30 哈希的应用
位图
概念
题目
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何判断一个数是否在这40亿个整数中
1.遍历,时间复杂度O(N)
2.二分查找,需要先排序,排序(N*logN),二分查找,logN。1个g大约存储10g字节,40亿个整数就需要160g字节,需要16个g的连续空间,内存中无法开出这么大的容量。
3.位图。判断一个数在不在的最小单位可以是位,将整数的范围全部做一个映射,有的值设置为1,没有就设置为0。这样,需要的空间就是42亿个位,0.5个g就可以存下

上面是3个字节的值,一个字节32位,可以表示的数的范围。计算一个值在第几个字节,在这个字节的第几个位。将一个数除以32就知道在第几个字节,取模就知道在第几个位,比如40,在第1个字节里,在第8位
位图概念
用每一位存放某种状态,适用于海量数据,数据无重复的场景,判断某个数据村部还存在的
实现
成员函数
可以用内置数组,这里直接用vector,成员类型是int
构造
为vector开辟需要的空间,每一位代表一个值,看需要多大的值,用非类型模板参数传入值。传入的是位,除以32再补上去的余数的一位,就是开辟多大整形的空间

set
将这个数据映射的值设为1。计算出数据所在的位,设置为1。i和j分别计算在第几个字节和第几位,让一个数的一位变为1,其他位不变化,可以或一个数,这个数这一位为1,其他位为0。可以将1左移j位就有了这个数
内存有大端和小端存储,左移都是往高位移动

reset
将这个数据清除,变为0。计算出i和j,让某一位变为0,可以与一个数,这个数这一位为0,其他都为1。1左移j位然后取反

test
查询一个数是否存在。1左移j位,与操作

全
#pragma once
#include <vector>//N是需要多少位
template <size_t N>
class bitset
{
public:bitset(){//多开一个防止不够_bit.resize(N / 32 + 1, 0);//_bit.resize( (N >> 5) + 1, 0)}void set(size_t x){int i = x / 32;int j = x % 32;_bit[i] = _bit[i] | (1 << j);}void reset(size_t x){int i = x / 32;int j = x % 32;_bit[i] = _bit[i] & ~(1 << j);}bool test(size_t x){int i = x / 32;int j = x % 32;return _bit[i] & (1 << j);}
public:std::vector<int> _bit;
};
测试
40亿的整数需要开辟的空间必须是无符号的整形大小,int是有符号的,所以用0xffffffff或-1

bitset<0xffffffff> bs;
bs.set(39256);
bs.set(43450);
bs.reset(40);cout << bs.test(24515) << endl;
cout << bs.test(32329) << endl;
cout << bs.test(39256) << endl;
cout << bs.test(2314) << endl;
cout << bs.test(43450) << endl;

