python–基础篇–正则表达式–是什么
文章目录
- 定义一:正则表达式就是记录文本规则的代码
- 定义一:正则表达式是一个特殊的字符序列,用于判断一个字符串是否与我们所设定的字符序列是否匹配,也就是说检查一个字符串是否与某种模式匹配。
- 初识 Python 正则表达式
- 定义一:正则表达式是一种工具,它定义了字符串的匹配模式(如何检查一个字符串是否有跟某种模式匹配的部分或者从一个字符串中将与模式匹配的部分提取出来或者替换掉)。
- 使用正则表达式
- 正则表达式相关知识
- Python对正则表达式的支持
- 例子1:验证输入用户名和QQ号是否有效并给出对应的提示信息。
- 例子2:从一段文字中提取出国内手机号码。
- 例子3:拆分长字符串
- 后话
- 正则表达式就是记录文本规则的代码。
- 正则表达式是一个特殊的字符序列,用于判断一个字符串是否与我们所设定的字符序列是否匹配,也就是说检查一个字符串是否与某种模式匹配。
- 正则表达式是一种工具,它定义了字符串的匹配模式(如何检查一个字符串是否有跟某种模式匹配的部分或者从一个字符串中将与模式匹配的部分提取出来或者替换掉)。
定义一:正则表达式就是记录文本规则的代码
https://deerchao.cn/tutorials/regex/regex.htm
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。
很可能你使用过Windows/Dos下用于文件查找的通配符(wildcard),也就是*和?。如果你想查找某个目录下的所有的Word文档的话,你会搜索*.doc。在这里,*会被解释成任意的字符串。和通配符类似,正则表达式也是用来进行文本匹配的工具,只不过比起通配符,它能更精确地描述你的需求——当然,代价就是更复杂——比如你可以编写一个正则表达式,用来查找所有以0开头,后面跟着2-3个数字,然后是一个连字号“-”,最后是7或8位数字的字符串(像010-12345678或0376-7654321)。
定义一:正则表达式是一个特殊的字符序列,用于判断一个字符串是否与我们所设定的字符序列是否匹配,也就是说检查一个字符串是否与某种模式匹配。
初识 Python 正则表达式
正则表达式是一个特殊的字符序列,用于判断一个字符串是否与我们所设定的字符序列是否匹配,也就是说检查一个字符串是否与某种模式匹配。
Python 自 1.5 版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。re 模块使 Python 语言拥有全部的正则表达式功能。
下面通过实例,一步一步来初步认识正则表达式。
比如在一段字符串中寻找是否含有某个字符或某些字符,通常我们使用内置函数来实现,如下:
# 设定一个常量
a = '两点水|twowater|liangdianshui|草根程序员|ReadingWithU'# 判断是否有 “两点水” 这个字符串,使用 PY 自带函数print('是否含有“两点水”这个字符串:{0}'.format(a.index('两点水') > -1))
print('是否含有“两点水”这个字符串:{0}'.format('两点水' in a))
输出的结果如下:
是否含有“两点水”这个字符串:True
是否含有“两点水”这个字符串:True
那么,如果使用正则表达式呢?
刚刚提到过,Python 给我们提供了 re 模块来实现正则表达式的所有功能,那么我们先使用其中的一个函数:
re.findall(pattern, string[, flags])
该函数实现了在字符串中找到正则表达式所匹配的所有子串,并组成一个列表返回,具体操作如下:
import re# 设定一个常量
a = '两点水|twowater|liangdianshui|草根程序员|ReadingWithU'# 正则表达式findall = re.findall('两点水', a)
print(findall)if len(findall) > 0:print('a 含有“两点水”这个字符串')
else:print('a 不含有“两点水”这个字符串')输出的结果:
['两点水']
a 含有“两点水”这个字符串
从输出结果可以看到,可以实现和内置函数一样的功能,可是在这里也要强调一点,上面这个例子只是方便我们理解正则表达式,这个正则表达式的写法是毫无意义的。为什么这样说呢?
因为用 Python 自带函数就能解决的问题,我们就没必要使用正则表达式了,这样做多此一举。而且上面例子中的正则表达式设置成为了一个常量,并不是一个正则表达式的规则,正则表达式的灵魂在于规则,所以这样做意义不大。
