数据结构与算法基础(王卓)(15):KMP算法详解(含速成套路和详细思路剖析)
如果时间不够,急(忙)着应付考试没心思看,直接参考(照抄)如下套路:



PART 1:关于next [ j ]
PPT:P30
根据书上以及视频上给出的思路(提醒),我们对于KMP算法拥有了如下的初步(第一阶段)的了解:
书上的内容(经过简化和解释说明后的版本):
分析模式串t:
对于模式串(子串)t的每个字符 t [ j ] (0≤j≤m-1)
即 j 在字符串最后一个字符前
存在一个整数k(k<j),使得
模式串中开头的k个字符(t0…t[ k-1])
依次与t[ j ]的
前面k个字符(t[ j – k ]…t[ j – 1 ])相同
其实就是说:
子串里面的第j个字符,这个字符他前面的k个字符刚好和子串最前面(开头)的k个字符一模一样
注:
这里,我们暂且就给这两串相同的玩意取个名字方便称呼:
我们将前者称之为前缀,后者称之为后缀
将其图像化可能更加直观:

这种属性落实到具体提高比较效率上,重点就是:当出现了前缀和后缀以后
我们可以把(子串)前缀移动到后缀的位置,主串不变,进行下一轮比较
换句话说,就是在(到)下一轮比较时
直接把前缀移动到(移动)之前后缀所处的位置,跳过这中间所有的字符
直接进行这个位置开始的,后面的比较
学习过程中遇到的问题(很容易踩的坑):
按理说,这里接下来我们就可以进行顺理成章地归纳关于next [ i ]的公式了,比如说至少能理解书上的这一条:

但是,这里我们很容易就发现一个问题:
不是,你这个子串不是说是要往后移吗,怎么经过了这个公式怎么还越变越小了???
k都移动到第j位了,j 不得移动到 j +(j-k)位上???
这个大概就不对了吧?又或者说,next [ j ]其实并不代表下一次 j 的位置?
然而实际上,该问题的出现根源于没有真正的画图和敲代码(实践)
而该具体问题的核心在于:
j 往前指(指向字符串前面的第k个字符)
并不是说
让 子串的 位序为 j 的 字符移动到 主串的 位序为next [ j ]的位置(正下方)开始匹配
把后缀移动到之前前缀的位置上来
另外,在这个算法案例中此 j (next【j】)非彼 j(前面文字介绍里面的 j)
这里的 j, 相当于一个功能类似于指针的一个下标
要彻底搞清楚该问题过程的核心和本质,我们需要彻底从头开始,重新缕一缕这个KMP算法
(再整个比较过程中的流程和步骤):
实践操作步骤:
- 直接匹配(一个一个字符往后匹配),直到匹配不上
- 看匹配不上的字符之前的字符有没有能实现前缀后缀一样的
- (有一样的话)直接把前缀移动到后缀之前摆放的位置
- 继续匹配
这里 j 的执行过程是
从t【0】开始往后面排,匹配发现不一样以后,i 不变,j(不一样的前一位)
数值变为next [ j ],指向子串内下标为next [ j ] 的字符
再次说明强调:
不是说让 子串的 位序为 j 的 字符移动到 主串的 位序为next [ j ]的位置(的正下方)开始匹配
是主串不动,j 指向子串内下标为next [ j ] 的字符
相当于将子串内下标为next [ j ] 的字符向后移动到原来下标为 j 的字符的位置
注意:
这里写的所谓的“移动”的说法,只是我们为了方便初步理解匹配算法的过程
实际上并不存在什么子串的移动来移动去,只有说:
操作过程前,主串的同一个字符(位序为 i ),比较的是子串里(相对而言)靠前面的字符(位序为 j )
操作后,主串的同一个字符(位序为 i ),比较的是子串里(相对而言)靠后面的字符(位序为 next [ j ] )
关于next [ j ]的总结:
解决了这么大的一个问题,现在,我们终于可以可以归纳关于next [ i ]的公式了:
(1):如上面所示,如果存在前缀后缀相同的情况,我们可以让 j (可移动的类似指针的)下标变为 k (指向子串中位序为k的,前缀的后面的第一位字符)来加速比较
(2):上面我们都默认下标(位序) j 是从0开始,是因为我们的书上写的都是默认为0的情况
实际上下标可以从0开始,也可以从1开始(比如说PPT、网课里面)
但是
对于第一位下标的 next [ j ] 值,他们都选择了:
比第一个下标小1位(第一个下标的前面一位,也是我们实际上永远都取不到的一个位置)
对于“其他情况”(不是第一位但是也没有什么相同的前缀和后缀)的 next [ j ] 值
他们都选择了:第一个下标位
所以说实际上都可以,表面上两个归纳的结果的数值完全不一样


