Redis主从复制、哨兵模式以及Cluster集群
一.主从复制
1.主从复制的概念
- 主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(Master),后者称为从节点(Slave);数据的复制是单向的,只能由主节点到从节点。
- 默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
2.主从复制的作用
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
3.主从复制流程
1)首次同步:当从节点要进行主从复制时,它会发送一个SYNC命令给主节点。主节点收到SYNC命令后,会执行BGSAVE命令来生成RDB快照文件,并在生成期间使用缓冲区记录所有写操作。
2)快照传输:当主节点完成BGSAVE命令并且快照文件准备好后,将快照文件传输给从节点。主节点将快照文件发送给从节点,并且在发送过程中,主节点会继续将新的写操作缓冲到内存中。
3)追赶复制:当从节点收到快照文件后,会加载快照文件并应用到自己的数据集中。一旦快照文件被加载,从节点会向主节点发送一个PSYNC命令,以便获取缓冲区中未发送的写操作。
4)增量复制:主节点收到PSYNC命令后,会将缓冲区中未发送的写操作发送给从节点,从节点会执行这些写操作,保证与主节点的数据一致性。此时,从节点已经追赶上了主节点的状态。
5)同步:从节点会继续监听主节点的命令,并及时执行主节点的写操作,以保持与主节点的数据同步。主节点会定期将自己的操作发送给从节点,以便从节点保持最新的数据状态。
注意:当slave首次同步或者宕机后恢复时,会全盘加载,以追赶上大部队,即全量复制
4.搭建Redis 主从复制
- Master节点:192.168.86.110
- Slave1节点:192.168.86.140
- Slave2节点:192.168.86.60
1)安装 Redis
//环境准备
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config#修改内核参数
vim /etc/sysctl.conf
vm.overcommit_memory = 1
net.core.somaxconn = 2048sysctl -p2)安装redis
mkdir /usr/local/redis/{conf,log,data}cp /opt/redis-7.0.9/redis.conf /usr/local/redis/conf/useradd -M -s /sbin/nologin redis
chown -R redis.redis /usr/local/redis/#环境变量
vim /etc/profile
PATH=$PATH:/usr/local/redis/bin #增加一行source /etc/profile//定义systemd服务管理脚本
vim /usr/lib/systemd/system/redis-server.service
[Unit]
Description=Redis Server
After=network.target[Service]
User=redis
Group=redis
Type=forking
TimeoutSec=0
PIDFile=/usr/local/redis/log/redis_6379.pid
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
PrivateTmp=true[Install]
WantedBy=multi-user.target
3)修改 Redis 配置文件(Master节点操作)
vim /usr/local/redis/conf/redis.conf
bind 0.0.0.0 #87行,修改监听地址为0.0.0.0
protected-mode no #111行,将本机访问保护模式设置no
port 6379 #138行,Redis默认的监听6379端口
daemonize yes #309行,设置为守护进程,后台启动
pidfile /usr/local/redis/log/redis_6379.pid #341行,指定 PID 文件
logfile "/usr/local/redis/log/redis_6379.log" #354行,指定日志文件
dir /usr/local/redis/data #504行,指定持久化文件所在目录
#requirepass abc123 #1037行,可选,设置redis密码
appendonly yes #1380行,开启AOFsystemctl restart redis-server.service4)修改 Redis 配置文件(Slave节点操作)
vim /usr/local/redis/conf/redis.conf
bind 0.0.0.0 #87行,修改监听地址为0.0.0.0
protected-mode no #111行,将本机访问保护模式设置no
port 6379 #138行,Redis默认的监听6379端口
daemonize yes #309行,设置为守护进程,后台启动
pidfile /usr/local/redis/log/redis_6379.pid #341行,指定 PID 文件
logfile "/usr/local/redis/log/redis_6379.log" #354行,指定日志文件
dir /usr/local/redis/data #504行,指定持久化文件所在目录
#requirepass abc123 #1037行,可选,设置redis密码
appendonly yes #1380行,开启AOF
replicaof 192.168.86.110 6379 #528行,指定要同步的Master节点IP和端口
