LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
论文链接:http://arxiv.org/abs/2406.03459
代码链接:https://github.com/Atten4Vis/LW-DETR
一、摘要
介绍了一种轻量级检测变换器LWDETR,它在实时物体检测方面超越了YOLO系列。LWDETR的架构简单,由ViT编码器、投射器和浅层DETR解码器堆叠而成。该方法利用了如有效的训练技巧(如改进的损失函数和预训练)、以及交叉的窗口和全局注意力,以降低ViT编码器的复杂性。通过聚合多级特征图以及ViT编码器中的中间和最终特征图,形成了更丰富的特征图,从而改进了ViT编码器。同时,引入了窗口优先的特征图组织方式,以提高交叉注意力计算的效率。实验结果表明,该方法在COCO和其他基准数据集上,相对于现有的实时检测器(如YOLO及其变种)具有显著优势。

文章目录
- LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
- 一、摘要
- 二、创新点
- 三、原理
- 1、Architecture
- 2、Instantiation
- 3、Effective Training
- 4、Efficient Inference
- 5、Empirical Study
- 四、实验
- 1、Settings
- 2、Results
- 3、Discussions
- 4、Experiments on more datasets
- 五、总结
二、创新点
-
构建了一个轻量级DETR方法,用于实时物体检测。一个普通的ViT编码器[17],通过卷积投影器与DETR解码器相连。提出聚合多级特征图,包括编码器中的中间和最终特征图,形成更强的编码特征图。
-
使用了高效的推理技术。采用了交错窗口和全局注意力[36,37],在普通的ViT编码器中替换一些全局注意力,以减少复杂性。通过窗口优先的特征图组织方法实现交错注意力的高效实现,有效地减少了昂贵的内存重排操作。
三、原理
1、Architecture
LW-DETR 由一个ViT编码器(Vision Transformer Encoder)、一个投影器(Projector)和一个DETR解码器(DETR Decoder)组成。
Encoder 采用ViT [17] 作为检测编码器。原始的ViT包含一个分块层和Transformer编码层。Transformer编码层在最初的ViT中包含一个对所有token(patch)的全局自注意力层和一个FFN层。全局自注意力计算成本较高,其时间复杂度与token(patch)数量的平方成正比。通过使用窗口自注意力来降低计算复杂度(详细内容见4)。作者提出将多级特征图、编码器中间层和最终特征图进行聚合,形成更强的编码特征图。编码器的一个例子如图2所示。

Decoder 解码器是一个堆叠的Transformer解码层。每个层包含一个自我注意力、一个交叉注意力和一个FFN(前向传播神经网络)。为了提高计算效率,采用了可变形的交叉注意力 [74]。DETR及其变体通常采用6个解码层。论文实现使用了3个Transformer解码层。这使得时间从1.4毫秒减少到0.7毫秒,相对于所提方法中Tiny版本的其余部分(1.3毫秒)来说,这是一个显著的减少。
采用混合查询选择策略 [67]来形成对象查询,它是内容查询和空间查询的组合。内容查询是可学习的嵌入,类似于DETR。空间查询基于两阶段方法:首先从Projector的最后一层中选择前K个特征,然后预测边界框,并将相应的框转换为嵌入作为空间查询。
Projector 使用投影器连接编码器和解码器。投影器以编码器的聚合特征图作为输入。投影器是一个C2f块(密集连接网络(DenseNet)的跨阶段部分扩展[26,60]),在YOLOv8 [29]中实现。
在构建LW-DETR的large和xlarge版本时,修改了投影器Projector,使其输出两种尺度( 1 8 \frac{1}{8} 81 和 1 32 \frac{1}{32} 321 )的特征图,并相应地使用多尺度解码器[74]。投影器包含两个并行的C2f块。一个处理通过反卷积上采样的 1 8 \frac{1}{8} 81 尺度特征图,另一个处理通过步长卷积下采样的 1 32 \frac{1}{32} 321尺度特征图。图3展示了单尺度投影器和多尺度投影器的pipeline。

