓存存储器都不同有些可能还没有。所以java为了实现跨平台性,搞了JMM出来,来代指这套与硬件相关的信息
volatile 和 synchronized 的区别
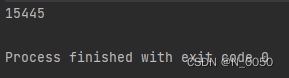
1.synchronized 能够保证原子性, volatile 保证的是内存可见性,不能保证原子性
public class Test5 {public static volatile int count;public static void main(String[] args) throws InterruptedException {Thread t1 = new Thread(() -> {for (int i = 0; i < 10000; i++) {count++;}});Thread t2 = new Thread(() -> {for (int i = 0; i < 10000; i++) {count++;}});t1.start();t2.start();t1.join();t2.join();System.out.println(count);}
}输出结果和我们预期的不符合,应该输出20000,还是会造成线程不安全的问题
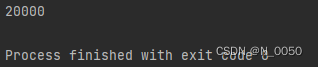
2.synchronized 既能保证原子性, 也能保证内存可见性。之前演示过,同一线程对同一变量进行修改的操作
public class Test5 {public static volatile int count;public static void main(String[] args) throws InterruptedException {Object lock = new Object();Thread t1 = new Thread(() -> {for (int i = 0; i < 10000; i++) {synchronized (lock) {count++;}}});Thread t2 = new Thread(() -> {for (int i = 0; i < 10000; i++) {synchronized (lock) {count++;}}});t1.start();t2.start();t1.join();t2.join();System.out.println(count);}
}输出结果
wait和notify方法
之前提到的join方法能控制线程结束的先后顺序,但是呢我们希望线程不结束也能控制先后顺序,注意join不是只能影响主线程,哪个线程调用join方法哪个就会受影响,就是谁调用谁受影响
我们知道多个线程的执行顺序是随机的,由于系统随机调度,抢占式执行的, 因此线程之间执行的先后顺序难以预知。但是实际开发中有时候我们希望合理的协调多个线程之间的执行先后顺序,多线程中有个重要机制,就是协调多个线程的执行顺序,使用wait和notify方法
wait方法
wait对应的中文意思是等待,所以这个方法就是让指定线程进入阻塞状态
wait 要搭配 synchronized 来使用,脱离 synchronized 使用 wait 会直接抛出异常。并且wait可以设置等待时间,一般建议设置不要死等,wait和notify都是Object类的方法,所以随便定义个对象都可以使用
public class Test5 {public static void main(String[] args) throws InterruptedException {System.out.println("开始");Object o = new Object();o.wait();System.out.println("结束");}
}输出结果

所以我们在使用wait方法的时候要注意这三件事:
1.释放当前的锁(就是解锁了,因为我们知道加锁要确定那个对象),只有先加锁了才能解锁
2.让线程进入阻塞
3.当线程被唤醒的时候,重新获取到锁(就是可以去拿锁了)
public class Test5 {public static void main(String[] args) throws InterruptedException {System.out.println("开始");Object o = new Object();synchronized (o) {o.wait(1000);}System.out.println("结束");}
}输出结果
notify方法
notify对应的中文意思是通知,所以这个方法就是唤醒对应的阻塞状态的线程,指定唤醒进入阻塞状态的线程
notify也需要搭配synchronized使用,wait和notify都是Object类的方法,所以随便定义个对象都可以使用
public class Test5 {public static void main(String[] args) throws InterruptedException {Object o = new Object();Thread t1 = new Thread(() -> {System.out.println("t1线程开始睡了");synchronized (o) {try {o.wait();} catch (InterruptedException e) {throw new RuntimeException(e);}}System.out.println("t1线程睡醒了");});t1.start();Thread.sleep(100);synchronized (o) {o.notify();}}
}输出结果
注意wait和notify在使用的时候需要借助同一个对象!!!
线程饿死
什么是线程饿死呢?就比如说线程A获取一把锁之后在cpu上执行,其他线程想获取这把锁只能进入阻塞等待没在cpu上执行。然后当线程A解锁后,这些线程想去cpu上执行获取这把锁,注意此时这些线程要去cpu上执行获取这把锁需要系统调度,所以需要时间。但是呢线程A已经在cpu上执行了,后续想要再获取这把锁,比其他线程更好拿到,如果线程A一直重复这样的操作,会导致其他线程饿死。下面代码进行演示
public class Test5 {public static void main(String[] args) throws InterruptedException {Object o = new Object();Thread t1 = new Thread(() -> {synchronized (o) {System.out.println("t1线程来了");}synchronized (o) {System.out.println("t1线程来了");}synchronized (o) {System.out.println("t1线程来了");}//这里省略n条});Thread t2 = new Thread(() -> {synchronized (o) {System.out.println("t2线程来了");}});Thread t3 = new Thread(() -> {synchronized (o) {System.out.println("t3线程来了");}});t1.start();t2.start();t3.start();}
}输出结果,如果我在t1线程串行的加n个锁,就会导致其他线程没机会获取到这个锁
使用wait和notify方法可以避免线程饿死,因为wait方法会释放锁然后进入阻塞状态
notifyAll方法
notify方法是一次唤醒一个线程,notifyAll是一次唤醒全部线程,但是要注意唤醒的时候,wait会重新获取锁,所以是串行执行的
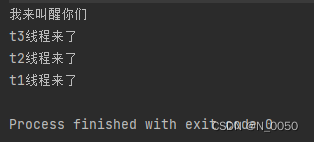
public class Test5 {public static void main(String[] args) throws InterruptedException {Object o = new Object();Thread t1 = new Thread(() -> {synchronized (o) {try {o.wait();} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println("t1线程来了");}});Thread t2 = new Thread(() -> {synchronized (o) {try {o.wait();} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println("t2线程来了");}});Thread t3 = new Thread(() -> {synchronized (o) {try {o.wait();} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println("t3线程来了");}});t1.start();t2.start();t3.start();Thread.sleep(100);System.out.println("我来叫醒你们");synchronized (o) {o.notifyAll();}}
}输出结果,注意一下虽然是同时唤醒 3 个线程, 但是这 3 个线程需要竞争锁. 所以并不是同时执行, 而仍然是有先有后的执行
wait和sleep的区别
如果需要线程间通信和协作,则使用wait()方法,如果是让线程阻塞一段时间,则使用sleep()方法
1.wait 需要搭配 synchronized 使用,sleep 不需要
2.wait是Object类的方法,sleep是Thread类的静态方法
以上便是本章的内容多线程引发的安全问题,后续还会讲解到内容太多分着讲解,这章节的内容同样很重要,不管是日常还是面试中都会频繁出现。我们下一章再见💕
相关文章:
多线程引发的安全问题
前言👀~ 上一章我们介绍了线程的一些基础知识点,例如创建线程、查看线程、中断线程、等待线程等知识点,今天我们讲解多线程下引发的安全问题 线程安全(最复杂也最重要) 产生线程安全问题的原因 锁(重要…...

