2-requests模块(6节课学会爬虫)
2-requests模块(6节课学会爬虫)
- 1,安装requests
- 2,发送get,post请求,获取响应
- 3,response的方法
- 方法一(Response.text)
- 方法二(response.content.decode())
- 4,获取网页源码的正确打开方式(一定能获取网页正确解码的字符串)
- 5,发送带header的请求
- 6,使用超时参数
- 7,Retrying模块的学习
- 8,处理cookie相关的请求
- 方法一,直接携带cookie请求url地址
- 方法二,在程序中登录
1,安装requests
pip install requests
2,发送get,post请求,获取响应
Response = requests.get(url) 发送get请求,请求url地址对应的响应
发送post请求
Data={请求体的字典}
response = requests.post(url,data=data)
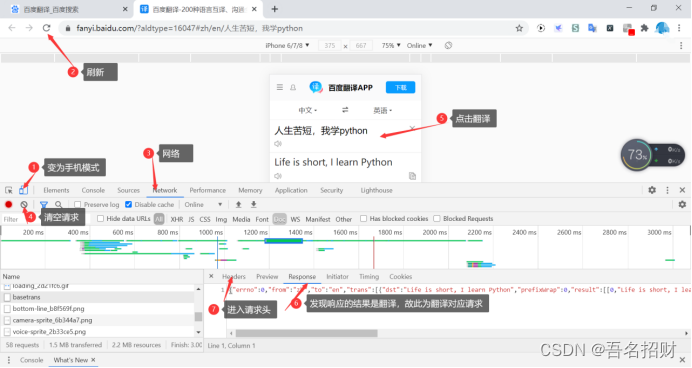
下面模拟浏览器发送post请求,能进行翻译
(1)找到要发送的url地址
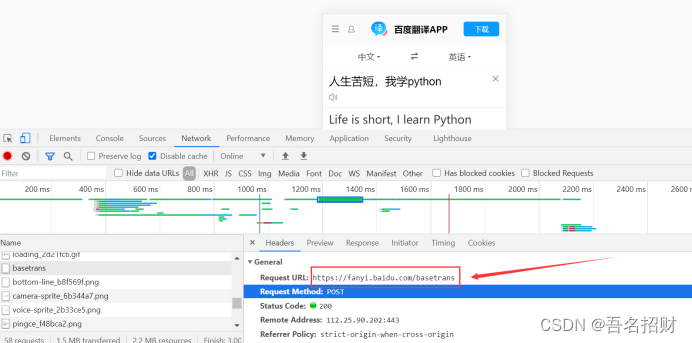
import requestsurl = "https://fanyi.baidu.com/basetrans"
(2)要携带的数据,在最下方
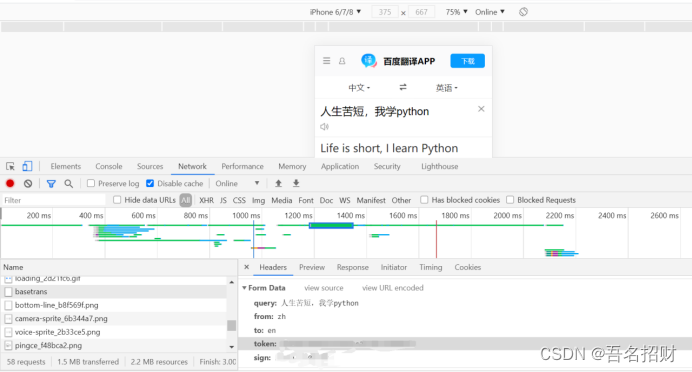
将其复制到字典中,并变成键值对的形式
程序如下(data内容并不全面,需补充,可能是导致后方,无法返回结果的原因)
data={"query": "人生苦短,我学python","from":"zh","to": "en"}
3,response的方法
方法一(Response.text)
该方式往往会出现乱码,出现乱码使用response.encoding=”utf-8”进行解码
ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ
import requestsurl = "http://www.baidu.com"
response = requests.get(url) #发送get请求
#print(response) #<Response [200]>尖括号表示对象,200是状态码response.encoding="utf-8"
print(response.text)
百度一下,你就知道
方法二(response.content.decode())
把响应的二进制流转换成str类型
import requestsurl = "http://www.baidu.com"
response = requests.get(url) #发送get请求
#print(response) #<Response [200]>尖括号表示对象,200是状态码#获取网页的HTML字符串
# response.encoding="utf-8"
# print(response.text)print(response.content.decode())
Response.requests.url #发送请求的url地址
Response.url #response响应的url地址
Response.requests.headers #请求头
Response.headers #响应请求
4,获取网页源码的正确打开方式(一定能获取网页正确解码的字符串)
当要获取网页时,使用下方的从前向后,第一种无法获取正确网页时,使用第二种,最后第三种,一定是可以能够获取的
1.response.content.decode()
2.response.content.decode("gbk")
3.reponse.content.decode('unicode-escape')
4.response.text
import requestsurl = "https://fanyi.baidu.com/basetrans"
data={"query": "人生苦短,我学python","from":"zh","to": "en"}reponse = requests.post(url,data=data)