Objective function 采用了一种IoU感知分类(Intersection over Union-aware classification)损失,即IA-BCE损失[3]:
L c l s = ∑ i = 1 N p o s B C E ( s i , t i ) + ∑ j = 1 N n e g s j 2 B C E ( s j , 0 ) , ( 1 ) L_{cls} = \sum^{N_{pos}}_{i=1} BCE(s_{i}, t_{i}) + \sum^{N_{neg}}_{j=1} s^{2}_{j} BCE(s_{j}, 0), \ (1) Lcls=i=1∑NposBCE(si,ti)+j=1∑Nnegsj2BCE(sj,0), (1)
其中, N p o s N_{pos} Npos 和 N n e g N_{neg} Nneg 分别表示正样本和负样本的数量。 s s s是预测的分类得分, t t t是吸收了IoU得分 u u u(与真实值)的目标得分: t = s α u 1 − α t = s^{\alpha}u^{1−\alpha} t=sαu1−α,其中$\alpha$实际上被设置为0.25(参见Cai等人2023年的工作[3])。
整体损失是分类损失和与DETR框架(如[4,67,74]中相同的)相结合的边界框损失,其公式如下:
L c l s + λ i o u L i o u + λ L 1 L 1 。 ( 2 ) L_{cls} + \lambda_{iou} L_{iou} + \lambda_{L_{1}}L_{1}。 \ (2) Lcls+λiouLiou+λL1L1。 (2)
其中, λ i o u \lambda_{iou} λiou 和 λ L 1 \lambda_{L_{1}} λL1 被设置为 2.0 和 5.0,这与[4, 67, 74]中的做法相似。 L i o u L_{iou} Liou 和 L 1 L_{1} L1 分别是广义IoU(GIoU)损失[52] 和用于边界框回归的L1损失
2、Instantiation
文中实例化了5个实时检测器:tiny、small、medium、large和xlarge。详细的设置见表2。

