Interview preparation--elasticSearch正排索引原理
正排索引
-
ElastciSearch 适合做或者说擅长做全文检索,在做全文检索的时候,他会通过生成倒排索引的方式来辅助查询,生成一个词项到 文档id的一个倒排表,这样直接通过 词项可以快速找到所有的 稳定信息。
-
但是并不是所有的搜索都是全文检索的需求,因此在ElasticSearch中还存在其他的查询方式,例如基础的聚合查询它用到的就是正排索引,底层使用的数据结构就是(doc values)
-
概念:doc values 本质上是一个序列化的 列式存储 。列式存储 适用于聚合、排序、脚本等操作,所有的数字、地理坐标、日期、IP 和不分词( not_analyzed )字符类型都会默认开启,不支持text和annotated_text类型。
-
如果在Mapping创建之初我就能确定某一些字段我一定不会参与聚合查询,那么我们应该将整个字段的doc values 设置为false,这样这个字段就不会参与正排索引的创建,以此来减少索引对磁盘空间的占用
正排索引 和 倒排索引的区别
- 倒排索引:倒排索引的优势是可以快速查找包含某个词项的文档有哪些。如果用倒排来确定哪些文档中是否包含某个词项就很鸡肋。
- 正排索引:正排索引的优势在于可以快速的查找某个文档里包含哪些词项。同理,正排不适用于查找包含某个词项的文档有哪些。
正排索引数据结构
- doc values:doc values是正排索引的基本数据结构之一,其存在是为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc values值以节省磁盘空间。
- fielddata:基于内存的一个正排索引,比如我们认为某个字段不需要参与聚合查询,但是我们可以开启fielddata的方式来应对临时查询,elasticsearch在对文档中字段A聚合查询的时候,如果A没有开启doc values,但是开启了fielddata,这个时候他会在内存中给A生成一个正排索引,基于内存的方式去走索引查询,fielddata 的构建和管理发生在 JVM Heap中,Fielddata默认是不启用的,因为text字段比较长,一般只做关键字分词和搜索,很少拿它来进行全文匹配和聚合还有排序。
案例分析正排索引 & 倒排索引
- 有如下json数据
{"id":"1","name":"xiaomi phone","price":13999,"date":"2024-05-19","tags":["xingjiabi","fashao","buka"]}{"id":"2","name":"hongmi erji","price":4999,"date":"2024-05-20","tags":["xingjiabi","fashao","menjinka"]}{"id":"3","name":"xiaomi erji","price":4999,"date":"2024-05-20","tags":["xingjiabi","fashao","menjinka"]}{"id":"4","name":"hongmi phone","price":4999,"date":"2024-05-20","tags":["xingjiabi","fashao","menjinka"]}{"id":"5","name":"xiaomi nfc erji","price":399,"date":"2024-05-20","tags":["newbee","xuhangniu","zhiliangx"]}
- 正排索引构建出来的正排表如下:
正排索引:每个doc包含哪些term
doc1: term1、term2、term3...
doc2: term1、term2、term3...
doc3: term1、term2、term3...
doc4: term1、term2、term3...
doc5: term1、term2、term3...
.....
- 倒排索引构建出来的倒排表如下:
倒排索引:哪些doc包含了当前term
xiaomi: doc1、doc3、doc5...
term2: doc2、doc3、doc6...
term3: doc5、doc4、doc2...
term4: doc1、doc7、doc8...
term5: doc1、doc6、doc9...
.....
正排索引总结
- 倒排索引适用于确认 term 在哪些文档中, 正排索引正好相反适用于确认某个文档中存在哪些term
- 正排索引 和 倒排索引都是在index-time时候 创建,存储位置都是在lucene文件中序列化到磁盘中
- doc values 使用非jvm heap,对gc友好
- 不分词的field在index-time的时候会生成正排索引,在做聚合查询的时候使用正排索引,设置了分词的field在index-time的时候没有正排索引,而没有doc values的field需要做聚合查询的唯一方式就是开启fielddata,让es在内存中生成一个临时的正排索引
doc values & fieldData 优化与使用限制
- 因为filedData会在内存中生成正排索引表,那么会有很多限制
- doc values优化:fielddata使用的是jvm内存,doc value在内存不足时会静静的待在磁盘中,而当内存充足是,也会蹦到内存里提升性能。
- fieldData 优化:Fielddata默认是不启用的,因为text字段比较长,一般只做关键字分词和搜索,很少拿它来进行全文匹配和聚合还有排序。
- ES采用了circuit breaker(熔断)机制避免field data一次性超过物理内存大小而导致内存溢出,如果触发熔断,查询会被终止并返回异常。
相关文章:

Interview preparation--elasticSearch正排索引原理
正排索引 ElastciSearch 适合做或者说擅长做全文检索,在做全文检索的时候,他会通过生成倒排索引的方式来辅助查询,生成一个词项到 文档id的一个倒排表,这样直接通过 词项可以快速找到所有的 稳定信息。 但是并不是所有的搜索都是…...
C++精解【10】
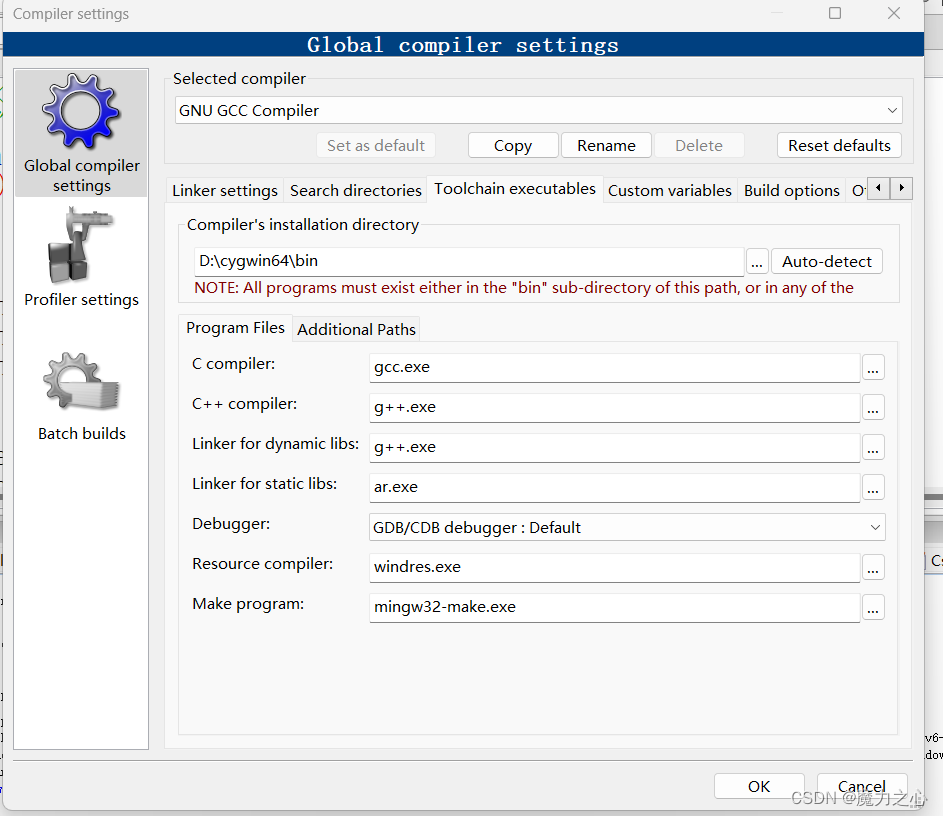
文章目录 constexpr函数GMP大整数codeblock环境配置数据类型函数类 EigenminCoeff 和maxCoeffArray类 constexpr函数 函数可能在编译时求值,则声明它为constexpr,以提高效率。需要使用constexpr告诉编译器允许编译时计算。 constexpr int min(int x, i…...
Linux高级编程——进程
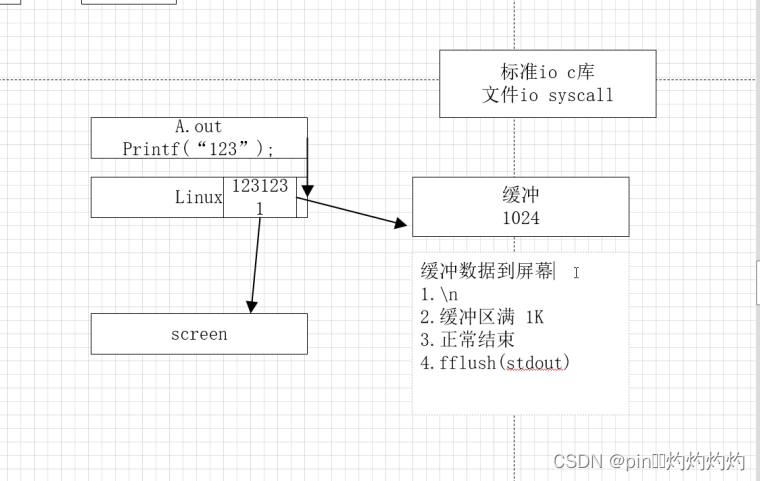
1.进程的含义? 进程是一个程序执行的过程,会去分配内存资源,cpu的调度 PID, 进程标识符 当前工作路径 chdir umask 0002 进程打开的文件列表 文件IO中有提到 (类似于标准输入 标准输出的编号,系统给0,1…...