print(reponse)
print(reponse.content.decode())
上方状态码是200,但是没有响应结果,虽然请求发出去了,但对方服务器将我们识别为爬虫了,所以不给响应
只有url和data是不够的,还需要headers的字段内容
5,发送带header的请求
为了模拟浏览器,获取和浏览器一模一样的内容
headers = {"user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1"}
当发现user-agent请求时还不能成功,需要再加入其它的参数,如下,可以将除cookie的所有参数带上,再不成功的话就只能带上cookie(百度翻译是必须要带上cookie的,有user-agent和cookie就足够了,但cookie最好不要使用自己的容易泄露很多信息)
headers = {"user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1","referer": "https://fanyi.baidu.com/?aldtype=16047"}
reponse = requests.post(url,data=data,headers=headers)
因为手机版的返回错误,故使用网页版的进行测试(网页版的测试成功了,手机版只有user-agent和cookie的话好像不行)
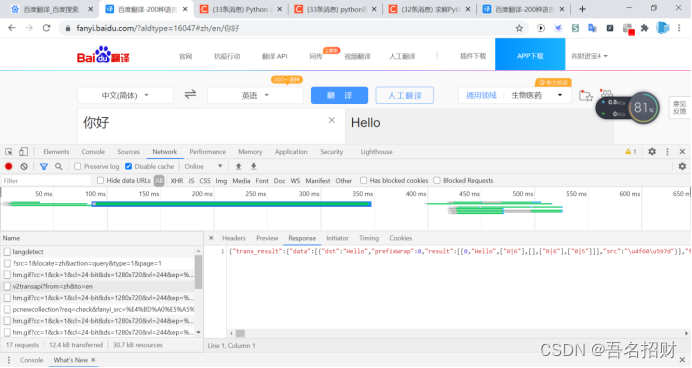
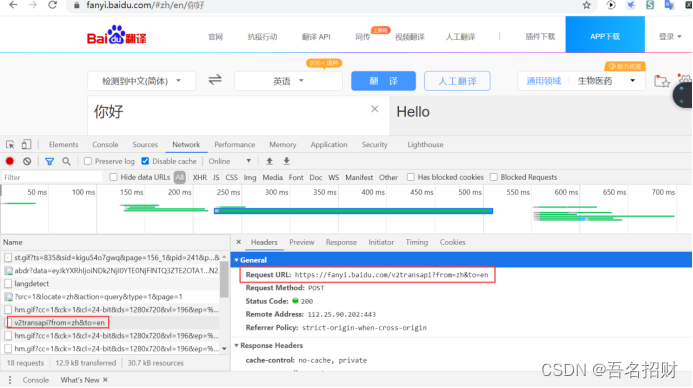
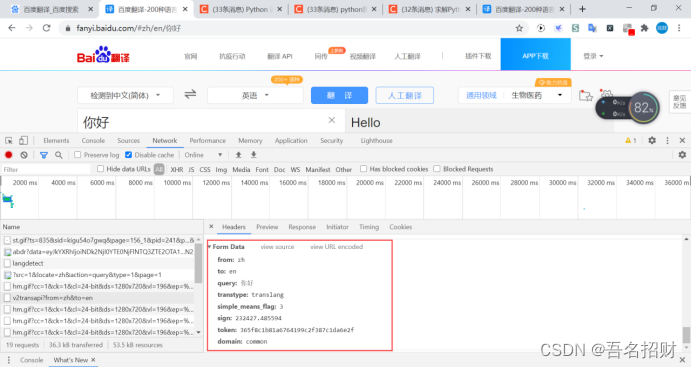
#模拟浏览器访问
url = "https://fanyi.baidu.com/v2transapi?from=zh&to=en"
data={"from": "zh","to": "en","query": "你好","transtype": "translang","simple_means_flag": "3","sign": "232427.485594","token": "365f8c1b81a6764199c2f387c1da6e2f","domain": "common"}
headers = {# "accept-encoding": "gzip, deflate, br",# "accept-language": "zh-CN,zh;q=0.9",# "cache-control": "no-cache",# "content-length": "150",# "content-type": "application/x-www-form-urlencoded; charset=UTF-8",# "origin": "https://fanyi.baidu.com",# "pragma": "no-cache",# "referer":"https://fanyi.baidu.com/v",# "sec-fetch-destv": "empty",# "sec-fetch-mode": "cors",# "sec-fetch-site": "same-origin",# "x-requested-with": "XMLHttpRequest","user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36","cookie": "使用自己的"}reponse = requests.post(url,data=data,headers=headers)
print(reponse.content.decode())
打印结果如下,有非常多的垃圾信息
{"trans_result":{"data":[{"dst":"Hello","prefixWrap":0,"result":[[0,"Hello",["0|6"],[],["0|6"],["0|5"]]],"src":"\u4f60\u597d"}],"from":"zh","status":0,"to":"en","type":2},1\",0]],[[\"'\",\"w_332\",\"w_321,w_332\",0],[\"Hi\",\"w_333\",\"w_322,w_333\",0],[\",\",\"w_334\",\"w_323,w_334\",0,\" \"],