实际上他们的数值制定的原理本质都是一样的,似非而是
而在这里为了应用的方便,我们统一都采用(写成)书上(从0开始)的形式
但是我们也要知道:
如果我们不想从0开始,想要从1开始,这也都是可以的,只要直接按照PPT上面所执行的公式操作就行
next 代码思路:
那么接下来,就是我们把准备了那么多的时间的思想转换为代码的时候了:
框架
首先,我们先把整个(KMP)匹配算法的大框架搭建好:
int Index_KMP(SString S, SString T, int pos)
{int i = pos, j = 0;while (i <= S.length && j <= T.length){if (S.ch[i] == T.ch[j]){++i; ++j;}//主串和子串依次匹配下一个字符elsej = next[j]; }if (j > T.length) return i - T.length; //匹配成功,返回子串位置else return false;
}难题:如何写出一个判断子串的前后缀是否相同的语句
另外在这里,一开始其实我想写的是不用写什么next【j】,直接在代码里通过算法实现倒退到next【j】的功能,但是这样反而有点混乱,逻辑不清,而且到后面其实已经写不下去了:
int k = 0;while (1){if (T.ch[k] == T.ch[j]){k++; j--;//然后写一个判断子串的前后缀是否相同的语句//但是这里这样写的话我们可以说要写无穷个判断语句//根本无法实现}}//然后写一个判断子串的前后缀是否相同的语句
//但是这里这样写的话我们可以说要写无穷个判断语句
//根本无法实现
所以,如何写出一个判断子串的前后缀是否相同的语句使该算法的核心/重点
下面我们来针对此方面开展工作
首先,我们按部就班根据公式:
写出如下程序:
void Get_next(SString T, int(&next)[])
//给你一个子串T,教你逐个算出每个位序对应的next[]
//&:返回所有我们算出的next[]
{int j = 0,//从头开始算起k = -1;// k = 0; //不可以,根据公式和算法设计,即使是MAX[k]也必须要小于jnext[0] = -1;//根据公式while (j <= T.length - 1)//因为位序从0(而非1)开始{if (k == -1 || T.ch[k] == T.ch[j]){}}
}
然而写到具体如何一个一个判断匹配把比较前缀后缀的思想实现成代码的时候又卡壳卡住了
对此,我们的解决方法是:
多画图,一步一步、一格一格算,不用着急,慢慢来
画出步骤图如下:



在这个过程中,我们很容易就感受到:
其实如果上一步进行匹配运算结果为真的话
下一轮其实我们只需要比较上一轮比较的两个串的后面的一个字符就可以直接判定结果
下一轮的next 【j】是不是上一轮加一
有人说你这TM不是废话吗,但是这句废话在我们这里的程序设计中含有至关重要的意义:
事实上,根据上面这句废话,我们可以画出我们在采用这种方法的流程图
如下:
 根据上述流程图,我们不难得到:
根据上述流程图,我们不难得到:
if情况:(新字符匹配)
(1):实现前面所说的
实现一个一个判断匹配把比较前缀后缀的思想实现成代码的操作
至少这里我们可以通过废话:
其实如果上一步进行匹配运算结果为真的话
下一轮其实我们只需要比较上一轮比较的两个串的后面的一个字符就可以直接判定结果
下一轮的next 【j】是不是上一轮加一
以及流程图写出 if 判断语句后面的表达式:
思考逻辑流程:
第一次给next【j】赋值的时候
我们要意识到next【0】是在一开始我们就已经给了他初值的
也就是说第一个被赋值的,是next【1】
此时(系统给的条件): j = 0, k = -1; 而我们要写入的,是next【1】
重新参考步骤图,我们知道:
给next【1】赋值时,k = 0 ,j = 1;
更何况后面每一步我们都要进行自增,然后再比较的操作
所以自然的:
j++;
k++;
的操作是不可少的
然后我们要考虑的就是赋值和自增操作的前后顺序安排问题了:
再对应着步骤图一个一个看:
| next [ 1 ] | k = 0 ,j = 1 | next [ 1 ] = 0; |
| next [ 2 ] | k = 1 ,j = 2 | 一样:next [ 2 ] = 1 不一样:next [ 2 ] = 0 |
| next [ 3 ] | k = 2 ,j = 3 | 一样:next [ 3 ] = 2 不一样:next [ 3 ] = 1或0 |
我们可以看到:
如果(后面的那一个新的字符)匹配结果为真
则 next [ j ] 的值,就为新的(和上一轮不一样的)k的值(新的值其实这里也就是自增过以后得的值)
匹配结果为假,那是else情况里面的东西,我们先不管他
所以从上述操作我们大概就可以判断出来:如果(后面的那一个新的字符)匹配结果为真
那么就先自增,然后赋值next [ j ] = 新的k
else情况:(新字符不匹配)
现在,我们回过头去看看流程图,研究匹配结果为假的情况:
步骤:
(1):我们会(可以)发现,无一例外,他们进行的操作都是去执行少一位的前缀和后缀的比较(匹配)的算法操作
(当然了,很多人会说,这又是一句废话,你TM介绍算法的基本原理的时候里面TM不就写着吗)
(2):既然如此(他执行的还是这个比较的操作),比较的操作流程必须由前面的 if 语句执行:
一方面我不可能去再重复写一遍这个比较
另一方面如果一直这样写下去的话,后面就变成了无穷无尽的循环了
所以说到这一步,我们需要思考的:
是怎么让前缀和后缀这两个东西倒(回退)回去,而不是在 else 里面写比较的语句
(3):在参考过课本上的思路以后,我们意识到:
其实回头去找前缀后缀里面最长的、能相等的两个串,本质上和我们比较子串和主串本质上其实没什么区别
也就是说,在这里,我们可以用KMP算法直接加速这一比较的过程
更巧的是,他前面其实已经给我们算好了 j 前面所有的 next [ j ]
当然,在这我写是这么写,但是总感觉要完整这个过程好像还缺点什么,不够确定就是这样(说不出来缺了什么东西)
总的来说,到了这一步,我们可以用KMP算法,在 else 语句后面写:
k = next[k];
也可以老老实实的就用BF算法:
k--;
是 k-- 吗?我好像不确定,欢迎大家指正😂
代码实现见下一节
相关文章:
数据结构与算法基础(王卓)(15):KMP算法详解(含速成套路和详细思路剖析)
如果时间不够,急(忙)着应付考试没心思看,直接参考(照抄)如下套路: PART 1:关于next [ j ] PPT:P30 根据书上以及视频上给出的思路(提醒)&#x…...