#masterauth abc123 #535行,可选,指定Master节点的密码,仅在Master节点设置了requirepasssystemctl restart redis-server.service
5)验证主从效果
在Master节点上看日志:
tail -f /usr/local/redis/log/redis_6379.log
Replica 192.168.86.140:6379 asks for synchronization
Replica 192.168.86.60:6379 asks for synchronization
Synchronization with replica 192.168.86.140:6379 succeeded
Synchronization with replica 192.168.86.60:6379 succeeded在Master节点上验证从节点:
redis-cli info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.86.140,port=6379,state=online,offset=1246,lag=0
slave1:ip=192.168.86.60,port=6379,state=online,offset=1246,lag=1
二.Redis 哨兵模式
主从切换技术的方法是:
- 当服务器宕机后,需要手动一台从机切换为主机,这需要人工干预,不仅费时费力而且还会造成一段时间内服务不可用。为了解决主从复制的缺点,就有了哨兵机制。
- 哨兵的核心功能:在主从复制的基础上,哨兵引入了主节点的自动故障转移。
1.哨兵模式的作用
- 监控:哨兵会不断地检查主节点和从节点是否运作正常。
- 自动故障转移:当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其它从节点改为复制新的主节点。
- 通知(提醒):哨兵可以将故障转移的结果发送给客户端。
2.哨兵结构
由两部分组成,哨兵节点和数据节点
- 哨兵节点:哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的redis节点,不存储数据。
- 数据节点:主节点和从节点都是数据节点。
3.故障转移机制
1.由哨兵节点定期监控发现主节点是否出现了故障
- 每个哨兵节点每隔1秒会向主节点、从节点及其它哨兵节点发送一次ping命令做一次心跳检测。如果主节点在一定时间范围内不回复或者是回复一个错误消息,那么这个哨兵就会认为这个主节点主观下线了(单方面的)。当超过半数哨兵节点认为该主节点主观下线了,这样就客观下线了。
2.当主节点出现故障,此时哨兵节点会通过Raft算法(选举算法)实现选举机制共同选举出一个哨兵节点为leader,来负责处理主节点的故障转移和通知。所以整个运行哨兵的集群的数量不得少于3个节点。
3.由leader哨兵节点执行故障转移,过程如下
- 将某一个从节点升级为新的主节点,让其它从节点指向新的主节点;
- 若原主节点恢复也变成从节点,并指向新的主节点;
- 通知客户端主节点已经更换。
需要特别注意的是,客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作
4.主节点的选举
- 过滤掉不健康的(已下线的),没有回复哨兵 ping 响应的从节点。
- 选择配置文件中从节点优先级配置最高的。(replica-priority,默认值为100)
- 选择复制偏移量最大,也就是复制最完整的从节点。
哨兵的启动依赖于主从模式,所以须把主从模式安装好的情况下再去做哨兵模式
5.搭建Redis 哨兵模式
- Master节点:192.168.86.110
- Slave1节点:192.168.86.140
- Slave2节点:192.168.86.40
1)修改 Redis 哨兵模式的配置文件(所有节点操作)
cp /opt/redis-7.0.9/sentinel.conf /usr/local/redis/conf/
chown redis.redis /usr/local/redis/conf/sentinel.confvim /usr/local/redis/conf/sentinel.conf
protected-mode no #6行,关闭保护模式
port 26379 #10行,Redis哨兵默认的监听端口
daemonize yes #15行,指定sentinel为后台启动
pidfile /usr/local/redis/log/redis-sentinel.pid #20行,指定 PID 文件
logfile "/usr/local/redis/log/sentinel.log" #25行,指定日志存放路径
dir /usr/local/redis/data #54行,指定数据库存放路径
sentinel monitor mymaster 192.168.80.10 6379 2 #73行,修改 指定该哨兵节点监控192.168.80.10:6379这个主节点,该主节点的名称是mymaster,最后的2的含义与主节点的故障判定有关:至少需要2个哨兵节点同意,才能判定主节点故障并进行故障转移
#sentinel auth-pass mymaster abc123 #76行,可选,指定Master节点的密码,仅在Master节点设置了requirepass
sentinel down-after-milliseconds mymaster 3000 #114行,判定服务器down掉的时间周期,默认30000毫秒(30秒)
sentinel failover-timeout mymaster 180000 #214行,同一个sentinel对同一个master两次failover之间的间隔时间(180秒)
2)启动哨兵模式
先启master,再启slave
cd /usr/local/redis/conf/
redis-sentinel sentinel.conf &
3)查看哨兵信息