手机数据恢复篇:如何在OPPO中恢复永久删除的视频?
说到丢失重要的记忆,如何在OPPO设备中恢复永久删除的视频是一个经常困扰许多用户的话题。意外删除重要视频的情况并不少见,对许多人来说,意识到它们已经消失可能很困难。但是,在正确的指导、方法和工具的帮助下,可以找…...

Obsidan插件开发
1 Obidian 开发 Obsidian 基于 Electron 框架开发,其前端主要使用了 HTML、CSS 和 JavaScript,而后端使用了 Node.js。Node.js 是基于 Chrome V8 引擎的 JavaScript 运行环境,使 JavaScript 能在服务器端运行。 在开发 Obsidian 插件时&…...

【全球首个开源AI数字人】DUIX数字人-打造你的AI伴侣!
目录 1. 引言1.1 数字人技术的发展背景1.2 DUIX数字人项目的开源意义1.3 DUIX数字人技术的独特价值1.4 本文目的与结构 2. DUIX数字人概述2.1 定义与核心概念2.2 硅基智能与DUIX的关系2.3 技术架构2.4 开源优势2.5 应用场景2.6 安全与合规性 3. DUIX数字人技术特点3.1 开源性与…...
微信小程序服务器从腾讯云迁移到阿里云出现的坑
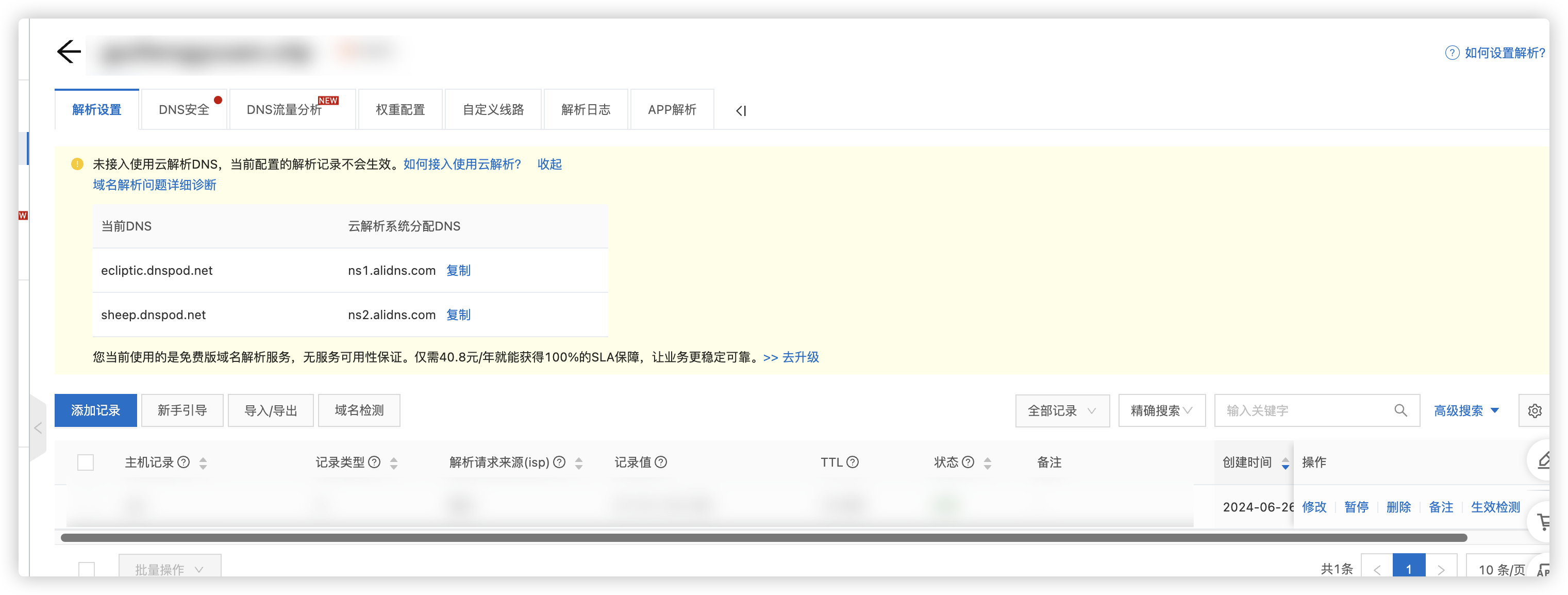
微信小程序服务器从腾讯云迁移到阿里云出现的坑 背景 原先小程序后台服务器到期,因为之前买的是腾讯云新用户,便宜,到期后续费金额懂的都懂。就在阿里云用新用户买了个新的,遂把服务全转到了阿里云服务器上。 此时,域…...