6,使用超时参数
平时请求一个网页,当网络不好等会出现一直刷新的情况,一旦有一个页面卡住,就会效率低,可以使用超时参数进行改进,超时参数避免超时,会报错可以进行错误捕获
Requests.get(url,headers=headers,timeout=3) #3秒内必须返回响应,否则会报错
7,Retrying模块的学习
使用retry模块,将其定义一个函数,用来进行url的访问
Retry能够执行一个函数反复执行多少次当其报错的时候
Pip install retrying
import requests
from retrying import retry#下方是电脑版的,若是手机版的,还需要更改为手机版
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}@retry(stop_max_attempt_number=3) #让下面被装饰的函数反复执行三次,三次全部报错才会报错,中间有一次正常,程序继续往后走
def _parse_url(url):print("*"*100)response = requests.get(url,headers=headers,timeout=5)return response.content.decode()def parse_url(url):try:html_str = _parse_url(url)except:html_str = Nonereturn html_strif __name__ == '__main__':url = "http://www.baidu.com"print(parse_url(url)[:100]) #只打印前100字符串,此处访问成功只出现一行*url1 = "www.baidu.com" #此处地址有误print(parse_url(url1)) #会出现三行*
8,处理cookie相关的请求
人人网
方法一,直接携带cookie请求url地址
先在页面登录了,网页检查可得到cookie
(1)cookie放在headers中
Headers = {“user-agent”:”....”,”cookie”:”cookie 字符串”}
(2)cookie字典传给cookies参数
Cookied 的字典,与上方的headers形式是完全不同的,这不详细写了,可在网上查找
Requests.get(url,cookies=cookie_dict)
有些需要登录的是需要cookie的
方法二,在程序中登录
不直接在网上登录,而是在程序中登录,输入账号,密码
先发送post请求,获取cookie,带上cookie请求登录后的页面
1.session = requests.session() #seesion具有的方法和requests一样
2.Session.post(url,data,headers) #服务器设置在本地的cookie会存在session
3.Session.get(url) #会带上之前保存在session中的cookie
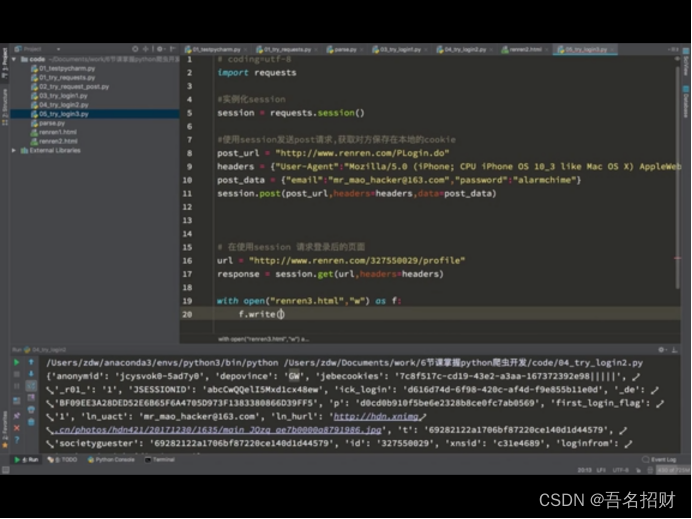
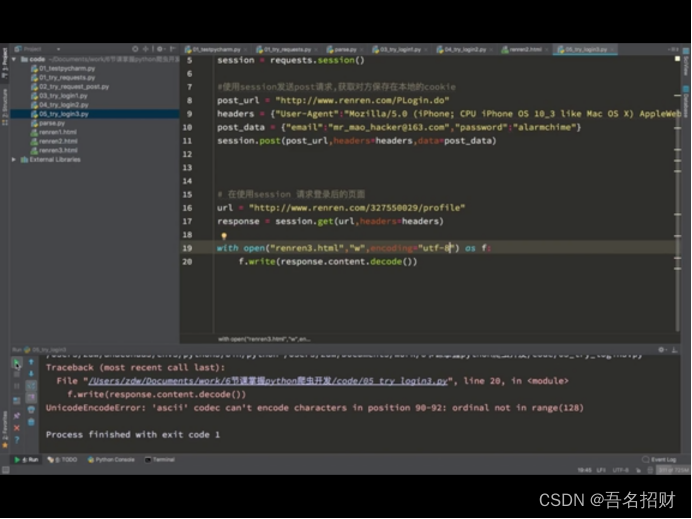
我们可以通过抓包,得到登录界面的请求post地址,
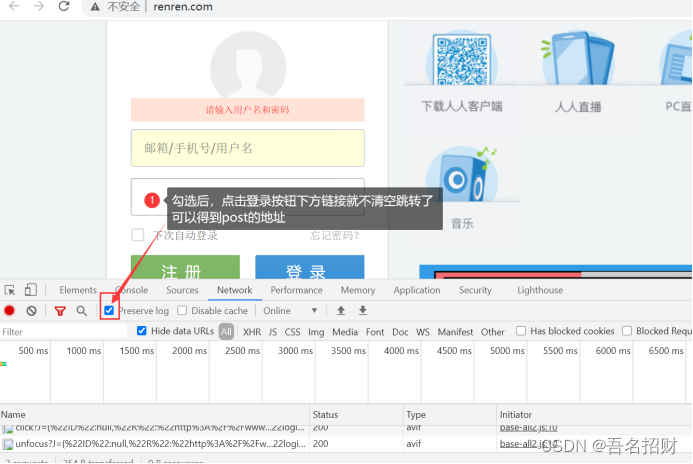
或者在form表单找action的url地址,或者模拟鼠标的selnum的模块,进行点击登录,输入账号密码(当密码在js中加密时)
在某些网站,会判断我们是否有cookie来判断我们是否为爬虫,也可以使用session先请求url地址,再
当我们使用一个用户名密码爬取大量数据,也是会被服务器认为是爬虫,这就需要有多套用户名密码,发送请求随机用户名密码进行请求
相关文章:
2-requests模块(6节课学会爬虫)
2-requests模块(6节课学会爬虫) 1,安装requests2,发送get,post请求,获取响应3,response的方法方法一(Response.text)方法二(response.content.decode()&#…...