redis-cli -p 26379 info Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.80.10:6379,slaves=2,sentinels=34)故障模拟
#查看redis-server进程号:
ps -ef | grep redis
root 57031 1 0 15:20 ? 00:00:07 /usr/local/bin/redis-server 0.0.0.0:6379
root 57742 1 1 16:05 ? 00:00:07 redis-sentinel *:26379 [sentinel]
root 57883 57462 0 16:17 pts/1 00:00:00 grep --color=auto redis#杀死 Master 节点上redis-server的进程号
kill -9 57031 #Master节点上redis-server的进程号#验证结果
tail -f /usr/local/redis/log/sentinel.log
6709:X 13 Mar 2023 12:27:29.517 # +sdown master mymaster 192.168.86.110 6379
6709:X 13 Mar 2023 12:27:29.594 * Sentinel new configuration saved on disk
6709:X 13 Mar 2023 12:27:29.594 # +new-epoch 1
6709:X 13 Mar 2023 12:27:29.595 * Sentinel new configuration saved on disk
6709:X 13 Mar 2023 12:27:29.595 # +vote-for-leader c64fac46fcd98350006900c330998364d6af635d 1
6709:X 13 Mar 2023 12:27:29.620 # +odown master mymaster 192.168.86.110 6379 #quorum 2/2
6709:X 13 Mar 2023 12:27:29.621 # Next failover delay: I will not start a failover before Mon Mar 13 12:33:30 2023
6709:X 13 Mar 2023 12:27:30.378 # +config-update-from sentinel c64fac46fcd98350006900c330998364d6af635d 192.168.86.140 26379 @ mymaster 192.168.86.110 6379
6709:X 13 Mar 2023 12:27:30.378 # +switch-master mymaster 192.168.86.110 6379 192.168.80.11 6379
6709:X 13 Mar 2023 12:27:30.378 * +slave slave 192.168.86.60:6379 192.168.86.60 6379 @ mymaster 192.168.80.140 6379
6709:X 13 Mar 2023 12:27:30.378 * +slave slave 192.168.86.110:6379 192.168.86.110 6379 @ mymaster 192.168.86.110 6379
6709:X 13 Mar 2023 12:27:30.381 * Sentinel new configuration saved on disk
6709:X 13 Mar 2023 12:27:33.379 # +sdown slave 192.168.86.110:6379 192.168.86.110 6379 @ mymaster 192.168.86.110 63792.redis-cli -p 26379 INFO Sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_tilt_since_seconds:-1
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=192.168.86.140:6379,slaves=2,sentinels=3三.Redis 群集模式
- 集群,即Redis Cluster,是Redis 3.0开始引入的分布式存储方案。
- 集群由多组节点(Node)组成,Redis的数据分布在这些节点组中。节点组中的节点分为主节点和从节点:只有主节点负责读写请求和集群信息的维护;从节点只进行主节点数据和状态信息的复制。
1.集群的作用
- 高可用:集群支持主从复制和主节点的自动故障转移(与哨兵类似);当任一节点发生故障时,集群仍然可以对外提供服务。
- 数据分区:数据分区(或称数据分片)是集群最核心的功能。
集群将数据分散到多组节点,一方面突破了Redis单机内存大小的限制,存储容量大大增加;另一方面每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力。
Redis单机内存大小受限问题,在介绍持久化和主从复制时都有提及;例如,如果单机内存太大,bgsave和bgrewriteaof的fork操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出。
2.Redis集群的数据分片
- Redis集群引入了哈希槽的概念
- Redis集群有16384个哈希槽(编号0-16383)
- 集群的每组节点负责一部分哈希槽
- 每个Key通过CRC16校验后对16384取余来决定放置哪个哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
以3个节点组成的集群为例:
节点A包含0到5460号哈希槽
节点B包含5461到10922号哈希槽
节点C包含10923到16383号哈希槽
3.Redis集群的主从复制模型
- 集群中具有A、B、C三个节点,如果节点B失败了,整个集群就会因缺少5461-10922这个范围的槽而不可以用。
- 为每个节点添加一个从节点A1、B1、C1整个集群便有三个Master节点和三个slave节点组成,在节点B失败后,集群选举B1位为的主节点继续服务。当B和B1都失败后,集群将不可用。
4.搭建Redis 群集模式
redis的集群一般需要6个节点,3主3从。方便起见,这里所有节点在同一台服务器上模拟:
以端口号进行区分:3个主节点端口号:6001/6002/6003,对应的从节点端口号:6004/6005/6006。
cd /usr/local/redis/
mkdir -p redis-cluster/redis600{1..6}for i in {1..6}
do
cp /opt/redis-7.0.9/redis.conf /usr/local/redis/redis-cluster/redis600$i
cp /opt/redis-7.0.9/src/redis-cli /opt/redis-7.0.9/src/redis-server /usr/local/redis/redis-cluster/redis600$i
done
1)开启群集功能
#其他5个文件夹的配置文件以此类推修改,注意6个端口都要不一样。
cd /usr/local/redis/redis-cluster/redis6001
vim redis.conf
#bind 127.0.0.1 #87行,注释掉bind项,默认监听所有网卡
protected-mode no #111行,关闭保护模式
port 6001 #138行,修改redis监听端口
daemonize yes #309行,设置为守护进程,后台启动
pidfile /usr/local/redis/log/redis_6001.pid #341行,指定 PID 文件
logfile "/usr/local/redis/log/redis_6001.log" #354行,指定日志文件
dir ./ #504行,指定持久化文件所在目录
appendonly yes #1379行,开启AOF
cluster-enabled yes #1576行,取消注释,开启群集功能
cluster-config-file nodes-6001.conf #1584行,取消注释,群集名称文件设置
cluster-node-timeout 15000 #1590行,取消注释群集超时时间设置
2)启动redis节点
分别进入那六个文件夹,执行命令:redis-server redis.conf ,来启动redis节点
cd /usr/local/redis/redis-cluster/redis6001
redis-server redis.conffor d in {1..6}
do
cd /usr/local/redis/redis-cluster/redis600$d
./redis-server redis.conf
doneps -ef | grep redis
3)启动集群
redis-cli --cluster create 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.1:6005 127.0.0.1:6006 --cluster-replicas 1#六个实例分为三组,每组一主一从,前面的做主节点,后面的做从节点。下面交互的时候 需要输入 yes 才可以创建。
--replicas 1 表示每个主节点有1个从节点。
4)测试群集
redis-cli -p 6001 -c #加-c参数,节点之间就可以互相跳转
127.0.0.1:6001> cluster slots #查看节点的哈希槽编号范围
1) 1) (integer) 54612) (integer) 10922 #哈希槽编号范围3) 1) "127.0.0.1"2) (integer) 6003 #主节点IP和端口号3) "fdca661922216dd69a63a7c9d3c4540cd6baef44"4) 1) "127.0.0.1"2) (integer) 6004 #从节点IP和端口号3) "a2c0c32aff0f38980accd2b63d6d952812e44740"
2) 1) (integer) 02) (integer) 54603) 1) "127.0.0.1"2) (integer) 60013) "0e5873747a2e26bdc935bc76c2bafb19d0a54b11"4) 1) "127.0.0.1"2) (integer) 60063) "8842ef5584a85005e135fd0ee59e5a0d67b0cf8e"
3) 1) (integer) 109232) (integer) 163833) 1) "127.0.0.1"2) (integer) 60023) "816ddaa3d1469540b2ffbcaaf9aa867646846b30"4) 1) "127.0.0.1"2) (integer) 60053) "f847077bfe6722466e96178ae8cbb09dc8b4d5eb"127.0.0.1:6001> set name zhangsan
-> Redirected to slot [5798] located at 127.0.0.1:6003
OK127.0.0.1:6001> cluster keyslot name #查看name键的槽编号redis-cli -p 6004 -c
127.0.0.1:6004> keys * #对应的slave节点也有这条数据,但是别的节点没有
1) "name"redis-cli -p 6001 -c cluster nodes
相关文章:

Redis主从复制、哨兵模式以及Cluster集群
一.主从复制 1.主从复制的概念 主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(Master),后者称为从节点(Slave);数据的复制是单向的,只能由主节点到从节点。默认情况下,…...

【chatgpt】npy文件和npz文件区别
npy文件和npz文件都是用于存储NumPy数组的文件格式。它们的主要区别如下: npy文件:这种文件格式用于存储单个NumPy数组。它是一种简单的二进制文件格式,可以快速地读写NumPy数组。 npz文件:这种文件格式是一个压缩包,…...

为什么IP地址会被列入黑名单?
您是否曾经历过网站访客数量骤减或电子邮件投递失败的困扰?这背后或许隐藏着一个常被忽略的原因:您的IP地址可能已经被列入了黑名单内。尽管您并没有进行任何违法的网络操作,但这个问题依然可能出现。那么,究竟黑名单是什么&#…...

【OceanBase诊断调优】—— 如何查找表被哪些其它表引用外键
本文详述如何查找指定表是否被其他表引用做外键。 适用版本 OceanBase 数据库所有版本。 MySQL 租户 obclient> select * from INFORMATION_SCHEMA.KEY_COLUMN_USAGE where REFERENCED_TABLE_NAME表名;Oracle 租户 obclient> SELECT TABLE_NAME FROM dba_constraint…...
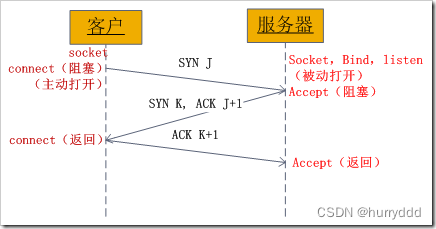
网络编程常见问题
1、TCP状态迁移图 2、TCP三次握手过程 2.1、握手流程 1、TCP服务器进程先创建传输控制块TCB,时刻准备接受客户进程的连接请求,此时服务器就进入了LISTEN(监听)状态; 2、TCP客户进程也是先创建传输控制块TCBÿ…...

回调函数的使用详解
实际工作中,经常使用回调函数。用来实现触发等机制,也是基于一些已开发好的底层平台,开发上层应用的常用方法。下面对回调函数做一个详细的解释。 目录 1. 简单的回调函数实例 2. C11,使用function<>的写法 3. 注册函数 …...
<电力行业> - 《第8课:输电(一)》
1 输电环节的意义 电能的传输,是电力系统整体功能的重要组成环节。发电厂与电力负荷中心通常都位于不同地区。在水力、煤炭等一次能源资源条件适宜的地点建立发电厂,通过输电可以将电能输送到远离发电厂的负荷中心,使电能的开发和利用超越地…...

【python学习】 __pycache__ 文件是什么
__pycache__文件是Python中的一个特殊目录,主要用于存储已编译的字节码文件(.pyc文件)。以下是关于__pycache__文件的详细解释: 作用:当Python解释器执行一个模块时,它会首先检查是否存在对应的.pyc文件。…...
论文阅读_基本于文本嵌入的信息提取
英文名:Embedding-based Retrieval with LLM for Effective Agriculture Information Extracting from Unstructured Data 中文名:基于嵌入的检索,LLM 从非结构化数据中提取有效的农业信息 地址: https://arxiv.org/abs/2308.03107 时间&…...

kafka学习笔记08
Springboot项目整合spring-kafka依赖包配置 有这种方式,就是可以是把之前test里的配置在这写上,用Bean注解上。 现在来介绍第二种方式: 1.添加kafka依赖: 2.添加kafka配置方式: 编写代码发送消息: 测试: …...