那么正则表达式的规则怎么写呢?先不急,我们一步一步来,先来一个简单的,找出字符串中的所有小写字母。首先我们在 findall 函数中第一个参数写正则表达式的规则,其中 [a-z] 就是匹配任何小写字母,第二个参数只要填写要匹配的字符串就行了。具体如下:
import re# 设定一个常量
a = '两点水|twowater|liangdianshui|草根程序员|ReadingWithU'# 选择 a 里面的所有小写英文字母re_findall = re.findall('[a-z]', a)print(re_findall)输出的结果:
['t', 'w', 'o', 'w', 'a', 't', 'e', 'r', 'l', 'i', 'a', 'n', 'g', 'd', 'i', 'a', 'n', 's', 'h', 'u', 'i', 'e', 'a', 'd', 'i', 'n', 'g', 'i', 't', 'h']
这样我们就拿到了字符串中的所有小写字母了。
定义一:正则表达式是一种工具,它定义了字符串的匹配模式(如何检查一个字符串是否有跟某种模式匹配的部分或者从一个字符串中将与模式匹配的部分提取出来或者替换掉)。
使用正则表达式
正则表达式相关知识
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要,正则表达式就是用于描述这些规则的工具,换句话说正则表达式是一种工具,它定义了字符串的匹配模式(如何检查一个字符串是否有跟某种模式匹配的部分或者从一个字符串中将与模式匹配的部分提取出来或者替换掉)。如果你在Windows操作系统中使用过文件查找并且在指定文件名时使用过通配符(*和?),那么正则表达式也是与之类似的用来进行文本匹配的工具,只不过比起通配符正则表达式更强大,它能更精确地描述你的需求(当然你付出的代价是书写一个正则表达式比打出一个通配符要复杂得多,要知道任何给你带来好处的东西都是有代价的,就如同学习一门编程语言一样),比如你可以编写一个正则表达式,用来查找所有以0开头,后面跟着2-3个数字,然后是一个连字号“-”,最后是7或8位数字的字符串(像028-12345678或0813-7654321),这不就是国内的座机号码吗。最初计算机是为了做数学运算而诞生的,处理的信息基本上都是数值,而今天我们在日常工作中处理的信息基本上都是文本数据,我们希望计算机能够识别和处理符合某些模式的文本,正则表达式就显得非常重要了。今天几乎所有的编程语言都提供了对正则表达式操作的支持,Python通过标准库中的re模块来支持正则表达式操作。
我们可以考虑下面一个问题:我们从某个地方(可能是一个文本文件,也可能是网络上的一则新闻)获得了一个字符串,希望在字符串中找出手机号和座机号。当然我们可以设定手机号是11位的数字(注意并不是随机的11位数字,因为你没有见过“25012345678”这样的手机号吧)而座机号跟上一段中描述的模式相同,如果不使用正则表达式要完成这个任务就会很麻烦。
关于正则表达式的相关知识,大家可以阅读一篇非常有名的博客叫《正则表达式30分钟入门教程》,读完这篇文章后你就可以看懂下面的表格,这是我们对正则表达式中的一些基本符号进行的扼要总结。
| 符号 | 解释 | 示例 | 说明 |
|---|---|---|---|
| . | 匹配任意字符 | b.t | 可以匹配bat / but / b#t / b1t等 |
| \w | 匹配字母/数字/下划线 | b\wt | 可以匹配bat / b1t / b_t等 但不能匹配b#t |
| \s | 匹配空白字符(包括\r、\n、\t等) | love\syou | 可以匹配love you |
| \d | 匹配数字 | \d\d | 可以匹配01 / 23 / 99等 |
| \b | 匹配单词的边界 | \bThe\b | |
| ^ | 匹配字符串的开始 | ^The | 可以匹配The开头的字符串 |
| $ | 匹配字符串的结束 | .exe$ | 可以匹配.exe结尾的字符串 |
| \W | 匹配非字母/数字/下划线 | b\Wt | 可以匹配b#t / b@t等 但不能匹配but / b1t / b_t等 |
| \S | 匹配非空白字符 | love\Syou | 可以匹配love#you等 但不能匹配love you |
| \D | 匹配非数字 | \d\D | 可以匹配9a / 3# / 0F等 |
| \B | 匹配非单词边界 | \Bio\B | |