应用
1.快速查找某个数据是否在一个集合中
2.排序+去重
3.求两个集合的交集、并集等
4.操作系统重磁盘块标记
题目
1.给定100亿个整数,设计算法找到只出现一次的整数
位图用一个位标识两种状态,存在和不在,找到出现一次的数需要第三种状态,可以用两个位来保存一个数。也可以复用前面的位图,用一个结构,成员两个位图。set时,当两个位图表示的是00的时候,就设置为01,01就设置为10,10就不做任何改变。打印的时候打印出01状态的数字
template <size_t N>
class twobitset
{
public:void set(size_t x){//00 0次//01 1次//10 2次或以上int i = x / 32;int j = x % 32;if (_bs1.test(x) == false && _bs2.test(x) == false){_bs2.set(x);}else if (_bs1.test(x) == false && _bs2.test(x) == true){_bs1.set(x);_bs2.reset(x);}}void printOne(){for (size_t i = 0; i < N; i++){if (_bs1.test(i) == false && _bs2.test(i) == true){printf("%d ", i);}}printf("\r\n");}public:bitset<N> _bs1;bitset<N> _bs2;
};
2.给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集
和上面的方法一样,无论多少整数,还是申请42亿,两个位图里都有的就是交集
3.位图变形,一个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
还是上面的类型,稍微修改,set函数10的时候变为11,11不变
template <size_t N>
class twobitset
{
public:void set(size_t x){//00 0次//01 1次//10 2次或以上int i = x / 32;int j = x % 32;if (_bs1.test(x) == false && _bs2.test(x) == false){_bs2.set(x);}else if (_bs1.test(x) == false && _bs2.test(x) == true){_bs1.set(x);_bs2.reset(x);}else if (_bs1.test(x) == true && _bs2.test(x) == false){_bs1.set(x);_bs2.set(x);}}void printOne(){for (size_t i = 0; i < N; i++){if (_bs1.test(i) == false && _bs2.test(i) == true){printf("一次%d ", i);}else if (_bs1.test(i) == true && _bs2.test(i) == false){printf("两次%d ", i);}}printf("\r\n");}public:bitset<N> _bs1;bitset<N> _bs2;
};
布隆过滤器
提出
每次看新闻时,会不断推荐新的内容,去掉已经看过的内容。问题来了,如何实现推送去重的,用服务器记录所有看过的记录,当推荐系统推荐新闻时从每个用户的历史记录里筛选,过滤掉已经存在的记录,怎么快速查找
目前搜索采用的各种方法
1.暴力查找,数据量太大了,效率就低
2.排序+二分查找,问题a:排序有代价 问题b:数组不方便增删
3.搜索树,avl树+红黑树
上面的数据结构对空间消耗的都很高,如果面对数据量很大的
5.[整形],在不在及其扩展问题,位图和变形,节省空间
6.[其他类型] 在不在,哈希和位图结合,布隆过滤器
概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的一种紧凑型的、比较巧妙的概率性数据结构,特点是高效的插入和查询,可以判断一个东西一定不在或可能在,是用多个哈希函数,将一个数据映射到位图结构中,此种方式不仅可以提升查询效率,也可以节省大量的内存空间

一个值映射一个比特位,冲突的概率很大,两个不同的字符串正好映射在一个比特位,这时判断的存在就是错误的。为了降低误判的概率,多映射几个比特位,映射的越多,消耗的空间就越多
插入
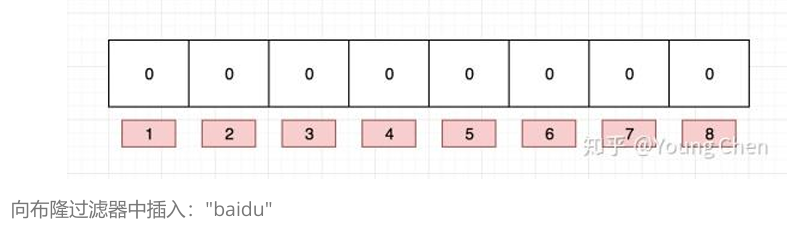

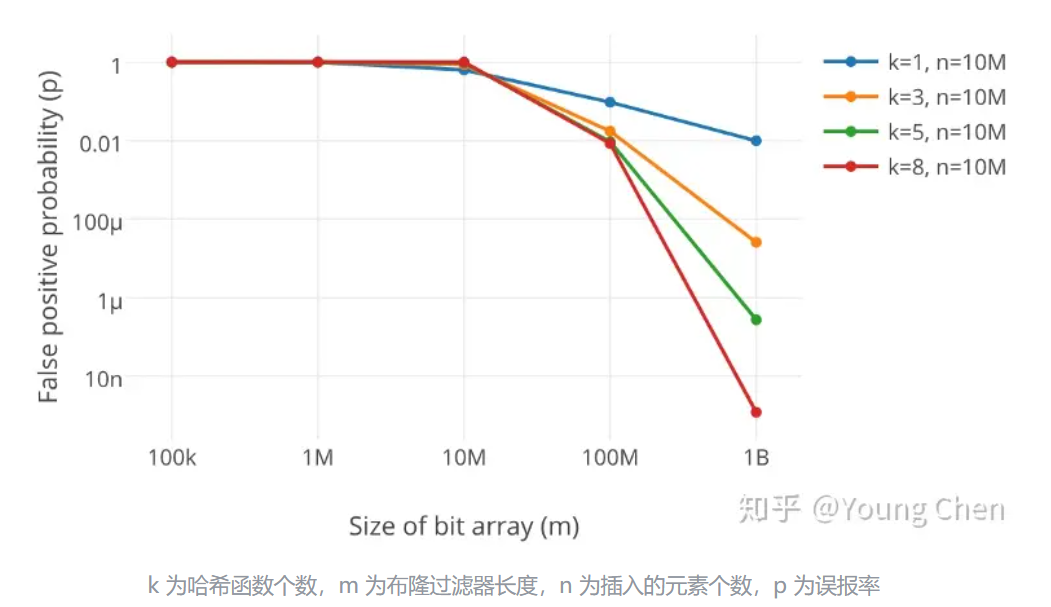 上图中,当k3个时,100m数据误判率0.01已经很低了
上图中,当k3个时,100m数据误判率0.01已经很低了