【互联网架构】聊一聊所谓的“跨语言、跨平台“
文章目录序跨语言跨平台【饭后杂谈】为什么有人说Java的跨平台很鸡肋?序 很多技术都具有跨语言、跨平台的特点 比如JSON是跨语言的、Java是跨平台的、UniAPP、Electron是跨平台的 跨语言和跨平台,是比较重要的一个特性。这些特性经常能够决定开发者是否…...
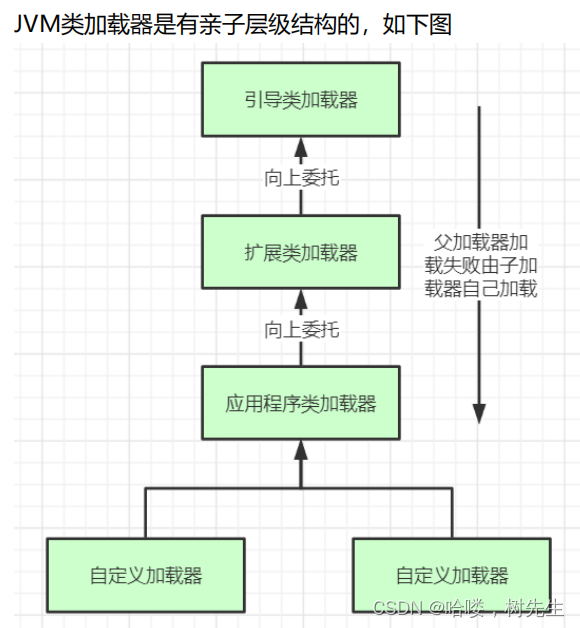
1.JVM常识之 类加载器
1.jvm组成 JVM组成: 1.类加载器 2.运行时数据区 3.执行引擎 4.本地库接口 各组件的作用: 首先通过类加载器(ClassLoader)会把 Java 代码转换成字节码,运行时数据区(Runtime Data Area)再把字节码…...
一天搞定《AI工程师的PySide2 PyQt5实战开发手册》
PySide2/PySide6、PyQt5/PyQt6:都是基于Qt 的Python库,可以形象地这样说,PySide2 是Qt的 亲儿子(Qt官方开发的) , PyQt5 是Qt还没有亲儿子之前的收的 义子 (Riverbank Computing这个公司开发的,有商业版权限…...

身份推理桌游
目录 杀人游戏(天黑请闭眼) (1)入门版 (2)标准版 (3)延伸版——百度百科 (3.1)引入医生和秘密警察 (3.2)引入狙击手、森林老人和…...
[LeetCode周赛复盘] 第 99 场双周赛20230304
[LeetCode周赛复盘] 第 99 场双周赛20230304 一、本周周赛总结二、 [Easy] 2578. 最小和分割1. 题目描述2. 思路分析3. 代码实现三、[Medium] 2579. 统计染色格子数1. 题目描述2. 思路分析3. 代码实现四、[Medium] 2580. 统计将重叠区间合并成组的方案数1. 题目描述2. 思路分析…...

Parcel Bundle漏洞学习
Bundle的序列化细节看上去还是有些复杂的,在之前已经讨论过,一般我们使用Parcel的时候,都是严格的write和read相对应。一些疏漏,不对应,竟然就可以成为漏洞,https://xz.aliyun.com/t/2364 里介绍了Bundle漏…...

RTP载荷H264(实战细节)
RTP包由两部分组成,RTP头和RTP载荷: RTP头 RTP头的 结构如下: 代码结构: typedef struct RtpHdr {uint8_t cc : 4, // CSRC countx : 1, // header extendp : 1, // padding flagversion : 2; // versionuint8_t …...

