大模型微调实战之基于星火大模型的群聊对话分角色要素提取挑战赛:Task01:跑通Baseline
目录
- 0 背景
- 1 环境配置
- 1.1 下载包
- 1.2 配置密钥
- 1.3 测试模型
- 2 解决问题
- 2.1 获取数据
- 2.2 设计Prompt
- 2.2 设计处理函数
- 2.3 开始提取
- 附全流程代码
0 背景
Datawhale AI夏令营第二期开始啦,去年有幸参与过第一期,收获很多,这次也立马参与了第二期,这一期主要是关于大模型微调实战的,之前一直想接触大模型,但是忙于毕业一直没有行动,抓住这次机会行动起来!
在当今数字化时代,企业积累了丰富的对话数据,这些数据不仅是客户与企业之间交流的记录,更是隐藏着宝贵信息的宝库。在这个背景下,群聊对话分角色要素提取成为了企业营销和服务的一项重要策略。
群聊对话分角色要素提取的理念是基于企业对话数据的深度分析和挖掘。通过对群聊对话数据进行分析,企业可以更好地理解客户的需求、兴趣和行为模式,从而精准地把握客户的需求和心理,提供更加个性化和优质的服务。这不仅有助于企业更好地满足客户的需求,提升客户满意度,还可以为企业带来更多的商业价值和竞争优势。
群聊对话分角色要素提取的研究,将企业对话数据转化为可用的信息和智能的洞察,为企业营销和服务提供了新的思路和方法。通过挖掘对话数据中隐藏的客户行为特征和趋势,企业可以更加精准地进行客户定位、推广营销和产品服务,实现营销效果的最大化和客户价值的最大化。这将为企业带来更广阔的发展空间和更持续的竞争优势。
相关链接:
基于星火大模型的群聊对话分角色要素提取挑战赛
零基础入门大模型技术竞赛-速通学习手册
1 环境配置
1.1 下载包
本项目是基于windows环境,pycharm编译器,星火认知大模型Spark3.5 Max,首先安装软件包
pip install --upgrade spark_ai_python # 这里相较于baseline版本去掉-q
国内使用:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple spark_ai_python
如果清华源版本不可用,请使用一下命令升级到最新版本:
pip install -i https://repo.model.xfyun.cn/api/packages/administrator/pypi/simple spark_ai_python --upgrade或者,开那个解决。(最好用)
我在安装的时候出现了报错,经分析是网络问题,开那个解决了。