| [] | 匹配来自字符集的任意单一字符 | [aeiou] | 可以匹配任一元音字母字符 |
| [^] | 匹配不在字符集中的任意单一字符 | [^aeiou] | 可以匹配任一非元音字母字符 |
| * | 匹配0次或多次 | \w* | |
| + | 匹配1次或多次 | \w+ | |
| ? | 匹配0次或1次 | \w? | |
| {N} | 匹配N次 | \w{3} | |
| {M,} | 匹配至少M次 | \w{3,} | |
| {M,N} | 匹配至少M次至多N次 | \w{3,6} | |
| | | 分支 | foo|bar | 可以匹配foo或者bar |
| (?#) | 注释 | ||
| (exp) | 匹配exp并捕获到自动命名的组中 | ||
| (?<name>exp) | 匹配exp并捕获到名为name的组中 | ||
| (?:exp) | 匹配exp但是不捕获匹配的文本 | ||
| (?=exp) | 匹配exp前面的位置 | \b\w+(?=ing) | 可以匹配I’m dancing中的danc |
| (?<=exp) | 匹配exp后面的位置 | (?<=\bdanc)\w+\b | 可以匹配I love dancing and reading中的第一个ing |
| (?!exp) | 匹配后面不是exp的位置 | ||
| (?<!exp) | 匹配前面不是exp的位置 | ||
| *? | 重复任意次,但尽可能少重复 | a.*b a.*?b | 将正则表达式应用于aabab,前者会匹配整个字符串aabab,后者会匹配aab和ab两个字符串 |
| +? | 重复1次或多次,但尽可能少重复 | ||
| ?? | 重复0次或1次,但尽可能少重复 | ||
| {M,N}? | 重复M到N次,但尽可能少重复 | ||
| {M,}? | 重复M次以上,但尽可能少重复 |
说明: 如果需要匹配的字符是正则表达式中的特殊字符,那么可以使用\进行转义处理,例如想匹配小数点可以写成\.就可以了,因为直接写.会匹配任意字符;同理,想匹配圆括号必须写成\(和\),否则圆括号被视为正则表达式中的分组。
Python对正则表达式的支持
Python提供了re模块来支持正则表达式相关操作,下面是re模块中的核心函数。
| 函数 | 说明 |
|---|---|
| compile(pattern, flags=0) | 编译正则表达式返回正则表达式对象 |
| match(pattern, string, flags=0) | 用正则表达式匹配字符串 成功返回匹配对象 否则返回None |
| search(pattern, string, flags=0) | 搜索字符串中第一次出现正则表达式的模式 成功返回匹配对象 否则返回None |
| split(pattern, string, maxsplit=0, flags=0) | 用正则表达式指定的模式分隔符拆分字符串 返回列表 |
| sub(pattern, repl, string, count=0, flags=0) | 用指定的字符串替换原字符串中与正则表达式匹配的模式 可以用count指定替换的次数 |
| fullmatch(pattern, string, flags=0) | match函数的完全匹配(从字符串开头到结尾)版本 |
| findall(pattern, string, flags=0) | 查找字符串所有与正则表达式匹配的模式 返回字符串的列表 |
| finditer(pattern, string, flags=0) | 查找字符串所有与正则表达式匹配的模式 返回一个迭代器 |
| purge() | 清除隐式编译的正则表达式的缓存 |
| re.I / re.IGNORECASE | 忽略大小写匹配标记 |
| re.M / re.MULTILINE | 多行匹配标记 |
说明: 上面提到的re模块中的这些函数,实际开发中也可以用正则表达式对象的方法替代对这些函数的使用,如果一个正则表达式需要重复的使用,那么先通过compile函数编译正则表达式并创建出正则表达式对象无疑是更为明智的选择。
下面我们通过一系列的例子来告诉大家在Python中如何使用正则表达式。
例子1:验证输入用户名和QQ号是否有效并给出对应的提示信息。
"""
验证输入用户名和QQ号是否有效并给出对应的提示信息要求:用户名必须由字母、数字或下划线构成且长度在6~20个字符之间,QQ号是5~12的数字且首位不能为0
"""