tiny检测器包含一个6层的transformer编码器。每层由多头自注意力模块和前馈网络(FFN)组成。每个图像块被线性映射到一个 192 192 192维的表征向量。投影器输出单尺度特征图,具有 256 256 256个通道。解码器有 100 100 100个对象查询。
small检测器包含 10 10 10层编码器, 300 300 300个对象查询。与tiny检测器相同,输入图像块的表征维度和投影器输出为 192 192 192和 256 256 256。medium检测器与small类似,区别在于输入图像块的表征维度提升到 384 384 384,因此编码器的维度也相应调整为 384 384 384。
large检测器由 10 10 10层编码器组成,并使用两尺度特征图(参见第1部分的投影器)。输入图像块的表征维度和投影器输出为 384 384 384和 384 384 384。xlarge检测器与large类似,区别在于输入图像块的表征维度提升到 768 768 768。
3、Effective Training
More supervision. 为了加速DETR的训练,已经发展出多种技术,例如 [6, 27, 75]。采用了易于实施且不影响推理过程的Group DETR [6]。按照[6]的做法,使用了13个并行的权重共享解码器进行训练。对于每个解码器,从投射器的输出特征中为每个组生成对象查询。同样遵循[6],使用主解码器进行推理。
Pretraining on Objects365. 预训练过程分为两阶段。首先,基于预训练模型,使用MIM方法CAEv2 [71] 在Objects365数据集上预训练ViT,这使得在COCO上的mAP提高了0.7。其次,按照[7, 67]的做法,重新训练编码器,并在Objects365上监督地训练投影器和解码器。
4、Efficient Inference
采用了交错的窗口和全局注意力:将一些全局自注意力层替换为窗口自注意力层。例如,在一个6层的ViT中,第一、第三和第五层使用窗口注意力。窗口注意力通过将特征图划分为不重叠的窗口,并分别在每个窗口上执行自注意力来实现。
采用了一种窗口优先的特征图组织(window-major feature map organization)策略,以实现高效的交错注意力。这种组织方式按窗口方式排列特征图。ViTDet实现[36]中,特征图按行(row-major organization)排列,为了转换为窗口优先的组织,需要昂贵的’permutation’操作。论文实现去除了这些操作,从而减少了模型延迟。通过一个简单的示例来说明窗口优先的方式。给定一个 4 × 4 4 \times 4 4×4的特征图:
[ f 11 f 12 f 13 f 14 f 21 f 22 f 23 f 24 f 31 f 32 f 33 f 34 f 41 f 42 f 43 f 44 ( 3 ) ] [f_{11} \ f_{12} \ f_{13} \ f_{14} \\ f_{21} \ f_{22} \ f_{23} \ f_{24} \\ f_{31} \ f_{32} \ f_{33} \ f_{34} \\ f_{41} \ f_{42} \ f_{43} \ f_{44} \ (3) ] [f11 f12 f13 f14f21 f22 f23 f24f31 f32 f33 f34f41 f42 f43 f44 (3)]
对于大小为 2 × 2 2 \times 2 2×2的窗口,其窗口主导向组织如下:
f 11 , f 12 , f 21 , f 22 ; f 13 , f 14 , f 23 , f 24 ; f 31 , f 32 , f 41 , f 42 ; f 33 , f 34 , f 43 , f 44 . ( 4 ) f_{11}, f_{12}, f_{21}, f_{22}; f_{13}, f_{14}, f_{23}, f_{24}; \\ f_{31}, f_{32}, f_{41}, f_{42}; f_{33}, f_{34}, f_{43}, f_{44}. \ (4) f11,f12,f21,f22;f13,f14,f23,f24;f31,f32,f41,f42;f33,f34,f43,f44. (4)
这种组织方式适用于不重新排列特征的窗口注意力和全局注意力。行主序组织
f 11 , f 12 , f 13 , f 14 ; f 21 , f 22 , f 23 , f 24 ; f 31 , f 32 , f 33 , f 34 ; f 41 , f 42 , f 43 , f 44 , ( 5 ) f_{11}, f_{12}, f_{13}, f_{14}; f_{21}, f_{22}, f_{23}, f_{24}; \\ f_{31}, f_{32}, f_{33}, f_{34}; f_{41}, f_{42}, f_{43}, f_{44}, \ (5) f11,f12,f13,f14;f21,f22,f23,f24;f31,f32,f33,f34;f41,f42,f43,f44, (5)
对于全局感知是合适的,但为了实现窗口注意力,它需要进行昂贵的permutation操作。
5、Empirical Study
实证展示了训练技巧和高效推理技术如何提升DETR的性能。以small检测器为例进行研究。本研究基于一个初始检测器:编码器采用所有层的全局注意力,并输出最后一层的特征图。实验结果见表2。
Latency improvements. ViTDet采用的交错窗口和全局注意力,将计算复杂度从23.0GFlops降低到16.6 GFlops,验证了用更快捷的窗口注意力替换昂贵的全局注意力的益处。然而,延迟并未减少,反而增加了0.2 ms。这是因为行优先特征图组织需要额外昂贵的(permutation)操作。采用列优先特征图组织(window-major)可以缓解这一副作用,导致更大的延迟降低,从3.7 ms降至2.9 ms。
Performance improvements.多级特征聚合带来了0.7的mAP提升。IoU感知的分类损失和更多的监督将mAP分数从34.7提升到35.4和38.4。对边界框回归目标的重新参数化(参考 [40],详情见附录)略有性能提升。预训练在Objects365上的显著改进达到8.7的mAP,表明transformer确实从大数据中获益。更长的训练周期可以带来进一步的提升,形成了LW-DETR-small模型。
四、实验
1、Settings
Datasets. 预训练数据集为Objects365 [54]。遵循[7,67]的做法,将train集的图像与validate集(除前5000张图像外)的图像合并进行检测预训练。使用微软COCO2017的标准数据划分策略[39],并在COCO val2017上进行评估。
Data augmentations. 采用DETR及其变体 [4, 74]中的数据增强方法。遵循实时检测算法 [1, 29, 46],在训练时随机将图像调整为正方形。为了评估性能和推理时间,按照实时检测算法 [1, 29, 46]的评估方案,将图像调整为 640 × 640 640 \times 640 640×640像素。使用 10 × 10 10 \times 10 10×10的窗口大小,以确保图像大小可以被窗口大小整除。
Implementation details. 在Objects365 [54]上预训练检测模型30个轮次(epoch),然后在COCO [39]上进行总共 180 , 000 180,000 180,000次迭代的微调。采用指数移动平均(EMA)技术 [55],衰减率为0.9997。实验使用AdamW优化器 [44]进行训练。
预训练时,投影器和DETR解码器的初始学习率为 4 × e − 4 4 \times e^{−4} 4×e−4,ViT主干网络的初始学习率为 6 × e − 4 6 \times e^{−4} 6×e−4,批次大小为128。在微调阶段,投影器和DETR解码器的初始学习率为 1 × e − 4 1 × e^{−4} 1×e−4,ViT主干网络的初始学习率为 1.5 × e − 4 1.5 ×e^{−4} 1.5×e−4。tiny、small和medium模型的批次大小设置为32,large和xlarge模型的批次大小设置为16。对于180,000次迭代,tiny、small和medium模型为50个轮次,large和xlarge模型为25个轮次。更多细节,如权重衰减、ViT编码器的层别衰减以及微调过程中的组件衰减(component-wise decay)[7],请参阅补充材料。
以fp16精度和1个批次在COCO val2017上,使用T4 GPU进行端到端的平均推理延迟测量,环境设置为TensorRT-8.6.1、CUDA-11.6和CuDNN-8.7.0。采用TensorRT中的efficientNMSPlugin实现高效的NMS。所有实时检测器的性能和端到端延迟都在官方实现中进行测量。
2、Results