按公式计算:

3个哈希函数,n和m的关系是4.3,约为4倍容量
查找
将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置比特位一定为1.所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为零,只要有一个零,代表该元素一定不在哈希表中,否则可能在哈希表中
注意:布隆过滤器如果说某个元素不存在时,一定不存在,如果该元素存在时,可能存在,因为存在一定的误判
删除
不能直接支持删除操作,因为在删除一个元素时,可能影响到其他元素
比如:删除上图的"tecent”元素,如果直接将该元素对应的二进制比特位置置为0,“baidu”元素也被删除了,因为这两个元素在多个哈希函数计算的比特位有重叠
一种支持删除的方法:将布隆罗氯气每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。如果引用计数最大为255时,映射的单位就必须扩展为8位
缺陷:
1.无法确认元素是否真正在布隆过滤器中
2.存在计数回绕
实现
#pragma once
#include <bitset>struct BKDRHash
{size_t operator()(const std::string& key){// BKDRsize_t hash = 0;for (auto e : key){hash *= 31;hash += e;}return hash;}
};struct APHash
{size_t operator()(const std::string& key){size_t hash = 0;for (size_t i = 0; i < key.size(); i++){char ch = key[i];if ((i & 1) == 0){hash ^= ((hash << 7) ^ ch ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));}}return hash;}
};struct DJBHash
{size_t operator()(const std::string& key){size_t hash = 5381;for (auto ch : key){hash += (hash << 5) + ch;}return hash;}
};template <size_t N, class K = std::string,class HashFunc1 = BKDRHash,class HashFunc2 = APHash,class HashFunc3 = DJBHash>
class BloomFilter
{
public:void set(const std::string& key){size_t hashi1 = HashFunc1()(key) % N;size_t hashi2 = HashFunc2()(key) % N;size_t hashi3 = HashFunc3()(key) % N;_bs.set(hashi1);_bs.set(hashi2);_bs.set(hashi3);}// 一般不支持删除,删除一个值可能会影响其他值// 非要支持删除,也是可以的,用多个位标记一个值,存引用计数// 但是这样话,空间消耗的就变大了void Reset(const K& key);bool test(const std::string& key){size_t hashi1 = HashFunc1()(key) % N;if (_bs.test(hashi1) == false)return false;size_t hashi2 = HashFunc2()(key) % N;if (_bs.test(hashi2) == false)return false;size_t hashi3 = HashFunc3()(key) % N;if (_bs.test(hashi3) == false)return false;return true;}private:std::bitset<N> _bs;
};
测试
#include <time.h>
#include <vector>
#include <iostream>
#include <string>
#include "bloom.h"int main()
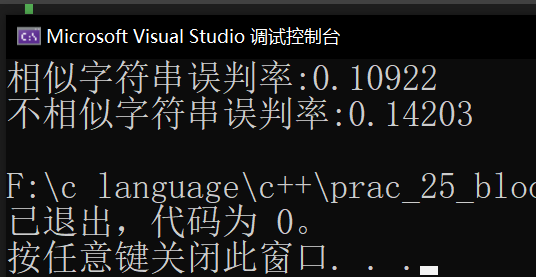