在晋升受阻或遭受不公待遇申诉时,这样写是不是好一些?
在晋升受阻或遭受不公待遇申诉时,这样写是不是好一些? 在职场中,晋升受阻或遭受不公待遇是员工可能面临的问题之一。面对这样的情况,如何撰写一份有效的申诉材料,以维护自己的合法权益,就显得尤为重要。#李…...

LeetCode 2710.移除字符串中的尾随零:模拟
【LetMeFly】2710.移除字符串中的尾随零:模拟 力扣题目链接:https://leetcode.cn/problems/remove-trailing-zeros-from-a-string/ 给你一个用字符串表示的正整数 num ,请你以字符串形式返回不含尾随零的整数 num 。 示例 1: 输…...

代码随想录训练营第二十三天 39组合总和 40组合总和II 131分割回文串
第一题: 原题链接:39. 组合总和 - 力扣(LeetCode) 思路: 终止条件: 用一个sum值来记录当前组合中元素的总和。当sum的值大于target的时候证明该组合不合适,直接return。当sum的值等于target的…...

【C++】数组、字符串
六、数组、字符串 讨论数组离不开指针,指针基本上就是数组的一切的基础,数组和指针的相关内容参考我的C系列博文:【C语言学习笔记】四、指针_通过变量名访问内存单元中的数据缺点-CSDN博客【C语言学习笔记】三、数组-CSDN博客 1、数组就是&…...

MySQL InnoDB支持几种行格式
数据库表的行格式决定了一行数据是如何进行物理存储的,进而影响查询和DML操作的性能。 在InnoDB中,常见的行格式有4种: 1、COMPACT:是MySQL 5.0之前的默认格式,除了保存字段值外,还会利用空值列表保存null…...

Day6: 344.反转字符串 541. 反转字符串II 卡码网:54.替换数字
题目344. 反转字符串 - 力扣(LeetCode) void reverseString(vector<char>& s) {int len s.size();int left 0;int right len - 1;while (left < right){swap(s[left], s[right--]);}return;} 题目541. 反转字符串 II - 力扣࿰…...

kubekey 离线安装高可用 kubernetes 集群
1. 准备环境 版本: kubernetes: v1.29.2 kubesphere: v3.4.1 kubekey: v3.1.1 说明: kubekey 只用于安装 kubernetes,因为 kubesphere 的配置在安装时经常需要变动,用 ks-installer 的 yaml 文件更好管理;ks-installe…...
)
大数据面试题之Hive(2)
目录 Hive的join操作原理,leftjoin、right join、inner join、outer join的异同? Hive如何优化join操作 Hive的mapjoin Hive语句的运行机制,例如包含where、having、group by、orderby,整个的执行过程? Hive使用的时候会将数据同步到HD…...