import redef main():username = input('请输入用户名: ')qq = input('请输入QQ号: ')# match函数的第一个参数是正则表达式字符串或正则表达式对象# 第二个参数是要跟正则表达式做匹配的字符串对象m1 = re.match(r'^[0-9a-zA-Z_]{6,20}$', username)if not m1:print('请输入有效的用户名.')m2 = re.match(r'^[1-9]\d{4,11}$', qq)if not m2:print('请输入有效的QQ号.')if m1 and m2:print('你输入的信息是有效的!')if __name__ == '__main__':main()
提示: 上面在书写正则表达式时使用了“原始字符串”的写法(在字符串前面加上了r),所谓“原始字符串”就是字符串中的每个字符都是它原始的意义,说得更直接一点就是字符串中没有所谓的转义字符啦。因为正则表达式中有很多元字符和需要进行转义的地方,如果不使用原始字符串就需要将反斜杠写作\\,例如表示数字的\d得书写成\\d,这样不仅写起来不方便,阅读的时候也会很吃力。
例子2:从一段文字中提取出国内手机号码。
下面这张图是截止到2017年底,国内三家运营商推出的手机号段。
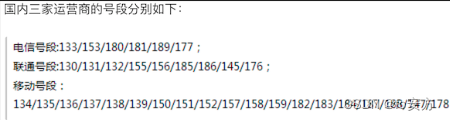
import redef main():# 创建正则表达式对象 使用了前瞻和回顾来保证手机号前后不应该出现数字pattern = re.compile(r'(?<=\D)1[34578]\d{9}(?=\D)')sentence = '''重要的事情说8130123456789遍,我的手机号是13512346789这个靓号,不是15600998765,也是110或119,王大锤的手机号才是15600998765。'''# 查找所有匹配并保存到一个列表中mylist = re.findall(pattern, sentence)print(mylist)print('--------华丽的分隔线--------')# 通过迭代器取出匹配对象并获得匹配的内容for temp in pattern.finditer(sentence):print(temp.group())print('--------华丽的分隔线--------')# 通过search函数指定搜索位置找出所有匹配m = pattern.search(sentence)while m:print(m.group())m = pattern.search(sentence, m.end())if __name__ == '__main__':main()
说明: 上面匹配国内手机号的正则表达式并不够好,因为像14开头的号码只有145或147,而上面的正则表达式并没有考虑这种情况,要匹配国内手机号,更好的正则表达式的写法是:
(?<=\D)(1[38]\d{9}|14[57]\d{8}|15[0-35-9]\d{8}|17[678]\d{8})(?=\D),国内最近好像有19和16开头的手机号了,但是这个暂时不在我们考虑之列。
例子3:拆分长字符串
import redef main():poem = '窗前明月光,疑是地上霜。举头望明月,低头思故乡。'sentence_list = re.split(r'[,。, .]', poem)while '' in sentence_list:sentence_list.remove('')print(sentence_list) # ['窗前明月光', '疑是地上霜', '举头望明月', '低头思故乡']if __name__ == '__main__':main()
后话
如果要从事爬虫类应用的开发,那么正则表达式一定是一个非常好的助手,因为它可以帮助我们迅速的从网页代码中发现某种我们指定的模式并提取出我们需要的信息,当然对于初学者来收,要编写一个正确的适当的正则表达式可能并不是一件容易的事情(当然有些常用的正则表达式可以直接在网上找找),所以实际开发爬虫应用的时候,有很多人会选择Beautiful Soup或Lxml来进行匹配和信息的提取,前者简单方便但是性能较差,后者既好用性能也好,但是安装稍嫌麻烦,这些内容我们会在后期的爬虫专题中为大家介绍。
相关文章:
python–基础篇–正则表达式–是什么
文章目录 定义一:正则表达式就是记录文本规则的代码定义一:正则表达式是一个特殊的字符序列,用于判断一个字符串是否与我们所设定的字符序列是否匹配,也就是说检查一个字符串是否与某种模式匹配。初识 Python 正则表达式 定义一&a…...