{srand(time(0));const size_t N = 100000;BloomFilter<N * 4> bf;std::vector<std::string> v1;//std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";std::string url = "猪八戒";for (size_t i = 0; i < N; ++i){v1.push_back(url + std::to_string(i));}for (auto& str : v1){bf.set(str);}// v2跟v1是相似字符串集(前缀一样),但是不一样std::vector<std::string> v2;for (size_t i = 0; i < N; ++i){std::string urlstr = url;urlstr += std::to_string(9999999 + i);v2.push_back(urlstr);}size_t n2 = 0;for (auto& str : v2){if (bf.test(str)) // 误判{++n2;}}std::cout << "相似字符串误判率:" << (double)n2 / (double)N << std::endl;// 不相似字符串集std::vector<std::string> v3;for (size_t i = 0; i < N; ++i){//string url = "zhihu.com";std::string url = "孙悟空";url += std::to_string(i + rand());v3.push_back(url);}size_t n3 = 0;for (auto& str : v3){if (bf.test(str)){++n3;}}std::cout << "不相似字符串误判率:" << (double)n3 / (double)N << std::endl;return 0;
}
优点
1.增加和查询元素的时间复杂度为:O(K),(k为哈希函数个数,一般比较小),与数据数量无关
2.哈希函数相互之间没有关系,方便硬件并行计算
3.布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
4.能够承受一定的误判时,布隆过滤器比其他数据结构有很大的空间优势
5.数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
6.使用同一组散列函数的布隆过滤器可以进行交、并、差运算
例如网页注册时,判断用户名存不存在。如果需要更进一步正确,可以将判断为存在的和数据库对比
缺陷
1.有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存在可能会误判的数据)
2.不能获取元素本身
3.一般情况下不能从布隆过滤器中删除元素
4.如果采用计数方式删除,可能会存在计数回绕问题
哈希切割
1. 给定两个文件,分别有100亿个query(字符串),只有1G内存,找到文件交集,精确算法和近似算法
近似算法就是上面的布隆过滤器
精确算法:
假设一个query有50个字节,100亿数据就需要500G,内存存不下,可以用哈希切分
读取每个query,计算i=Hash(query)%500,i是几,query就进入Ai小文件
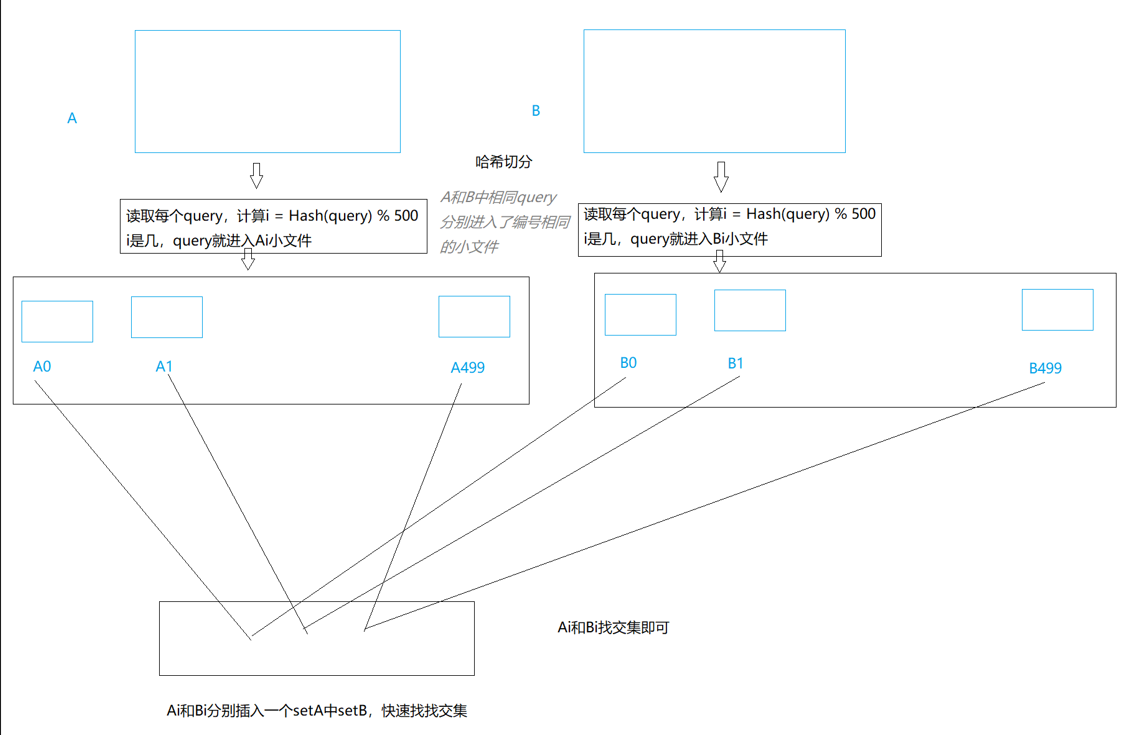
A和B相同的字符串会进入相同编号的块里,只需要比较两个相同编号的块,就能找到交集
如果切分的某个文件大于10G,还是无法加载到内存里?
1.这个小文件大多数都是1个query
2.这个小文件,有很多不同的query
不管文件大小,直接读到内存插入set,如果是情况1,文件有很多重复,会去重
如果是情况2,插入后就会内存不足,抛异常,换一个哈希函数,二次划分,再找交集
2. 给一个超过100G大小的logfile,存ip地址,设计找出次数最多的ip地址
还是用哈希切分,相同的ip就进入了同一个小文件,然后用map统计次数。如果找topk,也可以用堆来解决
相关文章:
30 哈希的应用
位图 概念 题目 给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何判断一个数是否在这40亿个整数中 1.遍历,时间复杂度O(N) 2.二分查找,需要先排序,排序(N*logN),二分查找,logN。…...
(笔记)Error: qemu-virgl: Failed to download resource “qemu-virgl--test-image“解决方法
错误: > Downloading https://www.ibiblio.org/pub/micro/pc-stuff/freedos/files/distributions/1.2/FD12FLOPPY.zip curl: (22) The requested URL returned error: 404Error: qemu-virgl: Failed to download resource "qemu-virgl--test-image" D…...