注:项目仅支持 Python3.8+
1.2 配置密钥
这里密钥从讯飞开发者平台申请,Datawhale还帮我们申请了200w的token,随便花!
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage
import json#星火认知大模型Spark3.5 Max的URL值,其他版本大模型URL值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v3.5/chat'
#星火认知大模型调用秘钥信息,请前往讯飞开放平台控制台(https://console.xfyun.cn/services/bm35)查看
SPARKAI_APP_ID = '' # 替换成自己的
SPARKAI_API_SECRET = '' # 替换成自己的
SPARKAI_API_KEY = '' # 替换成自己的
#星火认知大模型Spark3.5 Max的domain值,其他版本大模型domain值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_DOMAIN = 'generalv3.5'
1.3 测试模型
baseline提供了一个函数用于测试环境以及API是否配置合理,直接运行即可
def get_completions(text):messages = [ChatMessage(role="user",content=text)]spark = ChatSparkLLM(spark_api_url=SPARKAI_URL,spark_app_id=SPARKAI_APP_ID,spark_api_key=SPARKAI_API_KEY,spark_api_secret=SPARKAI_API_SECRET,spark_llm_domain=SPARKAI_DOMAIN,streaming=False,)handler = ChunkPrintHandler()a = spark.generate([messages], callbacks=[handler])return a.generations[0][0].text# 测试模型配置是否正确
text = "你是谁?"
print(get_completions(text)) # 注意这里要添加一个print函数
注意:相较于baseline,最后一行添加了print函数,因为百度在线平台会直接打印以及输出图片。
- 直接调用了
ChatMessage()用于获取用户输入的字符串,其中role参数:system用于设置对话背景,user表示是用户的问题,assistant表示AI的回复。content是用户和AI的对话内容。 ChatSparkLLM()构造了星火模型,其中streaming参数指的是采用一次性返回结果(非流式)还是采用流式返回结果。这里简单测试,采用False。
详细的SDK说明可以在星火的Github查看。
2 解决问题
2.1 获取数据
def read_json(json_file_path):"""读取json文件"""with open(json_file_path, 'r', encoding='utf-8') as f:data = json.load(f)return datadef write_json(json_file_path, data):"""写入json文件"""with open(json_file_path, 'w', encoding='utf-8') as f:json.dump(data, f, ensure_ascii=False, indent=4)# 读取数据
train_data = read_json("dataset/train.json")
test_data = read_json("dataset/test_data.json")
这里就是很普通的实现了Json文件的读取函数和写入函数。注意win环境下在读取和写入的时候要添加, encoding='utf-8',否则会读取失败。在许多中文Windows系统中,默认编码是gbk,而不是utf-8。
2.2 设计Prompt
baseline提供的Prompt:
# prompt 设计
PROMPT_EXTRACT = """
你将获得一段群聊对话记录。你的任务是根据给定的表单格式从对话记录中提取结构化信息。在提取信息时,请确保它与类型信息完全匹配,不要添加任何没有出现在下面模式中的属性。表单格式如下:
info: Array<Dict("基本信息-姓名": string | "", // 客户的姓名。"基本信息-手机号码": string | "", // 客户的手机号码。"基本信息-邮箱": string | "", // 客户的电子邮箱地址。"基本信息-地区": string | "", // 客户所在的地区或城市。"基本信息-详细地址": string | "", // 客户的详细地址。"基本信息-性别": string | "", // 客户的性别。"基本信息-年龄": string | "", // 客户的年龄。"基本信息-生日": string | "", // 客户的生日。"咨询类型": string[] | [], // 客户的咨询类型,如询价、答疑等。"意向产品": string[] | [], // 客户感兴趣的产品。"购买异议点": string[] | [], // 客户在购买过程中提出的异议或问题。"客户预算-预算是否充足": string | "", // 客户的预算是否充足。示例:充足, 不充足"客户预算-总体预算金额": string | "", // 客户的总体预算金额。"客户预算-预算明细": string | "", // 客户预算的具体明细。"竞品信息": string | "", // 竞争对手的信息。"客户是否有意向": string | "", // 客户是否有购买意向。示例:有意向, 无意向"客户是否有卡点": string | "", // 客户在购买过程中是否遇到阻碍或卡点。示例:有卡点, 无卡点"客户购买阶段": string | "", // 客户当前的购买阶段,如合同中、方案交流等。"下一步跟进计划-参与人": string[] | [], // 下一步跟进计划中涉及的人员(客服人员)。"下一步跟进计划-时间点": string | "", // 下一步跟进的时间点。"下一步跟进计划-具体事项": string | "" // 下一步需要进行的具体事项。
)>请分析以下群聊对话记录,并根据上述格式提取信息:**对话记录:**
'''
{content}
'''请将提取的信息以JSON格式输出。
不要添加任何澄清信息。
输出必须遵循上面的模式。
不要添加任何没有出现在模式中的附加字段。
不要随意删除字段。**输出:**
'''
[{{"基本信息-姓名": "姓名","基本信息-手机号码": "手机号码","基本信息-邮箱": "邮箱","基本信息-地区": "地区","基本信息-详细地址": "详细地址","基本信息-性别": "性别","基本信息-年龄": "年龄","基本信息-生日": "生日","咨询类型": ["咨询类型"],"意向产品": ["意向产品"],"购买异议点": ["购买异议点"],"客户预算-预算是否充足": "充足或不充足","客户预算-总体预算金额": "总体预算金额","客户预算-预算明细": "预算明细","竞品信息": "竞品信息","客户是否有意向": "有意向或无意向","客户是否有卡点": "有卡点或无卡点","客户购买阶段": "购买阶段","下一步跟进计划-参与人": ["跟进计划参与人"],"下一步跟进计划-时间点": "跟进计划时间点","下一步跟进计划-具体事项": "跟进计划具体事项"
}}, ...]
'''
"""
2.2 设计处理函数
import jsonclass JsonFormatError(Exception):def __init__(self, message):self.message = messagesuper().__init__(self.message)def convert_all_json_in_text_to_dict(text):"""提取LLM输出文本中的json字符串"""dicts, stack = [], []for i in range(len(text)):if text[i] == '{':stack.append(i)elif text[i] == '}':begin = stack.pop()if not stack:dicts.append(json.loads(text[begin:i+1]))return dicts# 查看对话标签
