深度剖析:前端如何驾驭海量数据,实现流畅渲染的多种途径
文章目录
- 一、分批渲染
- 1、setTimeout定时器分批渲染
- 2、使用requestAnimationFrame()改进渲染
- 2.1、什么是requestAnimationFrame
- 2.2、为什么使用requestAnimationFrame而不是setTimeout或setInterval
- 2.3、requestAnimationFrame的优势和适用场景
- 二、滚动触底加载数据
- 三、Element-Plus虚拟化表格
- 四、自定义虚拟滚动列表
- 1、视图结构
- 2、基本思路
- 3、具体计算
- 4、实现代码
- 五、使用el-table-infinite-scroll插件
- 1、el-table-infinite-scroll(vue3)
- 2、el-table-infinite-scroll(vue2)
- 六、使用Web Workers处理数据
- 七、借助服务端渲染(SSR)
处理大量数据的渲染对于前端开发来说是一项挑战,但也是提升网页性能和用户体验的重要环节。要有效解决这一问题,可以采用虚拟滚动(Virtual Scrolling)、分批渲染(Incremental Rendering)、使用Web Workers处理数据、利用前端分页(Pagination)、借助服务端渲染(SSR)来优化大量数据的处理。其中,虚拟滚动是一种非常有效的技术,它通过只渲染用户可见的列表项来极大减少DOM操作和提高性能。这种方式不仅提升了滚动的流畅度,也减轻了浏览器的负担,尤其适用于长列表数据的展示。
一、分批渲染
分批渲染或称增量渲染,是指将数据分成若干批次进行处理和渲染,每次只处理一小部分数据,通过逐步完成整体渲染的方式,避免了一次性处理大量数据造成的卡顿现象。
实现分批渲染通常可以通过requestAnimationFrame()或setTimeout()等异步API分配任务,确保在每个渲染帧中只处理足够少的数据,避免阻塞主线程。
1、setTimeout定时器分批渲染
//发送请求
onMounted(() => {getData()
})//获取数据
const getData = () => {fetch('http://124.223.69.156:3300/bigData').then(res => res.json()).then(data => {let newData = chunksData(data.data)console.log(newData);}).catch(err => console.log(err));
}//数据分页
const chunksData = (arr) => {let chunkSize = 10;let chunks = [];for (let i = 0; i < arr.length; i += chunkSize) {chunks.push(arr.slice(i, i + chunkSize));}return chunks
}//setTimeout分页渲染
for (let i = 0; i < newData.length; i++) {setTimeout(() => {tableData.push(...newData[i])}, 100*i)
}
2、使用requestAnimationFrame()改进渲染
2.1、什么是requestAnimationFrame
requestAnimationFrame是浏览器用于定时循环操作的一个API,通常用于动画和游戏开发。它会把每一帧中的所有DOM操作集中起来,在重绘之前一次性更新,并且关联到浏览器的重绘操作。
2.2、为什么使用requestAnimationFrame而不是setTimeout或setInterval
与setTimeout或setInterval相比,requestAnimationFrame具有以下优势:
- 通过系统时间间隔来调用回调函数,无需担心系统负载和阻塞问题,系统会自动调整回调频率。
- 由浏览器内部进行调度和优化,性能更高,消耗的CPU和GPU资源更少。
- 避免帧丢失现象,确保回调连续执行,实现更流畅的动画效果。
- 自动合并多个回调,避免不必要的开销。
- 与浏览器的刷新同步,不会在浏览器页面不可见时执行回调。
2.3、requestAnimationFrame的优势和适用场景
requestAnimationFrame最适用于需要连续高频执行的动画,如游戏开发,数据可视化动画等。它与浏览器刷新周期保持一致,不会因为间隔时间不均匀而导致动画卡顿。
const renderData = (page) => {if(page >= newData.length) returnrequestAnimationFrame(() => {tableData.push(...newData[page])page++renderData(page)})
}renderData(0)
二、滚动触底加载数据
前端分页是处理大量数据渲染的另一种常见策略,它通过每次只向用户展示一部分数据,让用户通过分页控件浏览完整的数据集。
实现前端分页首先需要从后端一次性获取完整数据,然后根据设定的每页数据量在前端进行切分,每次仅加载和渲染当前页的数据。这种方式减轻了单次渲染的负担,但增加了数据管理的复杂性。
//发送请求
onMounted(() => {getData()
})//获取数据
const getData = () => {fetch('http://124.223.69.156:3300/bigData').then(res => res.json()).then(data => {let newData = chunksData(data.data)//保存所有数据totalData.push(newData)//渲染第一页面数据renderData()}).catch(err => console.log(err));
}//数据分页
const chunksData = (arr) => {let chunkSize = 10;let chunks = [];for (let i = 0; i < arr.length; i += chunkSize) {chunks.push(arr.slice(i, i + chunkSize));}return chunks
}//渲染数据
const renderData = () => {if(totalData.length == 0) return//添加第一页数据tableData.push(...totalData[0])//删除第一页数据totalData.shift()
}
监听滚动事件,触底触底时触发renderData事件,继续加载下一页数据。
三、Element-Plus虚拟化表格
Element Plus 提供 的Virtualized Table 虚拟化表格
在前端开发领域,表格一直都是一个高频出现的组件,尤其是在中后台和数据分析场景。 但是,对于 Table V1来说,当一屏里超过 1000 条数据记录时,就会出现卡顿等性能问题,体验不是很好。
通过虚拟化表格组件,超大数据渲染将不再是一个头疼的问题。
即使虚拟化的表格是高效的,但是当数据负载过大时,网络和内存容量也会成为您应用程序的瓶颈。
因此请牢记,虚拟化表格永远不是最完美的解决方案,请考虑数据分页、过滤器等优化方案。
<template><div style="width: 100%;height: 100%"><el-auto-resizer><template #default="{ height, width }"><el-table-v2 :columns="columns" :data="tableData" :width="width" :height="height" fixed /></template></el-auto-resizer></div>
</template><script setup>
import { onMounted, reactive } from 'vue';
const tableData = reactive([])
const columns = [{key: 'id',dataKey: 'id',title: 'ID',width: 140
},
{key: 'name',dataKey: 'name',title: 'Name',width: 140,