五个LW-DETR模型的结果在表3中报告。LW-DETR-tiny 在T4 GPU上以500 FPS的速度实现了42.6的mAP。LW-DETR-small 和LW-DETR- medium 分别达到48.0 mAP,速度超过340 FPS,以及52.5 mAP,速度超过178 FPS。large 和xlarge 模型分别以113 FPS的速度达到56.1 mAP,以及58.3 mAP,速度为52 FPS。
Comparisons with state-of-the-art real-time detectors.
表3报告了LW-DETR模型与代表性的实时检测器(包括YOLO-NAS [1]、YOLOv8 [29]和RTMDet[46])的比较。可以看到,无论是否使用预训练,LW-DETR都持续优于先前的实时检测器最先进的性能。
LW-DETR在tiny到xlarge五个尺度上,无论是延迟还是检测性能,都明显优于YOLOv8和RTMDet。
与先前最佳方法之一YOLO-NAS(通过神经架构搜索获得)相比,LW-DETR模型在small和medium尺度上分别提高了0.4 mAP和0.9 mAP,速度分别快1.6倍和约1.4倍。随着模型规模增大,改进更为显著:在large尺度上以相同速度运行时,LW-DETR的mAP提高了3.8。
进一步通过精细调整NMS过程中的分类得分阈值,提高了其他方法的表现,并在右两列报告了结果。这些方法的性能大幅提高,但仍低于LW-DETR。所提方法可能从先前实时检测器采用的改进中受益,如神经架构搜索(NAS)、数据增强、伪标签数据和知识蒸馏[1,29,46]。
Comparison with concurrent works.
将LW-DETR与实时检测中的同期工作进行比较,包括YOLO-MS [12], Gold-YOLO [58], RT-DETR [45], 和YOLOv10 [57]。YOLO-MS通过增强多尺度特征表征来提高性能。(multi-scale feature representation)Gold-YOLO通过增强多尺度特征融合,并应用MAE风格的预训练[22],以提升YOLO的性能。YOLOv10设计了几个兼
顾效率和精度的模块来提升性能。(efficiency-driven modules)
RT-DETR [45],与LW-DETR密切相关,也是基于DETR框架,但在主干(backbone)、投影器(projector)、解码器(decoder)和训练方案上与所提方法有许多不同。