SQL Server触发器深度解析:数据完整性的守护者
标题:SQL Server触发器深度解析:数据完整性的守护者 摘要 在SQL Server中,触发器是一种特殊的存储过程,它在特定数据库事件发生时自动执行。触发器主要用于维护数据的完整性和实施复杂的业务规则。本文将详细介绍SQL Server中触…...
Qt信号槽的坑
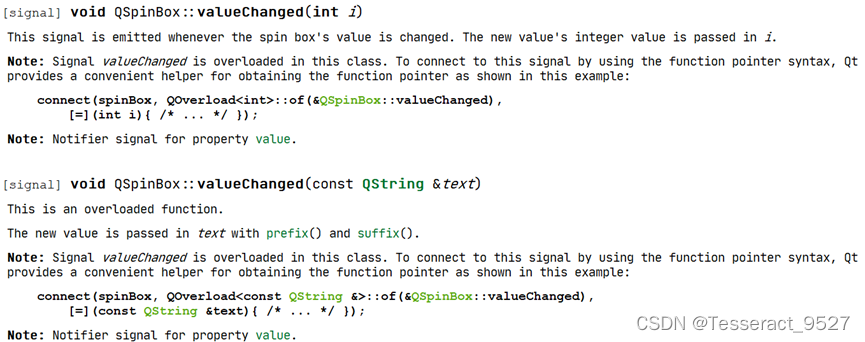
1、重载的信号(以QSpinBox为例) 像是点击按钮之类的信号槽很好连接,这是因为它的信号没有重载,如果像SpinBox那样有重载信号的话(Qt5.12的见下图,不过Qt5.15LTS开始就不再重载而是换信号名了)&…...
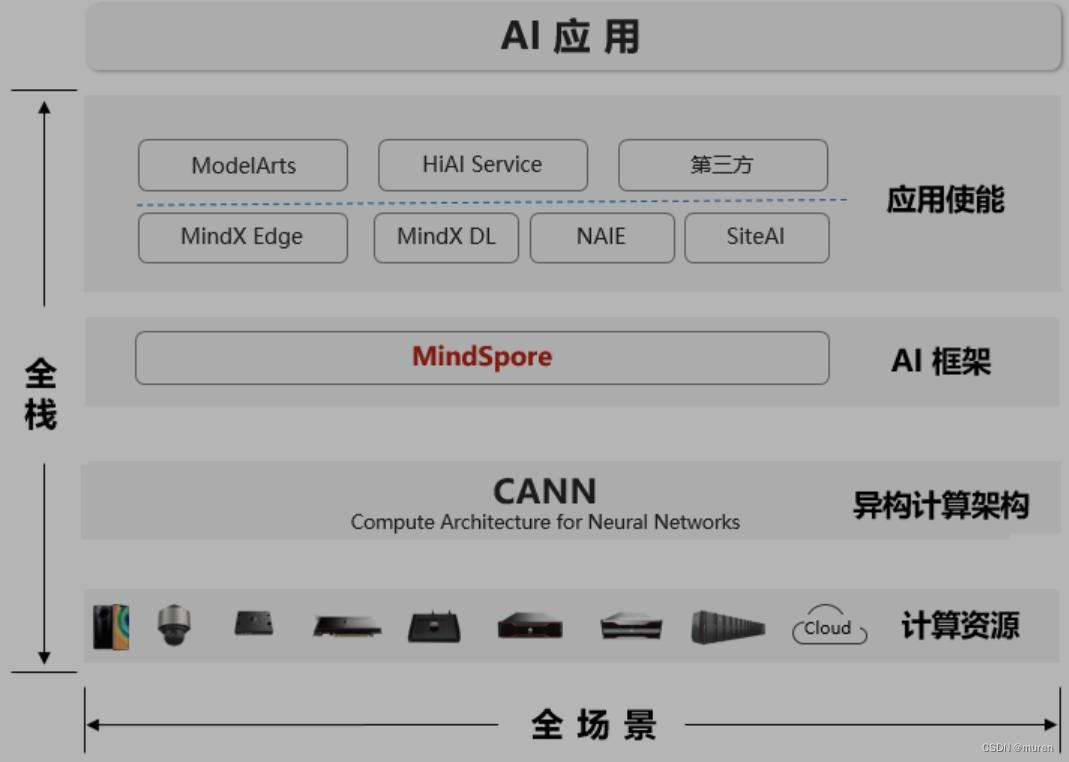
昇思MindSpore学习笔记1--基本介绍
昇思MindSpore是一个全场景深度学习框架。 一、框架组成 1. 模型库ModelZoo 提供深度学习算法网络。 2. 扩展库MindSpore Extend 拓展领域场景,如GNN/深度概率编程/强化学习等。 3. 科学计算MindSpore Science 科学计算套件。 包含数据集、基础模型、预置高精度模…...

Github Page 使用手册(保姆级教程!)
搭建个人网站?没有服务器?那不如尝试一下 Github Page ! 最近我正好在搭建个人网站,于是就写一篇博客来详细介绍 Github Page 的使用、部署方式吧! 一、进入 Github 访问:github.com 如果你没有 github…...

zram压缩机制看swapon系统调用