软考高级信息系统项目管理师系列之四十三:信息系统安全管理
软考高级信息系统项目管理师系列之四十三:信息系统安全管理 一、信息系统安全管理内容二、信息安全策略1.信息系统安全策略的概念与内容2.信息系统安全等级保护的概念三、信息安全系统1.信息安全系统三维空间2.信息安全系统三种架构体系四、PKI公开密钥基础设施1.PKI总体架构2…...
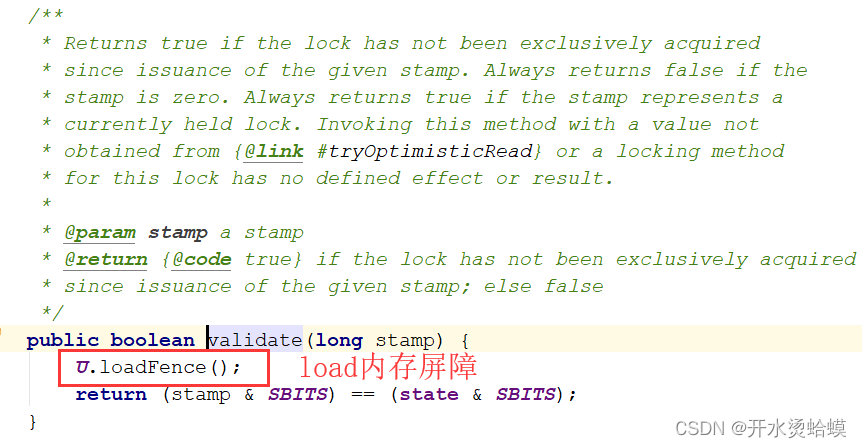
并发编程之AtomicUnsafe
目录 原子操作 定义 术语 处理器如何实现原子操作 处理器自动保证基本内存操作的原子性 使用总线锁保证原子性 使用缓存锁保证原子性 Java当中如何实现原子操作 Atomic 定义 原子更新基本类型类 原子更新数组类 原子更新引用类型 原子更新字段类 Unsafe应用解析…...
GDB调试快速入门
什么是GDB: GDB - - - (GNU symbolic debugger)是Linux平台下最常用的一款程序调试器。 自己的Linux是否安装GDB? 一般来说,使用Ubuntu的话,系统就会自带的有GDB调试器的 命令窗口输入如下命令可以查看是否安装了gdb: gdb -v …...

Vim一次复制,多次粘贴
我们平常在使用Vim时候,通过viwy或者yy等复制操作之后,p操作粘贴的时候,只能粘贴一次,想要粘贴多次怎么办? 解决方案:在使用p的是时候使用"0p,这样就能无限制的一直粘贴了。 可是ÿ…...
如何修改Win11上的默认程序?
在Win10之前,更改特定文件格式的默认程序很简单,但在Win11发布之后,很多用户都不清楚关于Win11的修改默认程序的操作步骤,接下来我们就一起来看看吧,希望可以帮助到大家。 步骤如下: 一、如何更改Windows 1…...
安装Linux虚拟机和Hadoop平台教程汇总及踩坑总结
📍主要内容介绍安装Linux虚拟机、ubuntu系统、安装hadoop三个环节的教程链接介绍及本机与虚拟机的FTP传输教程总结(直接找hadoop安装环节的5.filezilla传输文件)新鲜出炉的踩坑总结和填坑指南安装Linux虚拟机和ubuntu系统一、材料和工具1、下…...

Shell脚本的使用和介绍
为了方便以后工作使用和复习,吐血整理记录一下学习shell脚本的笔记,看这篇文章需要对linux系统熟悉,希望对大家有所帮助! 文章目录 目录 文章目录 一、什么是shell? 为什么要学习和使用shell? 二、shell的分类...
机械学习 - 基础概念 - scikit-learn - 数据预处理 - 1
目录安装 scikit-learn术语理解1. 特征(feature )和样本( sample / demo)的区别?2. 关于模型的概念一、机械学习概念1. 监督学习总结:2. 非监督学习总结:3. 强化学习总结:三种学习的…...
)
OLCNE cluster 配置 NFS Storage(英文)
OLCNE cluster 配置 NFS Storage(英文)Create an OLCNE cluster.Create an NFS server.a. Install the NFS utility package on the server and client instances.b. Create a directory for your shared files. Make sure that the server does not hav…...
RabbitMQ高级特性
RabbitMQ高级特性 消息可靠性投递 Consumer ACK 消费端限流 TTL 死信队列 延迟队列 日志与监控 消息可靠性分析与追踪 管理 消息可靠性投递 在使用 RabbitMQ 的时候,作为消息发送方希望杜绝任何消息丢失或者投递失败场景。RabbitMQ 为我们提供了两种方式用来控制…...
利用Dockerfile开发定制镜像实战.
Dockerfile的原理 dockerfile是一种文本格式的文件,用于描述如何构建Docker镜像。在Dockerfile中,我们可以定义基础镜像、安装依赖、添加文件等操作,最终生成一个可以直接运行的容器镜像。 Dockerfile的原理可以分为以下几个步骤:…...