比较结果见表4 和图4。LW-DETR在检测性能和延迟之间始终实现更好的平衡。YOLO-MS和Gold-YOLO在所有模型规模上都明显表现出比LW-DETR较差的结果。(worse results)LW-DETR-large 比相关性高的RT-DETR-R50在mAP上高出0.8,速度更快(8.8 ms vs. 9.9 ms)。其他规模的LW-DETR也表现出优于RT-DETR的结果。与最新工作YOLOv10-X [57]相比,LW-DETR-large 在性能上更高(56.1 mAP vs. 54.4mAP),延迟更低(8.8 ms vs. 10.70 ms)。
3、Discussions
NMS post-processing. DETR 方法是一种端到端的算法,不需要NMS后处理步骤。相比之下,现有的实时检测器,如 YOLO-NAS [1]、YOLOv8[29] 和 RTMDet [46],需要NMS [24]后处理。NMS过程会消耗额外的时间。在测量端到端推理成本时,包括了这个额外时间,这在实际应用中是需要考虑的。
作者对使用NMS的方法进行了进一步优化,通过调整NMS后处理的分类得分阈值。实验观察到,YOLO-NAS、YOLOv8和RTMDet的默认得分阈值(0.001)虽然能获得较高的mAP,但会产生大量框,从而导致较高的延迟。特别是当模型较小时,端到端延迟主要由NMS延迟主导。调整了阈值,以在mAP分数和延迟之间取得良好的平衡。实验发现,mAP分数略有下降(例如,-0.1 mAP到-0.5 mAP),而运行时间大幅减少,例如,减少了约4-5ms,对于RTMDet和YOLOv8,减少了1-2ms(YOLO-NAS的延迟)。这些减少来自于调整得分阈值后,输入NMS的预测框数量减少。不同得分阈值下的详细结果,以及COCO val2017上剩余框数的分布,见补充材料。
图1展示了与其他方法(经过良好调优的NMS流程)的比较。带有NMS的方法有所提升,但所提方法仍然优于其他方法。排名第二的YOLO-NAS是一种网络架构搜索算法,其性能非常接近实验的基线。作者认为,像YOLO-NAS中使用的复杂网络架构搜索过程可能对DETR方法有利,预计未来还有进一步的改进空间。

Pretraining. 实验性地研究了预训练的效果。如表5所示,预训练对所提方法带来了显著的改进,平均提高了5.5个mAP。tiny模型的mAP提高了6.1,而xlarge模型的mAP提高了5.3。这表明在大型数据集上对DETR类模型的预训练非常有益。
实验表明,训练过程适用于使用卷积编码器的DETR方法。用ResNet-18和ResNet-50替换transformer编码器。从表5中可以看出,这些LW-DETR变体在延迟和mAP方面的性能接近使用transformer编码器的LW-DETR,而且预训练带来的好处与transformer编码器的LW-DETR相似,但略低一些。

同时,作者研究了预训练对非端到端检测器的改进。根据表3, 4和6的结果,似乎在Objects365上预训练仅对非端到端检测器(如 [12, 29, 46, 58])显示出有限的提升,这与DETR基检测器中预训练带来的大幅改进不同。由于非端到端检测器可能训练300个甚至500个epoch,这种有限的提升是否与训练轮次有关?表6显示,随着训练轮次的增加,提升逐渐减小,这部分支持了上述假设。
4、Experiments on more datasets
实验检验了LW-DETR模型在更多检测数据集上的泛化能力。采用了两种评估方法,即跨域评估和多域微调。对于跨域评估,实验直接在COCO数据集上训练的实时检测器上评估在Unidentified Video Objects(UVO) [61]上的性能。在多域微调部分,使用预训练的实时检测器在多域检测数据集Roboflow 100 (RF100) [13]上进行微调。实验在每个数据集上对所有模型的超参数进行了粗略搜索,例如学习率。更多详细信息请参阅附录材料。
Cross-domain evaluation. 评估模型泛化能力的一种方法是直接在不同领域数据集上进行评估。实验采用了类agnostic的物体检测基准UVO [61],其中57%的物体实例不属于COCO的80个类别。UVO基于YouTube视频,其外观与COCO有很大差异,例如,有些视频是第一人称视角且存在显著的运动模糊。实验使用COCO(参见表3)训练的模型在UVO的验证集上进行评估。