使用ECharts创建动态数据可视化图表
使用ECharts创建动态数据可视化图表 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在现代Web应用开发中,数据可视化是至关重要的一环。ECharts作…...

Nacos配置中心客户端源码分析(一): 客户端如何初始化配置
本文收录于专栏 Nacos 推荐阅读:Nacos 架构 & 原理 文章目录 前言一、NacosConfigBeanDefinitionRegistrar二、NacosPropertySourcePostProcessor三、AbstractNacosPropertySourceBuilder总结「AI生成」 前言 专栏前几篇文章主要讲了Nacos作为服务注册中心相关…...
gin数据解析,绑定和渲染
一. 数据解析和绑定 1.1 Json数据解析和绑定 html文件: <!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8"> <meta name"viewport" content"widthdevice-width, initial-scale1.0&quo…...
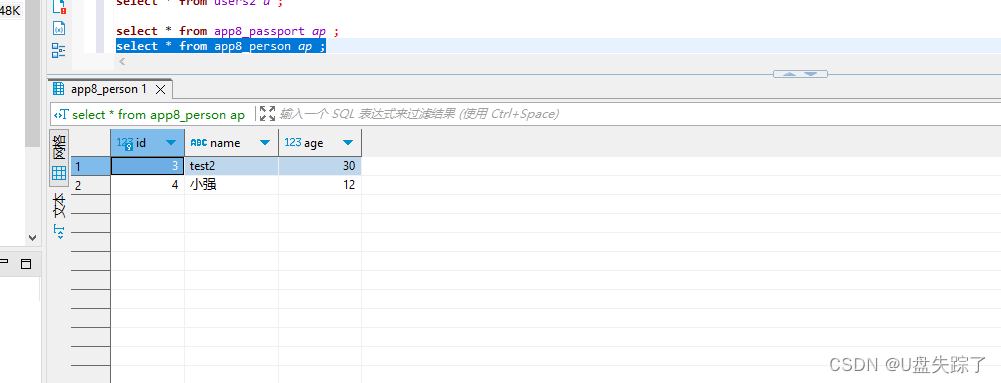
Django 对模型创建的两表插入数据
1,添加模型 Test/app8/models.py from django.db import modelsclass User(models.Model):username models.CharField(max_length50, uniqueTrue)email models.EmailField(uniqueTrue)password models.CharField(max_length128) # 使用哈希存储密码first_name …...