1.swapon开启zram交换分区 swapon /dev/block/zram0 mkswap /dev/block/zram0 上面命令调用了linux的swapon系统调用启动zram0交换分区;mkswap命令向块设备文件/dev/block/zram0写入了swap_header信息 问题:实际安卓平台是哪里触发swapon和mkswap调用的ÿ…...
SpringBoot2+Vue3开发博客管理系统
项目介绍 博客管理系统,可以帮助使用者管理自己的经验文章、学习心得、知识文章、技术文章,以及对文章进行分类,打标签等功能。便于日后的复习和回忆。 架构介绍 博客管理系统采用前后端分离模式进行开发。前端主要使用技术:Vu…...
)
JS【详解】Symbol (含Symbol 作为属性名,静态方法for 和 keyFor,11 个内置的 Symbol 值)
ES6 语法,表示唯一且不可变的值,常用作属性键值或者唯一标识符。 let a Symbol() let a Symbol(atomic symbol)console.log(Symbol() Symbol()) // false console.log(Symbol(atom) Symbol(atom)) // falseSymbol 作为属性名 let key Symbol(); le…...
Vue 项目运行时,报错Error: Cannot find module ‘node:path‘
Vue 项目运行时,报错Error: Cannot find module ‘node:path’ internal/modules/cjs/loader.js:883throw err;^Error: Cannot find module node:path Require stack: - D:\nodejs\node_modules\npm\node_modules\node_modules\npm\lib\cli.js - D:\nodejs\node_mo…...