表7给出了结果。LW-DETR在实时检测器中的表现优于当前最先进的方法。具体来说,LW-DETR-small在mAP上比RTMDet-s、YOLOv8-s和YOLO-NAS-s中的最佳结果高出1.3,而在AR上高出4.1。在召回率方面,它也显示出更强的检测不同尺度(小、中、大)物体的能力。上述发现表明,LW-DETR相对于先前的实时检测器的优势并非源于对COCO的特定调优,而是得益于其生成更通用模型的能力。
Multi-domain finetuning. 另一种方法是在不同领域的小型数据集上微调预训练的检测器。RF100包含100个小型数据集,7个图像领域,224,000张图像和829个类别标签。它可以帮助研究人员用现实生活中的数据测试模型的泛化能力。实验在RF100的每个小型数据集上微调实时检测器。

结果见表8。LW-DETR-small在不同领域表现出优于当前最先进的实时检测器的优势。特别是在’documents’和’electromagnetic’,LW-DETR明显优于YOLOv5、YOLOv7、RTMDet和YOLOv8(比这四个中最好的高出5.7AP和5.6 AP)。LW-DETR-medium 在整体上提供了进一步的改进。这些发现突出了LW-DETR的通用性,使其在一系列封闭领域任务中成为强大的基线。
五、总结
该方法利用了如有效的训练技巧(如改进的损失函数和预训练)、以及交叉的窗口和全局注意力,以降低ViT编码器的复杂性。引入聚合多级特征图和窗口优先的特征图组织方式。
相关文章:
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection
LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection 论文链接:http://arxiv.org/abs/2406.03459 代码链接:https://github.com/Atten4Vis/LW-DETR 一、摘要 介绍了一种轻量级检测变换器LWDETR,它在实时物体检测方面超越…...

前端技术(二)——javasctipt 介绍
一、javascript基础 1. javascript简介 ⑴ javascript的起源 ⑵ javascript 简史 ⑶ javascript发展的时间线 ⑷ javascript的实现 ⑸ js第一个代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>…...
FireFox 编译指南2024 Windows10篇-环境准备(一)
1. 引言 在开源浏览器项目中,Firefox因其高性能和灵活性而备受开发者青睐。为了在本地环境中编译和定制Firefox,开发者需要做好充分的环境准备工作。这不仅是编译成功的基础,也是后续调试、优化和二次开发的关键步骤。 编译Firefox是一个复…...

Spring Boot中的热部署配置
Spring Boot中的热部署配置 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将探讨如何在Spring Boot项目中实现热部署配置,提升开发效率和项…...

用ChatGPT快速打造一个专业WordPress网站
作为一个使用HostEase多年的老用户,我想和大家分享一下如何利用HostEase和ChatGPT快速构建一个WordPress网站的经验。这不仅仅是一个简单的操作步骤,更是一次从零到有的实战经历。希望我的分享能给你们带来一些实用的帮助。 获取主机服务和域名 首先&a…...

dsp入门
安装环境 安装 ccs5.5安装 BIOS-MCSDK 多核软件开发包安装 仿真器驱动 工程创建与导入工程 创建工程 创建工程填信息添加.cmd文件,配置内存编译 导入工程 导入 配置工程 选择properties 环境变量 头文件 库文件 仿真器 添加仿真器 先调出仿真器界面创建仿…...

Java并发编程-Atomiclnteger、LongAdder等原子类的使用及案例实战
文章目录 i++和Atomiclnteger之间的差别分析以及使用介绍i++AtomicInteger使用介绍i++ 示例AtomicInteger 示例总结Atomiclnteger中的CAS无锁化原理和思路介绍CAS 原理AtomicInteger 的 CAS 应用无锁化思路Atomiclnteger源码剖析:仅限JDK内部使用的Unsafe类`Unsafe` 类的关键作…...
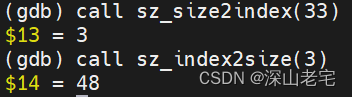
九浅一深Jemalloc5.3.0 -- ②浅*size class
目前市面上有不少分析Jemalloc老版本的博文,但5.3.0却少之又少。而且5.3.0的架构与之前的版本也有较大不同,本着“与时俱进”、“由浅入深”的宗旨,我将逐步分析Jemalloc5.3.0的实现。 另外,单讲实现代码是极其枯燥的,…...