},
{key: 'value',dataKey: 'value',title: 'Value',width: 140,
}]//获取数据
onMounted(() => {getData()
})const getData = () => {fetch('http://124.223.69.156:3300/bigData').then(res => res.json()).then(data => {tableData.push(...data.data)}).catch(err => console.log(err));
}
</script>
四、自定义虚拟滚动列表
虚拟滚动是通过仅渲染用户当前可视区域内的元素,当用户滚动时动态加载和卸载数据,从而实现长列表的高效渲染。这种方法能显著减少页面初始化时的渲染负担,加快首次渲染速度。
虚拟滚动实现的核心在于计算哪些数据应当被渲染在屏幕上。这涉及到监听滚动事件,根据滚动位置计算当前可视范围内的数据索引,然后仅渲染这部分数据。还需要处理好滚动条的位置和大小,确保用户体验的一致性。
1、视图结构
- viewport:可视区域的容器
- list-area:列表项的渲染区域
<div class="viewport" ref="viewport"><div class="list-area"><!-- item-1 --> <!-- item-2 --> <!-- item-n --> </div>
</div>
2、基本思路
虚拟列表的核心思路是 处理用户滚动时可视区域数据的显示 和 可视区外数据的隐藏,这里为了方便说明,引入以下相关变量:
- totalList :总列表数据
- startIndex :可视区域的开始索引
- endIndex :可视区域的结束索引
- paddingTop :可视区域的上内边距
- paddingBottom :可视区域的下内边距
当用户滚动列表时:
- 计算可视区域的 开始索引 和 结束索引
- 根据 开始索引 和 结束索引 渲染数据
- 计算 可视区域的上内边距 和下内边距 显示滚动条位置
3、具体计算
先假定可视区的高度固定为600px,每个列表项的高度固定为60px,则我们可设置和推导出:
- 可视区高度: viewportHeight = 600
- 列表项高度: itemSize = 60
- 可视区开始索引: startIndex = 0
- 可视区结束索引 :endIndex = startIndex + viewportHeight / itemSize
当用户滚动时,逻辑处理如下:
- 获取可视区滚动距离 scrollTop;
- 根据 滚动距离 scrollTop 和 单个列表项高度 itemSize 计算出 开始索引 startIndex = Math.floor(scrollTop / itemSize);
- 可视区域的上内边距 paddingTop = scrollTop;
- 可视区域的上内边距 paddingBottom = totalList * itemSize - viewportHeight - scrollTop;
- 只显示 开始索引 和 结束索引 之间的列表项;
4、实现代码
<template><div class="viewport" ref="viewport"><div class="list-area" :style="styleObject"><div v-for="(item, index) in scrollList" :key="index" class="item">index:{{ index }} id:{{ item.id }} name:{{item.name }}</div></div></div>
</template>
<script setup>
import { onMounted, reactive, ref, computed, onBeforeUnmount } from 'vue';
//总列表的数据
const totalList = reactive([])
//可视区域的开始索引
let startIndex = ref(0)
// 假设每个列表项的高度是60px
let itemSize = ref(60)
//可视区域的上内边距
let paddingTop = ref(0)
//可视区域的下内边距
let paddingBottom = ref(0)
//容器的高度
let viewportHeight = ref(600)
//容器
const viewport = ref(null)// 计算可视区域的列表数据
const scrollList = computed(() => {return totalList.slice(startIndex.value, endIndex.value);
})// 计算可视区域的高度和内边距
const styleObject = computed(() => {return {paddingTop: `${paddingTop.value}px`,paddingBottom: `${paddingBottom.value}px`,height: `${viewportHeight.value}px`}
})// 计算可视区域的结束索引
const endIndex = computed(() => {return Math.min(totalList.length, startIndex.value + Math.ceil(viewportHeight.value / itemSize.value));
})//发送请求获取数据
onMounted(() => {getData()
})//获取数据
const getData = () => {fetch('http://124.223.69.156:3300/bigData').then(res => res.json()).then(data => {let newArr = data.datatotalList.push(...newArr)initScrollListener()}).catch(err => console.log(err));
}// 监听可视区域滚动事件
const initScrollListener = () => {scrollListener()viewport.value.addEventListener('scroll', scrollListener);
}// 计算可视区域的内边距
const scrollListener = () => {// 计算可视区域滚动距离const scrollTop = viewport.value.scrollTop;// 计算可视区域的开始索引startIndex.value = Math.max(0, Math.floor(scrollTop / itemSize.value));// 计算可视区域的上内边距paddingTop.value = scrollTop;// 如果是最后一页,则不需要额外的底部填充 if (endIndex.value >= totalList.length) {paddingBottom.value = 0;} else {// 计算可视区域的下内边距paddingBottom.value = totalList.length * itemSize.value - viewportHeight.value - scrollTop;}
}// 移除可视区域滚动事件
onBeforeUnmount(() => {removeScrollListener()
})// 移除可视区域滚动事件
const removeScrollListener = () => {viewport.value.removeEventListener('scroll', scrollListener);
}<style scoped>
.viewport {width: 600px;height: 600px;overflow: auto;border: 1px solid #D3DCE6;margin: auto;
}.item {height: 59px;line-height: 60px;border-bottom: 1px solid #D3DCE6;padding-left: 20px;
}
</style>
这里可以看出,永远只渲染10条数据。随着滚动条滚动,动态渲染10条数据。