综合评价 | 基于组合博弈赋权的物流系统综合评价(Matlab)
目录 效果一览基本介绍程序设计参考资料 效果一览 基本介绍 综合评价 | 基于组合博弈赋权的物流系统综合评价(Matlab) 组合博弈赋权(Weighted Sum)是一种常见的多目标决策方法,用于将多个目标指标进行综合评估和权衡…...
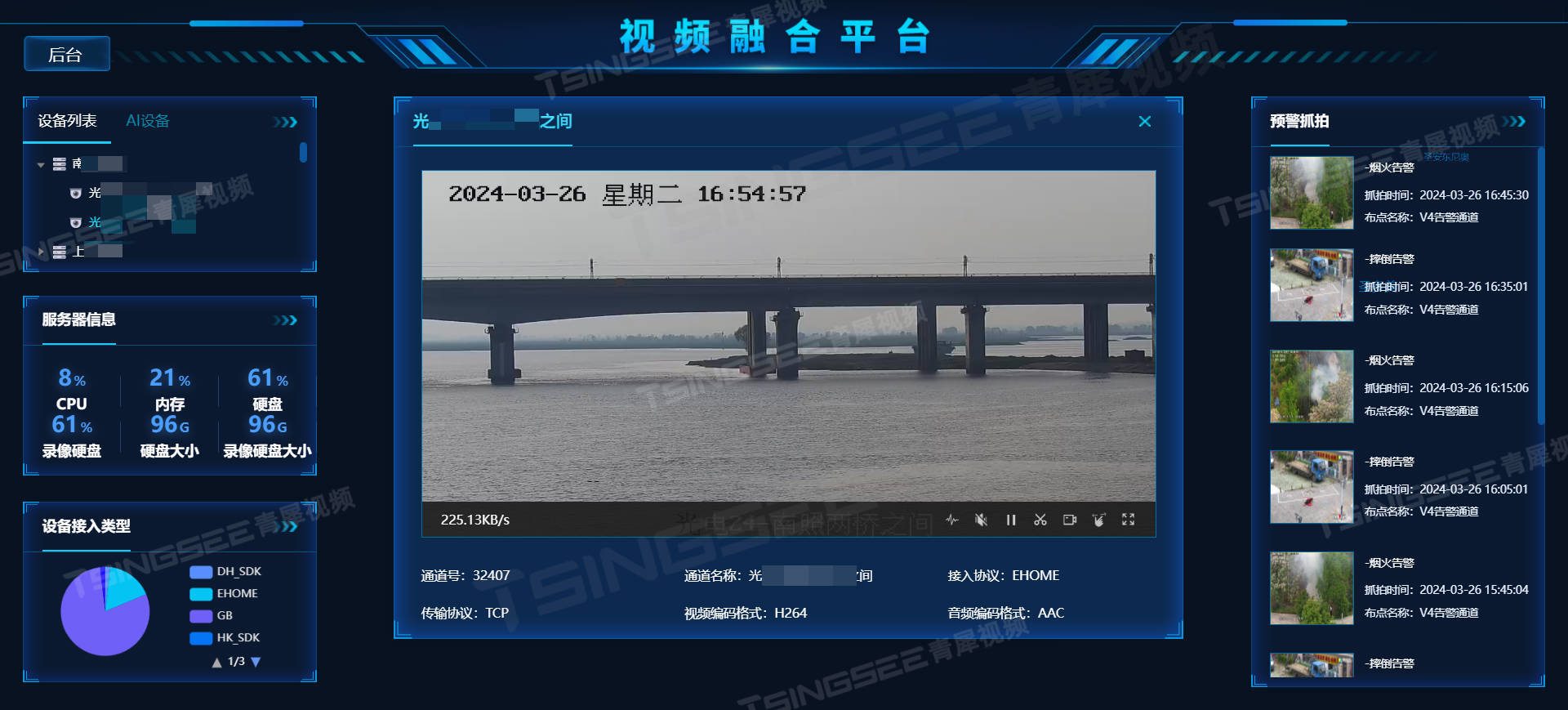
国标GB28181视频汇聚平台EasyCVR安防监控系统常见播放问题分析及解决方法
国标GB28181安防综合管理系统EasyCVR视频汇聚平台能在复杂的网络环境中,将前端设备统一集中接入与汇聚管理。平台支持多协议接入,包括:国标GB/T 28181协议、GA/T 1400协议、RTMP、RTSP/Onvif协议、海康Ehome、海康SDK、大华SDK、华为SDK、宇视…...
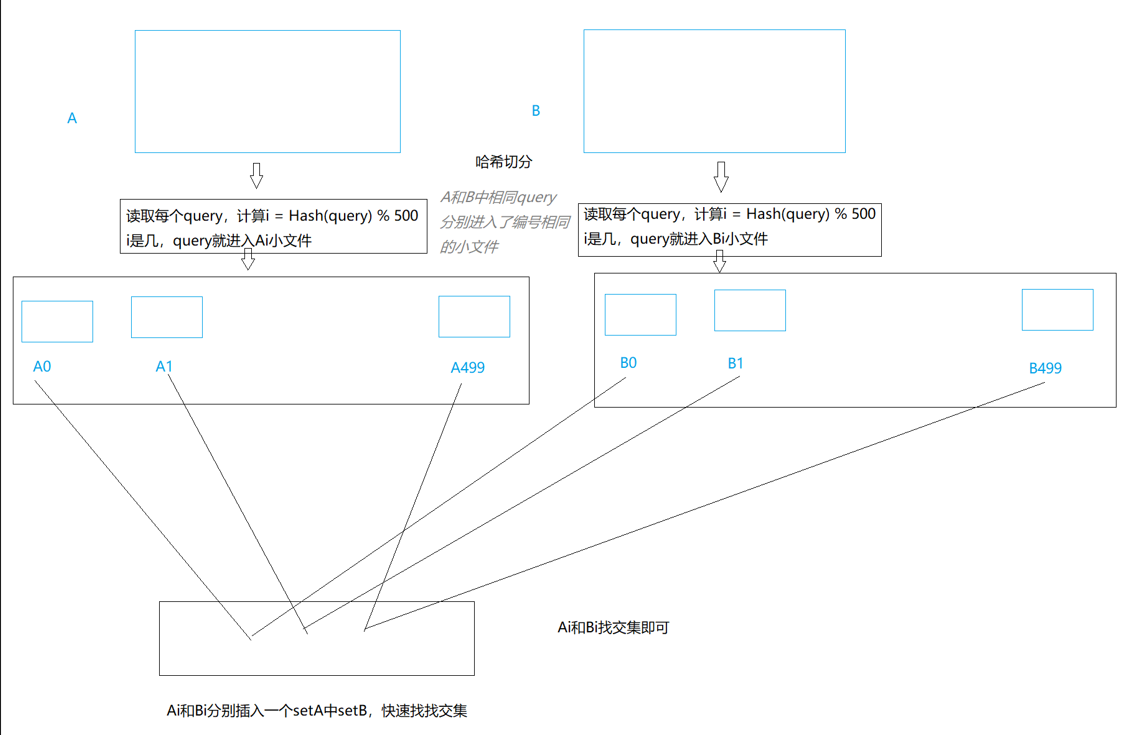
30 哈希的应用
位图 概念 题目 给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何判断一个数是否在这40亿个整数中 1.遍历,时间复杂度O(N) 2.二分查找,需要先排序,排序(N*logN),二分查找,logN。…...
(笔记)Error: qemu-virgl: Failed to download resource “qemu-virgl--test-image“解决方法
错误: > Downloading https://www.ibiblio.org/pub/micro/pc-stuff/freedos/files/distributions/1.2/FD12FLOPPY.zip curl: (22) The requested URL returned error: 404Error: qemu-virgl: Failed to download resource "qemu-virgl--test-image" D…...