def print_json_format(data):"""格式化输出json格式"""print(json.dumps(data, indent=4, ensure_ascii=False))def check_and_complete_json_format(data):required_keys = {"基本信息-姓名": str,"基本信息-手机号码": str,"基本信息-邮箱": str,"基本信息-地区": str,"基本信息-详细地址": str,"基本信息-性别": str,"基本信息-年龄": str,"基本信息-生日": str,"咨询类型": list,"意向产品": list,"购买异议点": list,"客户预算-预算是否充足": str,"客户预算-总体预算金额": str,"客户预算-预算明细": str,"竞品信息": str,"客户是否有意向": str,"客户是否有卡点": str,"客户购买阶段": str,"下一步跟进计划-参与人": list,"下一步跟进计划-时间点": str,"下一步跟进计划-具体事项": str}if not isinstance(data, list):raise JsonFormatError("Data is not a list")for item in data:if not isinstance(item, dict):raise JsonFormatError("Item is not a dictionary")for key, value_type in required_keys.items():if key not in item:item[key] = [] if value_type == list else ""if not isinstance(item[key], value_type):raise JsonFormatError(f"Key '{key}' is not of type {value_type.__name__}")if value_type == list and not all(isinstance(i, str) for i in item[key]):raise JsonFormatError(f"Key '{key}' does not contain all strings in the list")return data
- JsonFormatError 类: 这是一个自定义异常类,继承自Python内置的Exception类。当遇到JSON格式错误时,这个异常会被抛出。它接收一个消息参数,并将其存储在message属性中。
- convert_all_json_in_text_to_dict 函数: 这个函数接受一个字符串参数text,然后扫描这个字符串,寻找JSON对象,并将它们转换为Python字典。它使用一个栈来处理嵌套的JSON对象,并只在找到匹配的括号对时才尝试解析JSON。
- print_json_format 函数: 这个函数接受一个Python字典data作为参数,并将其转换为格式化的JSON字符串,然后打印出来。它使用json.dumps函数来实现这个转换,其中indent=4用于美化输出,ensure_ascii=False允许打印非ASCII字符。
- check_and_complete_json_format 函数: 这个函数用于检查一个列表中的每个字典是否包含一组特定的键,并且这些键对应的值的类型也是正确的。
2.3 开始提取
from tqdm import tqdmretry_count = 5 # 重试次数
result = []
error_data = []for index, data in tqdm(enumerate(test_data)):index += 1is_success = Falsefor i in range(retry_count):try:res = get_completions(PROMPT_EXTRACT.format(content=data["chat_text"]))infos = convert_all_json_in_text_to_dict(res)infos = check_and_complete_json_format(infos)result.append({"infos": infos,"index": index})is_success = Truebreakexcept Exception as e:print("index:", index, ", error:", e)continueif not is_success:data["index"] = indexerror_data.append(data)
write_json("output.json", result)
附全流程代码
配置好虚拟环境,下载两个json文件到dataset文件夹下即可直接使用。
"""
==========================================
@author: Seaton
@Time: 2024/6/29:下午7:19
@IDE: PyCharm
@Summary:Task01:baseline实现
==========================================
"""
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage
import json
from tqdm import tqdm# 星火认知大模型Spark3.5 Max的URL值,其他版本大模型URL值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v3.5/chat'
# 星火认知大模型调用秘钥信息,请前往讯飞开放平台控制台(https://console.xfyun.cn/services/bm35)查看
SPARKAI_APP_ID = ''
SPARKAI_API_SECRET = ''
SPARKAI_API_KEY = ''
# 星火认知大模型Spark3.5 Max的domain值,其他版本大模型domain值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_DOMAIN = 'generalv3.5'def get_completions(text):messages = [ChatMessage(role="user",content=text)]spark = ChatSparkLLM(spark_api_url=SPARKAI_URL,spark_app_id=SPARKAI_APP_ID,spark_api_key=SPARKAI_API_KEY,spark_api_secret=SPARKAI_API_SECRET,spark_llm_domain=SPARKAI_DOMAIN,streaming=False,)handler = ChunkPrintHandler()a = spark.generate([messages], callbacks=[handler])return a.generations[0][0].text# # 测试模型配置是否正确
# text = "你是谁?"
# print(get_completions(text)) # 注意这里要添加一个print函数def read_json(json_file_path):"""读取json文件"""with open(json_file_path, 'r', encoding='utf-8') as f:data = json.load(f)return datadef write_json(json_file_path, data):"""写入json文件"""with open(json_file_path, 'w', encoding='utf-8') as f:json.dump(data, f, ensure_ascii=False, indent=4)# 读取数据
train_data = read_json("dataset/train.json")
test_data = read_json("dataset/test_data.json")# prompt 设计
PROMPT_EXTRACT = """