五、使用el-table-infinite-scroll插件
1、el-table-infinite-scroll(vue3)
- 安装
npm install --save el-table-infinite-scroll
- 全局引入
import ElTableInfiniteScroll from "el-table-infinite-scroll";
app.use(ElTableInfiniteScroll);
- 局部引入
<template><el-table v-el-table-infinite-scroll="load"></el-table>
</template><script setup>
import { default as vElTableInfiniteScroll } from "el-table-infinite-scroll";
</script>
- 组件中使用
<template><p style="margin-bottom: 8px"><span>loaded page(total: {{ total }}): {{ page }}, </span>disabled:<el-switch v-model="disabled" :disabled="page >= total"></el-switch></p><el-tablev-el-table-infinite-scroll="load":data="data":infinite-scroll-disabled="disabled"height="200px"><el-table-column type="index" /><el-table-column prop="date" label="date" /><el-table-column prop="name" label="name" /><el-table-column prop="age" label="age" /></el-table>
</template><script setup>
import { ref } from 'vue';const dataTemplate = new Array(10).fill({date: '2009-01-01',name: 'Tom',age: '30',
});const data = ref([]);
const disabled = ref(false);
const page = ref(0);
const total = ref(5);const load = () => {if (disabled.value) return;page.value++;if (page.value <= total.value) {data.value = data.value.concat(dataTemplate);}if (page.value === total.value) {disabled.value = true;}
};
</script><style lang="scss" scoped>
.el-table {:deep(table) {margin: 0;}
}
</style>
2、el-table-infinite-scroll(vue2)
- 安装
npm install --save el-table-infinite-scroll@2
- 全局引入
import Vue from "vue";
import ElTableInfiniteScroll from "el-table-infinite-scroll";
Vue.directive("el-table-infinite-scroll", ElTableInfiniteScroll);
- 局部引入
<script>
import ElTableInfiniteScroll from "el-table-infinite-scroll";
export default {directives: {"el-table-infinite-scroll": ElTableInfiniteScroll,},
};
</script>
- 组件中使用
<template><el-tablev-el-table-infinite-scroll="load":data="data":infinite-scroll-disabled="disabled"height="200px"><el-table-column type="index" /><el-table-column prop="date" label="date" /><el-table-column prop="name" label="name" /><el-table-column prop="age" label="age" /></el-table>
</template><script>
const dataTemplate = new Array(10).fill({date: "2009-01-01",name: "Tom",age: "30",
});export default {data() {return {data: [],page: 0,total: 5,};},methods: {load() {if (this.disabled) return;this.page++;if (this.page <= this.total) {this.data = this.data.concat(dataTemplate);}if (this.page === this.total) {this.disabled = true;}},},
};
</script>
六、使用Web Workers处理数据
Web Workers提供了一种将数据处理操作放在后台线程的方法,这样即使处理大量或者复杂的数据,也不会阻塞UI的更新和用户的交互。
在Web Workers中处理数据,前端主线程可以保持高响应性。数据处理完成后,再将结果发送回主线程进行渲染。这对于需要复杂计算处理的大量数据尤为有用。
这里不详细描述
七、借助服务端渲染(SSR)
服务端渲染(SSR)是指在服务器端完成页面的渲染工作,直接向客户端发送渲染后的HTML内容,能显著提升首次加载的速度,对于SEO也非常友好。
虽然SSR不是直接在前端处理大量数据,但它通过减轻前端渲染压力、提前渲染页面内容来间接优化大数据处理的性能问题。结合客户端渲染,可以实现快速首屏加载与动态交互的平衡。
这里不详细描述
相关文章:
深度剖析:前端如何驾驭海量数据,实现流畅渲染的多种途径
文章目录 一、分批渲染1、setTimeout定时器分批渲染2、使用requestAnimationFrame()改进渲染2.1、什么是requestAnimationFrame2.2、为什么使用requestAnimationFrame而不是setTimeout或setInterval2.3、requestAnimationFrame的优势和适用场景 二、滚动触底加载数据三、Elemen…...