Flask的 preprocess_request
理解 Flask 类似框架中的 preprocess_request 方法 在 Flask 类似的 web 框架中,preprocess_request 方法是一个关键组件。它在请求被分派之前调用,用于执行一些预处理操作。让我们一步一步来理解这个方法的工作原理。 1. 方法概述 首先,我…...
)
重温react-05(类组件生命周期和性能优化)
类组件的生命周期 import React, { Component } from reactexport default class learnReact05 extends Component {state {number: 1}render() {return (<div>{this.state.number}</div>)}// 一般将请求的方法,放在这个生命周期componentDidMount() {setInterva…...
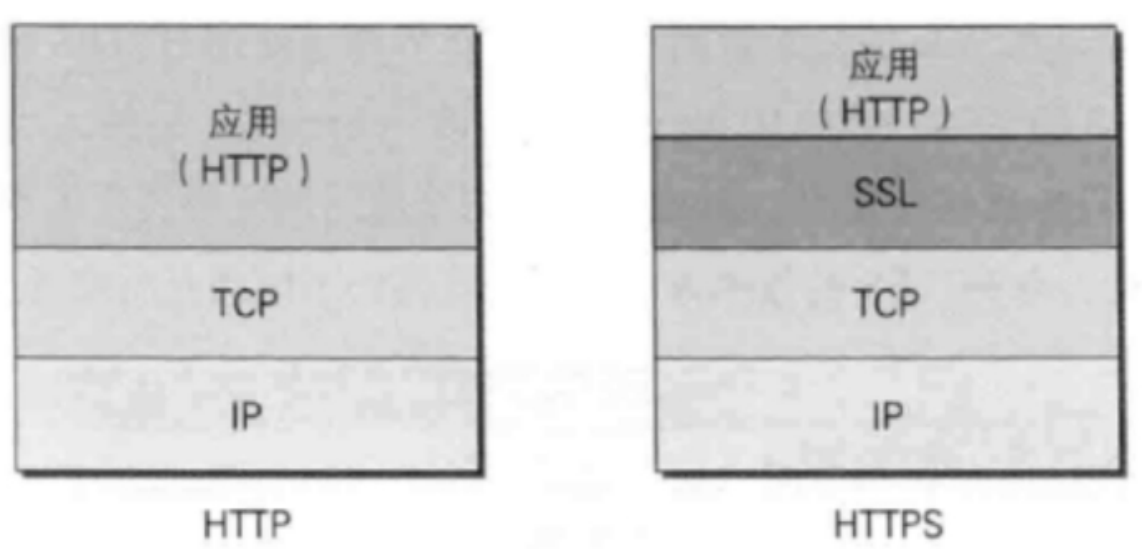
RHCE四---web服务器的高级优化方案
一、Web服务器(2) 基于https协议的静态网站 概念解释 HTTPS(全称:Hyper Text Transfer Protocol over Secure Socket Layer 或 Hypertext TransferProtocol Secure,超文本传输安全协议),是以…...
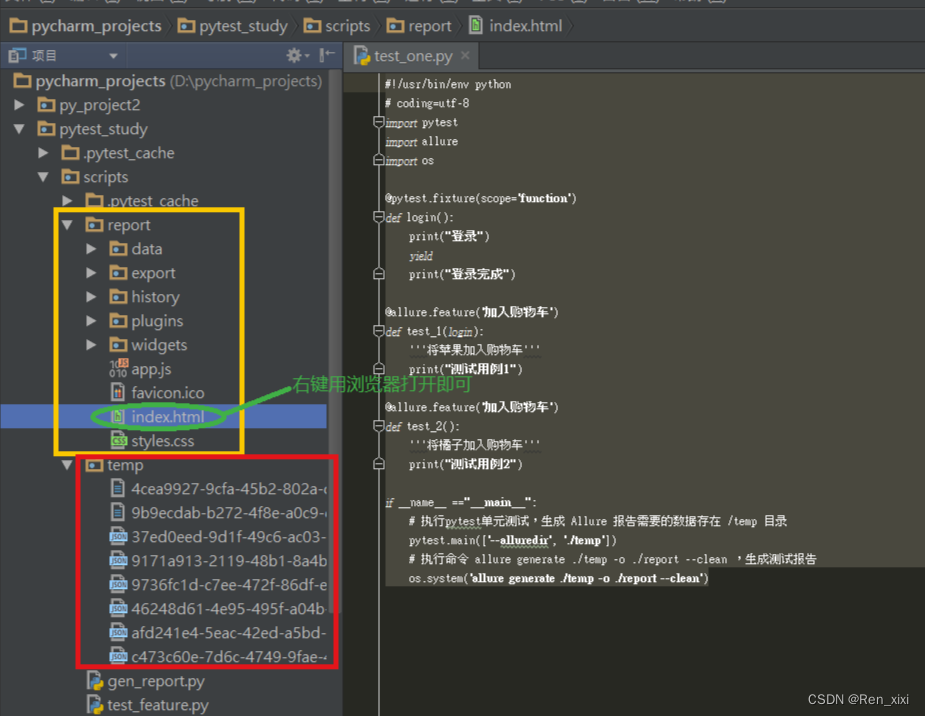
Pytest集成Allure生成测试报告
# 运行并输出报告在Report文件夹下 查看生成的allure报告 1. 生成allure报告:pycharm terminal中输入命令:产生报告文件夹 pytest -s --alluredir../report 2. pycharm terminal中输入命令:查看生成的allure报告 allure serve ../report …...

SpringBoot 参数校验
参数校验 引入springvalidation依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-validation</artifactId> </dependency>参数前添加Pattern public Result registry(Pattern(regexp &qu…...

【Arduino】实验使用ESP32控制可编程继电器制作跑马灯(图文)
今天小飞鱼实验使用ESP控制继电器,为了更好的掌握继电器的使用方法这里实验做了一个跑马灯的效果。 这里用到的可编程继电器,起始原理并不复杂,同样需要ESP32控制针脚输出高电平或低电平给到继电器,继电器使用这个信号控制一个电…...

islower()方法——判断字符串是否全由小写字母组成
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 语法参考 islower()方法用于判断字符串是否由小写字母组成。islower()方法的语法格式如下: str.islower() 如果字符串中包含至少一个区…...