JavaScript——属性的增删改查
目录 任务描述 相关知识 属性的获取 方式一 方式二 属性的修改与新增 删除属性 编程要求 任务描述 Luma Restaurant 以前的财务人员在统计销售额的时候不小心把数据弄错了,现在的财务人员想通过一个 JavaScript 函数方便的修改数据,并署上自己的…...

51单片机第15步_串口多机通讯使用CRC8校验
本章重点介绍串口多机通讯使用CRC8校验。 数据格式:"$123xxxx*crc8\r\n"; 如:"$1234567890ABCDEF*06\r\n" 如:"$1231234567890*31\r\n" crc8是CRC校验值,为十六进制的ASCII码,不包含$和校验值前面的那个* #include <REG51.h> //包含…...

WPF----进度条ProgressBar(渐变色)
ProgressBar 是一种用于指示进程或任务的进度的控件,通常在图形用户界面(GUI)中使用。它提供了一种视觉反馈,显示任务的完成程度,帮助用户了解任务的进展情况。 基本特性 Minimum 和 Maximum 属性: 这些属…...
)
Apipost接口测试工具的原理及应用详解(四)
本系列文章简介: 随着软件行业的快速发展,API(应用程序编程接口)作为不同软件组件之间通信的桥梁,其重要性日益凸显。API的质量直接关系到软件系统的稳定性、性能和用户体验。因此,对API进行严格的测试成为…...

【图论】200. 岛屿问题
200. 岛屿问题 难度:中等 力扣地址:https://leetcode.cn/studyplan/top-100-liked/ 问题描述 给你一个由 1(陆地)和 0(水)组成的的二维网格,请你计算网格中岛屿的数量。 岛屿总是被水包围&…...

AI学习指南机器学习篇-随机森林的优缺点
AI学习指南机器学习篇-随机森林的优缺点 引言 机器学习是人工智能领域的重要分支,其中随机森林(Random Forest)算法以其高性能和广泛应用而备受瞩目。然而,就像任何其他算法一样,随机森林也有其优缺点。本文将深入探讨随机森林算法的优势和…...
)
基于boost::beast的http服务器(上)
文章目录 1.beast网落库介绍2.相关类及api3.异步读写的处理3.1异步写案例3.2异步读案例 1.beast网落库介绍 Beast网络库是一个基于Boost库的C网络库,特别用于开发高性能的网络应用程序。它提供了一组易于使用的API,主要用于处理HTTP和WebSocket协议&…...
)
深度学习之近端策略优化(Proximal Policy Optimization,PPO)
PPO(Proximal Policy Optimization,近端策略优化)是深度强化学习中的一种算法,属于策略梯度方法中的一种。PPO通过优化策略来最大化累积奖励,具有稳定性好、易于调参等优点,是目前广泛应用的一种深度强化学习算法。下面介绍PPO的基本原理和流程。 PPO基本原理 PPO算法的…...

用pycharm进行python爬虫的步骤
使用 pycharm 进行 python 爬虫的步骤:下载并安装 pycharm。创建一个新项目。安装 requests 和 beautifulsoup 库。编写爬虫脚本,包括获取页面内容、解析 html 和提取数据的代码。运行爬虫脚本。保存和处理提取到的数据。 用 PyCharm 进行 Python 爬虫的…...

重写功能 rewrite
Nginx服务器利用 ngx_http_rewrite_module 模块解析和处理rewrite请求,此功能依靠 PCRE(perl compatible regular expression),因此编译之前要安装PCRE库,rewrite是nginx服务器的重要功能之 一,用于实现URL的重写,URL的…...

ISO19110操作要求类中/req/operation/operation-attributes的详细解释
/req/operation/operation-attributes 要求: 只有要素属性(feature attributes)可以通过‘observesValueOf’、‘triggeredByValuesOf’或‘affectsValuesOf’关联角色与要素操作(feature operations)关联。 具体解释 定义 要…...

访客(UV)、点击量(PV)、IP、访问量(VV)概念
1、https://www.cnblogs.com/QingPingZm/articles/13855808.htmlhttps://www.cnblogs.com/QingPingZm/articles/13855808.html...