AI时代,你的工作会被AI替代吗?
AI在不同领域的应用和发展速度是不同的。在智商方面,尤其是在逻辑推理、数据分析和模式识别等领域,AI已经取得了显著的进展。例如,在国际象棋、围棋等策略游戏中,AI已经能够击败顶尖的人类选手。在科学研究、医学诊断、股市分析等…...

Java_日志
日志技术 可以将系统执行的信息,方便的记录到指定的位置(控制台、文件中、数据库中) 可以随时以开关的形式控制日志启停,无需侵入到源代码中去进行修改。 日志技术的体系结构 日志框架:JUL、Log4j、Logback、其他实现。 日志接口…...
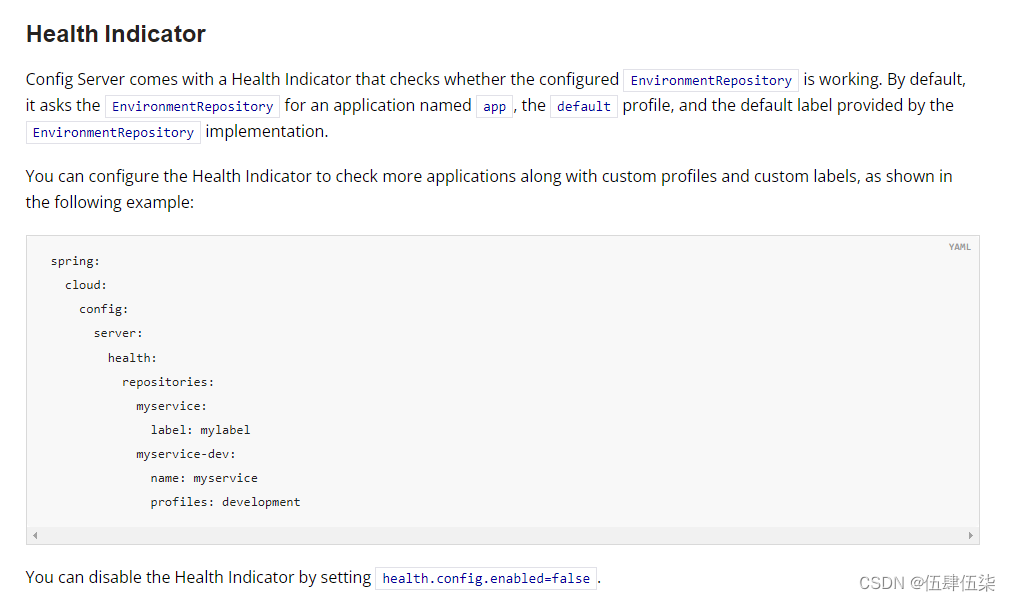
springcould-config git源情况下报错app仓库找不到
在使用spring config server服务的时候发现在启动之后的一段时间内控制台会抛出异常,spring admin监控爆红,控制台信息如下 --2024-06-26 20:38:59.615 - WARN 2944 --- [oundedElastic-7] o.s.c.c.s.e.JGitEnvironmentRepository : Error occured …...