你将获得一段群聊对话记录。你的任务是根据给定的表单格式从对话记录中提取结构化信息。在提取信息时,请确保它与类型信息完全匹配,不要添加任何没有出现在下面模式中的属性。表单格式如下:
info: Array<Dict("基本信息-姓名": string | "", // 客户的姓名。"基本信息-手机号码": string | "", // 客户的手机号码。"基本信息-邮箱": string | "", // 客户的电子邮箱地址。"基本信息-地区": string | "", // 客户所在的地区或城市。"基本信息-详细地址": string | "", // 客户的详细地址。"基本信息-性别": string | "", // 客户的性别。"基本信息-年龄": string | "", // 客户的年龄。"基本信息-生日": string | "", // 客户的生日。"咨询类型": string[] | [], // 客户的咨询类型,如询价、答疑等。"意向产品": string[] | [], // 客户感兴趣的产品。"购买异议点": string[] | [], // 客户在购买过程中提出的异议或问题。"客户预算-预算是否充足": string | "", // 客户的预算是否充足。示例:充足, 不充足"客户预算-总体预算金额": string | "", // 客户的总体预算金额。"客户预算-预算明细": string | "", // 客户预算的具体明细。"竞品信息": string | "", // 竞争对手的信息。"客户是否有意向": string | "", // 客户是否有购买意向。示例:有意向, 无意向"客户是否有卡点": string | "", // 客户在购买过程中是否遇到阻碍或卡点。示例:有卡点, 无卡点"客户购买阶段": string | "", // 客户当前的购买阶段,如合同中、方案交流等。"下一步跟进计划-参与人": string[] | [], // 下一步跟进计划中涉及的人员(客服人员)。"下一步跟进计划-时间点": string | "", // 下一步跟进的时间点。"下一步跟进计划-具体事项": string | "" // 下一步需要进行的具体事项。
)>请分析以下群聊对话记录,并根据上述格式提取信息:**对话记录:**
'''
{content}
'''请将提取的信息以JSON格式输出。
不要添加任何澄清信息。
输出必须遵循上面的模式。
不要添加任何没有出现在模式中的附加字段。
不要随意删除字段。**输出:**
'''
[{{"基本信息-姓名": "姓名","基本信息-手机号码": "手机号码","基本信息-邮箱": "邮箱","基本信息-地区": "地区","基本信息-详细地址": "详细地址","基本信息-性别": "性别","基本信息-年龄": "年龄","基本信息-生日": "生日","咨询类型": ["咨询类型"],"意向产品": ["意向产品"],"购买异议点": ["购买异议点"],"客户预算-预算是否充足": "充足或不充足","客户预算-总体预算金额": "总体预算金额","客户预算-预算明细": "预算明细","竞品信息": "竞品信息","客户是否有意向": "有意向或无意向","客户是否有卡点": "有卡点或无卡点","客户购买阶段": "购买阶段","下一步跟进计划-参与人": ["跟进计划参与人"],"下一步跟进计划-时间点": "跟进计划时间点","下一步跟进计划-具体事项": "跟进计划具体事项"
}}, ...]
'''
"""class JsonFormatError(Exception):def __init__(self, message):self.message = messagesuper().__init__(self.message)def convert_all_json_in_text_to_dict(text):"""提取LLM输出文本中的json字符串"""dicts, stack = [], []for i in range(len(text)):if text[i] == '{':stack.append(i)elif text[i] == '}':begin = stack.pop()if not stack:dicts.append(json.loads(text[begin:i+1]))return dicts# 查看对话标签
def print_json_format(data):"""格式化输出json格式"""print(json.dumps(data, indent=4, ensure_ascii=False))def check_and_complete_json_format(data):required_keys = {"基本信息-姓名": str,"基本信息-手机号码": str,"基本信息-邮箱": str,"基本信息-地区": str,"基本信息-详细地址": str,"基本信息-性别": str,"基本信息-年龄": str,"基本信息-生日": str,"咨询类型": list,"意向产品": list,"购买异议点": list,"客户预算-预算是否充足": str,"客户预算-总体预算金额": str,"客户预算-预算明细": str,"竞品信息": str,"客户是否有意向": str,"客户是否有卡点": str,"客户购买阶段": str,"下一步跟进计划-参与人": list,"下一步跟进计划-时间点": str,"下一步跟进计划-具体事项": str}if not isinstance(data, list):raise JsonFormatError("Data is not a list")for item in data:if not isinstance(item, dict):raise JsonFormatError("Item is not a dictionary")for key, value_type in required_keys.items():if key not in item:item[key] = [] if value_type == list else ""if not isinstance(item[key], value_type):raise JsonFormatError(f"Key '{key}' is not of type {value_type.__name__}")if value_type == list and not all(isinstance(i, str) for i in item[key]):raise JsonFormatError(f"Key '{key}' does not contain all strings in the list")return dataretry_count = 5 # 重试次数
result = []
error_data = []for index, data in tqdm(enumerate(test_data)):index += 1is_success = Falsefor i in range(retry_count):try:res = get_completions(PROMPT_EXTRACT.format(content=data["chat_text"]))infos = convert_all_json_in_text_to_dict(res)infos = check_and_complete_json_format(infos)result.append({"infos": infos,"index": index})is_success = Truebreakexcept Exception as e:print("index:", index, ", error:", e)continueif not is_success:data["index"] = indexerror_data.append(data)write_json("output.json", result)相关文章:
大模型微调实战之基于星火大模型的群聊对话分角色要素提取挑战赛:Task01:跑通Baseline
目录 0 背景1 环境配置1.1 下载包1.2 配置密钥1.3 测试模型 2 解决问题2.1 获取数据2.2 设计Prompt2.2 设计处理函数2.3 开始提取 附全流程代码 0 背景 Datawhale AI夏令营第二期开始啦,去年有幸参与过第一期,收获很多,这次也立马参与了第二…...