Arm架构在中国市场的潜力与挑战:从技术选型到实践落地
1. 项目概述:从一次技术选型引发的深度思考最近在为一个边缘计算项目做硬件选型,团队里关于采用x86还是Arm架构的服务器争论了好几天。这让我想起,这几年在国内的云计算、数据中心、甚至个人消费电子领域,Arm架构的声音是越来越响…...

面试鸭:一站式面试题库解决方案,助你轻松备战技术面试
面试鸭:一站式面试题库解决方案,助你轻松备战技术面试 【免费下载链接】mianshiya-public 持续维护的企业面试题库网站,帮你拿到满意 offer!⭐️ 2026年最新Java面试题、前端面试题、AI大模型面试题、AI Agent面试题、RAG面试题、…...

面试官最爱问的iOS底层三剑客:RunLoop、KVO、Runtime实战避坑指南
面试官最爱问的iOS底层三剑客:RunLoop、KVO、Runtime实战避坑指南 在iOS开发的中高级面试中,RunLoop、KVO和Runtime这三个底层机制几乎成为必考题。但很多开发者仅仅停留在概念背诵层面,当面试官深入追问实现原理或实战场景时往往语塞。本文将…...

TinyGPT-V 和 MiniGPT-4 在架构设计上的主要区别
MiniGPT-4 是“大 LLM 冻结视觉编码器 单层线性投影”的经典桥接式 MLLM;TinyGPT-V 是“小 LLM 视觉模块 更复杂 mapping / norm / LoRA 训练策略”的轻量化 sVLM。1. 总体架构对比对比项MiniGPT-4TinyGPT-V设计目标验证强 LLM 接入视觉后可涌现 GPT-4V 类多模态…...

网络安全新态势与应对策略
网络安全新态势与应对策略 在数字化浪潮席卷全球的今天,网络空间已成为国家竞争的新战场、经济发展的新引擎和社会生活的新空间。然而,伴随技术飞速发展的,是日益严峻和复杂的网络安全挑战。传统的边界防御模式在AI驱动的自动化攻击、无孔不…...
)
Zynq MPSoC实战:从官方Base TRD里,只抠出HDMI输入+DP显示这一个功能(Vivado 2020.1 + Petalinux)
Zynq MPSoC实战:精准剥离HDMI输入与DP显示功能的工程精简指南 面对Xilinx官方提供的Base TRD参考设计,许多开发者都会被其庞大的规模所震撼——12000行代码、数十个功能模块交织在一起,就像一个功能齐全但臃肿不堪的"瑞士军刀"。本…...

避开这些坑!用Python做模糊控制项目时,关于隶属函数和规则表的5个常见误区
避开这些坑!用Python做模糊控制项目时,关于隶属函数和规则表的5个常见误区 第一次用Python实现模糊控制系统时,那种兴奋感我至今记得——仿佛打开了人工智能的另一扇门。但很快,这种兴奋就被各种报错和不符合预期的结果浇灭了。记…...

评估智能体性能:成功率、延迟与成本
一个从“拍脑袋优化”到“数据驱动调优”的真实转型故事 ——顺便聊聊我这三年烧掉的API费用和熬过的夜 去年夏天,我们团队做了一个电商智能客服Agent。上线第一周,各项指标看起来都挺正常:用户满意度4.7分,平均响应时间不到2秒。…...

录音转文字在线版有哪些?这几款免费录音转文字在线工具怎么选?
很多人做录音转文字的时候默认用专业级的转录服务,其实像提词匠这样的轻量工具已经够用了。特别是如果你只是偶尔需要把会议录音、课堂笔记、视频素材转成文字,不必非要上手深度学习复杂的专业软件。下面我梳理了目前市面上主流的录音转文字在线版工具,既有微信小程序也有网页版…...

书匠策AI到底在干嘛?用“拆快递“的方式,给你科普它的毕业论文功能全流程
各位同学,你们有没有拆过那种"一步一步跟着说明书就能装好"的宜家家具? 今天我要用拆快递的逻辑,帮你把书匠策AI(官网:h 官网直达:www.shujiangce.com,微信公众号搜一搜"书匠策…...