MySQL serverTimezone=UTC
在数据库连接字符串中使用 serverTimezoneUTC 是一个常见的配置选项,特别是当数据库服务器和应用程序服务器位于不同的时区时。这个选项指定了数据库服务器应当使用的时区,以确保日期和时间数据在客户端和服务器之间正确传输和处理。 UTC(协…...
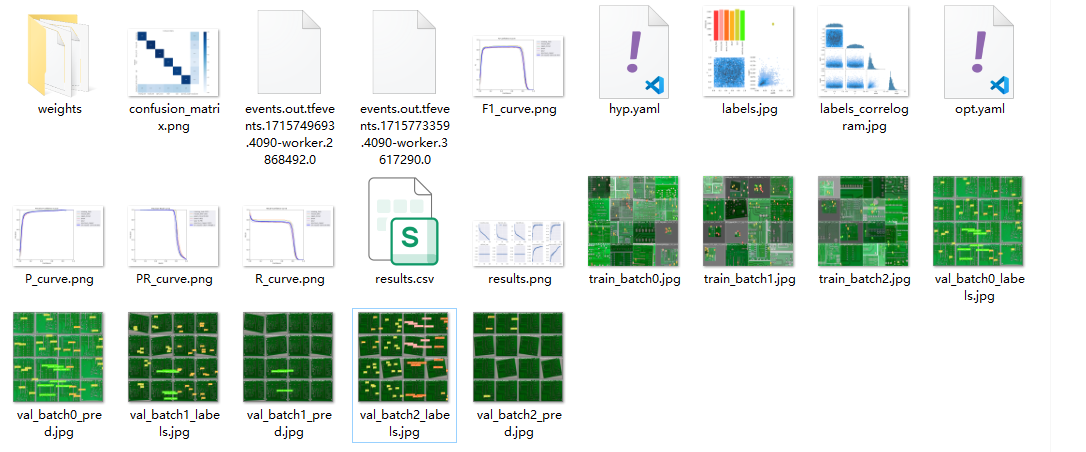
基于YOLOv9的PCB板缺陷检测
数据集 PCB缺陷检测,我们直接采用北京大学智能机器人开放实验室数据提供的数据集, 共六类缺陷 漏孔、鼠咬、开路、短路、杂散、杂铜 已经对数据进行了数据增强处理,同时按照YOLO格式配置好,数据内容如下 模型训练 采用YOLO…...

高考结束,踏上西北的美食之旅
高考的帷幕落下,暑期的阳光洒来,是时候放下书本,背上行囊,踏上一场充满期待的西北之旅。而在甘肃这片广袤的土地上,除了壮丽的自然风光,还有众多令人垂涎欲滴的美食等待着您的品尝。当您踏入甘肃࿰…...