Lua: 轻量级多用途脚本语言
Lua 是一种高效而轻量级的脚本语言,具备强大的扩展性和灵活性,广泛应用于游戏开发、嵌入式系统、Web 应用等多个领域。本文将深入探讨 Lua 的特性、应用场景以及如何使用 Lua 进行开发。 1. Lua 的起源与发展 Lua 的发展始于上世纪90年代初,…...
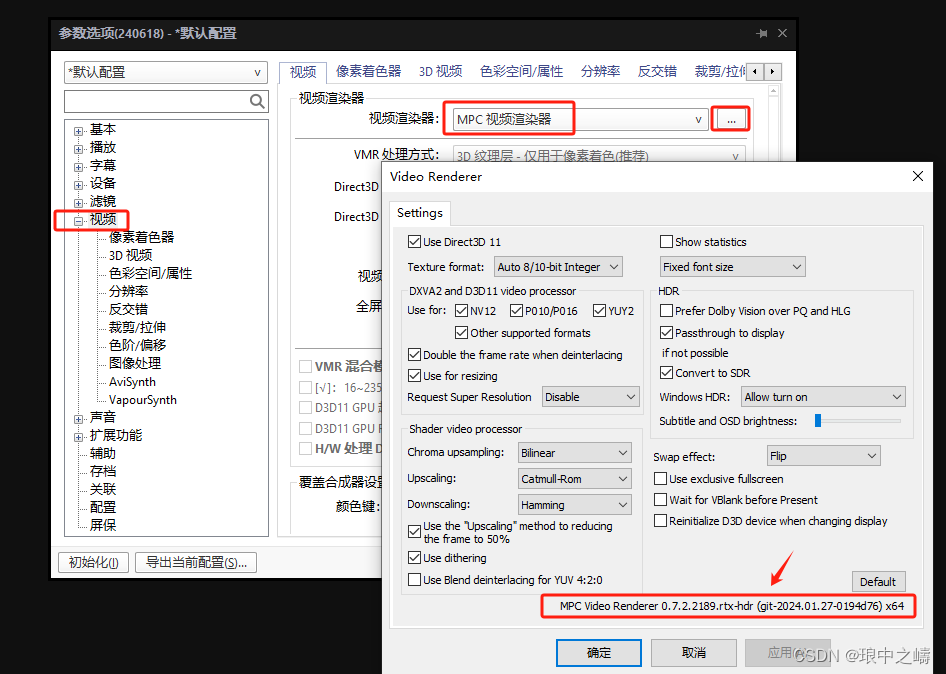
PotPlayer安装及高分辨率设置
第1步: 下载安装PotPlayer软件 PotPlayer链接:https://pan.baidu.com/s/1hW168dJrLBonUnpLI6F3qQ 提取码:z8xd 第2步: 下载插件,选择系统对应的位数进行运行,该文件不能删除,删除后将失效。 …...