求推荐几款http可视化调试工具?
Postman 非常流行的API调试工具,适用于构建、测试和文档化APIs。它支持各种HTTP方法,有强大的集合和环境管理功能,以及代码生成能力。 BB-API 是一款旨在提升开发效率的工具,它专注于提供简约、完全免费且功能强大的HTTP模拟请…...

Python逻辑控制语句 之 判断语句--if else结构
1.if else 的介绍 if else :如果 ... 否则 .... 2.if else 的语法 if 判断条件: 判断条件成立,执行的代码 else: 判断条件不成立,执行的代码 (1)else 是关键字, 后⾯需要 冒号 (2)存在冒号…...

word2016中新建页面显示出来的页面没有页眉页脚,只显示正文部分。解决办法
问题描述:word2016中新建页面显示出来的页面没有页眉页脚,只显示正文部分。设置了页边距也不管用。 如图1 图1 解决: 点击“视图”——“多页”——“单页”,即可。如图2操作 图2 结果展示:如图3 图3...
)
8.javaSE基础进阶_泛型generics(无解通配符?+上下界统配符superextends)
文章目录 泛型generics一.泛型简介二.泛型类1.泛型方法 三.泛型接口四.泛型进阶1.*<?>无解通配符*2.上界通配符 < ? extends E>3.下界通配符 < ? super E>4.泛型擦除 泛型generics 一.泛型简介 JDK5引入,一种安全机制,编译时检测不匹配类型 特点: 将数…...
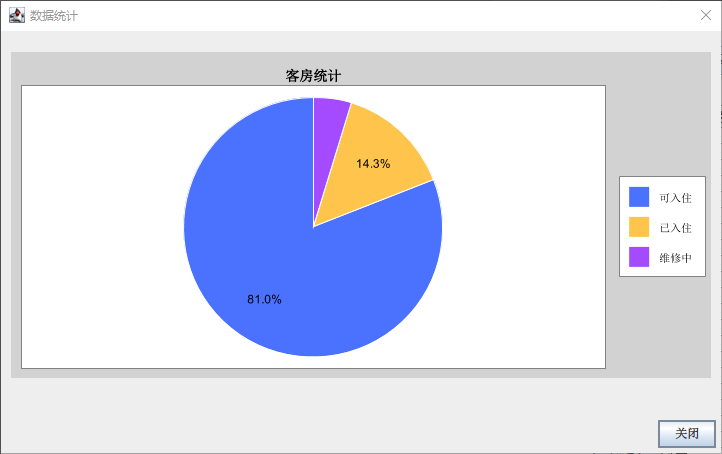
酒店客房管理系统(Java+MySQL)
技术栈 Java: 作为主要编程语言。Swing GUI: 用于开发图形用户界面。MySQL: 作为数据库管理系统。JDBC: 用于连接和操作MySQL数据库。 功能要点 管理登录认证 系统提供管理员登录认证功能。通过用户名和密码验证身份,确保只有授权的用户可以访问和管理酒店客房信…...
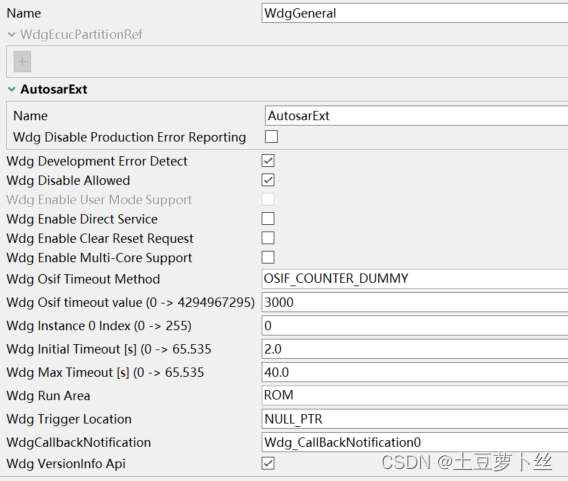
S32K3 --- Wdg(内狗) Mcal配置
前言 看门狗的作用是用来检测程序是否跑飞,进入死循环。我们需要不停地喂狗,来确保程序是正常运行的,一旦停止喂狗,意味着程序跑飞,超时后就会reset复位程序。 一、Wdg 1.1 WdgGeneral Wdg Disable Allowed : 启用此参数后,允许在运行的时候禁用看门狗 Wdg Enable User…...

LeetCode 算法:二叉树的层序遍历 c++
原题链接🔗:二叉树的层序遍历 难度:中等⭐️⭐️ 题目 给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 示例 1: 输入:roo…...

博途TIA Portal「集成自动化软件」下载安装,TIA Portal 灵活多变的编程环境
在编程领域,博途TIA Portal以其卓越的编程工具和灵活多变的编程环境,为众多用户提供了前所未有的便利。这款软件不仅支持多种编程语言,如梯形图(Ladder Diagram)、功能块图(Function Block Diagram…...