大数据开发如何管理项目
在面试的时候总是 会问起项目,那在大数据开发的实际工作中,如何做好一个项目呢? 目录 1. 需求分析与项目规划1.1 需求收集与梳理1.2 可行性分析1.3 项目章程与计划 2. 数据准备与处理2.1 数据源接入2.2 数据仓库建设2.3 数据质量管理 3. 系统…...

在实施数据加密时,有哪些常见的加密技术可供选择?
在实施数据加密时,有哪些常见的加密技术可供选择? 在实施数据加密时,有许多常见的加密技术可供选择,这些技术根据其原理、安全性、效率和适用场景有所不同。以下是一些常见的加密技术: 对称加密(Symmetri…...
容易涨粉的视频素材有哪些?容易涨粉的爆款短素材库网站分享
如何挑选社交媒体视频素材:顶级视频库推荐 在社交媒体上脱颖而出,视频素材的选择至关重要。以下是一些顶级的视频素材网站推荐,不仅可以提升视频质量,还能帮助你吸引更多粉丝。 蛙学网:创意的源泉 作为创意和独特性的…...

2024 CISCN 华东北分区赛-Ahisec
Ahisec战队 WEB python-1 break 源码如下: # -*- coding: UTF-8 -*-from flask import Flask, request,render_template,render_template_stringapp Flask(__name__)def blacklist(name):blacklists ["print","cat","flag",&q…...
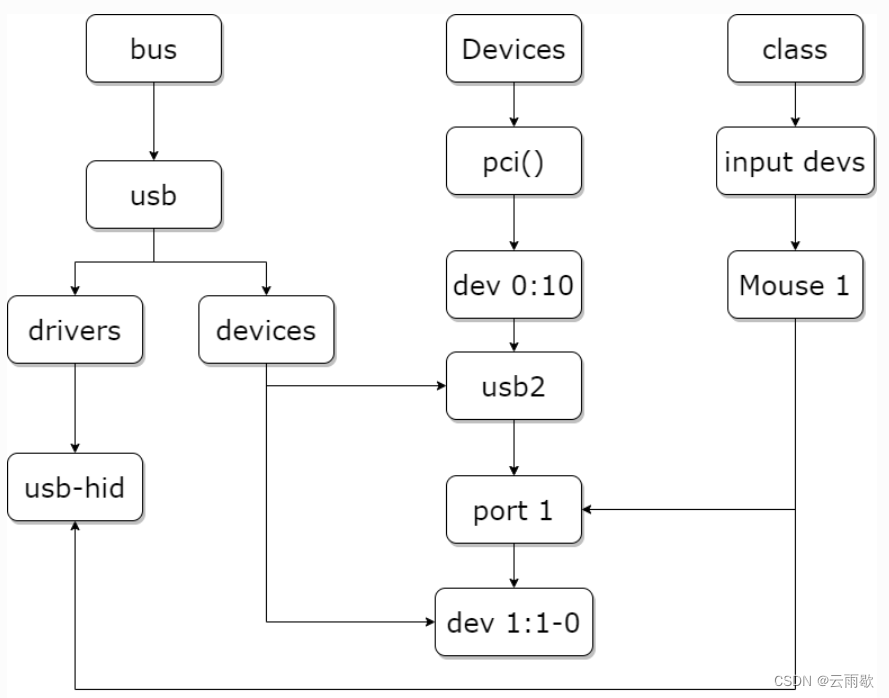
Linux驱动开发笔记(十三)Sysfs文件系统
文章目录 前言一、Sysfs1.1 Sysfs的引入1.2 Sysfs的目录结构1.2 Sysfs的目录详解1.2.1 devices1.2.2 bus1.2.3 class1.2.4 devices、bus、class目录之间的关系1.2.5 其他子目录 二、Sysfs使用2.1 核心数据结构2.2 相关函数2.2.1 kobject_create_and_add2.2.2 kobject_put()2.2.…...

Numpy array和Pytorch tensor的区别
1.Numpy array和Pytorch tensor的区别 笔记来源: 1.Comparison between Pytorch Tensor and Numpy Array 2.numpy.array 4.Tensors for Neural Networks, Clearly Explained!!! 5.What is a Tensor in Machine Learning? 1.1 Numpy Array Numpy array can only h…...

【面试系列】数据科学家 高频面试题及详细解答
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题. ⭐️ AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、…...

mysql是什么
mysql是什么 是DBMS软件系统,并不是一个数据库,管理数据库 DBMS相当于用户和数据库之间的桥梁,有超过300种不同的dbms系统 mysql是关系型数据库,关系型数据库存储模型很想excel,用行和列组织数据 sql是一门编程语言…...