IntelliJ IDEA介绍
IntelliJ IDEA 是由 JetBrains 开发的一个集成开发环境 (IDE),专门为 Java 开发设计,同时也支持多种其他编程语言和框架。IntelliJ IDEA 以其智能代码分析、强大的重构功能以及丰富的插件生态系统而闻名,是许多开发者的首选 IDE。 IntelliJ IDEA介绍 IntelliJ IDEA 的主要…...

【office技巧】如何合并pdf并且添加目录页
所用工具:wps,acrobat reader 1.制作目录页 在wps里设置一级标题,二级标题,然后自动生成目录页,保存为pdf。 在acrobat reader里删除除了目录页之外的其他页面。 2.pdf合并 在acrobat reader里合并pdf。 注意有可能…...

Spring Boot中的安全性配置详解
Spring Boot中的安全性配置详解 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将深入探讨如何在Spring Boot应用中实现全面的安全性配置,保…...

数据权限和字段权限设计指南
数据权限和字段权限的设计是信息系统安全的基础。随着数据量的增加和用户需求的多样化,合理的权限设计变得愈加重要。本文将介绍数据权限和字段权限的基本概念、设计思路和实际应用,帮助读者建立全面的权限管理体系。 2. 数据权限设计 2.1 数据权限的定…...

Linux 常用命令之 RZ和SZ 简介
一、引言 在Linux系统管理中,尤其是在远程操作时,文件的上传与下载是常见的需求。对于CentOS用户而言,rz和sz这两个命令提供了简单而高效的文件传输方式,尤其在SSH终端环境中更为便利。本文将详细介绍rz和sz命令的基本概念、如何…...