实现写入缓存策略的最佳方法探讨
实现写入缓存策略的最佳方法探讨 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨在软件开发中实现写入缓存策略的最佳方法。缓存在提升应用性能和…...

【Day03】0基础微信小程序入门-学习笔记
文章目录 视图与逻辑学习目标页面导航1. 声明式导航2. 编程式导航3. 导航传参 页面事件1. 下拉刷新2. 上拉触底3.扩展-自定义编译模式 生命周期1. 简介2. 生命周期函数3. 应用的生命周期函数4. 页面生命周期函数 WXS脚本1. 概述2. 基础语法3. WXS的特点4. 使用WXS处理手机号 总…...
libctk shared library的设计及编码实践记录
一、引言 1.1 <libctk>的由来 1.2 <libctk>的设计理论依据 1.3 <libctk>的设计理念 二、<libctk>的依赖库 三、<libctk>的目录说明 四、<libctk>的功能模块及使用实例说明 4.1 日志模块 4.2 mysql client模块 4.3 ftp client模块 4…...

【代码随想录训练营】【Day 65】【图论-2】| 卡码 99
【代码随想录训练营】【Day 65】【图论-2】| 卡码 99 需强化知识点 深度搜索和广度搜索 题目 99. 岛屿数量 思想:遍历到为1的节点,再搜索标记,每遇到新的陆地节点,增加计数 深度搜索广度搜索:此处用 [] 作为待遍…...

【动态规划】139. 单词拆分
139. 单词拆分 难度:中等 力扣地址:https://leetcode.cn/problems/word-break/description/ 问题描述 给你一个字符串 s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。 注意:不要求字…...

【C++】空指针访问成员函数
空指针访问成员函数 C中空指针也是可以调用成员函数的,但是也要注意有没有用到this指针 如果用到this指针,需要加以判断保证代码的健壮性 class Animal { public:void fun1() {//正常的成员函数}void fun2() {if (this NULL) {return;//如果没有这个…...

Linux的IO易错点总结
本文主要记录IO的一些易错操作。 阻塞IO和非阻塞IO,一般都是针对数据读取的,因为write是主动行为,不存在阻塞这一说。 非阻塞式IO,一般都要配合while轮询来读取数据。 IO多路复用 当只检测一路IO的时候,和普通IO的作…...

【Android面试八股文】说一说你对Android中的Context的理解吧
文章目录 一、Context是什么?1.1 主要功能和用途1.2 如何获取 Context 实例?1.3 注意事项二、Context 类的层次结构三、Context的数量四、Context的注意事项五、Android 中有多少类型的 Context,它们有什么区别 ?六、Contextlmpl实例是什么时候生成的,在 Activity 的 oncr…...

AI在音乐创作中的角色:创造还是毁灭?
目录 一、基本情况介绍 二、近期新闻 三、AI生成音乐方面的商业模式 四、人工智能和音乐人可能的合作模式 五、人们如何借助AI来创作音乐 六、人工智能在创意产业引发的伦理道德问题 七、如何平衡技术发展与提高人类创造积极性的关系? 总结 一、基本情况介绍…...