发布/订阅模式
实现发布/订阅模式的基本思路是通过一个中介者(发布者)来管理订阅者(监听器),并在特定事件发生时通知所有订阅者执行相应的操作。下面是实现发布/订阅模式的基本思路: 创建发布者对象:首先&…...

K8S Pod常见状态
这是自己所遇到 Pod 常见状态及可能原因,持续更新。 如有其他的错误状态,可私我更新 1. ImagePullBackOff 问题分析: 镜像拉取失败。 可能原因: 可能是网络问题导致,检查Pod所在节点是否能够正常访问网络; 镜…...

Hadoop3:Yarn常用Shell命令
一、查看任务 1、查看所有任务 yarn application -list2、根据状态查看任务 语法 yarn application -list -appStates (所有状态:ALL、NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED)例如 yarn application…...

如何通过Jellyfin Android TV客户端打造家庭影院级媒体体验?
如何通过Jellyfin Android TV客户端打造家庭影院级媒体体验? 【免费下载链接】jellyfin-androidtv Android TV Client for Jellyfin 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-androidtv 想要在智能电视上享受专业的媒体管理体验吗?…...

告别ET1100?聊聊AX58100这颗高性价比EtherCAT从站芯片的升级体验
告别ET1100?AX58100高性价比EtherCAT从站芯片的工业升级实战 当工业设备制造商面临从传统控制架构向实时以太网迁移时,EtherCAT从站芯片的选型往往成为关键转折点。十年前,ET1100凭借其稳定的性能和相对友好的开发门槛,成为许多工…...

如何5分钟掌握N_m3u8DL-RE:流媒体下载终极解决方案
如何5分钟掌握N_m3u8DL-RE:流媒体下载终极解决方案 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...
研究(Matlab代码实现))
一种用于并网光伏系统的创新型多层逆变器,以降低总谐波失真(THD)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

Kubernetes原生自动化部署工具Keel:实现容器镜像自动更新的最后一公里
1. 项目概述:什么是Keel,以及它解决了什么问题如果你和我一样,在团队里负责过一段时间的应用部署和更新,那你一定对“发布日”的紧张感深有体会。开发那边代码一提交,这边就得开始手动拉取镜像、更新Kubernetes的Deplo…...

Ash印相渲染失败率骤升47%?紧急预警:V6.2更新后Gamma 2.2→2.4迁移引发的印相断层危机
更多请点击: https://intelliparadigm.com 第一章:Ash印相渲染失败率骤升47%的全局现象与危机定性 近期,全球多个采用 Ash 印相引擎(v3.8.2)的影像处理平台集中报告渲染任务异常终止、输出空白或超时中断。监控数据显…...

湿版摄影×AI生成革命:为什么93%的MJ用户调不出真实碘化银斑痕?——资深暗房师+AI训练师双视角深度拆解
更多请点击: https://intelliparadigm.com 第一章:湿版摄影AI生成革命:为什么93%的MJ用户调不出真实碘化银斑痕?——资深暗房师AI训练师双视角深度拆解 湿版火棉胶摄影术诞生于1851年,其不可复制的物理噪点——由碘化…...

开源PCB自动布线神器FreeRouting:5分钟上手,效率提升300%
开源PCB自动布线神器FreeRouting:5分钟上手,效率提升300% 【免费下载链接】freerouting Advanced PCB auto-router 项目地址: https://gitcode.com/gh_mirrors/fr/freerouting FreeRouting是一款功能强大的开源PCB自动布线工具,它能帮…...

Arm Neoverse CMN-700多芯片架构与一致性哈希解析
1. Arm Neoverse CMN-700多芯片架构解析在现代高性能计算领域,多芯片系统架构已成为突破单芯片性能瓶颈的关键技术路径。Arm Neoverse CMN-700作为第二代一致性网状网络控制器,其设计哲学体现在三个维度:首先是通过模块化设计实现计算单元的可…...

Oracle数据库触发器概述
Oracle数据库触发器概述触发器介绍数据库触发器是一个 已编译的存储程序单元 ,使用 PL/SQL 或 Java 编写。 触发器是模式对象,类似于子程序;但其调用方法不同。 子程序由用户、应用程序、或触发器显式运行。而触发器是在触发的事件发生时由 数…...