15 个适用于企业的生成式 AI 用例
作者:来自 Elastic Jennifer Klinger 关于生成式人工智能及其能做什么(和不能做什么)有很多讨论。生成式人工智能(例如大型语言模型 - LLMs)利用从大量训练数据中学习到的模式和结构来创建原创内容,而无需存…...

若依框架中组件使用教程
...

秋招力扣刷题——数据流的中位数
一、题目要求 中位数是有序整数列表中的中间值。如果列表的大小是偶数,则没有中间值,中位数是两个中间值的平均值。 例如 arr [2,3,4] 的中位数是 3 。 例如 arr [2,3] 的中位数是 (2 3) / 2 2.5 。 实现 MedianFinder 类: MedianFinder() 初始化 …...
51单片机学习——LED功能一系列实现
目录 一、开发前准备 二、点亮LED 三、LED闪烁 四、LED流水灯 五、LED流水灯plus 一、开发前准备 开发工具软件 烧录软件 其次还需要一块51单片机学习开发板及原理图 keil创造project文件及开启生成.hex文件 二、点亮LED 看二位进制对照原理图; #include <…...

互联网大厂核心知识总结PDF资料
我们要敢于追求卓越,也能承认自己平庸,不要低估3,5,10年沉淀的威力 hi 大家好,我是大师兄,大厂工作特点是需要多方面的知识和技能。这种学习和积累一般人需要一段的时间,不太可能一蹴而就&…...

设计模式-状态模式和策略模式
1.状态模式 1.1定义 当一个对象的内在状态改变时允许根据当前状态作出不同的行为; 1.2 适用场景 (1)一个对象的行为取决于它的状态,并且它必须在运行时根据状态来决定其行为. (2)代码中包含了大量的与状态有关的条件语句,例如:一个操作含有庞大的多分值语句(if…...
Java NIO Buffer概念
针对每一种基本类型的 Buffer ,NIO 又根据 Buffer 背后的数据存储内存不同分为了:HeapBuffer,DirectBuffer,MappedBuffer。 HeapBuffer 顾名思义它背后的存储内存是在 JVM 堆中分配,在堆中分配一个数组用来存放 Buffe…...

Kubernetes在Java应用部署中的最佳实践
Kubernetes在Java应用部署中的最佳实践 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨如何在Java应用程序中使用Kubernetes进行最佳部署实践。K…...