PyInstaller 将DLL文件打包进exe
PyInstaller 将DLL文件打包进exe方法1:通过--add-data命令方法2:通过修改 .spec扩展:博主热门文章推荐:方法1:通过–add-data命令 注意:这里 dll末尾添加的.为当前目录,则该dll要放到main.py同一…...
:MySQL 持久化与 Redis 缓存机制源码解析)
DAG账本项目学习总结(七):MySQL 持久化与 Redis 缓存机制源码解析
1. 上期回顾在第六期中,我们分析了云端广播与交易确认机制。可以简单概括为:融合终端生成交易↓ 写入本地 DAG 账本↓ 广播给 cloud 和其他 fusion↓ cloud 插入全局账本↓ cloud 根据累计权重产生确认动作↓ 确认动作同步回各融合终端到这里为止&#x…...

终极Markdown Viewer浏览器扩展完整指南:打造高效文档阅读环境
终极Markdown Viewer浏览器扩展完整指南:打造高效文档阅读环境 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer Markdown Viewer是一款功能强大的浏览器扩展࿰…...

避坑指南:SV检测结果里那些奇怪的‘BND’和符号,到底在说什么?
结构变异检测实战:如何破译VCF文件中的BND密码 当你第一次打开SV检测生成的VCF文件时,那些DEL(缺失)和DUP(重复)的标签还算友好,但突然出现的BND(易位)和像[chr12:...[T、]chr12:...]A这样的神秘符号,是不是让你瞬间怀疑自己是否在…...

Go语言轻量级代理工具curxy:命令行驱动的HTTP/S请求转发与Mock服务器实践
1. 项目概述:一个轻量级的本地代理工具最近在折腾一些本地开发环境,特别是需要处理跨域请求或者模拟特定网络环境时,总是绕不开代理这个环节。用 Nginx 配置吧,对于简单的转发需求来说有点重;用 Node.js 写个简单的 HT…...

环境配置与基础教程:保姆级教程:VS Code DevContainer 一键构建可复现的 YOLO 训练开发容器
摘要 你是否还在为YOLO训练环境的搭建而焦头烂额?CUDA版本不匹配、Python依赖冲突、团队协作时“在我机器上能跑”的经典难题——这些问题浪费了无数开发者的宝贵时间。本文将带你通过VS Code DevContainer技术,一键构建完全可复现的YOLO训练开发容器,彻底告别环境配置噩梦…...

44《实车CAN总线报文ID含义与数据初步解读》
001、CAN总线基础与实车网络拓扑概述 从一次凌晨三点的“丢帧”说起 去年冬天,某主机厂的新能源车型在做冬季标定。凌晨三点,测试工程师打来电话,语气里带着疲惫和焦躁:“VCU发的车速信号,BMS偶尔收不到,但用CANoe监控又一切正常。”我赶到现场,第一件事不是看代码,而…...

3步实现智能自动化:三月七小助手如何每天为你节省90分钟游戏时间?
3步实现智能自动化:三月七小助手如何每天为你节省90分钟游戏时间? 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 你是否每天花费大量时间在《…...

智慧树刷课插件:3个核心功能帮你告别重复点击,学习效率提升300%
智慧树刷课插件:3个核心功能帮你告别重复点击,学习效率提升300% 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台繁琐的手动操作…...


创业公司利用Taotoken多模型能力进行A/B测试以优化产品效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业公司利用Taotoken多模型能力进行A/B测试以优化产品效果 对于AI产品创业团队而言,选择合适的大模型是产品成功的关键…...