人工智能 (AI) 在能源系统中应用的机会和风险
现代文明极度依赖于电力的获取。电力系统支撑着我们视为理所当然的几乎所有基本生活功能。没有电力的获取,大多数经济活动将是不可能的。然而,现有的电网系统并未设计来应对当前——更不用说未来的——电力需求。与此同时,气候变化迫切要求我…...

[AIGC] 定时删除日志文件
文章目录 需求实现脚本解释 需求 实现一个定时任务,定时删除两天前的日志文件,如果某个目录使用量超过80%,则删除文件 实现 要实现这样的要求,我们可以创建一个shell脚本,在该脚本中使用find命令查找两天前的日志文…...

C++:typeid4种cast转换
typeid typeid typeid是C标准库中提供的一种运算符,它用于获取类型的信息。它主要用于类型检查和动态类型识别。当你对一个变量或对象使用typeid运算符时,它会返回一个指向std::type_info类型的指针,这个信息包含了关于该类型名称、大小、基…...

vue3的配置和使用
vue的使用需要配置node且node版本需要在15以上。管理员方式打开cmd,输入node -v,可以查看node版本。 创建vue有以下两种方式 npm init vuelatestnpm create vuelatest创建后输入项目名,其它的输入否即可,新手可以先不用 按照要求…...
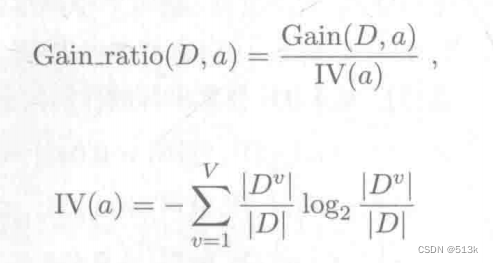
决策树划分属性依据
划分依据 基尼系数基尼系数的应用信息熵信息增益信息增益的使用信息增益准则的局限性 最近在学习项目的时候经常用到随机森林,所以对决策树进行探索学习。 基尼系数 基尼系数用来判断不确定性或不纯度,数值范围在0~0.5之间,数值越低&#x…...
短视频利器 ffmpeg (2)
ffmpeg 官网这样写到 Converting video and audio has never been so easy. 如何轻松简单的使用: 1、下载 官网:http://www.ffmpeg.org 安装参考文档: https://blog.csdn.net/qq_36765018/article/details/139067654 2、安装 # 启用RPM …...
【计算机毕业设计】基于Springboot的智能物流管理系统【源码+lw+部署文档】
包含论文源码的压缩包较大,请私信或者加我的绿色小软件获取 免责声明:资料部分来源于合法的互联网渠道收集和整理,部分自己学习积累成果,供大家学习参考与交流。收取的费用仅用于收集和整理资料耗费时间的酬劳。 本人尊重原创作者…...

【2024】LeetCode HOT 100——图论
目录 1. 岛屿数量1.1 C++实现1.2 Python实现1.3 时空分析2. 腐烂的橘子2.1 C++实现2.2 Python实现2.3 时空分析3. 课程表3.1 C++实现3.2 Python实现3.3 时空分析4. 实现 Trie (前缀树)4.1 C++实现4.2 Python实现4.3 时空分析1. 岛屿数量 🔗 原题链接:200. 岛屿数量 经典的Fl…...

解析Java中1000个常用类:Currency类,你学会了吗?
在线工具站 推荐一个程序员在线工具站:程序员常用工具(http://cxytools.com),有时间戳、JSON格式化、文本对比、HASH生成、UUID生成等常用工具,效率加倍嘎嘎好用。程序员资料站 推荐一个程序员编程资料站:程序员的成长之路(http://cxyroad.com),收录了一些列的技术教程…...

5.x86游戏实战-CE定位基地址
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:4.x86游戏实战-人物状态标志位 上一个内容通过CE未知的初始值、未变动的数值、…...

istitle()方法——判断首字母是否大写其他字母小写
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 语法参考 istitle()方法用于判断字符串中所有的单词首字母是否为大写而其他字母为小写。istitle()方法的语法格式如下: str.istitle() …...