Docker Compose:简化多容器管理的利器
在现代的应用开发和部署过程中,Docker已经成为不可或缺的工具。它通过容器化技术,使得应用的部署变得更加轻松和高效。然而,当我们需要管理和运行多个容器时,单纯依赖Docker命令行工具可能会显得繁琐且复杂。这时,Dock…...

深度解析:机器学习如何助力GPT-5实现语言理解的飞跃
文章目录 文章前言机器学习在GPT-5中的具体应用模型训练与优化机器翻译与跨语言交流:情感分析与问答系统:集成机器学习功能:文本生成语言理解任务适应 机器学习对GPT-5性能的影响存在的挑战及解决方案技术细节与示例 文章前言 GPT-5是OpenAI公…...
Springcloud-消息总线-Bus
1.消息总线在微服务中的应用 BUS- 消息总线-将消息变更发送给所有的服务节点。 在微服务架构的系统中,通常我们会使用消息代理来构建一个Topic,让所有 服务节点监听这个主题,当生产者向topic中发送变更时,这个主题产生的消息会被…...

js 接收回调函数 转换为promise
下面是一个示例代码,展示如何编写一个接收回调函数并将其转换为 Promise 的 JavaScript 函数: // 定义一个接收回调函数并转换为 Promise 的函数 function convertCallbackToPromise(callbackFunction) {// 返回一个新的 Promise 对象return new Promis…...

Python 面试【★★★】
欢迎莅临我的博客 💝💝💝,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「stormsha的主页」…...
计算机网络(物理层)
物理层 物理层最核心的工作内容就是解决比特流在线路上传输的问题 基本概念 何为物理层?笼统的讲,就是传输比特流的。 可以着重看一下物理层主要任务的特性 传输媒体 传输媒体举例: 引导型传输媒体 引导型传输媒体指的是信号通过某种…...

OpenGL-ES 学习(6)---- 立方体绘制
目录 立方体绘制基本原理立方体的顶点坐标和绘制顺序立方体颜色和着色器实现效果和参考代码 立方体绘制基本原理 一个立方体是由8个顶点组成,共6个面,所以绘制立方体本质上就是绘制这6个面共12个三角形 顶点的坐标体系如下图所示,三维坐标…...

《数据结构与算法基础 by王卓老师》学习笔记——类C语言有关操作补充
1.元素类型说明 2.数组定义 3.C语言的内存动态分配 4..C中的参数传递 5.传值方式 6.传地址方式 例子...

高频面试题基本总结回顾2(含笔试高频算法整理)
干货分享,感谢您的阅读! (暂存篇---后续会删除,完整版和持续更新见高频面试题基本总结回顾(含笔试高频算法整理)) 备注:引用请标注出处,同时存在的问题请在相关博客留言…...
》)
《深入浅出MySQL:数据库开发、优化与管理维护(第3版)》
深入浅出MySQL sql执行流程第一步:通过连接器进行连接第二步:解析器解析 SQL第三步:执行SQL 行记录存储格式行溢出日志数据库三大范式第一范式第二范式第三范式 索引索引分类B树索引BTree vs Hash需要索引1、字段需要频繁的查询操作2、字段用…...
VBA技术资料MF171:创建指定工作表数的工作簿
我给VBA的定义:VBA是个人小型自动化处理的有效工具。利用好了,可以大大提高自己的工作效率,而且可以提高数据的准确度。“VBA语言専攻”提供的教程一共九套,分为初级、中级、高级三大部分,教程是对VBA的系统讲解&#…...
【效率提升】新一代效率工具平台utools
下载地址:utools uTools这款软件,是一款功能强大且高度可定制的效率神器,使用快捷键alt space(空格) 随时调用,支持调用系统应用、用户安装应用和市场插件等。 utools可以调用系统设置和内置应用,这样可以方便快捷的…...