【软件工程】【22.04】p1
关键字: 软件需求规约基本性质、数据字典构成、内聚程度最高功能内聚、公有属性、RUP实体类、评审、测试序列、软件确认过程、CMMI能力等级 软件需求分类、DFD数据流图组成(实体)、经典详细设计、数据耦合、关联多重性、状态图、黑盒测试、…...

简单说下GPT-4
ChatGPT 4.0,是OpenAI开发的基于GPT-4架构的大型语言模型。它在多个方面相较于前代版本有了显著的改进。以下是从专业角度对ChatGPT 4.0的详解: 架构与训练 1. **架构**:GPT-4采用的是变压器(Transformer)架构&#x…...

力扣第一道困难题《3. 无重复字符的最长子串》,c++
目录 方法一: 方法二: 方法三: 方法四: 没有讲解,但给出了优秀题解 本题链接:4. 寻找两个正序数组的中位数 - 力扣(LeetCode) 话不多说,我们直接开始进行本题的思路解…...

【ai】tx2 nx :ubuntu查找NvInfer.h 路径及哪个包、查找符号
在Ubuntu系统中,你可以使用多种方法来查找某个头文件的路径。这里有几种常用的方法: 使用find命令: find命令是一个非常强大的工具,可以在文件系统中搜索匹配特定条件的文件。例如,如果你想查找名为stdio.h的头文件,可以使用以下命令:bash 复制代码 sudo find / -name …...

C++ 运算符的优先级和结合性表
优先级和结合性表 优先级运算符描述结合性1::作用域解析运算符左到右2() [] . -> --后缀运算符左到右3 -- - ! ~ * & sizeof new delete typeid一元运算符右到左4* / %乘除取模左到右5 -加法和减法左到右6<< >>左移和右移左到右7< < > >关系…...