Linux实用命令练习
目录 一、常用命令 二、系统命令 三、用户和组 四、权限 五、文件相关命令 六、查找 七、正则表达式 八、输入输出重定向 九、进程控制 十、其他命令 1、远程文件复制:scp 2、locate查找 3、which命令 4、设置或显示环境变量:export 5、修…...

刷题——二叉搜索树与双向链表
二叉搜索树与双向链表_牛客题霸_牛客网 方法一: void dfs(TreeNode* pRootOfTree, TreeNode* &pre){if(pRootOfTree NULL)return;dfs(pRootOfTree->left, pre);//所有左子树if(pre)pre->right pRootOfTree;pRootOfTree->left pre;pre pRootOfTree…...
)
Vivado工程文件太大?三步教你用Tcl脚本实现源码“瘦身”与备份(附完整命令)
Vivado工程瘦身实战:Tcl脚本驱动的源码管理与协作优化 在FPGA开发领域,Vivado工程文件的体积膨胀问题一直是开发者面临的痛点。一个中等规模的项目经过几次综合与实现后,工程目录轻松突破数百MB并不罕见。这不仅占用宝贵的存储空间ÿ…...

PTA数据结构实战:层次遍历巧解二叉树叶结点输出
1. 从问题理解到解题思路 第一次看到PTA上这道二叉树题目时,我也被题目描述唬住了。题目要求按从上到下、从左到右的顺序输出所有叶结点,这不就是典型的层次遍历(BFS)应用场景吗?但仔细分析输入格式后,我发…...

ParsecVDisplay终极指南:解锁Windows虚拟显示器完整解析
ParsecVDisplay终极指南:解锁Windows虚拟显示器完整解析 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 你是否曾渴望拥有额外的屏幕空间,却受限于物理显示…...

DIY智能烛光发饰:用导电缝纫线制作可穿戴电子入门项目
1. 项目概述:当传统手工艺遇上智能微光几年前,我开始接触可穿戴电子,最初的想法很简单:让日常穿戴的物件不只是静态的装饰,而是能与人产生动态交互的“伙伴”。从在衣服上缝几个会亮的LED,到尝试集成传感器…...

基于BLE与CircuitPython的远程服务器重启开关设计与实现
1. 项目概述与核心思路手头有几台电脑分散在家里各个角落,有时候它们死机了需要重启,但偏偏其中一台作为监控录像存储的服务器,被我塞进了一个带锁的柜子里。每次都得找钥匙、开门、按按钮,实在麻烦。这个需求催生了我动手做一个无…...

基于Code Llama的本地AI编程助手:VSCode插件部署与优化实战
1. 项目概述:为什么我们需要一个更聪明的代码助手?在VSCode的插件市场里搜索“AI代码补全”,结果可能会让你眼花缭乱。从基于GPT的Copilot到各种开源模型驱动的工具,选择很多,但痛点也很明显:要么需要稳定的…...

CloudBase-MCP:基于MCP协议桥接本地应用与云服务的实践指南
1. 项目概述:一个连接云与本地应用的“智能接线员”如果你正在开发一个应用,需要让它在本地服务器上运行,同时又想无缝地调用云上的各种能力——比如对象存储、数据库、AI模型或者消息队列,你会怎么做?传统的方式可能是…...
完)
MySQL数据库基础3--(函数)完
一、聚合函数聚合函数包括COUNT()、SUM()、AVG()、MAX()和MIN()。当需要对表中的记录求和、求平均值、查询最大值和查询最小值等操作时,可以使用聚合函数。GROUP BY关键字通常需要与聚合函数一起使用。COUNT()用来统计记录的条数;SUM()用来计算字段的值的…...

AI代码助手Cursor与Django全栈开发:十倍速构建Web应用实战
1. 项目概述:当AI代码助手遇上Django全栈开发如果你是一名独立开发者、初创团队的技术负责人,或者正在学习全栈开发,那么你一定对如何高效构建一个现代化的Web应用感到头疼。从环境配置、数据库设计、API接口开发到前端页面渲染,每…...

从 Palantir Ontology 到企业 AI 决策系统
这几年,大模型把企业 AI 的想象空间一下子拉高了。很多公司都已经能做聊天、做问答、做检索、做 Copilot,甚至做一些初步的 Agent。但真正往生产里推,很快就会撞到几个老问题:模型能说,却未必真懂业务;能总…...