IOS Swift 从入门到精通:@escaping 和PreferenceKey
@escaping 在Swift中,@escaping是一个属性关键字,用于标记闭包参数。当一个闭包在函数返回之后才被调用时,这个闭包被称为逃逸闭包(Escaping Closure)。使用@escaping关键字可以告诉Swift编译器,传递给函数的闭包可能会在函数执行完毕后被调用,因此它需要“逃逸”函数的…...
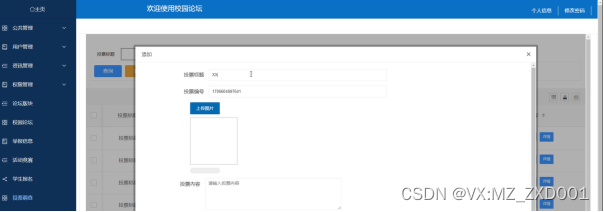
基于PHP技术的校园论坛设计的设计与实现-计算机毕业设计源码08586
摘 要 本项目旨在基于PHP技术设计与实现一个校园论坛系统,以提供一个功能丰富、用户友好的交流平台。该论坛系统将包括用户注册与登录、帖子发布与回复、个人信息管理等基本功能,并结合社交化特点,增强用户之间的互动性。通过利用PHP语言及其…...

开机弹窗缺失OpenCL.dll如何解决?分享5种靠谱的解决方法
在电脑使用过程中,我们可能会遇到一些错误提示,其中之一就是“开机提示找不到OpenCL.dll”。那么,这个错误提示到底是怎么回事呢?它又对电脑有什么影响?我们又该如何解决这个问题并预防OpenCL.dll再次丢失呢࿱…...

IIS 服务器安装SSL证书
IIS 服务器安装SSL证书 步骤一:准备好 SSL 证书 准备好.pfx 格式的证书文件。 步骤二:安装 SSL 证书 1、打开【开始】菜单,找到【管理工具】,打开【Internet 信息服务(IIS)管理器】。 2、单击服务器名…...

二叉树第二期:堆的实现与应用
若对树与二叉树的相关概念,不太熟悉的同学,可移置上一期博客 链接:二叉树第一期:树与二叉树的概念-CSDN博客 本博客目标:对二叉树的顺序结构,进行深入且具体的讲解,同时学习二叉树顺序结构的应用…...

python-求出 e 的值
[题目描述] 利用公式 e11/1!1/2!1/3!⋯1/𝑛!,求 e 的值,要求保留小数点后 10 位。输入: 输入只有一行,该行包含一个整数 n,表示计算 e 时累加到1/n!。输出: 输出只有一行,该行包含计…...

模型微调方法
文章目录 LoRADoRAMoRA 以下部分参考自: https://mp.weixin.qq.com/s/OxYNpXcyHF57OShQC26n4g LoRA LoRA是微软于2021年推出的一种经济型微调模型参数的方法。 它在冻结大部分的模型参数的情况下,仅仅更新额外的部分参数。其性能与全参数微调相似。 LoRA假设微调期间…...

cesium使用cesium-navigation-es6插件创建指南针比例尺
cesium-navigation-es6 是一个为 Cesium.js 提供导航控件的库,它提供了一些常见的用户界面组件,用于在 Cesium 场景中实现用户导航和交互。下面将介绍如何在项目中使用 cesium-navigation-es6。 使用步骤 1. 安装 cesium-navigation-es6 首先…...
Sync.Map)
go sync包(七)Sync.Map
Sync.Map 原理 通过 read 和 dirty 两个字段实现数据的读写分离,读的数据存在只读字段 read 上,将最新写入的数据存在 dirty 字段上。读取时会先查询 read,不存在再查询 dirty,写入时则只写入 dirty。读取 read 并不需要加锁&am…...

Batch文件中的goto命令:控制流程的艺术
Batch文件,也称为批处理脚本,是Windows操作系统中用于自动化任务的一种脚本文件。在Batch脚本中,goto命令是一个至关重要的控制结构,它允许脚本跳转到指定的标签位置,从而实现循环、条件分支等复杂的控制流程。本文将详…...