MySQL中SQL语句的执行过程详解
1. 客户端连接和请求 客户端连接 在MySQL中,客户端连接和请求过程是执行SQL语句的第一步。该步骤主要涉及客户端如何连接到MySQL服务器,以及如何维护和管理客户端与服务器之间的会话。 客户端连接: 连接器(Connector)…...
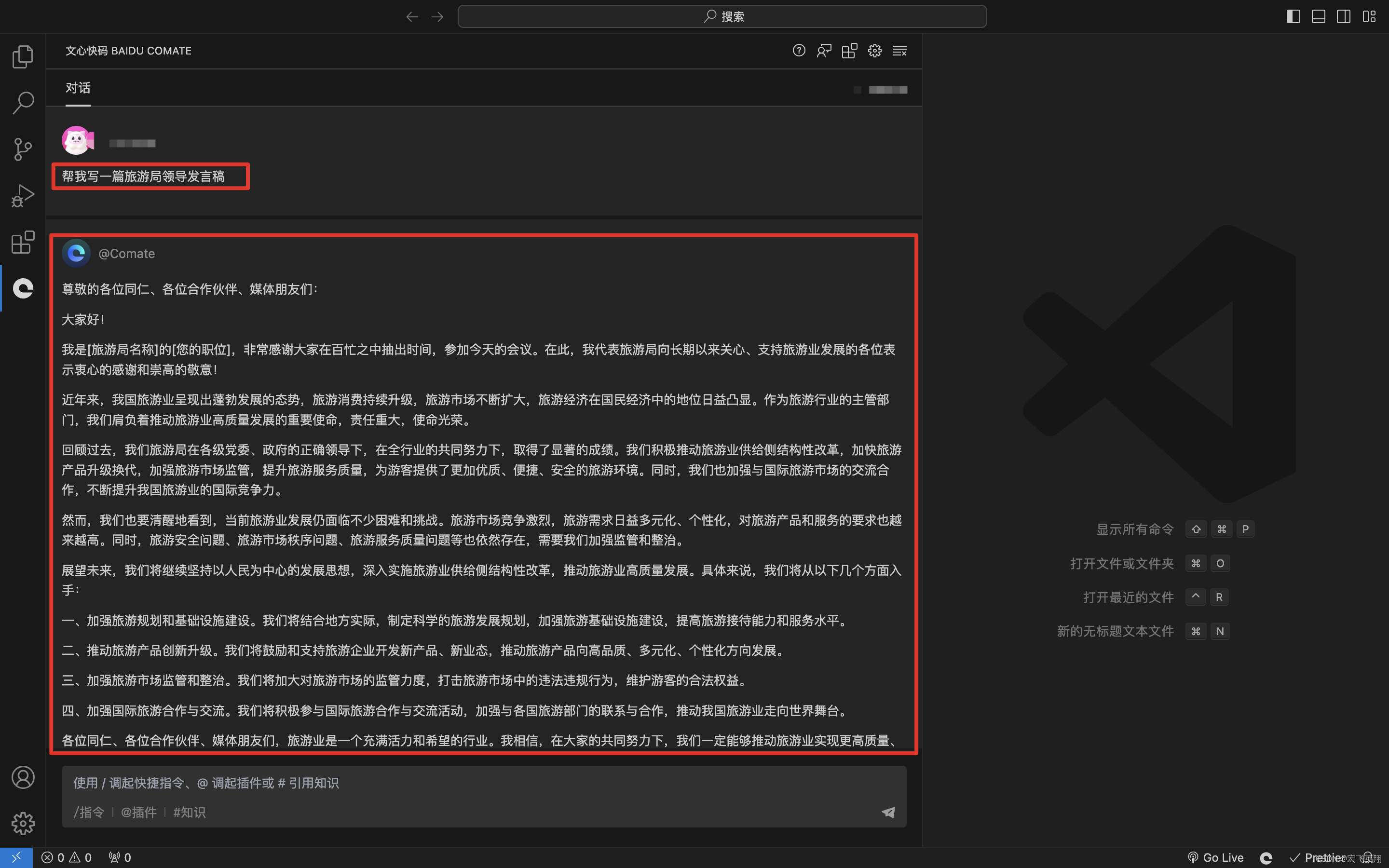
文心一言4.0免费使用
领取&安装链接:Baidu Comate 领取季卡 视频教程:免费使用文心一言4.0大模型_哔哩哔哩_bilibili 有图有真相 原理:百度comate使用文心一言最新的4.0模型。百度comate目前免费使用,可以借助comate达到免费使用4.0模型目的。 …...
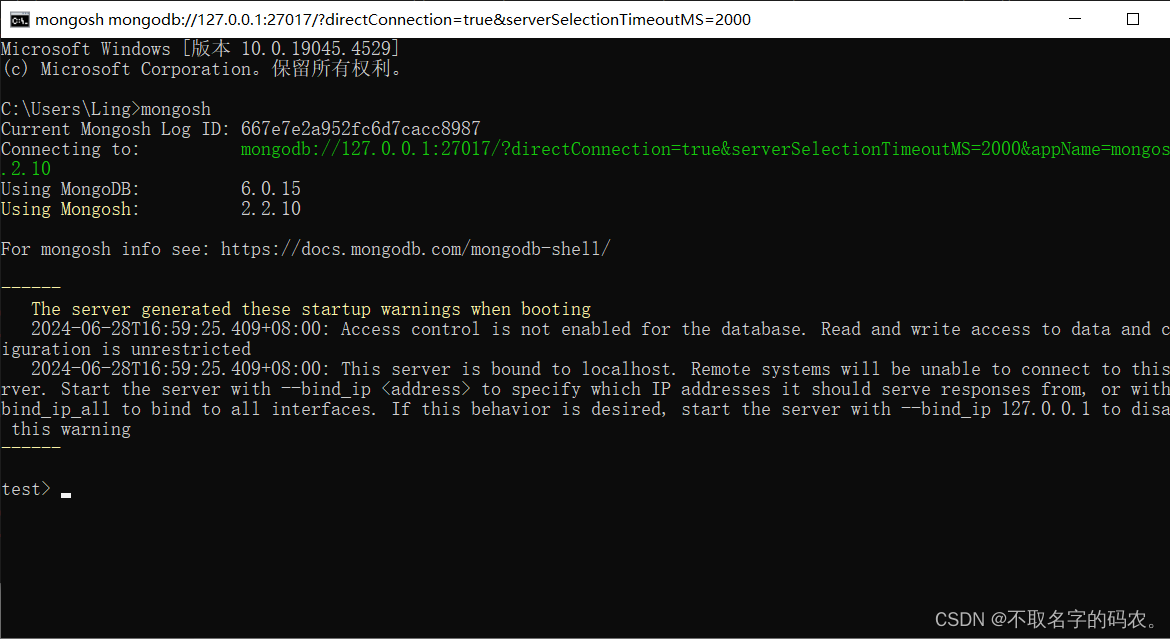
Mongodb安装与配置
Mongodb的下载 这里下载的是MongoDB 7.0.11版本的 首先进入官网:https://www.mongodb.com/ 点击完上面两步后,加载来到该页面,选择自己的版本、系统,是压缩包(zip)还是安装包(msi)。 下载好之后能,来到安装包哪里&a…...

Java校园跑腿小程序校园代买帮忙外卖源码社区外卖源码
🔥校园跑腿与外卖源码揭秘🔥 🚀 引言:为何需要校园跑腿与外卖源码? 在快节奏的校园生活里,学生们对于便捷、高效的服务需求日益增长。校园跑腿和外卖服务成为了解决这一需求的热门选择。然而,…...