火了10年的电脑监控软件有哪些?盘点8款热门的电脑监控软件
电脑监控软件领域经历了多年的发展,一些软件因为其稳定的功能、良好的用户体验和不断更新的技术支持,得以在市场上保持长期的热度和用户基础。以下是几款在过去十年里广受好评且持续流行的内网监控软件: 1.安企神:由河北安企神网络…...

入门Java爬虫:认识其基本概念和应用方法
Java爬虫初探:了解它的基本概念与用途,需要具体代码示例 随着互联网的快速发展,获取并处理大量的数据成为企业和个人不可或缺的一项任务。而爬虫(Web Scraping)作为一种自动化的数据获取方法,不仅能够快速…...

Flask新手入门(一)
前言 Flask是一个用Python编写的轻量级Web应用框架。它最初由Armin Ronacher作为Werkzeug的一个子项目在2010年开发出来。Werkzeug是一个综合工具包,提供了各种用于Web应用开发的工具和函数。自发布以来,Flask因其简洁和灵活性而迅速受到开发者的欢迎。…...

3步搞定Windows风扇噪音:用免费软件实现智能散热控制
3步搞定Windows风扇噪音:用免费软件实现智能散热控制 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/…...

为 Ubuntu 开发环境下的 Claude Code 配置 Taotoken 作为可靠后端
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为 Ubuntu 开发环境下的 Claude Code 配置 Taotoken 作为可靠后端 如果你在 Ubuntu 开发环境中使用 Claude Code 作为编程助手&…...

如何快速掌握Obsidian OCR插件:面向初学者的完整教程
如何快速掌握Obsidian OCR插件:面向初学者的完整教程 【免费下载链接】obsidian-ocr Obsidian OCR allows you to search for text in your images and pdfs 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-ocr 你是否曾为无法搜索图片和PDF中的文字…...

《每日一命令22:rsync——增量同步效率之王》
本期摘要scp每次复制都传整个文件,文件大了就慢。rsync只传文件的变化部分,而且支持断点续传、压缩传输、排除指定目录。本文从零开始,教你rsync的常用场景:本地同步、远程同步、只同步新增文件、排除特定目录、限速传输、删除源端…...

ROS新手避坑指南:除了改hosts,rosdep update超时还有哪些‘冷门’但好用的招?
ROS新手避坑指南:rosdep update超时的全方位解决方案 1. 理解rosdep update的核心机制 rosdep作为ROS生态中的依赖管理工具,其update操作的本质是从GitHub仓库获取最新的软件包依赖关系映射。这个过程涉及三个关键环节: 元数据获取࿱…...

安卓本地AI助手部署:基于GlibClaw与Magisk模块的离线解决方案
1. 项目概述:在安卓设备上部署AI助手如果你是一个喜欢折腾安卓设备的极客,或者是一个对AI应用本地化部署感兴趣的开发者,那么你很可能已经厌倦了那些必须联网、隐私存疑的云端AI助手。最近,我在一个开源社区里发现了一个名为GlibC…...

Cadence 17.4 实战指南:从零到一构建高速PCB设计流程
1. 初识Cadence 17.4:高速PCB设计的起点 第一次打开Cadence 17.4时,那个蓝底白字的启动界面让我想起了刚入行时的场景。作为电子设计自动化(EDA)领域的标杆工具,Cadence Allegro系列一直是高速PCB设计的首选。不同于其…...

开源项目chatgpt-artifacts:为ChatGPT实现Claude式并排视图,支持多模型部署
1. 项目概述:将Claude的Artifacts功能带到ChatGPT 如果你和我一样,既是ChatGPT的重度用户,又对Anthropic的Claude 3.5 Sonnet新推出的Artifacts功能眼馋不已,那么这个项目绝对值得你花时间折腾一下。简单来说, chatg…...

Semtech GS2972-IBE3:解锁专业级3G-SDI视频传输的设计奥秘
1. 揭秘GS2972-IBE3:专业视频传输的"瑞士军刀" 第一次拿到Semtech的GS2972-IBE3芯片时,我正为一个4K转播车的项目头疼。客户要求在不增加设备体积的情况下,实现8路3G-SDI信号的稳定传输。这块指甲盖大小的芯片,最终成了…...

5个理由让你爱上Bebas Neue:免费商用字体库的终极指南 [特殊字符]
5个理由让你爱上Bebas Neue:免费商用字体库的终极指南 🎨 【免费下载链接】Bebas-Neue Bebas Neue font 项目地址: https://gitcode.com/gh_mirrors/be/Bebas-Neue 还在为设计项目寻找一款既专业又免费的字体吗?Bebas Neue字体库就是你…...