【chatgpt】两层gcn提取最后一层节点输出特征,如何自定义简单数据集
文章目录 两层gcn,提取最后一层节点输出特征,10个节点,每个节点8个特征,连接关系随机生成(无全连接层)如何计算MSE 100个样本,并且使用批量大小为32进行训练第一个版本定义数据集出错࿰…...
)
【限时解密】Midjourney未公开的Tea印相冷启动协议:如何绕过默认sampler干扰,直触胶片模拟内核(仅剩37位开发者掌握)
更多请点击: https://intelliparadigm.com 第一章:Midjourney Tea印相冷启动协议的起源与本质 Midjourney Tea印相冷启动协议(Tea-Init Protocol)并非官方标准,而是由东亚AI艺术协作社区在2023年自发演化出的一套轻量…...

长期使用后回顾,Taotoken账单明细对项目财务核算的实际帮助
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用后回顾,Taotoken账单明细对项目财务核算的实际帮助 对于一个持续数月、深度依赖大模型能力的项目组而言&#…...

赛车电气系统设计的现代化转型与实践
1. 赛车电气系统设计的现状与挑战当人们谈论赛车技术时,脑海中浮现的往往是碳纤维车身、空气动力学套件或是大马力发动机。但在这光鲜亮丽的表象背后,电气系统才是现代赛车的"神经系统"。有趣的是,这个关键领域的设计方法却呈现出两…...

Linux系统下Vue开发环境搭建:从Node.js到Vite的完整指南
1. 项目概述:为什么要在Linux上搭建Vue环境?对于前端开发者而言,Vue.js 早已不是陌生的名字。它凭借其渐进式的设计理念、灵活的组件化系统和相对平缓的学习曲线,成为了构建现代Web应用的主流框架之一。然而,很多开发者…...

蓝桥杯EDA赛题深度解析:从客观题看电子设计核心考点
1. 蓝桥杯EDA赛题概述与备赛策略 蓝桥杯EDA设计与开发科目作为电子设计领域的重要赛事,每年吸引着众多高校学子参与。这个比赛最独特的地方在于它全面考察参赛者的电子设计自动化能力,从基础理论到软件操作,从元器件认知到电路分析࿰…...

FPGA开发入门:从零开始用Vivado实现LED流水灯项目
1. 项目概述与核心价值最近在后台和社群里,看到不少刚接触FPGA开发的朋友,特别是从单片机或嵌入式软件转过来的,对于如何上手第一个完整的FPGA项目感到有些迷茫。大家常问:“我学了Verilog语法,也跑过仿真了࿰…...

为什么Delorean是Python时间处理的最佳选择?
为什么Delorean是Python时间处理的最佳选择? 【免费下载链接】delorean Delorean: Time Travel Made Easy 项目地址: https://gitcode.com/gh_mirrors/de/delorean 在Python开发中,时间处理常常是一个令人头疼的问题,尤其是涉及到时区…...

别再只用DS18B20了!用51单片机+ADC0804做个PT100温度计,从硬件接线到代码调试保姆级教程
从DS18B20到PT100:51单片机高精度温度检测系统实战指南 1. 为什么选择PT100而非DS18B20? 在嵌入式温度检测领域,DS18B20确实因其即插即用的特性广受欢迎。但当我们面对工业级应用时,PT100铂电阻温度传感器展现出了不可替代的优势。…...

GPT5.5复杂任务拆解提示策略单次对话搞不定的活这样分
做多模型横向对比测试时常用的聚合平台推荐下:库拉KULAAI(c.877ai.cn),上面能直接调GPT-5.5和多个主流模型做复杂任务拆解能力对比。下面进入正题。复杂任务为什么让AI翻车用AI Agent干活一段时间后你一定遇到过这种情况。你让它一…...

用Gemini3.1Pro高效撰写工作汇报从素材整理到终稿交付全流程
做多模型横向对比测试时常用的聚合平台推荐下:库拉KULAAI(c.877ai.cn),上面能直接调Gemini 3.1 Pro和多个主流模型做职场办公场景对比。下面进入正题。工作汇报和周报不是一回事很多人把工作汇报和周报混为一谈。周报是流水线上的…...