Jmeter插件管理器,websocket协议,Jmeter连接数据库,测试报告的查看
目录 1、Jmeter插件管理器 1、Jmeter插件管理器用处:Jmeter发展并产生大量优秀的插件,比如取样器、性能监控的插件工具等。但要安装这些优秀的插件,需要先安装插件管理器。 2、插件的下载,从Availabale Plugins中选择ÿ…...

Swagger2Word终极指南:3种方法实现API文档自动化转换
Swagger2Word终极指南:3种方法实现API文档自动化转换 【免费下载链接】swagger2word 项目地址: https://gitcode.com/gh_mirrors/swa/swagger2word 还在为手动编写API文档而烦恼吗?Swagger2Word为你提供了一站式自动化解决方案,将Swa…...

3分钟高效恢复Windows 11 LTSC微软商店:完整解决方案指南
3分钟高效恢复Windows 11 LTSC微软商店:完整解决方案指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否在使用Windows 11 24H2 LT…...

告别ET1100?聊聊AX58100这颗高性价比EtherCAT从站芯片的升级体验
告别ET1100?AX58100高性价比EtherCAT从站芯片的工业升级实战 当工业设备制造商面临从传统控制架构向实时以太网迁移时,EtherCAT从站芯片的选型往往成为关键转折点。十年前,ET1100凭借其稳定的性能和相对友好的开发门槛,成为许多工…...

在线Graphviz图表编辑器:3步创建专业技术流程图
在线Graphviz图表编辑器:3步创建专业技术流程图 【免费下载链接】GraphvizOnline Lets Graphviz it online 项目地址: https://gitcode.com/gh_mirrors/gr/GraphvizOnline 还在为复杂的技术图表绘制而烦恼吗?GraphvizOnline作为一款革命性的在线G…...

Qdrant Python客户端全解析:从向量数据库连接到AI应用开发实战
1. 项目概述:从向量数据库到客户端,现代AI应用落地的关键拼图如果你最近在折腾大语言模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率已经听过“向量数据库”这个词了。简单来说,它就像一个专门为AI模型设…...

并行LLM推理技术:Hogwild! Inference原理与应用
1. 并行LLM推理的技术背景与挑战在传统Transformer架构中,语言模型的推理过程本质上是顺序执行的——每个新token的生成都严格依赖于之前所有token的注意力计算结果。这种串行特性导致两个显著瓶颈:首先,硬件计算资源利用率低下,特…...

Arm Cortex-X2/X3架构解析与性能优化实践
1. Arm Cortex-X2/X3集群架构概述在Armv9架构的高性能计算领域,Cortex-X2和X3代表了当前最先进的CPU设计理念。作为DynamIQ共享单元(DSU)的核心组件,它们通过可配置的缓存层次结构和智能一致性协议,为现代异构计算提供了灵活的解决方案。1.1 …...

基于RAG的Obsidian智能插件:用AI对话重塑个人知识管理
1. 项目概述:当笔记遇上AI,一个插件如何重塑知识管理最近在折腾我的Obsidian知识库时,发现了一个让我眼前一亮的插件:Smart2Brain。这名字起得挺有意思,“Smart to Brain”,直译过来就是“从智能到大脑”。…...
、连读规则注入与敬语语调开关(内测白名单已开放))
仅限菲律宾本地团队使用的ElevenLabs隐藏功能:Tagalog重音标记语法(`[ˈba.ka]`)、连读规则注入与敬语语调开关(内测白名单已开放)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs菲律宾文语音能力的本地化演进背景 菲律宾语(Filipino)作为以他加禄语(Tagalog)为基础的国家官方语言,拥有约1.05亿母语及第二语言…...

基于MCP协议构建AI编程助手:unloop-mcp文件系统服务器实战指南
1. 项目概述:一个面向开发者的“解循环”MCP服务器最近在GitHub上看到一个挺有意思的项目,叫Escapepaleolithic247/unloop-mcp。光看这个名字,可能有点摸不着头脑,但如果你是一个经常和AI助手(比如Claude、Cursor等&am…...