IntelliJ IDEA介绍
IntelliJ IDEA 是由 JetBrains 开发的一个集成开发环境 (IDE),专门为 Java 开发设计,同时也支持多种其他编程语言和框架。IntelliJ IDEA 以其智能代码分析、强大的重构功能以及丰富的插件生态系统而闻名,是许多开发者的首选 IDE。 IntelliJ IDEA介绍 IntelliJ IDEA 的主要…...

HS2-HF_Patch终极指南:一键为Honey Select 2安装完整增强补丁
HS2-HF_Patch终极指南:一键为Honey Select 2安装完整增强补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF_Patch是专为《Honey Select 2》…...

OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统
OpenCore Legacy Patcher终极指南:5步让老旧Mac完美运行最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是…...

构建本地化个人助理系统:事件驱动架构与模块化设计实践
1. 项目概述:一个高度可定制的个人助理系统最近在GitHub上看到一个挺有意思的项目,叫“Personal-Assistant”,作者是idk-man69。光看名字,你可能会觉得这又是一个类似Siri或Google Assistant的语音助手,但点进去仔细研…...

在线Graphviz图表编辑器:3步创建专业技术流程图
在线Graphviz图表编辑器:3步创建专业技术流程图 【免费下载链接】GraphvizOnline Lets Graphviz it online 项目地址: https://gitcode.com/gh_mirrors/gr/GraphvizOnline 还在为复杂的技术图表绘制而烦恼吗?GraphvizOnline作为一款革命性的在线G…...

Linuxbonding链路异常定位实战
Linuxbonding链路异常定位实战这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限、…...
)
从图片到摄像头:用YOLOv8n.pt模型在Win10上实现实时目标检测(代码+命令详解)
从图片到摄像头:用YOLOv8n.pt模型在Win10上实现实时目标检测(代码命令详解) 当计算机视觉遇上边缘计算,目标检测技术正在重塑人机交互的边界。YOLOv8作为当前最先进的实时检测框架之一,其轻量级版本yolov8n.pt在普通消…...

AI智能体操作安卓设备:基于agent-droid-bridge的自动化实践
1. 项目概述:连接AI与安卓设备的桥梁 最近在折腾AI智能体(Agent)和自动化流程时,遇到了一个挺有意思的需求:如何让运行在服务器上的AI程序,直接去操作一台真实的安卓手机或模拟器,完成一些复杂的…...

安得医疗冲刺港股:年营收9亿,利润1.5亿 上海亿瑞控制41%股权
雷递网 雷建平 5月16日山东安得医疗用品股份有限公司(简称:“安得医疗”)日前递交招股书,准备在港交所上市。截至2023年、2024年及2025年12月31日止年度,安得医疗分别宣派及派付股息6670万元、4670万元及4000万元。年营…...

Arm CoreLink PCK-600电源管理套件解析与应用实践
1. Arm CoreLink PCK-600电源控制套件概述在现代SoC设计中,电源管理已经成为一个关键的技术挑战。随着移动设备和物联网应用的普及,如何在保证性能的同时最大限度地降低功耗,成为芯片设计者面临的核心问题。Arm CoreLink PCK-600电源控制套件…...

RTKLIB 2.4.3项目在Visual Studio 2019中的工程化配置:告别零散文件,打造清晰结构
RTKLIB 2.4.3项目在Visual Studio 2019中的工程化配置:告别零散文件,打造清晰结构 对于卫星导航领域的开发者而言,RTKLIB无疑是一个绕不开的开源项目。这个由日本学者Tomoji Takasu开发的GNSS定位软件,以其强大的功能和开放的架构…...