MySQL高级-MVCC-基本概念(当前读、快照读)
文章目录 1、MVCC基本概念1.1、当前读1.1.1、创建表 stu1.1.2、测试 1.2、快照读 1、MVCC基本概念 全称Multi-Version Concurrency Control,多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突,快照读为MySQL实现MVCC提供了一个…...
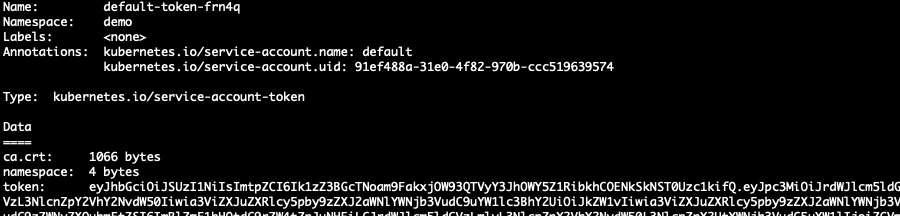
kubernetes给指定用户分配调用k8s的api权限
文章目录 概要利用RBAC添加角色权限使用shell命令创建角色权限使用配置文件创建角色权限 调用k8s的api获取k8s账户的token 小结 概要 使用kubernetes部署项目时,有些特殊场景,我们需要在自己创建的pod里面调用k8s的api来管理k8s,但是需要使用…...

GitHub仓库自动化同步工具xpull:原理、配置与实战应用
1. 项目概述:一个被低估的GitHub数据同步利器 如果你经常在GitHub上管理多个仓库,或者需要将某个仓库的特定分支、标签甚至整个提交历史同步到另一个仓库,那么你很可能经历过手动操作的繁琐。无论是为了备份、镜像、还是将上游的更新合并到自…...

AI驱动编辑预设:智能调色与音频处理实战指南
1. 项目概述:AI驱动的编辑预设库最近在折腾视频和图片后期的时候,发现一个挺有意思的项目,叫kaushalrao/ai-editor-presets。光看名字,你可能觉得这又是一个普通的滤镜包或者调色预设合集。但深入用下来,我发现它的核心…...

IDM激活脚本:3分钟解锁完整版下载功能的终极指南
IDM激活脚本:3分钟解锁完整版下载功能的终极指南 【免费下载链接】IDM-Activation-Script-ZH IDM激活脚本汉化版 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script-ZH 还在为Internet Download Manager(IDM)的30天…...

本地包管理器指南:实现开发环境隔离与依赖管理的工程实践
1. 项目概述:一个为开发者而生的本地包管理器指南如果你是一名开发者,尤其是经常在本地环境折腾各种工具、依赖和项目配置的开发者,那么“包管理器”这个词对你来说一定不陌生。无论是 Node.js 的 npm/yarn/pnpm,Python 的 pip/co…...

一个开发团队的时序数据库选型实战手记
当实验室的模拟数据,遇上真实产线上轰鸣的机器与错综复杂的业务逻辑,我们才发现:选择一款数据库,远不止比拼性能数字那么简单。历时半年选型、三个月上线,本文将完整复盘我们从InfluxDB、TDengine到最终落地金仓KES时序…...

基于AI宏观流动性监测框架的黄金三日连跌研究:美联储加息预期按兵不动后的市场重定价逻辑
摘要:本文通过AI宏观利率模型、美元流动性监测系统与黄金波动率因子分析,结合美通胀数据、美债收益率变化及市场利率预期重定价过程,分析黄金连续三日回落背后的核心驱动逻辑,并探讨当前“高利率持续”环境下黄金资产的阶段性压力…...

【DeepSeek Chat功能测试全链路指南】:20年AI工程师亲测的7大核心场景验证法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Chat功能测试的底层逻辑与验证哲学 DeepSeek Chat 的功能测试并非仅面向接口响应的“黑盒点击”,而是建立在模型行为可解释性、推理路径可追溯性与系统边界可控性三重基石之上的验…...

Beige CSS框架:现代CSS Grid与变量驱动的极简前端开发实践
1. 项目概述:一个被低估的现代CSS框架如果你和我一样,在过去的几年里,已经厌倦了Bootstrap、Tailwind CSS这些“巨无霸”框架带来的审美疲劳和项目同质化,同时又对从零开始手写CSS的繁琐感到头疼,那么今天聊的这个项目…...

STM32F4用HAL库驱动MPU6050,从引脚重映射到数据读取的保姆级避坑指南
STM32F4 HAL库驱动MPU6050全流程实战:从引脚重映射到数据解析的深度避坑指南 第一次接触STM32F4和MPU6050的组合时,我花了整整三天时间才让传感器吐出第一个有效数据。不是I2C通信失败,就是数据全为零,最崩溃的是明明按照教程操作…...

WebToEpub:3分钟将网页小说转为EPUB电子书的终极解决方案
WebToEpub:3分钟将网页小说转为EPUB电子书的终极解决方案 【免费下载链接】WebToEpub A simple Chrome (and Firefox) Extension that converts Web Novels (and other web pages) into an EPUB. 项目地址: https://gitcode.com/gh_mirrors/we/WebToEpub 还在…...