[深入理解DDR] 总目录
依公知及经验整理,原创保护,禁止转载。 专栏 《深入理解DDR》 蓝色的是传送门,点击链接即可到达指定文章。 图。 DDR 分类 导论 [RAM] DRAM 导论:DDR4 | DDR5 | LPDDR5 | GDRR6 | HBM 应运而生 运存与内存?内存与存…...
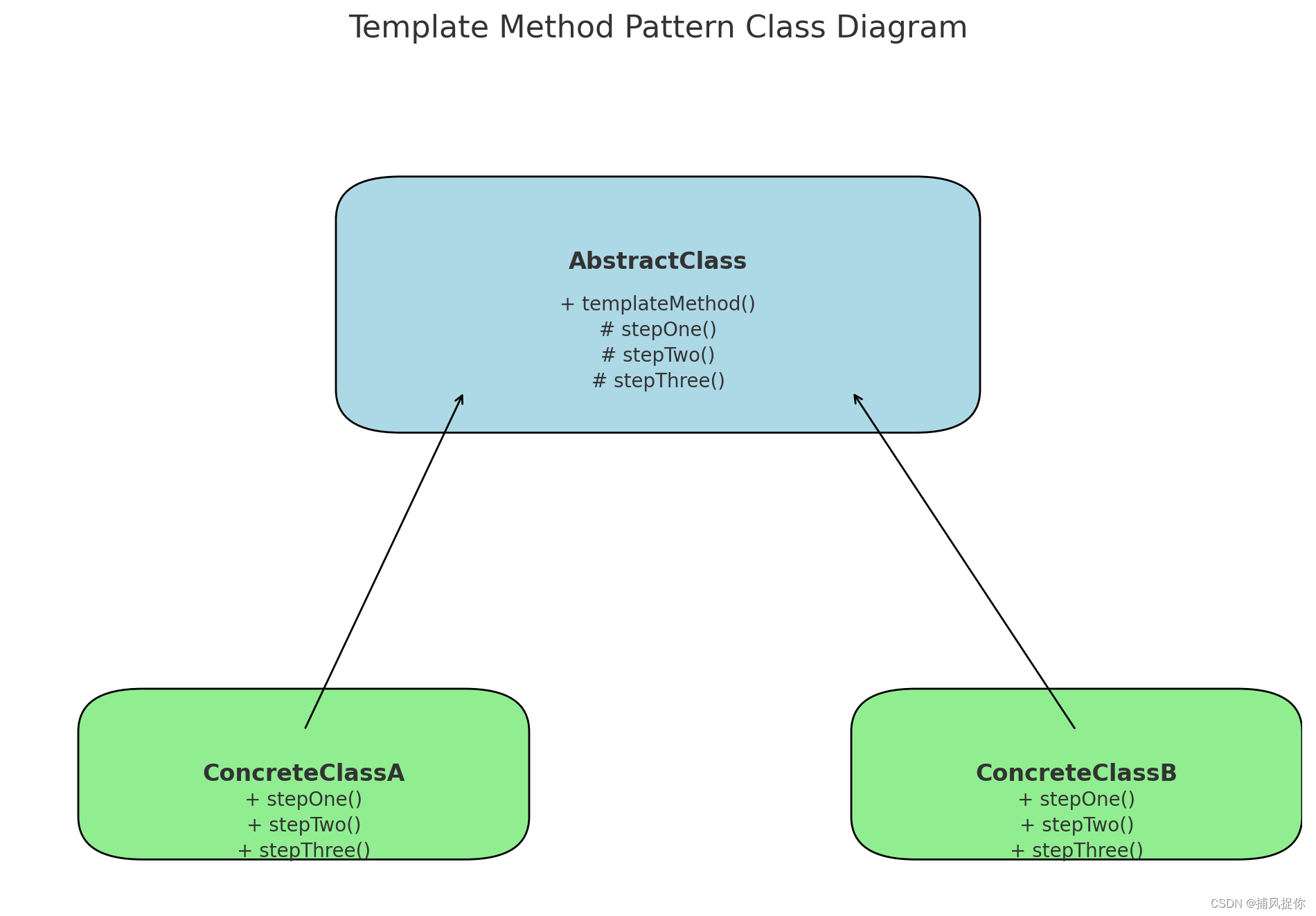
模板方法模式在金融业务中的应用及其框架实现
引言 模板方法模式(Template Method Pattern)是一种行为设计模式,它在一个方法中定义一个算法的框架,而将一些步骤的实现延迟到子类中。模板方法允许子类在不改变算法结构的情况下重新定义算法的某些步骤。在金融业务中ÿ…...

leetcode347.前k个高频元素
leetcode347.前k个高频元素 给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。 示例 1: 输入: nums [1,1,1,2,2,3], k 2 输出: [1,2] 示例 2: 输入: nums [1], k 1 输出: [1] 优先队列法 struct hash_…...

c++(二)
1. 类和对象 1.1. 封装 封装的意义 将属性和行为作为一个整体,表现生活中的事物;将属性和行为加以权限控制 public -> 公共权限:类内可以访问,类外也可以访问protected -> 保护权限:类内可以访问,…...

面向高校的基于算法的发明专利申请写作方法
发明专利作为国家和高校认可的成果形式之一,其申请和授权一直受到教师和学生们的高度重视;基于算法的发明专利作为发明专利的重要分支,每年都有大量的算法专利被授权或者拒绝。虽然高校的教师对论文写作非常熟悉,但是发明专利的写…...

轨道交通条形屏电源技术分析:超薄化与高可靠性的工程平衡
一、行业背景与技术挑战在智慧城轨建设中,地铁站内条形屏是乘客信息显示系统的核心终端设备。该应用场景对配套电源提出以下技术要求:技术需求具体指标工程挑战超薄化整机厚度3-8mm传统变压器/散热器高度难以压缩高可靠性MTBF≥50000小时轨道交通振动、温…...

提供充电桩运维托管的服务商:选择标准与服务内容解析
一、引言据中国电动汽车充电基础设施促进联盟(EVCIPA)数据显示,截截至2026年2月底,我国电动汽车充电基础设施(枪)总数达到2101.0万个,同比增长47.8%。其中,公共充电设施(…...
工作流使用攻略 操作指南(2026最新版))
Coze(扣子)工作流使用攻略 操作指南(2026最新版)
Coze工作流(Workflow)是实现复杂AI任务的核心工具,它通过可视化拖拽节点的方式,将大模型、插件、代码、数据库等组件组合成自动化流程。适合处理多步骤、结构化任务(如内容生成、数据分析、图像处理、客服流程等&#…...

终极指南:3分钟掌握Mouse Jiggler鼠标模拟器完整使用方法
终极指南:3分钟掌握Mouse Jiggler鼠标模拟器完整使用方法 【免费下载链接】mousejiggler Mouse Jiggler is a very simple piece of software whose sole function is to "fake" mouse input to Windows, and jiggle the mouse pointer back and forth. …...

InfluxDB实战:数据备份恢复的进阶策略与生产环境避坑指南
1. InfluxDB备份恢复的核心概念 第一次接触InfluxDB备份时,我也被各种术语搞得晕头转向。后来在实际项目中踩过几次坑才明白,InfluxDB的备份主要分为两类:元数据备份和数据库数据备份。元数据就像是你手机的通讯录,记录着所有用户…...

rt-thread源码探秘:rt_components_board_init的自动初始化机制剖析
1. 从零理解RT-Thread的自动初始化机制 第一次接触RT-Thread的开发者往往会对它的模块化初始化方式感到惊艳——只需要在设备驱动代码末尾加个INIT_BOARD_EXPORT宏,系统启动时就会自动执行初始化函数。这背后到底藏着什么魔法?今天我们就来揭开rt_compon…...

UTF8-CPP跨版本兼容性指南:从C++98到C++20的完整支持
UTF8-CPP跨版本兼容性指南:从C98到C20的完整支持 【免费下载链接】utfcpp UTF-8 with C in a Portable Way 项目地址: https://gitcode.com/gh_mirrors/ut/utfcpp UTF8-CPP是一个轻量级的C库,专注于以可移植的方式提供UTF-8编码和解码功能&#x…...
)
YOLOv8无人机识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 针对低空无人机(drone)的检测需求,本文基于YOLOv8目标检测算法构建了一个无人机识别系统。实验采用自建无人机数据集,包含训练集1012张图像、验证集347张图像,类别为单一目标“drone”。模型训练过程中ÿ…...

AI养老服务兴起:代写回忆录爆火,技术短板与市场乱象待解?
AI正在替人尽孝五六年前,采访北京一家智慧养老院,其为每个房间配智能音箱,用AI陪老人聊天等。今年回访,智能陪伴设备已停用。2023年新技术催生新AI养老服务,如2024年下半年AI代写回忆录风潮,从业者能月入过…...